
Nested Entity Recognition Fusing Span Relative Position and Region Information


Abstract
:1. Introduction
2. Related Work
2.1. Nested Named Entity Recognition
2.2. Word Pair Relationship Model
2.3. Collaborative Prediction
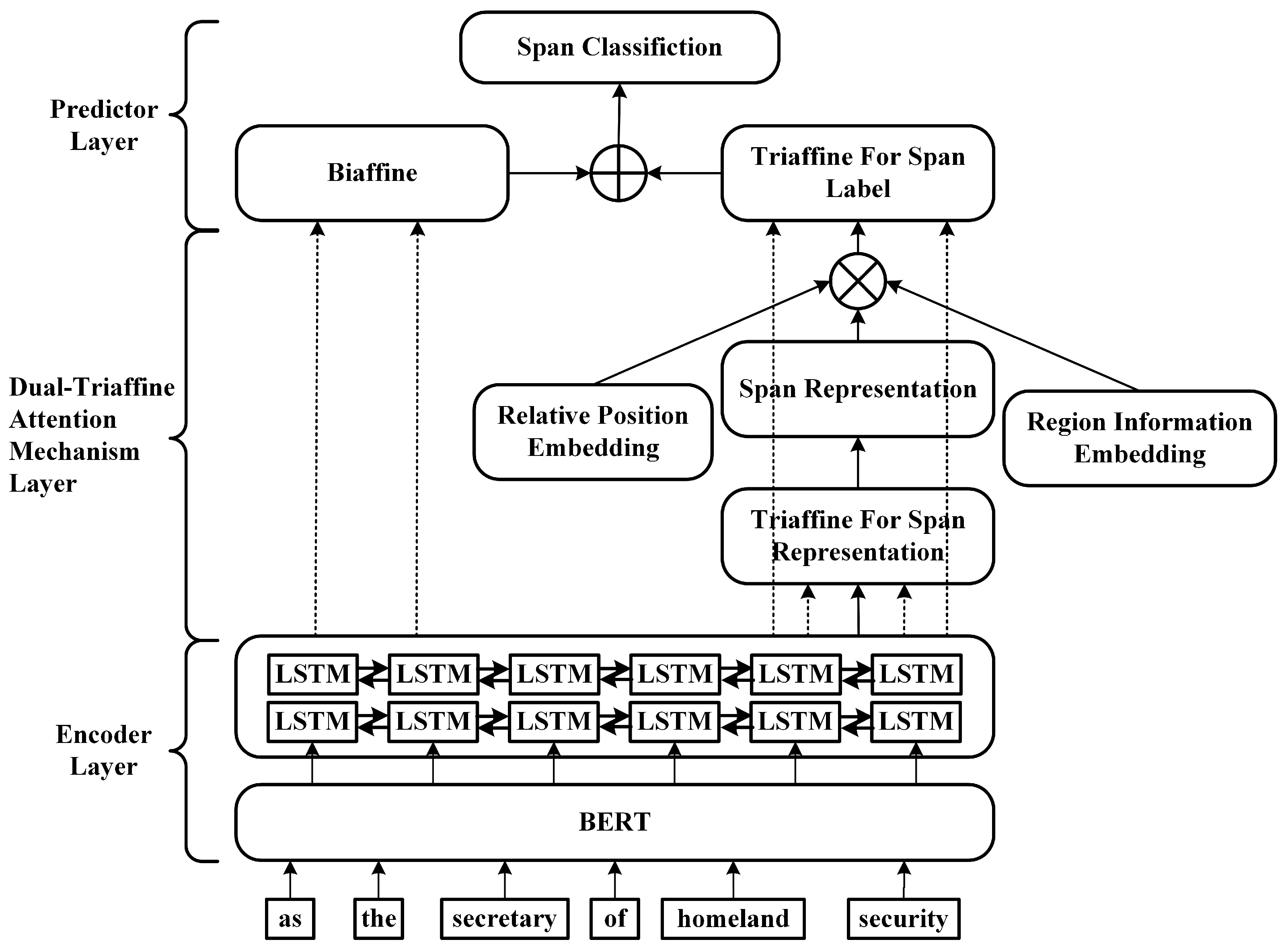
3. Model
3.1. Encoder Layer
3.2. Dual-Triaffine Attention Mechanism Layer
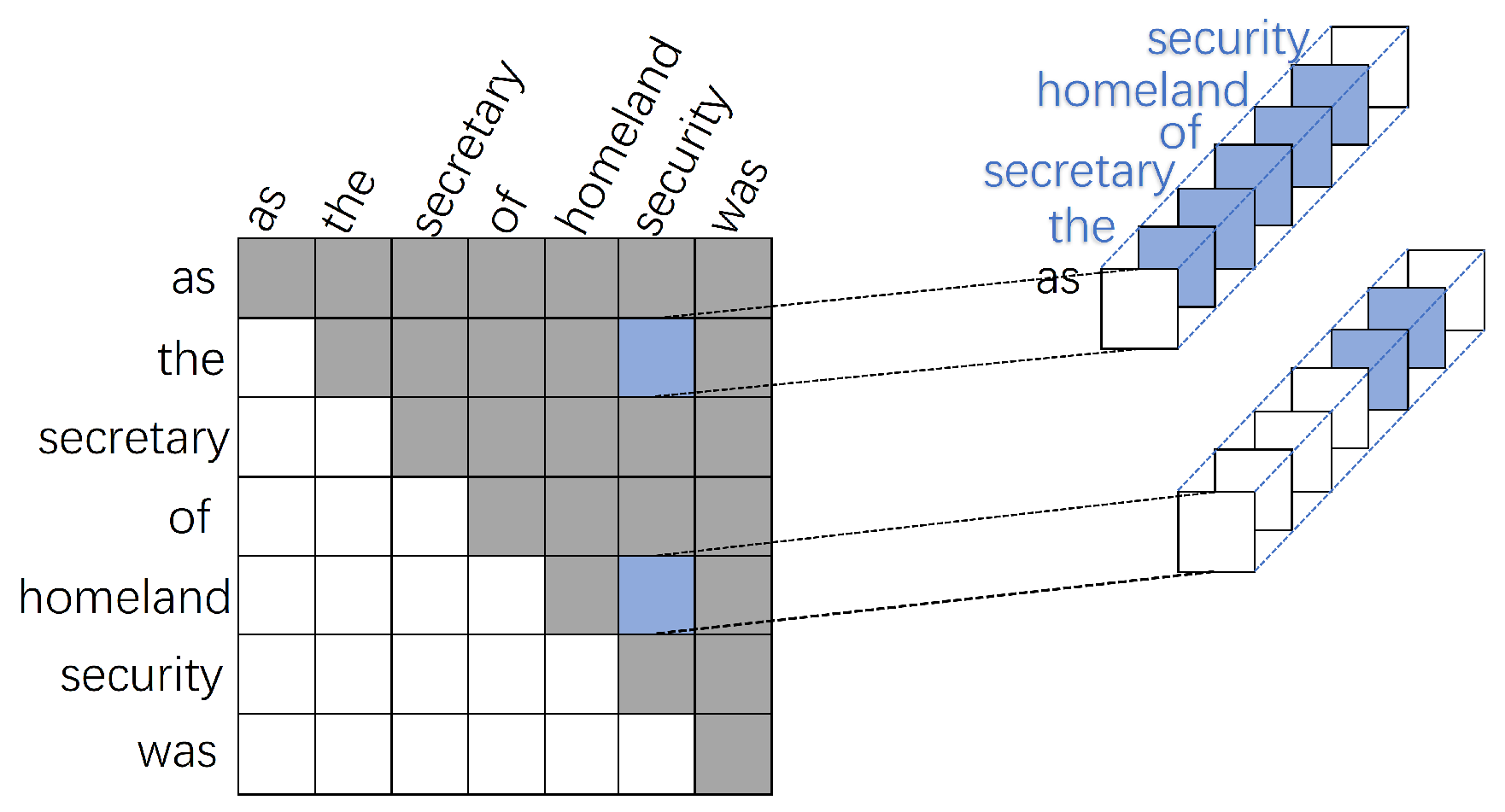
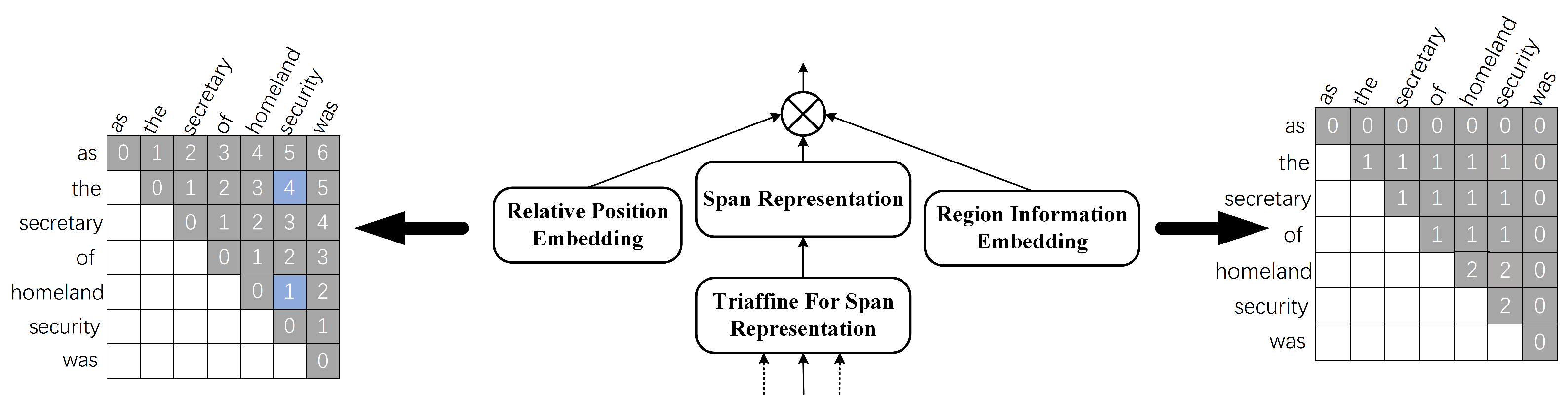
3.2.1. Triaffine Transformation
3.2.2. Dual-Triaffine Attention Mechanisms
3.3. Predictor Layer
3.3.1. Span Prediction
3.3.2. Biaffine Prediction
3.4. Loss Function
4. Experiment and Analysis
4.1. Dataset
4.2. Experiment Details
4.3. Baseline Approaches
4.4. Experimental Results and Analysis
4.4.1. Experiments on the Nested Entity Datasets
4.4.2. Experiments on the Flat Entity Datasets
4.5. Ablation Experiments
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lample, G.; Ballesteros, M.; Subramanian, S. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Yuan, Z.; Liu, Y.; Yin, Q. Unsupervised multi-granular Chinese word segmentation and term discovery via graph partition. J. Biomed. Inform. 2020, 110, 103542. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Shou, L.; Chen, K. Pyramid: A layered model for nested named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5918–5928. [Google Scholar]
- Ju, M.; Miwa, M.; Ananiadou, S. A neural layered model for nested named entity recognition. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 1446–1459. [Google Scholar]
- Fisher, J.; Vlachos, A. Merge and label: A novel neural network architecture for nested NER. arXiv 2019, arXiv:1907.00464. [Google Scholar]
- Shibuya, T.; Hovy, E. Nested named entity recognition via second-best sequence learning and decoding. Trans. Assoc. Comput. Linguist. 2020, 8, 605–620. [Google Scholar] [CrossRef]
