


Separating Malicious from Benign Software Using Deep Learning Algorithm


Abstract
:1. Introduction
- The new dataset creation method is proposed;
- The deep-learning-based methodology is suggested to separate malware from benign files;
- Machine learning classifiers are used to detect malware as well;
- The well-known literature studies are reviewed based on the main idea and important findings;
- The proposed method reduces the number of features while increasing the performance significantly;
- The suggested model can effectively detect both known and zero-day malware.
2. Related Work
2.1. Signature-Based Detection
2.2. Heuristic-Based Detection
2.3. Behavioral-Based Detection
2.4. Machine-Learning-Based Detection
2.5. Deep-Learning-Based Detection
2.6. Evaluation of Related Works on Malware Detection Approaches
- ML and DL algorithms make assumptions about the data and these assumptions can be wrong sometimes;
- Sometimes, there is not enough information within flows, need contextual features;
- Generally, data contain high dimensionality, which may decrease system performance;
- The algorithms do not take domain expert knowledge into account; this can generate meaningless features;
- ML algorithms are prone to bias and cannot handle outliers all the time;
- Detecting zero-day malware is challenging;
- The intelligent malware evades the ML- and DL-based classifiers.
3. Materials and Methods
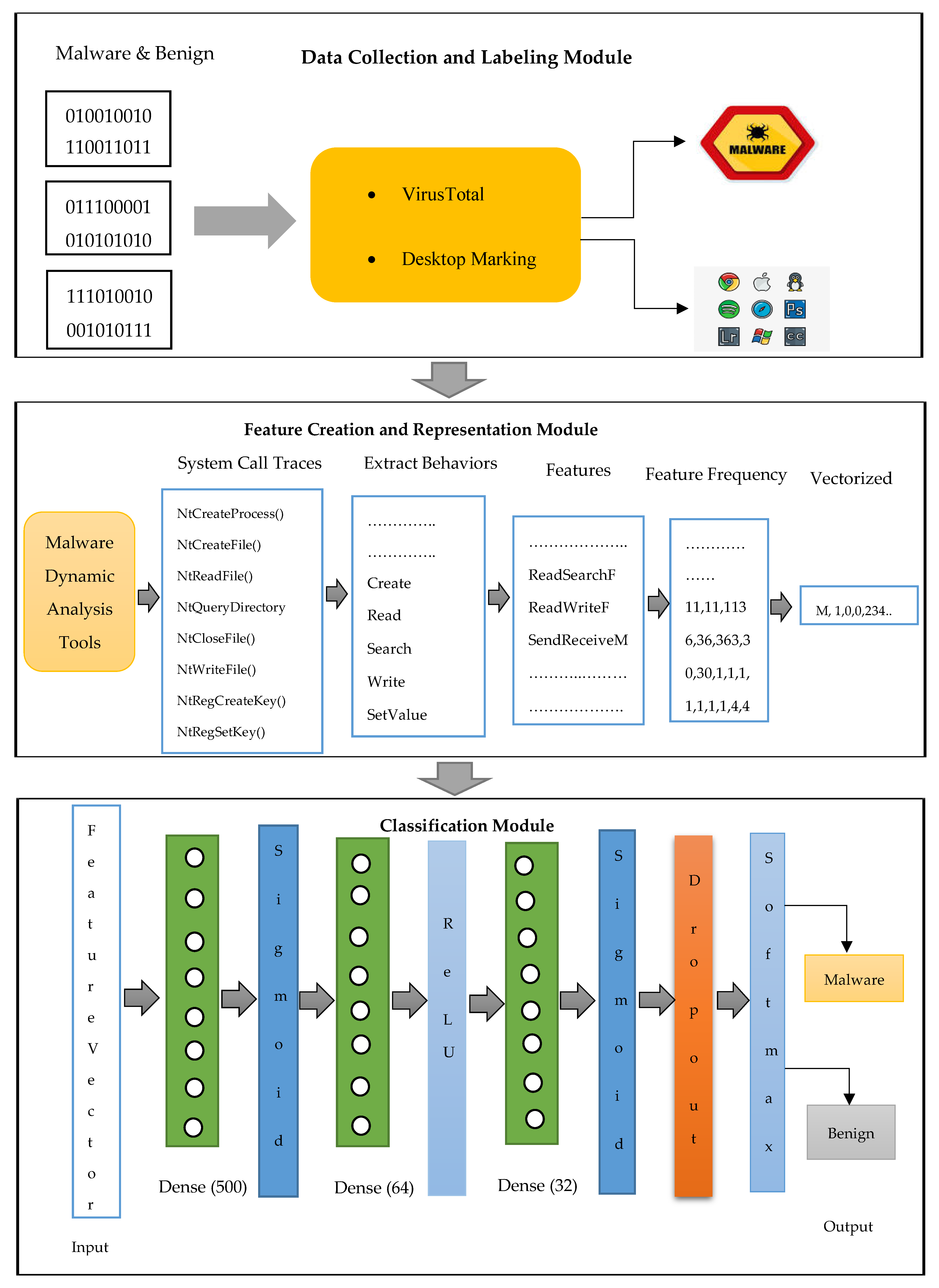
3.1. Dataset Creation and Representation Method
- Stage 1: The malware and benign samples are employed under the dynamic malware analysis tools;
- Stage 2: The execution traces of system calls are obtained;
- Stage 3: System calls are converted into behaviors;
- Stage 4: Behaviors are classified based on the resource types and paths;
- Stage 5: The importance level of behaviors is calculated;
- Stage 6: The features are generated based on the relationship among the behaviors as well as the level of behaviors;
- Stage 7: The feature frequency is calculated for each program sample;
- Stage 8: The row feature vector is created for each program sample.
3.2. Classification Model
3.2.1. Using the Proposed Deep Learning Methodology to Detect Malware
3.2.2. Using Machine Learning Algorithms to Detect Malware
- , where C is a hyper parameter in SVM
