1. Introduction
The size of the credit card market is growing steadily. In 2019, the number of credit cards in Korea was 110.98 million, up 5.92 million from the previous year. In other words, each economically active population in Korea had 3.9 units [
1]. In addition to policy support, such as income deductions, the use of credit cards has greatly expanded due to the increase in credit card preference for micropayment and simple payment services. Credit sales through credit cards accounted for only 13.7% of private final consumption expenditures in 2000 but have steadily risen since then, exceeding 70% [
2]. When combined with debit cards, the utilization rate of non-cash electronic payment methods in Korea reaches 90% [
3].
Accordingly, domestic credit card companies are changing their marketing methods to attract customers [
4]. In the early days of card industry growth, marketing focused on card issuance and loans. Now, personalized marketing methods that provide optimized services for each customer are being developed extensively [
5]. The mass method, which provides services to an unspecified number of people, is expensive, and the customer response rate is low. However, personalized marketing that properly understands customer interests and satisfies their needs can expect a high response rate at a relatively low cost.
Recently, in the credit card industry, the recommendation system has become an essential element for effective personalized marketing [
6]. This is because understanding individual tastes and payment patterns and recommending suitable products or stores based on that data can effectively lock in customers. Therefore, this study proposes a personalized recommendation system model that recommends merchants that customers are likely to use in the future by combining historical credit card payment data with customer and member store information.
The model proposed in this study is based on [
4], Neural Collaborative Filtering, which has been widely used in recent recommendation system research. The proposed model has three major changes.
First, unlike the existing model, which only reflects whether the user purchased the item, the customer’s demographic information was added to the learning data. This is because customers of the same gender and age group were expected to show similar payment patterns [
7].
Secondly, in order to reflect the unique characteristics of credit card payment data, information on the industry and region of merchants were added and learned together. The industry information is the most basic data representing the characteristics of the merchants, and regional information also acts as an important factor in understanding payment patterns. It is clear that recommending franchises in Busan to customers living in Seoul would reduce the possibility of future use [
8].
Third, the model can be applied to customers with low card usage. In the existing model, only data with more than twenty interactions between users and items were used. However, by lowering the criteria to two, this study implemented a model that can be applied to customers with many interactions and customers with few interactions. Customers were divided into three groups (High/Mid/Low) according to the number of affiliated stores they used, and performance was compared for each group [
9,
10].
3. Proposed Method
The model proposed in this study is based on the framework of [
4]. It is based on the Neural Matrix Factorization (NMF) structure that combines Generalized Matrix Factorization (GMF) and Multi-Layer Perceptron (MLP). In order to implement a model optimized for recommending potential payment merchants using credit card payment data, the following were reviewed [
4,
6,
7,
15,
16].
3.1. Performance Evaluation Method of Models That Reflect the Domain Information of Credit Card Payment Data
In order to recommend stores that a specific customer is likely to use in the future based on credit card payment data, it is important to understand the characteristics of the customer and the stores used by the customer. The most basic factors that can identify customer characteristics are gender and age information. This is because consumption patterns vary depending on gender, and the items consumed by age groups often vary. In addition, the industry information of a store is the most basic data that indicates the character of the store, and region information also plays a very important role in identifying customer consumption. For example, if a member store located in Busan is recommended to a customer living in Seoul, the possibility of actual consumption will decrease.