- Muis, A.O.; Lu, W. Learning to recognize discontiguous entities. arXiv 2018, arXiv:1810.08579. [Google Scholar]
- Katiyar, A.; Cardie, C. Nested named entity recognition revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 861–871. [Google Scholar]
- Wang, B.; Lu, W. Neural segmental hypergraphs for overlapping mention recognition. arXiv 2018, arXiv:1810.01817. [Google Scholar]
- Gillick, D.; Brunk, C.; Vinyals, O. Multilingual language processing from bytes. arXiv 2015, arXiv:1512.00103. [Google Scholar]
- Straková, J.; Straka, M.; Hajič, J. Neural architectures for nested NER through linearization. arXiv 2019, arXiv:1908.06926. [Google Scholar]
- Zheng, C.; Cai, Y.; Xu, J. A boundary-aware neural model for nested named entity recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 357–366. [Google Scholar]
- Tan, C.; Qiu, W.; Chen, M. Boundary enhanced neural span classification for nested named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9016–9023. [Google Scholar]
- Yuan, Z.; Tan, C.; Huang, S. Fusing heterogeneous factors with triaffine mechanism for nested named entity recognition. arXiv 2021, arXiv:2110.07480. [Google Scholar]
- Yu, J.; Bohnet, B.; Poesio, M. Named entity recognition as dependency parsing. arXiv 2020, arXiv:2005.07150. [Google Scholar]
- Xia, C.; Zhang, C.; Yang, T.; Li, Y.; Du, N.; Wu, X.; Fan, W.; Ma, F.; Yu, P. Multi-grained Named Entity Recognition. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Wadden, D.; Wennberg, U.; Luan, Y.; Hajishirzi, H. Entity, Relation, and Event Extraction with Contextualized Span Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021. [Google Scholar]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Ostendorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001. [Google Scholar]
- Ronan, C.; Jason, W.; Léon, B.; Michael, K.; Koray, K.; Pavel, P.K. Natural Language Processing (almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2670–2680. [Google Scholar]
