
A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- A.
- CONTRIBUTIONS
- We proposed the Multi-Attention EfficientNetB3 and EfficientNetV2S models to distinguish the ALL (unhealthy cells) and hem (healthy cells) in this article;
- We simply modified the last block of both models and added the Multi-Attention Layers in both models. After including this Multi-Attention mechanism not only reduces the model’s complexities but also generalizes its network quite well;
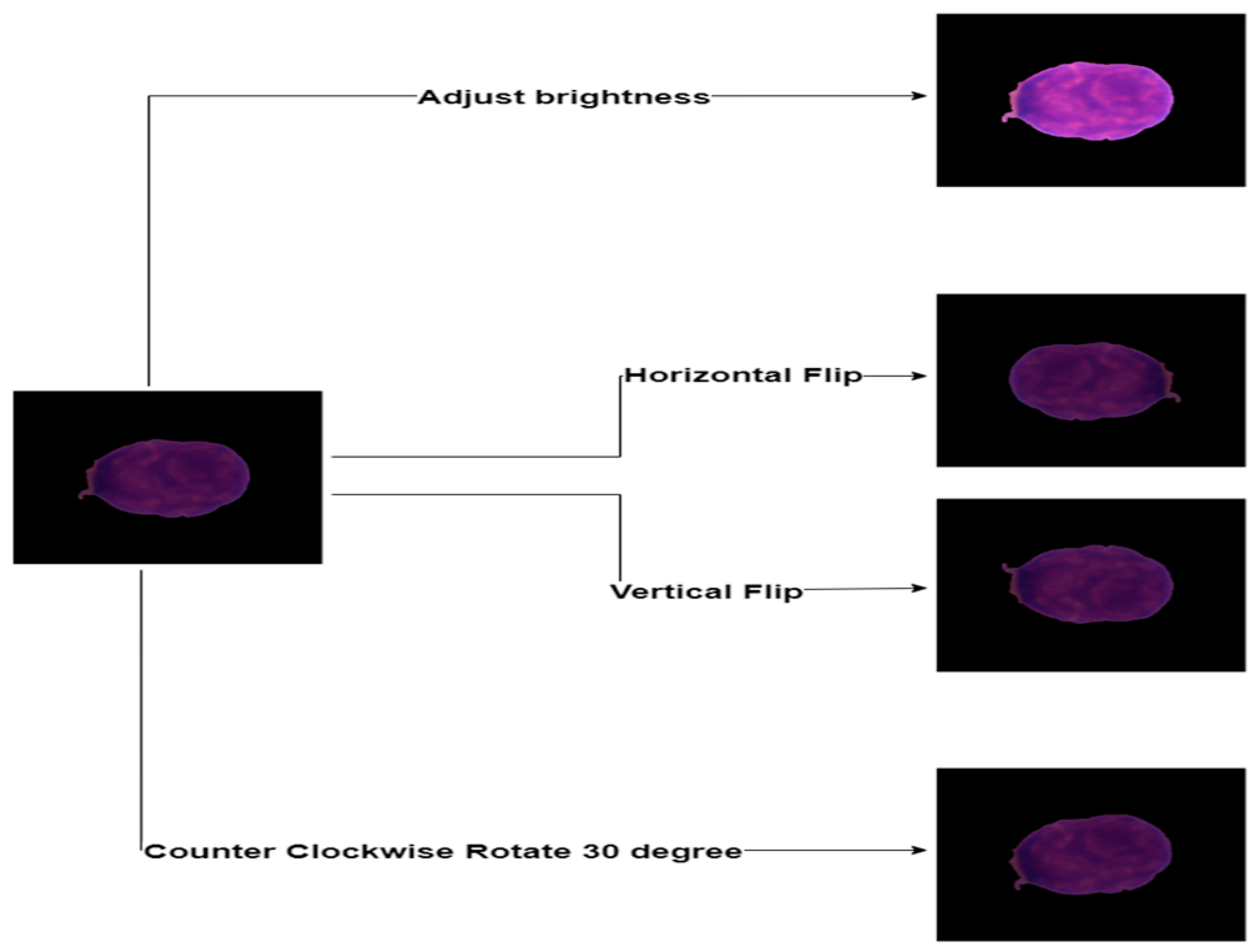
- We added a crop function to reduce the unwanted part of the image;
- To address the issue of unbalanced data, we also applied the augmentation technique to expand the dataset;
- Our Multi-Attention EfficientNetV2S and EfficientNetB3 models achieved the 99.73% and 99.25% accuracy, respectively, on the test dataset for ALL and hem cells;
- We also compared our model to other CNN models that were previously used for the detection of normal cells and cancerous cells from blood smear images but our Multi-Attention EfficientNetV2S and EfficientNetB3 models provided a higher classification accuracy.
- B.
- ORGANIZATION
2. Related Work
3. Methods and Materials
- A.
- DATASET PREPROCESSING AND AUGMENTATION
- B.
