1. Introduction
Robots now have the ability to independently navigate a variety of surroundings thanks to advanced robotics research. Nevertheless, addressing unanticipated situations while performing complex jobs remains challenging for robots. Robots should execute tasks by comprehending working environments beyond metric data and considering protective measures for various scenarios. Using semantic knowledge recently has become a research trend to solve such problems [
1,
2]. In cognitive robotics, the concept of “semantic knowledge” can be represented by general knowledge that people use, such as concepts, attributes, properties, and purposes of environmental elements (e.g., object and place) and their relationships.
We introduce a map for robots to explain semantic knowledge. When building a map for people, we first consider how to represent the environment according to their requirements. For example, if we make a park guide map, the map shows the park’s structure. In this case, we illustrate the location of significant landmarks and paths connecting them on the map. However, maps used by robots are extremely different. We need to consider the understanding ability of the robot that uses the map. If robots have human-level intelligence, it would be enough to give them the maps we use. However, for robots that do not have human-level intelligence, it is essential to make specific maps that can be perceived and utilized. Building maps for robots is handled as a Simultaneously Localization and Mapping (SLAM) problem in robotics. The SLAM problem can be defined as generating an unknown environmental map and simultaneously estimating the robot’s pose on the map.
The early research directions for SLAM were aimed at building a metric map such as a grid, feature, and point cloud map [
3,
4]. A metric map describes the world using low-level metric information within a fixed coordinate system. Therefore, using the metric map, robots can deduce only the metric location and geometrical structure of the environment. Furthermore, to operate the robots, an administrator should convert their instructions into a metric form that robots can perceive. For example, if we want the robots to “move to a second door”, we must give them instructions such as “move to (x,y) coordinate”. Controlling the robots with numerical commands is not a problem when performing simple tasks in uncomplicated environments. However, various limitations exist while performing a high-level task (e.g., fetch a package) in complex environments using only metric instructions and information.
An increasing number of recent studies have shown advancements in the map concept by including semantic knowledge on the map to overcome these limitations [
2,
5,
6]. Many researchers have developed numerous semantic SLAM approaches that build enriched maps, known as semantic maps, by extracting semantic knowledge such as environmental elements’ labels and geometrical relationships that can be obtained from various sensors [
7,
8,
9,
10,
11]. These approaches combine extracted semantic knowledge with the metric maps. On the other hand, in the case of implicit knowledge (e.g., conceptual hierarchy, attributes, and properties) that cannot be extracted directly, researchers have defined and represented the knowledge depending on a specific domain for the robot’s application [
1].
A semantic navigation framework enables robots to perform tasks by utilizing semantic knowledge. The framework’s core is modeling and handling knowledge to complete tasks without problems. Our previous work [
12] proposed a semantic navigation framework composed of the Semantic Modeling Framework (SMF), the Semantic Autonomous Navigation (SAN) module, and the Semantic Information Processing (SIP) module. Each framework module utilizes semantic knowledge by defining the Triplet Ontological Semantic Model (TOSM). We showed the inspection scenario based on semantic knowledge in an indoor single-floor environment.
In this paper, we present a TOSM-based scalable semantic navigation framework for various conditions: robots, environments, and scenarios. We extend the previous framework with the following contributions:
Integrating the framework for robots with different kinematics and various tasks using Web Ontology Language (OWL) and Planning Domain Definition Language (PDDL);
Modeling a TOSM-based semantic knowledge for robots, indoor multi-floor buildings, and outdoor environments;
Generating a semantic map containing asserted and inferred semantic knowledge of environmental elements: objects, places, and robots;
Designing a hierarchical planning scheme that utilizes semantic knowledge in each layer;
For maintenance, updating the semantic map whenever the robot works;
Re-planning to ensure the framework’s reliability when the plan fails.
In the rest of the paper, we introduce and compare the related works in
Section 2.
Section 3 and
Section 4 explain the extended framework’s modules that define and utilize semantic knowledge.
Section 5 describes the experiments that demonstrate the framework. Lastly, we discuss and conclude in
Section 6 and
Section 7.
2. Related Work
Ontology is a method for describing concepts and the relationships between them. Many researchers have adopted ontology-based approaches to design semantic knowledge [
1,
2,
13,
14]. Ontological definitions of semantic knowledge can be specified according to each application domain: office [
15,
16], challenging fields [
17], medical [
18,
19], manufacturing [
20,
21], domestic [
22,
23,
24,
25,
26], and convention center [
12]. We set the detailed comparison criteria as semantic knowledge (ontology, reasoner, query), planner, scalability (environment, robot type, and task), and reliability (re-planning and map maintenance).
Table 1, ordered by year, shows the comparison between semantic navigation frameworks.
