
RSP-DST: Revisable State Prediction for Dialogue State Tracking

Abstract
:1. Introduction
2. Related Work
3. Methods
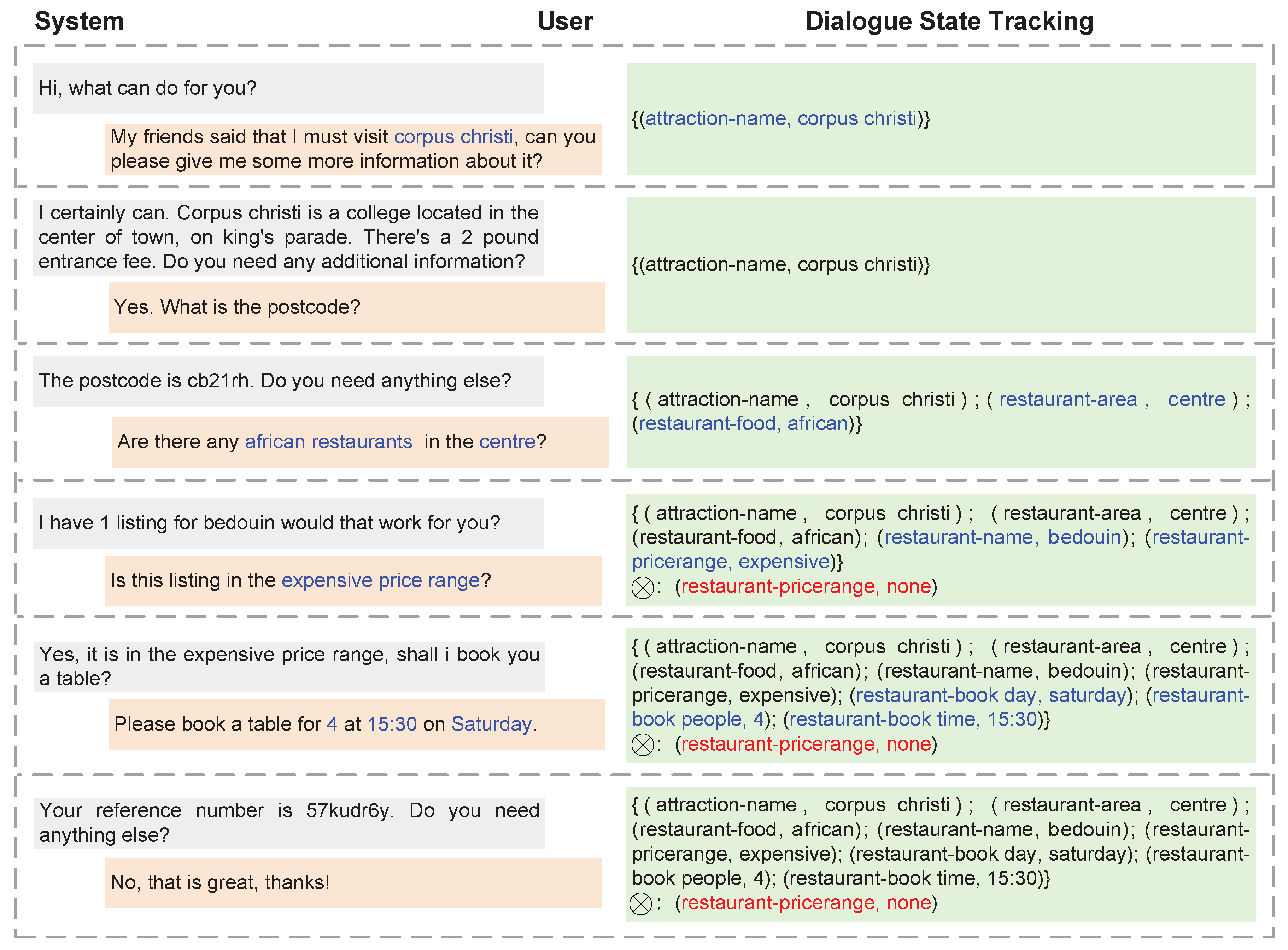
3.1. Problem Definition
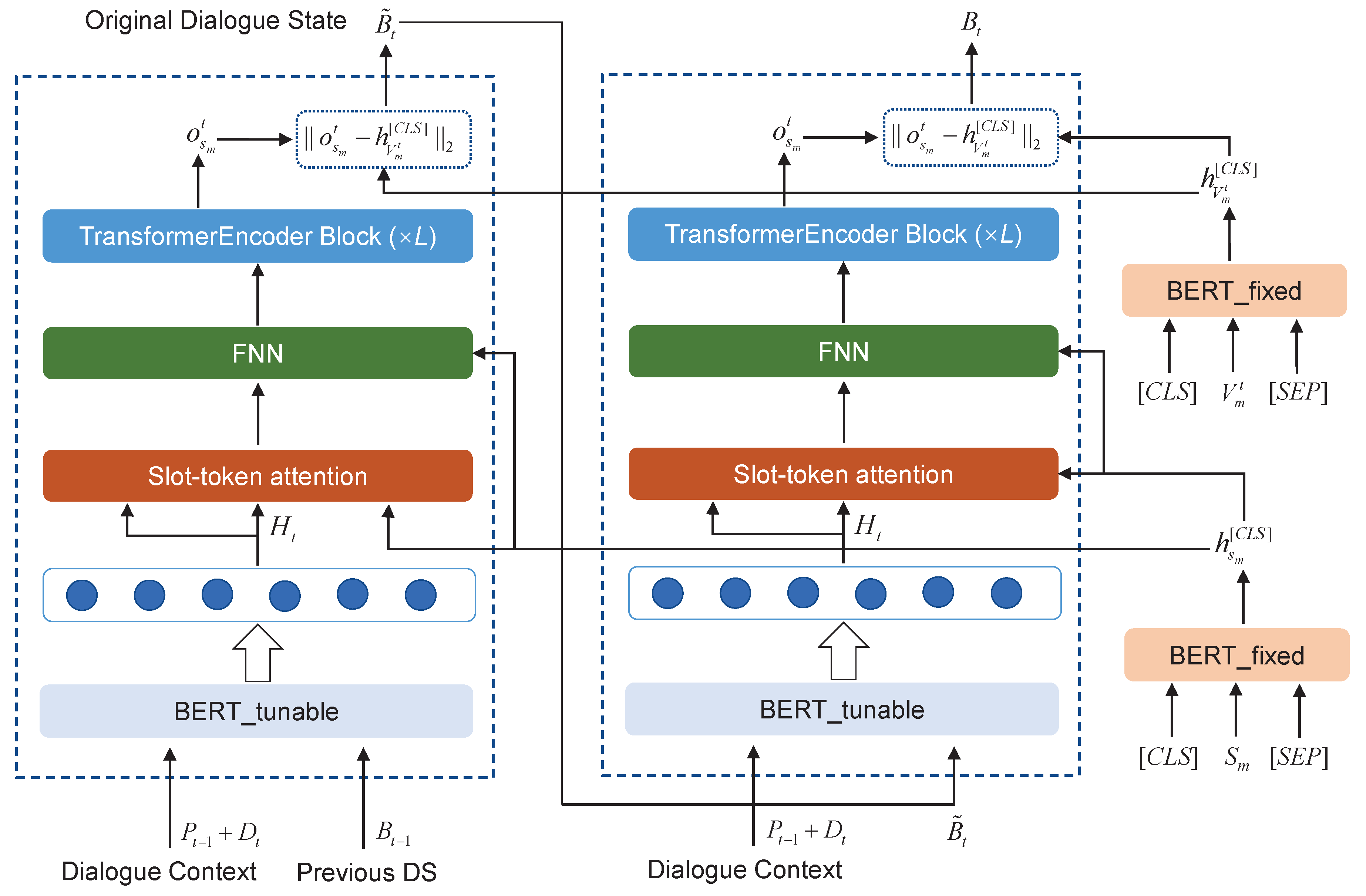
3.2. Original Dialogue State Prediction
3.2.1. Dialogue Context Encoder
3.2.2. Slot and Value Encoder
3.2.3. Slot Attention
3.2.4. Value Prediction
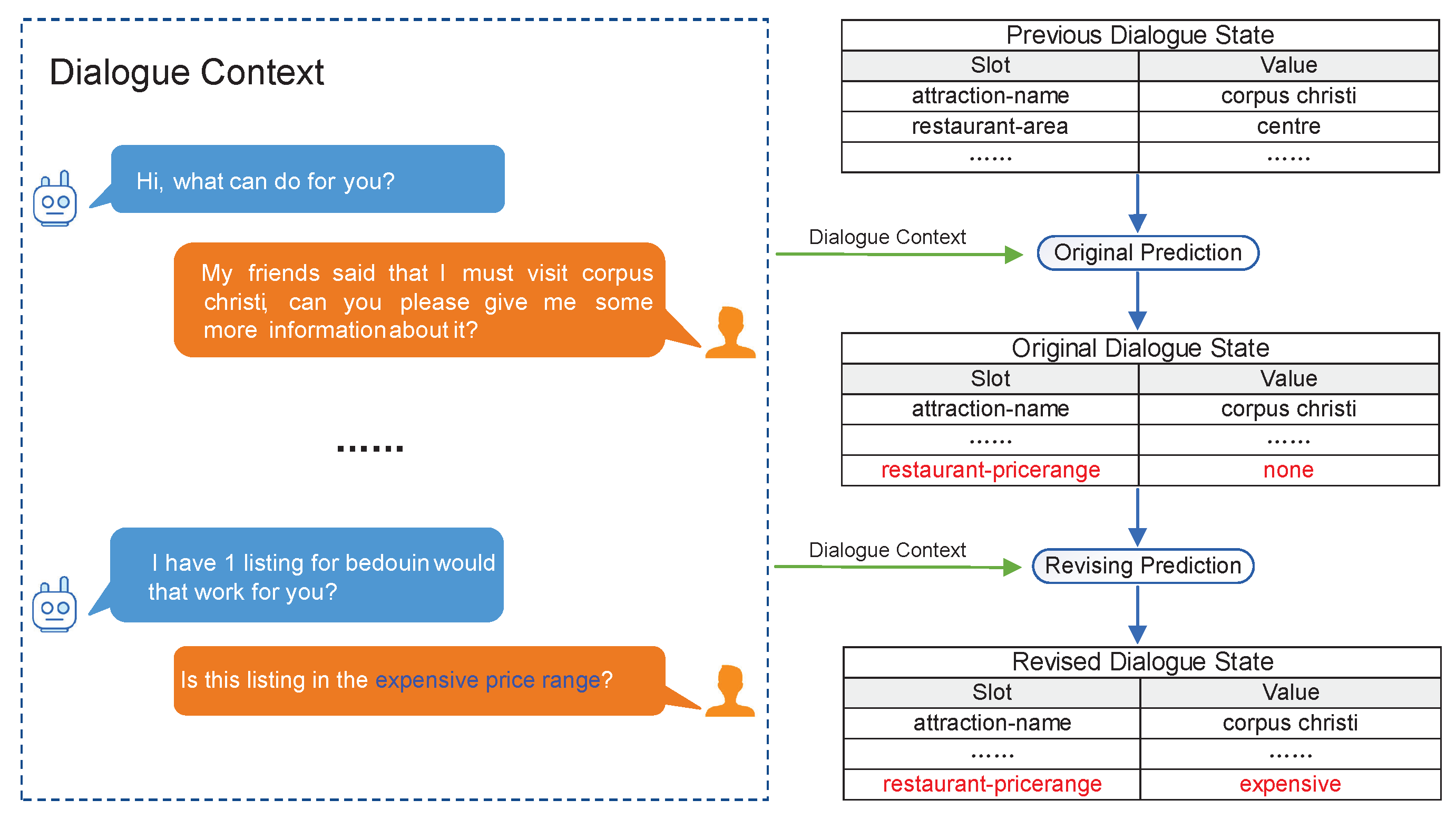
3.3. Revising Dialogue State Prediction
3.4. Training Objective
4. Experiments
4.1. Datasets
4.2. Evaluation Metric
4.3. Baselines
4.4. Implementation Details
5. Results and Discussion
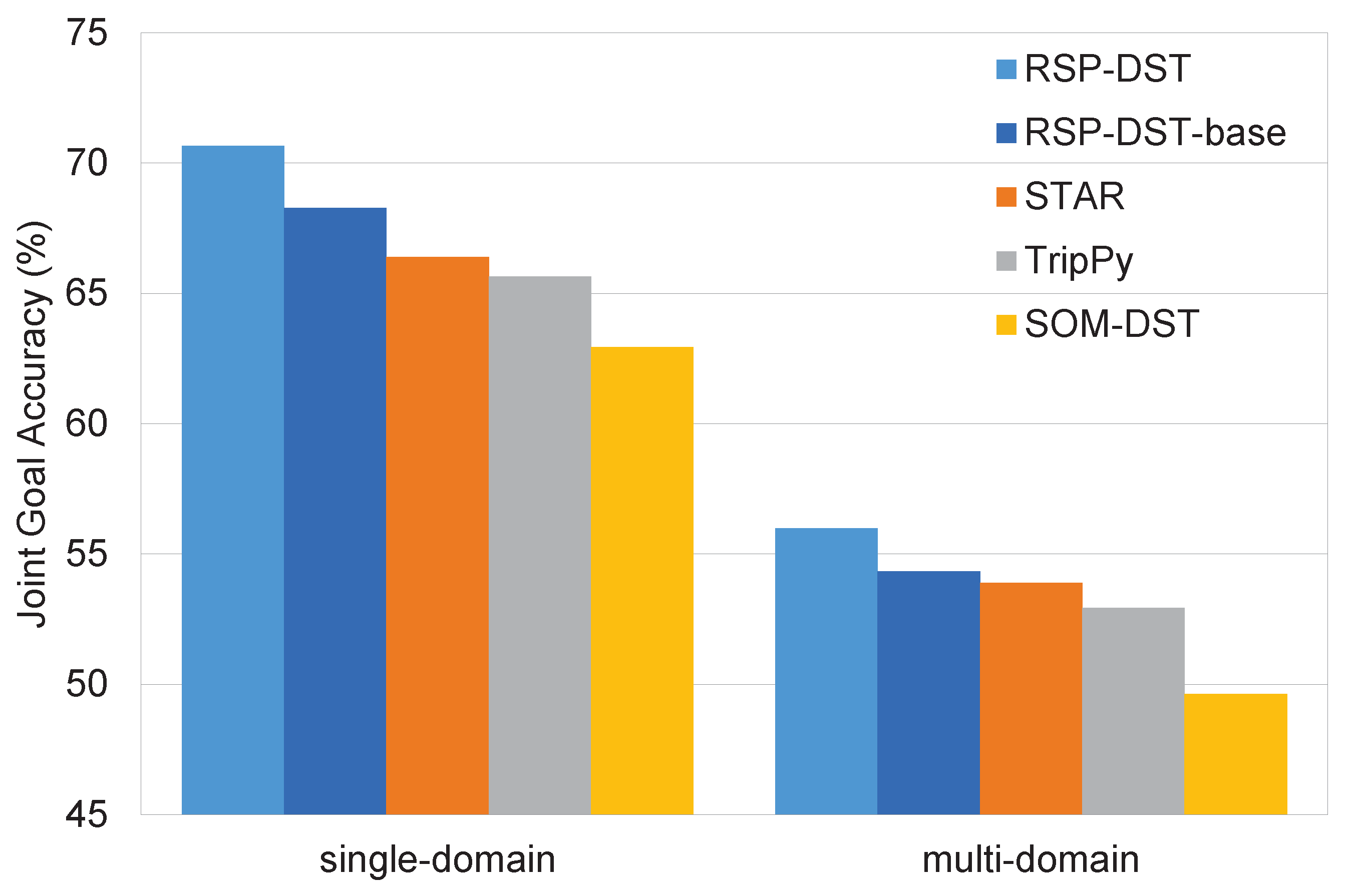
5.1. Main Results
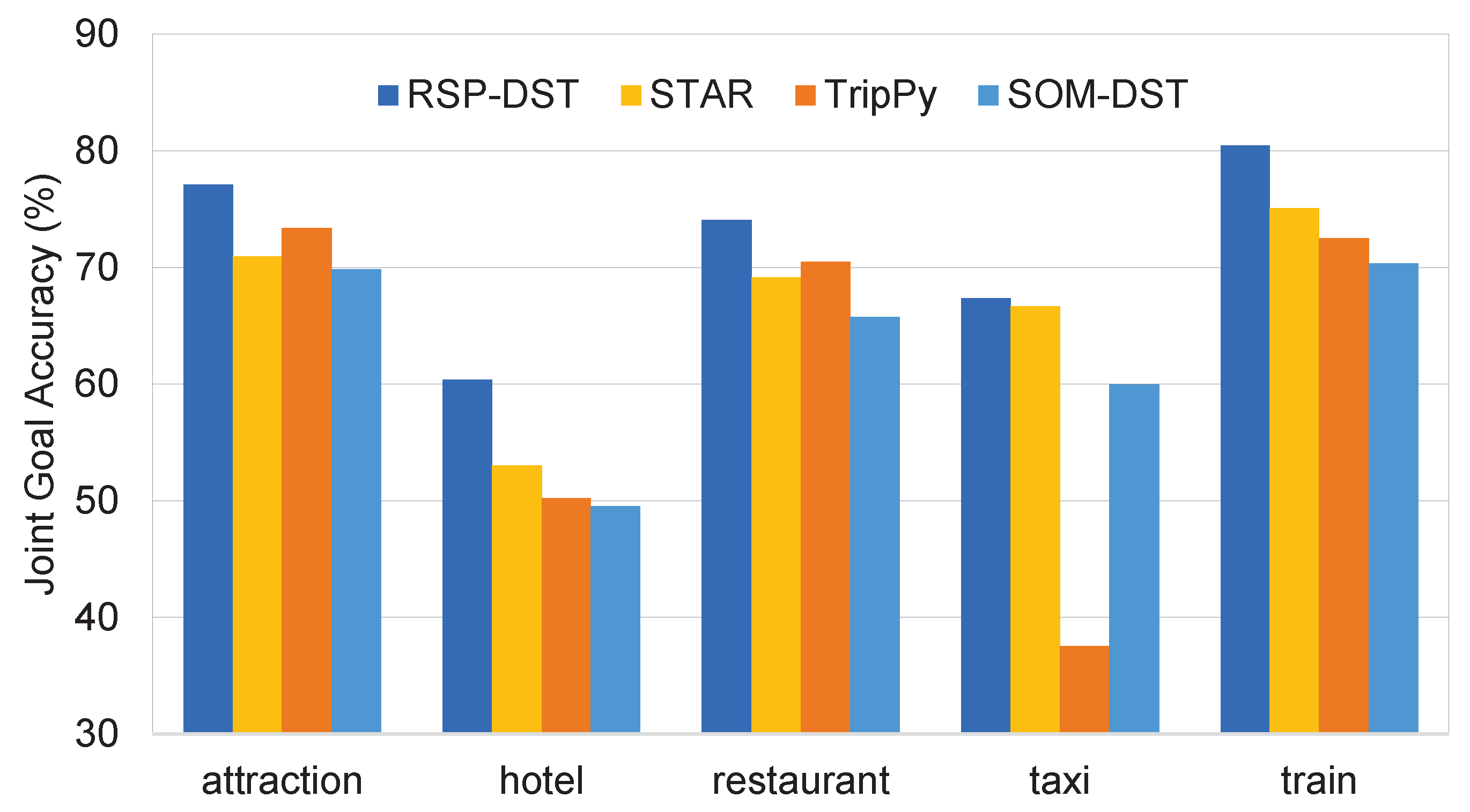
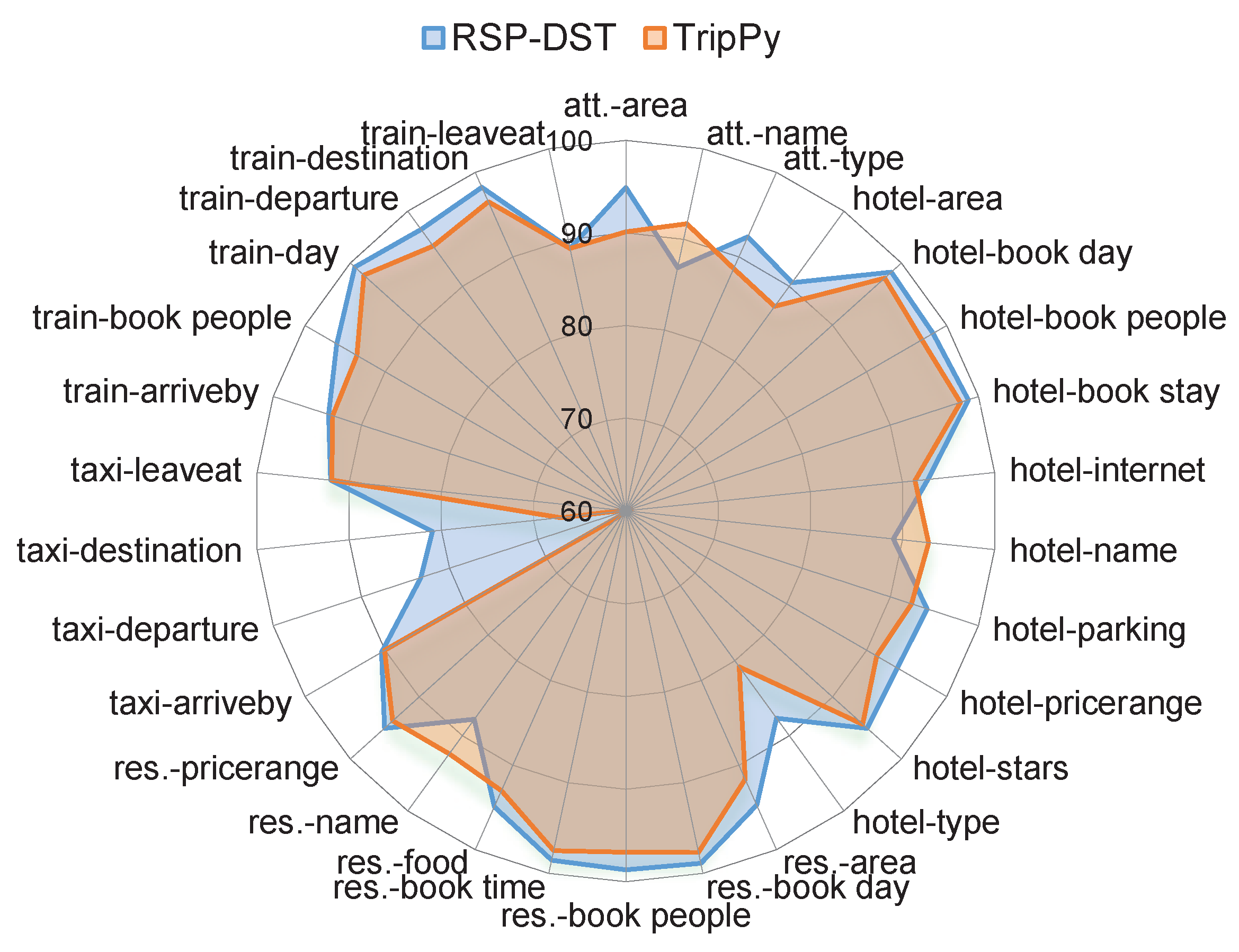
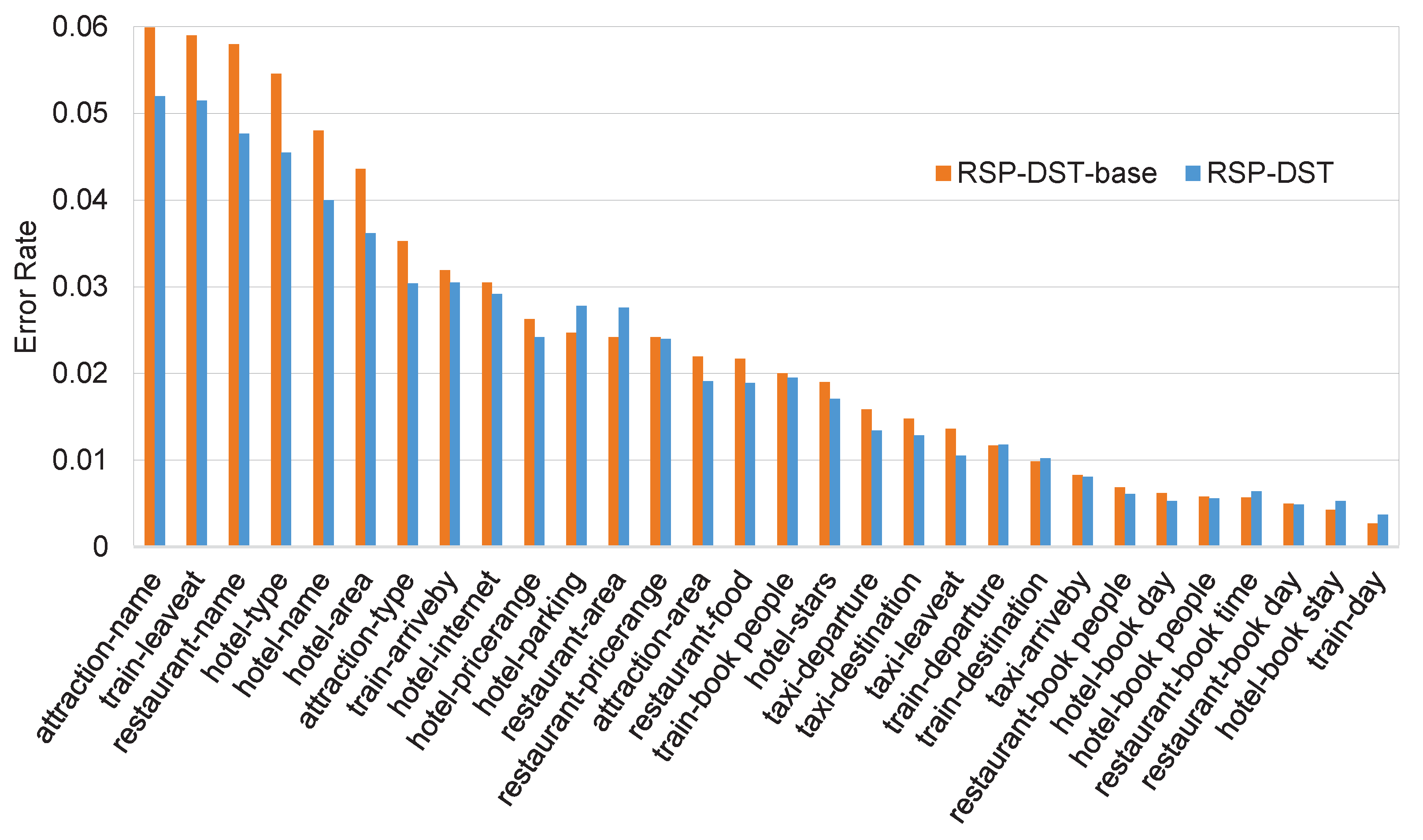
5.2. Domain-Specific Joint Goal Accuracy and Per-Slot Accuracy
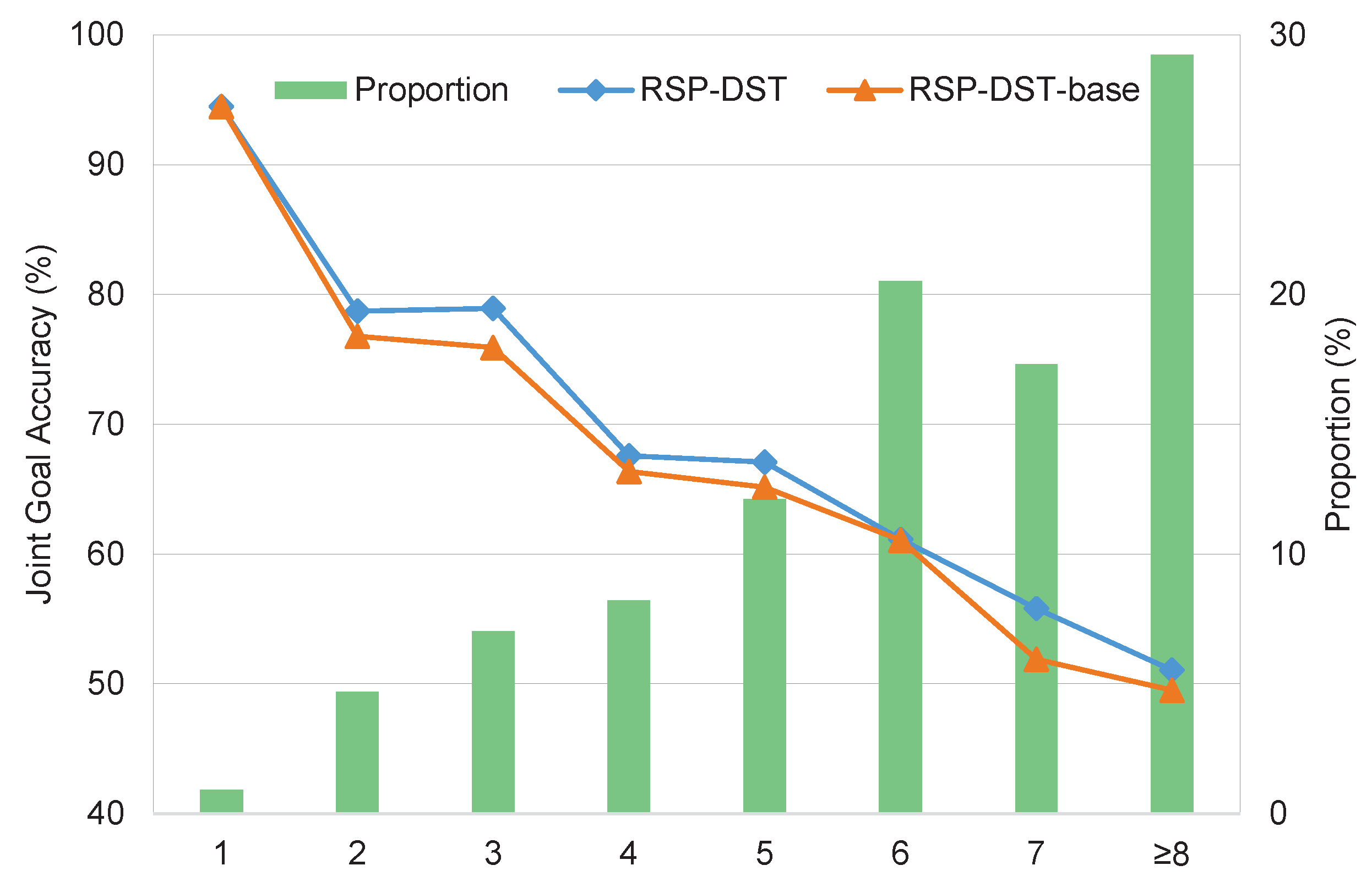
5.3. Each Turn Joint Goal Accuracy
5.4. Effect of Dialogue History and Previous Dialogue State
5.5. Error Analysis
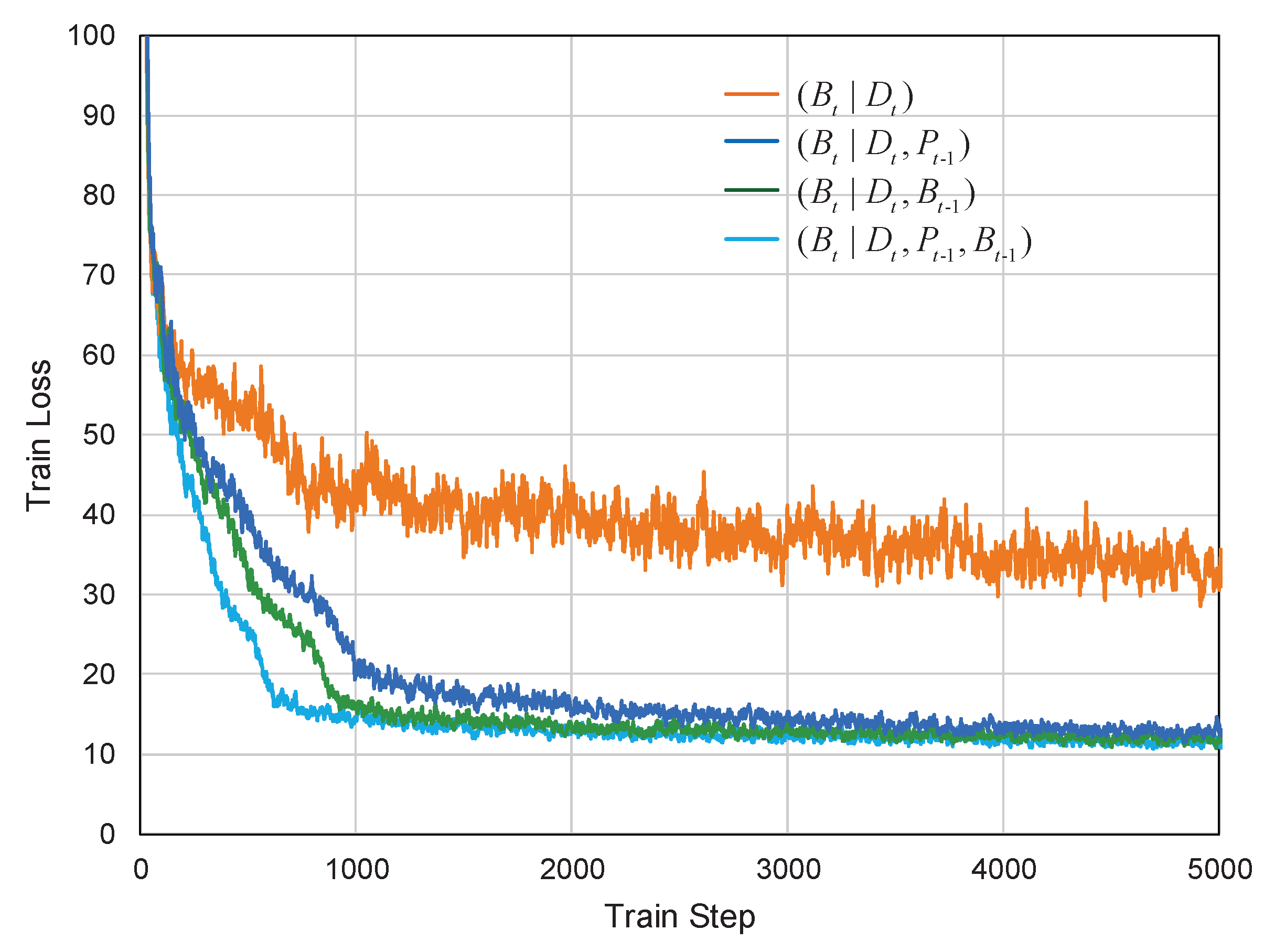
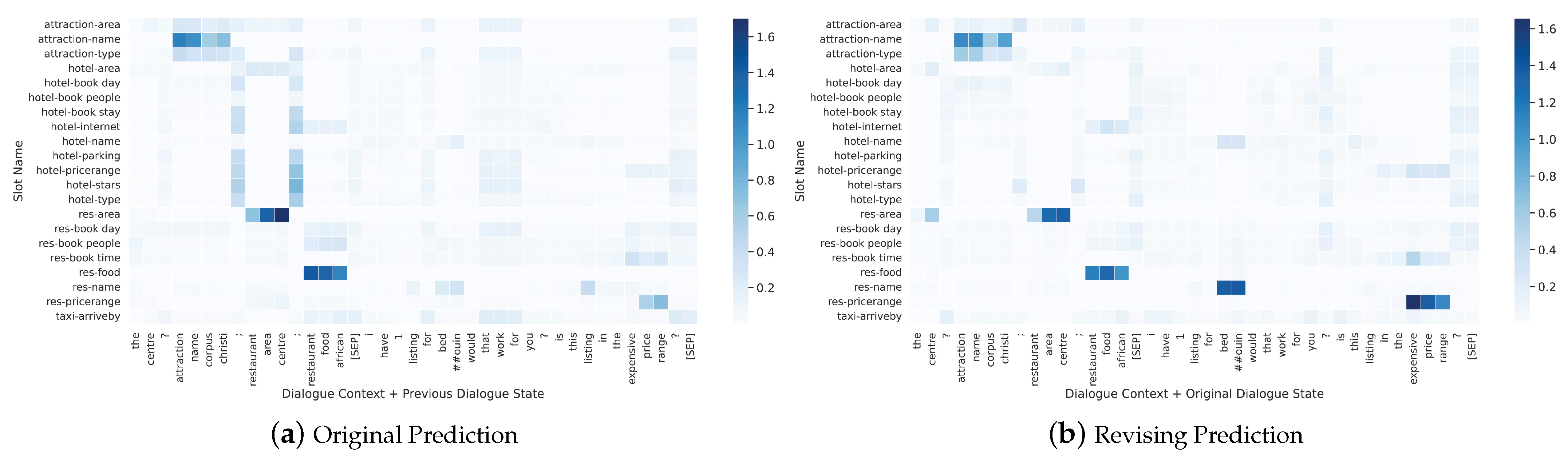
5.6. Visualization
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Description of Symbols

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| A set of dialogues with T turns | |
| A dialogue at turn t consisting of system response and user utterance | |
| System response at turn t | |
| User utterance at turn t | |
| The dialogue history of turn t | |
| A set of M predefined slots | |
| The m-th slot in | |
| The corresponding value of slot at turn t | |
| The dialogue state at turn t consisting of a set of (slot, value) pairs | |
| The input sequence of dialogue context at turn t | |
| The output of , and it is the matrix form of all tokens’ representations in | |
