
Graph-Embedded Online Learning for Cell Detection and Tumour Proportion Score Estimation



Abstract
:1. Introduction
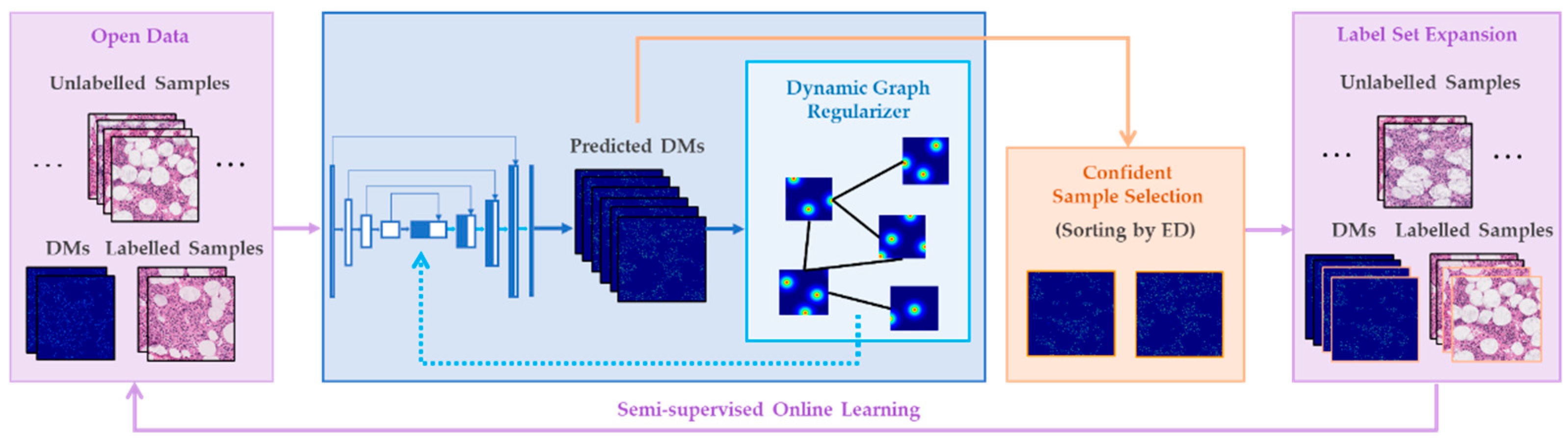
- It proposes an online learning network, GeoNet, for cell detection in open datasets. It is trained in a semi-supervised fashion, which enables learning features from unknown images while simultaneously predicting nuclear locations. It uses incomplete annotations and saves manual effort. To avoid introducing errors, GeoNet selects only the most reliable new samples with rigid confidence measured according to morphology features of extracted nuclear instances to optimize the backbone.
- The proposed GeoNet is designed to adapt to new images with various cell patterns. It leverages historical data and new images to enhance its feature representation ability and increase nuclear localization accuracy. Moreover, it engages dynamic graph regularization and learns inherent nonlinear structures of cells to gain generalizability.
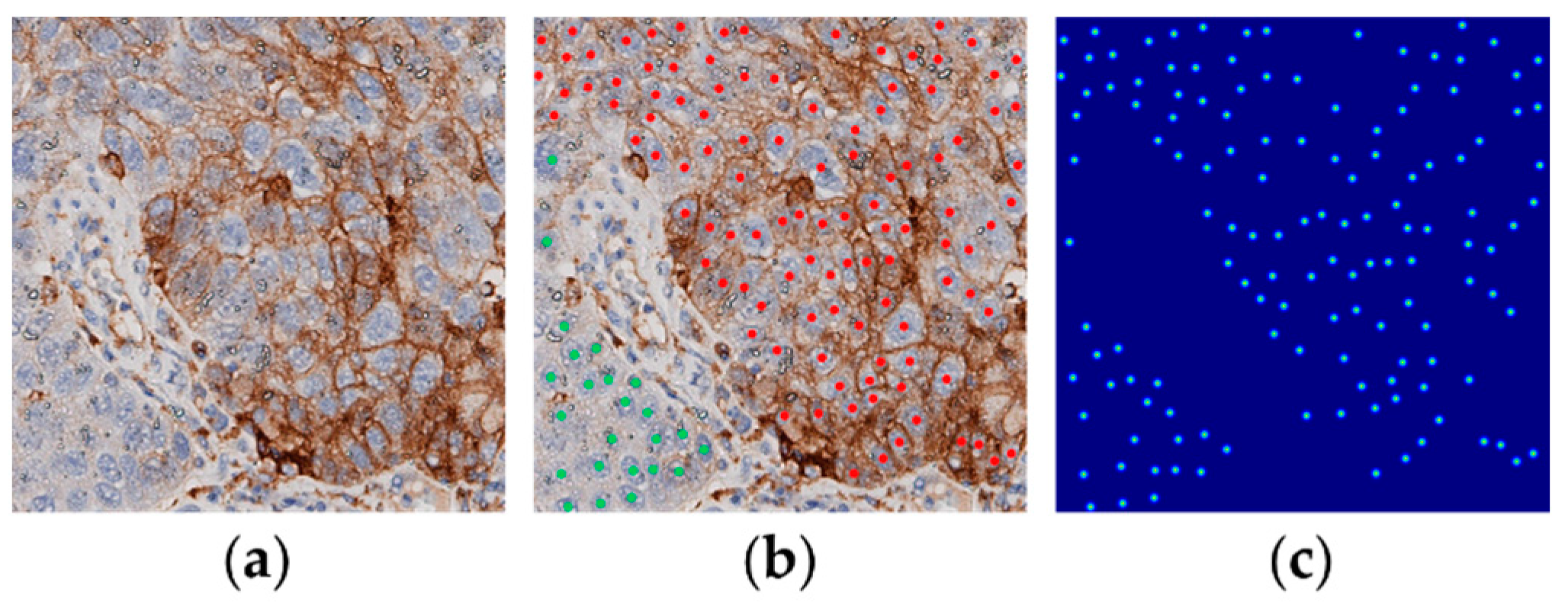
- GeoNet is a practical solution for computer-aided biomedical study and pathology diagnosis. It is a flexible framework, allowing any encoder-decoders for regression or pretrained networks for classification. Moreover, the cell detection results it produces can easily be used in many downstream applications, such as estimation of tumour proportion score (TPS), which is a key measurement for prognosis and treatment of lung squamous cell carcinoma (LUSC) [9].