In
Table 1, (M) represents that multiple methods are used depending on the case for semantic knowledge and planner; methods not mentioned are expressed with a hyphen (−). (In) and (Out) mean that the framework is applied indoors and outdoors. A black circle (•) and (
√) mean that the framework considers various robot types and tasks and has functions for re-planning and map maintenance. An empty circle (∘) and a hyphen (×) mean that it does not.
While most frameworks do not consider scalability and reliability, our framework, TOSMNav, manages all components of them. We explain some papers and our previous work in detail for further understanding.
Galindo et al. used a semantic map to improve the robot’s task planning efficiency [
15]. The utilized semantic map is defined by integrating hierarchical spatial information and semantic knowledge. The spatial information, called S-Box, contains the state of elements in the environment (e.g., area, object, and robot) and the spatial relationships between them, such as
at and
connected. The domain knowledge for the elements is defined as a terminological component called T-Box. The instances and assertions of the concepts are stored in the assertional component called A-Box. When the robot builds a map, the occupancy map can be classified as
area-4 in the S-Box and linked to
Room, an ontological concept, in the T-Box. The explained semantic map is represented based on the structure of the knowledge representation system called Description Logic (DL) [
29]. They demonstrated the proposed semantic map using MOVE and OBSERVE actions in a home environment.
Lim et al. proposed an Ontology-Based Unified Robot Knowledge (OUR-K) framework [
22], which consists of knowledge description and knowledge association for indoor service robots. The knowledge description module separates the knowledge into the world model (objects, spaces, and contexts) and interaction methods with the world (features and actions). The object knowledge contains three hierarchical levels:
,
, and
.
is the part-object level with functional and perceptual parts.
is the object level for name, and
is the compound level for similar concepts. The space knowledge includes three kinds of maps: metric (
), topological (
), and semantic (
). Context knowledge comprises spatial relationships (e.g., on, in, and left) and temporal concepts (e.g., before, after, and met). For the interaction knowledge, the feature knowledge has the perceptual feature and the concept level; the action knowledge has the primitive behavior, sub-task, and task level. The framework’s semantic knowledge representation is based on the ontological framework of Karlsruhe Ontology (KAON) in [
30]. The knowledge association module defines the relationships between knowledge descriptions using logical inference, Bayesian inference, and heuristics. The proposed framework was verified with a reception service scenario.
In another research work, Tenorth et al. presented the KnowRob-Map system that combines encyclopedic knowledge with instances of an object in the environment [
31]. The object-based map is built using the method in [
32] and processed to semantically represent the knowledge based on the system, called KnowRob [
33]. The KnowRob-Map system integrates both systems to generate knowledge-linked semantic object maps. The maps are constructed using a triple
, consisting of data, ontology, and rules, represented by SWI Prolog [
34]. Kunze et al. applied the system to search for objects in large-scale indoor environments [
35]. They presented the decision-theoretic search algorithm to maximize the probability of finding the object’s location. Other applications using the system are described in detail in the paper [
28].
Deeken et al. introduced the Semantic Environment Mapping (SEMAP) framework [
16,
36]. The framework aims to generate and maintain spatial relationships using Geometrical Information Systems (GIS), specifically PostGIS, and to support query languages for reasoning based on an ontological framework, Apache JENA. The ontological model for the environment representation consists of a core ontology for general knowledge and a domain-specific ontology for various applications. Environmental instances’ geometrical information (e.g., points, lines, and polygons) are stored in the PostGIS database and connected with the SEMAP’s knowledge database using the properties such as
semap:hasDbId. The framework utilizes these links to manage and query the semantic map. They applied the framework to the real robot by implementing an interface to the Robot Operating System (ROS) in the office environment.
