
Transformer-Based GAN for New Hairstyle Generative Networks



Abstract
:1. Introduction
- We propose a novel hairstyle generation composite network, Face Transformer Generative Hairstyle networks (FTGH), to overcome the single generation network and the abnormal situation of generating new hairstyle images of people by adding modules for extracting face masks and segmenting face regions to enhance the realistic effects of GAN image generation.
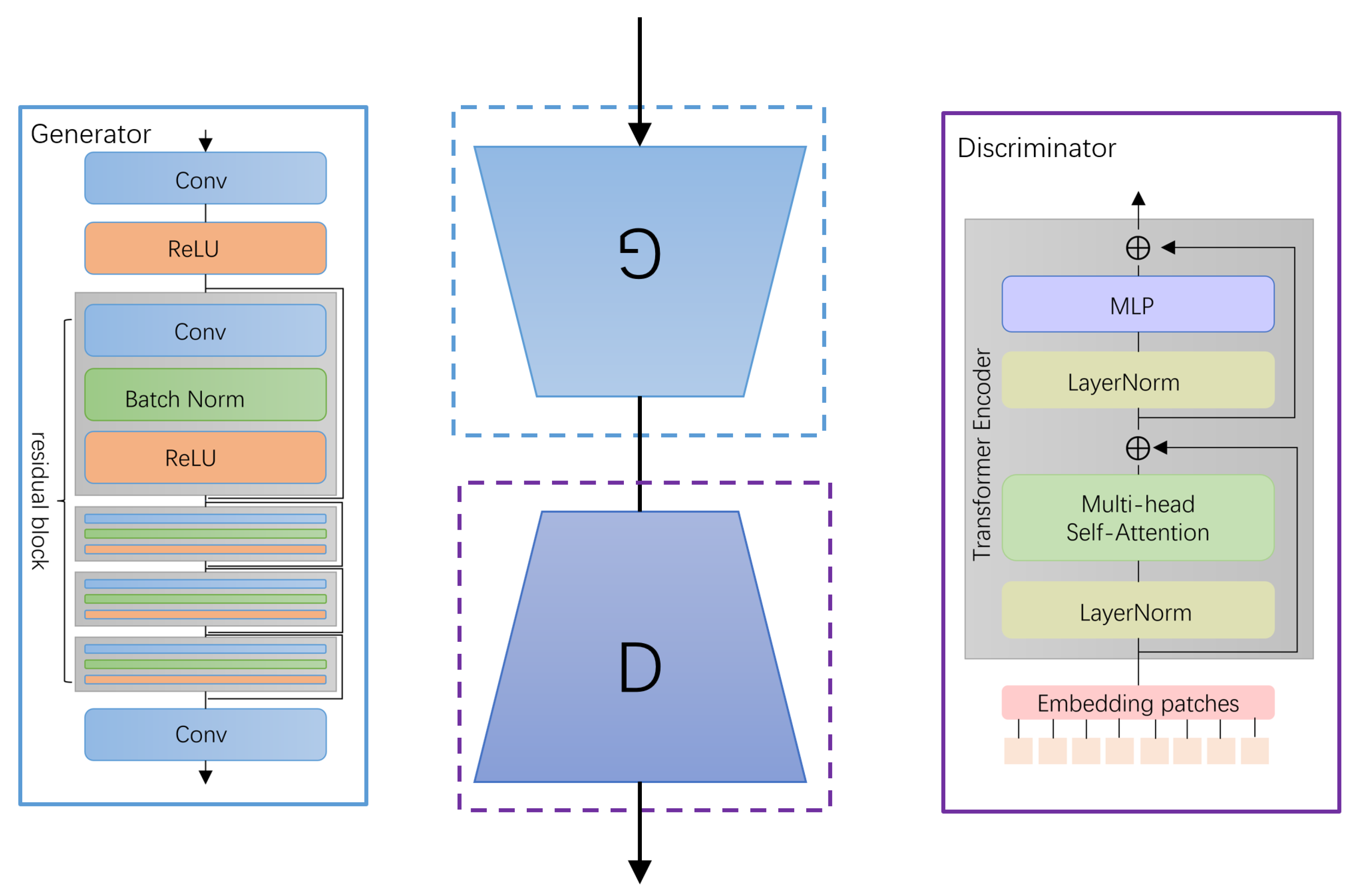
- We designed a GAN image generation network incorporating transformers. To avoid the problem of insufficient accuracy of images generated by Vision Transformer (ViT), ResNet was used for image generation in the generator part and the transformer method was used to discriminate the generated images in the discriminator part.
- We used the open-source datasets CelebA-HQ and FFHQ to train and validate our proposed model. Verification with various image evaluation standards revealed that our method is more robust than the other existing methods.
