
Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications



Abstract
:1. Introduction
- Surveillance: Face analysis and tracking is widely used for surveillance purposes by CV researchers. A surveillance system presented in [20] uses the attention of people in a particular scene as an indication of exciting events. Similarly, the work proposed in [21] captures the visual attention of people by using various fixed surveillance cameras.
- Targeted advertisement: One very interesting application of face analysis is targeted advertisement. Several interesting works are proposed by CV researchers regarding targeted advertisement using face analysis. For instance, Smith et al. [22] present a work that tracks the focus of attention of people. The proposed system also counts the number of subjects looking at outdoor advertisements. This work also has some implications in human behavior analysis and cognitive science. Some recent work on targeted advertisment using CV and machine learning (ML) can be explored in [23,24,25].
- Social Behaviour Analysis: The human face is tracked and used in intelligent rooms to monitor and observe the participants’ activities. The visual focus of participants’ attention is particularly judged through head tracking [26,27,28,29,30]. This system follows the direction of speaking of individuals and also provides information about the gestures in a meeting. The semantic cues obtained are later transcribed with conversations and intentions of all participants, which further provides some searchable indexes to be used in the future. Some excellent works which use human face tracking in workplaces and other meetings can be explored in the references [31,32,33,34,35].
- Driving Safety: Face analysis also plays a key role in ensuring driver safety while driving. Some researchers designed a driver-monitoring system by installing a camera within the car and then tracking eyebrow and eyelid movements from fatigue [36,37,38]. It can also provide alert signals to drivers, for instance, if there is some danger of accident due to pedestrians [39]. Blind spots are detected in the method proposed in [40] while driving. This helps the driver to change their vehicle direction. Another method proposed in [41] combines head localization and head pose estimation (HPE) information to estimate pedestrian path. This helps drivers to make some vital decisions while driving.
- Estimation of face, expression, gender, age, and race: In the context of CV, human face analysis acquires high-level knowledge about a facial image. Face images convey several pieces of information, such as who the subject is, the gender and race of the person in the photograph, whether he/she is sad or happy, and what angle they are looking at. In all these tasks, a facial analysis infers knowledge from a face image. Some human face analysis problems are multidisciplinary, as well as intrinsically related to human science. However, very few research works combine various face image analysis tasks in a single unified framework. Our current research paper reports papers that combine at least two face image analysis tasks in one model. Estimating age, race, gender, expression, and head pose are the most important problems in face analysis, with further applications in forensics, the entertainment industry, cosmetology, security controls, and so on [42,43,44,45].
2. Contributions and Paper Organization
- We present a detailed survey on different human face image analysis tasks. This provides researchers with a new and recent up-to-date overview of the SOA technology. We also introduce a taxonomy of all the existing methods for these tasks. We added a detailed discussion on the used technology’s characteristics. Additionally, we explicitly elaborate on the open problems faced by the existing face analysis technology.
- We provide a list of all the publicly available datasets for each of the five face analysis tasks. We also describe the way these datasets are collected and their characteristics. We provide information such as the number of images contained, subjects involved, sex information, environmental diversity, and other details.
- We conducted a detailed study of all the methods for each of the five tasks, both in indoor and outdoor conditions. We summarize the results obtained using each method and present a detailed discussion. We present a concrete summary of the results for each task, provide a critical review, and point to some future directions. We also dedicate attention to various sensors used for data collection and discuss how ground truth data is collected and labeled.
3. Datasets
- UNISA-Public [57]: The UNISA-Public is collected in real-time and unconstrained conditions. The DB consists of 406 face images taken from 58 individuals. The available DB does not provide cropped faces, but a face localization algorithm is needed for the images to be used for gender classification. The data is collected in a building with a camera fixed at the entrance point; therefore, lighting conditions do not change significantly. Different poses and facial expressions are taken, as the participants were not told about the data collection process beforehand. Some motion blur conditions can be seen due to the sudden movement of the individuals.
- Adience [58]: This is the latest DB released for face analysis tasks, including age and gender classification tasks. It is also a challenging DB collected in an outdoor environment. All the images are collected through a smartphone device. The data set is much more challenging, as different pose variations are included along with changing lighting conditions. The DB is large, as the number of face images is around 25,580. The total number of candidates who participated in data collection is 2284. The exact age of each participant is not given, but instead, each subject is assigned to a specific group. This clearly shows that the DB can be used for age classification but not estimation. The DB can be freely downloaded from the Open University of Israel.
- IMDB [59]: The IMDB contains images of celebrities collected from a website named IMDB. The DB is partitioned into two parts, namely IMDB and WIKI. The first part consists of 523, whereas WIKI consists of 51 face images. These images are manually labeled with both gender and age. There are some errors in the annotation of ground truth data. In fact, the authors assume that each face image belongs to the listed celebrity and then automatically annotate it with the gender declared in the profile. This automatic assumption results in errors in ground truth data annotation.
- VGGFace [60]: This DB was explicitly built for face recognition but was later used for additional face analysis tasks. It is a large enough DB to train a DL framework. This DB was gathered in a very inexpensive way through google search. A huge quantity of weakly annotated face images are obtained in this way. These face images are filtered and annotated manually through a fast and inexact process. VGGFace2 is an extension of the VGGFACE DB.
- VGGFace2 [61]: This DB was released in 2018, and it contains more than 3.31 million images. All the images are downloaded from the internet. Images in VGGFace2 have significant variations in illumination conditions, race, profession, and age. The DB is gender-balanced, as an almost equal number of male and female subjects are considered in the images collection. All rotation angles have been considered while collecting the DB.
- SASE [62]: The SASE DB images are collected using a Kinect camera. They consist of RGB and depth images, taken from 32 males and 18 females. There are variations in subjects’ hairstyle, race, and age. Three rotation angles are considered in the SASE DB. Unlike VGGFace2, facial expressions in the SASE are complex and variable. This DB is used both for HPE and expression recognition.
- AFLW [66]: All images in AFLW are from a collection downloaded from the internet, with a very unconstrained background. Both profile and frontal images are considered in nine lighting conditions. All images have variations in face appearance, expression, and some other environmental factors. The total number of images is 13,000, with 5749 subjects. The DB can be used for face detection, landmarks localization, gender recognition, and HPE.
- Multi-Pie [67]: The illumination conditions and facial expressions in Multi-Pie are variable. All data is collected in different sessions with 15 high-resolution cameras. The DB is large, as more than 75,000 images are collected. It is not a balanced DB, as 69% of the total participants are males and the rest are females. People of different races are considered, including European, Asian, and African communities.
- The FacePix [61]: This is an imbalanced DB with 25 male and 5 female subjects. The total number of images in the DB is 5430. The yaw rotation is covered between with a step size of only . Only one rotation angle yaw is considered in the FacePix DB. FacePix has been used for gender recognition and HPE.
- CelebA [72]: This is a large DB with around 200,000 images. The total number of identities is 10,000. Each image in CelebA is labeled with 40 unique binary attributes. It is a very diverse DB, including entire body and cropped face images. Due to the large number of images, CelebA is adopted by many researchers for DL-based face image analysis tasks.
- FEI [68]: This is also a multi-purpose DB that has been used for gender classification, expression recognition, and HPE. The DB is comparatively simple, as all images are collected in constrained conditions with a uniform and one-color background. The total number of participants is 200, half male and half female. The DB was collected over two sessions, called FEI A and B. Only two facial expressions are considered in FEI. Session A images are of a neutral facial expression, whereas session B images are smiling.
- FERET [69]: This is a DB that was introduced earlier for a number of face analysis tasks. The tasks include face recognition, gender classification, and HPE. It is also a simple DB that is collected in constrained laboratory conditions. It is a medium-sized DB, having 14,126 images. The number of subjects involved is 1199. The DB is somewhat challenging, as variations in facial expressions are present in images. The lighting conditions of the images are also not uniform.
- CAS-PEAL [70]: CAS-PEAL has more than 100,000 images. The number of participants is also sufficiently large (more than 1000). The DB is not balanced, having 595 male and 445 female candidates. The authors considered yaw and pitch angles in the range and . The DB is simple to use in experiments, as less complexity is included in the data collection, and the number of poses is also less.
