
Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification


Abstract
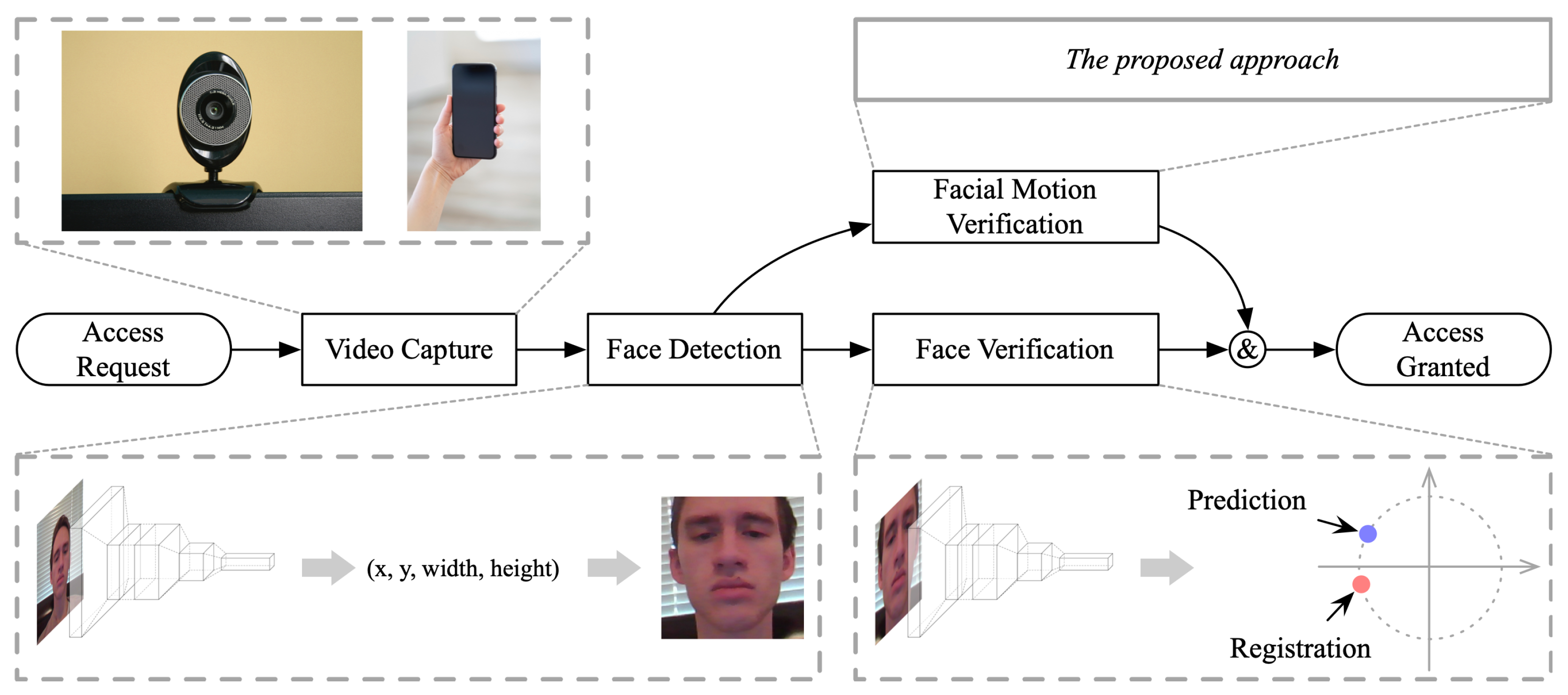
:1. Introduction
1.1. Background
1.1.1. Video-Based Facial Expression Recognition
1.1.2. Pre-Training Approaches
1.1.3. Lightweight Structures for Face Analysis
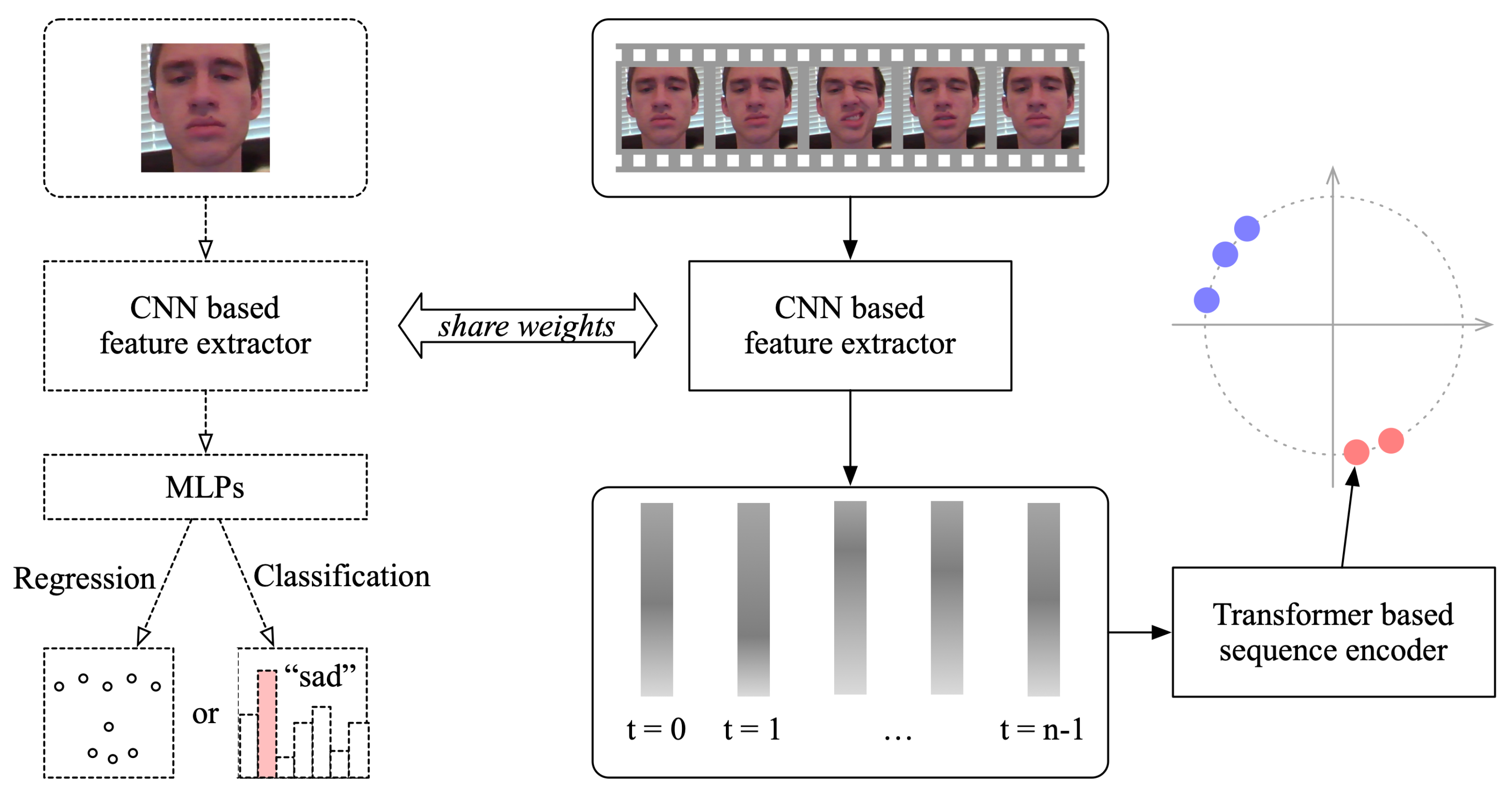
2. Methods
2.1. Spatial Feature Extractors
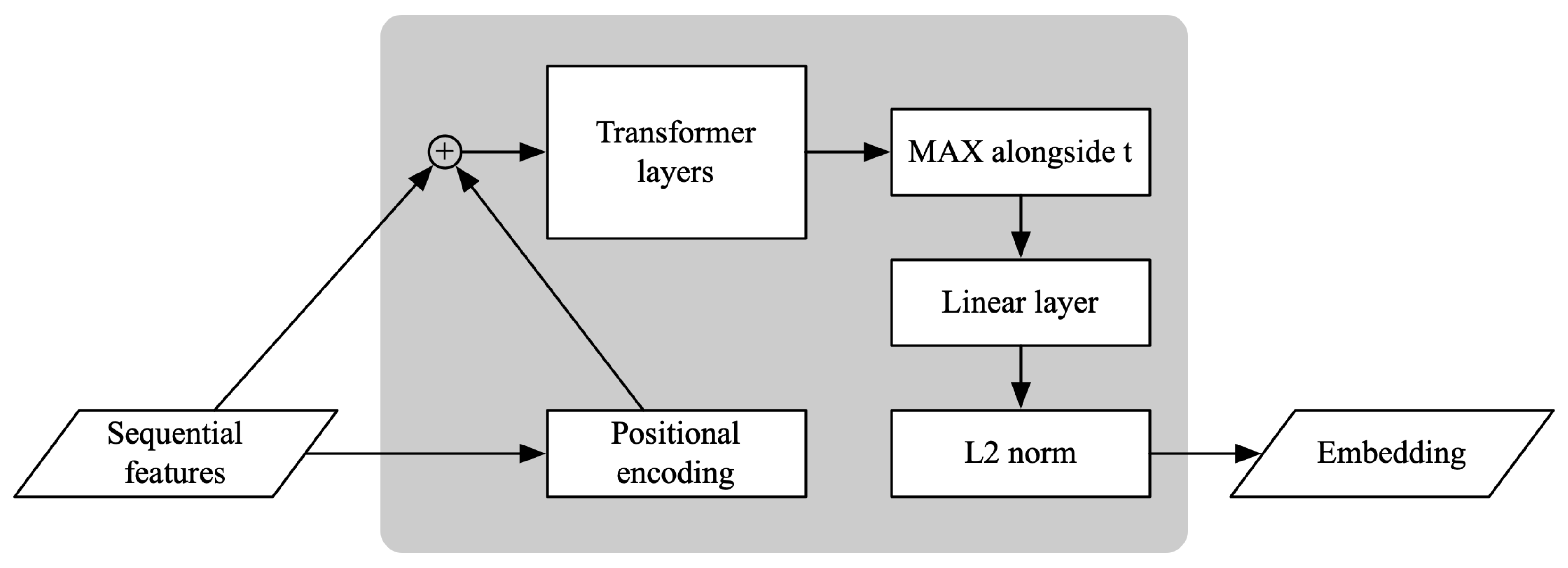
2.2. Sequence Encoder
2.3. Loss Functions
2.4. Dataset
2.5. Augmentation
3. Experiments and Results
3.1. Metrics
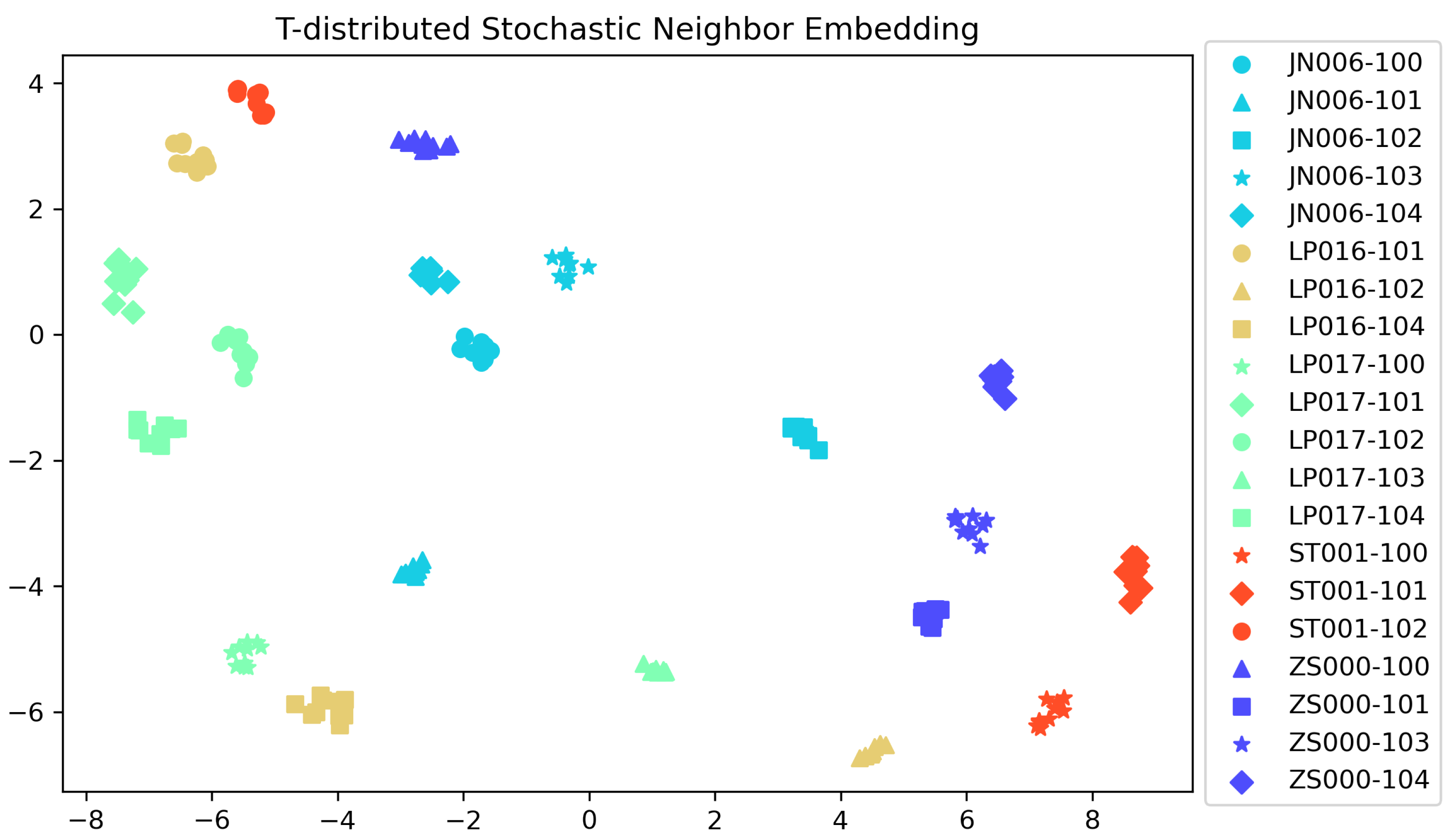
3.2. Customized Facial Motions
3.3. Lip Movements
4. Discussion
4.1. Failed Cases
4.1.1. False Positive Cases
4.1.2. False Negative Cases
4.2. Other Potential Applications
4.3. Future Research Directions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar]
- Marelli, D.; Bianco, S.; Ciocca, G. Faithful Fit, Markerless, 3D Eyeglasses Virtual Try-On. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 460–471. [Google Scholar]
- Xu, Z.; Li, S.; Deng, W. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 141–145. [Google Scholar]
- Sun, Z.; Lee, D.J.; Zhang, D.; Li, X. Concurrent Two-Factor Identify Verification Using Facial Identify and Facial Actions. Electron. Imaging 2021, 2021, 318-1–318-7. [Google Scholar] [CrossRef]
