
On the Optimization of Machine Learning Techniques for Chaotic Time Series Prediction


Abstract
:1. Introduction
2. Chaotic Systems and Time Series Prediction by ML Methods
2.1. Chaotic Systems
2.2. Chaotic Time Series Prediction by ML Methods
3. Optimization of ML Methods for Predicting Chaotic Time Series
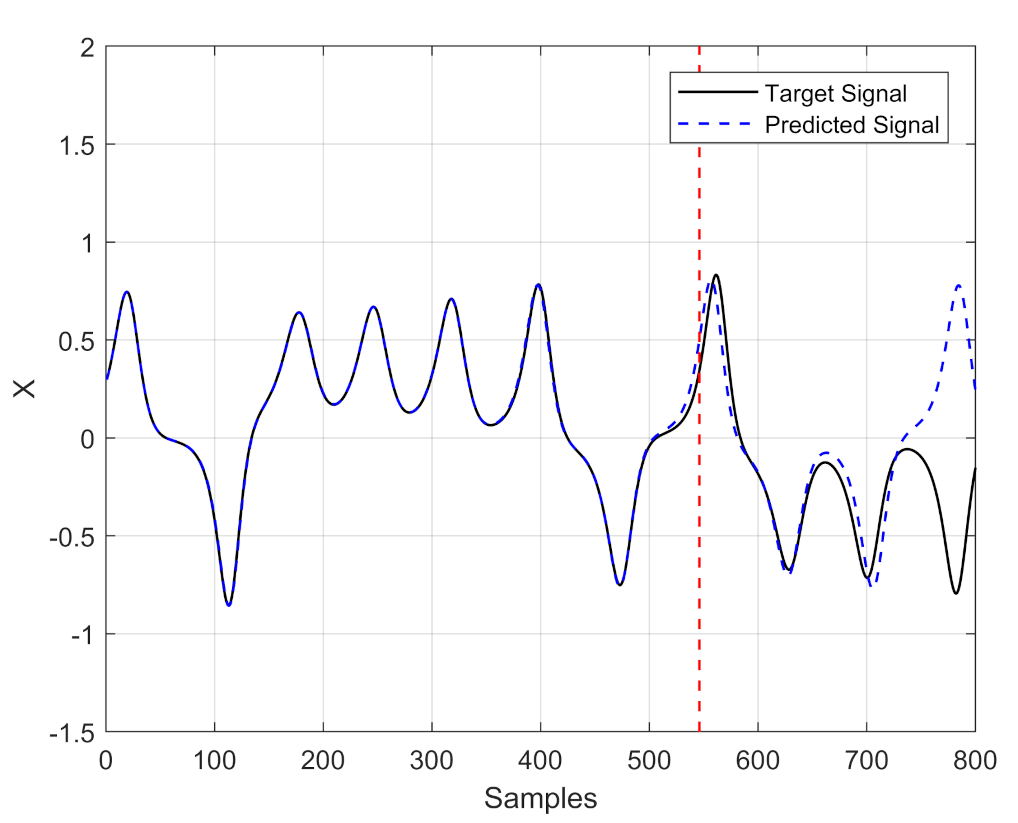
