
Efficient Face Region Occlusion Repair Based on T-GANs


Abstract
:1. Introduction
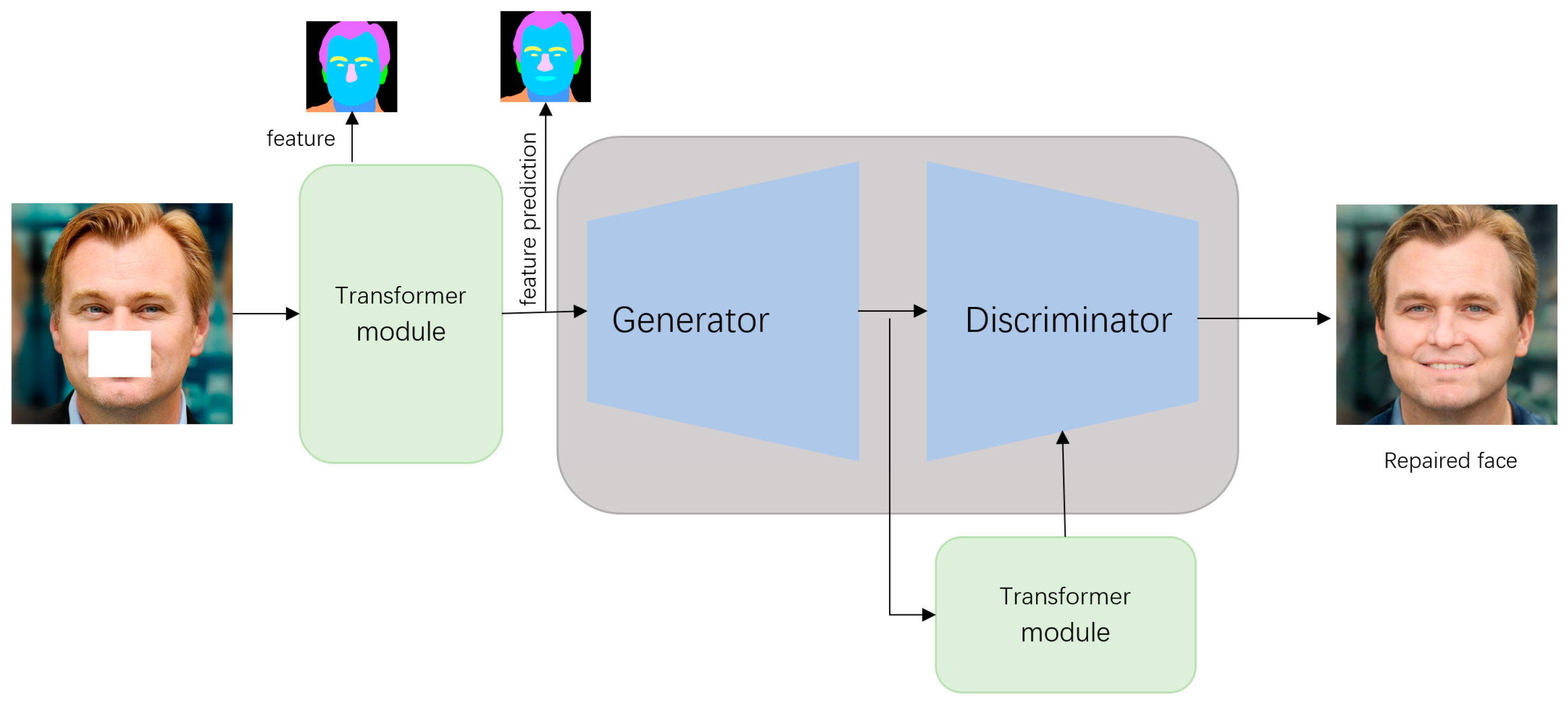
- We studied and proposed T-GANs for face image restoration generation tasks, which solved the inability of most GANs-based image generation networks in image local feature generation to achieve uniformity and natural fidelity of the generated image as a whole.
- In the network, add multiple transformer modules to confirm the missing features of the face before generating the local features of the face, and perform feature prediction. In the generative network, a discriminator is combined to perform local and global feature detection on the generated image.
