
Two-Stage Generator Network for High-Quality Image Inpainting in Future Internet

Abstract
:1. Introduction
- (1)
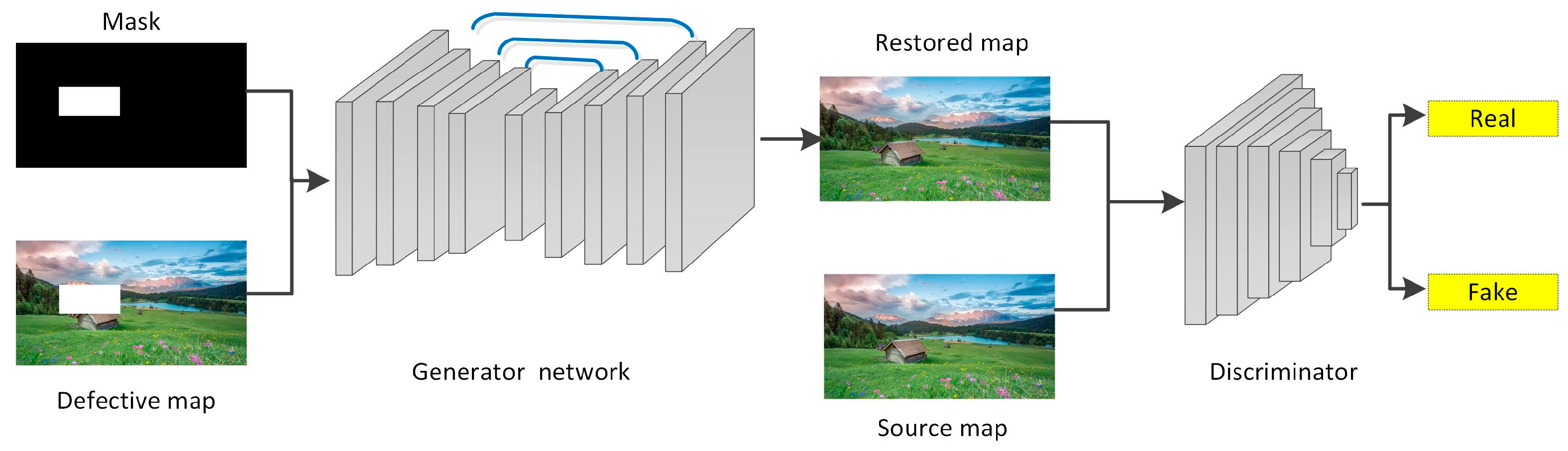
- We present a high-quality image inpainting network derived from Transformer, which is a two-stage generator model based on the encoder-decoder network.
- (2)
- We apply the adaptive multi-head attention mechanism to the fine network to control the input of the features in order to reduce the computation overhead.
- (3)
- We fuse the pyramid and perception as the loss function of the generator network to improve the overall efficiency.