| The output of , and it is the is vector representation of slot | |
| The slot attention vector of slot at turn t | |
| The token-aware slot vector representation of slot at turn t | |
| The matrix form of all slots’ vector representations at turn t | |
| The slot-related representation of slot at turn t | |
| The matrix form of all slot-related representations at turn t | |
| The final semantic vector representation of slot at turn t |
References
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A Survey on Dialogue Systems: Recent Advances and New Frontiers. SIGKDD Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Gao, J.; Galley, M.; Li, L. Neural Approaches to Conversational AI. Found. Trends® Inf. Retr. 2019, 13, 127–298. [Google Scholar] [CrossRef] [Green Version]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Cambria, E. Recent advances in deep learning based dialogue systems: A systematic survey. Artif. Intell. Rev. 2023, 56, 3055–3155. [Google Scholar] [CrossRef]
- Mrkšić, N.; Ó Séaghdha, D.; Wen, T.H.; Thomson, B.; Young, S. Neural Belief Tracker: Data-Driven Dialogue State Tracking. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1777–1788. [Google Scholar]
- Williams, J.D.; Raux, A.; Henderson, M. The dialog state tracking challenge series: A review. Dialogue Discourse 2016, 7, 4–33. [Google Scholar] [CrossRef]
- Chen, Y.N.; Celikyilmaz, A.; Hakkani-Tür, D. Deep Learning for Dialogue Systems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 8–14. [Google Scholar]
- Jacqmin, L.; Rojas Barahona, L.M.; Favre, B. “Do you follow me?”: A Survey of Recent Approaches in Dialogue State Tracking. In Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue, Edinburgh, UK, 7–9 September 2022; pp. 336–350. [Google Scholar]
