
Parity Check Based Fault Detection against Timing Fault Injection Attacks


Abstract
:1. Introduction
- We propose two efficient detection approaches against timing FIAs based on the parity code check. The two approaches realize the idea of fine-grained parity check with low overhead in two ways and apply the parity check on the pipelined and iterative circuits. The two approaches provide designers with different design capabilities with alternative countermeasures.
- We develop the implementation flow of the proposed approaches, which can be integrated with the existing IC design flow, enabling security-driven hardware design flow.
- We design parity check blocks for basic operations involved in various encryption algorithms. In this way, the proposed methods apply to multiple widely used cryptography ICs.
- We evaluate the proposed approaches on RC5, AES, and DES encryption implementations. Compared with the word parity check, the results show that the mixed-grained approach increases the fault coverage rate by up to while consuming more resources; the word recombination approach increases the fault coverage rate by up to while introducing up to resource usage.
2. Background
2.1. Principle of Parity Code-Based Detection
2.2. Basic Operations in RC5, DES and AES Encryption Algorithms
| Algorithm 1: RC5 algorithm |
Input 64-bit plaintext, which is divided into 32-bit words A, B, and key. Output: ciphertext 1: A, B = Permutation-P(plaintext) 2: A=A+key [0] 3: B=B+key [1] 4: for i =1 to 12 5: A = ((A xor B) B)+key[2i] 6: B = ((B xor A)A)+key[2i+1] 7: ciphertext = {A, B}. |
| Algorithm 2: DES algorithm |