- K (, ) is the kernel function, and values are Lagrange multipliers.
3.3. Case Study
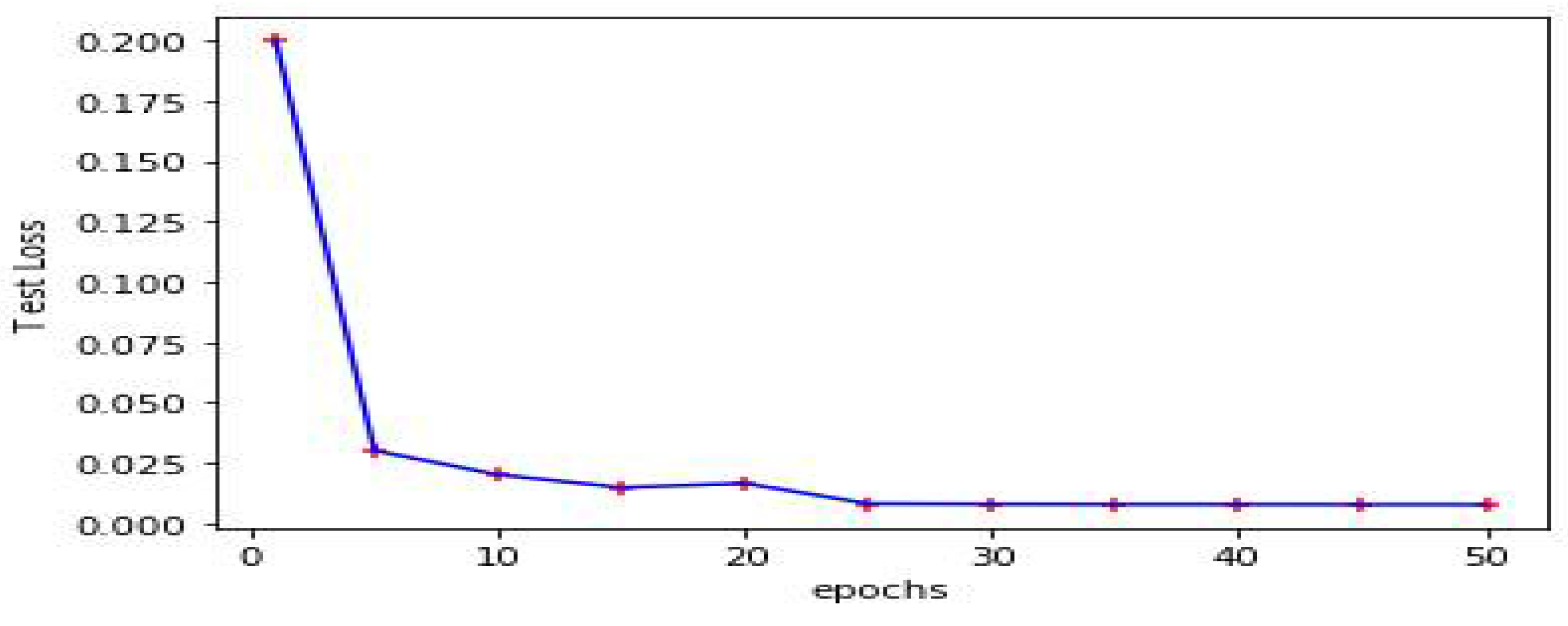
3.4. Model Performance and Evaluation
4. Experimental Results and Discussion
5. Limitations and Future Works
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Aslan, Ö. Ransomware Detection in Cyber Security Domain. Bitlis Eren Üniversitesi Fen Bilimleri Dergisi 2022, 11, 509–519. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, H.; Sun, L. Social Engineering in Cybersecurity: Effect Mechanisms, Human Vulnerabilities and Attack Methods. IEEE Access 2021, 9, 11895–11910. [Google Scholar] [CrossRef]
- Aslan, Ö. A Methodology to Detect Distributed Denial of Service Attacks. Bilişim Teknolojileri Dergisi 2022, 15, 149–158. [Google Scholar] [CrossRef]
- Morgan, S. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. Cybercrime Magazine, 13 November 2020. [Google Scholar]
- Aslan, Ö.; Ozkan-Okay, M.; Gupta, D. Intelligent Behavior-Based Malware Detection System on Cloud Computing Environment. IEEE Access 2021, 9, 83252–83271. [Google Scholar] [CrossRef]
- Pears, M.; Konstantinidis, S.T. Cybersecurity Training in the Healthcare Workforce—Utilization of the ADDIE Model. In Proceedings of the 2021 IEEE Global Engineering Education Conference (EDUCON), Online, 21–23 April 2021; pp. 1674–1681. [Google Scholar] [CrossRef]
- Aslan, Ö.; Samet, R. Investigation of possibilities to detect malware using existing tools. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 1277–1284. [Google Scholar]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef] [Green Version]
- Aslan, Ö.; Samet, R. A Comprehensive Review on Malware Detection Approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Ahn, S. Deep learning architectures and applications. J. Intell. Inf. Syst. 2016, 22, 127–142. [Google Scholar]
- Yuxin, D.; Siyi, Z. Malware detection based on deep learning algorithm. Neural Comput. Appl. 2019, 31, 461–472. [Google Scholar] [CrossRef]
- Hosseini, M.P.; Lu, S.; Kamaraj, K.; Slowikowski, A.; Venkatesh, H.C. Deep learning architectures. In Deep Learning: Concepts and Architectures; Springer: Cham, Switzerland, 2020; pp. 1–24. [Google Scholar]