- Balaraman, V.; Sheikhalishahi, S.; Magnini, B. Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey. In Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue, Singapore, 29–31 July 2021; pp. 239–251. [Google Scholar]
- Zhong, V.; Xiong, C.; Socher, R. Global-Locally Self-Attentive Encoder for Dialogue State Tracking. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 1458–1467. [Google Scholar]
- Lee, H.; Lee, J.; Kim, T.Y. SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5478–5483. [Google Scholar]
- Zhu, S.; Li, J.; Chen, L.; Yu, K. Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 766–781. [Google Scholar]
- Ye, F.; Manotumruksa, J.; Zhang, Q.; Li, S.; Yilmaz, E. Slot Self-Attentive Dialogue State Tracking. In Proceedings of the Web Conference 2021, WWW’21, Ljubljana, Slovenia, 19–23 April 2021; pp. 1598–1608. [Google Scholar]
- Heck, M.; van Niekerk, C.; Lubis, N.; Geishauser, C.; Lin, H.C.; Moresi, M.; Gašić, M. TripPy: A Triple Copy Strategy for Value Independent Neural Dialog State Tracking. In Proceedings of the 21st Annual Meeting of the Special Interest Group on Discourse and Dialogue, Virtual meeting, 1–3 July 2020; pp. 35–44. [Google Scholar]
- Wu, C.S.; Madotto, A.; Hosseini-Asl, E.; Xiong, C.; Socher, R.; Fung, P. Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 808–819. [Google Scholar]
- Kim, S.; Yang, S.; Kim, G.; Lee, S.W. Efficient Dialogue State Tracking by Selectively Overwriting Memory. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 567–582. [Google Scholar]
- Zeng, Y.; Nie, J. Multi-Domain Dialogue State Tracking—A Purely Transformer-Based Generative Approach. arXiv 2020, arXiv:2010.14061. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gašić, M. MultiWOZ—A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 5016–5026. [Google Scholar]