2. Related Works
3. Methods
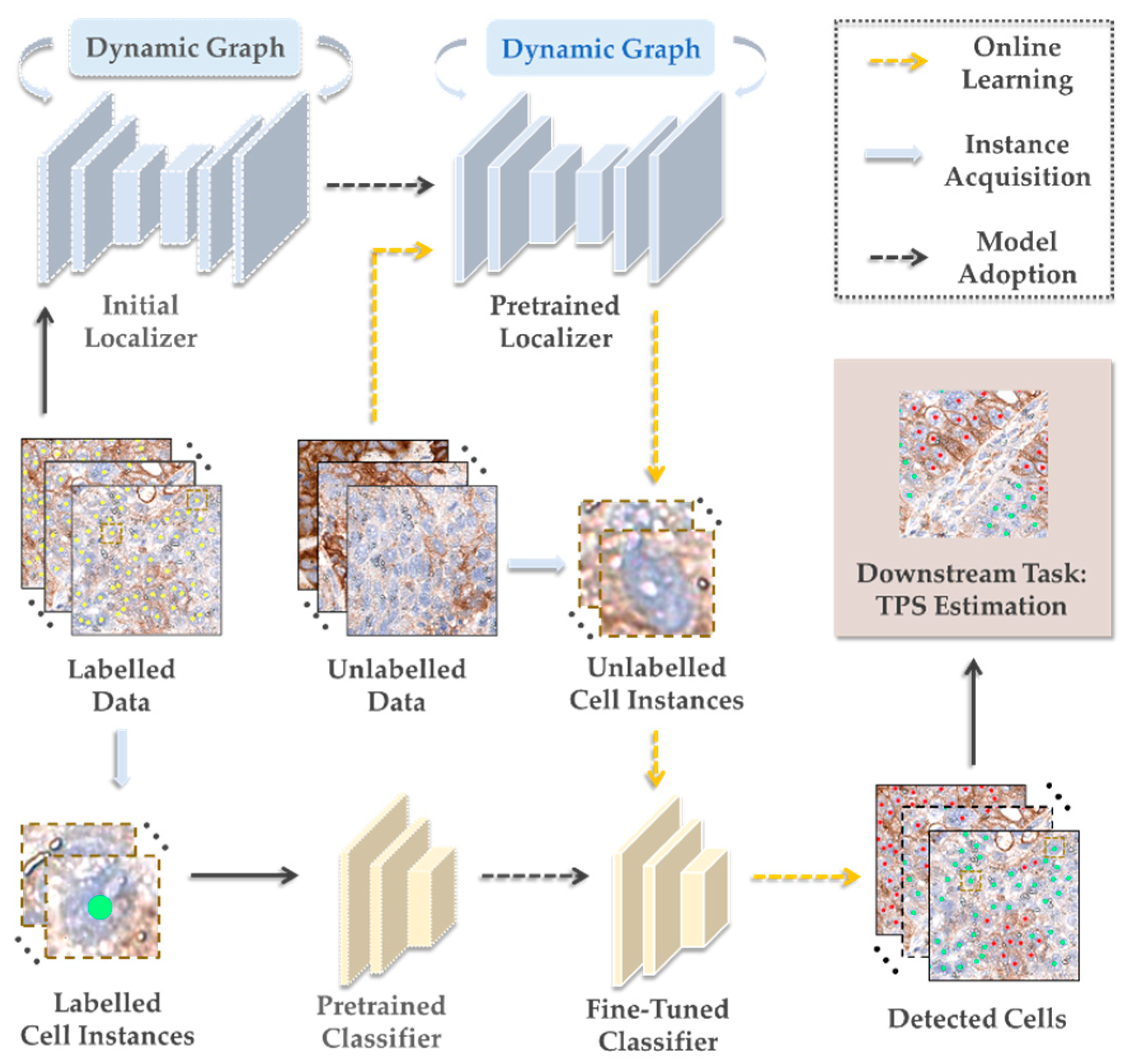
3.1. The Whole Pipeline for Online Cell Detection
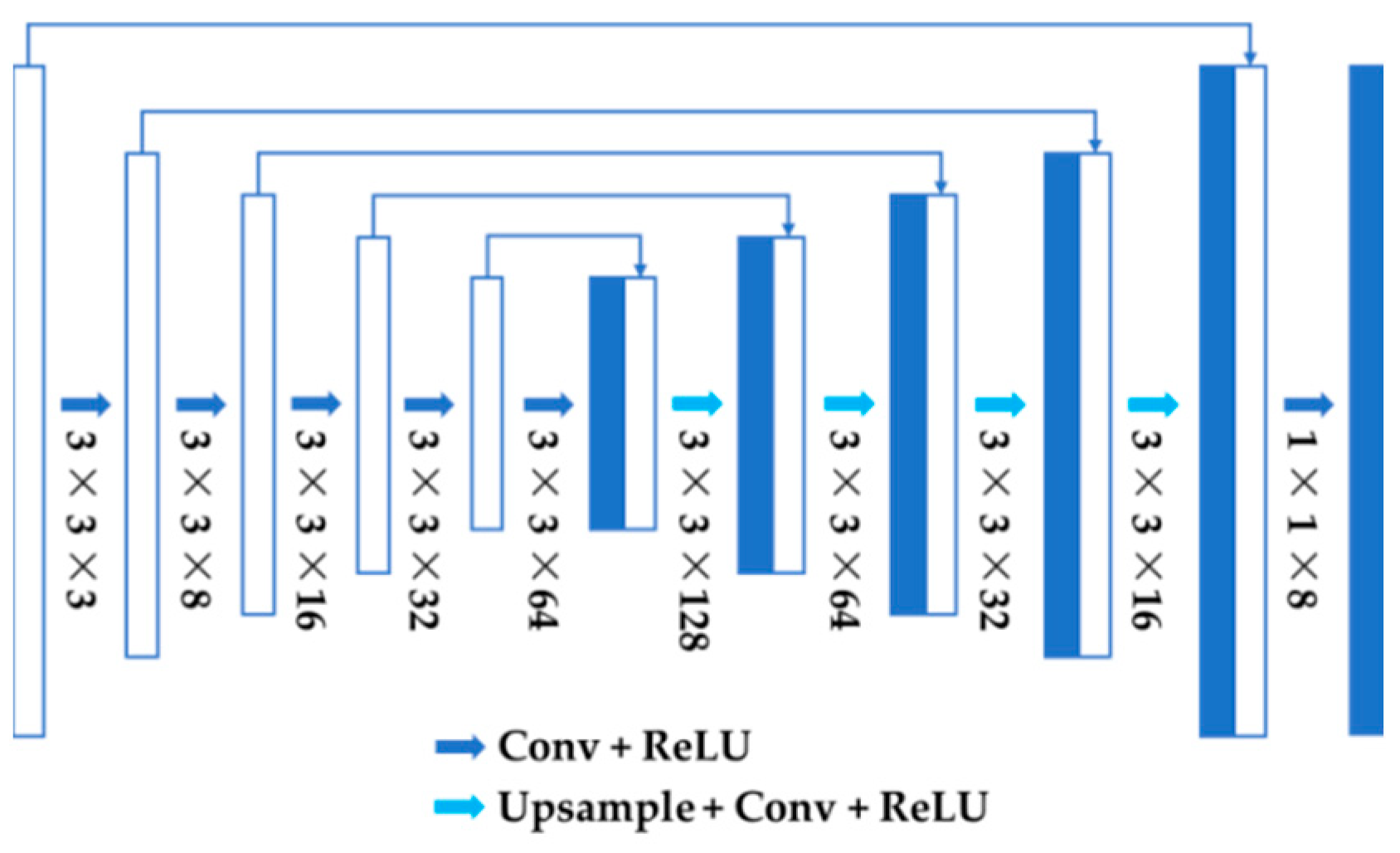
3.2. Nuclear Localization
3.2.1. Preprocessing
- (1)
- Patch split: To increase detection accuracy and reduce computational cost in each epoch, the microscopy images are split in an open dataset into patches , where , and represent the numbers of historical samples with dot annotations on nuclei and newly collected samples without any labels, respectively.