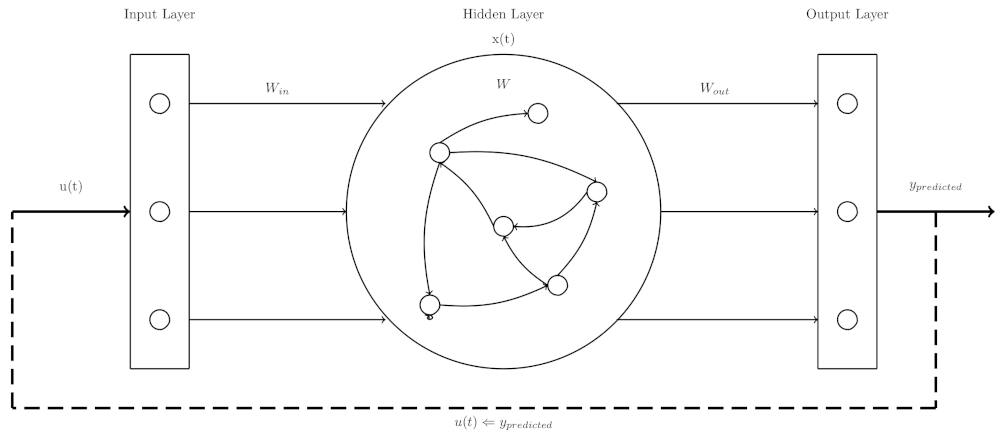
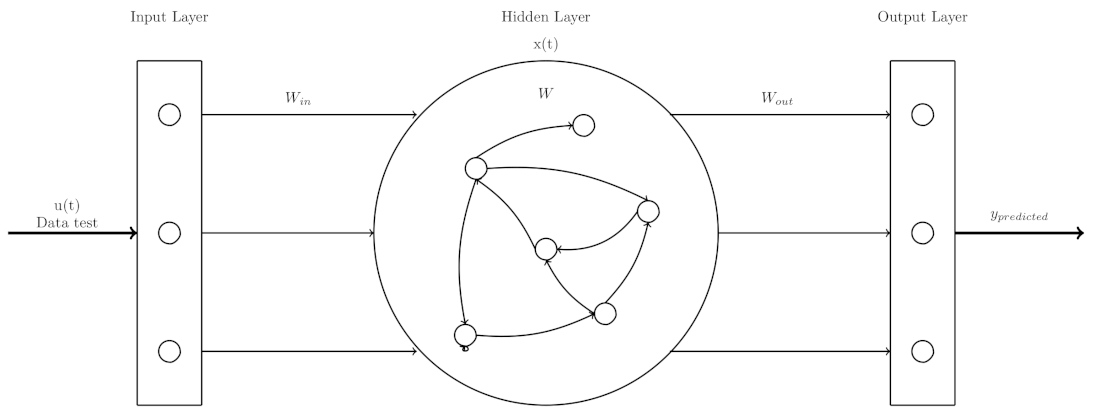
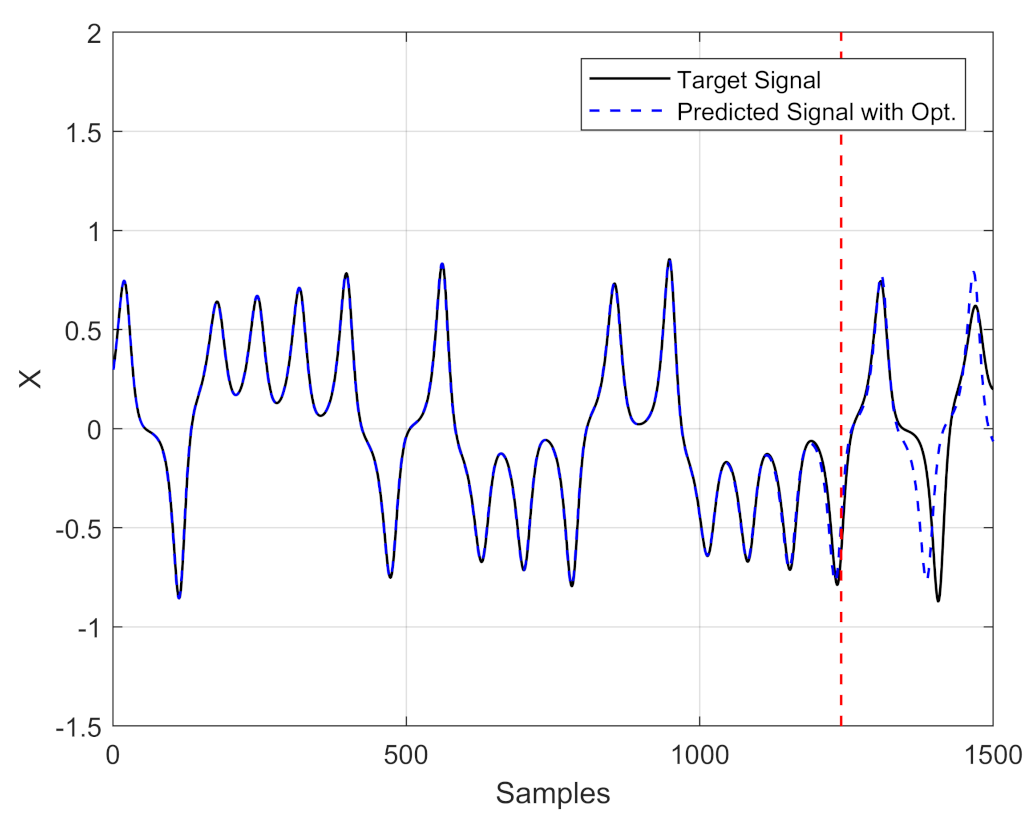
4. Optimizing an ESN by PSO to Enhance Time Series Prediction Horizon
- Leaking Rate : This parameter is associated with leaky integrator ESNs (LI-ESNs) [69]. These are ESNs whose reservoir neurons perform leaky integration of their activations from past steps of time.