- Eric, M.; Goel, R.; Paul, S.; Sethi, A.; Agarwal, S.; Gao, S.; Kumar, A.; Goyal, A.; Ku, P.; Hakkani-Tur, D. MultiWOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 422–428. [Google Scholar]
- Ye, F.; Manotumruksa, J.; Yilmaz, E. MultiWOZ 2.4: A Multi-Domain Task-Oriented Dialogue Dataset with Essential Annotation Corrections to Improve State Tracking Evaluation. In Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue, Edinburgh, UK, 7–9 September 2022; pp. 351–360. [Google Scholar]
- Thomson, B.; Young, S. Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Comput. Speech Lang. 2010, 24, 562–588. [Google Scholar] [CrossRef] [Green Version]
- Henderson, M.; Thomson, B.; Young, S. Word-Based Dialog State Tracking with Recurrent Neural Networks. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 292–299. [Google Scholar]
- Williams, J.D. Web-style ranking and SLU combination for dialog state tracking. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 282–291. [Google Scholar]
- Wen, T.H.; Vandyke, D.; Mrkšić, N.; Gašić, M.; Rojas-Barahona, L.M.; Su, P.H.; Ultes, S.; Young, S. A Network-based End-to-End Trainable Task-oriented Dialogue System. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 438–449. [Google Scholar]
- He, Y.; Tang, Y. A Neural Language Understanding for Dialogue State Tracking. In Proceedings of the Knowledge Science, Engineering and Management; Springer International Publishing: Cham, Switzerland, 2021; pp. 542–552. [Google Scholar]
- Rastogi, P.; Gupta, A.; Chen, T.; Lambert, M. Scaling Multi-Domain Dialogue State Tracking via Query Reformulation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 2, pp. 97–105. [Google Scholar]
- Ren, L.; Ni, J.; McAuley, J. Scalable and Accurate Dialogue State Tracking via Hierarchical Sequence Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1876–1885. [Google Scholar]