- LFW [71]: This is a comparatively challenging DB, as most of the images are collected from very unconstrained environmental conditions. The total number of participants in the DB is 5479, whereas the total number of images is 1323. All images are downloaded from the internet with very poor resolution. It is a highly imbalanced DB, having 2977 female and 102,566 male participants.
- BJUT-3D [73]: A total of 500 subjects participated in data collection, half male and half female. There are 93 poses in the DB. The pitch and yaw rotations have ranges of and , respectively. The DB can be used for gender recognition and HPE.
- FairFace [74]: This is a large DB with more than 108,500 images. The DB is collected considering three tasks: age, race, and gender classification. It is a DB with seven race groups, which is the largest number of groups reported in the CV research community. The DB is balanced as far as the ethnicity of various races is concerned. Some images are very small; the minimum size of a face fixed is . The DB is publically available for research purposes and downloading. It is challenging DB since the images are collected in real-time conditions with various difficulty levels due to occlusion, lighting variations, and so on.
- UTKFace [75]: This is a large DB with significant variations in the age range. The age range is from 0 to 116 years. Variations in the pose, illumination, occlusion, and so on are included in data collection, making the DB more challenging. The total number of images used for experiments is 23,688. The number of subjects is about 500+.
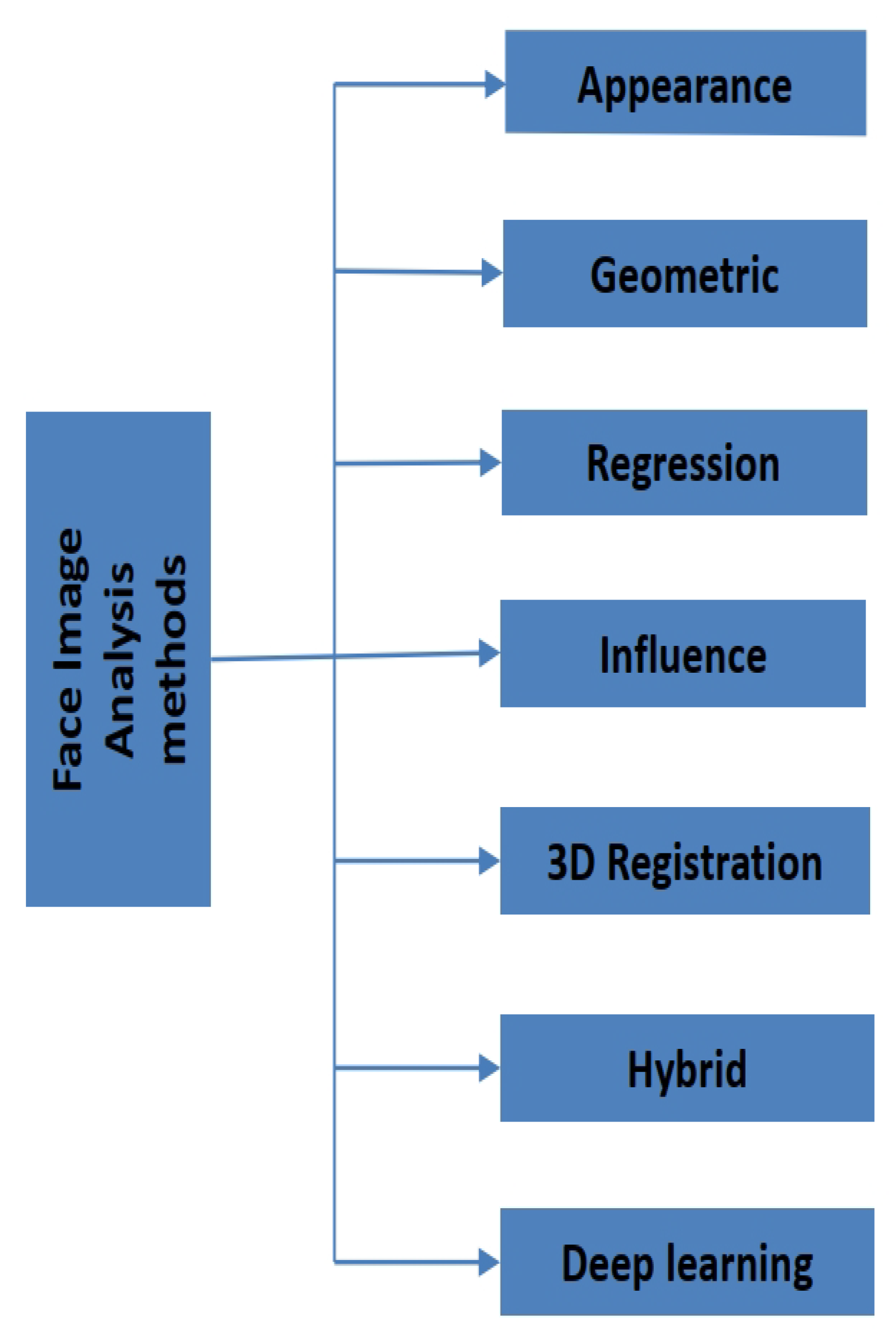
4. Methods
4.1. Appearance Methods
4.2. Geometric Methods
4.3. Regression Methods
4.4. Influence Modeling
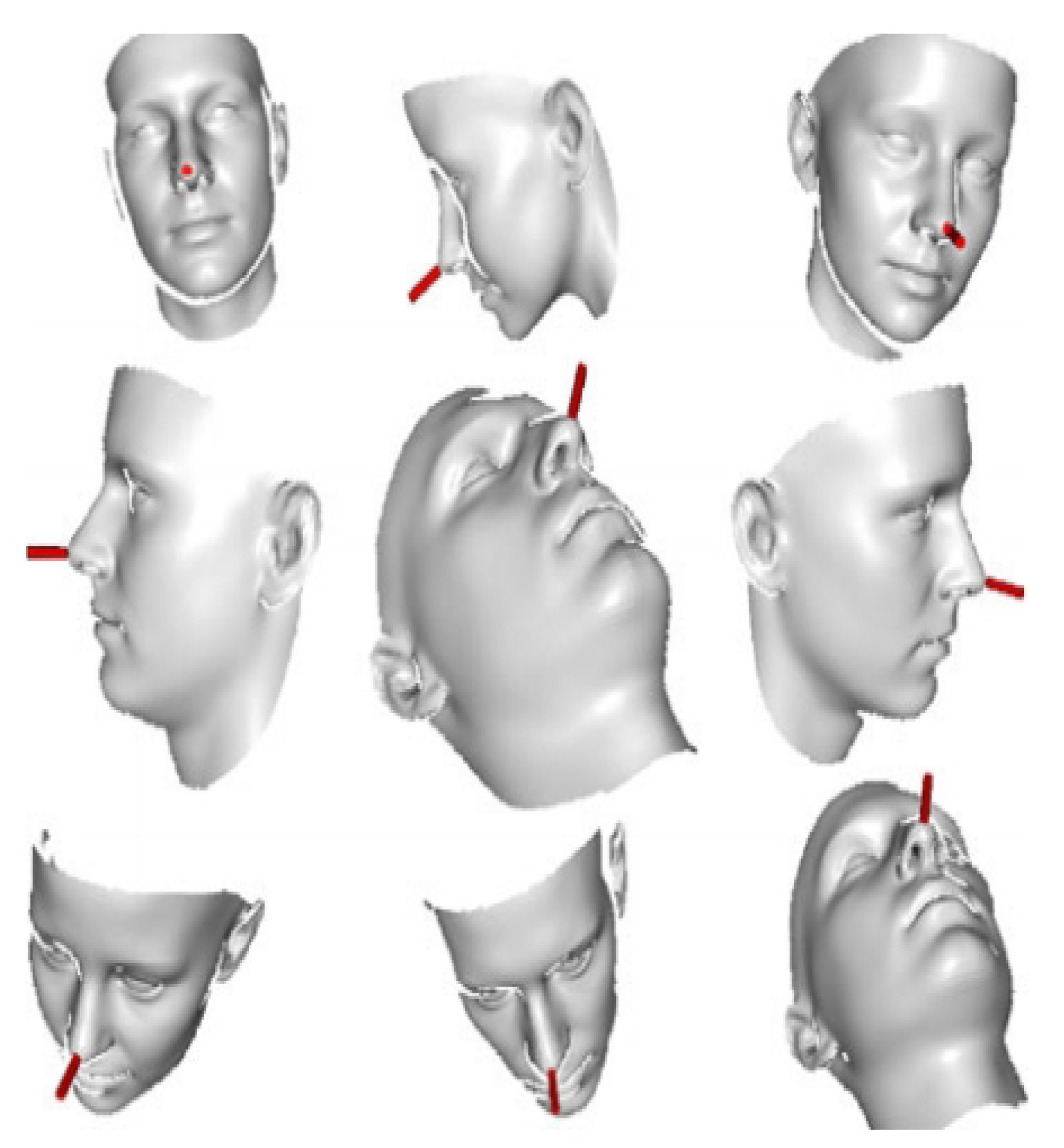
4.5. Model-Based 3D Registration
4.6. Hybrid Methods
4.7. Deep Learning Methods
5. Annotation Type and Processes
6. Discussion: Open Areas of Research and Methods Comparison
6.1. Comparative Assessment of Reported Results
- Previous methods reported their results using classification rate (CR) (age, gender, expression, and race classification). We also compared and present results for these four tasks with CR. CR is a single metric that is the ratio of correctly identified images to the total number of images. Mathematically, this can be written as follows:Along with CR, two other informative metrics are used for evaluating an HPE framework, that is, pose estimation accuracy () and mean absolute error (). is comparatively more common than , as this metric provides a single value which provides an easy insight about the overall performance of an HPE system. On the other hand, purely depends on the poses used, and hence provides comparatively less information regarding evaluation of the performance of a system. Sometimes, confusion matrices () are also provided with results. are in a tabular form, where rows are indexed with original and column entries with estimated class. gives a deep visual insight into the classification errors of multiple classes. However, in this paper, we are not considering and , as very few papers reported these metrics, and a proper comparison cannot be made. Mathematically, can be represented as follows:In Equation (2), N represents the test samples, the ground truth count, and the count estimated for the ith sample.