2. Related Work
2.1. GAN
2.2. Image Inpainting
2.3. Self-Attentive Mechanism
2.4. Pyramid Loss
2.5. Perceptual Loss
3. Methodology
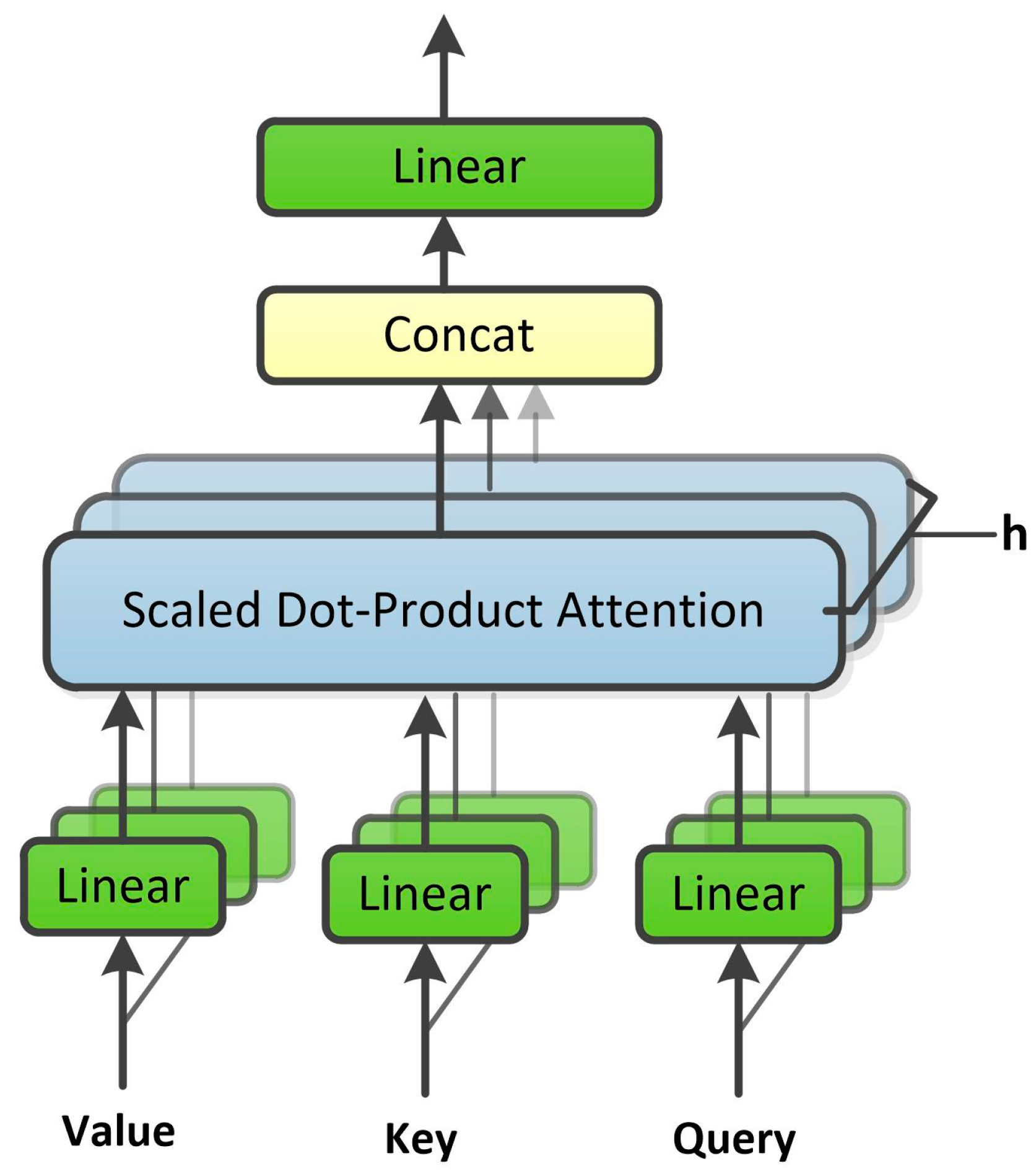
3.1. Adaptive Multi-Head Attention Mechanism
3.2. Network Structure Based on Transformer
3.3. Loss Functions
4. Experiments
4.1. Experimental Settings
4.2. Quality Assessment
4.3. Quantitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, J.; Kang, S.; Ahuja, N.; Kopf, J. Image completion using planar structure guidance. ACM Trans. Graph. (TOG) 2014, 33, 1–10. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Image completion approaches using the statistics of similar patches. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2423–2435. [Google Scholar] [CrossRef]
- Li, H.; Hu, L.; Hua, Q.; Yang, M.; Li, X. Image Inpainting Based on Contextual Coherent Attention GAN. J. Circuits Syst. Comput. 2022, 31, 2250209. [Google Scholar] [CrossRef]
- Jam, J.; Kendrick, C.; Walker, K.; Drouard, V.; Hsu, J.G.S.; Yap, M. A comprehensive review of past and present image inpainting methods. Comput. Vis. Image Underst. 2021, 203, 103147. [Google Scholar] [CrossRef]
- Qin, Z.; Zeng, Q.; Zong, Y.; Xu, F. Image inpainting based on deep learning: A review. Displays 2021, 69, 102028. [Google Scholar] [CrossRef]
- Zhang, X.; Zhai, D.; Li, T.; Zhou, Y.; Yang, L. Image inpainting based on deep learning: A review. Inf. Fusion 2023, 90, 74–94. [Google Scholar] [CrossRef]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’00, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar] [CrossRef]
- Yan, J.; Chen, B.; Guo, R.; Zeng, M.; Yan, H.; Xu, Z.; Wang, Y. Tongue Image Texture Classification Based on Image Inpainting and Convolutional Neural Network. Comput. Math. Methods Med. 2022, 2022, 6066640. [Google Scholar] [CrossRef]
- Pathak, A.; Karmakar, J.; Nandi, D.; Mandal, M.K. Feature enhancing image inpainting through adaptive variation of sparse coefficients. Signal Image Video Process. 2022, 1–9. [Google Scholar] [CrossRef]
- Criminisi, A.; Pérez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Guleryuz, O. Nonlinear approximation based image recovery using adaptive sparse reconstructions and iterated denoising-part I: Theory. IEEE Trans. Image Process. 2006, 15, 539–554. [Google Scholar] [CrossRef]
- Li, Z.; Chen, A.; Miao, T. A fingerprint removal method based on fractal–criminisi technology. Fractals 2022, 30, 2250157. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Neural Information Processing Systems; MIT Press: Montreal, QC, Canada, 2014. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Shi, C.; Yan, Z.; Li, X.; Kong, B. De-gan: Domain embedded gan for high quality face image inpainting. Pattern Recognit. 2022, 124, 108415. [Google Scholar] [CrossRef]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated contextual transformations for high-resolution image inpainting. IEEE Trans. Vis. Comput. Graph. 2022. [Google Scholar] [CrossRef]