- Ren, L.; Xie, K.; Chen, L.; Yu, K. Towards Universal Dialogue State Tracking. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2780–2786. [Google Scholar]
- Ouyang, Y.; Chen, M.; Dai, X.; Zhao, Y.; Huang, S.; Chen, J. Dialogue State Tracking with Explicit Slot Connection Modeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 34–40. [Google Scholar]
- Feng, Y.; Wang, Y.; Li, H. A Sequence-to-Sequence Approach to Dialogue State Tracking. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1, pp. 1714–1725. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Shan, Y.; Li, Z.; Zhang, J.; Meng, F.; Feng, Y.; Niu, C.; Zhou, J. A contextual hierarchical attention network with adaptive objective for dialogue state tracking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6322–6333. [Google Scholar]
- Zhang, J.; Hashimoto, K.; Wu, C.S.; Wang, Y.; Yu, P.; Socher, R.; Xiong, C. Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking. In Proceedings of the Ninth Joint Conference on Lexical and Computational Semantics, Barcelona, Spain, 13–14 September 2020; pp. 154–167. [Google Scholar]
- Hosseini-Asl, E.; McCann, B.; Wu, C.S.; Yavuz, S.; Socher, R. A Simple Language Model for Task-Oriented Dialogue. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 20179–20191. [Google Scholar]
- Pan, B.; Yang, Y.; Li, B.; Cai, D. Self-supervised attention flow for dialogue state tracking. Neurocomputing 2021, 440, 279–286. [Google Scholar] [CrossRef]
- Wang, Y.; He, T.; Mei, J.; Fan, R.; Tu, X. A Stack-Propagation Framework with Slot Filling for Multi-Domain Dialogue State Tracking. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Li, B.; Mi, F.; Zhu, X.; Huang, M. Continual Prompt Tuning for Dialog State Tracking. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 1124–1137. [Google Scholar]
