
A Novel Target Tracking Scheme Based on Attention Mechanism in Complex Scenes

Abstract
:1. Introduction
- Based on an in-depth analysis of Siamese trackers, we propose a novel Siamese network tracking framework which introduces an attention mechanism to improve the expressive power of the neural network. The attention weights are integrated within the Siamese network without additional modules, maintaining its end-to-end property.
- We design an improved attention module which skillfully integrates a spatial attention mechanism and channel attention mechanism to systematically learn features at different levels. Recalibration of the attention maps ensures that the network attends to discriminative and robust features.
- After carrying out extensive experiments on challenging large benchmark datasets, we analyze performance under different visual attributes, then compare our proposed tracker with other state-of-the-art and real-time depth trackers. Simulation results and real data validation confirm that the proposed algorithm is efficient and performs well in cluttered environments.
2. Related Work
2.1. Deep Feature-Based Trackers
2.2. Siamese Tracking
2.3. Attention Mechanism
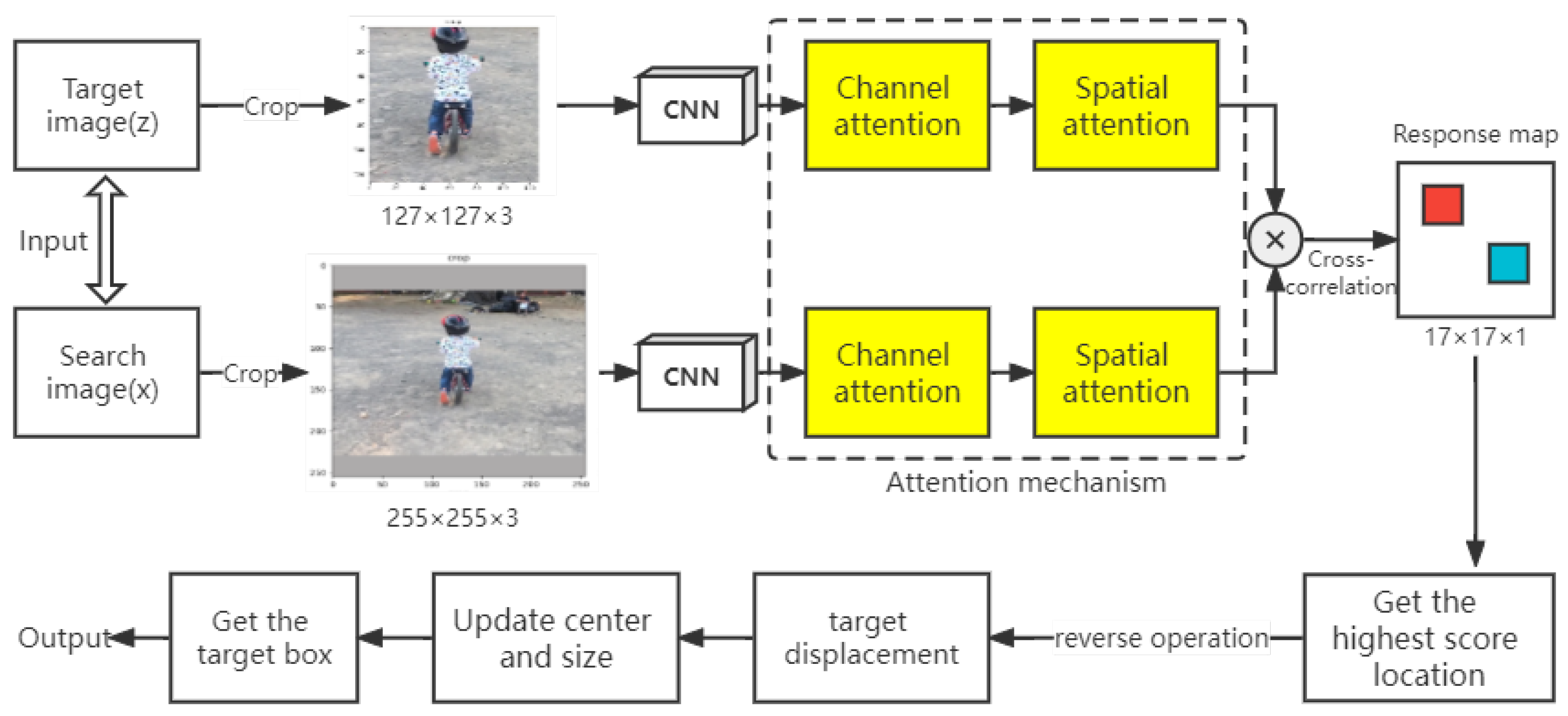
3. The Proposed Algorithm
