
Predictive Analysis of COVID-19 Symptoms in Social Networks through Machine Learning



Abstract
:1. Introduction
2. Methodology
2.1. Text Classification
2.2. Classification Algorithms
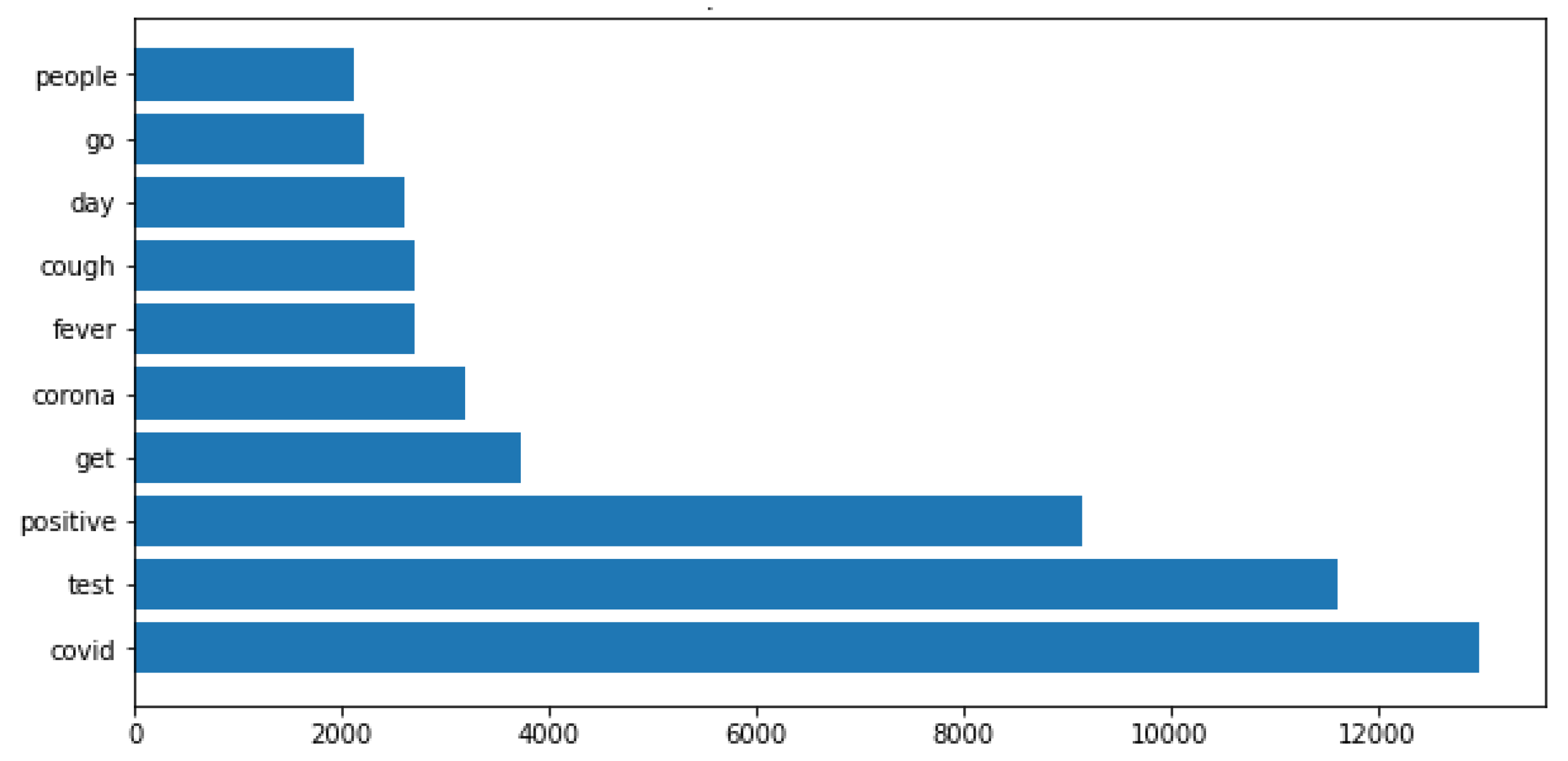
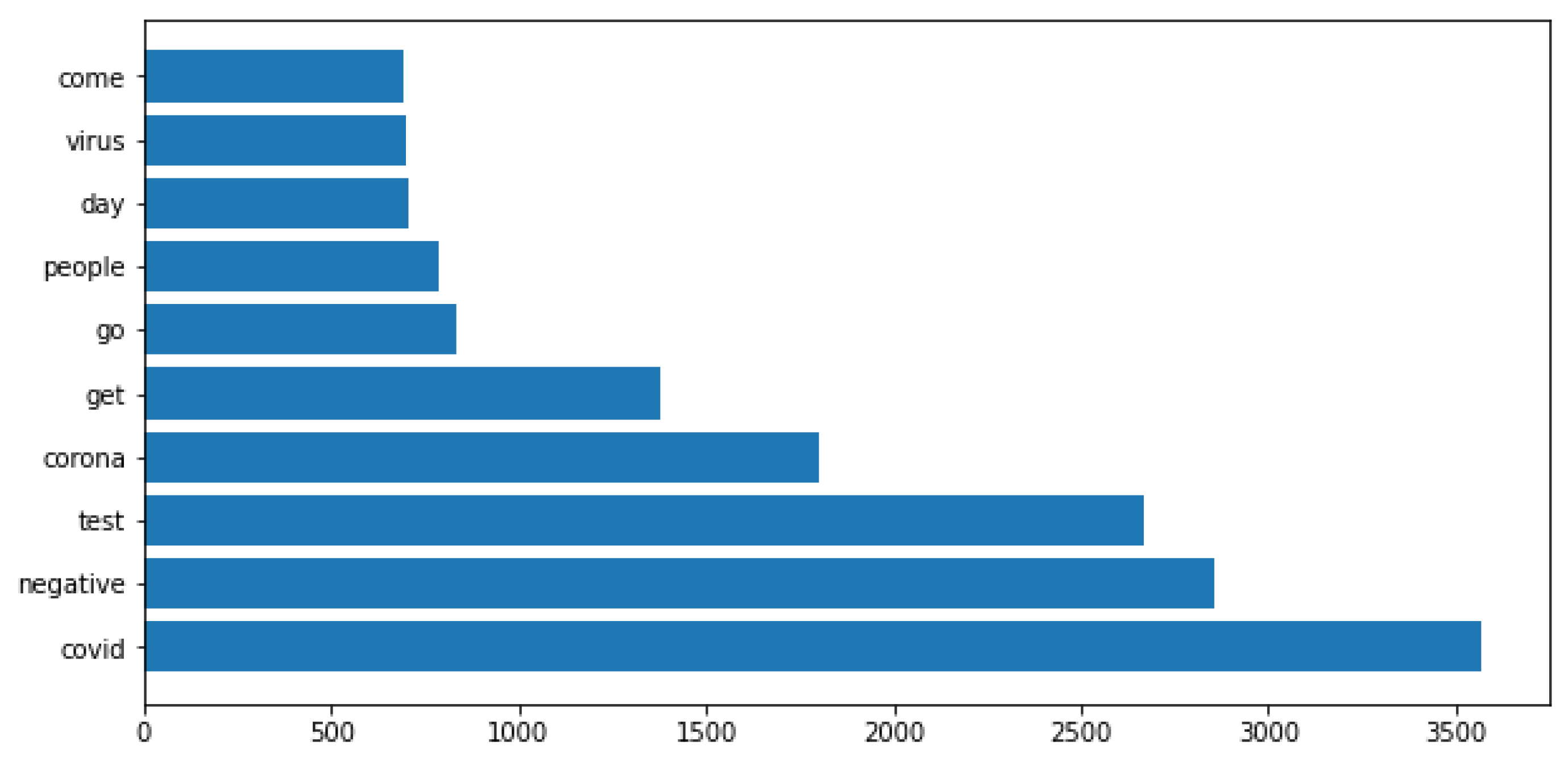
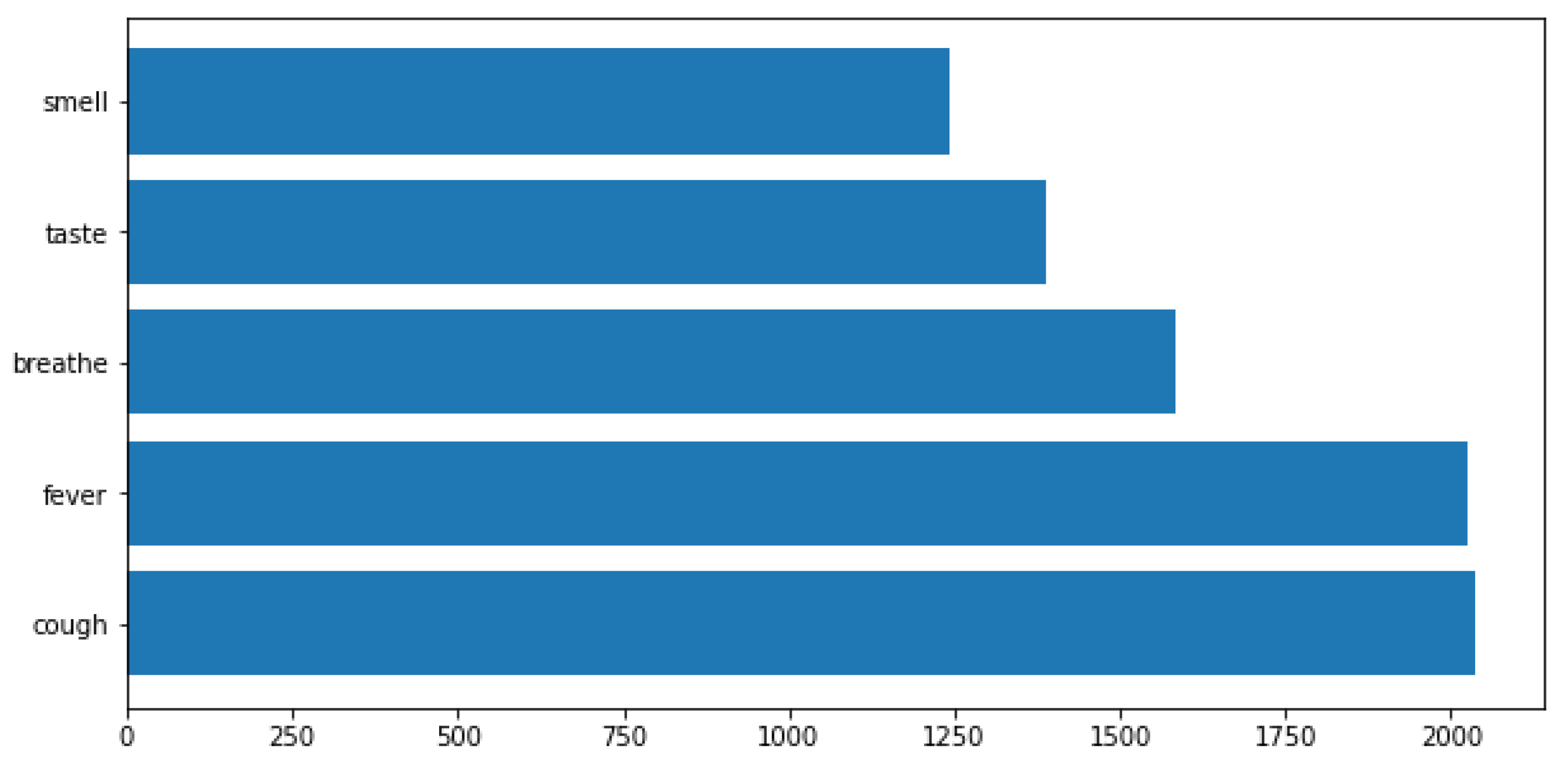