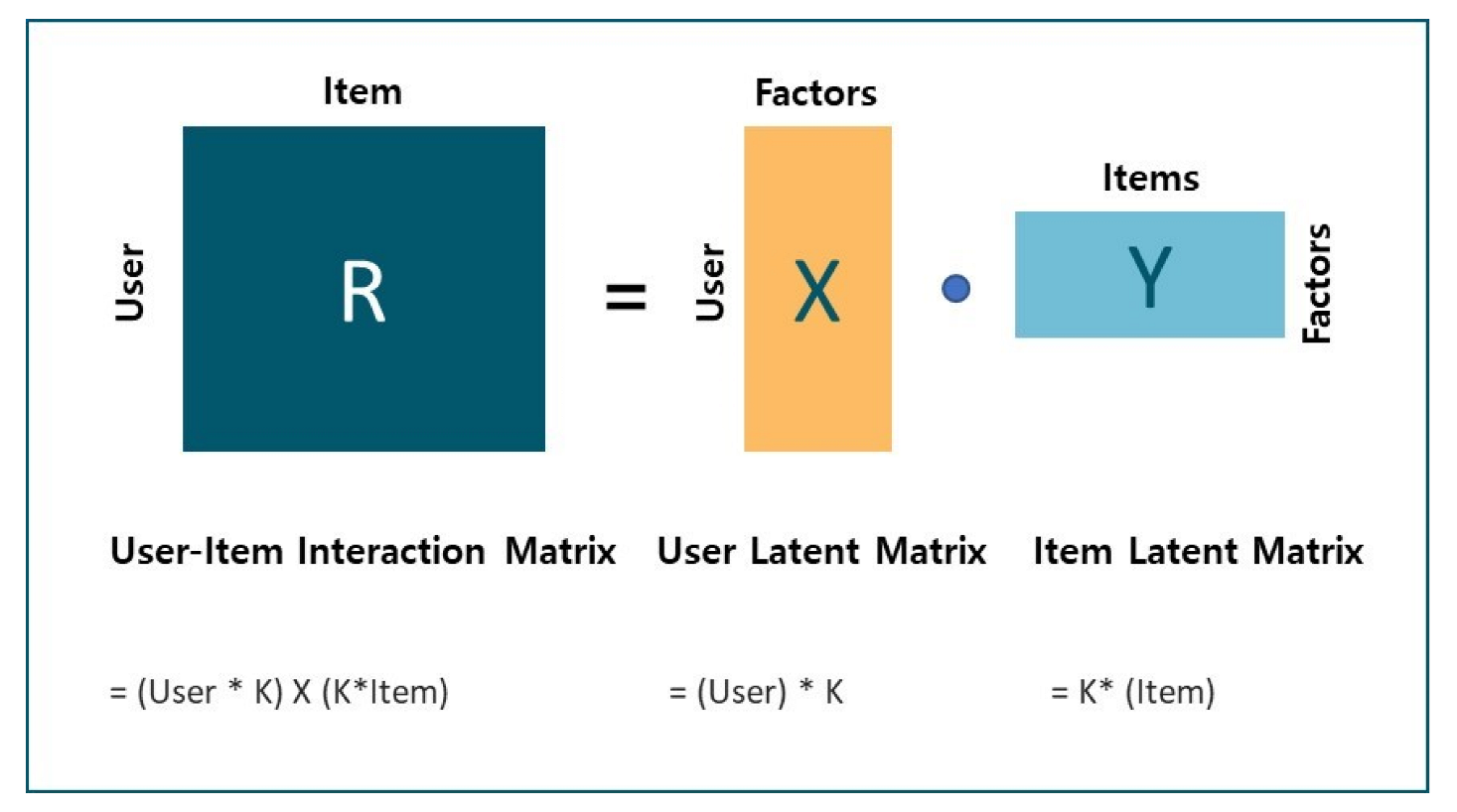
In the existing research [
4], the proposed model learns using only the user ID and item ID. However, when this structure is applied to card payment data as is, there is a limitation in that the major domain information required for the recommendation of the stores mentioned above is not reflected. To supplement this, this study implemented a model optimized for merchant recommendation by adding learning data and changing the model structure accordingly.
In the same way as
Figure 3 shows the structure proposed in the existing research model [
4], it was learned with only the customer ID and the store ID.
As
Figure 4 shows, Customer Information (gender, age) was added to the Base NMF to learn, and the Customer Latent Vector was calculated by combining Customer ID and Customer Information.
Store Information (industry, region) was added to the Base NMF to learn, and the Store Latent Vector was calculated by combining Store ID and Store Information as
Figure 5 shows.