- Spectral Radius (SR): It is described as the maximum absolute eigenvalue of the reservoir weights . It is recommended that this parameter be between to ensure the echo state property [70].
- Reservoir Size (N): The reservoir size N represents the number of neuron units within the reservoir. It is a very crucial parameter, since it decides the maximum number of possible connections within the reservoir [71]. Jaeger [71] has suggested that N be in the range with T as the length of training data.
- Input /Output scaling : The input weight influences the level of the linearity of the responses of reservoir units. For a that is uniformly distributed, the input scaling is referred to as a range from which values of are drawn.
- Reservoir Activation Function: For the ESN, the reservoir activation is a non-linear function. In most works, the function of choice has been the or positive logistic [72].
- Regularization parameter of ridge regression (RR): Regularization is often aimed at reducing the noise sensitivity of the network and also to prevent overfitting [73].
| Algorithm 1: Optimization of an ESN to predict the Lorenz system with PSO. |
|
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nadiga, B.T. Reservoir Computing as a Tool for Climate Predictability Studies. J. Adv. Model. Earth Syst. 2021, 13, e2020MS002290. [Google Scholar] [CrossRef]
- Dueben, P.D.; Bauer, P. Challenges and design choices for global weather and climate models based on machine learning. Geosci. Model Dev. 2018, 11, 3999–4009. Available online: https://gmd.copernicus.org/articles/11/3999/2018/ (accessed on 31 August 2022). [CrossRef] [Green Version]
- Scher, S. Toward Data-Driven Weather and Climate Forecasting: Approximating a Simple General Circulation Model With Deep Learning. Geophys. Res. Lett. 2018, 12, 12616–12622. [Google Scholar] [CrossRef] [Green Version]
- Bec, J.; Biferale, L.; Boffetta, G.; Cencini, M.; Musacchio, S.; Toschi, F. Lyapunov exponents of heavy particles in turbulence. Phys. Fluids 2006, 18, 091702. [Google Scholar] [CrossRef] [Green Version]
- Hassanaly, M.; Raman, V. Ensemble-LES analysis of perturbation response of turbulent partially-premixed flames. Proc. Combust. Inst. 2019, 37, 2249–2257. Available online: https://www.sciencedirect.com/science/article/pii/S154074891830395X (accessed on 31 August 2022). [CrossRef] [Green Version]
- Nastac, G.; Labahn, J.W.; Magri, L.; Ihme, M. Lyapunov exponent as a metric for assessing the dynamic content and predictability of large-eddy simulations. Phys. Rev. Fluids 2017, 2, 094606. [Google Scholar] [CrossRef]
- Shahi, S.; Marcotte, C.D.; Herndon, C.J.; Fenton, F.H.; Shiferaw, Y.; Cherry, E.M. Long-Time Prediction of Arrhythmic Cardiac Action Potentials Using Recurrent Neural Networks and Reservoir Computing. Front. Physiol.202112734178. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8502981/ (accessed on 31 August 2022).
- Pathak, J.; Hunt, B.; Girvan, M.; Lu, Z.; Ott, E. Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach. Phys. Rev. Lett. 2018, 120, 024102. [Google Scholar] [CrossRef] [Green Version]
- Hüsken, M.; Stagge, P. Recurrent neural networks for time series classification. Neurocomputing 2003, 50, 223–235. Available online: https://www.sciencedirect.com/science/article/pii/S0925231201007068 (accessed on 31 August 2022). [CrossRef]
- Lin, X.; Yang, Z.; Song, Y. Short-term stock price prediction based on echo state networks. Expert Syst. Appl. 2009, 36, 7313–7317. Available online: https://www.sciencedirect.com/science/article/pii/S0957417408006519 (accessed on 31 August 2022). [CrossRef]
- Yao, K.; Huang, K.; Zhang, R.; Hussain, A. Improving Deep Neural Network Performance with Kernelized Min-Max Objective. In Neural Information Processing; Series Lecture Notes in Computer Science; Cheng, L., Leung, A., Ozawa, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 182–191. [Google Scholar]
- Han, M.; Xu, M. Laplacian Echo State Network for Multivariate Time Series Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 238–244. [Google Scholar] [CrossRef]
- Wikner, A.; Pathak, J.; Hunt, B.; Girvan, M.; Arcomano, T.; Szunyogh, I.; Pomerance, A.; Ott, E. Combining machine learning with knowledge-based modeling for scalable forecasting and subgrid-scale closure of large, complex, spatiotemporal systems. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 053111. [Google Scholar] [CrossRef] [PubMed]