We proposed the semantic navigation framework consisting of the SMF, the SIP module, and the SAN module [
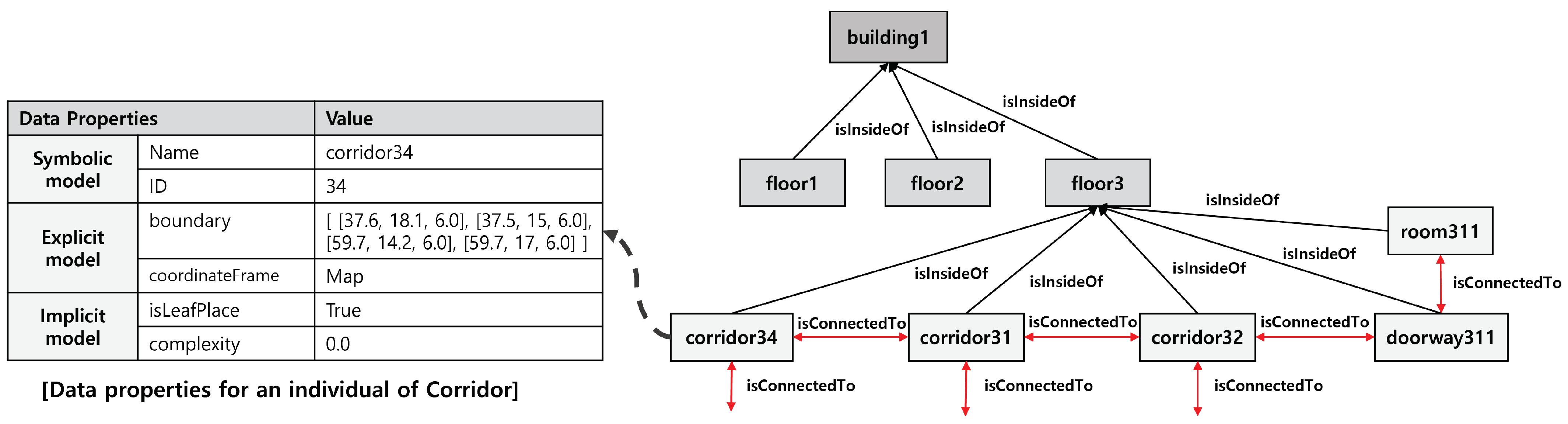
12], based on the TOSM integrating three models: explicit, implicit, and symbolic. The explicit model describes the information obtained from sensors, such as metric state, geometrical characteristics, and image information. The implicit model contains relationships and facts for environmental elements; we classify the environmental elements as
Object,
Place, and
Robot. The environmental elements are symbolized using the symbolic model. The TOSM utilizes OWL terminologies defined in the OWL reference [
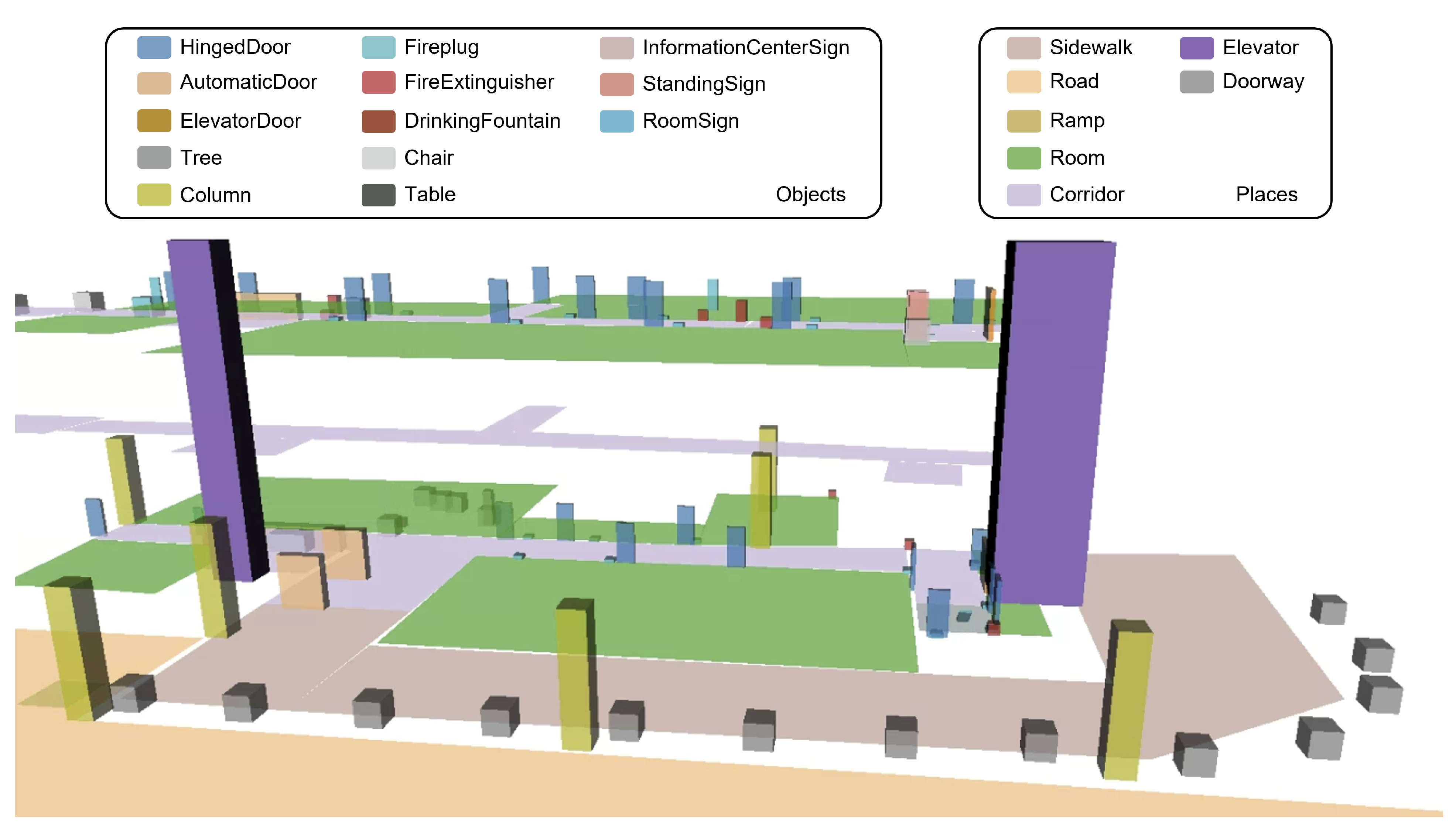
37] to represent the world. The terminologies consist of the class, object property, and data property. The class defines the hierarchy of the environmental elements that provide “is-a” knowledge of elements. The classes’ relationship knowledge and attributes are represented using object and data properties, respectively. We demonstrated the framework using an inspection scenario in an indoor convention center environment.