- Griffin, K.; Schneider, S.; Hu, X.; Chiueh, T.-C. Automatic Generation of String Signatures for Malware Detection. In Proceedings of the International Workshop Recent Advances in Intrusion Detection; Springer: Berlin, Germany, 2009; pp. 101–120. [Google Scholar] [CrossRef]
- Savenko, O.; Nicheporuk, A.; Hurman, I.; Lysenko, S. Dynamic Signature-based Malware Detection Technique Based on API Call Tracing. In Proceedings of the ICTERI Workshops, Kherson, Ukraine, 12–15 June 2019; pp. 633–643. [Google Scholar]
- Sahoo, A.K.; Sahoo, K.S.; Tiwary, M. Signature based malware detection for unstructured data in Hadoop. In Proceedings of the 2014 International Conference on Advances in Electronics Computers and Communications, Bangalore, India, 10–11 October 2014; pp. 1–6. [Google Scholar]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 28–30 May 2013; pp. 113–120. [Google Scholar] [CrossRef]
- Ye, Y.; Wang, D.; Li, T.; Ye, D. IMDS: Intelligent malware detection system. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Jose, CA, USA, 12–15 August 2007; pp. 1043–1047. [Google Scholar]
- Bilar, D. Opcodes as predictor for malware. Int. J. Electron. Secur. Digit. Forensics 2007, 1, 156–168. [Google Scholar] [CrossRef]
- Lanzi, A.; Balzarotti, D.; Kruegel, C.; Christodorescu, M.; Kirda, E. Accessminer: Using system-centric models for malware protection. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 399–412. [Google Scholar]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2016, 12, 59–67. [Google Scholar] [CrossRef]
- Ding, Y.; Xia, X.; Chen, S.; Li, Y. A malware detection method based on family behavior graph. Comput. Secur. 2018, 73, 73–86. [Google Scholar] [CrossRef]
- Markel, Z.A. Machine Learning Based Malware Detection; Naval Academy: Annapolis, MD, USA, 2015. [Google Scholar]
- Sethi, K.; Kumar, R.; Sethi, L.; Bera, P.; Patra, P.K. A novel machine learning based malware detection and classification framework. In Proceedings of the 2019 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Oxford, UK, 3–4 June 2019; pp. 1–4. [Google Scholar]
- Singh, J.; Singh, J. A survey on machine learning-based malware detection in executable files. J. Syst. Archit. 2021, 112, 101861. [Google Scholar] [CrossRef]
- Sudhakar; Kumar, S. MCFT-CNN: Malware classification with fine-tune convolution neural networks using traditional and transfer learning in Internet of Things. Future Gener. Comput. Syst. 2021, 125, 334–351. [Google Scholar] [CrossRef]
