
Intelligent Deep Machine Learning Cyber Phishing URL Detection Based on BERT Features Extraction

 , , ,
, , ,
Abstract
:1. Introduction
- Creation of an intelligent convolutional neural network learning method based on BERT features extraction to discover the appropriate features for cyber-phishing URL website detection.
- It improved the accuracy of phishing website detection better than deep machine learning.
- The proposed method was compared, examined, and evaluated as evident for its performance and effectiveness.
- The study compared and evaluated the findings of the proposed method with other developed methods and with results from the literature that had used similar datasets.
2. Related Works
3. Materials and Methods
3.1. Dataset Description and Representation
3.2. BERT
3.3. Deep Machine Learning
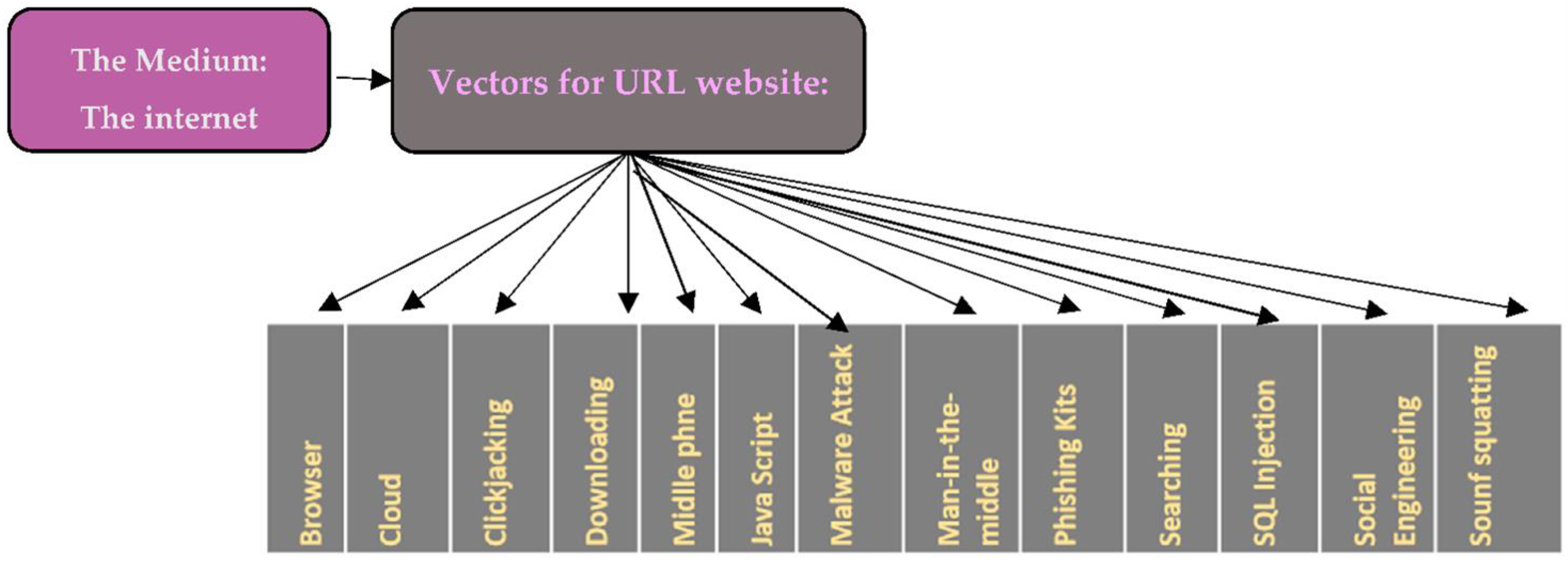
3.4. URL Phishing Components
- Medium of phishing: the most used medium is the internet,
- Transmission vector of attack: a website as a medium for transmitting attacks between attacker and the victim,
- Attack technical approaches: include social engineering and browser vulnerabilities, such as browser vulnerabilities, cloud environment, click jacking, etc.
4. Proposed Method
- (1)
- The URL column: contained unique URLs.
- (2)
- The Label column: contained the corresponding URL detection—good or bad (phishing).
- Read dataset.
- Check for duplicated records and remove them. Initially, there were 549,346 records before removing the duplicated records, resulting in 472,272 records.
- Check for the null column value and remove the corresponding record, whereby there were no null records found and the number of records remains the same, at 472,272.