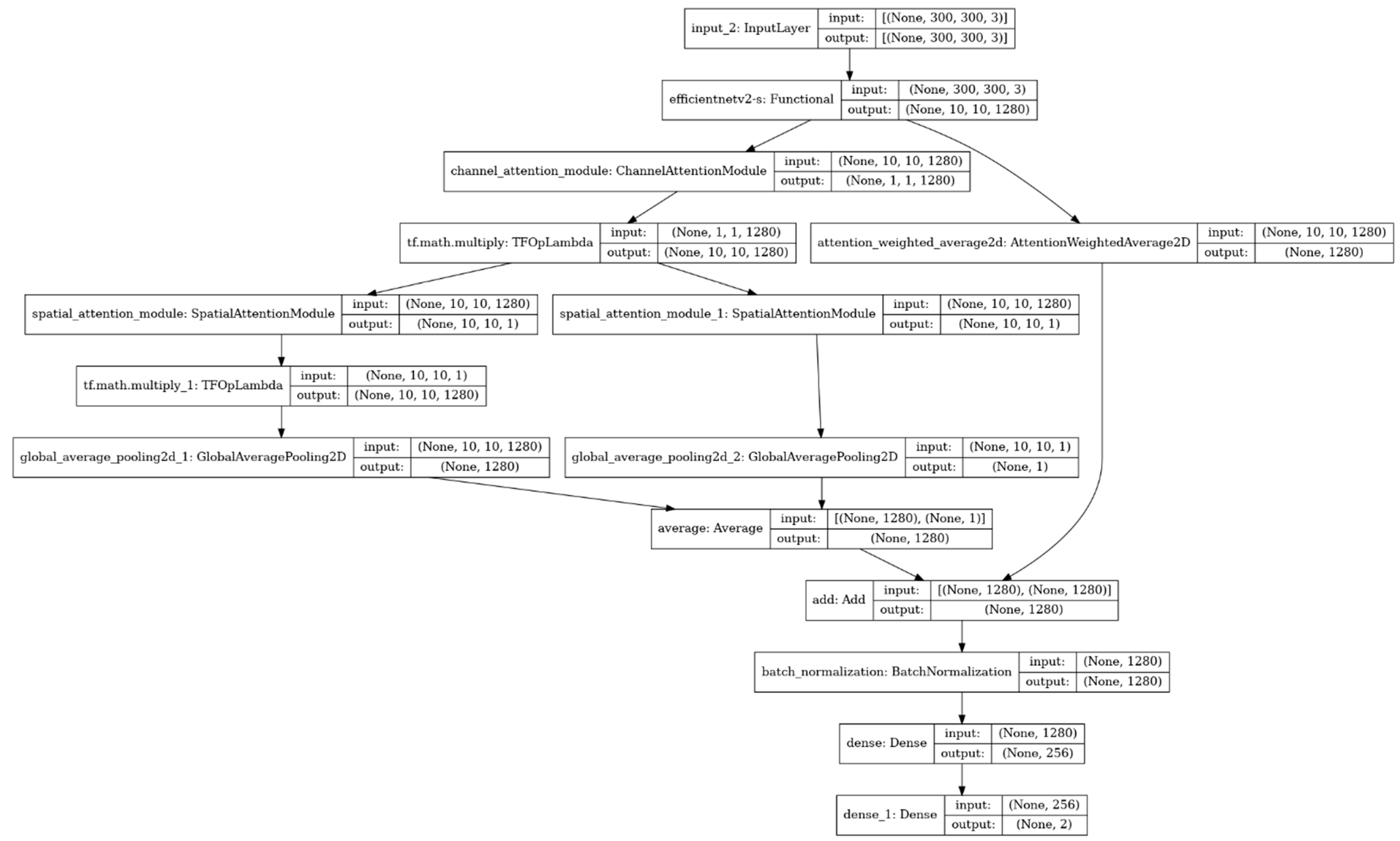
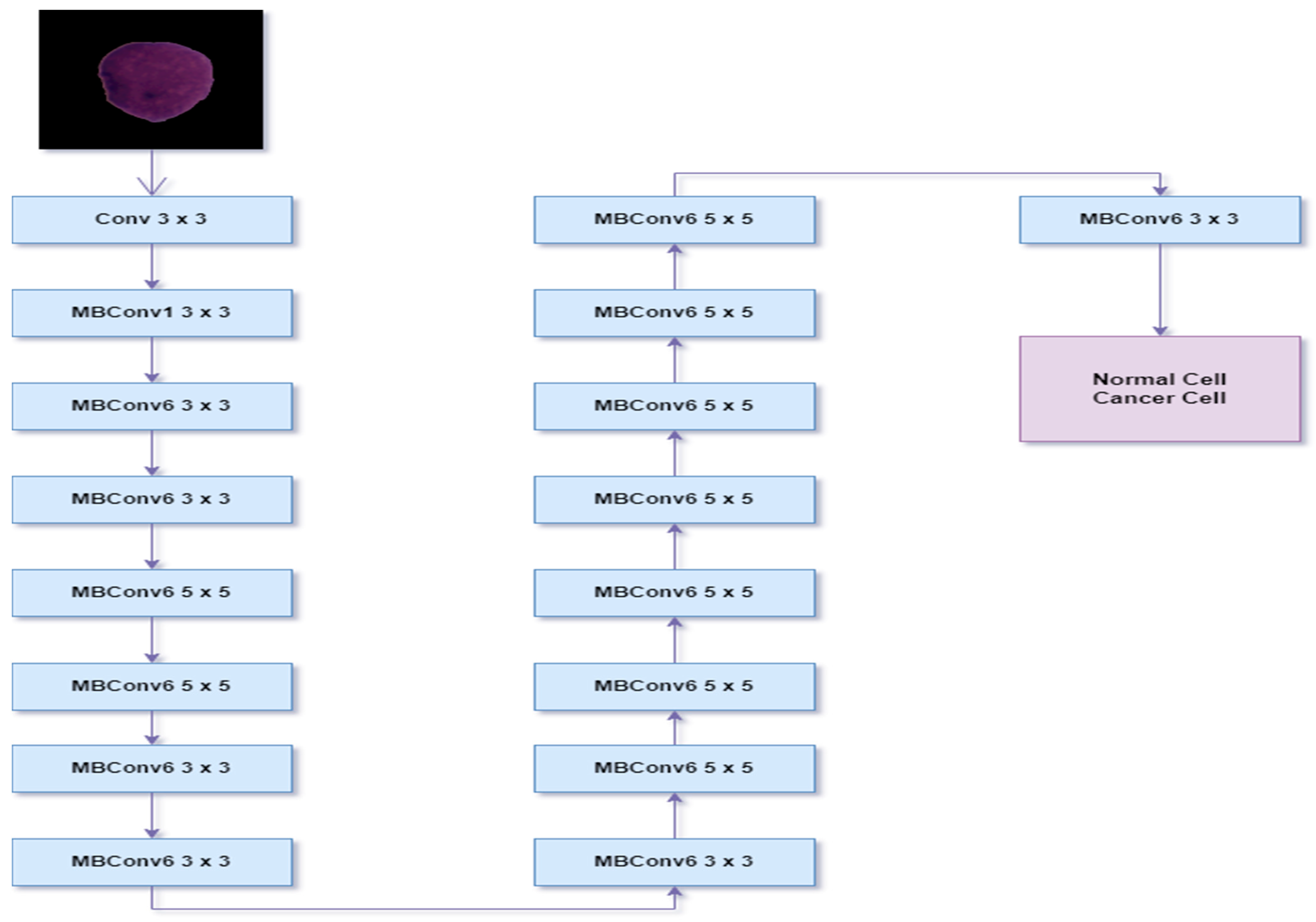