- (2)
- Distance map generation: Distance maps are used instead of location coordinates to train a regression network for cell detection, because the distance maps not only reflect nuclear locations but also encode spatial and morphological information of cells. The distance maps provide a better optimization goal for feature representation. They are also useful for confidence measurement and reliable sample selection, which is the key to our semi-supervised mechanism, to be fully introduced in the next subsection.
3.2.2. Graph-Embedded Network for Semi-Supervised Regression
3.2.3. Postprocessing
| Algorithm 1 Implementation details of the nuclear localizer |
| Input: labelled dataset with dot annotations and newly-sampled unlabelled images ; |
| Step 1 Preprocessing (1a) Split the input images into patches and ; (1b) Convert to distance maps by Equation (1); Step 2 Localization //Pretraining (2a) Pretrain on using Equation (5); (2b) Let the semi-supervised iteration number and ; (2c) Initialize the labelled set as ; //Semi-supervised Online Learning (2d) Feed to and infer ; (2e) Select most confident from ; (2f) Expand the label set as and ; let , and ; (2g) Fine-tune by Equation (6); (2h) Repeat Steps 2d–2g and produce ; Step 3 Postprocessing for (3a) Apply thresholding to and obtain ; (3b) Apply connected region filtering to and obtain ; (3c) Calculate the centroid of each region in and obtain ; end for |
| Output: predicted nuclear locations for . |
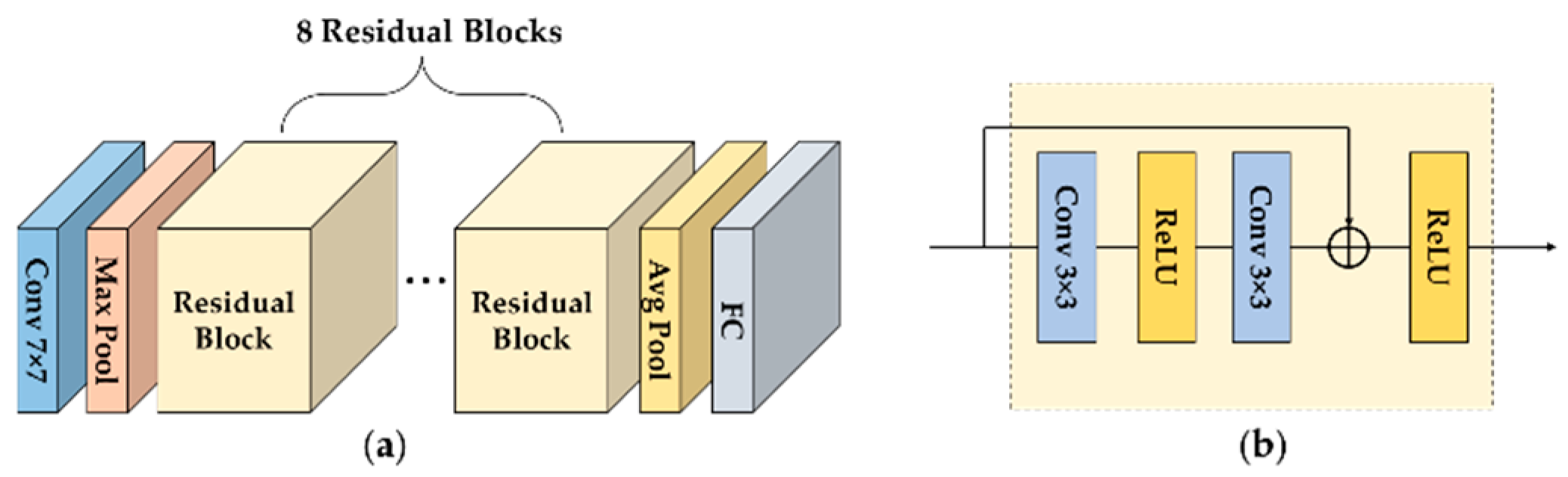
3.3. Cell Classification
| Algorithm 2 Online cell detection by GeoNet and TPS estimation with PD-L1 IHC slides |
| Input: with dot annotations and newly-sampled unlabelled PD-L1 slides ; |
| Step 1 Initialization (1a) Preprocess and produce as in Step1, Algorithm 1; (1b) Pretrain on using Equation (5); (1c) Fine-tune on as in Section 3.3; Step 2 Online Cell Detection //Localization (2a) Let the semi-supervised iteration number ; for (2b) Feed to and get via Steps 2d–2g in Algorithm 1; (2c) Predict cell locations via Steps 3a–3c in Algorithm 1; //Classification (2d) Obtain from as described in Section 3.3; (2e) Feed to and infer cell classes ; //TPS Estimation (2f) Compute TPS for by Equation (8); end for. |
| Output: predicted nuclear locations , inferred cell classes , and estimated TPS for , where . |
3.4. Application: TPS Estimation
4. Results
4.1. Datasets
- This dataset comprises bacterial cells in fluorescent-light microscopy images (BCFM) [39]. It contains 200 synthetic images, each with 256 × 256 pixels and 171 ± 64 cells. We randomly selected 32 images from the first 50 images as the labelled set and 50–100 images as unlabelled set (i.e., newly sampled data for online learning).