- Sheng, C.; Zhao, J.; Wang, W.; Leung, H. Prediction intervals for a noisy nonlinear time series based on a bootstrapping reservoir computing network ensemble. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1036–1048. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Qiao, J.; Han, H.; Wang, L. Design of polynomial echo state networks for time series prediction. Neurocomputing 2018, 290, 148–160. Available online: https://www.sciencedirect.com/science/article/pii/S0925231218301711 (accessed on 31 August 2022). [CrossRef]
- Malik, Z.; Hussain, A.; Wu, Q. Multilayered Echo State Machine: A Novel Architecture and Algorithm. IEEE Trans. Cybern. 2017, 47, 946–959. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, A.; Zimmermann, H.-G. Recurrent neural networks are universal approximators. Int. J. Neural Syst. 2007, 17, 253–263. [Google Scholar] [CrossRef]
- Siegelmann, H.T.; Sontag, E.D. Turing computability with neural nets. Appl. Math. Lett. 1991, 4, 77–80. Available online: https://www.sciencedirect.com/science/article/pii/089396599190080F (accessed on 31 August 2022). [CrossRef] [Green Version]
- Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn Ger. Ger. Natl. Res. Cent. Inf. Technol. GMD Tech. Rep. 2001, 148, 13. [Google Scholar]
- Shen, L.; Chen, J.; Zeng, Z.; Yang, J.; Jin, J. A novel echo state network for multivariate and nonlinear time series prediction. Appl. Soft Comput. 2018, 62, 524–535. Available online: https://www.sciencedirect.com/science/article/pii/S1568494617306439 (accessed on 31 August 2022). [CrossRef]
- Maass, W.; Natschläger, T.; Markram, H. Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef]
- Yperman, J.; Becker, T. Bayesian optimization of hyper-parameters in reservoir computing. arXiv 2016, arXiv:1611.05193. [Google Scholar]
- Zhang, C.; Lin, Q.; Gao, L.; Li, X. Backtracking Search Algorithm with three constraint handling methods for constrained optimization problems. Expert Syst. Appl. 2015, 42, 7831–7845. Available online: https://www.sciencedirect.com/science/article/pii/S0957417415003863 (accessed on 31 August 2022). [CrossRef]
- Dorigo, M. Optimization, Learning and Natural Algorithms. Ph.D. Thesis, Politecnico di Milano, Milan, Italy, 1992. [Google Scholar]
- Yang, X.-S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: 2010. Available online: www.luniver.com (accessed on 31 August 2022).
- Yang, X.-S.; Deb, S. Cuckoo Search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of theICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Strogatz, S. Nonlinear Dynamics and Chaos (Studies in Nonlinearity); Westview Press: Boulder, CO, USA, 1994. [Google Scholar]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 1963, 20, 130–141. Available online: https://journals.ametsoc.org/view/journals/atsc/20/2/1520-0469-1963-020-0130-dnf-2-0-co-2.xml (accessed on 31 August 2022). [CrossRef]
- Rössler, O.E. An equation for continuous chaos. Phys. Lett. A 1976, 57, 397–398. Available online: https://www.sciencedirect.com/science/article/pii/0375960176901018 (accessed on 31 August 2022). [CrossRef]
- Leonov, G.A.; Kuznetsov, N.V. On differences and similarities in the analysis of Lorenz, Chen, and Lu systems. Appl. Math. Comput. 2015, 256, 334–343. Available online: http://www.sciencedirect.com/science/article/pii/S0096300314017937 (accessed on 31 August 2022). [CrossRef] [Green Version]
- Augustová, P.; Beran, Z. Characteristics of the Chen Attractor. In Nostradamus 2013: Prediction, Modeling and Analysis of Complex Systems; Series Advances in Intelligent Systems and Computing; Zelinka, I., Chen, G., Rössler, O., Snasel, V., Abraham, A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2013; Volume 210, pp. 305–312. [Google Scholar]
- Zhong, G.-Q.; Ayrom, F. Experimental confirmation of chaos from Chua’s circuit. Int. J. Circuit Theory Appl. 1985, 13, 93–98. [Google Scholar] [CrossRef]
- Tsaneva-Atanasova, K.; Osinga, H.M.; Rieß, T.; Sherman, A. Full system bifurcation analysis of endocrine bursting models. J. Theor. Biol. 2010, 264, 1133–1146. Available online: https://www.sciencedirect.com/science/article/pii/S0022519310001633 (accessed on 31 August 2022). [CrossRef] [Green Version]
- González-Zapata, A.M.; Tlelo-Cuautle, E.; Cruz-Vega, I.; León-Salas, W.D. Synchronization of chaotic artificial neurons and its application to secure image transmission under MQTT for IoT protocol. Nonlinear Dyn. 2021, 104, 4581–4600. [Google Scholar] [CrossRef]