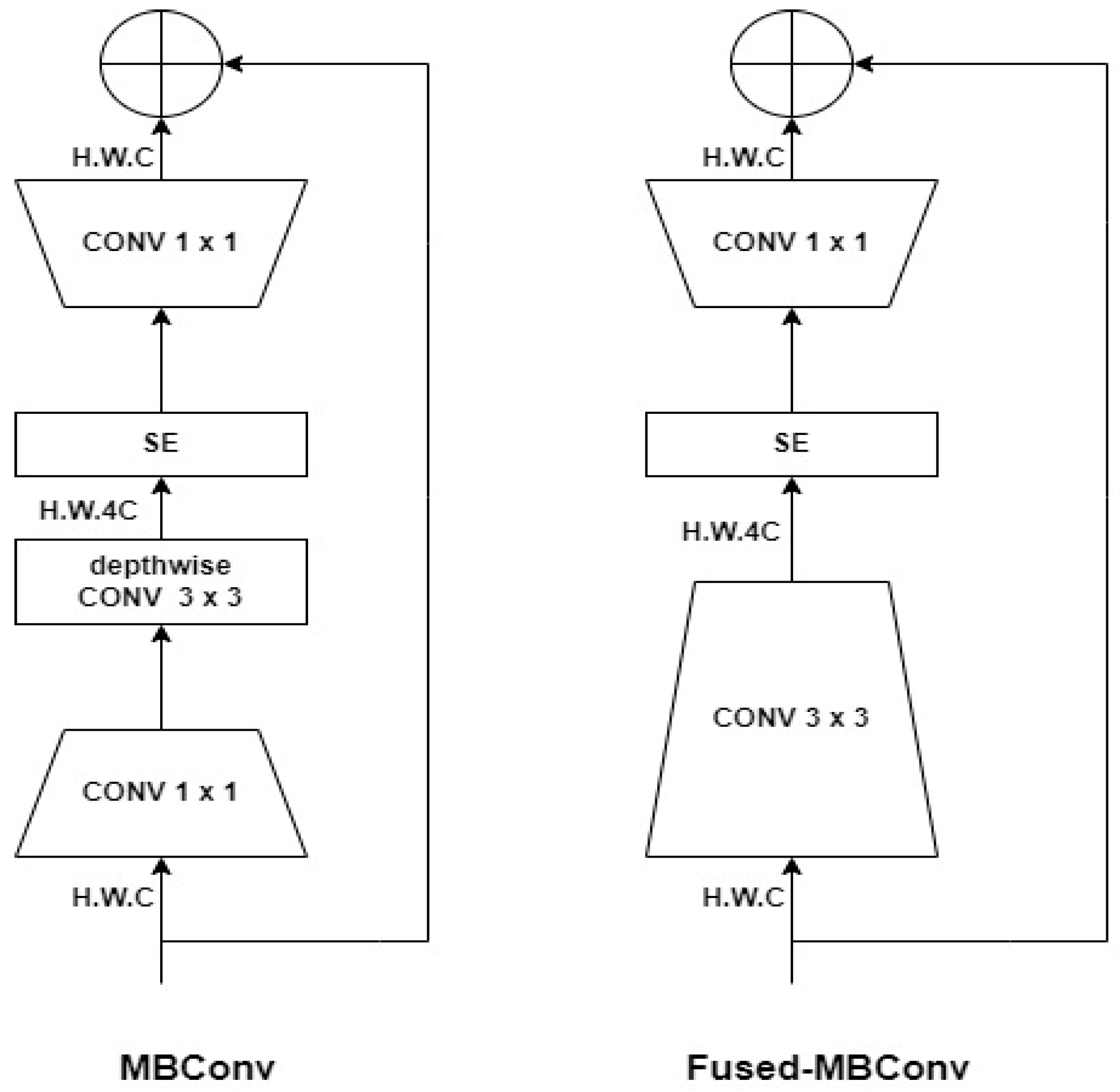
- EFFICIENTNET CNN MODEL
- C.
- EFFICIENTNET V2S
Multi-Attention Mechanism
- D.