3.1. Network Architecture
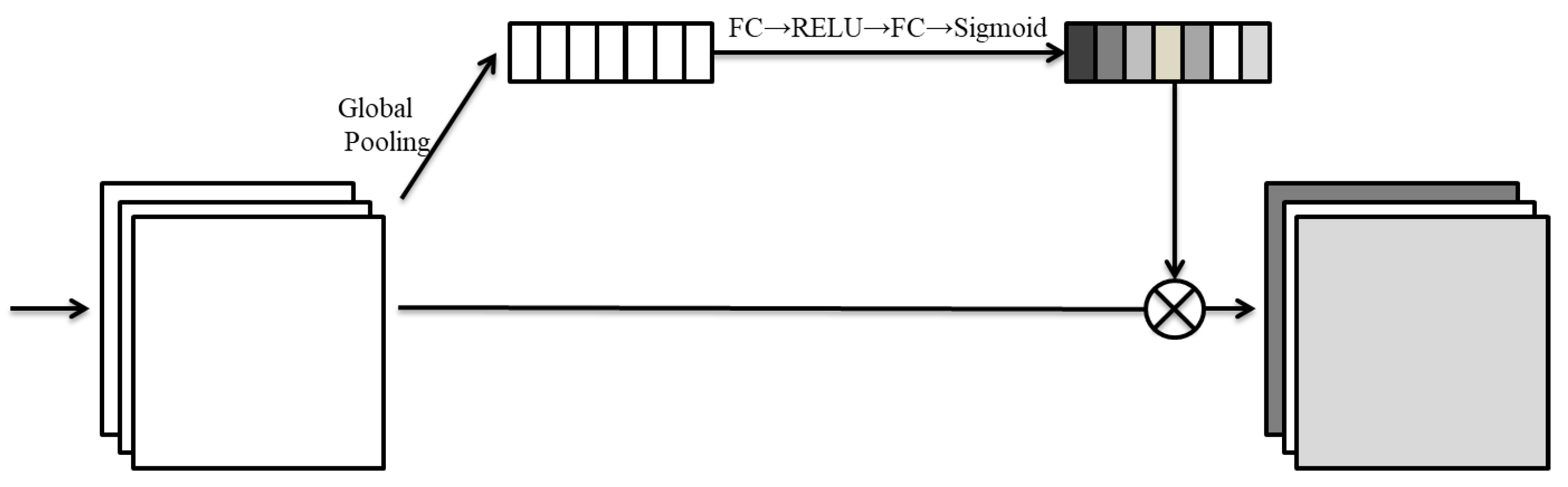
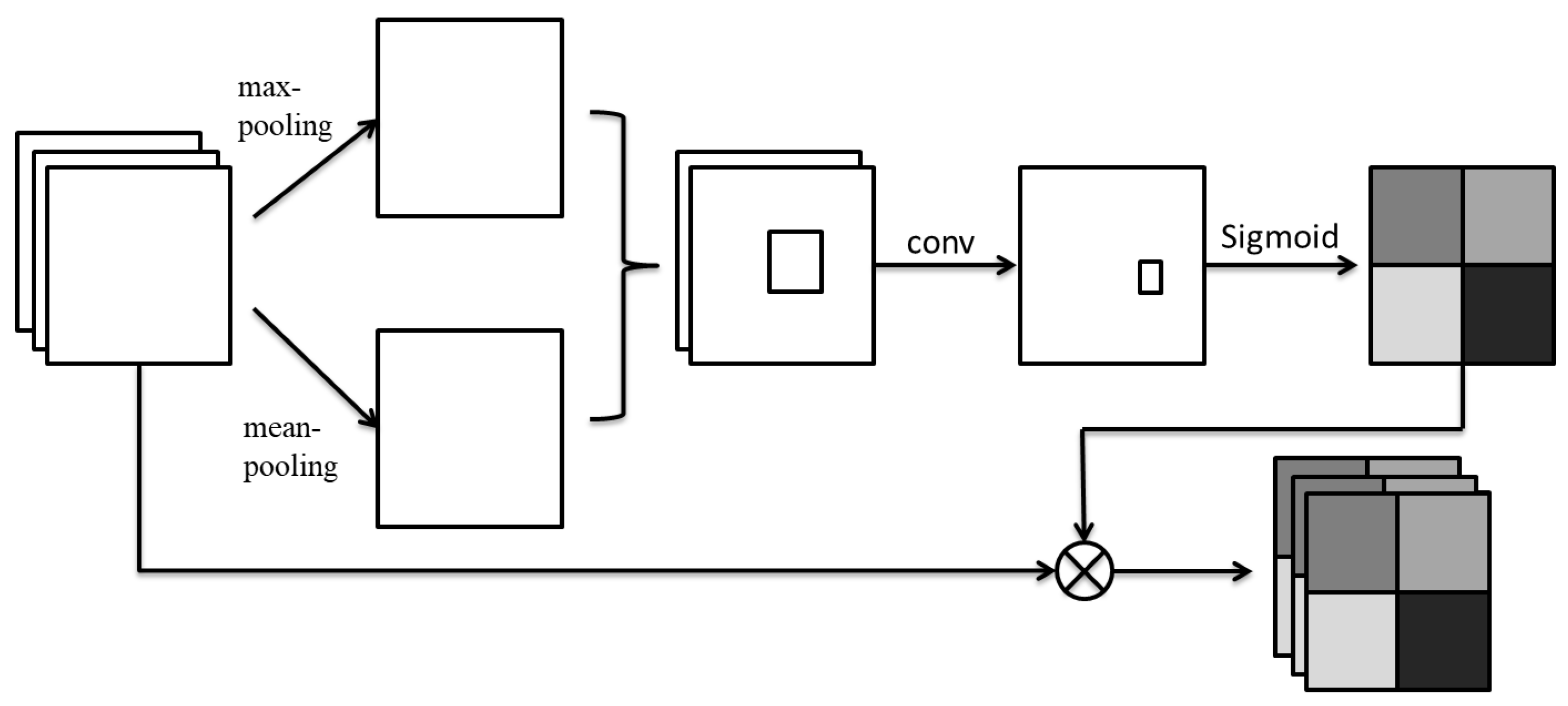
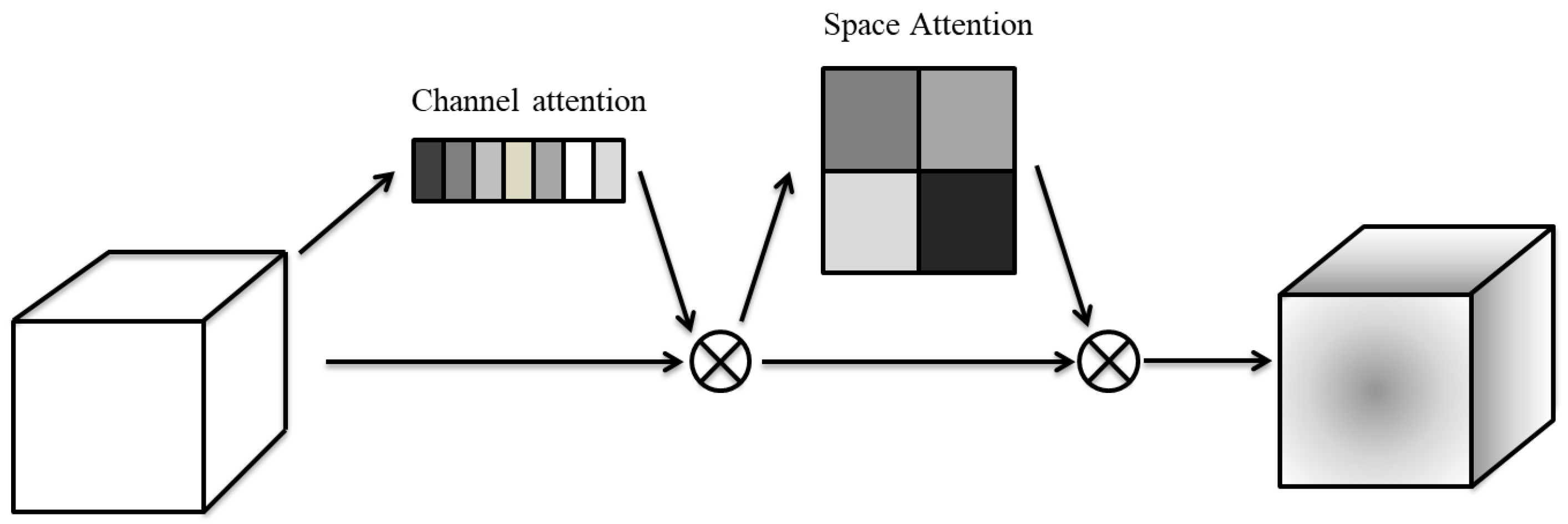
3.2. Stacked Channel–Spatial Attention
3.2.1. Channel Attention
3.2.2. Spatial Attention
3.2.3. Convolutional Block Attention Module
3.3. Implementation Details
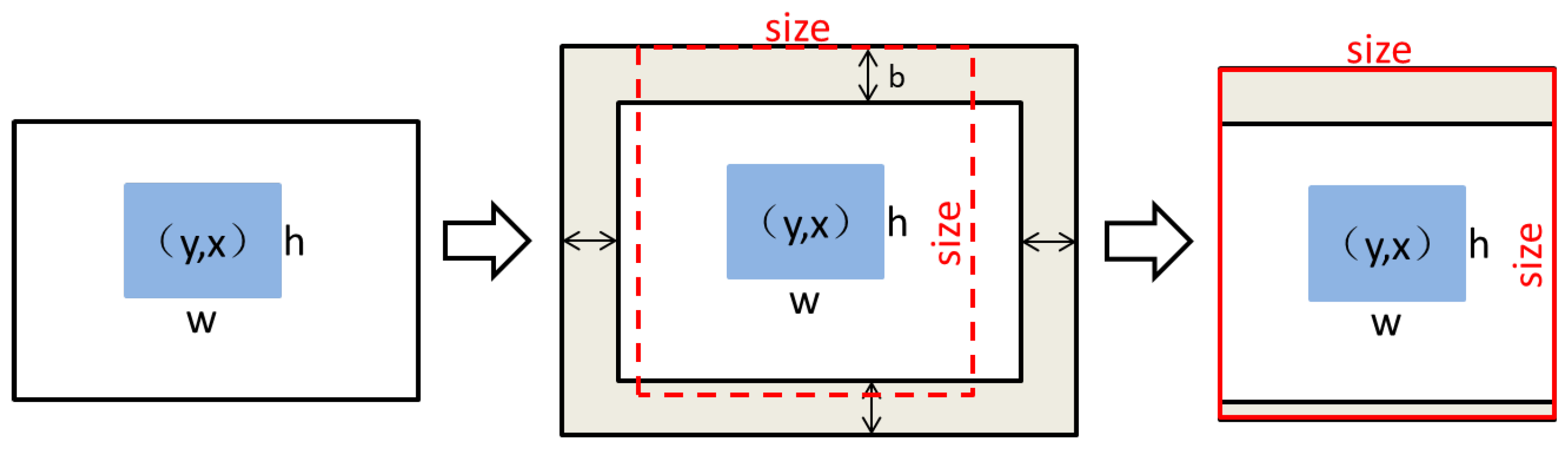
3.3.1. Image Cropping
3.3.2. Feature Extraction
3.3.3. Network Training
3.3.4. Testing
4. Experimental Results
4.1. Implementation Details
4.1.1. Experimental Environment
4.1.2. Evaluation Dataset and Criteria
4.2. Experimental Results and Analysis under Different Visual Conditions
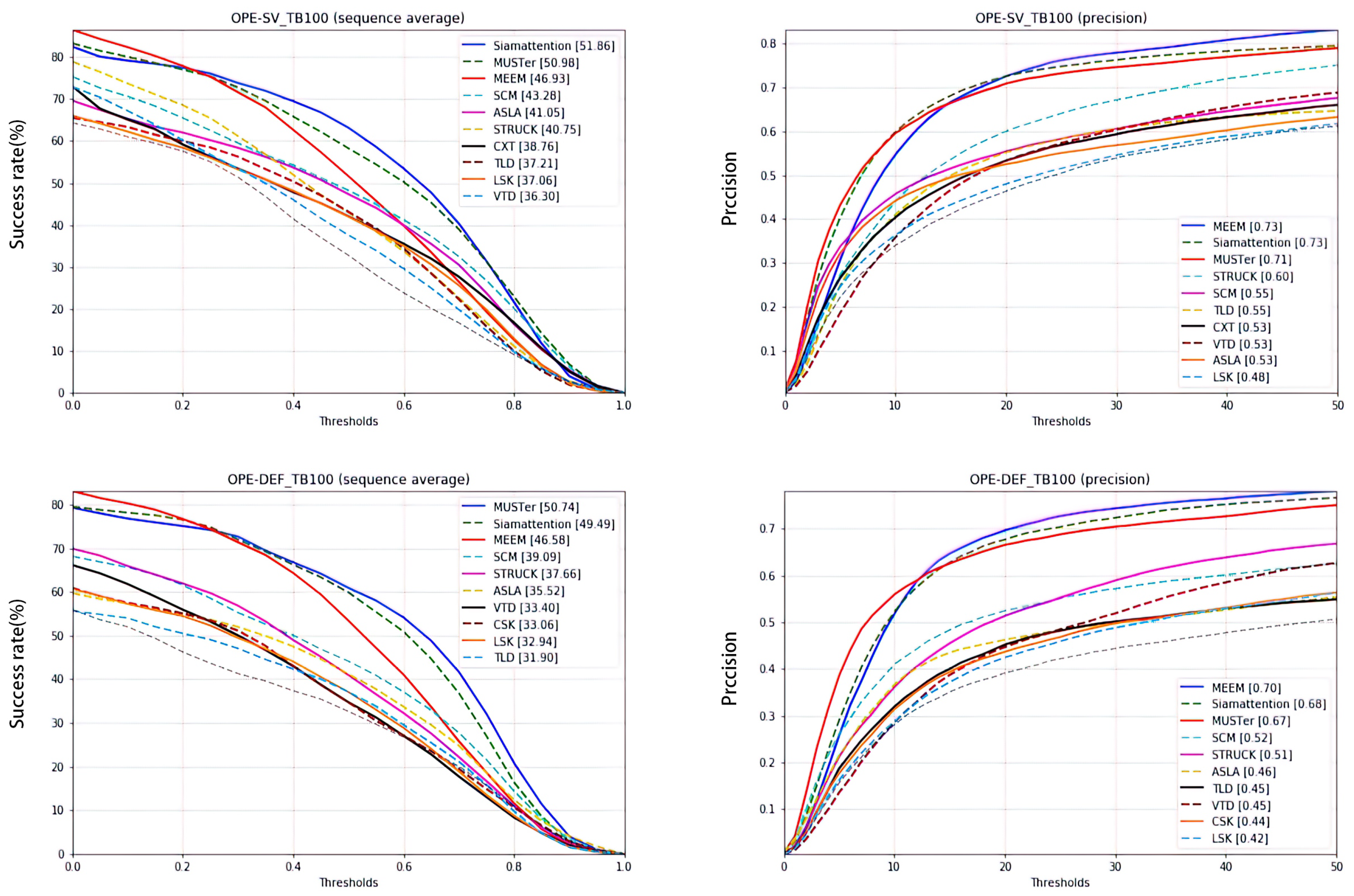
4.2.1. Target Change
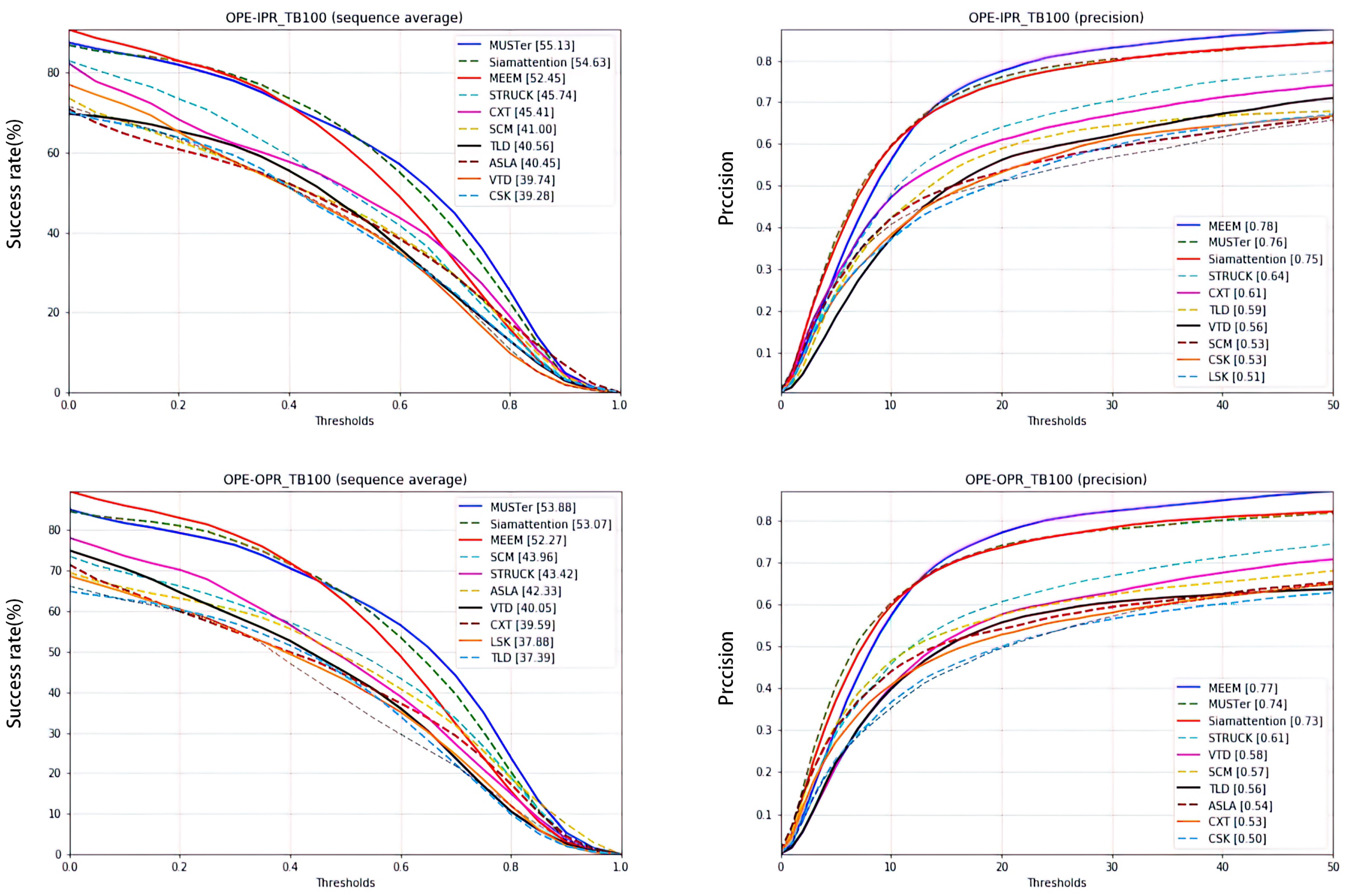
4.2.2. Incomplete Target
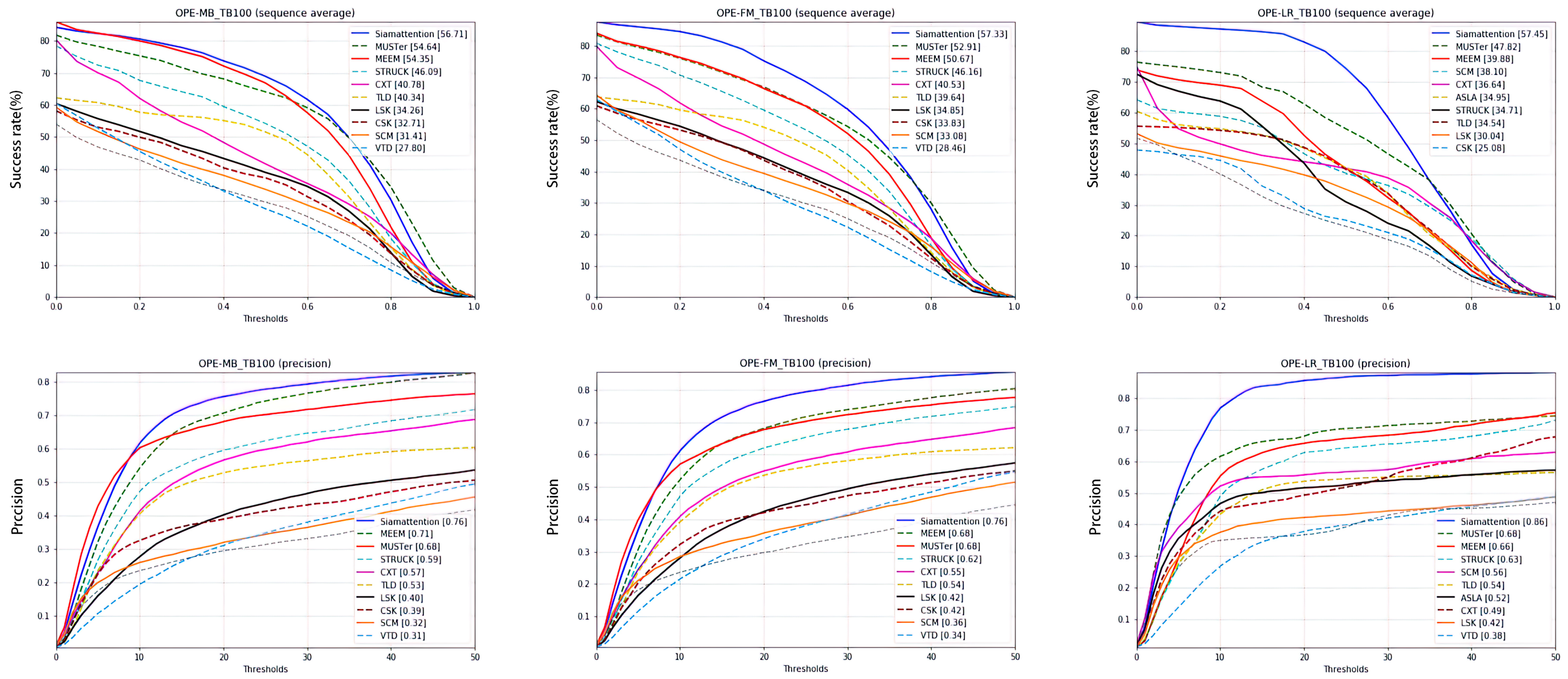
4.2.3. Fuzzy Objective
4.2.4. Target Environment
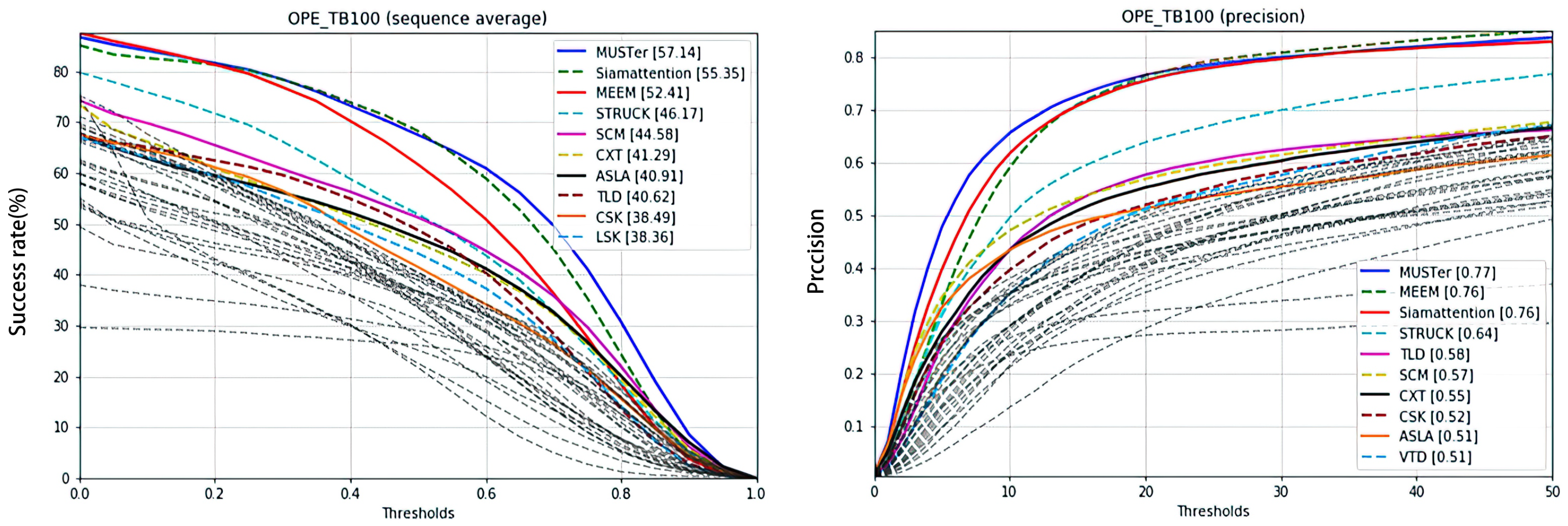
4.3. Overall Effect Evaluation of Tracker
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balta, D.; Kuo, H.; Wang, J.; Porco, I.G.; Schladen, M.; Cereatti, A.; Lum, P.S.; Della Croce, U. Infant upper body 3D kinematics estimated using a commercial RGB-D sensor and a deep neural network tracking processing tool. In Proceedings of the 2022 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Messina, Italy, 22–24 June 2022; pp. 1–6. [Google Scholar]