Input 64-bit plaintext divided into 32-bit L and R, and key. Output: ciphertext Begin 1: for i = 1 to 16 2: = R; 3: = L xor function-f (R, key); 4: ciphertext = {L, R}; End Function-f(R, key) 5: E = Expansion-E ( R ) 6: Address_Sbox = E xor key 7: S = Sbox (Address_Sbox) 8: P = Permutation-P (S). |
| Algorithm 3: AES-128 algorithm |
Input: 128-bit Plaintext, which is presented as the state matrix, and key. Output: ciphertext Begin: 1: state = Plaintext 2: AddRoundKey (state, key) 3: for round=1 to 9 4: state=Subbytes(state) 5: state=shiftRows(state) 6: state=MixColumns(state) 7: state=AddRoundKey(state, key[round]). End Final round Begin: 8: state=Subbyte(state) 9: state=shiftRows(state) 10: state=AddRoundKey(state, key[round]) 11: ciphertext=state. End |
3. Threat Model
4. Proposed Approaches
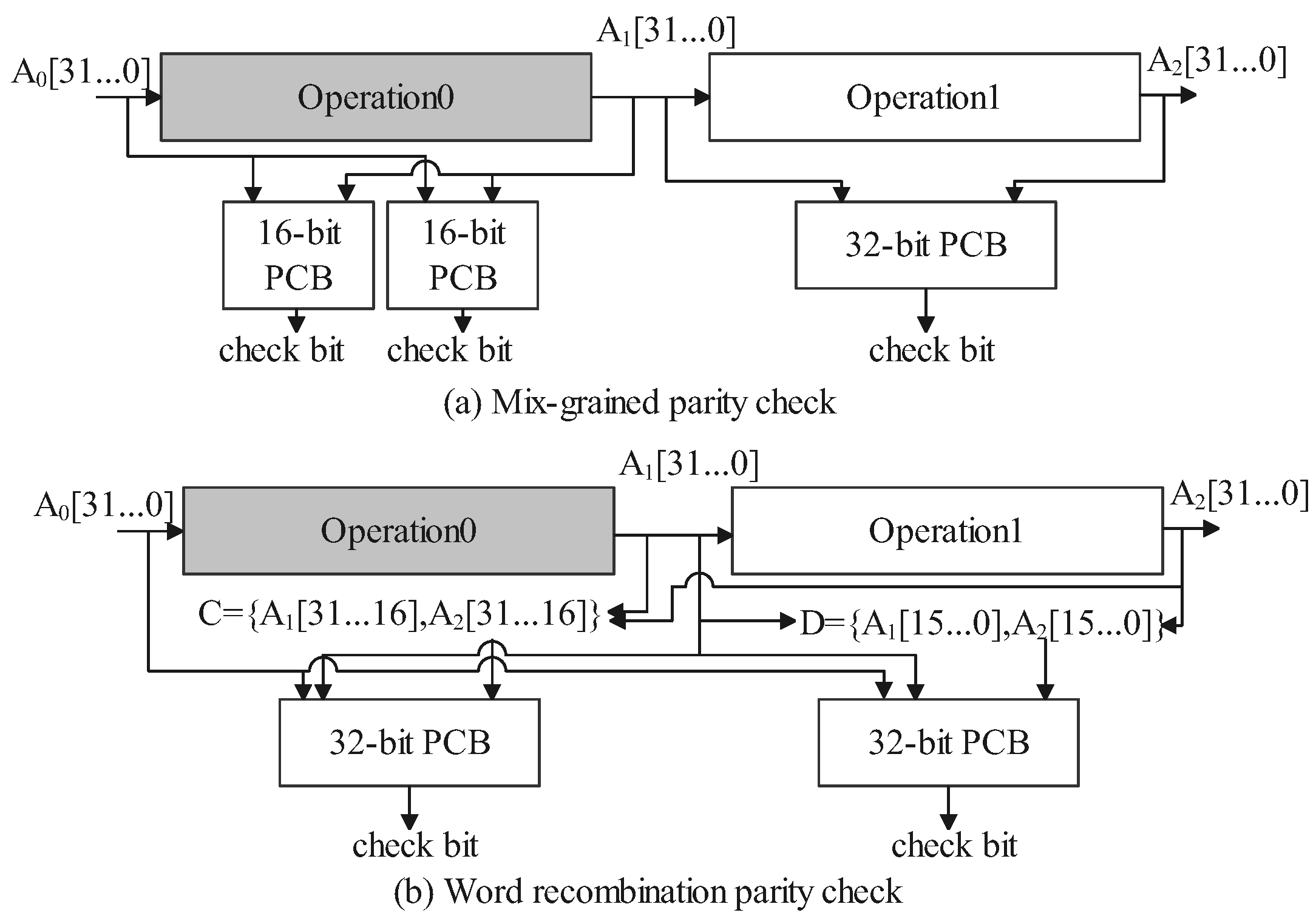
4.1. Mixed-Grained Parity Check
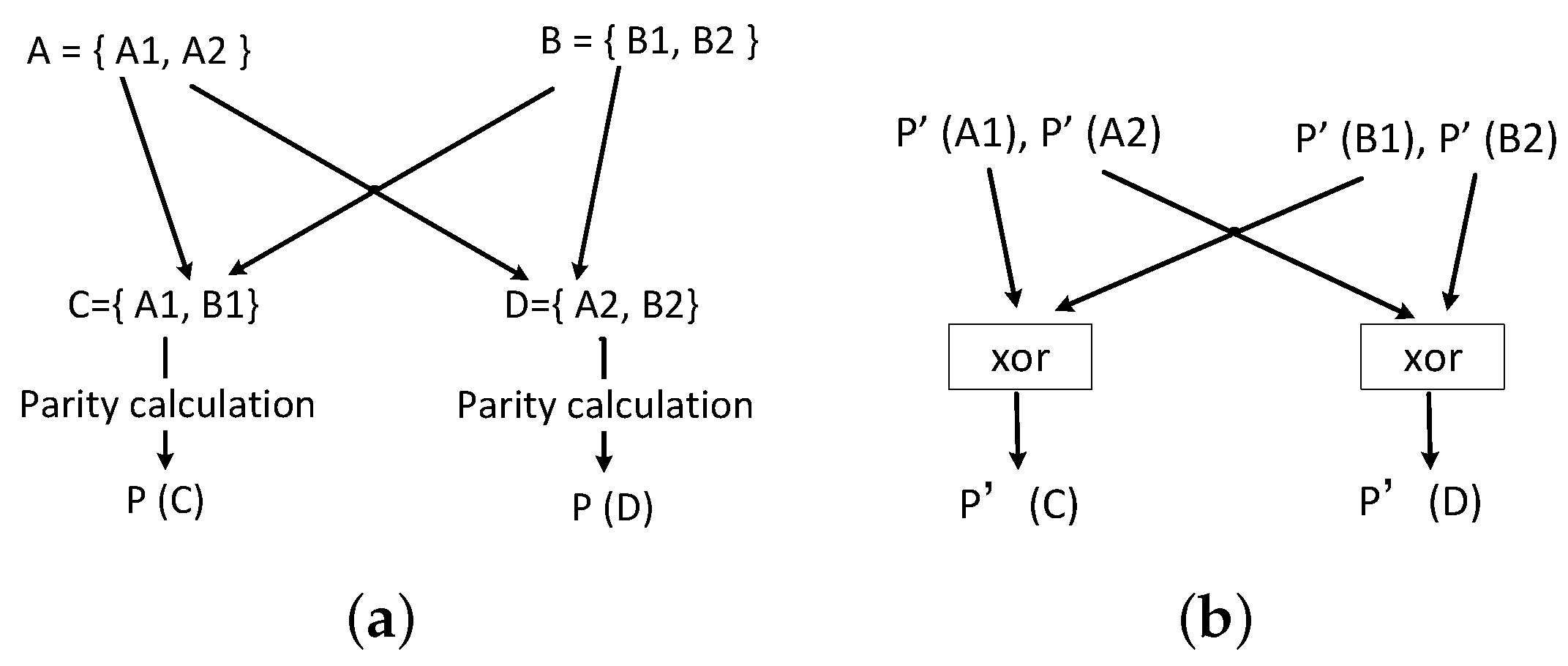
4.2. Word Recombination Parity Check
5. Parity Prediction of Basic Operations
5.1. Conventional Arithmetic Addition
5.2. Modulo 2 Addition
5.3. Logical Shift
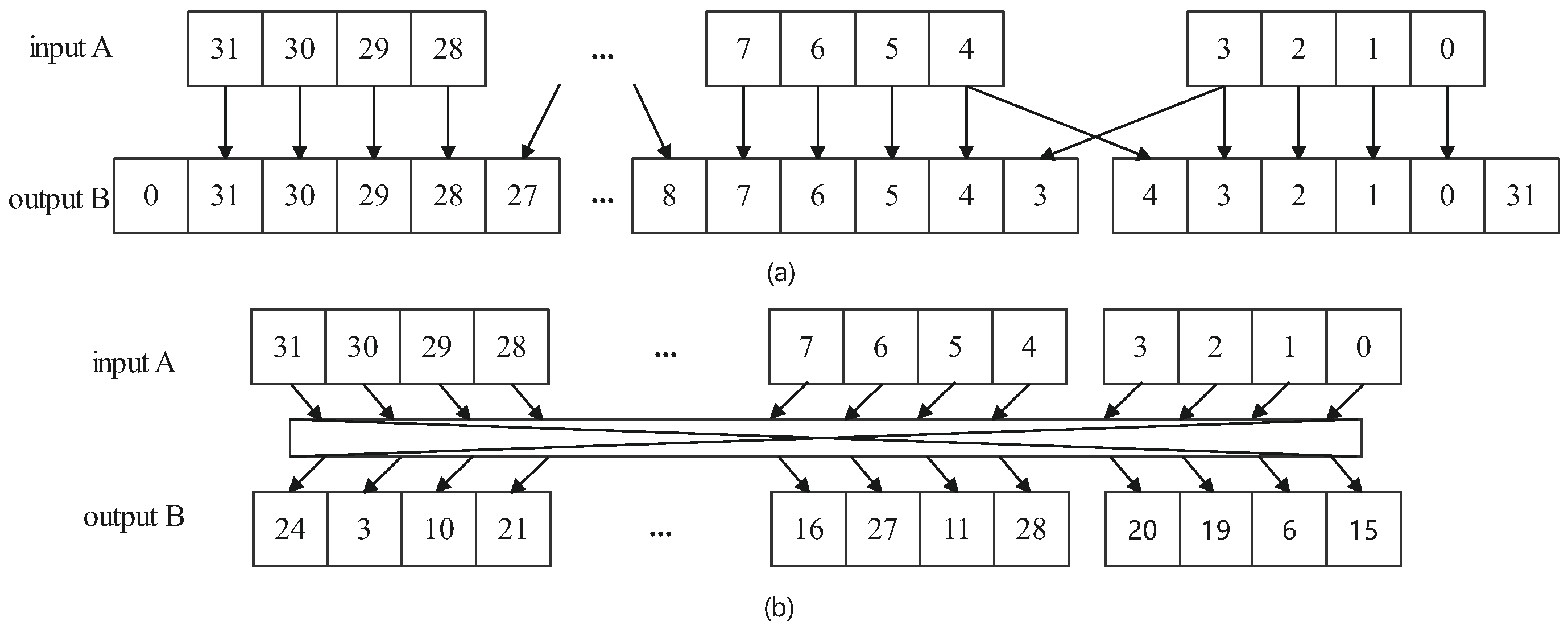
5.4. Permutation Operation
5.5. Substitution Box
6. Design Flow
6.1. Critical Parts Specification
6.2. Parity Check Scheme Determination
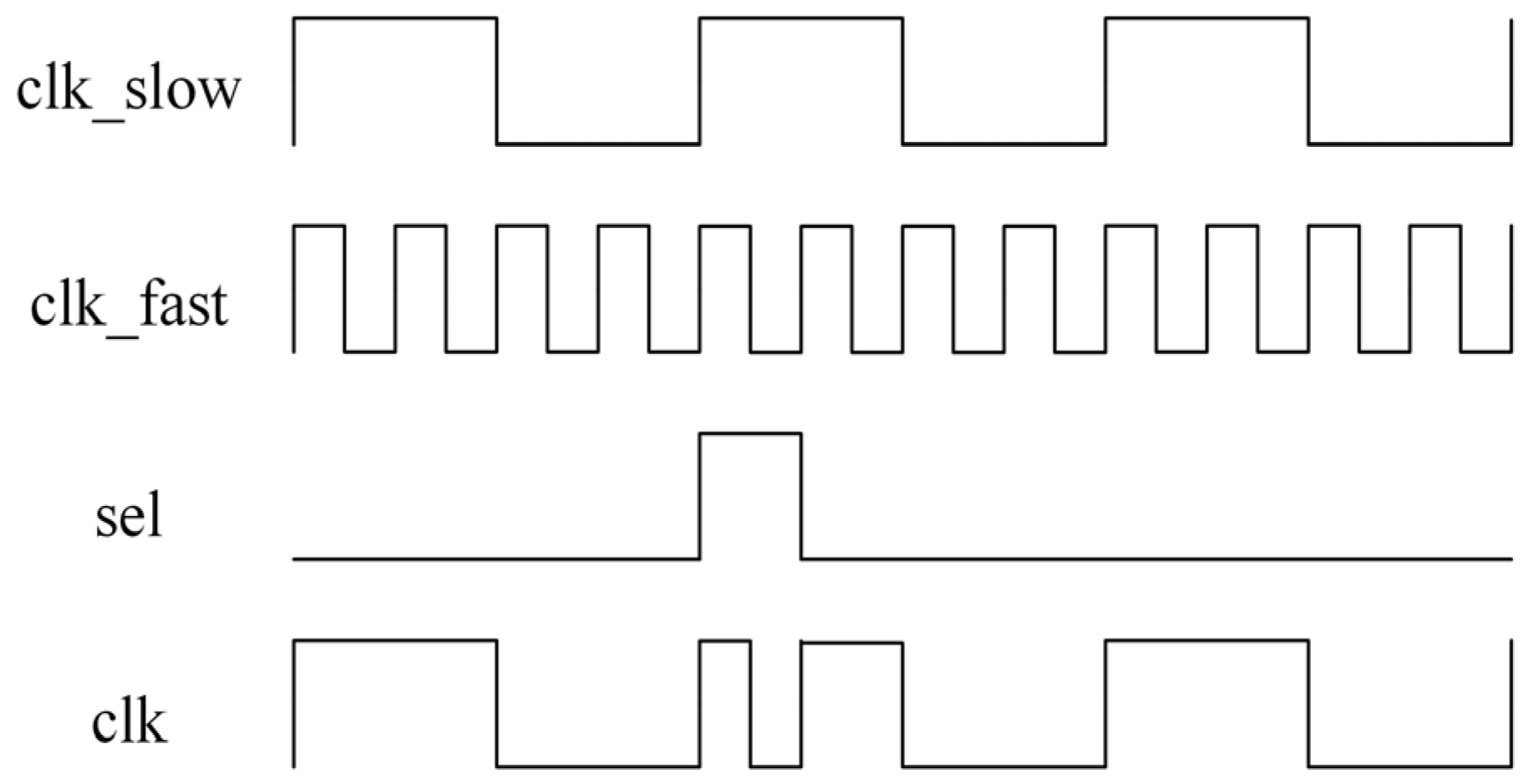
6.3. Circuit Implementation
6.4. Evaluation
7. Experiment Results
7.1. Experiment Setup
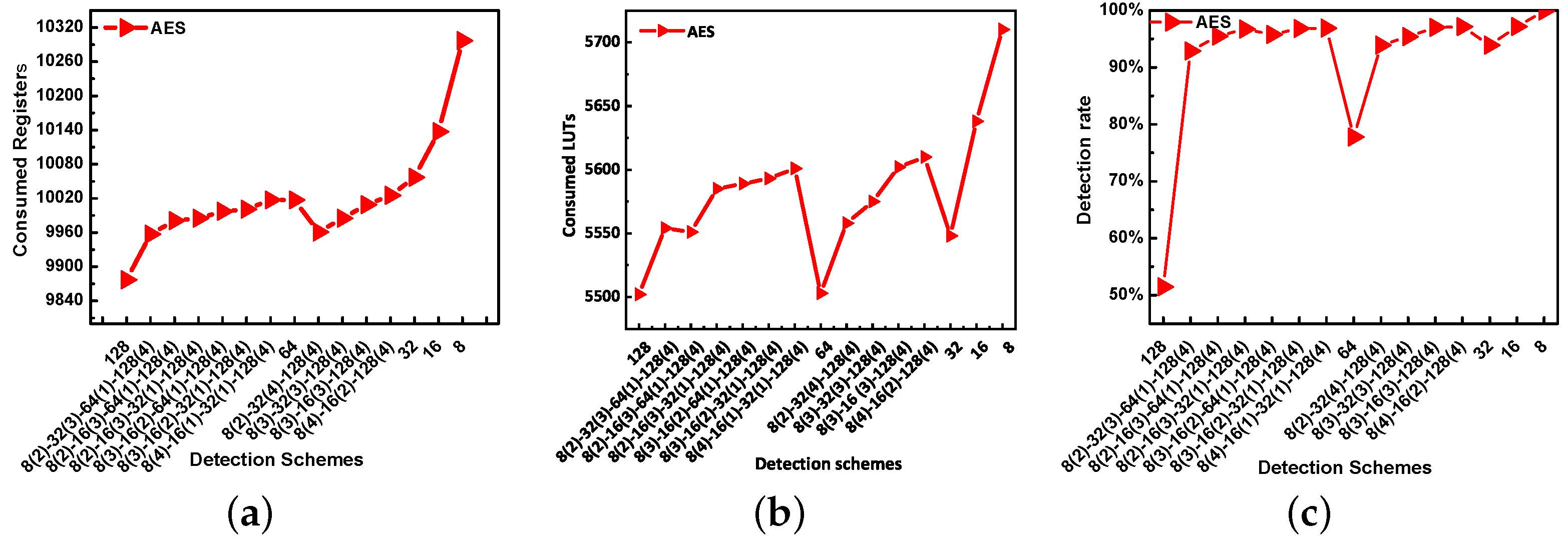
7.2. Results
7.2.1. Evaluation of Mixed-Grained Parity Check
7.2.2. Evaluation of Word Recombination Parity Check
8. Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Y.; Pal, A.; Abuadbba, S.; Pokhrel, S.R.; Nepal, S.; Janicke, H. Towards IoT Security Automation and Orchestration. In Proceedings of the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; pp. 55–63. [Google Scholar] [CrossRef]