- Chen, D. Neural Reading Comprehension and Beyond. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2018. [Google Scholar]
- Wilcock, G.; Jokinen, K. Conversational AI and Knowledge Graphs for Social Robot Interaction. In Proceedings of the 2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Sapporo, Japan, 7–10 March 2022; pp. 1090–1094. [Google Scholar]
- Shen, Y.; Ding, N.; Zheng, H.T.; Li, Y.; Yang, M. Modeling Relation Paths for Knowledge Graph Completion. IEEE Trans. Knowl. Data Eng. 2021, 33, 3607–3617. [Google Scholar] [CrossRef]
- Wu, Y.; Liao, L.; Zhang, G.; Lei, W.; Zhao, G.; Qian, X.; Chua, T.S. State Graph Reasoning for Multimodal Conversational Recommendation. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Zhou, L.; Small, K. Multi-domain dialogue state tracking as dynamic knowledge graph enhanced question answering. arXiv 2019, arXiv:1911.06192. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, L.; Lv, B.; Wang, C.; Zhu, S.; Tan, B.; Yu, K. Schema-guided multi-domain dialogue state tracking with graph attention neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7521–7528. [Google Scholar]
- Zhao, M.; Wang, L.; Jiang, Z.; Li, R.; Lu, X.; Hu, Z. Multi-task learning with graph attention networks for multi-domain task-oriented dialogue systems. Knowl.-Based Syst. 2023, 259, 110069. [Google Scholar] [CrossRef]
- Feng, Y.; Lipani, A.; Ye, F.; Zhang, Q.; Yilmaz, E. Dynamic Schema Graph Fusion Network for Multi-Domain Dialogue State Tracking. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 115–126. [Google Scholar]
- Moerland, T.M.; Broekens, J.; Plaat, A.; Jonker, C.M. Model-based Reinforcement Learning: A Survey. Found. Trends® Mach. Learn. 2023, 16, 1–118. [Google Scholar] [CrossRef]