- Yan, H.; Deng, B.; Li, X.; Qiu, X. TENER: Adapting Transformer Encoder for Named Entity Recognition. arXiv 2019, arXiv:1911.04474. [Google Scholar]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER Using Flat-Lattice Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6836–6842. [Google Scholar]
- Yan, H.; Gui, T.; Dai, J.; Guo, Q.; Zhang, Z.; Qiu, X. A Unified Generative Framework for Various NER Subtasks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 5808–5822. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Fu, Y.; Tan, C.; Chen, M.; Huang, S.; Huang, F. Nested Named Entity Recognition with Partially-Observed TreeCRFs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 12839–12847. [Google Scholar]
- Li, J.; Fei, H.; Liu, J.; Wu, S.; Zhang, M.; Teng, C.; Ji, D.; Li, F. Unified Named Entity Recognition as Word-Word Relation Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 10965–10973. [Google Scholar]
- Li, J.; Xu, K.; Li, F.; Fei, H.; Ren, Y.; Ji, D. MRN: A Locally and Globally Mention-Based Reasoning Network for Document-Level Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1359–1370. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1554–1564. [Google Scholar]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X. A Lexicon-Based Graph Neural Network for Chinese NER. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1040–1050. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Huang, X. Simplify the Usage of Lexicon in Chinese NER. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5951–5960. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| ACE2004 | ACE2005 | GENIA | Resume | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Dev | Test | Train | Dev | Test | Train | Test | Train | Dev | Test | |