- Moini, S.; Tian, S.; Holcomb, D.; Szefer, J.; Tessier, R. Power Side-Channel Attacks on BNN Accelerators in Remote FPGAs. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 357–370. [Google Scholar] [CrossRef]
- Ghosh, A.; Nath, M.; Das, D.; Ghosh, S.; Sen, S. Electromagnetic Analysis of Integrated On-Chip Sensing Loop for Side-Channel and Fault-Injection Attack Detection. IEEE Microw. Wirel. Components Lett. 2022, 32, 784–787. [Google Scholar] [CrossRef]
- Yoshikawa, H.; Kaminaga, M.; Shikoda, A.; Suzuki, T. Round addition DFA for microcontroller implemented the triple DES. In Proceedings of the 2013 IEEE 2nd Global Conference on Consumer Electronics (GCCE), Tokyo, Japan, 1–4 October 2013; pp. 538–539. [Google Scholar] [CrossRef]
- Boneh, D.; DeMillo, R.A.; Lipton, R.J. On the Importance of Checking Cryptographic Protocols for Faults. In Proceedings of the Advances in Cryptology—EUROCRYPT ’97, Konstanz, Germany, 11–15 May 1997; pp. 37–51. [Google Scholar]
- Zhang, J.; Ji, X.; Wang, J.; Li, J.; Wang, N. A Differential Fault Attack on Security Vehicle System Applied SIMON Block Cipher. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Macau, China, 8–12 October 2022; pp. 1–12. [Google Scholar] [CrossRef]
- Rodriguez, J.; Baldomero, A.; Montilla, V.; Mujal, J. LLFI: Lateral Laser Fault Injection Attack. In Proceedings of the 2019 Workshop on Fault Diagnosis and Tolerance in Cryptography (FDTC), Atlanta, GA, USA, 24 August 2019; pp. 41–47. [Google Scholar] [CrossRef]
- Ning, B.; Liu, Q. Modeling and Efficiency Analysis of Clock Glitch Fault Injection Attack. In Proceedings of the 2018 Asian Hardware Oriented Security and Trust Symposium (AsianHOST), Hong Kong, China, 17–18 December 2018; pp. 13–18. [Google Scholar] [CrossRef]