- Tlelo-Cuautle, E.; González-Zapata, A.M.; Díaz-Muñoz, J.D.; Fraga, L.G.d.; Cruz-Vega, I. Optimization of fractional-order chaotic cellular neural networks by metaheuristics. Eur. Phys. J. Spec. Top. 2022, 231, 2037–2043. [Google Scholar] [CrossRef]
- Tlelo-Cuautle, E.; Díaz-Muñoz, J.D.; González-Zapata, A.M.; Li, R.; León-Salas, W.D.; Fernández, F.V.; Guillén-Fernández, O.; Cruz-Vega, I. Chaotic Image Encryption Using Hopfield and Hindmarsh–Rose Neurons Implemented on FPGA. Sensors 2020, 20, 1326. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. Available online: https://www.nature.com/articles/323533a0 (accessed on 31 August 2022). [CrossRef]
- Li, D.; Han, M.; Wang, J. Chaotic Time Series Prediction Based on a Novel Robust Echo State Network. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 787–799. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Han, M.; Qiu, T.; Lin, H. Hybrid Regularized Echo State Network for Multivariate Chaotic Time Series Prediction. IEEE Trans. Cybern. 2019, 49, 2305–2315. [Google Scholar] [CrossRef] [PubMed]
- Bompas, S.; Georgeot, B.; Guéry-Odelin, D. Accuracy of neural networks for the simulation of chaotic dynamics: Precision of training data vs precision of the algorithm. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 113118. [Google Scholar] [CrossRef]
- Bo, Y.-C.; Wang, P.; Zhang, X. An asynchronously deep reservoir computing for predicting chaotic time series. Appl. Soft Comput. 2020, 95, 106530. Available online: https://www.sciencedirect.com/science/article/pii/S1568494620304695 (accessed on 31 August 2022). [CrossRef]
- Doan, N.A.K.; Polifke, W.; Magri, L. Physics-Informed Echo State Networks for Chaotic Systems Forecasting. In Computational Science—ICCS 2019; Series Lecture Notes in Computer Science; Rodrigues, J.M.F., Cardoso, P.J.S., Monteiro, J., Lam, R., Krzhizhanovskaya, V.V., Lees, M.H., Dongarra, J.J., Sloot, P.M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 192–198. [Google Scholar]
- Pathak, J.; Wikner, A.; Fussell, R.; Chandra, S.; Hunt, B.R.; Girvan, M.; Ott, E. Hybrid forecasting of chaotic processes: Using machine learning in conjunction with a knowledge-based model. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 041101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Racca, A.; Magri, L. Robust Optimization and Validation of Echo State Networks for learning chaotic dynamics. Neural Netw. 2021, 142, 252–268. Available online: https://www.sciencedirect.com/science/article/pii/S0893608021001969 (accessed on 31 August 2022). [CrossRef]
- Yao, X.; Wang, Z. Fractional Order Echo State Network for Time Series Prediction. Neural Process. Lett. 2020, 52, 603–614. [Google Scholar] [CrossRef]
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep Learning with Long Short-Term Memory for Time Series Prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef] [Green Version]
- Griffith, A.; Pomerance, A.; Gauthier, D.J. Forecasting chaotic systems with very low connectivity reservoir computers. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 123108. [Google Scholar] [CrossRef] [Green Version]
- Qiao, J.; Wang, L.; Yang, C.; Gu, K. Adaptive Levenberg-Marquardt Algorithm Based Echo State Network for Chaotic Time Series Prediction. IEEE Access 2018, 6, 10720–10732. [Google Scholar] [CrossRef]
- Pathak, J.; Lu, Z.; Hunt, B.R.; Girvan, M.; Ott, E. Using machine learning to replicate chaotic attractors and calculate Lyapunov exponents from data. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 121102. [Google Scholar] [CrossRef] [PubMed]
- Chattopadhyay, A.; Hassanzadeh, P.; Subramanian, D. Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: Reservoir computing, artificial neural network, and long short-term memory network. Nonlinear Process. Geophys. 2020, 27, 373–389. Available online: https://npg.copernicus.org/articles/27/373/2020/ (accessed on 31 August 2022). [CrossRef]
- Yanan, G.; Xiaoqun, C.; Bainian, L.; Kecheng, P. Chaotic Time Series Prediction Using LSTM with CEEMDAN. J. Phys. Conf. Ser. 2020, 1617, 012094. [Google Scholar] [CrossRef]
- Xu, M.; Han, M. Adaptive Elastic Echo State Network for Multivariate Time Series Prediction. IEEE Trans. Cybern. 2016, 46, 2173–2183. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Sun, Y.; Ren, J. Low dimensional mid-term chaotic time series prediction by delay parameterized method. Inf. Sci. 2020, 516, 1–19. Available online: https://www.sciencedirect.com/science/article/pii/S0020025519311351 (accessed on 31 August 2022). [CrossRef]
- Alemu, M.N. A Fuzzy Model for Chaotic Time Series Prediction. Int. J. Innov. Comput. Inf. Control. 2018, 14, 1767–1786. [Google Scholar] [CrossRef]
