


Patch-Based Difference-in-Level Detection with Segmented Ground Mask †

Abstract
:1. Introduction
- This paper proposes a method for difference-in-level detection that considers the explicit features of the differences using a machine learning technique. The proposed method accurately detects differences in level in various situations (e.g., where the ground is curved or mixed with differences in level of different sizes). In addition, as much as possible, we were able to detect differences in level using ground mask images;
- To reduce the work for manual annotation for detecting the differences in level of outdoor images, a method for automatically detecting some of the differences in level is adapted for generating datasets of image patches containing them. When creating the image patches of the normal map, the camera coordinate system of the acquired 3D point cloud was converted into a single world coordinate system, and then the normal vector was calculated. This made it easier to learn the features of the differences in level using normal vectors;
- The effectiveness of smartphones with depth cameras, which are becoming easier to use in practice, is demonstrated by experimental validation using an RGB-D camera.
2. Related Work
2.1. 3D Plane Segmentation from a Single Image
2.2. Difference-in-Level Detection
2.2.1. Use of RGB-D Images
2.2.2. Use of Convolutional Neural Network
2.3. Edge Detection from RGB-D Images with Deep Learning
3. Proposed Method
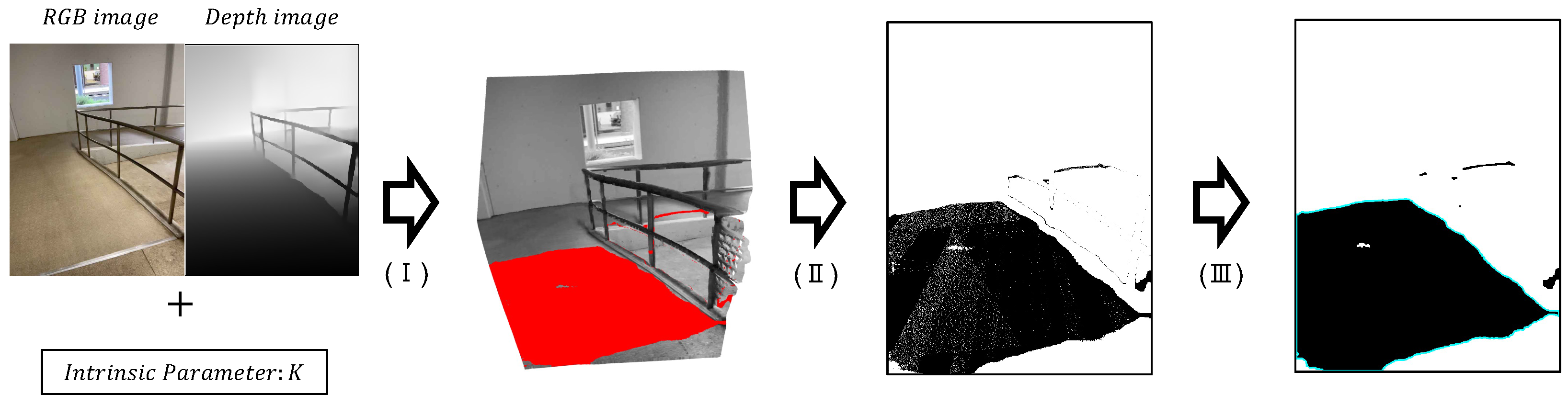
3.1. Difference-In-Level Detection for Creating the Dataset
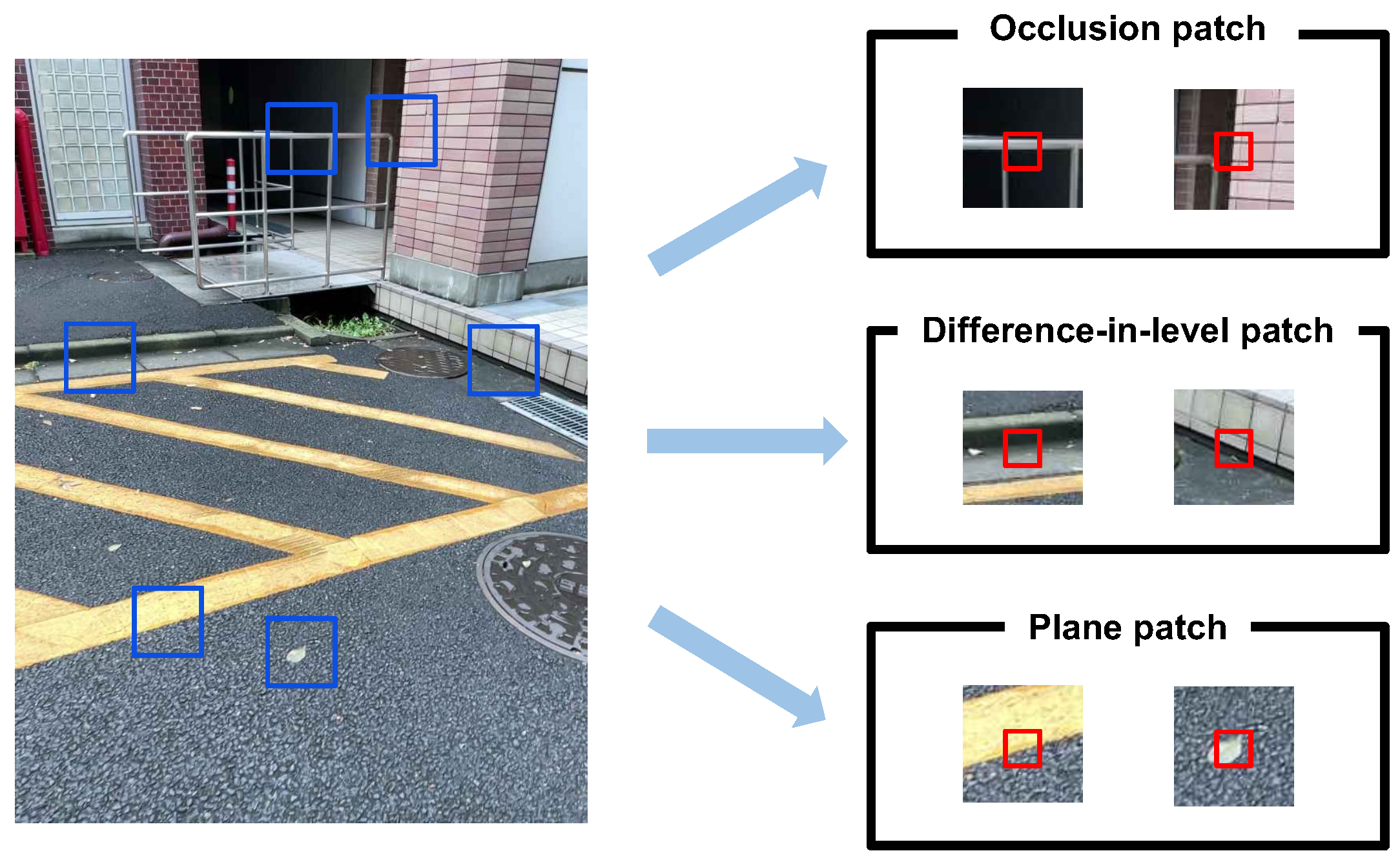
3.2. Patch-Based Difference-in-Level Detection with Segmented Ground Mask
- Occlusion patch: An occlusion patch contains central pixels that have an abrupt change in value in the depth map, such as a pipe or a corner;
- Difference-in-level patch: A difference-in-level patch contains the edges of differences in level. The edge of a difference in level is defined as a boundary line where the height suddenly changes from one plane to another;
- Plane patch: A plane patch is a patch of a plane in 3D space, such as a wall or a road.