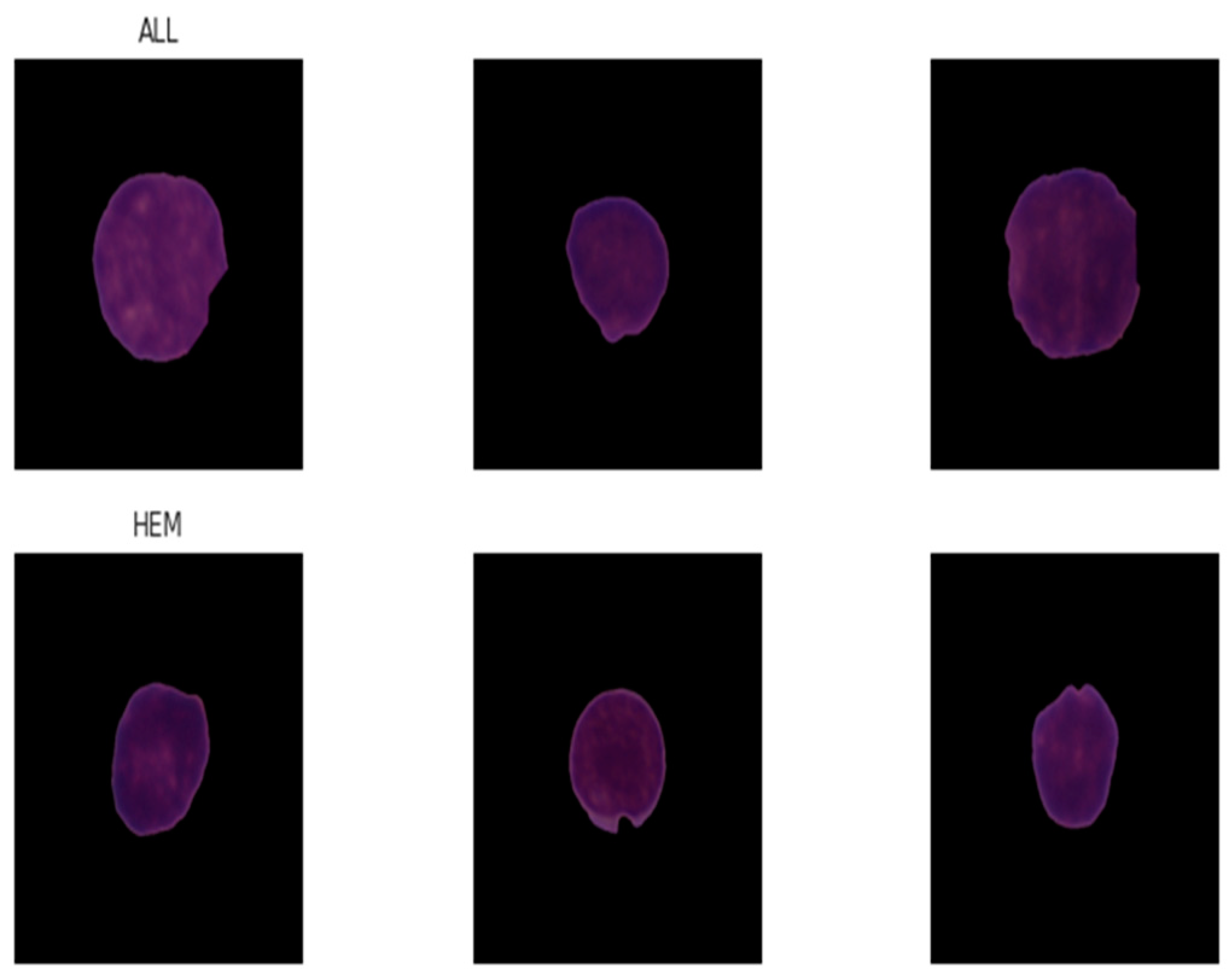
- DATASET DESCRIPTION
4. Results and Discussion
- A.
- PERFORMANCE EVALUATION METRICS
- B.
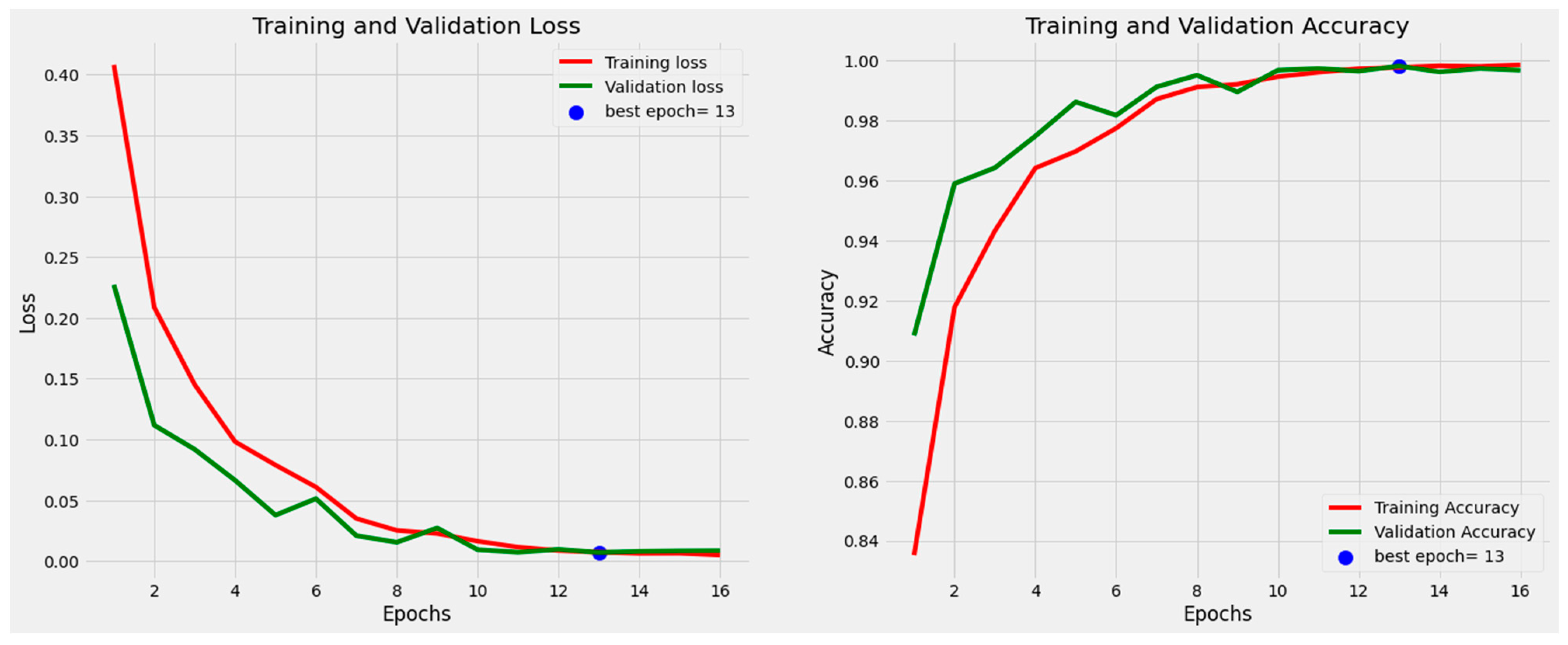
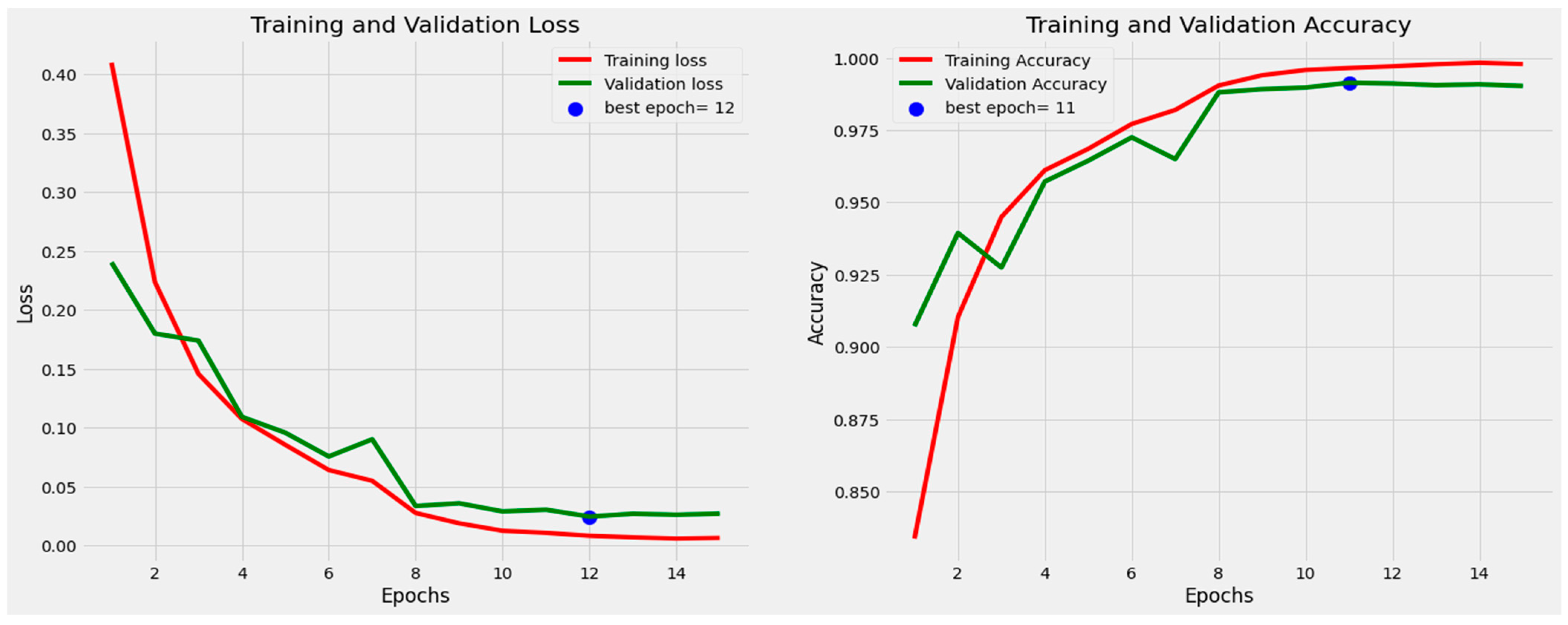
- EXPERIMENTAL SETUP AND HYPERPARAMETERS
- The learning rate hyperparameter determines how much change will be made to the network’s weights after each backpropagation pass. We set a learning rate of 0.001 for both models. The learning rate is reduced to a 0.5 factor if the monitor value does not improve;
- Epochs are set to 20 for both efficietNetB3 and efficientNetV2S;
- The batch size is set to 16 for both models;
- The patience parameter is set to 1 and the stop patience parameter is set to 3;
- Both models are saved with the highest accuracy in the validation set;
- Adamax optimizer is used for training purposes with extension of Adam that try to combine the best part of the RMSProp and momentum optimizer. In some scenarios, the Adamax optimizer provides the better optimization than the Adam optimizer;
- Categorical cross-entropy is used to calculate the loss during training that is well-suited for the categorical problem;
- We added an additional batch norm [43] layer before fully connected layers;
- The TensorFlow [44] framework and Python 3.7 were used to implement the experiments;
- C.