- The bone marrow (BM) [40] dataset consists of 11 H&E images with 1200 × 1200 pixels, cropped from WSIs (40× magnification) from 8 different patients. We split them into 44 patches, each with 600 × 600 pixels. The labelled set used 15 patches the unlabelled set used 18.
- The Kaggle 2018 Data Science Bowl dataset (Kaggle) [41] contains 670 H&E stained images of different sizes. From these, 335 images were used as the labelled set and 135 as the unlabelled set.
- Pan-Cancer Histology Data for Nuclei Instance Segmentation and Classification (PanNuke) [42] contains 7901 images with 256 × 256 pixels of 19 different tissues, including neoplastic cells, inflammatory cells, connective tissue cells, dead cells and epithelial cells. The data set was supplied split into three subsets. We used the first subset as the labelled set and the second as the unlabelled set.
- LUSC is an in-house dataset, provided by a teaching hospital and a professional pathology diagnosis center [9]. It contains 43 immuostained PD-L1 images with 1000 × 1000 pixels cropped from 4 WSIs scanned with KF-PRO-120 (0.2481 μm/pixel, 40× magnification). We randomly selected 34 images as the labelled set and 9 images as the unlabelled set.
4.2. Implementation Details
4.3. Experimental Analysis
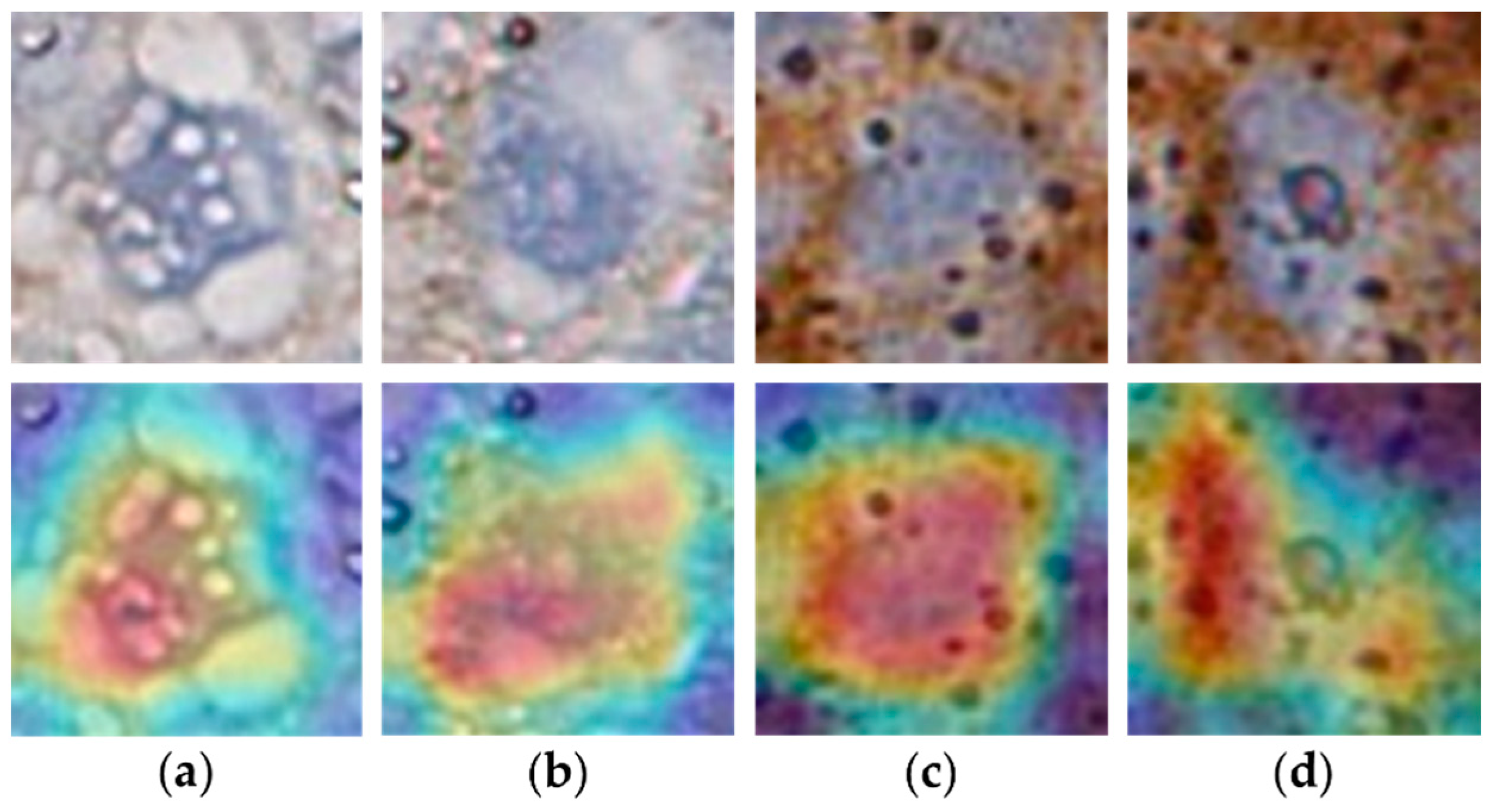
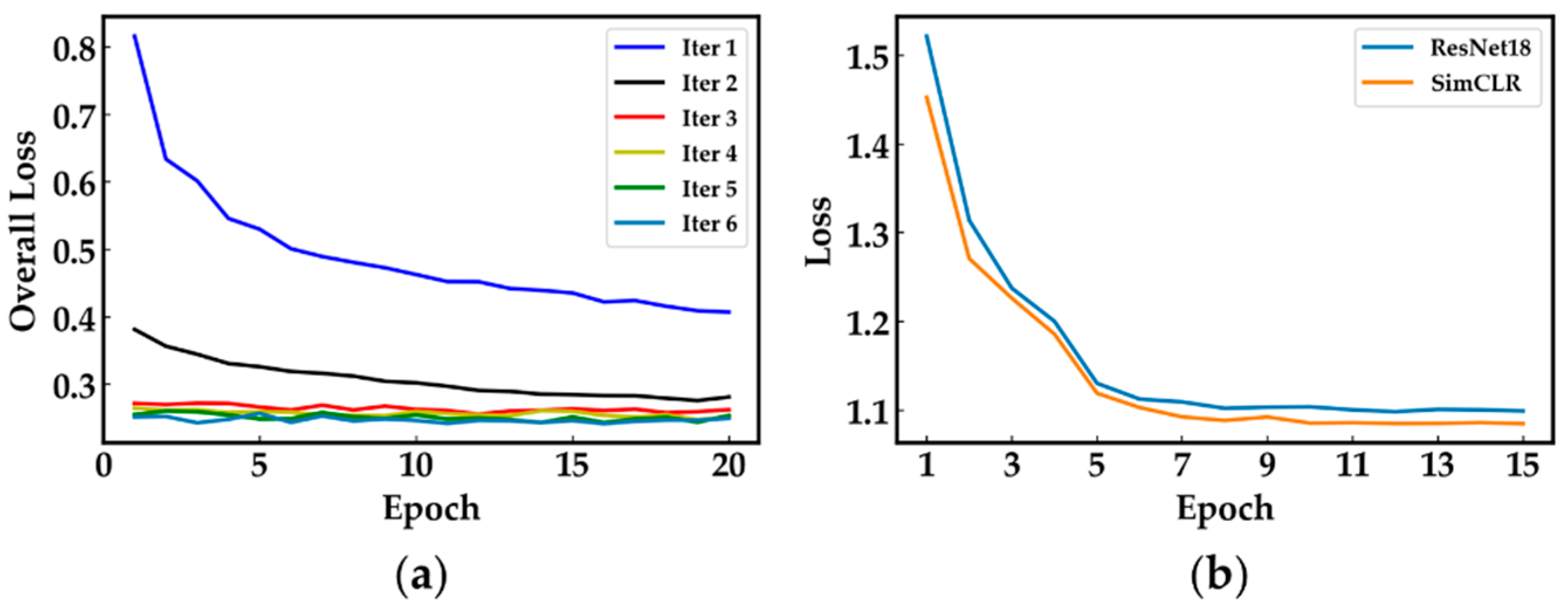
4.3.1. Detection Performance
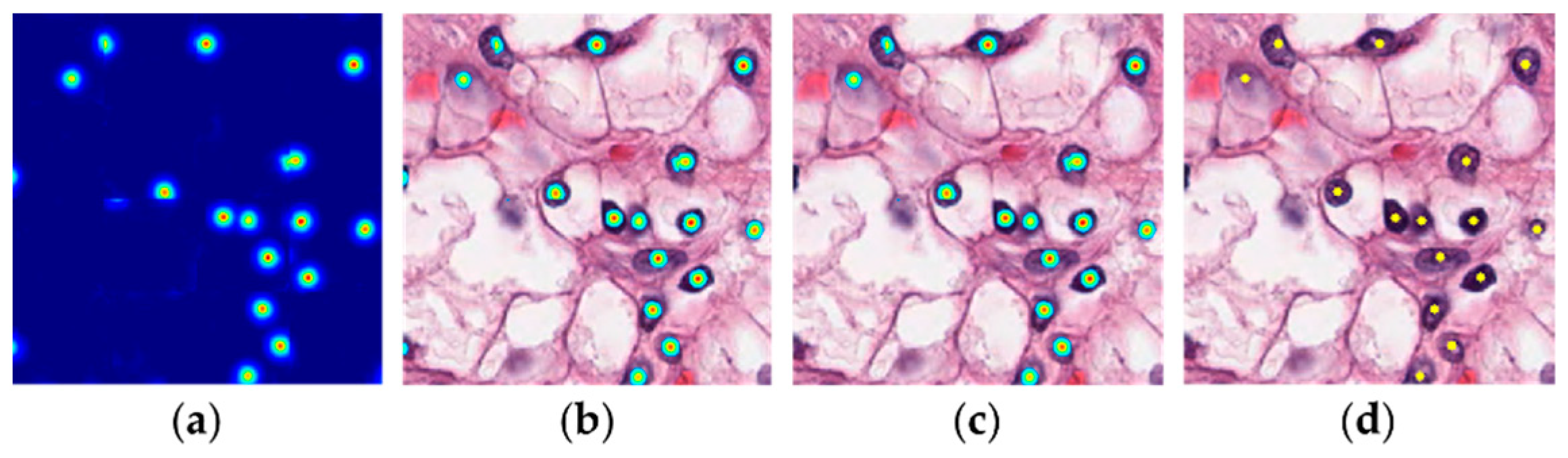
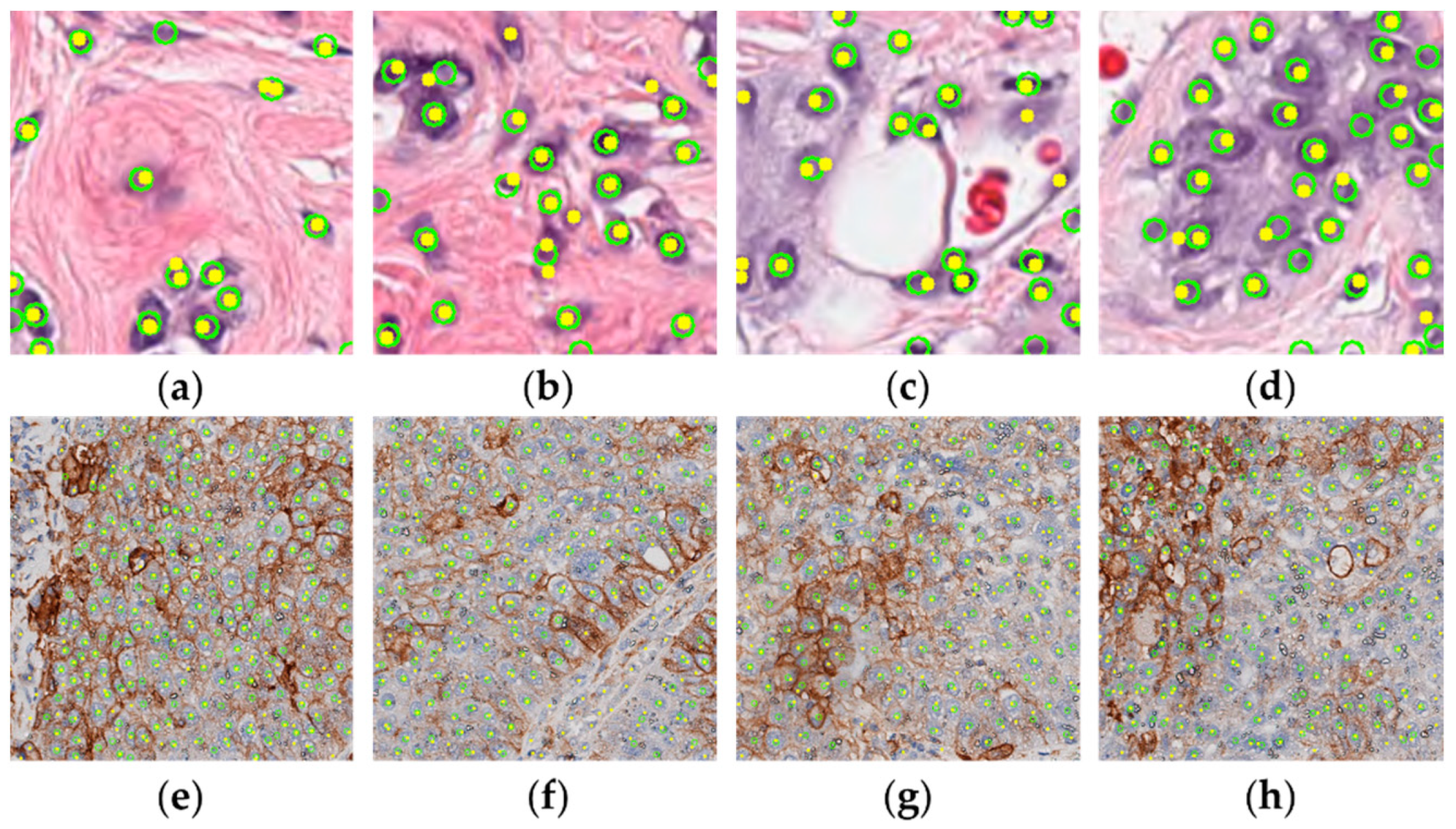
4.3.2. Detailed Localization Results
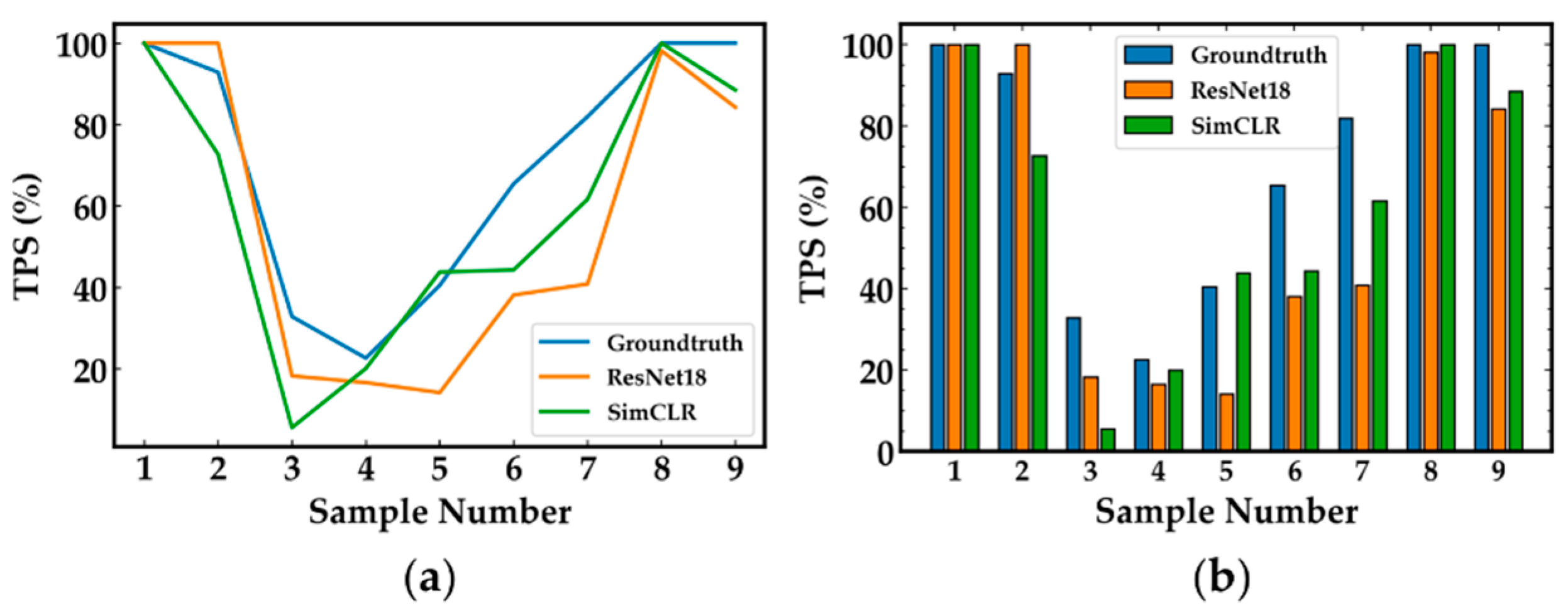
4.3.3. TPS Estimation Errors
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xie, Y.; Xing, F.; Shi, X.; Kong, X.; Su, H.; Yang, L. Efficient and robust cell detection: A structured regression approach. Med. Image Anal. 2018, 44, 245–254. [Google Scholar] [CrossRef] [PubMed]
- Saranya, A.; Kottilingam, K. A Survey on Bone Fracture Identification Techniques using Quantitative and Learning Based Algorithms. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 241–248. [Google Scholar]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, J.; Xiao, L.; Lian, Z. Contour-Seed Pairs Learning-Based Framework for Simultaneously Detecting and Segmenting Various Overlapping Cells/Nuclei in Microscopy Images. IEEE Trans. Image Process. 2018, 27, 5759–5774. [Google Scholar] [CrossRef]