- Zhang, K.; Wang, W.; Wang, J. Robust Correlation Tracking in Unmanned Aerial Vehicle Videos via Deep Target-specific Rectification Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510605. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Heidari, A.; Navimipour, N.J.; Unal, M. Applications of ML/DL in the management of smart cities and societies based on new trends in information technologies: A systematic literature review. Sustain. Cities Soc. 2022, 85, 104089. [Google Scholar] [CrossRef]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Wu, L.; Zhao, C.; Ding, Z.; Zhang, X.; Wang, Y.; Li, Y. A Multi-Target Tracking and Positioning Technology for UAV Based on Siamrpn Algorithm. In Proceedings of the 2022 Prognostics and Health Management Conference (PHM-2022 London), London, UK, 27–29 May 2022; pp. 456–461. [Google Scholar]
- Wang, H.; Zhang, S.; Zhao, S.; Wang, Q.; Li, D.; Zhao, R. Real-time detection and tracking of fish abnormal behavior based on improved YOLOV5 and SiamRPN++. Comput. Electron. Agric. 2022, 192, 106512. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Wang, Q.; Teng, Z.; Xing, J.; Gao, J.; Hu, W.; Maybank, S. Learning attentions: Residual attentional siamese network for high performance online visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4854–4863. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Cao, Y.; Ji, H.; Zhang, W.; Shirani, S. Feature Aggregation Networks Based on Dual Attention Capsules for Visual Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 674–689. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Yang, T.; Chan, A.B. Visual tracking via dynamic memory networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 360–374. [Google Scholar] [CrossRef] [PubMed]
- Fralick, M.; Campbell, K.R. The basics of machine learning. NEJM Evid. 2022, 1. [Google Scholar] [CrossRef]
- Liu, M.; Liu, Z.; Lu, W.; Chen, Y.; Gao, X.; Zhao, N. Distributed few-shot learning for intelligent recognition of communication jamming. IEEE J. Sel. Top. Signal Process. 2021, 16, 395–405. [Google Scholar] [CrossRef]
- Liu, M.; Wang, J.; Zhao, N.; Chen, Y.; Song, H.; Yu, F.R. Radio frequency fingerprint collaborative intelligent identification using incremental learning. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3222–3233. [Google Scholar] [CrossRef]
- Pan, C.; Huang, J.; Hao, J.; Gong, J. Towards zero-shot learning generalization via a cosine distance loss. Neurocomputing 2020, 381, 167–176. [Google Scholar] [CrossRef]