4. Semantic Navigation
To make a robot complete an assigned task based on semantic knowledge, we presented the Semantic Autonomous Navigation (SAN) module and the Semantic Information Processing (SIP) module in [
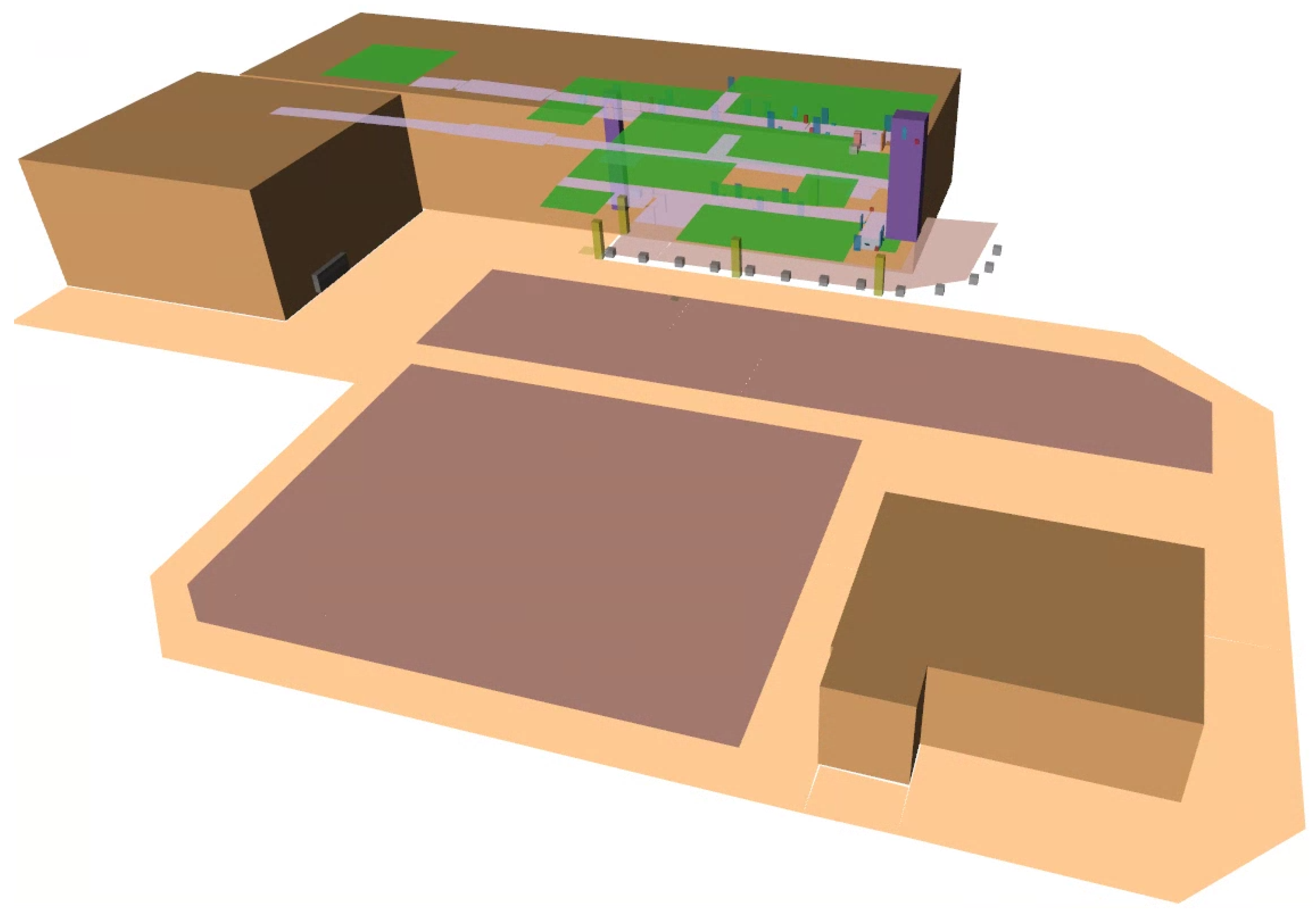
12]. The SAN module adopts the hierarchical planning scheme composed of task, behavior, and action planning. When a robot works, the SIP module semantically recognizes the environment to handle the robot’s behaviors and actions. This work enhances the modules to take miscellaneous robots and tasks in indoor and outdoor fields. The following sections explain how the modules are implemented organically and make the framework sustainable in the selected environment, as shown in
Figure 1.