- Xing, F.; Xie, Y.; Yang, L. An Automatic Learning-Based Framework for Robust Nucleus Segmentation. IEEE Trans. Med. Imaging 2016, 35, 550–566. [Google Scholar] [CrossRef]
- Li, J.; Yang, S.; Huang, X.; Da, Q.; Yang, X.; Hu, Z.; Duan, Q.; Wang, C.; Li, H. Signet Ring Cell Detection With a Semi-supervised Learning Framework. arXiv 2019, arXiv:1907.03954. [Google Scholar]
- Ying, H.; Song, Q.; Chen, J.; Liang, T.; Gu, J.; Zhuang, F.; Chen, D.Z.; Wu, J. A semi-supervised deep convolutional framework for signet ring cell detection. Neurocomputing 2021, 453, 347–356. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Z.; Liu, J.; Zheng, Q.; Zhu, Y.; Zuo, Y.; Wang, Z.; Guan, X.; Wang, Y.; Li, Y. Weakly Supervised Histopathology Image Segmentation With Sparse Point Annotations. IEEE J. Biomed. Health Inform. 2021, 25, 1673–1685. [Google Scholar] [CrossRef]
- Chen, Y.; Liang, D.; Bai, X.; Xu, Y.; Yang, X. Cell Localization and Counting Using Direction Field Map. IEEE J. Biomed. Health Inform. 2022, 26, 359–368. [Google Scholar] [CrossRef]
- Huang, Z.; Ding, Y.; Song, G.; Wang, L.; Geng, R.; He, H.; Du, S.; Liu, X.; Tian, Y.; Liang, Y.; et al. BCData: A Large-Scale Dataset and Benchmark for Cell Detection and Counting. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020, Lima, Peru, 4–8 October 2020; pp. 289–298. [Google Scholar]
- Song, T.H.; Sanchez, V.; Daly, H.E.; Rajpoot, N.M. Simultaneous Cell Detection and Classification in Bone Marrow Histology Images. IEEE J. Biomed. Health Inform. 2019, 23, 1469–1476. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Xing, F.; Kong, X.; Su, H.; Yang, L. Beyond Classification: Structured Regression for Robust Cell Detection Using Convolutional Neural Network. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 358–365. [Google Scholar]
- Hagos, Y.B.; Narayanan, P.L.; Akarca, A.U.; Marafioti, T.; Yuan, Y. ConCORDe-Net: Cell Count Regularized Convolutional Neural Network for Cell Detection in Multiplex Immunohistochemistry Images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; pp. 667–675. [Google Scholar]