- Extract netloc (domain name): a function to extract the different structure paths of a full-path URL (parse_url), in which a new column (parsed_url) contains all the URL parts. Then, this component column was fragmented into multiple columns, whereby each column contained one part of the URL structure. The finding was that the number of records remained the same.
- Remove noise (null netloc): Netloc is the domain name, thus, if it is phishing, the URL would be a phishing URL regardless of remainder parts. Therefore, the important feature is the netloc feature, and it is needed to check if it has noise data, i.e., null values. After removing the null values (noise removal), the number of records was 472,259.
- Scheme: the protocol name, usually http or https.
- Netloc: contains the network location—which includes the domain itself (and subdomain if present), the port number, along with optional credentials in the form of username:password. Together, it may take the form of username:[email protected]:80.
- Path: contains information on how the specified resource needs to be accessed.
- Params: element which adds fine-tuning to the path (optional).
- Query: another element, adding fine-grained access to the path under consideration (optional).
- Fragment: contains bits of information about the resource being accessed within the path (optional).
5. Evaluation Metrics
6. Results Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gupta, B.B.; Tewari, A.; Jain, A.K.; Agrawal, D.P. Fighting against phishing attacks: State of the art and future challenges. Neural Comput. Appl. 2017, 28, 3629–3654. [Google Scholar] [CrossRef]
- Ali, B.J. Impact of COVID-19 on consumer buying behavior toward online shopping in Iraq. Econ. Stud. J. 2020, 18, 267–280. [Google Scholar]
- Huang, Y.; Qin, J.; Wen, W. Phishing URL detection via capsule-based neural network. In Proceedings of the 2019 IEEE 13th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 25–27 October 2019; pp. 22–26. [Google Scholar]
- Venkatesha, S.; Reddy, K.R.; Chandavarkar, B. Social engineering attacks during the COVID-19 pandemic. SN Comput. Sci. 2021, 2, 78. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.statista.com/statistics/420442/organizations-most-affected-byphishing/ (accessed on 28 July 2022).
- Oest, A.; Safei, Y.; Doupé, A.; Ahn, G.-J.; Wardman, B.; Warner, G. Inside a phisher′s mind: Understanding the anti-phishing ecosystem through phishing kit analysis. In Proceedings of the 2018 APWG Symposium on Electronic Crime Research (eCrime), San Diego, CA, USA, 15–17 May 2018; pp. 1–12. [Google Scholar]
- Hong, J. The state of phishing attacks. Commun. ACM 2012, 55, 74–81. [Google Scholar] [CrossRef] [Green Version]
- Akbar, N. Analysing Persuasion Principles in Phishing Emails. Master’s Thesis, University of Twente, Twente, The Netherlands, 2014. [Google Scholar]
- Jamil, A.; Asif, K.; Ghulam, Z.; Nazir, M.K.; Alam, S.M.; Ashraf, R. Mpmpa: A mitigation and prevention model for social engineering based phishing attacks on facebook. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5040–5048. [Google Scholar]
- Odeh, A.; Keshta, I.; Abdelfattah, E. Machine learningtechniquesfor detection of website phishing: A review for promises and challenges. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual, 27–30 January 2021; pp. 0813–0818. [Google Scholar]
- Khan, M.F. Detection of Phishing Websites Using Deep Learning Techniques. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 3880–3892. [Google Scholar]
- Yi, P.; Guan, Y.; Zou, F.; Yao, Y.; Wang, W.; Zhu, T. Web phishing detection using a deep learning framework. Wirel. Commun. Mob. Comput. 2018, 4678746. [Google Scholar] [CrossRef]