- Wei, Z.; Yang, X. Object tracking algorithm based on fusion of SiamFC and Feature Pyramid Network. In Proceedings of the 2021 International Conference on Internet, Education and Information Technology (IEIT), Suzhou, China, 16–18 April 2021; pp. 244–248. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. arXiv 2022, arXiv:2202.09741. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Cho, K.; Bengio, Y. End-to-end continuous speech recognition using attention-based recurrent NN: First results. arXiv 2014, arXiv:1412.1602. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J.S. Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 16–20. [Google Scholar]
- Yuan, Z.W.; Zhang, J. Feature extraction and image retrieval based on AlexNet. In Proceedings of the Eighth International Conference on Digital Image Processing (ICDIP 2016), Chengu, China, 20–22 May 2016; Volume 10033, p. 100330E. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Ketkar, N. Stochastic gradient descent. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 113–132. [Google Scholar]
- Ruby, U.; Yendapalli, V. Binary cross entropy with deep learning technique for image classification. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5393–5397. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Advantages | Disadvantages |
|---|---|---|
| Generative Adversarial Network [18] | Generating random occlusions alleviates the problem of imbalanced training samples | Struggles to converge during training |
| Recurrent Neural Network [19] | Makes full use of the temporal information between networks to improve the target discrimination ability | The network parameters are large, and the overall performance is poor |
| Siamese Network | Weights are shared, network complexity is low, and it achieves a good balance of accuracy and speed | The robustness is relatively poor in complex environments |
| The Algorithm Name | Advantages | Disadvantages |
|---|---|---|
| SiamFC | The tracking process is transformed into a similarity learning problem, which ensures the translation invariance of the network and balances the running speed and accuracy | The effect of target tracking in complex environments is poor |
| SiamRPN | The RPN network is introduced to predict the scale of the target, and the discrimination of the target is enhanced | Due to the anchor frame mechanism of RPN, there are errors in target position prediction and scale estimation |