- Face image analysis is a hot topic in CV. Table 2 shows more details on the performance reported for each method. Table 3 shows a summary of the face analysis work done from 2012 to 2022. It is clear from Table 2 that improvements are brought gradually in CR and values. A quick look at the results in Table 2 reveals that the performance for HPE, gender recogntion, and age classification tasks on both traditional ML and newly introduced DL methods is not same. From [50,51,52], it is clear that influence-based modeling methods perform better than conventional ML-based methods. Morever, in some cases, influence-based methods perform better than DL-based methods. Therefore, we believe that a much better understanding of the DL algorithm methods and their implementation on face analysis tasks is needed. The performance of influence-based modeling on simple DBs acquired in indoor conditions is better. However, when influence-based methods are applied to DBs acquired in open, uncontrolled conditions, a significant drop in performance can be seen. DL methods show much improved results for challenging DBs (for instance, ALFW [66]). Results of traditional ML methods on AFLW are very poor. However, DL has shown much better performance on the same set of images and the same DBs. As far as the performance of traditional ML algorithms is concerned, a mixed response with regard to face analysis tasks can be seen in Table 2. Much better results are shown by hybrid models, as is clear from Table 2.
- Existing methods for face analysis do not define any specific experimental protocol that can be used as a standard for experimental validation. Consequently, different authors use their own experimental setup for validation of their methods. Most of the researchers use 10-fold or 5-fold cross-validation experiments. The results and summary presented in Table 2 are with different experimental setups and validation methods. Therefore, results reported in Table 2 with the same DB may use different validation protocols and setups. For example, Geng et al. [128] use 5-fold cross-validation for Pointing’04, whereas Khan et al. [52] use a subset of the same DB. Therefore, the results presented in Table 2 can be used as a summary, but with a warning to avoid to draw concrete conclusions.
- From the results in Table 2, it can be seen that the performance of most of the methods on Adience DB is significantly lower than the other DBs. Adience is a large DB that is collected in unconstrained conditions. The results in Table 2 highlight the fact that the difficulty level in Adience DB is still high, and more research is needed to make the face analysis technology applicable to images collected in uncontrolled conditions. Moreover, the quality and type of available ground truth data are diverse. Gradual development in the methods of ground truth data can be seen from Section 5. The widely employed manual labeling methods introduce labeling errors, which are reduced with new methods. Synthetic DBs and the creation of manual data are comparatively simple. There is a lower chance of error creation with this method. Most of the images in the DBs mentioned in Table 1 are either centered or cropped faces. Very few methods are fully automated face analysis techniques. An automated face analysis method will detect a face in the initial step and then move to other secondary face analysis applications or tasks. This could be an interesting area to be explored in the future.

{kind=link}
{kind=link}
{kind=link}
| Paper | DB | Task | CR% | |
| Xing et al. [129] | GR | 98.7 | – | |
| RC | 99.2 | – | ||
| AE | – | 2.96 | ||
| Yoo et al. [130] | AE | – | 2.89 | |
| Wan et al. [131] | GR | 98.4 | – | |
| Morph-II | AE | – | 2.93 | |
| GR | 99.1 | – | ||
| Xie et al. [132] | RC | 94.9 | – | |
| AE | – | 2.81 | ||
| Sun et al. [133] | GR | 99.5 | – | |
| RC | 99.6 | – | ||
| Zhou et al. [134] | AE | 98.05 | – | |
| GR | 93.22 | – | ||
| Duan et al. [115] | AE | 52.3 | – | |
| Paper | DB | Task | ||
| GR | 88.2 | – | ||
| Rodriguez et al. [135] | Adience | AE | 61.8 | 2.68 |
| GR | 93.0 | – | ||
| Lapuschkin et al. [136] | AE | 63.8 | – | |
| GR | 94.0 | – | ||
| Tizita et al. [137] | GR | 96 | – | |
| AE | 65 | – | ||
| Levi et al. [138] | GR | 86.8 | – | |
| AE | 55 | – | ||
| Savchenko et al. [139] | AE | 91.95 | 5.96 | |
| GR | 99.86 | 94.01 | ||
| Eidinger et al. [58] | GR | 77.8 | – | |
| Liao et al. [140] | GR | 78.63 | – | |
| Hassner et al. [141] | GR | 79.3 | – | |
| Levi et al. [138] | GR | 86.8 | – | |
| Dehghan et al. [142] | GR | 91.0 | – | |
| Gurnani et al. [143] | GR | 91.8 | – | |
| Zhou et al. [134] | AE | 97.8 | – | |
| GR | 98.3 | |||
| Smith et al. [22] | VGGFace | GR | 98.2 | – |
| AE | – | 4.1 | ||
| Acien et al. [144] | GR | 94.8 | – | |
| RC | 90.1 | |||
| Sharma et al. [75] | AE | 94.01 | 0.77 | |
| GR | 99.86 | 2.9 | ||
| Das et al. [145] | UTKFace | RC | 90.1 | – |
| AE | 70.1 | – | ||
| GR | 98.23 | – | ||
| Mane et al. [146] | FER | 88.18 | – | |
| GR | 96.0 | – | ||
| Mane et al. [146] | IMDB | FER | 88.18 | – |
| GR | 96.0 | – | ||
| Thomaz et al. [147] | GR | 99.0 | – | |
| FER | 95.0 | |||
| Sergio et al. [50] | FEI | GR | 98.5 | – |
| FER | 96.25 | |||
| HPE | 81.0 | 2.79 | ||
| Khan et al. [52] | GR | 97.3 | – | |
| FER | 98.85 | |||
| HPE | 91.35 | 2.32 | ||
| Thomaz et al. [147] | FERET | GR | 84.0 | – |
| FER | 74.0 | |||
| Sergio et al. [50] | GR | 96.5 | – | |
| FER | 93.25 | |||
| Baltrusaitis et al. [103] | ICT-3DHP | HPE | 3.2 | |
| FER | 59.4 | – | ||
| Ranjan et al. [109] | AFLW | HPE | 2.71 | – |
| GR | 94 | – | ||
| CelebA | HPE | 52.3 | – | |
| Ranjan et al. [109] | Dali3DHP | HPE | – | 6.07 |
| FER | 65 | – | ||
| Ranjan et al. [148] | AFW | HPE | 99.1 | 0.293 |
| GR | 99 | – | ||
| FER | 93 | – | ||
| AE | – | 0.20 | ||
| Shin et al. [149] | LFW | AE | 62.73 | – |
| GR | 92.2 | – | ||
| Karkkainenet et al. [74] | FairFace | AE | 59.7 | – |
| GR | 94.2 | |||
| RC | 93.7 |
| Paper | Method | Face Task | DB |
|---|---|---|---|
| 2022 | |||
| Sharma et al. [75] | DL | age and gender | IDMB and UTKFace |
| Bhushan et al. [150] | DL | age and expression | YALE |
| Chethana et al. [151] | DL | age, gender, and expression | |
| Pandi et al. [152] | DL | gender and expression | IMDB |
| 2021 | |||
| Karkkainen et al. [153] | DL | race, age, and gender | FairFace |
| Lahariya et al. [154] | DL | gender and expression | IMDB |
| Park et al. [155] | DL | age and gender | Mega Asian |
| Benkaddour et al. [156] | DL | age and gender | Adience |
| Micheala et al. [157] | DL | age and gender | FERET |
| Kale et al. [158] | DL | race, age, and gender | Face |
| 2020 | |||
| Li et al. [159] | DL | age and gender | AFLW |
| Barra et al. [160] | geometric | age and gender | AFLW |
| Lim et al. [161] | DL | age and gender | IMDB |
| 2019 | |||
| Yang et al. [162] | regression | age and expression | AFLW |
| HyperFace [109] | DL | appearance and DL | AFLW |
| Sergio et al. [50] | IBM | gender, age, and expression | FEI, FERET |
| Hsu et al. [117] | regression | HPE and expression | AFLW |
| Khan et al. [52] | IBM | HPE, age, and gender | FEI, FERET |
| Thomaz et al. [147] | IBM | gender and expression | FEI, FERET |
| Zhou et al. [134] | DL | gender and age | Adience, VGGFace2 |
| 2018 | |||
| Gupta et al. [163] | regression | expressions and gender | AFLW |