- Saha, M.; Chakraborty, C. Her2Net: A Deep Framework for Semantic Segmentation and Classification of Cell Membranes and Nuclei in Breast Cancer Evaluation. IEEE Trans. Image Process. 2018, 27, 2189–2200. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Grunewald, T.; Akarca, A.U.; Ledermann, J.A.; Marafioti, T.; Yuan, Y. Symmetric Dense Inception Network for Simultaneous Cell Detection and Classification in Multiplex Immunohistochemistry Images. In Proceedings of the MICCAI Workshop on Computational Pathology, Strasbourg, France, 27 September–1 October 2021; pp. 246–257. [Google Scholar]
- Hou, L.; Nguyen, V.; Kanevsky, A.B.; Samaras, D.; Kurc, T.M.; Zhao, T.; Gupta, R.R.; Gao, Y.; Chen, W.; Foran, D.; et al. Sparse autoencoder for unsupervised nucleus detection and representation in histopathology images. Pattern Recogn. 2019, 86, 188–200. [Google Scholar] [CrossRef] [PubMed]
- Javed, S.; Mahmood, A.; Dias, J.; Werghi, N.; Rajpoot, N. Spatially Constrained Context-Aware Hierarchical Deep Correlation Filters for Nucleus Detection in Histology Images. Med. Image Anal. 2021, 72, 102104. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Bigras, G.; Hugh, J.; Ray, N. Training Convolutional Neural Networks and Compressed Sensing End-to-End for Microscopy Cell Detection. IEEE Trans. Med. Imaging 2019, 38, 2632–2641. [Google Scholar] [CrossRef] [Green Version]
- Theera-Umpon, N. White Blood Cell Segmentation and Classification in Microscopic Bone Marrow Images. In Proceedings of the Fuzzy Systems and Knowledge Discovery, Changsha, China, 27–29 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 787–796. [Google Scholar]
- Sharma, H.; Zerbe, N.; Heim, D.; Wienert, S.; Behrens, H.-M.; Hellwich, O.; Hufnagl, P. A Multi-resolution Approach for Combining Visual Information using Nuclei Segmentation and Classification in Histopathological Images. In Proceedings of the 10th International Conference on Computer Vision Theory and Applications, Berlin, Germany, 11–14 March 2015; pp. 37–46. [Google Scholar]
- Yang, X.; Li, H.; Zhou, X. Nuclei Segmentation Using Marker-Controlled Watershed, Tracking Using Mean-Shift, and Kalman Filter in Time-Lapse Microscopy. IEEE Trans. Circuits Syst. Regul. Pap. 2006, 53, 2405–2414. [Google Scholar] [CrossRef]