4. Experiments
4.1. Dataset
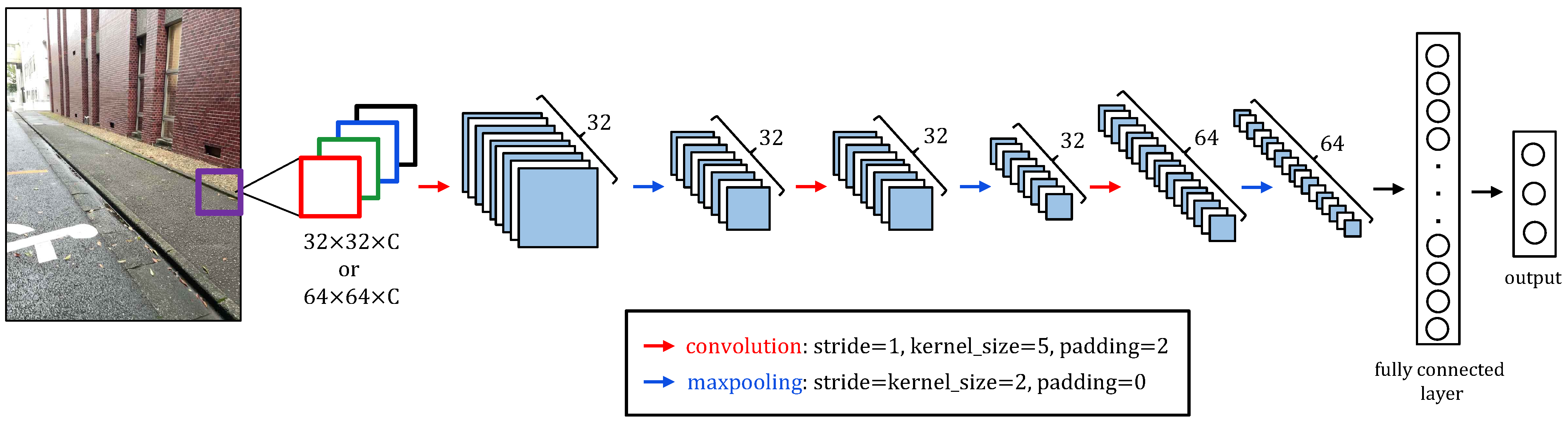
4.2. Network Training
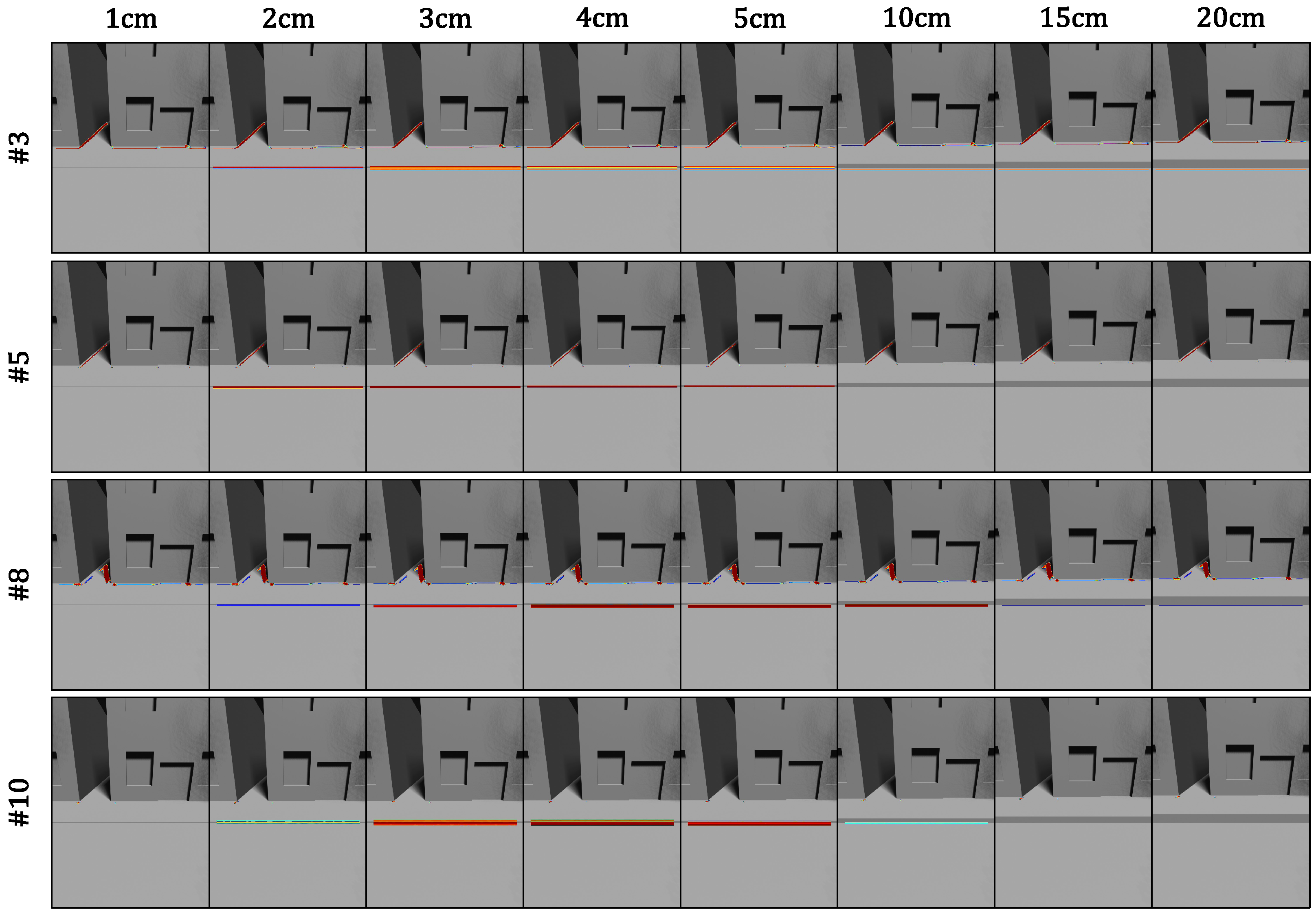
4.3. Difference-in-Level Detection on Various Inputs
4.3.1. Quantitative Evaluation
4.3.2. Qualitative Evaluation
4.4. Difference-in-Level Detection for Synthetic Test Images
- Precision: The percentage of patches that are actually difference-in-level patches out of those that are predicted;
- Recall: The percentage of patches that are predicted to be difference-in-level patches out of those that are actually difference-in-level patches;
- F1-Score: The harmonic mean of Precision and Recall.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
References
- Conde, M.V.; Vasluianu, F.; Vazquez-Corral, J.; Timofte, R. Perceptual Image Enhancement for Smartphone Real-Time Applications. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 1848–1858. [Google Scholar]
- Wang, P.; Wang, L.; Leung, H.; Zhang, G. Super-Resolution Mapping Based on Spatial–Spectral Correlation for Spectral Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2256–2268. [Google Scholar] [CrossRef]
- Xiao, W.; Zhang, Y.; Wang, H.; Li, F.; Jin, H. Heterogeneous Knowledge Distillation for Simultaneous Infrared-Visible Image Fusion and Super-Resolution. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Dong, J.; Pan, J.; Su, Z.; Yang, M.-H. Blind Image Deblurring with Outlier Handling. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2497–2505. [Google Scholar]
- Saleh, F.S.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M. Effective Use of Synthetic Data for Urban Scene Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, Y.; Shi, J.; Li, Y. Real-Time Semantic Understanding and Segmentation of Urban Scenes for Vehicle Visual Sensors by Optimized DCNN Algorithm. Appl. Sci. 2022, 12, 7811. [Google Scholar] [CrossRef]
- Guo, D.; Yang, G.; Qi, B.; Wang, C. Curb Detection and Compensation Method for Autonomous Driving via a 3-D-LiDAR Sensor. IEEE Sens. J. 2022, 22, 19500–19512. [Google Scholar] [CrossRef]