- Sun, T.; Fang, W.; Chen, W.; Yao, Y.; Bi, F.; Wu, B. High-resolution image inpainting based on multi-scale neural network. Electronics 2019, 8, 1370. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. Comput. Ence 2015, 1511, 06434. [Google Scholar]
- Chen, X.; Zhao, J. Improved semantic image inpainting method with deep convolution generative adversarial networks. Big Data 2022, 10, 506–514. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Wang, H.; Wang, J.; Wang, Y.; He, F.; Zhang, J. SA-Net: A scale-attention network for medical image segmentation. PLoS ONE 2021, 16, e0247388. [Google Scholar] [CrossRef]
- Rong, L.; Li, C. Coarse-and fine-grained attention network with background-aware loss for crowd density map estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3675–3684. [Google Scholar]
- Guan, S.; Hsu, K.T.; Eyassu, M.; Chitnis, P.V. Dense dilated UNet: Deep learning for 3D photoacoustic tomography image reconstruction. arXiv 2021, arXiv:2104.03130. [Google Scholar]
- Jing, J.; Wang, Z.; Rätsch, M.; Zhang, H. Mobile-Unet: An efficient convolutional neural network for fabric defect detection. Text. Res. J. 2020, 92, 30–42. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Zeng, Y.; Lin, Z.; Yang, J.; Zhang, J.; Shechtman, E. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In European Conference on Computer Vision 2020; Springer: Cham, Switzerland, 2020; pp. 1–17. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lui, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kaur, G.; Sinha, R.; Tiwari, P.K.; Yadav, S.K.; Pandey, P.; Raj, R.; Rakhra, M. Face mask recognition system using CNN model. Neurosci. Inform. 2022, 2, 100035. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.; Zhang, Z.; Fang, Z. An effective CNN and Transformer complementary network for medical image segmentation. Pattern Recognit. 2023, 136, 109228. [Google Scholar] [CrossRef]
- Han, Q.; Liu, J.; Jung, C. Lightweight generative network for image inpainting using feature contrast enhancement. IEEE Access 2022, 10, 86458–86469. [Google Scholar] [CrossRef]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 47–60. [Google Scholar] [CrossRef]
- Li, H.; Zheng, Q.; Yan, W.; Tao, R.; Wen, Z. Image super-resolution reconstruction for secure data transmission in Internet of Things environment. Math. Biosci. Eng. 2021, 18, 6652–6672. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative adversarial networks (GANs) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 2022, 200, 107208. [Google Scholar] [CrossRef]
- Xiang, H.; Zou, Q.; Nawaz, M.A.; Huang, X.; Zhang, F.; Yu, H. Deep learning for image inpainting: A survey. Pattern Recognit. 2023, 134, 109046. [Google Scholar] [CrossRef]