2. Related Work
3. Methods
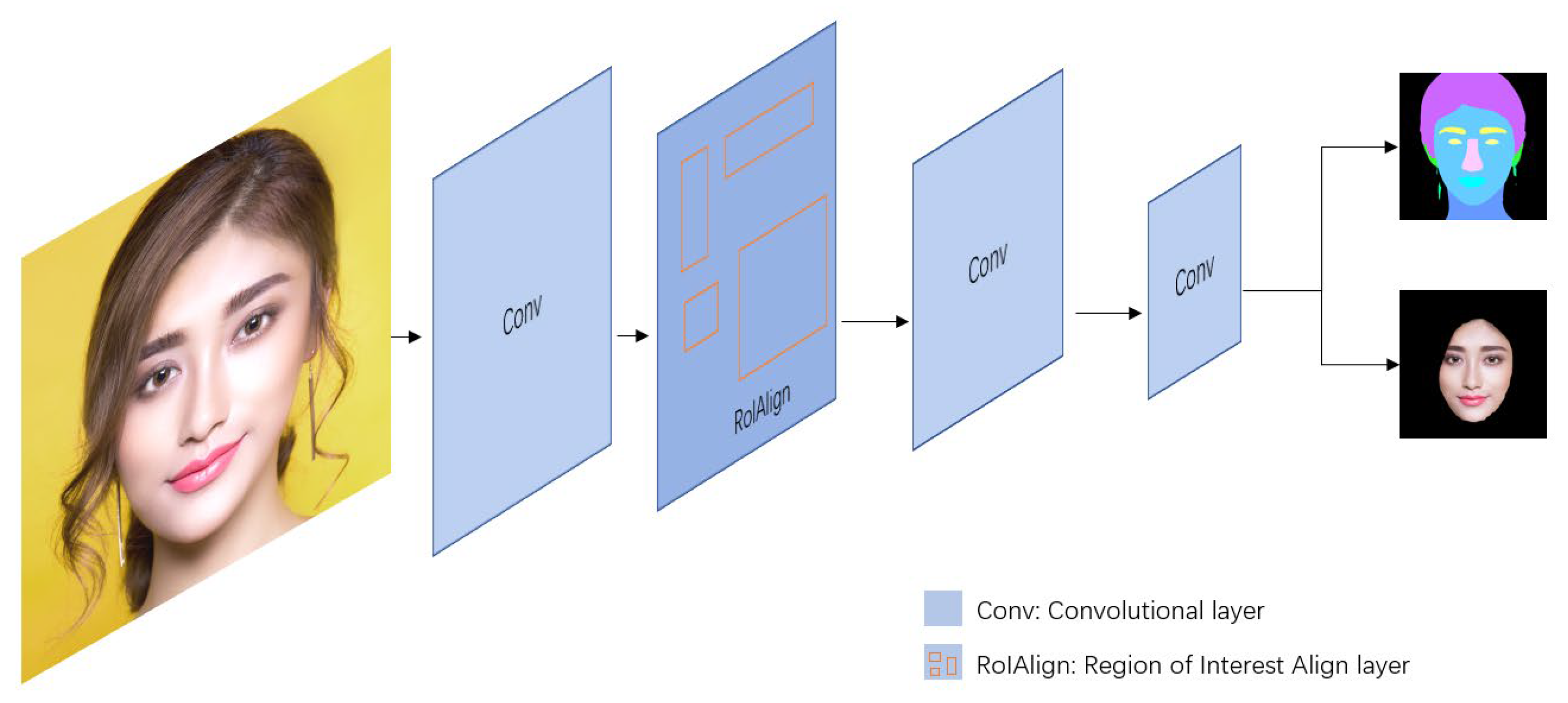
3.1. Face Segmentation (F) Module
3.2. Transformer Generative Hairstyle (TGH) Module
4. Experiments
4.1. Datasets
4.2. Implementation Details
| Algorithm 1 FTGH, using standard GAN losses and R1 gradient penalty to train our networks. The number of steps to apply to the discriminator, k, is a hyperparameter, initialized k = 1. |
| for number of training iterations do for k steps do
|
4.3. Main Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Z.; Ping, L.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Pasupa, K.; Sunhem, W.; Loo, C.K. A hybrid approach to building face shape classifier for hairstyle recommender system. Expert Syst. Appl. 2019, 120, 14–32. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ian, G.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Advances in neural information processing systems. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. Rsgan: Face swapping and editing using face and hair representation in latent spaces. arXiv 2018, arXiv:1804.03447. [Google Scholar]
- Yin, W.; Fu, Y.; Ma, Y.; Jiang, Y.; Xiang, T.; Xue, X. Learning to Generate and Edit Hairstyles. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1627–1635. [Google Scholar]
- Li, Y.; Liu, S.; Yang, J.; Yang, M. Generative Face Completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3911–3919. [Google Scholar]
- Darabi, S.; Shechtman, E.; Barnes, C.; Goldman, D.B.; Sen, P. Image melding: Combining inconsistent images using patch-based synthesis. ACM Trans. Graph. TOG 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Criminisi, A.; Pérez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Processing 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. TOG 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Alexei, A.E. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1486–1494. [Google Scholar]
- Wan, Z.; Zhang, J.; Chen, D.; Liao, J. High-Fidelity Pluralistic Image Completion with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4692–4701. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Alexei, A.E. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.; Kim, S.; Choo, J. Stargan: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Gu, J.; Shen, Y.; Zhou, B. Image Processing Using Multi-Code Gan Prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3012–3021. [Google Scholar]
- Tero, K.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of Stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. Adv. Neural Inf. Processing Syst. 2021, 34, 852–863. [Google Scholar]
- Lin, J.; Li, Y.; Yang, G. FPGAN: Face de-identification method with generative adversarial networks for social robots. Neural Netw. 2021, 133, 132–147. [Google Scholar] [CrossRef] [PubMed]