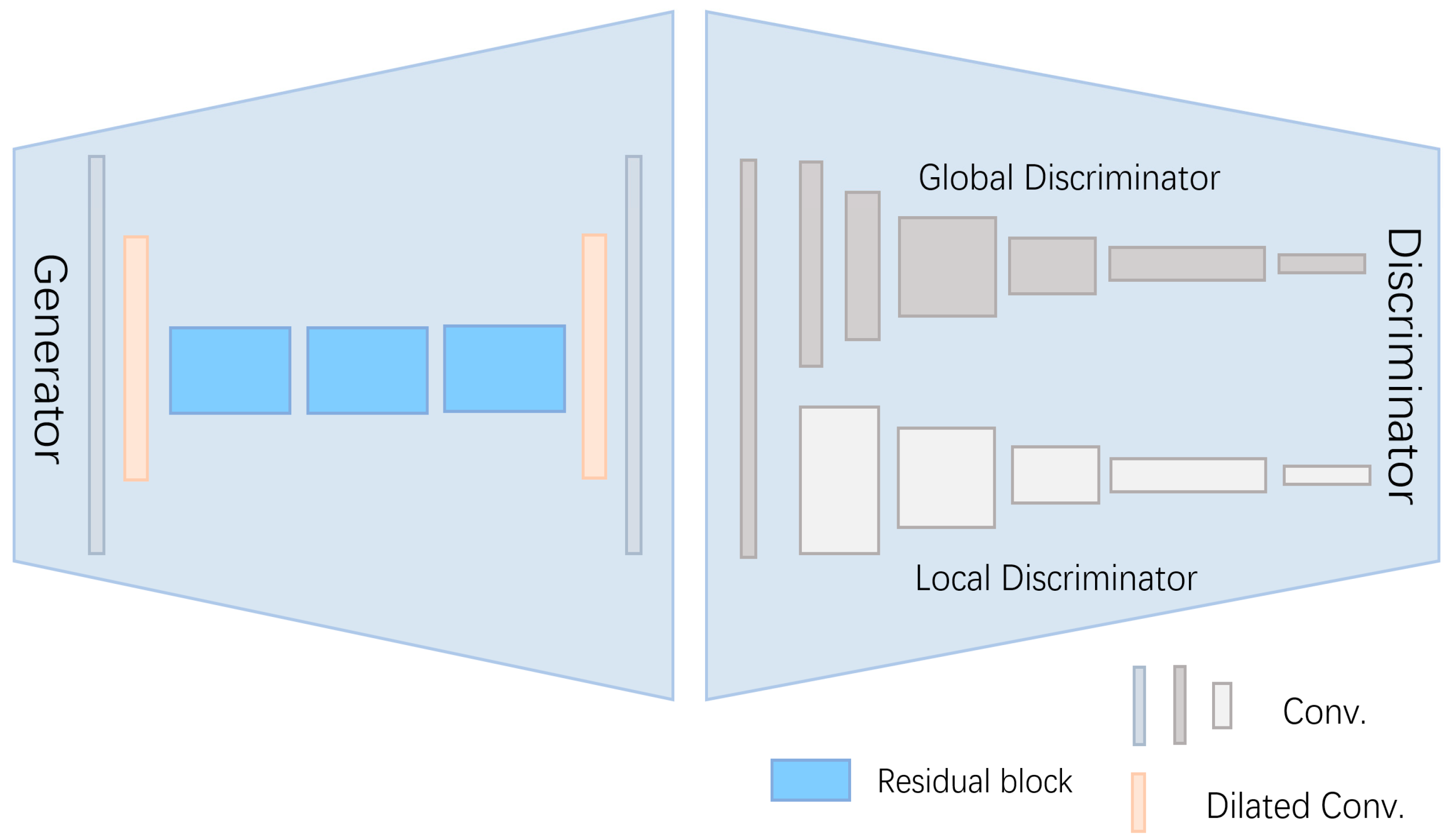
- In the generation network, the generator uses convolution and dilated convolution to generate facial features. In the discriminator, global and local dual discriminators are used for feature discrimination of the generated images.