4.1. Hierarchical Planning
The main components of hierarchical planning are task, behavior, and action planning. The task planner generates a behavior sequence using PDDL, the behavior planner decides an action sequence for each behavior by exploiting the behavior database, and the action planner makes direct robot control signals for each action. For each planner, we offer criteria to distinguish them. First, “task” is a set of goal states that a robot needs to accomplish. The state can be visiting somewhere, delivering coffee, or finding something. Second, “behavior” is a concept of acting to target goals with prior static knowledge. For example, when we go to a convenience store, we plan paths such as “going to an elevator” and “using the elevator”, then “going through some places” to get to the goal. These instances can be behaviors. Lastly, on the other hand, “action” needs to make real-time decisions by considering dynamic situations while executing.
For a clear understanding, we describe the hierarchical planning procedure for different robots using a delivery task example. When a robot receives a task, such as “Deliver a stuff to corridor32”, the task planner makes the goal state “(deliver robot_name stuff_name corridor32)” in the problem file of PDDL by parsing the task. The predicates of goal states are defined in the domain file of PDDL.
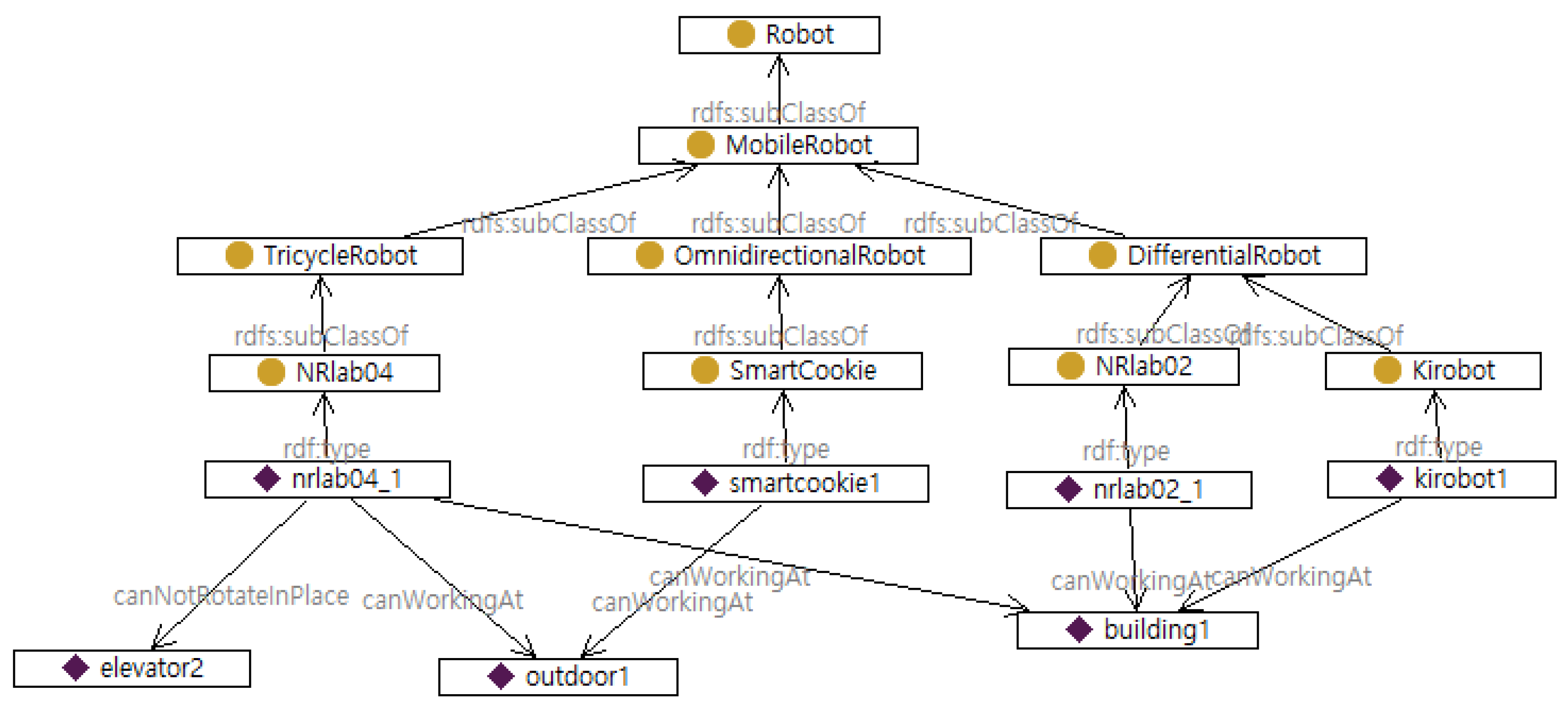