- Bittner, O.; Krachenfels, T.; Galauner, A.; Seifert, J.P. The Forgotten Threat of Voltage Glitching: A Case Study on Nvidia Tegra X2 SoCs. In Proceedings of the 2021 Workshop on Fault Detection and Tolerance in Cryptography (FDTC), Milan, Italy, 17 September 2021; pp. 86–97. [Google Scholar] [CrossRef]
- Nishiyama, H.; Fujimoto, D.; Kim, Y.; Sone, H.; Hayashi, Y.I. IEMI Fault Injection Method Using Continuous Sinusoidal Wave with Controlled Frequency, Amplitude, and Phase. In Proceedings of the 2021 13th International Workshop on the Electromagnetic Compatibility of Integrated Circuits (EMC Compo), Bruges, Belgium, 18–11 March 2022; pp. 97–101. [Google Scholar] [CrossRef]
- Bedoui, M.; Mestiri, H.; Bouallegue, B.; Machhout, M. A reliable fault detection scheme for the AES hardware implementation. In Proceedings of the 2016 International Symposium on Signal, Image, Video and Communications (ISIVC), Tunis, Tunisia, 21–23 November 2016; pp. 47–52. [Google Scholar] [CrossRef]
- Ebrahimabadi, M.; Mehjabin, S.S.; Viera, R.; Guilley, S.; Danger, J.L.; Dutertre, J.M.; Karimi, N. Detecting Laser Fault Injection Attacks via Time-to-Digital Converter Sensors. In Proceedings of the 2022 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), San Jose, CA, USA, 1–4 May 2022; pp. 97–100. [Google Scholar] [CrossRef]
- Bertoni, G.; Breveglieri, L.; Koren, I.; Maistri, P.; Piuri, V. A parity code based fault detection for an implementation of the Advanced Encryption Standard. In Proceedings of the 17th IEEE International Symposium on Defect and Fault Tolerance in VLSI Systems, DFT 2002, Vancouver, BC, Canada, 6–8 November 2002; pp. 51–59. [Google Scholar] [CrossRef]