- Baek, I.; Tai, T.C.; Bhat, M.M.; Ellango, K.; Shah, T.; Fuseini, K.; Rajkumar, R.R. Curbscan: Curb detection and tracking using multi-sensor fusion. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Romero, L.M.; Guerrero, J.A.; Romero, G. Road Curb Detection: A Historical Survey. Sensors 2021, 21, 6952. [Google Scholar] [CrossRef] [PubMed]
- Imai, K.; Kitahara, I.; Kameda, Y. Detecting walkable plane areas by using RGB-D camera and accelerometer for visually impaired people. In Proceedings of the 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Copenhagen, Denmark, 7–9 June 2017; pp. 1–4. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Yanagihara, K.; Takefuji, H.; Sarakon, P.; Kawano, H. A method to detect steps on the sidewalks for supporting visually impaired people in walking. Proc. Fuzzy Syst. Symp. (Jpn. Soc. Fuzzy Theory Intell. Inf.) 2020, 36, 395–398. [Google Scholar]
- Nonaka, Y.; Uchiyama, H.; Saito, H.; Yachida, S.; Iwamoto, K. Difference-in-level Detection from RGB-D Images. In Proceedings of the International Symposium on Visual Computing (ISVC), San Diego, CA, USA, 3–5 October 2022; pp. 393–406. [Google Scholar]
- Liu, C.; Kim, K.; Gu, J.; Furukawa, Y.; Kautz, J. PlaneRCNN: 3D Plane Detection and Reconstruction From a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, Z.; Zheng, J.; Lian, D.; Zhou, Z.; Gao, S. Single-Image Piece-Wise Planar 3D Reconstruction via Associative Embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tan, B.; Xue, N.; Bai, S.; Wu, T.; Xia, G. PlaneTR: Structure-Guided Transformers for 3D Plane Recovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, C.; Yang, J.; Ceylan, D.; Yumer, E.; Furukawa, Y. PlaneNet: Piece-Wise Planar Reconstruction From a Single RGB Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, F.; Zhou, Z. Recovering 3D Planes from a Single Image via Convolutional Neural Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wang, S.; Pang, H.; Zhang, C.; Tian, Y. RGB-D image-based detection of stairs, pedestrian crosswalks and traffic signs. J. Vis. Commun. Image Represent. 2014, 25, 263–272. [Google Scholar] [CrossRef]
- Harms, H.; Rehder, E.; Schwarze, T.; Lauer, M. Detection of ascending stairs using stereo vision. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 2496–2502. [Google Scholar]