Next, the SAN module queries the robot’s on-demand semantic database to the SMF. Exploiting SPARQL, the SMF queries all semantic knowledge related to the robot to the database using the robot’s name. After acquiring the on-demand database, the task planner can realize the robot’s locations, workable and untraversable leaf places defined as
isLocatedAt,
canWorkingAt, and
canNotGoThrough, respectively. For example, if the task is assigned to nrlab04_1, part of the obtained semantic relationships is as follows: “nrlab04_1
isLocatedAt corridor11”, “nrlab04_1
canWorkingAt sidewalk2”, “nrlab04_1
canWorkingAt corridor39”, and “nrlab04_1
canNotGoThrough doorway115”. These relationships are stored in the problem file as init states, and environmental individuals’ classes are saved in the object field of the domain file. Then, the task planner generates behavior sequences through the Partial Order Planning Forwards (POPF) planner [
41] using the built problem file and pre-defined domain file.
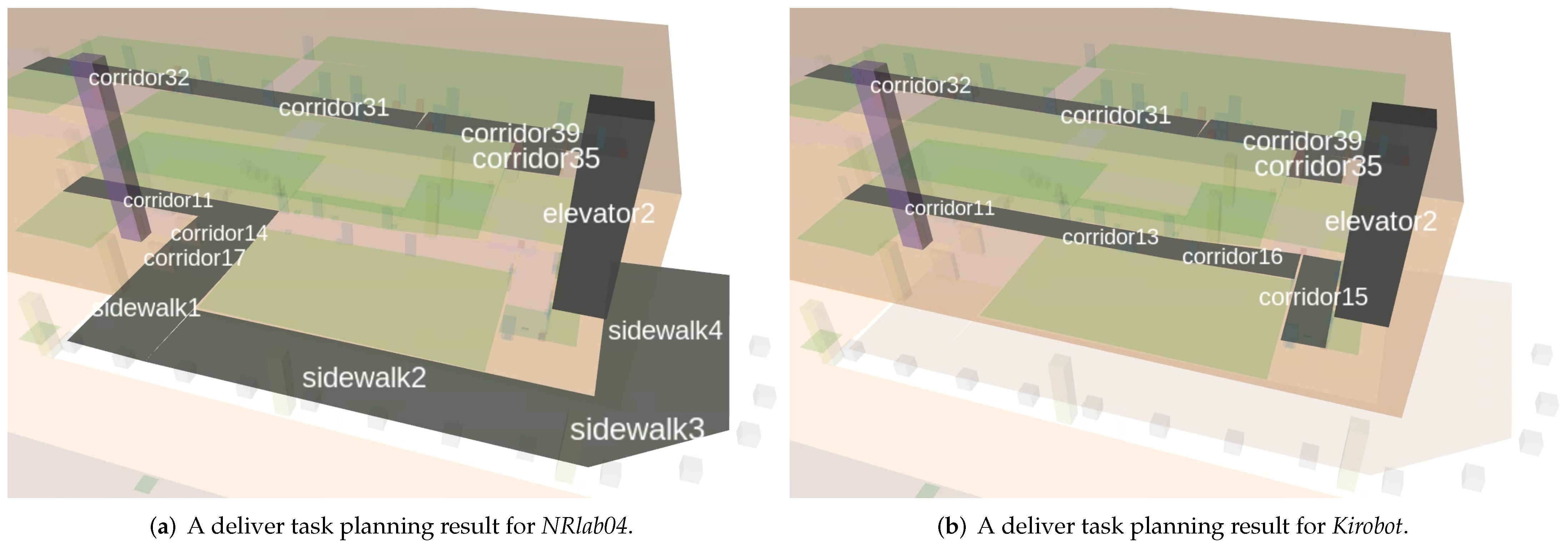
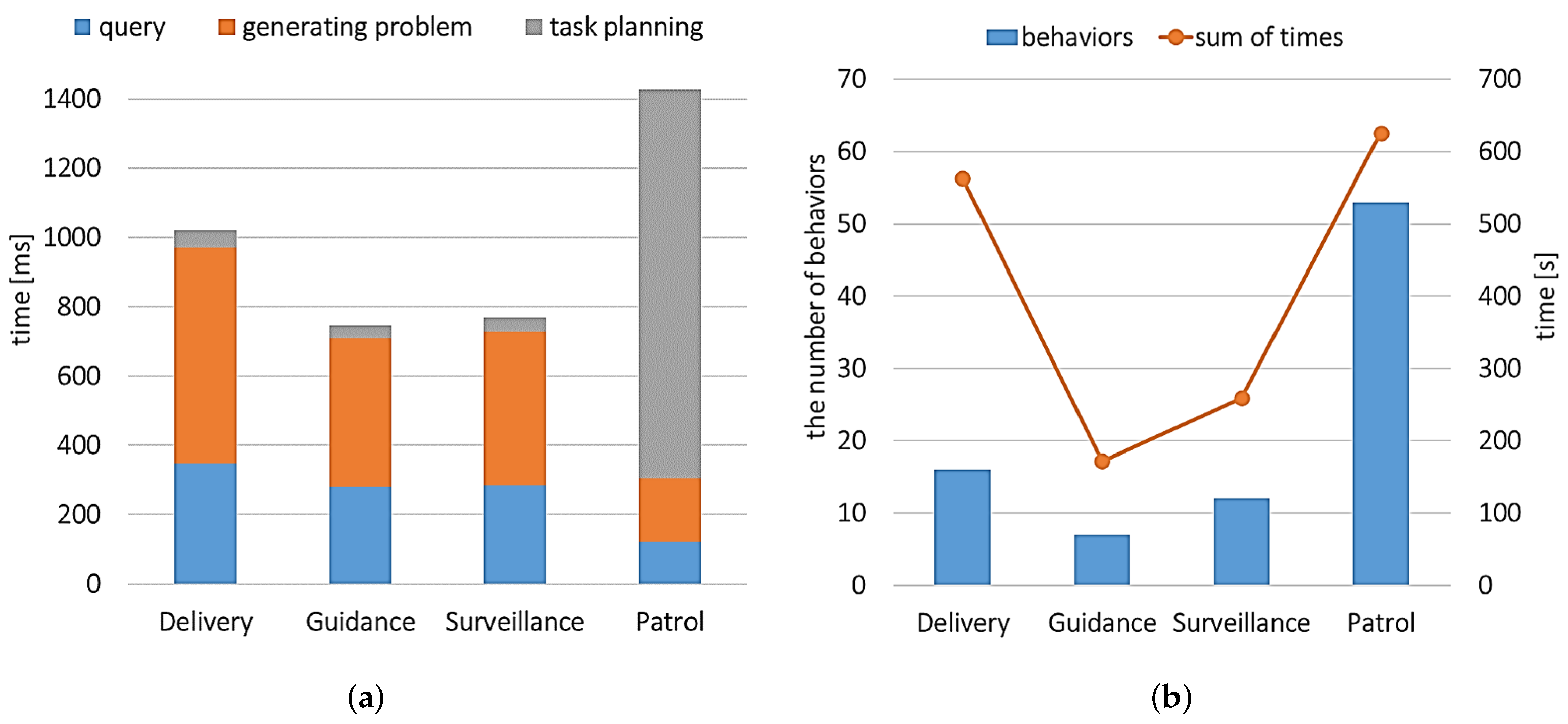
As expected, assigning the same task to different robots causes different results, as illustrated in
Figure 5. Recall the characteristics of two robots:
NRlab04 and
Kirobot. Since
NRlab04 cannot directly go to floor3 indoors, the plan for
NRlab04 guides the robot outdoors via sidewalks, whereas