| SiamRPN++ | The accuracy is further improved by a multi-layer aggregation network | The improvement in accuracy is limited, and the real-time performance is reduced due to the multi-layer network |
| SiamDW | An internal Clipping Residual (CIR) unit is used to eliminate the impact of padding and enhance the positioning accuracy. | The outermost feature of the feature map boundary of each frame needs to be cropped, which increases the time complexity and reduces the real-time tracking performance |
| Layer | Filter Size | Total Number of Channels | Stride | Target Image | Search Image | Channel |
|---|---|---|---|---|---|---|
| Input | ||||||
| Conv1 | 2 | |||||
| Pool1 | 2 | |||||
| Conv2 | 1 | |||||
| Pool2 | 2 | |||||
| Conv3 | 1 | |||||
| Conv4 | 1 | |||||
| Conv5 | 1 |
| Attributes | Success Rate (%) | Lower Than the First (%) | Higher Than the Next (%) | Ranking |
|---|---|---|---|---|
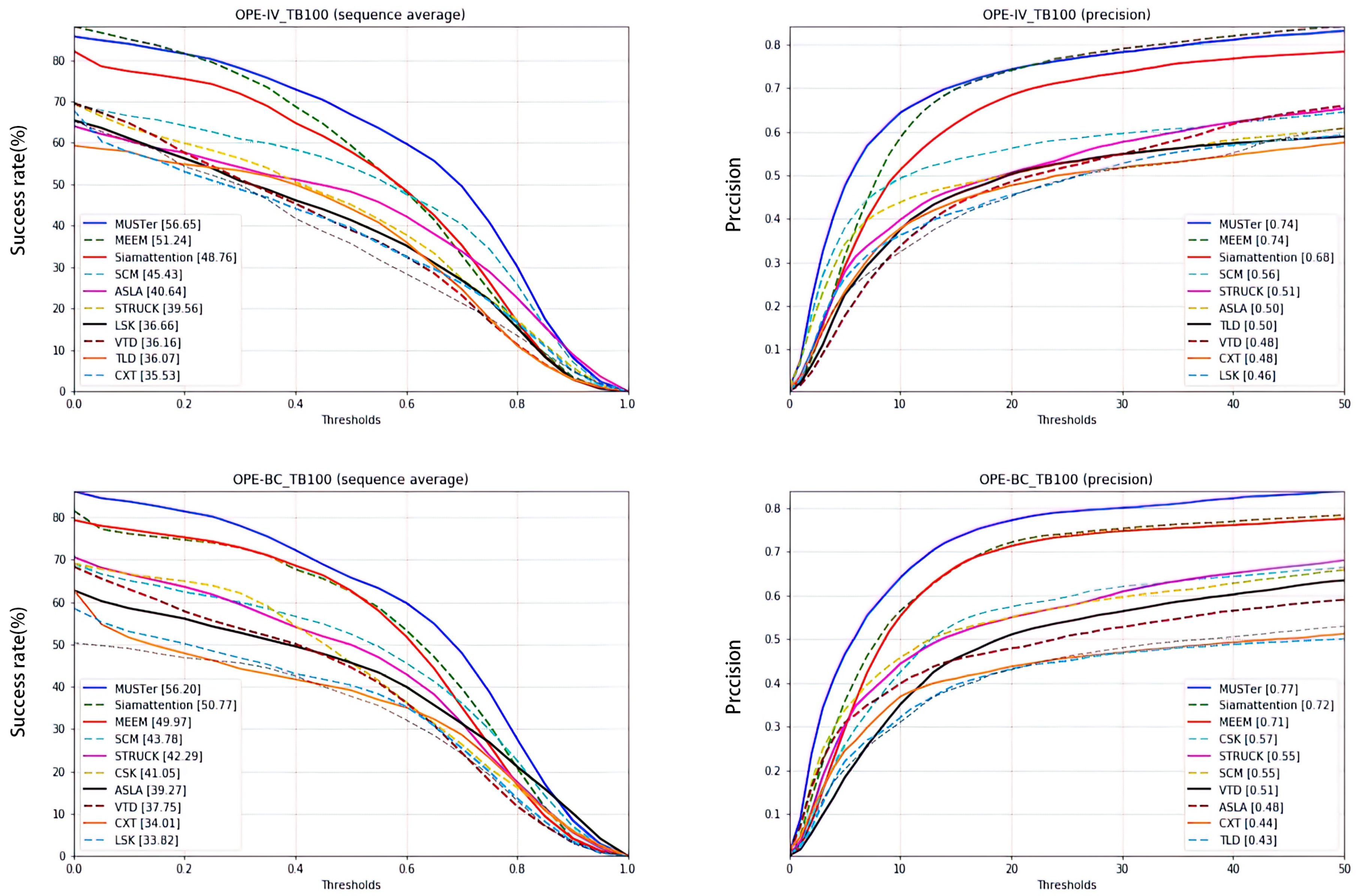
| BC | 50.77 | 5.43 | 0.8 | 2 |
| DEF | 49.49 | 1.25 | 2.91 | 2 |
| FM | 57.73 | 0 | 4.43 | 1 |
| IPR | 54.63 | 0.5 | 2.18 | 2 |
| IV | 48.76 | 7.89 | 3.33 | 3 |
| LR | 57.45 | 0 | 9.63 | 1 |
| MB | 56.71 | 0 | 2.07 | 1 |
| OCC | 49.78 | 4.55 | 0.34 | 2 |
| OPR | 53.07 | 0.81 | 0.8 | 2 |
| OV | 45.98 | 2.33 | 7.56 | 3 |