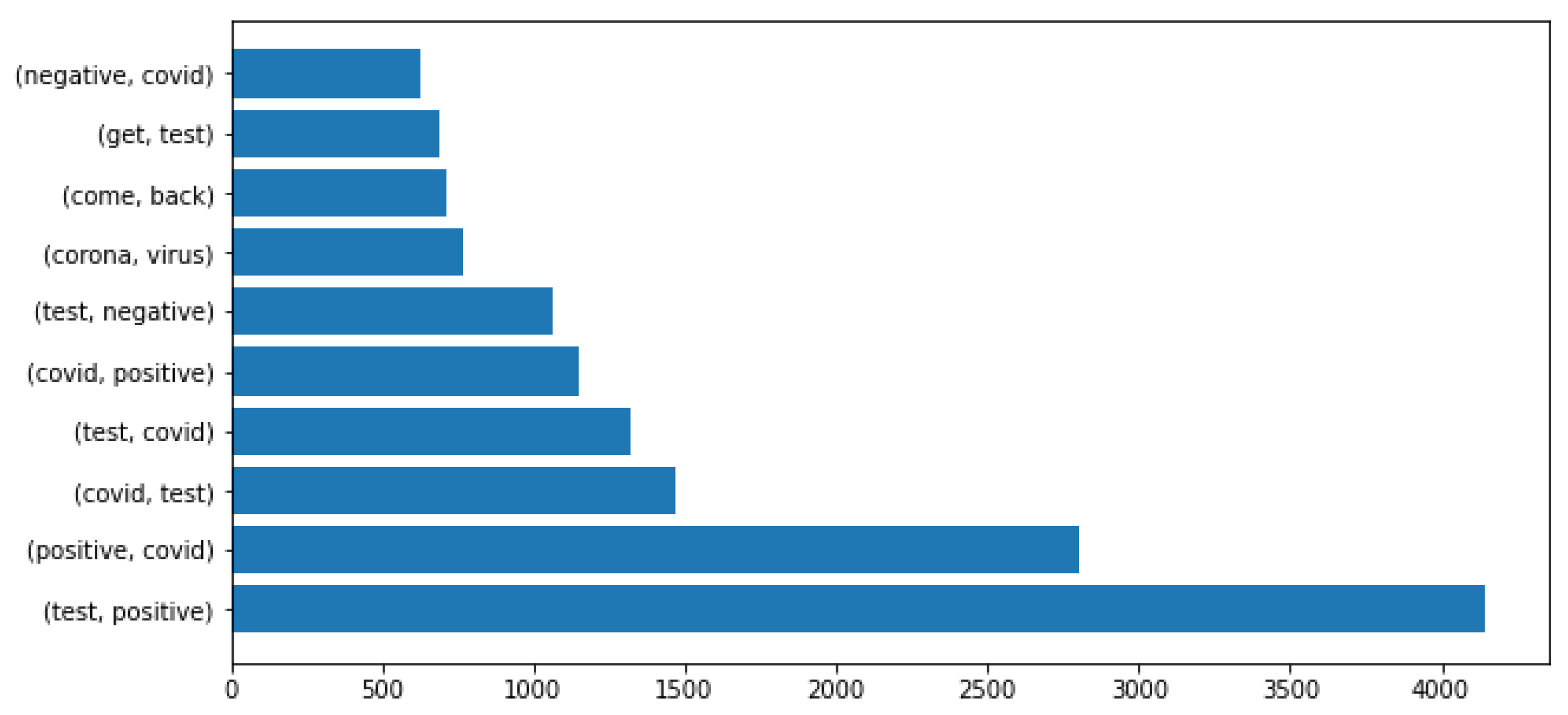
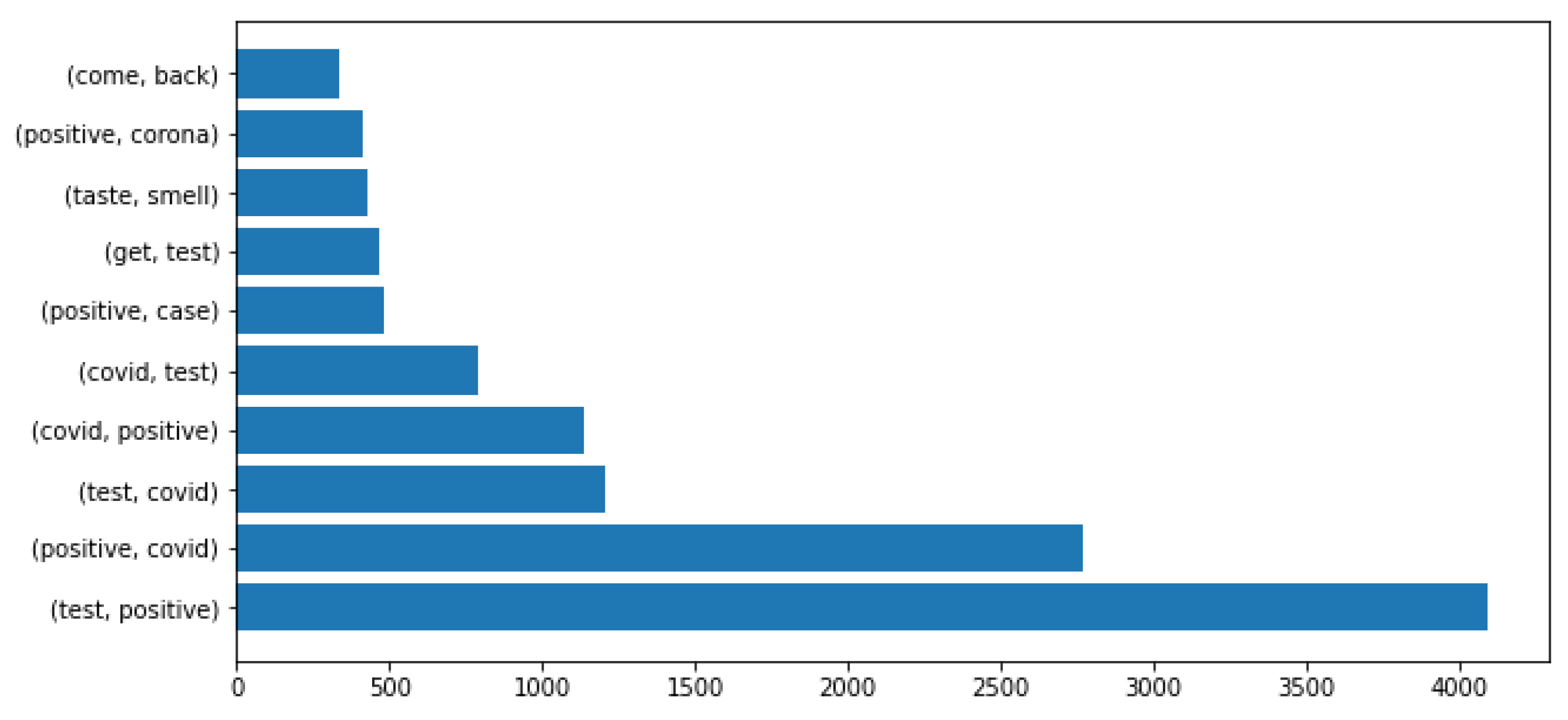
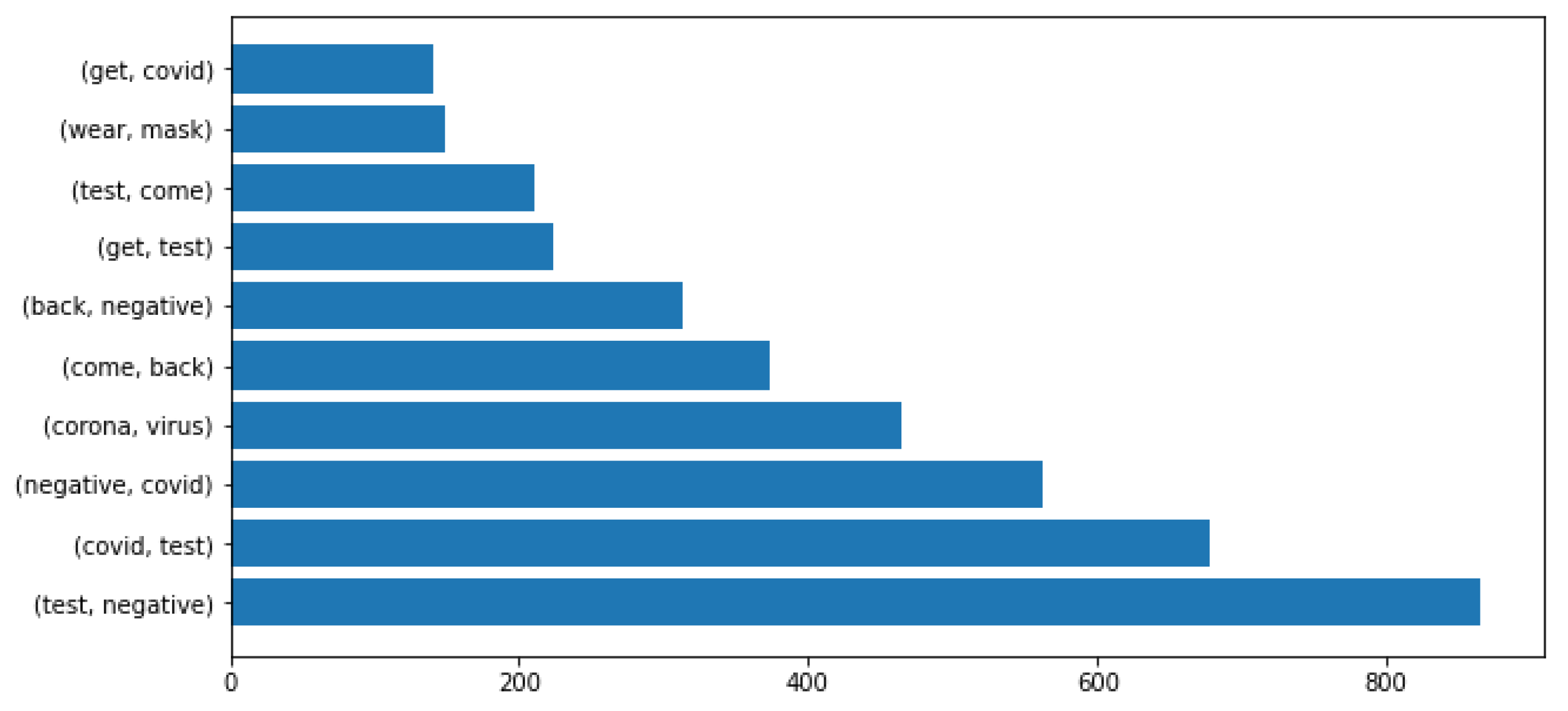
2.3. Dataset
- Emoticon removal;
- Decapitalization of the text: (Tomorrow → tomorrow);
- Removing user tagging: (@someUser);
- URL Removal: (http://www.somedomain.com, accessed on 30 December 2021);
- Extra spacing removal;
- Stop Words Removal;
- Lematization: (Plays, playing, plays → play).