- Ring, M.; Schlör, D.; Wunderlich, S.; Landes, D.; Hotho, A. Malware detection on windows audit logs using LSTMs. Comput. Secur. 2021, 109, 102389. [Google Scholar] [CrossRef]
- Jian, Y.; Kuang, H.; Ren, C.; Ma, Z.; Wang, H. A novel framework for image-based malware detection with a deep neural network. Comput. Secur. 2021, 109, 102400. [Google Scholar] [CrossRef]
- Baek, S.; Jeon, J.; Jeong, B.; Jeong, Y.S. Two-stage hybrid malware detection using deep learning. Hum.-Cent. Comput. Inf. Sci. 2021, 11, 10-22967. [Google Scholar]
- Aslan, Ö.; Yilmaz, A.A. A New Malware Classification Framework Based on Deep Learning Algorithms. IEEE Access 2021, 9, 87936–87951. [Google Scholar] [CrossRef]
- Awan, M.J.; Masood, O.A.; Mohammed, M.A.; Yasin, A.; Zain, A.M.; Damaševičius, R.; Abdulkareem, K.H. Image-Based Malware Classification Using VGG19 Network and Spatial Convolutional Attention. Electronics 2021, 10, 2444. [Google Scholar] [CrossRef]
- Azeez, N.A.; Odufuwa, O.E.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE Malware Detection Using Ensemble Learning. Informatics 2021, 8, 10. [Google Scholar] [CrossRef]
- Kim, J.-Y.; Bu, S.-J.; Cho, S.-B. Malware Detection Using Deep Transferred Generative Adversarial Networks. In Proceedings of the International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2017; pp. 556–564. [Google Scholar] [CrossRef]
- Cui, Z.; Xue, F.; Cai, X.; Cao, Y.; Wang, G.-G.; Chen, J. Detection of Malicious Code Variants Based on Deep Learning. IEEE Trans. Ind. Inform. 2018, 14, 3187–3196. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Venkatraman, S. Robust Intelligent Malware Detection Using Deep Learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; pp. 11–20. [Google Scholar]
- Santos, I.; Brezo, F.; Ugarte-Pedrero, X.; Bringas, P.G. Opcode sequences as representation of executables for data-mining-based unknown malware detection. Inf. Sci. 2013, 231, 64–82. [Google Scholar] [CrossRef]
- Firdausi, I.; Lim, C.; Erwin, A.; Nugroho, A.S. Analysis of Machine learning Techniques Used in Behavior-Based Malware Detection. In Proceedings of the 2010 Second International Conference on Advances in Computing, Control, and Telecommunication Technologies, Jakarta, Indonesia, 2–3 December 2010; pp. 201–203. [Google Scholar] [CrossRef]