- Šubrtová, A.; Čech, J.; Franc, V. Hairstyle Transfer between Face Images. In Proceedings of the 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Srinivas, A.; Lin, T.-S.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Wu, S.; Wu, T.; Tan, H.; Guo, G. Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention. arXiv 2021, arXiv:2112.14000. [Google Scholar] [CrossRef]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. Adv. Neural Inf. Processing Syst. 2021, 34, 14745–14758. [Google Scholar]
- Lee, K.; Chang, H.; Jiang, L.; Zhang, H.; Tu, Z.; Liu, C. Vitgan: Training gans with vision transformers. arXiv 2021, arXiv:2107.04589. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Lee, C.-H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards Diverse and Interactive Facial Image Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5549–5558. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. Stgan: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3673–3682. [Google Scholar]
- Schonfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8207–8216. [Google Scholar]
- Wei, Y.; Gan, Z.; Li, W.; Lyu, S.; Chang, M.; Zhang, L.; Gao, J.; Zhang, P. Maggan: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network. In Proceedings of the Asian Conference on Computer Vision, Online, 30 November–4 December 2020. [Google Scholar]
- Saha, R.; Duke, B.; Shkurti, F.; Taylor, G.W.; Aarabi, P. Loho: Latent Optimization of Hairstyles via Orthogonalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1984–1993. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| lg | Generator learning rate |
| ld | Discriminator learning rate |
| sg | Generator training steps |
| sd | Discriminator training steps |
| Method. | FID (↓) |
|---|---|
| STGAN [38] | 47.54 |
| U-NetGAN [39] | 43.99 |
| MagGAN [40] | 41.32 |
| MASKGAN | 37.55 |
| LOHO [41] | 35.50 |
| FTGH (ours) | 21.72 |
| Method | FID (↓) |
|---|---|
| G&D (ResNet) | 29.2 |
| G&D (Transformer) | 44.7 |
| TGH (G: ResNet/D: Transformer) | 21.5 |
| Method | PSNR (dB) (↑) | SSIM (↑) |
|---|---|---|
| STGAN | 17.92 | 0.72 |
| U-NetGAN | 18.55 | 0.75 |
| MagGAN | 20.43 | 0.78 |
| MASKGAN | 20.75 | 0.80 |
| LOHO | 22.28 | 0.83 |
| FTGH (ours) | 30.10 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Man, Q.; Cho, Y.-I.; Jang, S.-G.; Lee, H.-J. Transformer-Based GAN for New Hairstyle Generative Networks. Electronics 2022, 11, 2106. https://doi.org/10.3390/electronics11132106
Man Q, Cho Y-I, Jang S-G, Lee H-J. Transformer-Based GAN for New Hairstyle Generative Networks. Electronics. 2022; 11(13):2106. https://doi.org/10.3390/electronics11132106
Chicago/Turabian StyleMan, Qiaoyue, Young-Im Cho, Seong-Geun Jang, and Hae-Jeung Lee. 2022. "Transformer-Based GAN for New Hairstyle Generative Networks" Electronics 11, no. 13: 2106. https://doi.org/10.3390/electronics11132106
APA StyleMan, Q., Cho, Y. -I., Jang, S. -G., & Lee, H. -J. (2022). Transformer-Based GAN for New Hairstyle Generative Networks. Electronics, 11(13), 2106. https://doi.org/10.3390/electronics11132106