- Veta, M.; van Diest, P.J.; Kornegoor, R.; Huisman, A.; Viergever, M.A.; Pluim, J.P.W. Automatic Nuclei Segmentation in H&E Stained Breast Cancer Histopathology Images. PLoS ONE 2013, 8, e70221. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Mualla, F.; Schöll, S.; Sommerfeldt, B.; Maier, A.K.; Steidl, S.; Buchholz, R.; Hornegger, J. Unsupervised Unstained Cell Detection by SIFT Keypoint Clustering and Self-labeling Algorithm. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2014, Boston, MA, USA, 20 June–29 August 2014; pp. 377–384. [Google Scholar]
- Tofighi, M.; Guo, T.; Vanamala, J.K.P.; Monga, V. Prior Information Guided Regularized Deep Learning for Cell Nucleus Detection. IEEE Trans. Med. Imaging 2019, 38, 2047–2058. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zheng, Q.; Mu, X.; Zuo, Y.; Xu, B.; Jin, Y.; Wang, Y.; Tian, H.; Yang, Y.; Xue, Q.; et al. Automated tumor proportion score analysis for PD-L1 (22C3) expression in lung squamous cell carcinoma. Sci. Rep. 2021, 11, 15907. [Google Scholar] [CrossRef]
- Hondelink, L.M.; Hüyük, M.; Postmus, P.E.; Smit, V.; Blom, S.; von der Thüsen, J.H.; Cohen, D. Development and validation of a supervised deep learning algorithm for automated whole-slide programmed death-ligand 1 tumour proportion score assessment in non-small cell lung cancer. Histopathology 2022, 80, 635–647. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zheng, Y.; Chen, Z.; Zuo, Y.; Guan, X.; Wang, Z.; Mu, X. Manifold-Regularized Regression Network: A Novel End-to-End Method for Cell Counting and Localization. In Proceedings of the 4th International Conference on Innovation in Artificial Intelligence, Xiamen, China, 8–11 May 2020; pp. 121–124. [Google Scholar]
- Dong, W.; Moses, C.; Li, K. Efficient k-nearest neighbor graph construction for generic similarity measures. In Proceedings of the 20th international conference on World wide web, Hyderabad, India, 28 March–1 April 2011; pp. 577–586. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Remove Small Objects Function. Available online: https://scikit-image.org/docs/stable/api/skimage.morphology.html#skimage.morphology.remove_small_objects (accessed on 11 March 2022).