- The proposed network is validated using several open-source datasets such as VGG Face, Celeba, FFHQ, and EDFace-Celeb as well as various image quality evaluation methods such as FID, PSNR, and SSIM.
2. Related Work
3. Methods
3.1. Transformer Module
3.2. Facial Restoration Generative Network
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Main Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Unmasking Face Embeddings by Self-restrained Triplet Loss for Accurate Masked Face Recognition. arXiv 2021, preprint. arXiv:2103.01716. [Google Scholar]
- Damer, N.; Grebe, J.H.; Chen, C.; Boutros, F.; Kirchbuchner, F.; Kuijper, A. The effect of wearing a mask on face recognition performance: An exploratory study. In Proceedings of the 19th International Conference of the Biometrics Special Interest Group, BIOSIG 2020, Online, 16–18 September 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016; IEEE Computer Society, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Ima-geNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 341–346. [Google Scholar]
- Efros, A.A.; Leung, T.K. Texture synthesis by non-parametric sampling. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1033–1038. [Google Scholar]
- Darabi, S.; Shechtman, E.; Barnes, C.; Goldman, D.B.; Sen, P. Image melding: Combining inconsistent images using patch-based synthesis. ACM Trans. Graph. 2012, 31, 1–10. [Google Scholar] [CrossRef]
- ACriminisi, P.P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Satoshi, I.; Edgar, S.S.; Hiroshi, I. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar]
- Wan, Z.; Zhang, J.; Chen, D.; Liao, J. High-Fidelity Pluralistic Image Completion with Transformers. arXiv 2021, preprint. arXiv:2103.14031. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPP), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Learning pyramid-context encoder network for high-quality image inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1486–1494. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Denton, E.; Gross, S.; Fergus, R. Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks. arXiv 2016, preprint. arXiv:1611.06430. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, preprint. arXiv:1409.1556. [Google Scholar]
- Yeh, R.A.; Chen, C.; Yian Lim, T.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 17–19 June 1997; pp. 5485–5493. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ballester, C.; Bertalmio, M.; Caselles, V.; Sapiro, G.; Verdera, J. Filling-in by joint interpolation of vector fields and gray levels. IEEE Trans. Image Process. 2001, 10, 1200–1211. [Google Scholar] [CrossRef]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Xu, Z.; Sun, J. Image inpainting by patch propagation using patch sparsity. IEEE Trans. Image Process. 2010, 19, 1153–1165. [Google Scholar] [PubMed]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database andWeb-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Liu, H.; Jiang, B.; Xiao, Y.; Yang, C. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4170–4179. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European conference on computer vision (ECCV), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1–17. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.-H. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3911–3919. [Google Scholar]
- Guo, X.; Yang, H.; Huang, D. Image inpainting via conditional texture and structure dual generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14134–14143. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Liu, W.; Li, H. Adversarial spatio-temporal learning for video deblurring. IEEE Trans. Image Process. 2018, 28, 291–301. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Zhang, P.; Zhang, K.; Luo, W.; Li, C.; Yuan, Y.; Wang, G. Multi-Prior Learning via Neural Architecture Search for Blind Face Restoration. arXiv 2022, preprint. arXiv:2206.13962. [Google Scholar]
- Zhang, P.; Zhang, K.; Luo, W.; Li, C.; Wang, G. Blind Face Restoration: Benchmark Datasets and a Baseline Model. arXiv 2022, preprint. arXiv:2206.03697. [Google Scholar]