| Sentences | 6198 | 742 | 809 | 7285 | 968 | 1058 | 16,692 | 1854 | 36,487 | 6083 | 4472 |
| Entities | 22,204 | 2514 | 3035 | 24,827 | 3234 | 3041 | 50,509 | 5506 | 61,726 | 8969 | 7378 |
| Nested entities | 10148 | 1090 | 1415 | 9389 | 1110 | 1120 | 9064 | 1199 | |||
| Parameter Types | ACE2004, ACE2005 | GENIA |
|---|---|---|
| BERT name | BERT-large-uncased | BioBERT-v1.1 |
| BERT learning rate | 1 × 10 | 1 × 10 |
| BERT hidden size | 1024 | 768 |
| LSTM hidden size | 1024 | 512 |
| Triaffine hidden size | 512 | 512 |
| Epoch | 50 | 35 |
| Embedding dropout | 0.5 | 0.3 |
| Out dropout | 0.2 | 0.2 |
| Batch size | 8 | 8 |
| Distance embedding size | 20 | 20 |
| Region embedding size | 20 | 20 |
| Learning rate | 1 × 10 | 1 × 10 |
| Optimizer | AdamW | AdamW |
| Method | ACE2004 | ACE2005 | GENIA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | ||
| Luan et al. [19] | - | - | 84.7 | - | - | 82.9 | BERT | - | - | 76.2 |
| Xia et al. [16] | 81.7 | 77.4 | 79.5 | 79.0 | 77.3 | 78.2 | BERT | - | - | - |
| Tan et al. [13] | 85.8 | 84.8 | 85.3 | 83.8 | 83.9 | 83.9 | BERT | 79.2 | 77.4 | 78.3 |
| Fu et al. [27] | 86.7 | 86.5 | 86.6 | 84.5 | 86.4 | 85.4 | BERT | 78.2 | 78.2 | 78.2 |
| Yu et al. [15] | 87.3 | 86.0 | 86.7 | 85.2 | 85.6 | 85.4 | BERT | 81.8 | 79.3 | 80.5 |
| Wang et al. [3] | 86.08 | 86.48 | 86.28 | 83.95 | 85.39 | 84.66 | Bio-BERT | 79.63 | 78.38 | 79.00 |
| Straková et al. [11] | 84.71 | 83.96 | 84.33 | 82.58 | 84.29 | 83.42 | BERT | 79.92 | 76.55 | 78.20 |
| Shibuya et al. [6] | 85.23 | 84.72 | 84.97 | 83.30 | 84.69 | 83.99 | BERT | 77.46 | 76.65 | 77.05 |
| Yuan et al. [14] | 87.13 | 87.68 | 87.40 | 86.70 | 86.94 | 86.82 | Bio-BERT | 80.42 | 82.06 | 81.23 |
| Ours | 87.91 | 87.41 | 87.66 | 85.80 | 87.95 | 86.86 | Bio-BERT | 83.02 | 78.88 | 80.90 |
| GENIA | ACE2004 | |||
|---|---|---|---|---|
| Yuan et al. [14] | Ours | Yuan et al. [14] | Ours | |