- Bertoni, G.; Breveglieri, L.; Koren, I.; Maistri, P.; Piuri, V. Concurrent fault detection in a hardware implementation of the RC5 encryption algorithm. In Proceedings of the IEEE International Conference on Application-Specific Systems, Architectures, and Processors, ASAP 2003, The Hague, The Netherlands, 24–26 June 2003; pp. 423–432. [Google Scholar] [CrossRef]
- Wen, L.; Jiang, W.; Jiang, K.; Zhang, X.; Pan, X.; Zhou, K. Detecting Fault Injection Attacks on Embedded Real-Time Applications: A System-Level Perspective. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, New York, NY, USA, 24–26 August 2015; pp. 700–705. [Google Scholar] [CrossRef]
- Curiger, A.; Bonnenberg, H.; Zimmermann, R.; Felber, N.; Kaeslin, H.; Fichtner, W. VINCI: VLSI implementation of the new secret-key block cipher IDEA. In Proceedings of the IEEE Custom Integrated Circuits Conference—CICC ’93, San Diego, CA, USA, 9–12 May 1993; pp. 15.5.1–15.5.4. [Google Scholar] [CrossRef]
- Smekal, D.; Hajny, J.; Martinasek, Z. Hardware-Accelerated Twofish Core for FPGA. In Proceedings of the 2018 41st International Conference on Telecommunications and Signal Processing (TSP), Athens, Greece, 4–6 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Deshpande, C.; Yuce, B.; Ghalaty, N.F.; Ganta, D.; Schaumont, P.; Nazhandali, L. A Configurable and Lightweight Timing Monitor for Fault Attack Detection. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 461–466. [Google Scholar] [CrossRef]
- Agoyan, M.; Dutertre, J.M.; Naccache, D.; Robisson, B.; Tria, A. When Clocks Fail: On Critical Paths and Clock Faults. In Proceedings of the Smart Card Research and Advanced Application, Passau, Germany, 14–16 April 2010; pp. 182–193. [Google Scholar]