| Ruiz et al. [116] | DL | age and gender | AFLW |
| Smith et al. [22] | DL | gender and age | VGGFace |
| Acien et al. [144] | DL | gender and race | VGGFace |
| Baltrusaitis et al. [103] | DL | HPE and expression | ICT-3DHP |
| Das et al. [145] | DL | gender, age, race | UTKFace |
| Mane et al. [146] | appearance | gender and expression | IMDB |
| 2017 | |||
| Derkach et al. [164] | regression | appearance | SASE |
| Duan et al. [115] | hybrid | gender and age | Aidence |
| Dehghan et al. [142] | DL | age, gender, expression | Face+ |
| Ranjan et al. [109] | DL | age, race, gender, expression | AFW |
| Shin et al. [149] | DL | age and gender | AFW |
| 2016 | |||
| Baltrusaitis et al. [109] | 3D morphable | HPE and gender | Multi-Pie+BU |
| Ranjan et al. [109] | DL | head pose and gender | AFLW and CelebA |
| Xia et al. [165] | geometric | race, gender, and age | FRGCv2 |
| Lapuschkin et al. [136] | appearance | age and gender | Adience |
| 2015 | |||
| Afifa et al. [166] | appearance | age and gender | FacePix, CMU PIE, BU |
| Tulyakov et al. [64] | tracking | HPE and expr. | Dali3DHP |
| Peng et al. [167] | mainfold embedded | gender and expr. | CMU-Multipie+BU+AFW |
| Sang-Heon et al. [168] | geometric | age and gender | FERET |
| Levi et al. [138] | DL | age and gender | Adience |
| liu et al. [169] | DL | race, age, gender | FERET |
| Chaudhari et al. [170] | DL | age and gender | FERET |
| Mery et al. [171] | hybrid | race, age, and gender | FERET and JAFFE |
| 2017 | |||
| Tulyakov et al. [64] | tracking | HPE and expression | Dali3DHP |
| Laurentini et al. [172] | appearance | age, race, and gender | |
| Zhaoo et al. [173] | geometric | HPE and expression | LFW |
| Fazl-Ersi et al. [174] | appearance | age and gender | FERET |
| Eidinger et al. [58] | appearance | race, age, and gender | FERET |
| 2013 | |||
| Jain et al. [78] | appearance | expression and gender | CMU-Pie |
| Zhu et al. [111] | 3D registration | age, gender, and expression | CUM-MultiPie+AFW |
| Tizita et al. [137] | appearance | age and gender | FERET |
| Guo et al. [175] | geometric | age, expression, and gender | FERET |
| Boloorizadeh et al. [176] | hybrid | age and gender | FERET |
| 2012 | |||
| zhu et al. [111] | appearance | gender and HPE | FERET |
| Hao et al. [177] | regression | HPE and gender | FacePix, Pointing’04 |
| Jang et al. [102] | appearance | age and gender | BU+CMU-MultiPie |
| Xiangyang et al. [178] | registration | expression and gender | FacePix |
| Huang et al. [48] | appearance | age and gender | CAS-PEAL |
6.2. Benchmark DB Devolopment
6.3. Research on 3D Face is Required
6.4. Knowledge Transfer and Data Augmentation: Possible Areas of Exploration
7. Summary and Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Valenti, R.; Sebe, N.; Gevers, T. Combining head pose and eye location information for gaze estimation. IEEE Trans. Image Process. 2011, 21, 802–815. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation and augmented reality tracking: An integrated system and evaluation for monitoring driver awareness. IEEE Trans. Intell. Transp. Syst. 2010, 11, 300–311. [Google Scholar] [CrossRef]
- Wang, K.; Zhao, R.; Ji, Q. Human computer interaction with head pose, eye gaze and body gestures. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; p. 789. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map fitting with constrained local models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3444–3451. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Dantone, M.; Gall, J.; Fanelli, G.; Van Gool, L. Real-time facial feature detection using conditional regression forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation in computer vision: A survey. IEEE Trans.Pattern Anal. Mach. Intell. 2009, 31, 607–626. [Google Scholar] [CrossRef] [PubMed]
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Deformable model fitting by regularized landmark mean-shift. Int. J. Comput. Vis. 2011, 91, 200–215. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Xiong, X.; De la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition: A literature survey. ACM Comput. Surv. (CSUR) 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Masi, I.; Wu, Y.; Hassner, T.; Natarajan, P. Deep face recognition: A survey. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, 29 October–1 November 2018; pp. 471–478. [Google Scholar]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [Green Version]
- Sharif, M.; Naz, F.; Yasmin, M.; Shahid, M.A.; Rehman, A. Face Recognition: A Survey. J. Eng. Sci. Technol. Rev. 2017, 10, 471–478. [Google Scholar] [CrossRef]
- Pandya, J.M.; Rathod, D.; Jadav, J.J. A survey of face recognition approach. Int. J. Eng. Res. Appl. (IJERA) 2013, 3, 632–635. [Google Scholar]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Lal, M.; Kumar, K.; Arain, R.H.; Maitlo, A.; Ruk, S.A.; Shaikh, H. Study of face recognition techniques: A survey. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 42–49. [Google Scholar] [CrossRef]
- Alghamdi, J.; Alharthi, R.; Alghamdi, R.; Alsubaie, W.; Alsubaie, R.; Alqahtani, D.; Alqarni, L.; Alshammari, R. A survey on face recognition algorithms. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–5. [Google Scholar]
- Benfold, B.; Reid, I.D. Guiding visual surveillance by tracking human attention. BMVC 2009, 2, 7. [Google Scholar]
- Sankaranarayanan, K.; Chang, M.-C.; Krahnstoever, N. Tracking gaze direction from far-field surveillance cameras. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 519–526. [Google Scholar]
- Smith, K.; Ba, S.O.; Odobez, J.-M.; Gatica-Perez, D. Tracking the visual focus of attention for a varying number of wandering people. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1212–1229. [Google Scholar] [CrossRef] [Green Version]
- Khan, Z.; Fu, Y. One label, one billion faces: Usage and consistency of racial categories in computer vision. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Toronto, Canada, 3–10 March 2021; pp. 587–597. [Google Scholar]
- Zhang, L.; Shen, J.J.; Zhang, J.; Xu, J.; Li, Z.; Yao, Y.; Yu, L. Multimodal marketing intent analysis for effective targeted advertising. IEEE Trans. Multimed. 2022, 24, 1830–1843. [Google Scholar] [CrossRef]
- Xiao, Y.; Wang, C. You see what I want you to see: Exploring targeted black-box transferability attack for hash-based image retrieval systems. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1934–1943. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Multimodal deep convolutional neural network for audio-visual emotion recognition. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, ACM, New York, NY, USA, 6–9 June 2016; pp. 281–284. [Google Scholar]
- Nihei, F.; Nakano, Y.I. Exploring methods for predicting important utterances contributing to meeting summarization. Multimodal Technol. Interact. 2019, 3, 50. [Google Scholar] [CrossRef] [Green Version]
- Basu, S.; Choudhury, T.; Clarkson, B.; Pentland, A. Towards measuring human interactions in conversational settings. In Proceedings of the IEEE CVPR Workshop on Cues in Communication, Kauai, HI, USA, 9 December 2001. [Google Scholar]
- McCowan, L.; Gatica-Perez, D.; Bengio, S.; Lathoud, G.; Barnard, M.; Zhang, D. Automatic analysis of multimodal group actions in meetings. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 305–317. [Google Scholar] [CrossRef] [Green Version]