- Huang, Y.; Feng, J.; Hu, M.; Wu, X.; Du, X.; Ma, S. Meta-Reinforced Multi-Domain State Generator for Dialogue Systems. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7109–7118. [Google Scholar]
- Gao, S.; Sethi, A.; Agarwal, S.; Chung, T.; Hakkani-Tur, D. Dialog State Tracking: A Neural Reading Comprehension Approach. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, Stockholm, Sweden, 11–13 September 2019; pp. 264–273. [Google Scholar]
- Gao, S.; Agarwal, S.; Jin, D.; Chung, T.; Hakkani-Tur, D. From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap. In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, Online, 5–10 July 2020; pp. 79–89. [Google Scholar]
- Hu, J.; Yang, Y.; Chen, C.; He, L.; Yu, Z. SAS: Dialogue State Tracking via Slot Attention and Slot Information Sharing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6366–6375. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Lei Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bowman, S.; Vilnis, L.; Vinyals, O.; Dai, A.; Jozefowicz, R.; Bengio, S. Generating sentences from a continuous space. In Proceedings of the CoNLL 2016—20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 10–21. [Google Scholar]










| Domain | Slots | Train | Valid | Test |
|---|---|---|---|---|
| Train | arriveby, leaveat, day, book people, destination, departure | 3103 | 484 | 494 |
| Taxi | arriveby, leaveat, destination, departure | 1654 | 207 | 195 |
| Hotel | area, parking, type, stars, book people, book day, book stay, pricerange, name, internet | 3381 | 416 | 394 |
| Attraction | area, type, name | 2717 | 401 | 395 |
| Restaurant | area, book people, book time, book day, name, pricerange, food | 3813 | 438 | 437 |