- Ghalaty, N.F.; Yuce, B.; Taha, M.; Schaumont, P. Differential Fault Intensity Analysis. In Proceedings of the 2014 Workshop on Fault Diagnosis and Tolerance in Cryptography, Washington, DC, USA, 23 September 2014; pp. 49–58. [Google Scholar] [CrossRef]
- Sakiyama, K.; Li, Y.; Iwamoto, M.; Ohta, K. Information-Theoretic Approach to Optimal Differential Fault Analysis. IEEE Trans. Inf. Forensics Secur. 2012, 7, 109–120. [Google Scholar] [CrossRef]
- Patranabis, S.; Chakraborty, A.; Mukhopadhyay, D.; Chakrabarti, P.P. Fault Space Transformation: A Generic Approach to Counter Differential Fault Analysis and Differential Fault Intensity Analysis on AES-Like Block Ciphers. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1092–1102. [Google Scholar] [CrossRef]
- Wei, L.; Zhi, T.; Dawu, G.; Li, S.; Bo, Q.; Zhiqiang, L.; Ya, L. An effective differential fault analysis on the Serpent cryptosystem in the Internet of Things. China Commun. 2014, 11, 129–139. [Google Scholar] [CrossRef]
- Pogue, T.E.; Nicolici, N. Incremental Fault Analysis: Relaxing the Fault Model of Differential Fault Attacks. IEEE Trans. Very Large Scale Integr. Syst. 2020, 28, 750–763. [Google Scholar] [CrossRef]
- Yao, Y.; Kiaei, P.; Singh, R.; Tajik, S.; Schaumont, P. Programmable RO (PRO): A Multipurpose Countermeasure against Side-channel and Fault Injection Attack. arXiv 2021, arXiv:2106.13784. [Google Scholar]
- Zhang, M.; Liu, Q. A Digital and Lightweight Delay-Based Detector against Fault Injection Attacks. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 21–25 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Benevenuti, F.; Kastensmidt, F.L. Evaluation of fault attack detection on SRAM-based FPGAs. In Proceedings of the 2017 18th IEEE Latin American Test Symposium (LATS), Bogotá, Colombia, 13–15 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chu, J.; Benaissa, M. Error detecting AES using polynomial residue number systems. Microprocess. Microsyst. 2013, 37, 228–234. [Google Scholar] [CrossRef]