2.4. Training
3. Results
- TP is when the model classifies an instance as positive and the real class is positive;
- FP is the classification of an instance as positive but its real class is negative;
- TN is the classification of an instance as negative and the real class is negative;
- FN is the classification of an instance as negative but its real class is positive.
- Precision quantifies the number of positive class predictions that actually belong to the positive class. To calculate the precision of the model, the following formula is used: .
- Recall quantifies the number of positive class predictions made out of all positive examples in the dataset. To calculate the recall of the model, the following formula is used: .
- F-Measure provides a single score that balances both the concerns of precision and recall in one number. To calculate the F-Measure of the model, the following formula is used: F-Measure .
- Accuracy presents an overall performance of the model, among all instances, how many of them were correctly classified. To calculate the accuracy of the model, it is used the following formula: .
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Garadi, M.A.; Yang, Y.C.; Lakamana, S.; Sarker, A. A Text Classification Approach for the Automatic Detection of Twitter Posts Containing Self-Reported COVID-19 Symptoms. 2020. Available online: https://openreview.net/pdf?id=xyGSIttHYO (accessed on 30 December 2021).
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Ding, W.; Wang, Q.G.; Zhang, J.X. Analysis and prediction of COVID-19 epidemic in South Africa. ISA Trans. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ding, Q.; Massey, D.; Huang, C.; Grady, C.B.; Lu, Y.; Cohen, A.; Matzner, P.; Mahajan, S.; Caraballo, C.; Kumar, N.; et al. Tracking Self-reported Symptoms and Medical Conditions on Social Media During the COVID-19 Pandemic: Infodemiological Study. JMIR Public Health Surveill. 2021, 7, e29413. [Google Scholar] [CrossRef] [PubMed]
- Hasni, S.; Faiz, S. Word embeddings and deep learning for location prediction: Tracking Coronavirus from British and American tweets. Soc. Netw. Anal. Min. 2021, 11, 66. [Google Scholar] [CrossRef]
- Marengo, D.; Montag, C.; Sindermann, C.; Elhai, J.D.; Settanni, M. Examining the links between active Facebook use, received likes, self-esteem and happiness: A study using objective social media data. Telemat. Inform. 2021, 58, 101523. [Google Scholar] [CrossRef]
- Faelens, L.; Hoorelbeke, K.; Soenens, B.; Van Gaeveren, K.; De Marez, L.; De Raedt, R.; Koster, E.H. Social media use and well-being: A prospective experience-sampling study. Comput. Hum. Behav. 2021, 114, 106510. [Google Scholar] [CrossRef]
- Chen, X.; Pan, Z. A review on assessment, early warning and auxiliary diagnosis of depression based on different modal data. In Proceedings of the Twelfth International Conference on Graphics and Image Processing (ICGIP 2020), Xi’an, China, 13–15 November 2020; p. 75. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Ziora, L. Natural Language Processing in the Support of Business Organization Management. In Intelligent Systems and Applications; Lecture Notes in Networks and Systems; Arai, K., Ed.; Springer International Publishing: Cham, Switzerland, 2022; Volume 296, pp. 76–83. [Google Scholar] [CrossRef]
- Cortis, K.; Davis, B. Over a decade of social opinion mining: A systematic review. Artif. Intell. Rev. 2021, 54, 4873–4965. [Google Scholar] [CrossRef] [PubMed]
- Singhal, T. A Review of Coronavirus Disease-2019 (COVID-19). Indian J. Pediatr. 2020, 87, 281–286. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. Coronavirus Disease (COVID-19): Vaccines; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Zhou, Y. Natural Language Processing with Improved Deep Learning Neural Networks. Sci. Program. 2022, 2022, 1–8. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Lopes, R. CeDRI at eRisk 2021: A naive approach to early detection of psychological disorders in social media. In Proceedings of the CEUR Workshop Proceedings, CEUR-WS, Bucharest, Romania, 21–24 September 2021; Volume 2936, pp. 981–991. [Google Scholar]