- Odobez, J.-M.; Ba, S. A cognitive and unsupervised map adaptation approach to the recognition of the focus of attention from head pose. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 1379–1382. [Google Scholar]
- Stiefelhagen, R.; Yang, J.; Waibel, A. A model-based gaze tracking system. Int. J. Artif. Intell. Tools 1997, 6, 193–209. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Hu, Y.; Liu, M.; Huang, T. Head pose estimation in seminar room using multi view face detectors. In International Evaluation Workshop on Classification of Events, Activities and Relationships; Springer: Berlin/Heidelberg, Germany, 2006; pp. 299–304. [Google Scholar]
- Zen, G.; Lepri, B.; Ricci, E.; Lanz, O. Space speaks: Towards socially and personality aware visual surveillance. In Proceedings of the 1st ACM International Workshop on Multimodal Pervasive Video Analysis, ACM, Firenze, Italy, 29 October 2010; pp. 37–42. [Google Scholar]
- Reid, I.; Benfold, B.; Patron, A.; Sommerlade, E. Understanding interactions and guiding visual surveillance by tracking attention. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 380–389. [Google Scholar]
- Chen, C.-W.; Aghajan, H. Multiview social behavior analysis in work environments. In Proceedings of the 2011 Fifth ACM/IEEE International Conference on Distributed Smart Cameras, Ghent, Belgium, 22–25 August 2011; pp. 1–6. [Google Scholar]
- Zdzisław, K.; Czubenko, M.; Merta, T. Emotion monitoring system for drivers. IFAC-PapersOnLine 2019, 52, 200–205. [Google Scholar]
- Braun, M.; Schubert, J.; Pfleging, B.; Alt, F. Improving driver emotions with affective strategies. Multimodal Technol. Interact. 2019, 3, 21. [Google Scholar] [CrossRef] [Green Version]
- Ihme, K.; Dömel, C.; Freese, M.; Jipp, M. Frustration in the face of the driver: A simulator study on facial muscle activity during frustrated driving. Interact. Stud. 2018, 19, 487–498. [Google Scholar] [CrossRef]
- Murphy-Chutorian, E.; Doshi, A.; Trivedi, M.M. Head pose estimation for driver assistance systems: A robust algorithm and experimental evaluation. In Proceedings of the 2007 IEEE Intelligent Transportation Systems Conference, Bellevue, WA, USA, 30 September–3 October 2007; pp. 709–714. [Google Scholar]
- Ray, S.J.; Teizer, J. Coarse head pose estimation of construction equipment operators to formulate dynamic blind spots. Adv. Eng. Inform. 2012, 26, 117–130. [Google Scholar] [CrossRef]
- Schulz, A.; Damer, N.; Fischer, M.; Stiefelhagen, R. Combined head localization and head pose estimation for video-based advanced driver assistance systems. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2011; pp. 51–60. [Google Scholar]
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. PAMI 2010, 32, 1955–1976. [Google Scholar]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef]
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological states. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A survey of affect recognition methods: Audio, visual and spontaneous expressions. IEEE Trans. PAMI 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Wollaston, W.H. Xiii. on the apparent direction of eyes in a portrait. Philos. Trans. R. Soc. Lond. 1824, 114, 247–256. [Google Scholar]
- Langton, S.R.; Honeyman, H.; Tessler, E. The influence of head contour and nose angle on the perception of eye-gaze direction. Percept. Psychophys. 2004, 66, 752–771. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Ding, X.; Fang, C. Head pose estimation based on random forests for multiclass classification. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 934–937. [Google Scholar]
- Khan, K.; Mauro, M.; Migliorati, P.; Leonardi, R. Head pose estimation through multi-class face segmentation. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 175–180. [Google Scholar]
- Khan, K.; Ahmad, N.; Khan, F.; Syed, I. A framework for head pose estimation and face segmentation through conditional random fields. Signal Image Video Process. 2019, 14, 159–166. [Google Scholar] [CrossRef]
- Benini, S.; Khan, K.; Leonardi, R.; Mauro, M.; Migliorati, P. Face analysis through semantic face segmentation. Signal Process. Image Commun. 2019, 74, 21–31. [Google Scholar] [CrossRef]
- Khan, K.; Attique, M.; Syed, I.; Sarwar, G.; Irfan, M.A.; Khan, R.U. A unified framework for head pose, age and gender classification through end-to-end face segmentation. Entropy 2019, 21, 647. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, K.; Mauro, M.; Leonardi, R. Multi-class semantic segmentation of faces. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 827–831. [Google Scholar]
- Raji, I.D.; Fried, G. About face: A survey of facial recognition evaluation. arXiv 2021, arXiv:2102.00813. [Google Scholar]
- Mascio, T.D.; Fantozzi, P.; Laura, L.; Rughetti, V. Age and Gender (Face) Recognition: A Brief Survey. In International Conference in Methodologies and intelligent Systems for Techhnology Enhanced Learning; Springer: Cham, Switzerland, 2021; pp. 105–113. [Google Scholar]
- Khan, K.; Khan, R.U.; Leonardi, R.; Migliorati, P.; Benini, S. Head pose estimation: A survey of the last ten years. Signal Process. Image Commun. 2021, 99, 116479. [Google Scholar] [CrossRef]
- Azzopardi, G.; Greco, A.; Saggese, A.; Vento, M. Fast gender recognition in videos using a novel descriptor based on the gradient magnitudes of facial landmarks. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Eidinger, E.; Enbar, R.; Hassner, T. Age and gender estimation of unfiltered faces. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2170–2179. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Gool, L.V. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef] [Green Version]
- Breitenstein, M.D.; Kuettel, D.; Weise, T.; Gool, L.V.; Pfister, H. Real-time face pose estimation from single range images. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A DB for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Usi, I.L.; Junior, J.C.J.; Gorbova, J.; Baro, X.; Escalera, S.; Demirel, H.; Allik, J.; Ozcinar, C.; Anbarjafari, G. Joint challenge on dominant and complementary emotion recognition using micro emotion features and head-pose estimation: DBs. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 809–813. [Google Scholar]
- Liu, Y.; Chen, J.; Su, Z.; Luo, Z.; Luo, N.; Liu, L.; Zhang, K. Robust head pose estimation using dirichlet-tree distribution enhanced random forests. Neurocomputing 2016, 173, 42–53. [Google Scholar] [CrossRef]
- Tulyakov, S.; Vieriu, R.-L.; Semeniuta, S.; Sebe, N. Robust real-time extreme head pose estimation. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 2263–2268. [Google Scholar]
- Demirkus, M.; Clark, J.J.; Arbel, T. Robust semi-automatic head pose labeling for real-world face video sequences. Multimed. Tools Appl. 2014, 70, 495–523. [Google Scholar] [CrossRef]
- Koestinger, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Annotated facial landmarks in the wild: A large-scale, real-world DB for facial landmark localization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2144–2151. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-pie. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef]
- Centro Universitario Da Fei, Fei Face DB. Available online: http://www.fei.edu.br/cet/faceDB.html (accessed on 13 March 2022).