Kirobot takes the elevator indoors. The task planner’s results for each robot are represented in Listing 1 and Listing 2, respectively. There are two kinds of “goto” behavior in the listings: goto_place and goto_place_through_doorway. goto_place, defined in Listing 3, handles general navigation behaviors between connected leaf places. Otherwise, goto_place_through_doorway specifies behaviors for two connected leaf places with a doorway. The parameter field of goto_place_through_doorway is defined as (?r - robot ?from ?to - leafplace ?dw - doorway) in the PDDL domain file. In line 8 of Listing 1, the robot moves between floors using move_floor_using_elevator behavior with the parameter field (?r - robot ?from ?to - leafplace ?dw_from ?dw_to - doorway ?ev - elevator).
| Listing 1. A behavior sequence for NRlab04 generated by the task planner. |
![Electronics 11 02420 i001]() |
| Listing 2. A behavior sequence for Kirobot generated by the task planner. |
![Electronics 11 02420 i002]() |
| Listing 3. goto_place behavior. |
![Electronics 11 02420 i003]() |
After generating the behavior sequence, each behavior is dispatched to its behavior planner. The behavior planner can determine sophisticated action sequences using semantic knowledge of environmental elements. In the case of goto_place_through_doorway behavior, the planner obtains the individual name of the doorway that connects two leaf places. Then, the planner queries a door that is inside the doorway. If there is no door, the robot goes through via the doorway, but if an automatic door or a hinged door exists, the robot should check the door before passing. Therefore, the planner includes a checking action for this case.