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. arXiv 2020, arXiv:2011.13971. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Mok, T.S.K.; Wu, Y.L.; Kudaba, I.; Kowalski, D.M.; Cho, B.C.; Turna, H.Z.; Castro, G., Jr.; Srimuninnimit, V.; Laktionov, K.K.; Bondarenko, I.; et al. Pembrolizumab versus chemotherapy for previously untreated, PD-L1-expressing, locally advanced or metastatic non-small-cell lung cancer (KEYNOTE-042): A randomised, open-label, controlled, phase 3 trial. Lancet 2019, 393, 1819–1830. [Google Scholar] [CrossRef]
- Lempitsky, V.; Zisserman, A. Learning To count objects in images. In Proceedings of the 23rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1324–1332. [Google Scholar]
- Kainz, P.; Urschler, M.; Schulter, S.; Wohlhart, P.; Lepetit, V. You Should Use Regression to Detect Cells. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 276–283. [Google Scholar]
- Kaggle 2018 Data Science Bowl. Available online: https://www.kaggle.com/c/data-science-bowl-2018/data (accessed on 11 March 2022).
- Gamper, J.; Alemi Koohbanani, N.; Benet, K.; Khuram, A.; Rajpoot, N. PanNuke: An Open Pan-Cancer Histology Dataset for Nuclei Instance Segmentation and Classification. In Proceedings of the Digital Pathology, Athens, Greece, 29 August–1 September 2019; pp. 11–19. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cell Type | GeoNet-ResNet18 | GeoNet-SimCLR | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Neoplastic | 0.626 | 0.792 | 0.700 | 0.621 | 0.806 | 0.702 |
| Epithelial | 0.497 | 0.414 | 0.452 | 0.535 | 0.343 | 0.418 |
| Inflammatory | 0.627 | 0.668 | 0.647 | 0.636 | 0.667 | 0.651 |
| Connective | 0.575 | 0.539 | 0.556 | 0.588 | 0.517 | 0.550 |
| Dead | 0.551 | 0.326 | 0.410 | 0.535 | 0.343 | 0.418 |
| Cell Type | GeoNet-ResNet18 | GeoNet-SimCLR | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Negative | 0.671 | 0.772 | 0.718 | 0.692 | 0.781 | 0.734 |
| Positive | 0.800 | 0.703 | 0.748 | 0.812 | 0.731 | 0.769 |
| Model | BCFM | BM | Kaggle | PanNuke | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| U-Net | 0.920 | 0.916 | 0.918 | 0.742 | 0.810 | 0.775 | 0.767 | 0.841 | 0.802 | 0.652 | 0.691 | 0.671 |
| SR | 0.758 | 0.816 | 0.786 | 0.855 | 0.932 | 0.892 | 0.720 | 0.745 | 0.732 | 0.648 | 0.667 | 0.657 |
| GeNet | 0.935 | 0.914 | 0.924 | 0.844 | 0.961 | 0.899 | 0.847 | 0.829 | 0.838 | 0.687 | 0.702 | 0.694 |
| O-U-Net | 0.924 | 0.920 | 0.922 | 0.765 | 0.813 | 0.789 | 0.768 | 0.868 | 0.815 | 0.690 | 0.711 | 0.700 |
| O-SR | 0.764 | 0.824 | 0.793 | 0.875 | 0.933 | 0.903 | 0.755 | 0.785 | 0.770 | 0.677 | 0.680 | 0.678 |
| GeoNet | 0.935 | 0.919 | 0.927 | 0.868 | 0.950 | 0.907 | 0.850 | 0.846 | 0.848 | 0.712 | 0.730 | 0.721 |
| Model | Time Cost for Training (s/image) | Time Cost for Prediction (s/image) |
|---|---|---|
| O-U-Net | 410.57 | 0.34 |
| O-SR | 820.98 | 0.54 |
| GeoNet | 658.14 | 0.35 |
| Estimation Method | GeoNet-ResNet18 | GeoNet-SimCLR |
|---|---|---|
| Real TPS | 70.7% | |
| Predicted TPS | 56.7% | 59.6% |
| Relative Error | 13.9% | 11.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Zhu, Y.; Chen, Z. Graph-Embedded Online Learning for Cell Detection and Tumour Proportion Score Estimation. Electronics 2022, 11, 1642. https://doi.org/10.3390/electronics11101642
Chen J, Zhu Y, Chen Z. Graph-Embedded Online Learning for Cell Detection and Tumour Proportion Score Estimation. Electronics. 2022; 11(10):1642. https://doi.org/10.3390/electronics11101642
Chicago/Turabian StyleChen, Jinhao, Yuang Zhu, and Zhao Chen. 2022. "Graph-Embedded Online Learning for Cell Detection and Tumour Proportion Score Estimation" Electronics 11, no. 10: 1642. https://doi.org/10.3390/electronics11101642
APA StyleChen, J., Zhu, Y., & Chen, Z. (2022). Graph-Embedded Online Learning for Cell Detection and Tumour Proportion Score Estimation. Electronics, 11(10), 1642. https://doi.org/10.3390/electronics11101642