- Yin, D.B.M.; Mukhlas, A.A.; Chik, R.Z.W.; Othman, A.T.; Omar, S. A proposed approach for biometric-based authentication using of face and facial expression recognition. In Proceedings of the 2018 IEEE 3rd International Conference on Communication and Information Systems (ICCIS), Singapore, 28–30 December 2018; pp. 28–33. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Meng, D.; Peng, X.; Wang, K.; Qiao, Y. Frame attention networks for facial expression recognition in videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3866–3870. [Google Scholar]
- Meng, Z.; Liu, P.; Cai, J.; Han, S.; Tong, Y. Identity-aware convolutional neural network for facial expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 558–565. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 1. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Computer Vision– ACCV 2014, Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 143–157. [Google Scholar]
- Chen, W.; Zhang, D.; Li, M.; Lee, D.J. Stcam: Spatial-temporal and channel attention module for dynamic facial expression recognition. IEEE Trans. Affect. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Teng, J.; Zhang, D.; Zou, W.; Li, M.; Lee, D.J. Typical Facial Expression Network Using a Facial Feature Decoupler and Spatial-Temporal Learning. IEEE Trans. Affect. Comput. 2021, 1. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q. Former-DFER: Dynamic Facial Expression Recognition Transformer. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 1553–1561. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Becattini, F.; Song, X.; Baecchi, C.; Fang, S.T.; Ferrari, C.; Nie, L.; Del Bimbo, A. PLM-IPE: A Pixel-Landmark Mutual Enhanced Framework for Implicit Preference Estimation. In MMAsia ’21: ACM Multimedia Asia; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
- Liu, X.; Xia, Y.; Yu, H.; Dong, J.; Jian, M.; Pham, T.D. Region based parallel hierarchy convolutional neural network for automatic facial nerve paralysis evaluation. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2325–2332. [Google Scholar] [CrossRef] [PubMed]
- Bulat, A.; Cheng, S.; Yang, J.; Garbett, A.; Sanchez, E.; Tzimiropoulos, G. Pre-training strategies and datasets for facial representation learning. arXiv 2021, arXiv:2103.16554. [Google Scholar]
- Guan, J.; Shen, D. Transfer Spatio-Temporal Knowledge from Emotion-Related Tasks for Facial Expression Spotting. In FME’21: Proceedings of the 1st Workshop on Facial Micro-Expression: Advanced Techniques for Facial Expressions Generation and Spotting; Association for Computing Machinery: New York, NY, USA, 2021; pp. 19–24. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In Proceedings of the Chinese Conference on Biometric Recognition, Urumqi, China, 11–12 August 2018; Springer: Cham, Switzerland, 2018; pp. 428–438. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the International Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008; pp. 1–11. [Google Scholar]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-millisecond neural face detection on mobile gpus. arXiv 2019, arXiv:1907.05047. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Chen, C. PyTorch Face Landmark: A Fast and Accurate Facial Landmark Detector. Available online: https://github.com/cunjian/pytorch_face_landmark (accessed on 20 June 2022).
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: Database and results. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Bates, D.; Dromey, C.; Xu, X.; Antani, S. An imaging system correlating lip shapes with tongue contact patterns for speech pathology research. In Proceedings of the 16th IEEE Symposium Computer-Based Medical Systems, New York, NY, USA, 26–27 June 2003; pp. 307–313. [Google Scholar]
- Grishchenko, I.; Ablavatski, A.; Kartynnik, Y.; Raveendran, K.; Grundmann, M. Attention Mesh: High-fidelity Face Mesh Prediction in Real-time. arXiv 2020, arXiv:2006.10962. [Google Scholar]
- Wood, E.; Baltrusaitis, T.; Hewitt, C.; Johnson, M.; Shen, J.; Milosavljevic, N.; Wilde, D.; Garbin, S.; Sharp, T.; Stojiljkovic, I.; et al. 3D face reconstruction with dense landmarks. arXiv 2022, arXiv:2204.02776. [Google Scholar]
- Kollias, D.; Zafeiriou, S. Expression, affect, action unit recognition: Aff-wild2, multi-task learning and arcface. arXiv 2019, arXiv:1910.04855. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extractors | Loss Functions | Random Trimming | Average Precision | Peak -Score |