- Pano-Azucena, A.D.; Tlelo-Cuautle, E.; Ovilla-Martinez, B.; Fraga, L.G.d.; Li, R. Pipeline FPGA-Based Implementations of ANNs for the Prediction of up to 600-Steps-Ahead of Chaotic Time Series. J. Circuits Syst. Comput. 2021, 30, 2150164. [Google Scholar] [CrossRef]
- Lin, C.-J.; Chen, C.-H.; Lin, C.-T. A Hybrid of Cooperative Particle Swarm Optimization and Cultural Algorithm for Neural Fuzzy Networks and Its Prediction Applications. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2009, 39, 55–68. [Google Scholar]
- Chandra, R. Competition and Collaboration in Cooperative Coevolution of Elman Recurrent Neural Networks for Time-Series Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3123–3136. [Google Scholar] [CrossRef] [Green Version]
- Lan, P.; Xia, K.; Pan, Y.; Fan, S. An Improved GWO Algorithm Optimized RVFL Model for Oil Layer Prediction. Electronics 2021, 10, 3178. [Google Scholar] [CrossRef]
- Cao, Z. Evolutionary optimization of artificial neural network using an interactive phase-based optimization algorithm for chaotic time series prediction. Soft Comput. 2020, 24, 17093–17109. [Google Scholar] [CrossRef]
- Ong, P.; Zainuddin, Z. Optimizing wavelet neural networks using modified cuckoo search for multi-step ahead chaotic time series prediction. Appl. Soft Comput. 2019, 80, 374–386. Available online: https://www.sciencedirect.com/science/article/pii/S1568494619302078 (accessed on 31 August 2022). [CrossRef]
- Sun, W.; Peng, T.; Luo, Y.; Zhang, C.; Hua, L.; Ji, C.; Ma, H. Hybrid short-term runoff prediction model based on optimal variational mode decomposition, improved Harris hawks algorithm and long short-term memory network. Environ. Res. Commun. 2022, 4, 045001. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Luo, G. A new optimization algorithm for non-stationary time series prediction based on recurrent neural networks. Future Gener. Comput. Syst. 2020, 102, 738–745. Available online: https://www.sciencedirect.com/science/article/pii/S0167739X18332540 (accessed on 31 August 2022). [CrossRef]
- Xie, H.; Zhang, L.; Lim, C.P. Evolving CNN-LSTM Models for Time Series Prediction Using Enhanced Grey Wolf Optimizer. IEEE Access 2020, 8, 161519–161541. [Google Scholar] [CrossRef]
- Chouikhi, N.; Ammar, B.; Rokbani, N.; Alimi, A.M. PSO-based analysis of Echo State Network parameters for time series forecasting. Appl. Soft Comput. 2017, 55, 211–225. Available online: https://www.sciencedirect.com/science/article/pii/S1568494617300649 (accessed on 31 August 2022). [CrossRef]
- Zhang, M.; Wang, B.; Zhou, Y.; Sun, H. WOA-Based Echo State Network for Chaotic Time Series Prediction. J. Korean Phys. Soc. 2020, 76, 384–391. [Google Scholar] [CrossRef]
- Bala, A.; Ismail, I.; Ibrahim, R.; Sait, S.M. Applications of Metaheuristics in Reservoir Computing Techniques: A Review. IEEE Access 2018, 6, 58012–58029. [Google Scholar] [CrossRef]
- Lukoševičius, M.; Jaeger, H. Reservoir computing approaches to recurrent neural network training. Comput. Sci. Rev. 2009, 3, 127–149. Available online: https://www.sciencedirect.com/science/article/pii/S1574013709000173 (accessed on 31 August 2022). [CrossRef]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky- integrator neurons. Neural Netw. 2007, 20, 335–352. Available online: https://www.sciencedirect.com/science/article/pii/S089360800700041X (accessed on 31 August 2022). [CrossRef]
- Lukosevicius, M. A Practical Guide to Applying Echo State Networks. In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 659–686. [Google Scholar] [CrossRef]
- Jaeger, H. Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the “Echo State Network” Approach; GMD-Forschungszentrum Informationstechnik: Bonn, Germany, 2002; Volume 5. [Google Scholar]
- Wang, S.; Yang, X.-J.; Wei, C.-J. Harnessing Non-linearity by Sigmoid-wavelet Hybrid Echo State Networks (SWHESN). In Proceedings of the 2006 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; Volume 1, pp. 3014–3018. [Google Scholar]
- Verducci, J.S. Prediction and Discovery: AMS-IMS-SIAM Joint Summer Research Conference, Machine and Statistical Learning: Prediction and Discovery, June 25–29, 2006, Snowbird, Utah; American Mathematical Society: Providence, RI, USA, 2007. [Google Scholar]
- Shi, Y. Particle Swarm Optimization. IEEE Connect. 2014, 2, 8–13. Available online: https://www.marksmannet.com/RobertMarks/Classes/ENGR5358/Papers/pso_bySHI.pdf (accessed on 31 August 2022).