- Wang, T.; Zhang, K.; Chen, X.; Luo, W.; Deng, J.; Lu, T.; Cao, X.; Liu, W.; Li, H.; Zafeiriou, S. A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal. arXiv 2022, preprint. arXiv:2211.02831. [Google Scholar]
- Ge, S.; Li, C.; Zhao, S.; Zeng, D. Occluded face recognition in the wild by identity-diversity inpainting. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3387–3397. [Google Scholar] [CrossRef]
- Xu, Z.; Yu, X.; Hong, Z.; Zhu, Z.; Han, J.; Liu, J.; Ding, E.; Bai, X. Facecontroller: Controllable attribute editing for face in the wild. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3083–3091. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, preprint. arXiv:1511.07122. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In BMVC 2015—Proceedings of the British Machine Vision Conference 2015; British Machine Vision Association: Durham, UK, 2015; pp. 1–12. [Google Scholar]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5549–5558. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4401–4410. [Google Scholar]
- Zhang, K.; Li, D.; Luo, W.; Liu, J.; Deng, J.; Liu, W.; Zafeiriou, S. EDFace-Celeb-1 M: Benchmarking Face Hallucination with a Million-scale Dataset. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, Santa Clara, CA, USA, 1 March 2023; Volume 45, pp. 3968–3978. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, preprint. arXiv:1412.6980. [Google Scholar]
- Song, L.; Cao, J.; Song, L.; Hu, Y.; He, R. Geometry-aware face completion and editing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2506–2513. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. Pluralistic image completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1438–1447. [Google Scholar]
- Ma, Y.; Liu, X.; Bai, S.; Wang, L.; Liu, A.; Tao, D.; Hancock, E.R. Regionwise generative adversarial image inpainting for large missing areas. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef] [PubMed]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, preprint. arXiv:1901.00212. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mask | |||||
|---|---|---|---|---|---|
| 10–20% | 20–30% | 30–40% | 40–50% | Center | |
| GAFC [43] | 7.29 | 15.76 | 26.41 | 38.85 | 7.50 |
| PIC [44] | 6.57 | 12.93 | 20.12 | 33.71 | 4.89 |
| Region Wise [45] | 7.05 | 15.53 | 24.58 | 31.47 | 8.75 |
| Edge Connect [46] | 5.37 | 9.24 | 17.35 | 27.41 | 8.22 |
| Ours | 4.35 | 7.23 | 12.41 | 17.29 | 4.91 |
| Mask | GAFC | PIC | Region Wise | Edge Connect | Ours | |
|---|---|---|---|---|---|---|
| PSNR | 10–20% | 27.51 | 30.33 | 30.58 | 30.73 | 35.17 |
| 20–30% | 24.42 | 27.05 | 26.83 | 27.55 | 29.53 | |
| 30–40% | 22.15 | 24.71 | 24.75 | 25.21 | 27.01 | |
| 40–50% | 20.30 | 22.45 | 22.38 | 23.50 | 25.27 | |
| center | 24.21 | 24.27 | 24.05 | 24.79 | 29.74 | |
| SSIM | 10–20% | 0.925 | 0.962 | 0.963 | 0.971 | 0.983 |
| 20–30% | 0.891 | 0.92.7 | 0.930 | 0.941 | 0.974 | |
| 30–40% | 0.832 | 0.886 | 0.889 | 0.905 | 0.939 | |
| 40–50% | 0.760 | 0.829 | 0.855 | 0.859 | 0.907 | |
| center | 0.865 | 0.869 | 0.871 | 0.874 | 0.925 |
| FLOPs | Time | |
|---|---|---|
| GAFC | 103.1 G | 1.74 s |
| PIC | 109.0 G | 1.62 s |
| Region Wise | 114.5 G | 1.82 s |
| Edge Connect | 122.6 G | 2.05 s |
| Ours | 95.5 G | 1.03 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Man, Q.; Cho, Y.-I. Efficient Face Region Occlusion Repair Based on T-GANs. Electronics 2023, 12, 2162. https://doi.org/10.3390/electronics12102162
Man Q, Cho Y-I. Efficient Face Region Occlusion Repair Based on T-GANs. Electronics. 2023; 12(10):2162. https://doi.org/10.3390/electronics12102162
Chicago/Turabian StyleMan, Qiaoyue, and Young-Im Cho. 2023. "Efficient Face Region Occlusion Repair Based on T-GANs" Electronics 12, no. 10: 2162. https://doi.org/10.3390/electronics12102162
APA StyleMan, Q., & Cho, Y. -I. (2023). Efficient Face Region Occlusion Repair Based on T-GANs. Electronics, 12(10), 2162. https://doi.org/10.3390/electronics12102162