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The feret DB and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Fanelli, G.; Dantone, M.; Gall, J.; Fossati, A.; Gool, L.V. Random forests for real time 3d face analysis. Int. J. Comput. 2013, 101, 437–458. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A DB Forstudying Face Recognition in Unconstrained Environments. 2008. Available online: https://hal.inria.fr/inria-00321923 (accessed on 13 March 2022).
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Baocai, Y.; Yanfeng, S.; Chengzhang, W.; Yun, G. Bjut-3d large scale 3d face DB and information processing. J. Comput. Res. Dev. 2009, 6, 020. [Google Scholar]
- Kärkkäinen, K.; Joo, J. Fairface: Face attribute DB for balanced race, gender, and age. arXiv 2019, arXiv:1908.04913. [Google Scholar]
- Sharma, N.; Sharma, R.; Jindal, N. Face-Based Age and Gender Estimation Using Improved Convolutional Neural Network Approach. Wirel. Pers. Commun. 2022, 1–20. [Google Scholar] [CrossRef]
- Burl, M.C.; Perona, P. Recognition of planar object classes. In Proceedings of the CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 223–230. [Google Scholar]
- Asteriadis, S.; Tzouveli, P.; Karpouzis, K.; Kollias, S. Estimation of behavioral user state based on eye gaze and head pose application in an e-learning environment. Multimed. Tools Appl. 2009, 41, 469–493. [Google Scholar] [CrossRef]
- Jain, V.; Crowley, J.L. Head pose estimation using multi-scale gaussian derivatives. In Image Analysis; Kämäräinen, J.-K., Koskela, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 319–328. [Google Scholar]
- Ma, B.; Huang, R.; Qin, L. Vod: A novel image representation for head yaw estimation. Neurocomputing 2015, 148, 455–466. [Google Scholar] [CrossRef]
- Zavan, F.H.; Nascimento, A.C.; Bellon, O.R.; Silva, L. Nosepose: A competitive, landmark-free methodology for head pose estimation in the wild. In Proceedings of the Conference on Graphics, Patterns and Images-W. Face Processing 2016, Sao Paulo, Brazil, 4–7 October 2016. [Google Scholar]
- Svanera, M.; Muhammad, U.R.; Leonardi, R.; Benini, S. Figaro, hair detection and segmentation in the wild. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 933–937. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, U.R.; Svanera, M.; Leonardi, R.; Benini, S. Hair detection, segmentation, and hairstyle classification in the wild. Image Vis. Comput. 2018, 71, 25–37. [Google Scholar] [CrossRef] [Green Version]
- Sherrah, J.; Gong, S. Fusion of perceptual cues for robust tracking of head pose and position. Pattern Recognit. 2001, 34, 1565–1572. [Google Scholar] [CrossRef]
- Nikolaidis, A.; Pitas, I. Facial feature extraction and determination of pose. In Noblesse Workshop on Non-Linear Model Based Image Analysis; Springer: London, UK, 1998. [Google Scholar]
- Wu, J.; Trivedi, M.M. A two-stage head pose estimation framework and evaluation. Pattern Recognit. 2008, 41, 1138–1158. [Google Scholar] [CrossRef] [Green Version]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef] [Green Version]
- Fleuret, F.; Geman, D. Fast face detection with precise pose estimation. In Object Recognition Supported by User Interaction for Service Robots; IEEE: Piscataway, NJ, USA, 2002; Volume 1. [Google Scholar]
- Li, Y.; Gong, S.; Sherrah, J.; Liddell, H. Support vector machine based multi-view face detection and recognition. Image Vis. Comput. 2004, 22, 413–427. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxforduniversity Press: Oxford, UK, 1995. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Brown, L.M.; Tian, Y.-L. Comparative study of coarse head pose estimation. In Proceedings of the Workshop on Motion and Video Computing, Orlando, FL, USA, 5–6 December 2002; pp. 125–130. [Google Scholar]
- Schiele, B.; Waibel, A. Gaze tracking based on face-color. In International Workshop on Automatic Face-and Gesture-Recognition; University of Zurich Department of Computer Science Multimedia Laboratory: Zürich, Switzerland, 1995; Volume 476. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ma, B.; Zhang, W.; Shan, S.; Chen, X.; Gao, W. Robust head pose estimation using lgbp. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Washington, DC, USA, 20–24 August 2006; Volume 2, pp. 512–515. [Google Scholar]
- Ma, Y.; Konishi, Y.; Kinoshita, K.; Lao, S.; Kawade, M. Sparse bayesianregression for head pose estimation. In Proceedings of the 18th International Conferenceon Pattern Recognition (ICPR’06), Washington, DC, USA, 20–24 August 2006; Volume 3, pp. 507–510. [Google Scholar]
- Pan, W.; Dong, W.; Cebrian, M.; Kim, T.; Fowler, J.H.; Pentland, A.S. Modeling dynamical influence in human interaction: Using data to make better inferences about influence within social systems. IEEE Signal Process. Mag. 2012, 29, 77–86. [Google Scholar] [CrossRef]
- Dong, W.; Lepri, B.; Pianesi, F.; Pentland, A. Modeling functional rolesdynamics in small group interactions. IEEE Trans. Multimed. 2012, 15, 83–95. [Google Scholar] [CrossRef]
- Malciu, M.; Preteux, F. A robust model-based approach for 3d headtracking in video sequences. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat.No. PR00580), Grenoble, France, 28–30 March 2000; pp. 169–174. [Google Scholar]
- Yu, Y.; Mora, K.A.F.; Odobez, J.-M. Robust and accurate 3d head-pose estimation through 3dmm and online head model reconstruction. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 711–718. [Google Scholar]
- Ghiass, R.S.; Arandjelovi´c, O.; Laurendeau, D. Highly accurate andfully automatic head pose estimation from a low quality consumer-levelrgb-d sensor. In Proceedings of the 2nd Workshop on ComputationalModels of Social Interactions: Human-Computer-Media Communication, ACM, Brisbane, Australia, 4–9 May 2015; pp. 25–34. [Google Scholar]
- Papazov, C.; Marks, T.K.; Jones, M. Real-time 3d head pose and faciallandmark estimation from depth images using triangular surface patchfeatures. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4722–4730. [Google Scholar]
- Jang, J.-S.; Kanade, T. Robust 3d Head Tracking by View-Based Featurepoint Registration. 2010. Available online: http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=8FE1D32FB3577413DD9E5D3200E0C734?doi=10.1.1.180.5065&rep=rep1&type=pdf (accessed on 13 March 2022).