- Taylor, W.L. “Cloze procedure”: A new tool for measuring readability. J. Appl. Psychol. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Alex, S.A.; Jhanjhi, N.; Humayun, M.; Ibrahim, A.O.; Abulfaraj, A.W. Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE. Electronics 2022, 11, 2737. [Google Scholar] [CrossRef]
- Khan, T.; Sherazi, H.H.R.; Ali, M.; Letchmunan, S.; Butt, U.M. Deep learning-based growth prediction system: A use case of China agriculture. Agronomy 2021, 11, 1551. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Pet. Res. 2021. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D. Theory-guided deep-learning for electrical load forecasting (TgDLF) via ensemble long short-term memory. Adv. Appl. Energy 2021, 1, 100004. [Google Scholar] [CrossRef]
- Adebowale, M.A.; Lwin, K.T.; Hossain, M.A. Deep learning with convolutional neural network and long short-term memory for phishing detection. In Proceedings of the 2019 13th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Island of Ulkulhas, Maldives, 26–28 August 2019; pp. 1–8. [Google Scholar]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Predicting phishing websites based on self-structuring neural network. Neural Comput. Appl. 2014, 25, 443–458. [Google Scholar] [CrossRef]
- Al-Alyan, A.; Al-Ahmadi, S. Robust URL phishing detection based on deep learning. KSII Trans. Internet Inf. Syst. (TIIS) 2020, 14, 2752–2768. [Google Scholar]
- Vigneshwaran, P.; Roy, A.S.; Sathvik, B.S.; Nasirulla, D.M.; Chowdary, M.L. Multidimensional features driven phishing detection based on deep learning. In Proceedings of the Integrated Emerging Methods of Artificial Intelligence & Cloud Computing, IEMAICLOUD 2021. Smart Innovation, Systems and Technologies; Springer: Berlin/Heidelberg, Germany; Volume 273. [CrossRef]
- Bustio-Martínez, L.; Álvarez-Carmona, M.A.; Herrera-Semenets, V.; Feregrino-Uribe, C.; Cumplido, R. A lightweight data representation for phishing URLs detection in IoT environments. Inf. Sci. 2022, 603, 42–59. [Google Scholar] [CrossRef]
- Available online: https://scholar.google.com/scholar?as_q=phishing&as_epq=Deep+learning&as_oq=&as_eq=&as_occt=title&as_sauthors=&as_publication=&as_ylo=2018&as_yhi=2022&hl=ar&as_sdt=0%2C5 (accessed on 20 July 2022).
- Al-Ahmadi, S. PDMLP: Phishing detection using multilayer perceptron. Int. J. Netw. Secur. Its Appl. (IJNSA) 2020, 12, 59–71. [Google Scholar]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Zouina, M.; Outtaj, B. A novel lightweight URL phishing detection system using SVM and similarity index. Hum.-Cent. Comput. Inf. Sci. 2017, 7, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Moghimi, M.; Varjani, A.Y. New rule-based phishing detection method. Expert Syst. Appl. 2016, 53, 231–242. [Google Scholar] [CrossRef]
- Ferreira, R.P.; Martiniano, A.; Napolitano, D.; Romero, M.; Gatto, D.D.D.O.; Farias, E.B.P.; Sassi, R.J. Artificial neural network for websites classification with phishing characteristics. Soc. Netw. 2018, 7, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Zhao, G.; Zeng, P. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Somesha, M.; Pais, A.R.; Rao, R.S.; Rathour, V.S. Efficient deep learning techniques for the detection of phishing websites. Sādhanā 2020, 45, 1–18. [Google Scholar] [CrossRef]
- Kaggle.com, P.S.U.A.O. Available online: https://www.kaggle.com/taruntiwarihp/phishing-site-urls (accessed on 27 April 2022).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805, 2018. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Taud, H.; Mas, J. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Berlin/Heidelberg, Germany, 2018; pp. 451–455. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Fielding, R. Relative Uniform Resource Locators; RFC1808 (acm.org); 1995; Available online: https://dl.acm.org/doi/pdf/10.17487/RFC1808 (accessed on 18 March 2022).