- Bai, Q. Analysis of particle swarm optimization algorithm. Comput. Inf. Sci. 2010, 3, 180. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zeng, Y.-R.; Wang, S.; Wang, L. Optimizing echo state network with backtracking search optimization algorithm for time series forecasting. Eng. Appl. Artif. Intell. 2019, 81, 117–132. Available online: https://www.sciencedirect.com/science/article/pii/S0952197619300326 (accessed on 31 August 2022). [CrossRef]
- Bala, A.; Ismail, I.; Ibrahim, R. Cuckoo Search Based Optimization of Echo State Network for Time Series Prediction. In Proceedings of the 2018 International Conference on Intelligent and Advanced System (ICIAS), Kuala Lumpur, Malaysia, 13–14 August 2018; pp. 1–6. [Google Scholar]
- Tian, Z. Echo state network based on improved fruit fly optimization algorithm for chaotic time series prediction. J. Ambient. Intell. Humaniz. Comput. 2020, 13, 3483–3502. [Google Scholar] [CrossRef]
- Chen, H.-C.; Wei, D.-Q. Chaotic time series prediction using echo state network based on selective opposition grey wolf optimizer. Nonlinear Dyn. 2021, 104, 3925–3935. [Google Scholar] [CrossRef]
- Chouikhi, N.; Fdhila, R.; Ammar, B.; Rokbani, N.; Alimi, A.M. Single- and multi-objective particle swarm optimization of reservoir structure in Echo State Network. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 440–447. [Google Scholar]
- Liu, J.; Sun, T.; Luo, Y.; Yang, S.; Cao, Y.; Zhai, J. Echo state network optimization using binary grey wolf algorithm. Neurocomputing 2020, 385, 310–318. Available online: https://www.sciencedirect.com/science/article/pii/S0925231219317783 (accessed on 31 August 2022). [CrossRef]
- Yang, C.; Qiao, J.; Wang, L. A novel echo state network design method based on differential evolution algorithm. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 3977–3982. [Google Scholar]
- Chouikhi, N.; Ammar, B.; Rokbani, N.; Alimi, A.M.; Abraham, A. A Hybrid Approach Based on Particle Swarm Optimization for Echo State Network Initialization. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 2896–2901. [Google Scholar]
- Otte, S.; Butz, M.V.; Koryakin, D.; Becker, F.; Liwicki, M.; Zell, A. Optimizing recurrent reservoirs with neuro-evolution. Neurocomputing 2016, 192, 128–138. Available online: https://www.sciencedirect.com/science/article/pii/S0925231216002629 (accessed on 31 August 2022). [CrossRef]
- Na, X.; Han, M.; Ren, W.; Zhong, K. Modified BBO-Based Multivariate Time-Series Prediction System With Feature Subset Selection and Model Parameter Optimization. IEEE Trans. Cybern. 2020, 52, 2163–2173. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chaotic System | Differential Equations | Parameters | Attractor |
|---|---|---|---|
| Lorenz [28] |  | ||
| Rössler [30] |  | ||
| Lü [31] |  | ||
| Chen [32] |  |
| ML | Dataset | Steps Ahead | RMSE | |
|---|---|---|---|---|
| ESN [50] | Lorenz | 300 | — | — |
| ESN [51] | Lorenz | 460 | 10.35 | — |
| RNN-LSTM [51] | Lorenz | 180 | 4.05 | — |
| ANN [51] | Lorenz | 120 | 2.7 | — |
| CEEMDAN-LSTM [52] | Lorenz | — | 2 | |