- Bozkir, A.S.; Tahillioglu, E.; Aydos, M.; Kara, I. Catch them alive: A malware detection approach through memory forensics, manifold learning and computer vision. Comput. Secur. 2021, 103, 102166. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Class | Facts on Malware Concerns and Trends |
|---|---|
| Economic damage | Cybercrime expected to cost nearly USD 10 trillion to the world economy by 2025 |
| Propagation (speed) | The current number of malware variants is more than 1 billion The malware increasing rate is exponential |
| Spread method/environment | Most of the malware is delivered by email and drive-by download Different malware samples are being sold on DarkWeb |
| Malware target | Mostly small businesses become the target of the malware IoT devices, cloud environments, banks, and healthcare systems mostly become the target of malware |
| Common malware | Trojans are the most common malware types Mobile malware variants are increasing Every minute, a few companies become a victim of ransomware |
| Detectors’ efficiency | Antivirus programs do not effectively detect the new malware variants Not resistant to obfuscation techniques |
| Scientific Research | Year | Feature Extraction Method/Feature Representation | Detection Method | Success |
|---|---|---|---|---|
| Griffin et al. [14] | 2009 | Range of library detection techniques and diversity-based heuristics | Signature-Based | Not given |
| Sahoo et al. [16] | 2014 | Unstructured data in Hadoop by using a fast string search algorithm | Not given | |
| Savenko et al. [15] | 2019 | Frequency of API calls as well as the interaction of critical API calls | 92.7% accuracy | |
| Ye et al. [18] | 2007 | API sequences with FP-growth algorithm | Heuristic-Based | 93.07% accuracy |
| Bilar [19] | 2007 | Opcode frequency distributions | Not given | |
| Lanzi et al. [20] | 2010 | Behavior sequences extracted from the system calls | Behavior-Based | 91% detection rate |
| Galal et al. [21] | 2016 | High-level features were represented as API calls | 93.98% accuracy | |
| Ding et al. [22] | 2018 | Dependency graph by using taint analysis | 91.6 accuracy | |
| Markel [23] | 2015 | Header metadata from Windows Portable Executable | Machine-Learning-Based | Low performance |