- Khan, M.R.H.; Afroz, U.S.; Masum, A.K.M.; Abujar, S.; Hossain, S.A. Sentiment analysis from bengali depression dataset using machine learning. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21. [Google Scholar] [CrossRef] [Green Version]
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Lakshmanarao, A.; Babu, M.R.; Krishna, M.B. Malicious URL Detection using NLP, Machine Learning and FLASK. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2021; pp. 1–4. [Google Scholar]
- Parekh, S.; Parikh, D.; Kotak, S.; Sankhe, S. A new method for detection of phishing websites: URL detection. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 949–952. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Best Algorithm | Result | Datasets | Dataset Size |
|---|---|---|---|---|
| Al-Ahmadi [25] | Multi-layer-deep neural network | 95.73% | Kaagle dataset | 549,346 |
| Sahingoz et al. [26] | Random Forest | 97.98% | Ebbu2017 Phishing Dataset | 73,575 |
| Zouina et al. [27] | SVM with Gaussian kernel | 95.80% | PhishTank | 2000 |
| Moghimi et al. [28] | SVM and decision tree | 98.86% | Yahoo directory service, PhishTank | 2134 |
| Ferreira et al. [29] | ANN-MLP | 98.23% | Phishing Websites Dataset of the University of California’s Machine Learning and Intelligent Systems Learning Center | 3000 |
| Peng Yang et al. [30] | CNN-LSTM, DCDA, Multidimensional Features | 98.61% | Dmoztools.net, PhishTank | 1,965,944 |
| M Somesha et al. [31] | CNN-LSTM and DNN | 99.52% | PhishTank and Alexa database | 3526 |