| Total Parameters | 526,495,078 | 255,976,987 | 628,675,700 | 524,412,639 |
| Batch Size | 4 | 4 | 4 | 4 |
| BERT | Bio-BERT | Bio-BERT | BERT-large-uncased | BERT-large-uncased |
| Train Time (one epoch) | 17 min | 7 min | 6 min | 3.5 min |
| GPU Memory | 30 G | 19 G | 30 G | 30 G |
| LSTM Hidden Size | 1024 | 512 | 1024 | 1024 |
| F1 score | 80.33 | 80.90 | 87.11 | 87.66 |
| Resume | |||
|---|---|---|---|
| P | R | F1 | |
| Yan et al. (2019) [23] | - | - | 95.00 |
| Gui et al. (2019) [32] | 95.37 | 94.84 | 95.11 |
| Li et al. (2020) [24] | - | - | 95.86 |
| Ma et al. (2020) [33] | 96.08 | 96.13 | 96.13 |
| Li et al. (2022) [28] | 96.96 | 96.35 | 96.65 |
| Ours | 95.77 | 96.73 | 96.24 |
| ACE2005 | |||
|---|---|---|---|
| P | R | F1 | |
| case1 | 83.65 | 87.82 | 85.65 (−1.21) |
| case2 | 85.48 | 86.33 | 85.90 (−0.96) |
| case3 | 85.10 | 87.49 | 86.28 (−0.58) |
| case4 | 85.36 | 87.59 | 86.46 (−0.4) |
| Full model | 85.80 | 87.95 | 86.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Tang, T.; Sun, S.; Wu, Y.; Li, X. Nested Entity Recognition Fusing Span Relative Position and Region Information. Electronics 2023, 12, 2483. https://doi.org/10.3390/electronics12112483
Guo Y, Tang T, Sun S, Wu Y, Li X. Nested Entity Recognition Fusing Span Relative Position and Region Information. Electronics. 2023; 12(11):2483. https://doi.org/10.3390/electronics12112483
Chicago/Turabian StyleGuo, Yunqiao, Tinglong Tang, Shuifa Sun, Yirong Wu, and Xiaolong Li. 2023. "Nested Entity Recognition Fusing Span Relative Position and Region Information" Electronics 12, no. 11: 2483. https://doi.org/10.3390/electronics12112483
APA StyleGuo, Y., Tang, T., Sun, S., Wu, Y., & Li, X. (2023). Nested Entity Recognition Fusing Span Relative Position and Region Information. Electronics, 12(11), 2483. https://doi.org/10.3390/electronics12112483