- Pereira, A.; Trifan, A.; Lopes, R.P.; Oliveira, J.L. Systematic review of question answering over knowledge bases. IET Softw. 2022, 16, 1–13. [Google Scholar] [CrossRef]
- Jonker, R.A.A.; Poudel, R.; Pedrosa, T.; Lopes, R.P. Using Natural Language Processing for Phishing Detection. In Optimization, Learning Algorithms and Applications; Communications in Computer and Information, Science; Pereira, A.I., Fernandes, F.P., Coelho, J.P., Teixeira, J.P., Pacheco, M.F., Alves, P., Lopes, R.P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 1488, pp. 540–552. [Google Scholar] [CrossRef]
- Mori, K. Decoding peak emotional responses to music from computational acoustic and lyrical features. Cognition 2022, 222, 105010. [Google Scholar] [CrossRef]
- Abisado, M.; Yongson, M.; De Los Trinos, M. Towards the Development of Music Mood Classification of Original Pilipino Music (OPM) Songs Based on Audio and Lyrics Keyword. In Proceedings of the 2021 5th International Conference on E-Society, E-Education and E-Technology, Taipei, Taiwan, 21–23 August 2021; pp. 87–90. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Z.O. A fast KNN algorithm for text categorization. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, 19–22 August 2007; Volume 6, pp. 3436–3441. [Google Scholar]
- Jose, I. KNN (K-Nearest Neighbors). 2018. Available online: https://medium.com/brasil-ai/knn-k-nearest-neighbors-1-e140c82e9c4e (accessed on 30 December 2021).
- Adamu, H.; Bin Mat Jiran, M.J.; Gan, K.H.; Samsudin, N.H. Text Analytics on Twitter Text-based Public Sentiment for COVID-19 Vaccine: A Machine Learning Approach. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 13–15 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Joyce, J. Bayes’ Theorem. The Stanford Encyclopedia of Philosophy (Fall 2021 Edition). Available online: https://plato.stanford.edu/archives/fall2021/entries/bayes-theorem/ (accessed on 30 December 2021).
- Raschka, S. Naive bayes and text classification i-introduction and theory. arXiv 2014, arXiv:1410.5329. [Google Scholar]
- Elyassami, S.; Alseiari, S.; ALZaabi, M.; Hashem, A.; Aljahoori, N. Fake News Detection Using Ensemble Learning and Machine Learning Algorithms. In Combating Fake News with Computational Intelligence Techniques; Studies in Computational, Intelligence; Lahby, M., Pathan, A.S.K., Maleh, Y., Yafooz, W.M.S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; Volume 1001, pp. 149–162. [Google Scholar] [CrossRef]
- Hossain, F.; Uddin, M.N.; Halder, R.K. An Ensemble Method-Based Machine Learning Approach Using Text Mining to Identify Semantic Fake News. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning; Lecture Notes on Data Engineering and Communications, Technologies. Arefin, M.S., Kaiser, M.S., Bandyopadhyay, A., Ahad, M.A.R., Ray, K., Eds.; Springer: Singapore, 2022; Volume 95, pp. 733–744. [Google Scholar] [CrossRef]
- Gandhi, R. Support Vector Machine—Introduction to Machine Learning Algorithms. 2018. Available online: https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 (accessed on 30 December 2021).
- Islam, N.; Shaikh, A.; Qaiser, A.; Asiri, Y.; Almakdi, S.; Sulaiman, A.; Moazzam, V.; Babar, S.A. Ternion: An Autonomous Model for Fake News Detection. Appl. Sci. 2021, 11, 9292. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Kuala Lumpur, Malaysia, 2016. [Google Scholar]
- Haykin, S. Redes Neurais: Princípios e Prática; Bookman Editora: Orange, CA, USA, 2007. [Google Scholar]
- Leite, T.M. Redes Neurais, Perceptron Multicamadas e o Algoritmo Backpropagation. 2018. Available online: https://medium.com/ensina-ai/redes-neurais-perceptron-multicamadas-e-o-algoritmo-backpropagation-eaf89778f5b8 (accessed on 30 December 2021).