| ID | URL | Label |
|---|---|---|
| 92669 | www.doggie-school.com/~lmafamor/www.paypal.com.au/webscr.php (accessed on 27 April 2022) | Bad |
| 66744 | www.premiumcentral.us/~lmafamor/www.paypal.com.au/webscr.php (accessed on 27 April 2022) | Bad |
| 78923 | members.tripod.com/~mindcrime_2/freemud.html (accessed on 27 April 2022) | Good |
| 45367 | www.thesmileforsuccess.com/~lmafamor/www.paypal.com.au/webscr.php (accessed on 27 April 2022) | Bad |
| 43256 | www.performancepcplus.com/majormud/index.htm (accessed on 27 April 2022) | Good |
| 78903 | www.myred19.com/~lmafamor/www.paypal.com.au/webscr.php (accessed on 27 April 2022) | Bad |
| 224568 | www.performancepcplus.com/majormud/index.htm (accessed on 27 April 2022) | Good |
| 278908 | www.gameport.com/mudproducts/index.html (accessed on 27 April 2022) | Good |
| # | Feature Name | Data Type | Meaning |
|---|---|---|---|
| 1 | Length | Integer | URL length in character |
| 2 | Tld | Text | URL domain name extension |
| 3 | is_ip | Boolean | True if URL contains IP, false otherwise |
| 4 | domain_hyphens | Integer | The count of appearing “–“at the domain part |
| 5 | domain_underscores | Integer | The count of appearing “_” at the domain part |
| 6 | path_hyphens | Integer | The count of appearing “–“at the path part |
| 7 | path_underscores | Integer | The count of appearing “_” at the path part |
| 8 | Slashes | Integer | The count of appearing “/” |
| 9 | full_stops | Integer | The count of appearing “.” |