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.-P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Hong, C.; Yu, J.; Zhang, J.; Jin, X.; Lee, K. Multimodal face-pose estimation with multitask manifold deep learning. IEEE Trans. Ind. Inform. 2018, 15, 3952–3961. [Google Scholar] [CrossRef] [Green Version]
- Stéphane, L.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A comprehensive analysis of deep regression. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2065–2081. [Google Scholar]
- Zhang, F.; Zhang, T.; Mao, Q.; Xu, C. Joint pose and expression modeling for facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3359–3368. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to Learn; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Gee, A.; Cipolla, R. Determining the gaze of faces in images. Image Vis. Comput. 1994, 12, 639–647. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 121–135. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Alavi, A.; Chellappa, R. Kepler: Keypoint and pose estimation of unconstrained faces by learning efficient h-cnn regressors. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, DC, USA, 30 May–3 June 2017; pp. 258–265. [Google Scholar]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2879–2886. [Google Scholar]
- Jebara, T.S.; Pentland, A. Parametrized structure from motion for 3dadaptive feedback tracking of faces. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 144–150. [Google Scholar]
- Thamilselvan, P.; Sathiaseelan, J.G.R. Image classification using hybrid data mining algorithms-a review. In Proceedings of the 2015 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 19–20 March 2015; pp. 1–6. [Google Scholar]
- Khalil, K.; Attique, M.; Syed, I.; Gul, A. Automatic gender classification through face segmentation. Symmetry 2019, 11, 770. [Google Scholar]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNN–ELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Ruiz, N.; Chong, E.; Rehg, J.M. Fine-grained head pose estimation without key points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2074–2083. [Google Scholar]
- Hsu, H.-W.; Wu, T.-Y.; Wan, S.; Wong, W.H.; Lee, C.-Y. Quatnet: Quaternion-based head pose estimation with multi regression loss. IEEE Trans. Multimed. 2018, 21, 1035–1046. [Google Scholar] [CrossRef]
- Patacchiola, M.; Cangelosi, A. Head pose estimation in the wild usingconvolutional neural networks and adaptive gradient methods. Pattern Recognit. 2017, 71, 132–143. [Google Scholar]
- Gozde, Y.; Oztel, I.; Kazan, S.; Oz, C.; Bunyak, F. Deep learning-based face analysis system for monitoring customer interest. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 237–248. [Google Scholar]
- Andrea, G.; Ceccacci, S.; Mengoni, M. A deep learning-based system to track and analyze customer behavior in retail store. In Proceedings of the 2018 IEEE 8th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; pp. 1–6. [Google Scholar]
- Lopes, R.R.; Schwartz, G.M.; Ruggiero, W.V.; Rodríguez, D.Z. A knowledge-based recommendation system that includes sentiment analysis and deep learning. IEEE Trans. Ind. Inform. 2018, 15, 2124–2135. [Google Scholar]
- Hou, J. Deep Learning-Based Human Emotion Detection Framework Using Facial Expressions. J. Interconnect. Netw. 2022, 2141018. [Google Scholar] [CrossRef]
- Apoorva, S.; Saha, S.; Hasanuzzaman, M.; Dey, K. Multitask learning for complaint identification and sentiment analysis. Cogn. Comput. 2022, 14, 212–227. [Google Scholar]
- Liu, X.; Liang, W.; Wang, Y.; Li, S.; Pei, M. 3d head pose estimation with convolutional neural network trained on synthetic images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1289–1293. [Google Scholar]
- Rae, R.; Ritter, H.J. Recognition of human head orientation based on artificial neural networks. IEEE Trans. Neural Netw. 1998, 9, 257–265. [Google Scholar] [CrossRef]
- Cascia, M.L.; Sclaroff, S.; Athitsos, V. Fast, reliable head tracking under varying illumination: An approach based on registration of texturemapped 3d models. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 322–336. [Google Scholar] [CrossRef] [Green Version]
- Morency, L.-P.; Rahimi, A.; Darrell, T. Adaptive view-based appearance models. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003. I-803. [Google Scholar]
- Geng, X.; Zhou, Z.-H.; Smith-Miles, K. Automatic age estimation basedon facial aging patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2234–2240. [Google Scholar] [CrossRef] [Green Version]
- Xing, J.; Li, K.; Hu, W.; Yuan, C.; Ling, H. Diagnosing deep learning models for high accuracy age estimation from a single image. Pattern Recognit. 2017, 66, 106–116. [Google Scholar] [CrossRef]
- Yoo, B.; Kwak, Y.; Kim, Y.; Choi, C.; Kim, J. Deep facial age estimation using conditional multitask learning with weak label expansion. IEEE Signal Process. Lett. 2018, 25, 808–812. [Google Scholar] [CrossRef]
- Wan, J.; Tan, Z.; Guo, G.; Li, S.Z.; Lei, Z. Auxiliary demographic information assisted age estimation with cascaded structure. IEEE Trans. Cybern. 2018, 48, 2531–2541. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.-C.; Pun, C.-M. Chronological age estimation under the guidance of age-related facial attributes. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2500–2511. [Google Scholar] [CrossRef]
- Sun, H.; Pan, H.; Han, H.; Shan, S. Deep Conditional Distribution Learning for Age Estimation. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4679–4690. [Google Scholar] [CrossRef]
- Zhou, Y.; Ni, H.; Ren, F.; Kang, X. Face and gender recognition system based on convolutional neural networks. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 1091–1095. [Google Scholar]
- Rodriguez, P.; Cucurull, G.; Gonfaus, J.M.; Roca, F.X.; Gonzalez, J. Age and gender recognition in the wild with deep attention. Pattern Recognit. 2017, 72, 563–571. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Binder, A.; Muller, K.R.; Samek, W. Understanding and comparing deep neural networks for age and gender classification. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1629–1638. [Google Scholar]
- Shewaye, T.N. Age group and gender recognition from human facial images. arXiv 2013, arXiv:1304.0019. [Google Scholar]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Savchenko, A.V. Efficient facial representation for age, gender and identity recognition in organizing photo albums using multi-output CNN. PeerJ Comput. Sci. 2019, 5, e197. [Google Scholar] [CrossRef] [Green Version]
- Liao, Z.; Petridis, S.; Pantic, M. Local Deep Neural networks for Age and Gender Classification. arXiv 2017, arXiv:1703.08497. [Google Scholar]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Dehghan, A.; Ortiz, E.G.; Shu, G.; Masood, S.Z. Dager: Deep age, gender andemotion recognition using convolutional neural networks. arXiv 2017, arXiv:1702.04280. [Google Scholar]
- Gurnani, A.; Shah, K.; Gajjar, V.; Mavani, V.; Khandhediya, Y. SAFBAGE: Salient approach for face soft-biometric classification–age, gender, and face expression. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2018. [Google Scholar]
- Acien, A.; Morales, A.; Vera-Rodriguez, R.; Bartolome, I.; Fierrez, J. Measuring the gender and ethnicity bias in deep models for face recognition. In Iberoamerican Congress on Pattern Recognition; Springer: Cham, Switzerland, 2018; pp. 584–593. [Google Scholar]
- Das, A.; Dantcheva, A.; Bremond, F. Mitigating bias in gender, age and ethnicity classification: A multi-task convolution neural network approach. In Proceedings of the European Conference on Computer Vision (Eccv) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mane, S.; Shah, G. Facial recognition, expression recognition, and gender identification. In Data Management, Analytics and Innovation; Springer: Singapore, 2019; pp. 275–290. [Google Scholar]
- Thomaz, C.; Giraldi, G.; Costa, J.; Gillies, D. A priori-driven PCA. In Computer VisionACCV 2012 Workshops, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 236–247. [Google Scholar]
- Ranjan, R.; Sankaranarayanan, S.; Castillo, C.D.; Chellappa, R. An all-in-one convolutional neural network for face analysis. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 17–24. [Google Scholar]
- Shin, M.; Seo, J.H.; Kwon, D.S. Face image-based age and gender estimation with consideration of ethnic difference. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; pp. 567–572. [Google Scholar]
- Bhushan, S.; Alshehri, M.; Agarwal, N.; Keshta, I.; Rajpurohit, J.; Abugabah, A. A Novel Approach to Face Pattern Analysis. Electronics 2022, 11, 444. [Google Scholar] [CrossRef]
- Chethana, H.T.; Nagavi, T.C. A Review of Face Analysis Techniques for Conventional and Forensic Applications. Cyber Secur. Digit. Forensics 2022, 223–240. [Google Scholar] [CrossRef]
- Pandi, C.; Adi Narayana Reddy, K.; Alladi, R.; Chandra Sekhar Reddy, V.; Sumithabhashini, P. Emotion and Gender Classification Using Convolution Neural Networks. In ICT Systems and Sustainability; Springer: Singapore, 2022; pp. 563–573. [Google Scholar]
- Karkkainen, K.; Joo, J. Fairface: Face attribute DB for balanced race, gender, and age for bias measurement and mitigation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 1548–1558. [Google Scholar]
- Lahariya, A.; Singh, V.; Tiwary, U.S. Real-time Emotion and Gender Classification using Ensemble CNN. arXiv 2021, arXiv:2111.07746. [Google Scholar]
- Park, G.; Jung, S. Facial Information Analysis Technology for Gender and Age Estimation. arXiv 2021, arXiv:2111.09303. [Google Scholar]
- Benkaddour, M.K. CNN based features extraction for age estimation and gender classification. Informatica 2021, 45. [Google Scholar] [CrossRef]
- Micheala, A.A.; Shankar, R. Automatic Age and Gender Estimation using Deep Learning and Extreme Learning Machine. Turk. J. Comput. Math. Educ. 2021, 12, 63–73. [Google Scholar]
- Kale, A.; Altun, O. Age, Gender and Ethnicity Classification from Face Images with CNN-Based Features. In Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference (ASYU), Elazig, Turkey, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Li, J.; Wang, J.; Ullah, F. An end-to-end task-simplified and anchor-guided deep learning framework for imagebased head pose estimation. IEEE Access 2020, 8, 42458–42468. [Google Scholar] [CrossRef]
- Barra, P.; Barra, S.; Bisogni, C.; Marsico, M.D.; Nappi, M. Web-shaped model for head pose estimation: An approach for best exemplar selection. IEEE Trans. Image Process. 2020, 29, 5457–5468. [Google Scholar] [CrossRef]
- Abu Nada, A.M.; Alajrami, E.; Al-Saqqa, A.A.; Abu-Naser, S.S. Age and Gender Prediction and Validation through Single User Images Using CNN. 2020. Available online: http://dspace.alazhar.edu.ps/xmlui/handle/123456789/632 (accessed on 13 March 2022).