- Guerrero, J.J.; Pérez-Yus, A.; Gutiérrez-Gómez, D.; Rituerto, A.; López-Nicolás, G. Human navigation assistance with a RGB-D sensor. In Proceedings of the ACTAS V Congreso Internacional de Turismo Para Todos: VI Congreso Internacional de Diseno, Redes de Investigacion y Tecnologia para todos DRT4ALL, Madrid, Spain, 23–25 September 2015; pp. 285–312. [Google Scholar]
- Guerrero, J.J.; Pérez-Yus, A.; Gutixexrrez-Gómez, D.; Rituerto, A.; Lxoxpez-Nicolás, G. Stairs detection with odometry-aided traversal from a wearable RGB-D camera. Comput. Vis. Image Underst. 2017, 154, 192–205. [Google Scholar]
- Vu, H.; Hoang, V.; Le, T.; Tran, T.; Nguyen, T.T. A projective chirp based stair representation and detection from monocular images and its application for the visually impaired. Pattern Recognit. Lett. 2020, 137, 17–26. [Google Scholar] [CrossRef]
- Arunpriyan, J.; Variyar, V.V.S.; Soman, K.P.; Adarsh, S. Real-time speed bump detection using image segmentation for autonomous vehicles. In Proceedings of the Intelligent Computing, Information and Control Systems (ICICCS 2019), Madurai, India, 15–17 May 2019; Volume 1039. [Google Scholar]
- Lion, K.M.; Kwong, K.H.; Lai, W.K. Smart speed bump detection and estimation with kinect. In Proceedings of the 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 465–469. [Google Scholar]
- Fernández, C.; Gavilán, M.; Llorca, D.F.; Parra, I.; Quintero, R.; Lorente, A.G.; Vlacic, L.; Sotelo, M.A. Free space and speed humps detection using lidar and vision for urban autonomous navigation. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Madrid, Spain, 3–7 June 2012; pp. 698–703. [Google Scholar]
- Poma, X.S.; Riba, E.; Sappa, A. Dense extreme inception network: Towards a robust cnn model for edge detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1923–1932. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Sarkarand, S.; Venugopalan, V.; Reddy, K.; Ryde, J.; Jaitly, N.; Giering, M. Deep learning for automated occlusion edge detection in RGB-D frames. J. Signal Process. Syst. 2017, 88, 205–217. [Google Scholar] [CrossRef]