| 10 | num_subdomains | Integer | The count of subdomains, in general this column equlas to full_stops +1 |
| 11 | domain_tokens | T ext | Domain text only without digits or symbols |
| 12 | path_tokens | Text | Path text only without digits or symbols |
| # | Parameter | Value |
|---|---|---|
| 1 | Input layer with data dimension d | 768 |
| 2 | One-dimension CNN network | filters = 256, kernel size = 2, activation function is relu, and the input vector dimension is (7681) |
| 3 | Batch normalization layer | 1 |
| 4 | One-dimension max-pooling size | 2 |
| 5 | Drop out layer around | 0.2 |
| 6 | One-dimension CNN network: | filters = 256, kernel size = 2, and activation function is relu. |
| 7 | Batch normalization layer | 1 |
| 8 | One-dimension max-pooling layer: with pool size | 2 |
| 9 | Drop out layer around | 0.4 |
| 10 | One-dimension CNN network: | filters = 256, kernel size = 2, and activation function is relu. |
| 11 | Batch normalization layer | 1 |
| 12 | One-dimension max-pooling layer: with pool size | 2 |
| 13 | Drop out layer around | 0.4 |
| 14 | Flatten layer | 1 |
| 15 | Dropout layer | 1 |
| 16 | Dense layer neurons and relu as activation function | 128 neurons |
| 17 | Output layer: one neuron and activation function are relu | 1 |
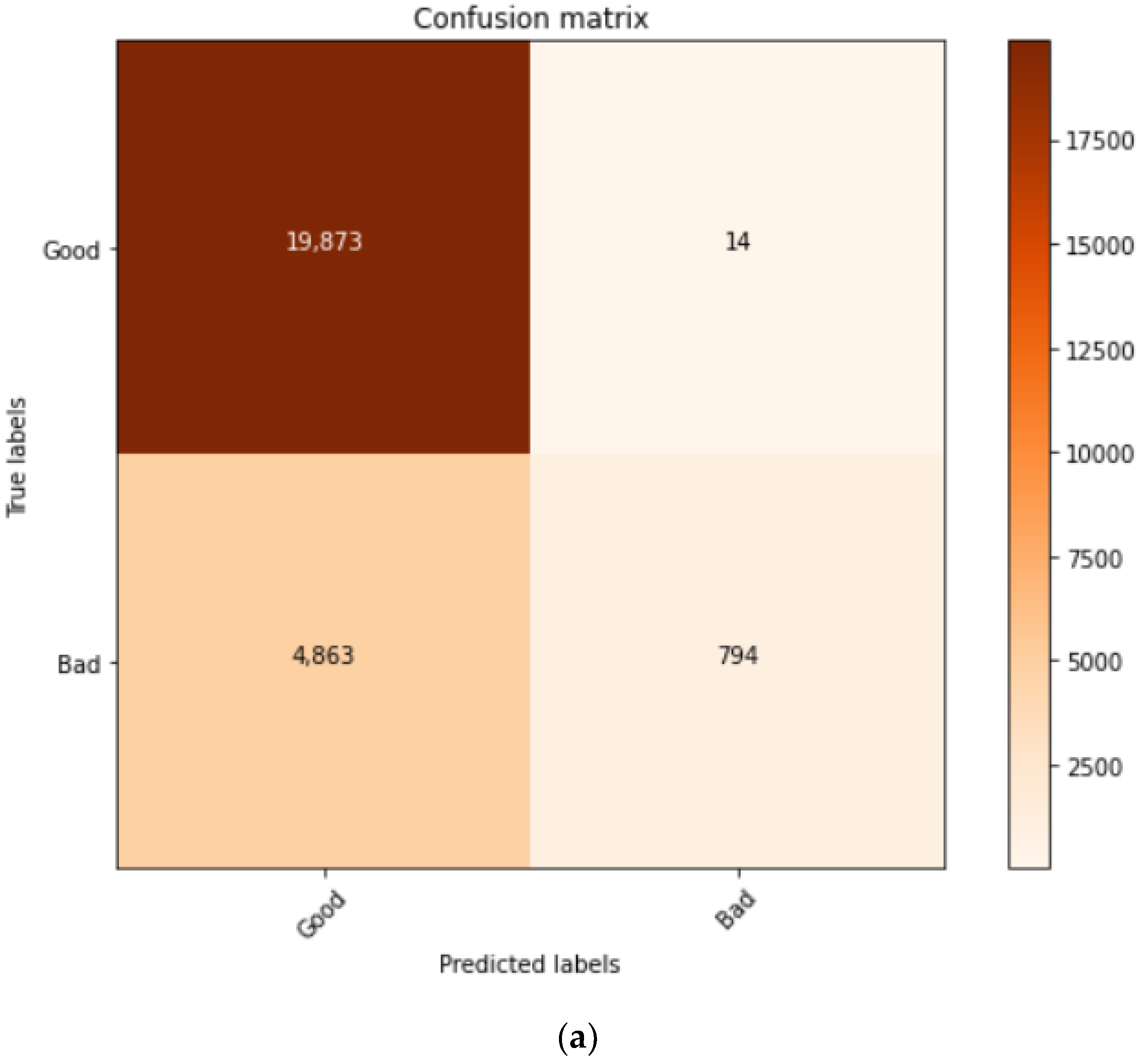
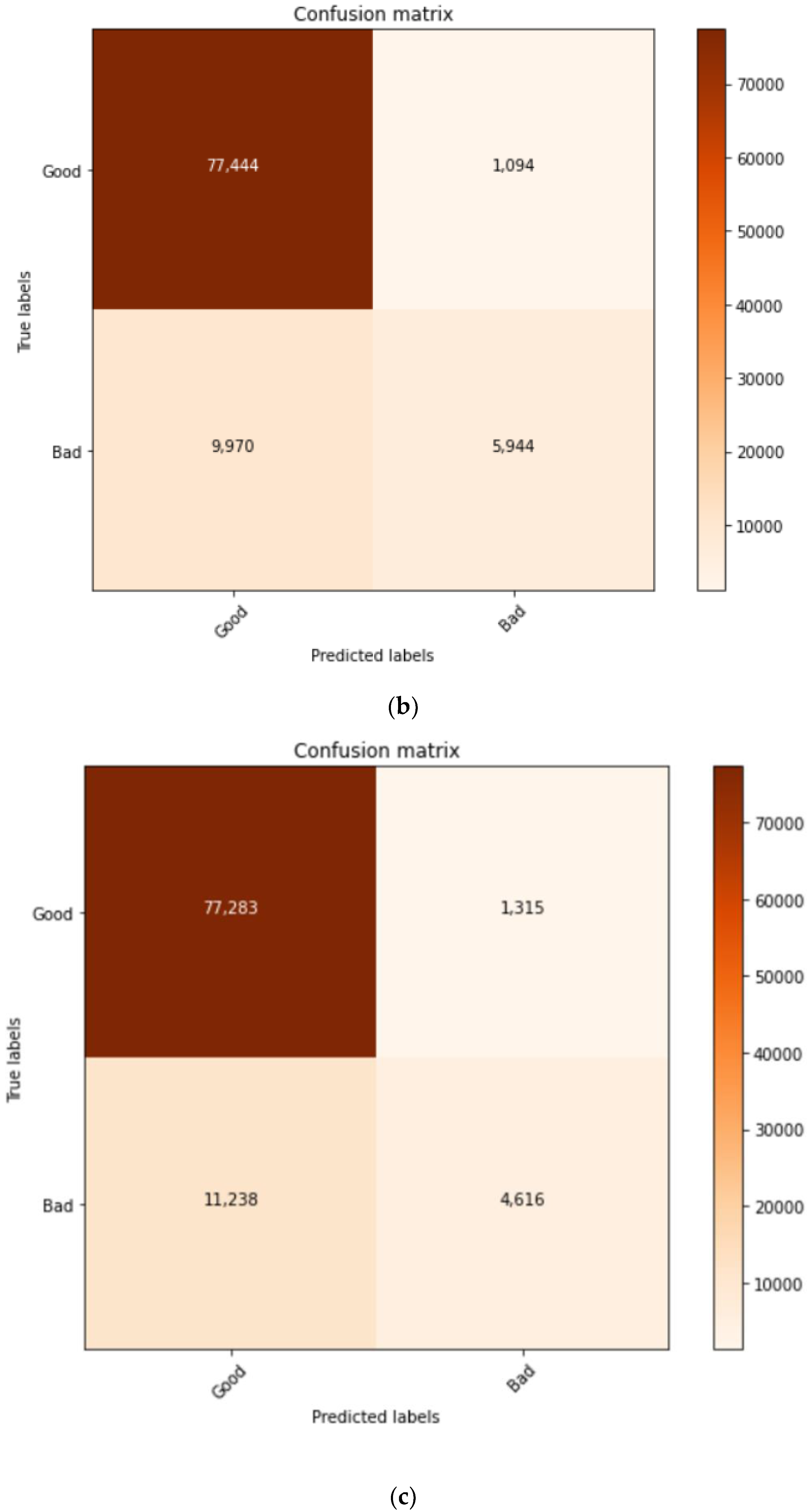
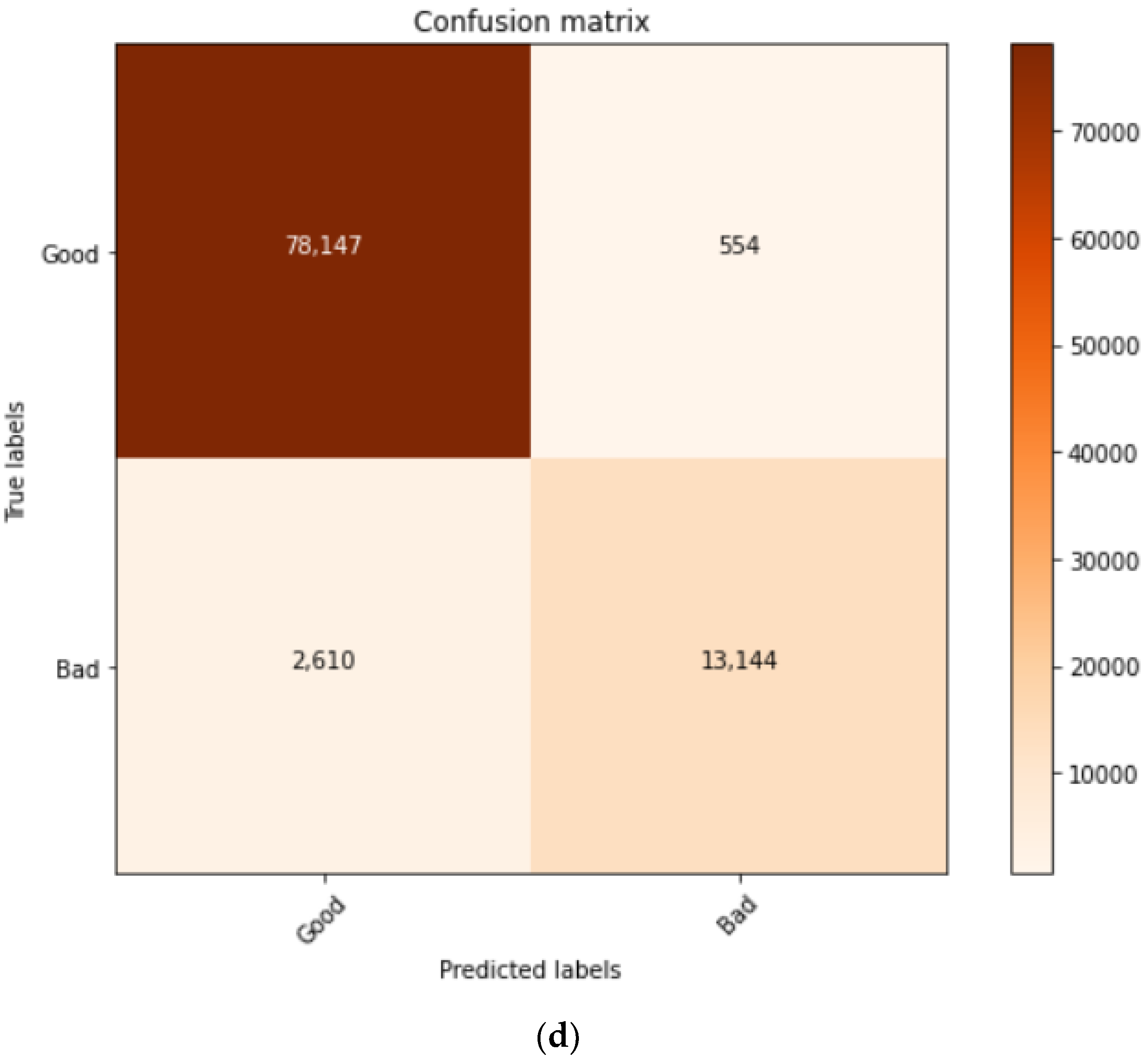
| Model | TP | FP | TN | FN | Accuracy | F1-Score | Precision |
|---|---|---|---|---|---|---|---|