As
Figure 6 shows, both Customer Information and Store Information were added to the Base NMF to learn, Customer ID and Customer Information were combined, and Store ID and Store Information were combined to calculate each Latent Vector.
3.2. Negative Sampling
When creating a recommendation system model, past feedback information is used to learn user preferences. In this process, information on both the products preferred and non-preferred by users is needed. However, there is no clear label for user preferences in Implicit Feedback Data, so it only gives information on whether or not to use items. Therefore, when learning the model, all products used by the user were assumed to be positive examples, and some products not used by the user were selected as negative examples. In this way, the process of selecting a sample among products not used by the user is Negative Sampling. As discussed in previous related studies, using negative samples is a way to improve the performance of the model by allowing the recommendation model to distinguish between negative samples that are close to the correct answer [
4,
6,
7].
In this study, Random Negative Sampling was used. Random Negative Sampling is a method of randomly selecting samples from all items not used. In the experiment, the model performance was compared while changing the number of negative samples.
3.3. Using a Pretrained Model
When training a model, initialization plays an important role in the performance of deep learning models. In the previous research [
4], it was proposed to initialize NeuMF using the Pretrained Model. Each GMF and MLP were trained until convergence through random initialization, and the learned parameter values of each model were used as the initial values parameter of the NeuMF model. After inputting the learned parameters into NeuMF, only the parameter part of the output layer, where the weights of the two models are combined, was learned. Adam was used for pretraining GMF and MLP, and vanilla SGD was used for NeuMF training. Adam needed to store appropriate momentum information when updating parameters, as this approach was not suitable for optimizing NeuMF.
3.4. Coverage Expansion to Low-Performing Customers
In the existing research model [
4], two datasets were used, MovieLens and Pinterest. In the MovieLens dataset, only users with at least 20 ratings were used, and in the Pinterest dataset, only users with more than 20 interactions were used for learning. However, when recommending merchants by using credit card payment data, recommendations should be made to customers with poor usage performance. Additionally, when marketing using the recommendation system, recommendations should also be made to customers with low usage. Thus, this study expanded the coverage to include low-performance customers. According to the number of stores used during the analysis period, customers were divided into three groups, High, Mid, and Low, and the performance of each was compared and evaluated. The top 10% of customers were classified as High, the bottom 30% of customers were classified as Low, and the remaining customers were classified as Mid. The criteria for dividing groups are as follows:
- (1)
High: Customers with more than 20 stores used;
- (2)
Mid: Customers with 6 to 20 stores used;
- (3)
Low: Customers with less than 5 stores used.
4. Experiments
4.1. Dataset Description
The data used in this study was the payment data from one domestic credit card company, and the analysis period was from November 2021 to March 2022. There were about 8 million customers with valid credit cards and about 1.6 million valid affiliated stores. Finally, 10,000 customers and 5000 affiliated stores were used for learning through sampling.
The criteria for sampling customers and stores were as follows. First of all, in the case of customers, after dividing into three groups according to the number of stores they used, high, mid, and low, 3000, 2000, and 1000 people were sampled, respectively, and the learning data was composed of a total of 10,000 customers. In the case of valid stores, learning may not be performed properly if very small franchises are included. Therefore, the number of customers who visited the store was limited to the top 5000 based on payment data for the last month.
Finally, in order to reflect the domain information of the credit card payment data, the customer’s gender and age information and the store’s industry and region information were added. For the industry information of stores, categories based on our company’s standard code were used, and regional information was used in units of cities and counties.
4.2. Evaluation Metrics
In this study, HR@5, HR@10, HR@20, NDCG@5, NDCG@10, and NDCG@20 were used as performance indicators.
4.2.1. HR@K (Hit Rate)
HR@K is an index indicating the number of hit users among all users, and the formula is as follows:
4.2.2. NDCG@K (Normalized Discounted Cumulative Gain)
NDCG@K is an indicator of how good the current recommendation list is compared to the ideal combination and has a value between 0 and 1. The closer it is to 1, the better the performance.