| Sethi et al. [24] | 2019 | Dynamic system activities | 88.2% accuracy | |
| Singh [25] | 2021 | Runtime features | Depends on the study | |
| Kumar [26] | 2021 | Fine-tune convolution neural networks with ResNet50 | Deep-Learning-Based | 98.6% accuracy |
| Baek et al. [29] | 2021 | Bi-LSTM with EfficientNet-B3 model | 94.9% accuracy | |
| Aslan and Yilmaz [30] | 2021 | Grayscale images with ResNet-50 and AlexNet | 97.7% accuracy | |
| Awan et al. [31] | 2021 | Transfer learning based on spatial convolutional attention | 97.4% accuracy |
| Parameter | Value |
|---|---|
| Batch Size | 64 |
| The number of hidden layers | 3 |
| Epochs | 50 |
| Dropout Rate | 0.6 |
| Learning Rate | 0.01 |
| Activation Function | Sigmoid, ReLU, Softmax |
| Loss Function | Sparse Categorical Cross Entropy |
| Optimizer | Adam |
| Predicted Class | |||
|---|---|---|---|
| Actual class | Yes | No | |
| Yes No | TP FP | FN TN | |
| Method | No. of Neurons in First Hidden Layer | No. of Neurons in Second Hidden Layer | No. of Neurons in Third Hidden Layer | Benign Malware | Prec (%) | Rec (%) | F1 (%) | Acc (%) |
|---|---|---|---|---|---|---|---|---|
| Deep Learning Using Cross-Validation k = 5 | 500 | 64 | 32 | 0 | 99 | 100 | 99.5 | 99.80 |
| 1 | 100 | 100 | 100 | |||||
| Deep Learning Using Cross-Validation k = 10 | 500 | 64 | 32 | 0 | 99 | 100 | 99.5 | 99.60 |
| 1 | 100 | 99 | 99.5 | |||||
| Deep Learning Using Percentage Split (85%, 15%) | 500 | 64 | 32 | 0 | 99 | 100 | 99.5 | 99.73 |
| 1 | 100 | 100 | 100 | |||||
| Deep Learning Using Percentage Split (70%, 30%) | 500 | 64 | 32 | 0 | 100 | 99 | 99.5 | 99.67 |
| 1 | 100 | 100 | 100 | |||||
| Deep Learning Using Percentage Split (50%, 50%) | 500 | 64 | 32 | 0 | 99 | 99 | 99 | 99.60 |
| 1 | 100 | 100 | 100 |
| Method | Benign Malware | Prec (%) | Rec (%) | F1 (%) | Acc (%) |
|---|---|---|---|---|---|
| ANN Using Percentage Split (85%, 15%) | 0 | 77 | 98 | 86 | 90.8 |
| 1 | 99 | 88 | 93 | ||
| ANN Using Percentage Split (70%, 30%) | 0 | 70 | 99 | 82 | 86 |
| 1 | 99 | 83 | 90 | ||
| ANN Using Percentage Split (50%, 50%) | 0 | 73 | 91 | 81 | 86.7 |
| 1 | 95 | 85 | 90 |
| Predicted Class | |||||
|---|---|---|---|---|---|
| Actual Class | Cross-Validation | Percentage Split | |||
| DL | 445 | 1 | 1517 | 8 | |
| 3 | 1051 | 12 | 3463 | ||