- DISCUSSION
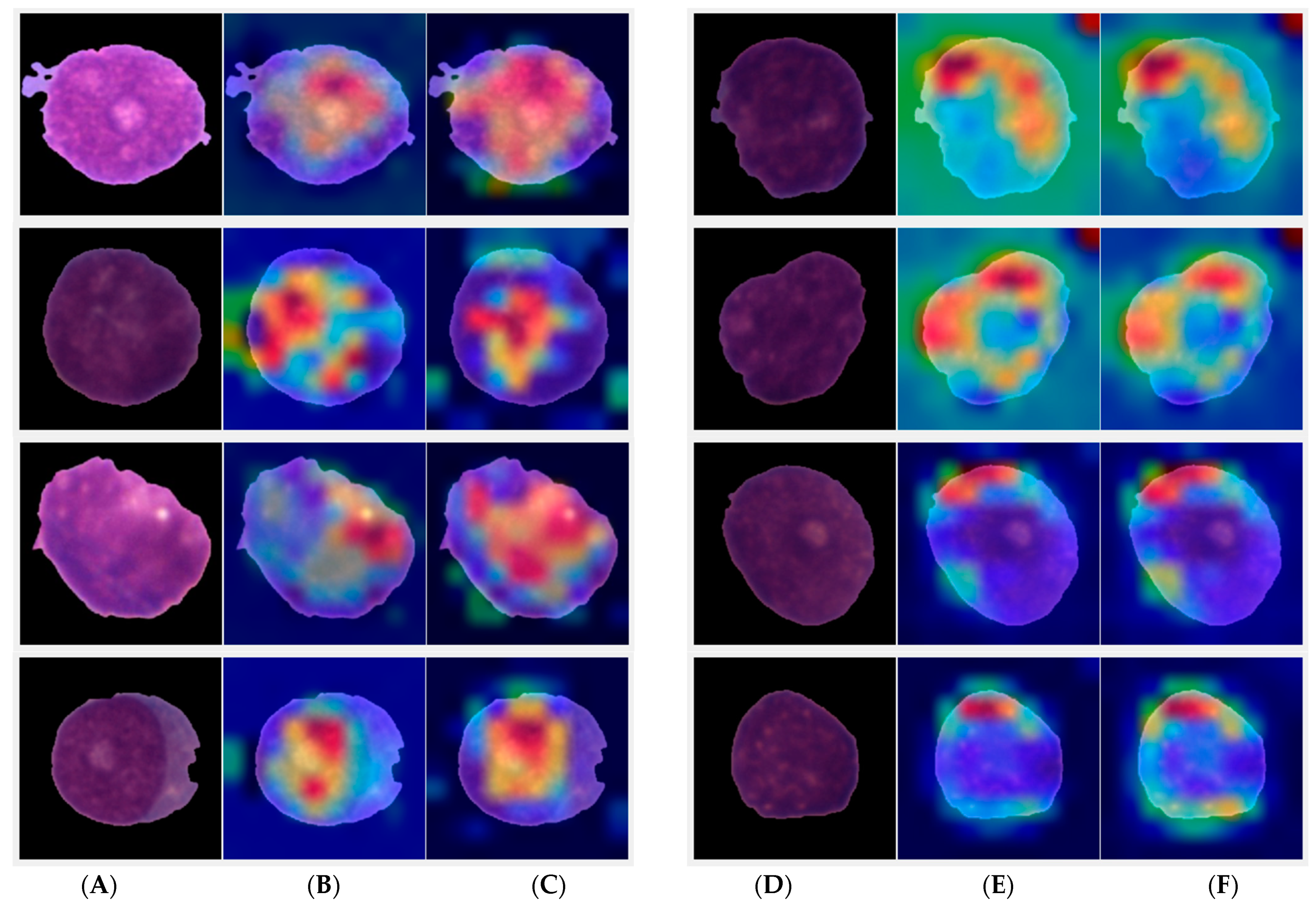
5. Grad-Cam Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Das, P.K.; Meher, S. An efficient deep Convolutional Neural Network based detection and classification of Acute Lymphoblastic Leukemia. Expert Syst. Appl. 2021, 183, 115311. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Kollmannsberger, P.; Ewees, A.A. Efficient Classification of White Blood Cell Leukemia with Improved Swarm Optimization of Deep Features. Sci. Rep. 2020, 10, 2536. [Google Scholar] [CrossRef] [Green Version]
- Alagu, S.; Bagan, K. Chronological Sine Cosine Algorithm Based Deep CNN for Acute Lymphocytic Leukemia Detection. Available online: https://www.researchgate.net/publication/353659892 (accessed on 4 April 2022).
- Rehman, A.; Abbas, N.; Saba, T.; Rahman, S.I.U.; Mehmood, Z.; Kolivand, H. Classification of acute lymphoblastic leukemia using deep learning. Microsc. Res. Tech. 2018, 81, 1310–1317. [Google Scholar] [CrossRef] [PubMed]
- Key Statistics for Acute Lymphocytic Leukemia. Available online: https://www.cancer.org/cancer/acute-lymphocytic-leukemia/about/key-statistics (accessed on 4 April 2022).
- American Cancer Society What’s New in Acute Lymphocytic Leukemia (ALL) Research? Available online: https://www.cancer.org/cancer/acute-lymphocytic-leukemia/about/new-research.html (accessed on 4 April 2022).