4.3. Experimental Results
For performance comparison with the basic structural model, the GMF, MLP, and NeuMF models proposed in [
4] were measured by learning only the Customer ID and Store ID of the credit card payment data in the same way as [
4]. The results are shown in
Table 1.
4.3.1. Baselines
As with the results in [
4], it was confirmed that most of the performance was high in NeuMF. Therefore, based on the NeuMF model structure, the major domain information of credit card payment data was sequentially reflected.
4.3.2. Models That Reflect the Domain Information of Credit Card Payment Data
The NeuMF (Base NMF) model discussed above has a structure that uses only Customer ID and Store ID as input data. In order to reflect the important domain information of payment data, the NMF_CI model with customer information added, the NMF_SI model with the store information added, and the NMF_CSI model with both customer information and store information were sequentially trained to measure the performance. The experimental results are shown in
Table 2.
The performance of NMF_CI with customer information was slightly lower than that of Base NMF, but the performance of NMF_SI with store information was improved, and it was confirmed that the NMF_CSI model, with both customer information and store information, was the highest in all evaluation indicators. Since the number of recommendations, K, was set to 10 in the primary research on recommendation systems, we compared the results of HR@10 and NDCG@10 [
17,
18,
19].
In addition, the performance of each customer group (High/Mid/Low) was as
Table 3 and
Table 4 show.
When comparing HR@10 and NDCG@10 values for each customer group, the NMF_CSI model also showed the best performance. Through this, it can be confirmed that it is more effective to learn the interaction between customers and stores by learning the customer’s gender/age information and the store’s industry/region information together.
Performance by group was high in the order of High > Mid > Low in all models. In other words, it can be said that the more active the card user is, the more accurate the provided recommendation is. However, the results of the NMF_CSI model showed that the HR@10 value of the group Low was 0.7565, and the NDCG@10 value was 0.5279, which was not much different from the NeuMF results (HR@10: 0.7688, NDCG@10: 0.5408) in
Table 1. Therefore, the merchant recommendation model proposed in this study shows that it is possible to expand and apply coverage to low-performance customers.
4.3.3. Model Comparison by the Number of Negative Samples
The Loss Function can be divided into the Pointwise method and the Pairwise method according to the number of items considered at once when learning the model. The Pointwise method considers one item at a time. Scores are obtained for all items and ranked by sorting. In the case of the Pairwise method, two items are considered as pairs at a time. It is a method of finding an optimized order in which the answer list and pairs match.
When using the Pairwise method, only one negative instance should be considered for one positive instance, but in this study, the sampling ratio for negative samples can be freely set because negative instances were learned together using Pointwise log loss.
Even with negative sampling, the performance of NMF_CSI was the best, and the performance was compared by changing the number of negative samples learned at once for the NMF_CSI model. The results are shown in
Table 5. Initially, the performance seemed to improve as the sampling ratio increased, but it was confirmed that if there were more than seven, the performance decreased. The optimal sampling ratio ranges from three to six.
4.3.4. Comparison of Models with or without the Pretrained Model
After learning using the pretrained model of GMF and MLP, the performance was compared. In both HR@10 and NDCG@10, using the pretrained model was higher. Each result is shown in
Table 6.
5. Conclusions
As the market for credit card payments has grown, the importance of personalized recommendations has increased in the credit card industry. However, if deep learning recommendation methods based on content recommendation, collaborative filtering, or simple user-item interaction are applied as is, there is a limit to the reflection of the main domain characteristics of credit card payment data. Therefore, in this study, we reconstructed learning data by adding customer gender and age information, merchant industry, and region information to implement a model optimized for recommending merchants with a high possibility of future payment by using credit card payment data. We have also expanded our coverage so that these results can be applied to underperforming customers. To verify the excellence of the NM_CSI model proposed in this study, payment data from a credit card company with more than 8 million customers collected in Korea was used. As a result of c experiments comparing the basic NMF model and the proposed NM_CSI model, performance improved by 3% based on HR@10 and 5% when based on NDCG@10. These results are expected to be used in various ways for research on affiliate store recommendations using credit card payment data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}