- Sun, Q.; Zhai, R.; Zuo, F.; Zhong, Y.; Zhang, Y. A Review of Image Inpainting Automation Based on Deep Learning. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2203, p. 012037. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Learning pyramid-context encoder network for high-quality image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. SegAN: Adversarial network with multi-scale L1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Tao, C.; Gao, S.; Shang, M.; Wu, W.; Zhao, D.; Yan, R. Get The Point of My Utterance! Learning Towards Effective Responses with Multi-Head Attention Mechanism. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4418–4424. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Liu, G.; Reda, F.; Shih, K. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Chen, C.; Fragonara, L.; Tsourdos, A. GapNet: Graph attention based point neural network for exploiting local feature of point cloud. arXiv 2019, arXiv:1905.08705. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | MAX PSNR/dB | MIN PSNR/dB | AVE PSNR/dB |
|---|---|---|---|
| Partial | 30.75 | 28.86 | 29.12 |
| Pennet | 32.75 | 30.86 | 31.72 |
| GapNet | 34.27 | 32.37 | 33.55 |
| Ours | 37.38 | 34.98 | 36.13 |
| Network Model | MAX SSIM/% | MIN SSIM/% | AVE SSIM/% |
|---|---|---|---|
| Partial | 69.61 | 62.42 | 68.23 |
| Pennet | 78.02 | 73.56 | 75.75 |
| GapNet | 90.08 | 85.01 | 88.13 |
| Ours | 94.96 | 89.66 | 92.09 |
| Network Model | MAX PSNR/dB | MIN PSNR/dB | AVE PSNR/dB |
|---|---|---|---|
| non-transformer two-layer network + loss function | 32.84 | 30.62 | 31.95 |
| two-layer network transformer + loss function | 37.20 | 34.36 | 35.27 |
| two-layer transformer + adaptive multi-head attention mechanism | 35.79 | 34.67 | 35.29 |
| two-layer transformer + adaptive multi-head attention mechanism + loss function | 37.38 | 34.98 | 36.13 |
| Network Model | MAX SSIM/% | MIN SSIM/% | AVE SSIM/% |
|---|---|---|---|
| non-transformer two-layer network + loss function | 84.12 | 79.68 | 82.11 |
| two-layer network transformer + loss function | 93.25 | 84.97 | 89.19 |
| two-layer transformer + adaptive multi-head attention mechanism | 91.09 | 84.18 | 89.27 |
| two-layer transformer + adaptive multi-head attention mechanism + loss function | 94.96 | 89.66 | 92.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, P.; Zhang, D.; Geng, S.; Zhou, M. Two-Stage Generator Network for High-Quality Image Inpainting in Future Internet. Electronics 2023, 12, 1490. https://doi.org/10.3390/electronics12061490
Zhao P, Zhang D, Geng S, Zhou M. Two-Stage Generator Network for High-Quality Image Inpainting in Future Internet. Electronics. 2023; 12(6):1490. https://doi.org/10.3390/electronics12061490
Chicago/Turabian StyleZhao, Peng, Dan Zhang, Shengling Geng, and Mingquan Zhou. 2023. "Two-Stage Generator Network for High-Quality Image Inpainting in Future Internet" Electronics 12, no. 6: 1490. https://doi.org/10.3390/electronics12061490
APA StyleZhao, P., Zhang, D., Geng, S., & Zhou, M. (2023). Two-Stage Generator Network for High-Quality Image Inpainting in Future Internet. Electronics, 12(6), 1490. https://doi.org/10.3390/electronics12061490