|---|---|---|---|---|
| SFE-E | contrastive | Y | 0.967 | 0.914 |
| contrastive | N | 0.966 | 0.912 | |
| N-pair | Y | 0.969 | 0.918 | |
| N-pair | N | 0.969 | 0.914 | |
| SFE-L | contrastive | Y | 0.988 | 0.959 |
| contrastive | N | 0.987 | 0.955 | |
| N-pair | Y | 0.986 | 0.957 | |
| N-pair | N | 0.986 | 0.955 |
| Training Data | Test Data | Average Precision | Peak -Score |
|---|---|---|---|
| LM | LM | 0.819 | 0.742 |
| FM, LM | LM | 0.816 | 0.741 |
| FM, LM | FM | 0.984 | 0.951 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Sumsion, A.W.; Torrie, S.A.; Lee, D.-J. Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification. Electronics 2022, 11, 1946. https://doi.org/10.3390/electronics11131946
Sun Z, Sumsion AW, Torrie SA, Lee D-J. Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification. Electronics. 2022; 11(13):1946. https://doi.org/10.3390/electronics11131946
Chicago/Turabian StyleSun, Zheng, Andrew W. Sumsion, Shad A. Torrie, and Dah-Jye Lee. 2022. "Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification" Electronics 11, no. 13: 1946. https://doi.org/10.3390/electronics11131946
APA StyleSun, Z., Sumsion, A. W., Torrie, S. A., & Lee, D. -J. (2022). Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification. Electronics, 11(13), 1946. https://doi.org/10.3390/electronics11131946