- Fischler, M.; Bolles, R. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Vojir, T.; Šipka, T.; Aljundi, R.; Chumerin, N.; Reino, D.O.; Matas, J. Road Anomaly Detection by Partial Image Reconstruction with Segmentation Coupling. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15631–15640. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Vizzo, I.; Chen, X.; Chebrolu, N.; Behley, J.; Stachniss, C. Poisson Surface Reconstruction for LiDAR Odometry and Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RGB | 3 | ✓ | ✓ | ✓ | ✓ | ||||||
| Gray Scale | 1 | ✓ | ✓ | ✓ | ✓ | ||||||
| Depth | 1 | ✓ | ✓ | ✓ | ✓ | ||||||
| Normal Vector | 3 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Channel Sum | − | 3 | 4 | 4 | 5 | 3 | 3 | 4 | 4 | 5 | 3 |
| Patch Size | − | 32 | 64 | ||||||||
| #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| macro-averaged Precision | 0.149 | 0.871 | 0.969 | 0.957 | 0.964 | 0.151 | 0.883 | 0.973 | 0.976 | 0.984 |
| macro-averaged Recall | 0.333 | 0.835 | 0.955 | 0.957 | 0.955 | 0.333 | 0.796 | 0.968 | 0.970 | 0.981 |
| macro-averaged F1-Score | 0.206 | 0.850 | 0.961 | 0.956 | 0.959 | 0.208 | 0.821 | 0.970 | 0.973 | 0.983 |
| #3 | #4 | #5 | #8 | #9 | #10 | |
|---|---|---|---|---|---|---|
| Precision | 0.331 | 0.599 | 0.512 | 0.196 | 0.0 | 0.327 |
| Recall | 0.780 | 0.486 | 0.684 | 0.470 | 0.0 | 0.693 |
| F1-Score | 0.456 | 0.534 | 0.560 | 0.274 | 0.0 | 0.432 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nonaka, Y.; Uchiyama, H.; Saito, H.; Yachida, S.; Iwamoto, K. Patch-Based Difference-in-Level Detection with Segmented Ground Mask. Electronics 2023, 12, 806. https://doi.org/10.3390/electronics12040806
Nonaka Y, Uchiyama H, Saito H, Yachida S, Iwamoto K. Patch-Based Difference-in-Level Detection with Segmented Ground Mask. Electronics. 2023; 12(4):806. https://doi.org/10.3390/electronics12040806
Chicago/Turabian StyleNonaka, Yusuke, Hideaki Uchiyama, Hideo Saito, Shoji Yachida, and Kota Iwamoto. 2023. "Patch-Based Difference-in-Level Detection with Segmented Ground Mask" Electronics 12, no. 4: 806. https://doi.org/10.3390/electronics12040806
APA StyleNonaka, Y., Uchiyama, H., Saito, H., Yachida, S., & Iwamoto, K. (2023). Patch-Based Difference-in-Level Detection with Segmented Ground Mask. Electronics, 12(4), 806. https://doi.org/10.3390/electronics12040806