| C1 | 794 | 14 | 19,873 | 4863 | 81.36% | 57.58% | 81.36% |
| C2.a | 5944 | 1094 | 77,444 | 9970 | 88.28% | 72.56% | 88.28% |
| C2.b | 4616 | 1315 | 77,283 | 11,238 | 86.70% | 67.43% | 86.70% |
| The proposed method | 13,144 | 554 | 78,147 | 2610 | 96.66% | 93.63% | 96.66% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elsadig, M.; Ibrahim, A.O.; Basheer, S.; Alohali, M.A.; Alshunaifi, S.; Alqahtani, H.; Alharbi, N.; Nagmeldin, W. Intelligent Deep Machine Learning Cyber Phishing URL Detection Based on BERT Features Extraction. Electronics 2022, 11, 3647. https://doi.org/10.3390/electronics11223647
Elsadig M, Ibrahim AO, Basheer S, Alohali MA, Alshunaifi S, Alqahtani H, Alharbi N, Nagmeldin W. Intelligent Deep Machine Learning Cyber Phishing URL Detection Based on BERT Features Extraction. Electronics. 2022; 11(22):3647. https://doi.org/10.3390/electronics11223647
Chicago/Turabian StyleElsadig, Muna, Ashraf Osman Ibrahim, Shakila Basheer, Manal Abdullah Alohali, Sara Alshunaifi, Haya Alqahtani, Nihal Alharbi, and Wamda Nagmeldin. 2022. "Intelligent Deep Machine Learning Cyber Phishing URL Detection Based on BERT Features Extraction" Electronics 11, no. 22: 3647. https://doi.org/10.3390/electronics11223647
APA StyleElsadig, M., Ibrahim, A. O., Basheer, S., Alohali, M. A., Alshunaifi, S., Alqahtani, H., Alharbi, N., & Nagmeldin, W. (2022). Intelligent Deep Machine Learning Cyber Phishing URL Detection Based on BERT Features Extraction. Electronics, 11(22), 3647. https://doi.org/10.3390/electronics11223647