| Model | Joint Goal Accuracy (%) | Slot Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| MWZ2.0 | MWZ2.1 | MWZ2.4 | MWZ2.0 | MWZ2.1 | MWZ2.4 | |
| TRADE [14] | 48.62 | 45.60 | 55.05 | 96.92 | 96.55 | 97.62 |
| SOM-DST [15] | 51.72 | 53.01 | 66.78 | - | 97.15 | 98.38 |
| SimpleTOD [34] | 51.37 | 51.89 | - | - | - | - |
| TripPy [13] | 53.51 | 55.18 | 59.62 | - | 97.48 | 97.94 |
| Seq2Seq-DU [29] | - | 56.10 | - | - | - | - |
| SAF [35] | - | 51.60 | - | - | 97.50 | - |
| SPSF-DST [36] | 54.88 | 54.32 | - | - | - | - |
| CHAN [32] | 53.06 | 53.38 | 68.25 | - | 97.39 | 98.52 |
| SST [44] | 51.17 | 55.23 | - | - | - | - |
| DST-picklist [33] | 54.39 | 53.30 | - | - | 97.40 | - |
| STAR [12] | 54.20 | 56.36 | 73.62 | 97.33 | 97.59 | 98.85 |
| RSP-DST-base * | 54.42 | 56.31 | 74.64 | 97.44 | 97.62 | 98.87 |
| RSP-DST | 56.35 | 58.09 | 75.65 | 97.54 | 97.75 | 98.95 |
| Structure | Joint Goal Accuracy(%) | Slot Accuracy(%) |
|---|---|---|
| 18.96 | 86.33 | |
| 56.43 | 97.63 | |
| 55.85 | 96.68 | |
| 58.09 | 97.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Zhang, W.; Huang, M.; Feng, S.; Wu, Y. RSP-DST: Revisable State Prediction for Dialogue State Tracking. Electronics 2023, 12, 1494. https://doi.org/10.3390/electronics12061494
Li Q, Zhang W, Huang M, Feng S, Wu Y. RSP-DST: Revisable State Prediction for Dialogue State Tracking. Electronics. 2023; 12(6):1494. https://doi.org/10.3390/electronics12061494
Chicago/Turabian StyleLi, Qianyu, Wensheng Zhang, Mengxing Huang, Siling Feng, and Yuanyuan Wu. 2023. "RSP-DST: Revisable State Prediction for Dialogue State Tracking" Electronics 12, no. 6: 1494. https://doi.org/10.3390/electronics12061494
APA StyleLi, Q., Zhang, W., Huang, M., Feng, S., & Wu, Y. (2023). RSP-DST: Revisable State Prediction for Dialogue State Tracking. Electronics, 12(6), 1494. https://doi.org/10.3390/electronics12061494