- Chang, J.H.; Poppe, M.M.; Hua, C.; Marcus, K.J.; Esiashvili, N. Acute lymphoblastic leukemia. Pediatr. Blood Cancer 2021, 68, e28371. [Google Scholar] [CrossRef]
- Cho, P.; Dash, S.; Tsaris, A.; Yoon, H.-J. Image transformers for classifying acute lymphoblastic leukemia. In Proceedings of the Medical Imaging 2022: Computer-Aided Diagnosis, San Diego, CA, USA, 4 April 2022. [Google Scholar] [CrossRef]
- Kasani, P.H.; Park, S.-W.; Jang, J.-W. An Aggregated-Based Deep Learning Method for Leukemic B-lymphoblast Classification. Diagnostics 2020, 10, 1064. [Google Scholar] [CrossRef]
- Papiththira, S.; Kokul, T. Melanoma Skin Cancer Detection Using EfficientNet and Channel Attention Module. In Proceedings of the International Conference on Industrial and Information Systems (ICIIS), Kandy, Sri Lanka, 9–11 December 2021; pp. 227–232. [Google Scholar] [CrossRef]
- Claro, M.; Vogado, L.; Veras, R.; Santana, A.; Tavares, J.; Santos, J.; Machado, V.M. Convolution Neural Network Models for Acute Leukemia Diagnosis. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 63–68. [Google Scholar] [CrossRef]
- Duong, L.T.; Nguyen, P.T.; Di Sipio, C.; Di Ruscio, D. Automated fruit recognition using EfficientNet and MixNet. Comput. Electron. Agric. 2020, 171, 105326. [Google Scholar] [CrossRef]
- Ali, S.; Javaid, N.; Javeed, D.; Ahmad, I.; Ali, A.; Badamasi, U.M. A Blockchain-Based Secure Data Storage and Trading Model for Wireless Sensor Networks. In International Conference on Advanced Information Networking and Applications; Springer: Cham, Switzerland; Caserta, Italy, 2020; pp. 499–511. [Google Scholar] [CrossRef]
- Raza, A.; Ayub, H.; Khan, J.A.; Ahmad, I.; Salama, A.S.; Daradkeh, Y.I.; Javeed, D.; Rehman, A.U.; Hamam, H. A Hybrid Deep Learning-Based Approach for Brain Tumor Classification. Electronics 2022, 11, 1146. [Google Scholar] [CrossRef]
- Javeed, D.; Gao, T.; Khan, M. SDN-Enabled Hybrid DL-Driven Framework for the Detection of Emerging Cyber Threats in IoT. Electronics 2021, 10, 918. [Google Scholar] [CrossRef]
- Al Razib, M.; Javeed, D.; Taimoor Khanet, M.; Alkanhel, R.; Ali Muthanna, M.S. Cyber Threats Detection in Smart Environments Using SDN-Enabled DNN-LSTM Hybrid Framework. IEEE Access 2022, 10, 53015–53026. [Google Scholar] [CrossRef]
- Javeed, D.; Gao, T.; Khan, M.T.; Shoukat, D. A Hybrid Intelligent Framework to Combat Sophisticated Threats in Secure Industries. Sensors 2022, 22, 1582. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Liu, Y.; Javeed, D.; Ahmad, S. A decision-making technique for solving order allocation problem using a genetic algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2020, 853, 012054. [Google Scholar] [CrossRef]
- Javeed, D.; Gao, T.; Khan, M.; Ahmad, I. A Hybrid Deep Learning-Driven SDN Enabled Mechanism for Secure Communication in Internet of Things (IoT). Sensors 2021, 21, 4884. [Google Scholar] [CrossRef] [PubMed]
- Ullah, M.Z.; Zheng, Y.; Song, J.; Aslam, S.; Xu, C.; Kiazolu, G.D.; Wang, L. An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification. Appl. Sci. 2021, 11, 10662. [Google Scholar] [CrossRef]
- Xu, C.; Xu, L.; Ohorodnyk, P.; Roth, M.; Chen, B.; Li, S. Contrast agent-free synthesis and segmentation of ischemic heart disease images using progressive sequential causal GANs. Med. Image Anal. 2020, 62, 101668. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, X.; Sun, S.; Wu, D.; Bai, J.; Yin, Y.; Liu, X.; Zhang, H.; de Albuquerque, V.H.C. Learning physical properties in complex visual scenes: An intelligent machine for perceiving blood flow dynamics from static CT angiography imaging. Neural Netw. 2020, 123, 82–93. [Google Scholar] [CrossRef]
- Gao, Z.; Chung, J.; Abdelrazek, M.; Leung, S.; Hau, W.K.; Xian, Z.; Zhang, H.; Li, S. Privileged Modality Distillation for Vessel Border Detection in Intracoronary Imaging. IEEE Trans. Med. Imaging 2019, 39, 1524–1534. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Dong, Z.; Wang, L.; Jiang, W. Method for Diagnosis of Acute Lymphoblastic Leukemia Based on ViT-CNN Ensemble Model. Comput. Intell. Neurosci. 2021, 2021, 7529893. [Google Scholar] [CrossRef] [PubMed]
- Alagu, S.; Bagan, K. A Novel Segmentation Approach for Acute Lymphocytic Leukemia Detection Using Deep Learning. 2021. Available online: https://www.researchgate.net/publication/353659988 (accessed on 3 September 2022).