| ESN [41] | Lorenz | 700 | — | — |
| RESN [39] | Lorenz | 500 | — | |
| Rossler | 500 | — | ||
| AESN [53] | Lorenz | 1 | — | |
| Rossler | 1 | — | ||
| HESN [44] | Lorenz | — | 12 | — |
| DPM [54] | Lorenz | 300 | — | |
| Fuzzy [55] | Mackey-Glass | 1000 | — | |
| ADRC [42] | Rossler | 40 | — | |
| ALM-ESN [49] | Lorenz | 1 | — | |
| Mackey-Glass | 84 | — | ||
| HESN [40] | Rossler | 28 | — | |
| FESN [46] | Mackey-Glass | 20 | — | — |
| NARX [56] | Chaotic Serie | 600 | — | |
| ESN [56] | Chaotic Serie | 600 | — | |
| ESN (This work) | Lorenz | 500 | — |
| ML | Optimization | Dataset | Fitness Function | Value | Data Test |
|---|---|---|---|---|---|
| RVFL [59] | GWO | Oil Layer | Accuracy | 130 | |
| PSO | Oil Layer | Accuracy | 130 | ||
| WOA | Oil Layer | Accuracy | 130 | ||
| FNN [60] | IPBO | Lorenz | MSE | 500 | |
| WNN [61] | MCSA | Mackey–Glass | RMSE | 500 | |
| Lorenz | RMSE | 500 | |||
| LSTM [62] | IHHO | Jinsha River | MAPE | 4.19 | 1753 |
| RNN [63] | NS-ADAM | Electric Power, Nanchang | MSE | 300 | |
| CNN-LSTM [64] | GWO | Energy Consumption | MAE | 290.5 | — |
| Parameters | a | MSE | Data Test | ||
|---|---|---|---|---|---|
| Original | 1.2500 | 0.5000 | 1000 | ||
| Solution 1 | 1.3540 | 0.5466 | 1000 | ||
| Solution 2 | 1.3208 | 0.5811 | 1000 | ||
| Solution 3 | 1.1338 | 0.3308 | 1000 | ||
| Solution 4 | 1.2694 | 0.4846 | 1000 | ||
| Solution 5 | 1.3332 | 0.5690 | 1000 |
| Optimization | Dataset | Fitness Function | Value | Data Test |
|---|---|---|---|---|
| BSA [76] | Canadan Lynx | MSE | 14 | |
| PSO [65] | Lorenz | RMSE | 500 | |
| Mackey–Glass | RMSE | 500 | ||
| CS [77] | Mackey–Glass | MSE | 1000 | |
| FOA [78] | Lorenz | RMSE | 4000 | |
| Mackey–Glass | RMSE | 1000 | ||
| SOGWO [79] | Mackey–Glass | RMSE | 800 | |
| WOA [66] | Lorenz | FF | 600 | |
| GA [66] | Lorenz | FF | 600 | |
| PSO [80] | Lorenz | RMSE | 500 | |
| BGWO [81] | Mackey–Glass | RMSE | 500 | |
| DE [82] | Mackey–Glass | NRMSE | 2000 | |
| PSO [83] | Mackey–Glass | MSE | 1000 | |
| Neuro-Evolution [84] | Hénon | NMSE | 3000 | |
| MBBO [85] | Lorenz | RMSE | 2000 | |
| PSO (This work) | Lorenz | MSE | 1000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Zapata, A.M.; Tlelo-Cuautle, E.; Cruz-Vega, I. On the Optimization of Machine Learning Techniques for Chaotic Time Series Prediction. Electronics 2022, 11, 3612. https://doi.org/10.3390/electronics11213612
González-Zapata AM, Tlelo-Cuautle E, Cruz-Vega I. On the Optimization of Machine Learning Techniques for Chaotic Time Series Prediction. Electronics. 2022; 11(21):3612. https://doi.org/10.3390/electronics11213612
Chicago/Turabian StyleGonzález-Zapata, Astrid Maritza, Esteban Tlelo-Cuautle, and Israel Cruz-Vega. 2022. "On the Optimization of Machine Learning Techniques for Chaotic Time Series Prediction" Electronics 11, no. 21: 3612. https://doi.org/10.3390/electronics11213612
APA StyleGonzález-Zapata, A. M., Tlelo-Cuautle, E., & Cruz-Vega, I. (2022). On the Optimization of Machine Learning Techniques for Chaotic Time Series Prediction. Electronics, 11(21), 3612. https://doi.org/10.3390/electronics11213612