- Mestiri, H.; Benhadjyoussef, N.; Machhout, M.; Tourki, R. High performance and reliable fault detection scheme for the advanced encryption standard. Int. Rev. Comput. Softw. 2013, 8, 730–746. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Granularity m | Uniform 32-bit | Uniform 16-bit | Mixed 16/32-bit | 2 Words Recombination |
|---|---|---|---|---|
| Fault coverage (%) | 50 | 75 | 50 | 75 |
| HW resource | 2 PCB | 4 PCBs | 3 PCBs | 2 PCBs |
| 32-bit | 16-bit | 8-bit | 4-bit | |
|---|---|---|---|---|
| (%) | 50 | 75 | 93.75 | 99.55 |
| Blocks | #XOR | #Reg | |
|---|---|---|---|
| Prediction | Addition | ||
| Modulo 2 addition | |||
| Logical shift | 0, if ;, if ; | ||
| Permutation | |||
| AES S-box | 3, if ; 1, if ; 0, others | , if ; , others | |
| Calculation+Comparison | 32 | ||
| Implementation | Reg | Power (W) | WNS (ns) | Power (W) | WNS (ns) | Reg | |
|---|---|---|---|---|---|---|---|
| AES | No detection | 9657 | 0.686 | 6.368 | - | - | - |
| 8(3)-16 (3)-128(4) | 10009 | 0.708 | 6.228 | 0.022 | 0.14 | 352 | |
| Pipelined DES | No detection | 8574 | 0.452 | 7.065 | - | - | - |
| 4(9)-8(5)-16(2) | 8920 | 0.63 | 6.932 | 0.178 | 0.133 | 346 | |
| RC5 | No detection | 4351 | 0.57 | 3.317 | - | - | - |
| 4(2)-8(1)-16(1)-32(8) | 4524 | 0.668 | 3.192 | 0.098 | 0.125 | 174 |
| Mixed Scheme | FC | Reg | LUT | ES | Power (W) | WNS (ns) |
|---|---|---|---|---|---|---|
| No detection | 0 | 56 | 92 | 0 | 0.3 | 4.958 |
| 32(4) | 53.9% | 66 | 135 | 0.817 | 0.33 | 4.798 |
| 4(4) | 99.3% | 94 | 153 | 1.056 | 0.331 | 4.68 |
| 4(1)-32(3) | 98.6% | 73 | 140 | 1.351 | 0.33 | 4.7553 |