- Yang, T.-Y.; Chen, Y.-T.; Lin, Y.-Y.; Chuang, Y.-Y. Fsa-net: Learning fine-grained structure aggregation for head pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1087–1096. [Google Scholar]
- Gupta, A.; Thakkar, K.; Gandhi, V.; Narayanan, P. Nose, eyes and ears: Head pose estimation by locating facial key points. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1977–1981. [Google Scholar]
- Derkach, D.; Ruiz, A.; Sukno, F.M. Head pose estimation based on3-d facial landmarks localization and regression. In Proceedings of the 2017 12th IEEEInternational Conference on Automatic Face & Gesture Recognition(FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 820–827. [Google Scholar]
- Xia, B.; Amor, B.B.; Daoudi, M. Joint gender, ethnicity and age estimation from 3D faces: An experimental illustration of their correlations. Image Vis. Comput. 2017, 64, 90–102. [Google Scholar] [CrossRef]
- Dahmane, A.; Larabi, S.; Bilasco, I.M.; Djeraba, C. Head pose estimation based on face symmetry analysis. Signal, Image Video Process. 2015, 9, 1871–1880. [Google Scholar] [CrossRef]
- Yang, X.; Huang, D.; Wang, Y.; Chen, L. Automatic 3d facial expression recognition using geometric scattering representation. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–6. [Google Scholar]
- Lee, S.; Sohn, M.; Kim, H. Implementation of age and gender recognition system for intelligent digital signage. In Proceedings of the Eighth International Conference on Machine Vision (ICMV 2015), Barcelona, Spain, 19–20 November 2015. [Google Scholar]
- Liu, H.; Shen, X.; Ren, H. FDAR-Net: Joint convolutional neural networks for face detection and attribute recognition. In Proceedings of the 2016 9th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10–11 December 2016; Volume 2, pp. 184–187. [Google Scholar]
- Chaudhari, S.J.; Kagalkar, R.M. Methodology for Gender Identification, Classification and Recognition of Human Age. Int. J. Comput. Appl. 2015, 975, 8887. [Google Scholar]
- Mery, D.; Bowyer, K. Automatic facial attribute analysis via adaptive sparse representation of random patches. Pattern Recognit. Lett. 2015, 68, 260–269. [Google Scholar] [CrossRef]
- Laurentini, A.; Bottino, A. Computer analysis of face beauty: A survey. Comput. Vis. Image Underst. 2014, 125, 184–199. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Kim, T.K.; Luo, W. Unified face analysis by iterative multi-output random forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1765–1772. [Google Scholar]
- Fazl-Ersi, E.; Mousa-Pasandi, M.E.; Laganiere, R.; Awad, M. Age and gender recognition using informative features of various types. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5891–5895. [Google Scholar]
- Guo, G.; Mu, G. Joint estimation of age, gender and ethnicity: CCA vs. PLS. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Boloorizadeh, P.; Tojari, F. Facial expression recognition: Age, gender and exposure duration impact. Procedia-Soc. Behav. Sci. 2013, 84, 1369–1375. [Google Scholar] [CrossRef] [Green Version]
- Ji, H.; Liu, R.; Su, F.; Su, Z.; Tian, Y. Robust head pose estimation viaconvex regularized sparse regression. In Proceedings of the 2011 18th IEEE InternationalConference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3617–3620. [Google Scholar]
- Liu, X.; Lu, H.; Li, W. Multi-manifold modeling for head pose estimation. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3277–3280. [Google Scholar]
- Afzal, H.R.; Luo, S.; Afzal, M.K.; Chaudhary, G.; Khari, M.; Kumar, S.A.P. 3D face reconstruction from single 2D image using distinctive features. IEEE Access 2020, 8, 180681–180689. [Google Scholar] [CrossRef]
- Hoffman, J.; Rodner, E.; Donahue, J.; Kulis, B.; Saenko, K. Asymmetricand category invariant feature transformations for domain adaptation. Int. J. Comput. Vis. 2014, 109, 28–41. [Google Scholar] [CrossRef]
- Zhou, Z.-H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; FeiFei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]



| DB | No. of Subjects | No. of Images | Gender | Age | Head Pose | Expressions | Race |
|---|---|---|---|---|---|---|---|
| UNISA-Public [57] | 58 | 406 | ✓ | ✓ | ✓ | ||
| Adience [58] | 2284 | 25,580 | ✓ | ✓ | |||
| IDMB [59] | 558 | 500 K | ✓ | ✓ | |||
| VGGFACE [60] | – | 6000 | ✓ | ✓ | |||
| VGGFace2 [61] | 9131 | 3.31 M | ✓ | ✓ | ✓ | ✓ | |
| SASE [62] | 50 | 30,000 | ✓ | ✓ | ✓ | ||
| CCNU [63] | 58 | 4350 | ✓ | ✓ | |||
| Dali3DHP [64] | 33 | 60,000 | ✓ | ✓ | |||
| McGill [65] | 60 | 60 | ✓ | ✓ | |||
| AFLW [66] | 21,997 | 25,993 | ✓ | ✓ | |||
| Multi-Pie [67] | 337 | 75,000 | ✓ | ✓ | ✓ | ✓ | |
| FacePix [61] | 30 | 5430 | ✓ | ✓ | |||
| FEI [68] | 200 | – | ✓ | ✓ | ✓ | ||
| FERET [69] | 1199 | 14,126 | ✓ | ✓ | |||
| CAS-PEAL [70] | 1040 | 100 K | ✓ | ✓ | ✓ | ||
| LFW [71] | 5749 | 13,233 | ✓ | ✓ | |||
| CelebA [72] | 10,000 | 200,000 | ✓ | ✓ | |||
| BJUT-3D [73] | 500 | – | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siddiqi, M.H.; Khan, K.; Khan, R.U.; Alsirhani, A. Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications. Electronics 2022, 11, 1210. https://doi.org/10.3390/electronics11081210
Siddiqi MH, Khan K, Khan RU, Alsirhani A. Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications. Electronics. 2022; 11(8):1210. https://doi.org/10.3390/electronics11081210
Chicago/Turabian StyleSiddiqi, Muhammad Hameed, Khalil Khan, Rehan Ullah Khan, and Amjad Alsirhani. 2022. "Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications" Electronics 11, no. 8: 1210. https://doi.org/10.3390/electronics11081210
APA StyleSiddiqi, M. H., Khan, K., Khan, R. U., & Alsirhani, A. (2022). Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications. Electronics, 11(8), 1210. https://doi.org/10.3390/electronics11081210