- Alagu, S. Automatic Detection of Acute Lymphoblastic Leukemia Using UNET Based Segmentation and Statistical Analysis of Fused Deep Features. Appl. Artif. Intell. 2021, 35, 1952–1969. [Google Scholar] [CrossRef]
- Genovese, A.; Hosseini, M.S.; Piuri, V.; Plataniotis, K.N.; Scotti, F. Acute Lymphoblastic Leukemia Detection Based on Adaptive Unsharpening and deep Learning. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1205–1209. [Google Scholar]
- Shafique, S.; Tehsin, S. Acute Lymphoblastic Leukemia Detection and Classification of Its Subtypes Using Pretrained Deep Convolutional Neural Networks. Technol. Cancer Res. Treat. 2018, 17, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loey, M.; Naman, M.; Zayed, H. Deep Transfer Learning in Diagnosing Leukemia in Blood Cells. Computers 2020, 9, 29. [Google Scholar] [CrossRef] [Green Version]
- Ghaderzadeh, M.; Hosseini, A.; Asadi, F.; Abolghasemi, H.; Bashash, D.; Roshanpoor, A. Automated Detection Model in Classification of B-Lymphoblast Cells from Normal B-Lymphoid Precursors in Blood Smear Microscopic Images Based on the Majority Voting Technique. Sci. Program. 2022, 2022, 4801671. [Google Scholar] [CrossRef]
- Genovese, A.; Hosseini, M.S.; Piuri, V.; Plataniotis, K.N.; Scotti, F. Histopathological Transfer Learning for Acute Lymphoblastic Leukemia Detection. In Proceedings of the 2021 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Di Milano, Italy, 1 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Gebremeskel, K.D.; Kwa, T.C.; Raj, K.H.; Zewdie, G.A.; Shenkute, T.Y.; Maleko, W.A. Automatic Early Detection and Classification of Leukemia from Microscopic Blood Image. AbyssiniaJ. Sci. Technol. 2021, 3, 1–10. Available online: https://journals.wu.edu.et/index.php/ajec/article/view/160 (accessed on 20 April 2022).
- Kandhari, R.; Bhan, A.; Bhatnagar, P.; Goyal, A. Computer based diagnosis of Leukemia in blood smear images. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1462–1466. [Google Scholar] [CrossRef]
- Bodzas, A.; Kodytek, P.; Zidek, J. Automated Detection of Acute Lymphoblastic Leukemia From Microscopic Images Based on Human Visual Perception. Front. Bioeng. Biotechnol. 2020, 8, 1005. [Google Scholar] [CrossRef]
- Chen, Y.-M.; Chou, F.-I.; Ho, W.-H.; Tsai, J.-T. Classifying microscopic images as acute lymphoblastic leukemia by Resnet ensemble model and Taguchi method. BMC Bioinform. 2021, 22, 615. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 11 September 2019; pp. 10691–10700. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, Virtual, CA, USA, 23 June 2021; Available online: http://arxiv.org/abs/2104.00298 (accessed on 6 June 2022).
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Ahmad, I.; Wang, X.; Zhu, M.; Wang, C.; Pi, Y.; Khan, J.; Li, G. EEG-Based Epileptic Seizure Detection via Machine/Deep Learning Approaches: A Systematic Review. Comput. Intell. Neurosci. 2022, 2022, 6486570. [Google Scholar] [CrossRef] [PubMed]
- Mondal, C.; Hasan, K.; Ahmad, M.; Awal, A.; Jawad, T.; Dutta, A.; Islam, R.; Moni, M.A. Ensemble of Convolutional Neural Networks to diagnose Acute Lymphoblastic Leukemia from microscopic images. Inform. Med. Unlocked 2021, 27, 100794. [Google Scholar] [CrossRef]
- Khan, T.U. Internet of Things (IOT) systems and its security challenges. Int. J. Adv. Res. Comput. Eng. Technol. (IJARCET) 2019, 8, 12. [Google Scholar]
- Ahmad, I.; Ullah, I.; Khan, W.U.; Ur Rehman, A.; Adrees, M.S.; Saleem, M.Q.; Shafiq, M. Efficient algorithms for E-healthcare to solve multiobject fuse detection problem. J. Healthc. Eng. 2021, 2021, 9500304. [Google Scholar] [CrossRef]
- Abaddi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2 November 2016; pp. 265–283. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy % | Precision % | Sensitivity % | Specificity % | F1-Score |
|---|---|---|---|---|---|
| EfficientNetV2S | 99.73 | 99.85 | 99.60 | 99.85 | 99.72 |
| EfficientNetB3 | 99.25 | 99.00 | 99.50 | 99.00 | 99.25 |
| Ref | Year | Methods | Accuracy |
|---|---|---|---|
| [20] | 2021 | VGG16 + ECA module | 91% |
| [24] | 2021 | EfficientNetB0 | 95.18% |
| [24] | 2021 | Vision Transformer | 98.90% |
| [9] | 2020 | NasNetLarge + VGG19 | 96.58% |
| [30] | 2022 | Ensemble model based on majority voting technique | 98.50% |
| [24] | 2021 | VIT-CNN Ensemble Model (EfficientNetB0 + Vision Transformer) | 99.03% |
| Proposed | 2022 | Multi-Attention EfficientNetB3 | 99.25% |
| Multi-Attention EfficientNetV2S | 99.73% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, A.; Shoukat, S.; Shehzad, K.; Ahmad, I.; Eshmawi, A.A.; Amin, A.H.; Tag-Eldin, E. A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia. Electronics 2022, 11, 3168. https://doi.org/10.3390/electronics11193168
Saeed A, Shoukat S, Shehzad K, Ahmad I, Eshmawi AA, Amin AH, Tag-Eldin E. A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia. Electronics. 2022; 11(19):3168. https://doi.org/10.3390/electronics11193168
Chicago/Turabian StyleSaeed, Adnan, Shifa Shoukat, Khurram Shehzad, Ijaz Ahmad, Ala’ Abdulmajid Eshmawi, Ali H. Amin, and Elsayed Tag-Eldin. 2022. "A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia" Electronics 11, no. 19: 3168. https://doi.org/10.3390/electronics11193168
APA StyleSaeed, A., Shoukat, S., Shehzad, K., Ahmad, I., Eshmawi, A. A., Amin, A. H., & Tag-Eldin, E. (2022). A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia. Electronics, 11(19), 3168. https://doi.org/10.3390/electronics11193168