| Circuit | Num. of Words | FC | Reg | ES | Power (W) | WNS (ns) |
|---|---|---|---|---|---|---|
| RC5 | 1 | 51.92% | 4427 | 0.012 | 0.61 | 3.252 |
| 2 | 87.48% | 4432 | 0.019 | 0.63 | 3.25 | |
| 4 | 94.83% | 4443 | 0.021 | 0.68 | 3.174 | |
| 8 | 98.21% | 4462 | 0.022 | 0.705 | 3.117 | |
| Pipelined DES | 1 | 53.69% | 8837 | 0.006 | 0.483 | 6.982 |
| 2 | 78.54% | 8841 | 0.009 | 0.505 | 6.978 | |
| 4 | 89.57% | 8857 | 0.010 | 0.527 | 6.953 | |
| 8 | 98.19% | 8889 | 0.011 | 0.54 | 6.942 | |
| AES | 1 | 51.44% | 9877 | 0.0052 | 0.697 | 6.368 |
| 2 | 75.11% | 9965 | 0.0075 | 0.743 | 6.302 | |
| 4 | 90.83% | 9997 | 0.0091 | 0.78 | 6.221 | |
| 8 | 98.60% | 10109 | 0.0098 | 0.824 | 6.115 |
| Num. of Words | FC | Reg | ES | Power (W) | WNS (ns) |
|---|---|---|---|---|---|
| 1 | 53.9% | 66 | 0.817 | 0.33 | 4.798 |
| 2 | 74.2% | 74 | 1.003 | 0.332 | 4.723 |
| 4 | 84.7% | 80 | 1.059 | 0.339 | 4.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Li , H.; Wang, P.; Liu, Q. Parity Check Based Fault Detection against Timing Fault Injection Attacks. Electronics 2022, 11, 4082. https://doi.org/10.3390/electronics11244082
Zhang M, Li H, Wang P, Liu Q. Parity Check Based Fault Detection against Timing Fault Injection Attacks. Electronics. 2022; 11(24):4082. https://doi.org/10.3390/electronics11244082
Chicago/Turabian StyleZhang, Maoshen, He Li , Peijing Wang, and Qiang Liu. 2022. "Parity Check Based Fault Detection against Timing Fault Injection Attacks" Electronics 11, no. 24: 4082. https://doi.org/10.3390/electronics11244082
APA StyleZhang, M., Li , H., Wang, P., & Liu, Q. (2022). Parity Check Based Fault Detection against Timing Fault Injection Attacks. Electronics, 11(24), 4082. https://doi.org/10.3390/electronics11244082