Additionally, due to the robot’s ability, we select a wireless elevator control solution for move_floor_using_elevator behavior. The following sequences can solve the behavior: “Find the elevator”, “Wait until opened”, “Call the elevator”, “Enter the elevator”, “Select the floor”, “Wait until arrived”, and “Leave the elevator”. If the robot has a manipulator that can touch the elevator buttons, the “Call” and “Select” action is converted into “Push the button” actions.
Finally, the action planner directly controls the robot according to the given action sequence from the behavior planner. We separate actions into moving and others. For moving actions, the robot navigates to the goal by changing the navigation parameters considering the type of the goal. For example, the robot can speed up in wide places; otherwise, it can be careful in narrow or complex places such as doorways or crowded hallways. Other actions, such as handling the elevator, depend on domain-specific knowledge.
4.2. Plan Execution
The hierarchical planning scheme follows a top-down approach; conversely, the robot executes the plan bottom-up. After completing the action, the action planner returns the action result to the behavior planner. Likewise, obtaining all results of the action sequence, the behavior planner sends the behavior result to the task planner.
While the robot executes the plans, the SIP module semantically recognizes the working environment as the following sequences.
First, the object detector, explained in
Section 3.2, finds objects and their positions to identify them. Based on the robot’s location (place), represented as
isLocatedAt, the SIP module queries objects using the
isInsideOf relationship with the place name, and then compares the positions to determine the ID of the detected objects. The SIP module updates and adds objects whenever the robot finishes each behavior because, after finishing a behavior, the robot moves to another leaf place. At this time, the matched objects’ position is updated, and others and their relationships are added to the semantic map in the same way as in semantic map generation in
Section 3.2.
Second, the SIP module recognizes the states of objects and places defined in the TOSM. In our environments, the most critical information about objects that the SIP module needs to check is whether the door is open or not. The SIP module uses ultrasonic sensors for the undetectable glass doors (automaticdoor114 and automaticdoor121); for others, such as wood and steel doors, it uses images and point clouds. The sensors to use are determined based on the door’s implicit knowledge (material), queried by the object detector’s identification results. In addition, the SIP module inspects whether the place is blocked; this information is related to the canNotGoThrough property. These results make the action planner decide to go, wait, or fail.
When the action planner returns a fail result with reason, the behavior planner sends the information to the task planner. Then, after updating the on-demand database, the task planner re-plans to find other behavior sequences. We explain the re-planning scenario in detail in
Section 5.
6. Discussion
The development of semantic navigation frameworks for robots has been advanced in recent years. The semantic knowledge enables robots to become intelligent, to realize the world and act in a human way. However, their abilities can be further improved in various applications. Therefore, we suggest several future research directions with associated open issues.
Executing complicated tasks. Nowadays, robots are applied for many tasks, such as surveillance, guidance, delivery, and disinfection. However, these tasks consist of behaviors that can be implemented without complex behavior knowledge. The final goal of using semantic knowledge is beyond completing simple repetitive works. For complicated tasks, knowledge of each task should be defined and utilized. Beetz et al. presented the KNOWROB 2.0 framework [
24] for complex manipulation tasks (e.g., making pizza and setting tables). To increase the capabilities of robots’ manipulation skills, they defined the task knowledge about them. Consequently, designing more sophisticated task models will enable the robots to execute various tasks, such as doing the laundry.
Improving recognition skills. State-of-the-art methods to recognize environments have achieved remarkable performance in many domains. However, the current recognition methods using only sensory inputs are insufficient for complex decisions in numerous situations. For example, when a robot is guarding a particular area, there are countermeasures for each case, such as specific domain knowledge. Therefore, we believe that improving recognition skills based on semantic knowledge in various situations is needed for reasonable determinations.
Standardization of semantic knowledge. There are several semantic knowledge representation approaches in [
1]. Each approach defines semantic knowledge for its specific domain. However, to share and accumulate semantic knowledge, semantic knowledge representations should be standardized. Schlenoff et al. discussed the IEEE-RAS working group, entitled Ontologies for Robotics and Automation (ORA WG), that developed a standard ontology for knowledge representation [
44]. They have tried to unify the format of entire knowledge representation terminologies. Their works proposed a Core Ontology for Robotics and Automation (CORA), described in [
45,
46,
47,
48]. Furthermore, the RoboEarth project [
49] was aimed at presenting a system for sharing knowledge between robots. The project was the first implementation of a World Wide Web for robots. They demonstrated that sharing knowledge between robots can accelerate the speed of learning. Further research on the standardization of semantic knowledge will offer a basis for robot knowledge.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}