| ANN | 866 | 11 | 1384 | 141 | |
| 366 | 1757 | 523 | 2952 | ||
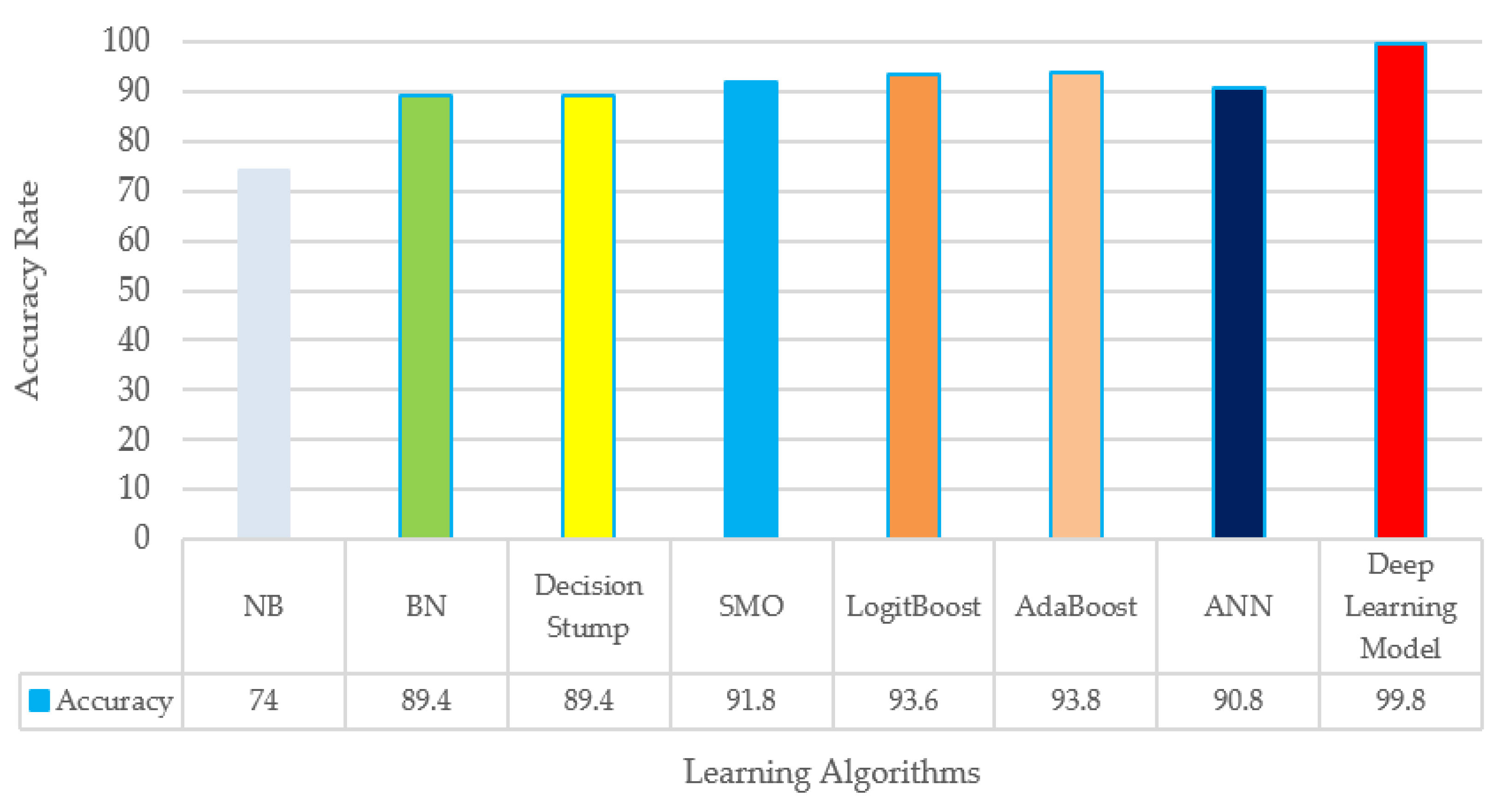
| Classifier | Benign Malware | Prec (%) | Rec (%) | F1 (%) | Acc (%) |
|---|---|---|---|---|---|
| NB | 0 | 55.3 | 92.2 | 69.2 | 74 |
| 1 | 94.8 | 65.7 | 77.6 | ||
| BN | 0 | 77.3 | 94.3 | 85 | 89.4 |
| 1 | 97.1 | 87.2 | 91.9 | ||
| Decision Stump | 0 | 86 | 79.3 | 82.5 | 89.4 |
| 1 | 90.8 | 94.1 | 92.4 | ||
| SMO | 0 | 83.9 | 91.5 | 87.6 | 91.8 |
| 1 | 95.9 | 91.9 | 93.9 | ||
| LogitBoost | 0 | 90 | 89.6 | 89.8 | 93.6 |
| 1 | 95.2 | 95.4 | 95.3 | ||
| AdaBoost | 0 | 89.4 | 91.3 | 90.4 | 93.8 |
| 1 | 96 | 95 | 95.5 |
| Paper | Year | Dataset | Model | Performance Based on Accuracy (%) |
|---|---|---|---|---|
| Kumar [26] | 2021 | Malimg and Microsoft BIG 2015 | Deep transfer learning | 98.63 |
| Aslan and Yilmaz [30] | 2021 | Malimg, Microsoft BIG 2015, and Malevis | Hybrid deep learning architecture | 97.78 |
| Kim et al. [33] | 2017 | Microsoft BIG 2015 | Transferred generative adversarial network | 96.36 |
| Cui et al. [34] | 2018 | Malimg | Deep learning using CNN | 94.5 |
| Vinayakumar et al. [35] | 2019 | Malimg | Deep neural networks | 90.4 |
| Saxe and Berlin [36] | 2015 | Their own dataset | Deep neural network | 95 |
| Santos et al. [37] | 2013 | Their own dataset | Machine learning using SVM | 89.6 |
| Firdausi et al. [38] | 2010 | Their own dataset | Machine learning using NB | 65.4 |
| Bozkir et al. [39] | 2021 | Their own dataset | Machine learning using XGBoost | 87.45% |
| Proposed Model | 2022 | Our own dataset | Deep learning | 99.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aslan, Ö. Separating Malicious from Benign Software Using Deep Learning Algorithm. Electronics 2023, 12, 1861. https://doi.org/10.3390/electronics12081861
Aslan Ö. Separating Malicious from Benign Software Using Deep Learning Algorithm. Electronics. 2023; 12(8):1861. https://doi.org/10.3390/electronics12081861
Chicago/Turabian StyleAslan, Ömer. 2023. "Separating Malicious from Benign Software Using Deep Learning Algorithm" Electronics 12, no. 8: 1861. https://doi.org/10.3390/electronics12081861
APA StyleAslan, Ö. (2023). Separating Malicious from Benign Software Using Deep Learning Algorithm. Electronics, 12(8), 1861. https://doi.org/10.3390/electronics12081861