- Glassner, A.S. Deep Learning: A Visual Approach; No Starch Press: San Francisco, CA, USA, 2021. [Google Scholar]
- Demuth, H.; Beale, M.; Hagan, M. Neural network toolbox. In Use MATLAB; MathWorks Inc.: Natick, MA, USA, 1992; Volume 2000. [Google Scholar]
- Schmidt-Hieber, J. Nonparametric regression using deep neural networks with ReLU activation function. Ann. Stat. 2020, 48, 1875–1897. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Amin, M.Z.; Nadeem, N. Convolutional neural network: Text classification model for open domain question answering system. arXiv 2018, arXiv:1809.02479. [Google Scholar]
- Singla, C.; Al-Wesabi, F.N.; Pathania, Y.S.; Alfurhood, B.S.; Hilal, A.M.; Rizwanullah, M.; Hamza, M.A.; Mahzari, M. An Optimized Deep Learning Model for Emotion Classification in Tweets. Comput. Mater. Contin. 2022, 70, 6365–6380. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Jernite, Y.; Bowman, S.R.; Sontag, D.A. Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning. arXiv 2017, arXiv:1705.00557. [Google Scholar]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef]
- Sarker, A.; Lakamana, S.; Hogg-Bremer, W.; Xie, A.; Al-Garadi, M.A.; Yang, Y.C. Self-reported COVID-19 symptoms on Twitter: An analysis and a research resource. J. Am. Med. Inform. Assoc. 2020, 27, 1310–1315. [Google Scholar] [CrossRef] [PubMed]
- Hsu, B.M. Comparison of Supervised Classification Models on Textual Data. Mathematics 2020, 8, 851. [Google Scholar] [CrossRef]
- Krishnakumari, K.; Sivasankar, E.; Radhakrishnan, S. Hyperparameter tuning in convolutional neural networks for domain adaptation in sentiment classification (HTCNN-DASC). Soft Comput. 2020, 24, 3511–3527. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | Similarity |
|---|---|
| rapid | 0.7554 |
| antibody | 0.7390 |
| inconclusive | 0.7301 |
| pcr | 0.7294 |
| corona | 0.7160 |
| retested | 0.7048 |
| Model | TP | TN | FP | FN |
|---|---|---|---|---|
| KNN | 1709 | 2592 | 2285 | 312 |
| Naive Bayes | 3614 | 1833 | 380 | 1071 |
| Decision Tree | 3732 | 2675 | 262 | 229 |
| Random Forest | 3801 | 2706 | 193 | 198 |
| SVM | 3695 | 2726 | 299 | 178 |
| MLP | 3641 | 2609 | 353 | 295 |
| CNN | 3721 | 2693 | 273 | 211 |
| BERT | 3699 | 2734 | 295 | 170 |
| Model | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|
| KNN | 84.6% | 42.8% | 56.8% | 62.3% |
| Naive Bayes | 77.1% | 90.4% | 83.2% | 79.0% |
| Decision Tree | 94.2% | 93.4% | 93.8% | 92.9% |
| Random Forest | 95.0% | 95.1% | 95.2% | 94.3% |
| SVM | 95.4% | 92.5% | 93.9% | 93.1% |
| MLP | 92.5% | 91.2% | 91.9% | 90.6% |
| CNN | 94.6% | 93.2% | 93.9% | 93.0% |
| BERT | 95.6% | 92.6% | 94.0% | 93.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, C.F.d.; Junior, A.C.; Lopes, R.P. Predictive Analysis of COVID-19 Symptoms in Social Networks through Machine Learning. Electronics 2022, 11, 580. https://doi.org/10.3390/electronics11040580
Silva CFd, Junior AC, Lopes RP. Predictive Analysis of COVID-19 Symptoms in Social Networks through Machine Learning. Electronics. 2022; 11(4):580. https://doi.org/10.3390/electronics11040580
Chicago/Turabian StyleSilva, Clístenes Fernandes da, Arnaldo Candido Junior, and Rui Pedro Lopes. 2022. "Predictive Analysis of COVID-19 Symptoms in Social Networks through Machine Learning" Electronics 11, no. 4: 580. https://doi.org/10.3390/electronics11040580
APA StyleSilva, C. F. d., Junior, A. C., & Lopes, R. P. (2022). Predictive Analysis of COVID-19 Symptoms in Social Networks through Machine Learning. Electronics, 11(4), 580. https://doi.org/10.3390/electronics11040580