| SV | 51.86 | 0 | 0.88 | 1 |
| Attributes | Precision (%) | Lower Than the First (%) | Higher Than the Next (%) | Ranking |
|---|---|---|---|---|
| BC | 72 | 5 | 1 | 2 |
| DEF | 68 | 2 | 1 | 2 |
| FM | 76 | 0 | 8 | 1 |
| IPR | 75 | 3 | 11 | 3 |
| IV | 68 | 6 | 12 | 3 |
| LR | 86 | 0 | 18 | 1 |
| MB | 76 | 0 | 5 | 1 |
| OCC | 68 | 4 | 14 | 3 |
| OPR | 73 | 4 | 12 | 3 |
| OV | 63 | 1 | 4 | 2 |
| SV | 73 | 0 | 2 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yang, Z.; Yang, W.; Yang, J. A Novel Target Tracking Scheme Based on Attention Mechanism in Complex Scenes. Electronics 2022, 11, 3125. https://doi.org/10.3390/electronics11193125
Wang Y, Yang Z, Yang W, Yang J. A Novel Target Tracking Scheme Based on Attention Mechanism in Complex Scenes. Electronics. 2022; 11(19):3125. https://doi.org/10.3390/electronics11193125
Chicago/Turabian StyleWang, Yu, Zhutian Yang, Wei Yang, and Jiamin Yang. 2022. "A Novel Target Tracking Scheme Based on Attention Mechanism in Complex Scenes" Electronics 11, no. 19: 3125. https://doi.org/10.3390/electronics11193125
APA StyleWang, Y., Yang, Z., Yang, W., & Yang, J. (2022). A Novel Target Tracking Scheme Based on Attention Mechanism in Complex Scenes. Electronics, 11(19), 3125. https://doi.org/10.3390/electronics11193125