
Evaluation Method of IP Geolocation Database Based on City Delay Characteristics


Abstract
:1. Introduction
- We propose a minimum network segment matching mechanism. This mechanism effectively integrates the network segment information from multiple IP geolocation databases, addressing the issues of address overlap between different databases and candidate address problems within segments.
- We introduce a nearest neighbor network segment matching mechanism. This mechanism expands the candidate cities for a network segment, which is crucial for improving the location accuracy of the segment.
- We put forth the concept of city delay feature (CDC). It accurately describes the delay distribution and delay pattern of a target city obtained from a specific detection point, offering a novel solution to improve the city-level geolocation accuracy of an IP address.
- Finally, we propose a network segment verification algorithm based on city delay features. By leveraging the similarity between the delay distribution of network segments and that of cities, we propose network segment delay feature values for candidate cities and select candidate cities for network segments based on these values.
2. Related Work
3. Evaluation Strategies
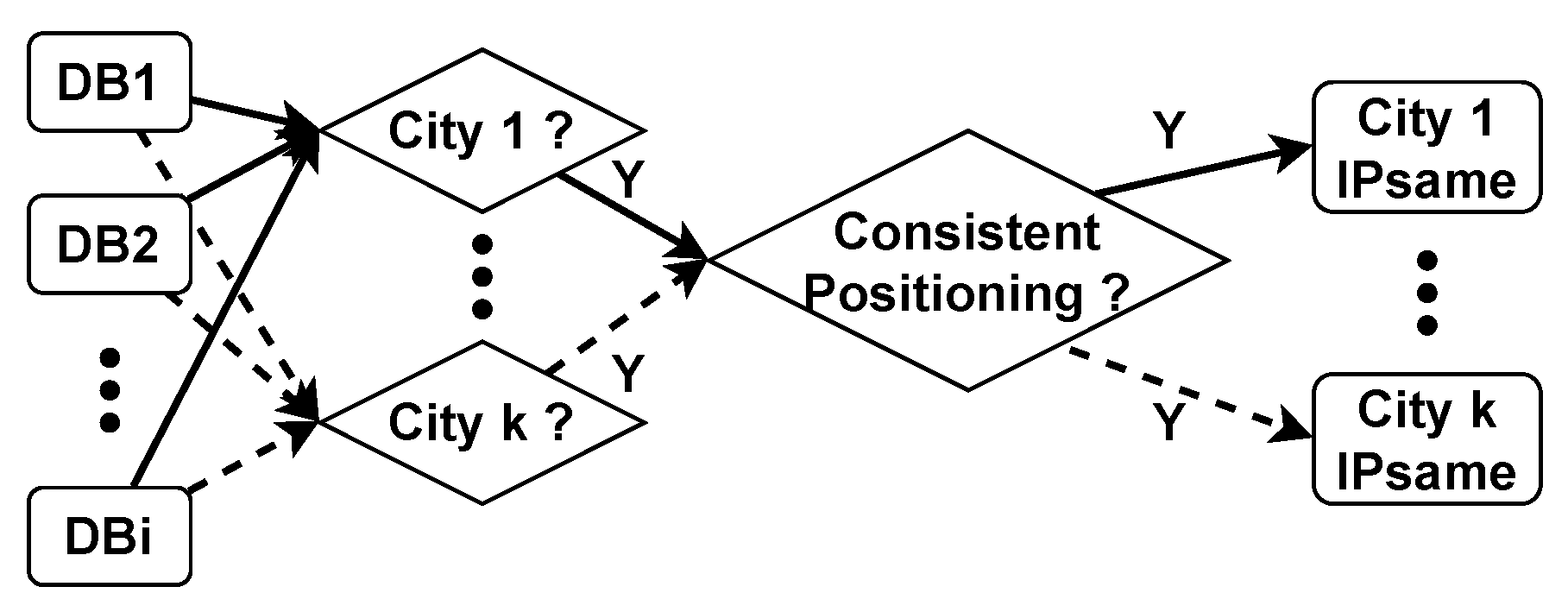
3.1. City-Based Assessment Strategies
3.2. Network Segment-Based Evaluation Strategy
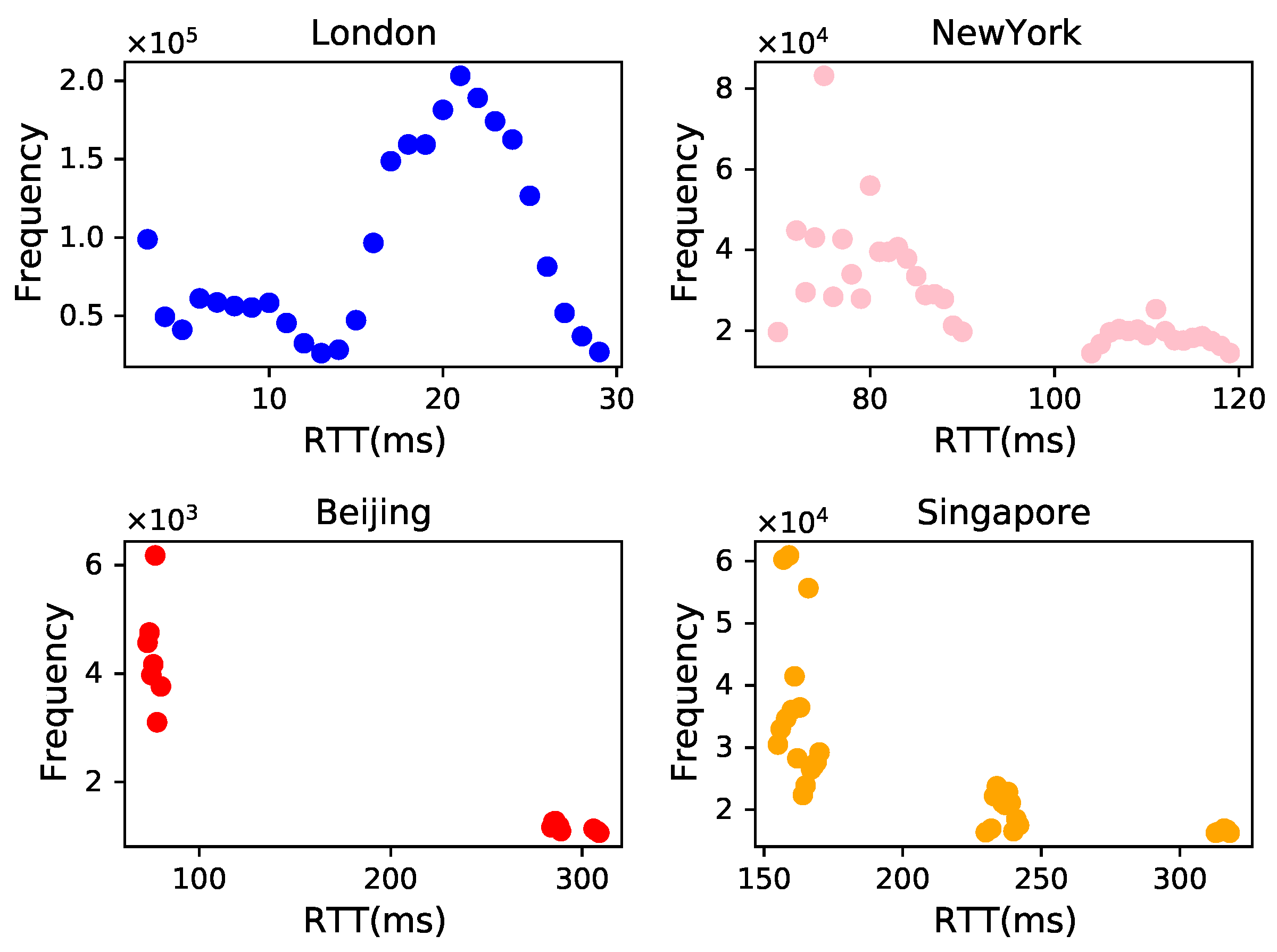
3.3. Evaluation Strategies Based on Delay Distribution
4. Method
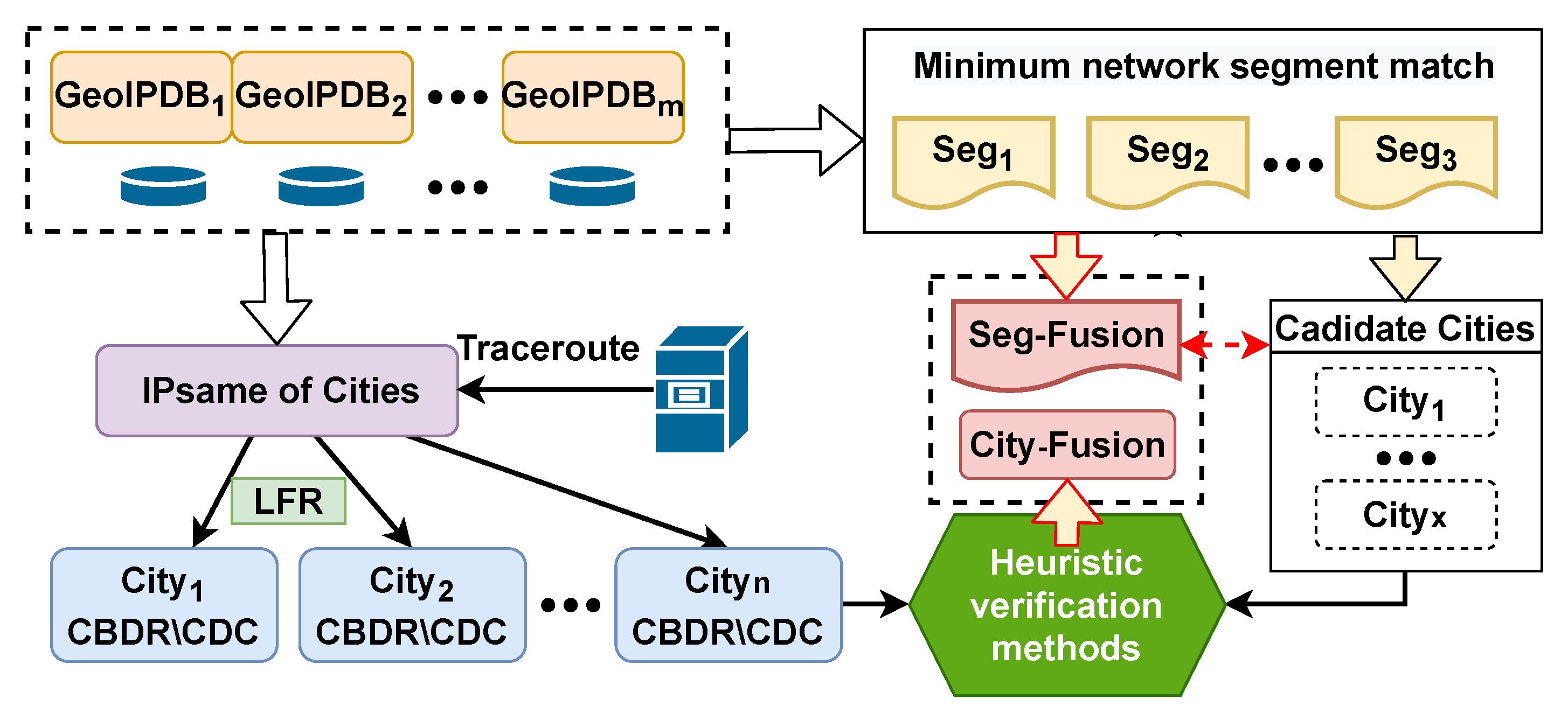
4.1. Overview
- Network Segment: The first is a network segment, which is a set of numerically neighboring IP address clusters, denoted in the text in the form .
- City IP Address Group: The second concept, referred to as a city IP address group, represents a cluster of IP addresses located in the same city.
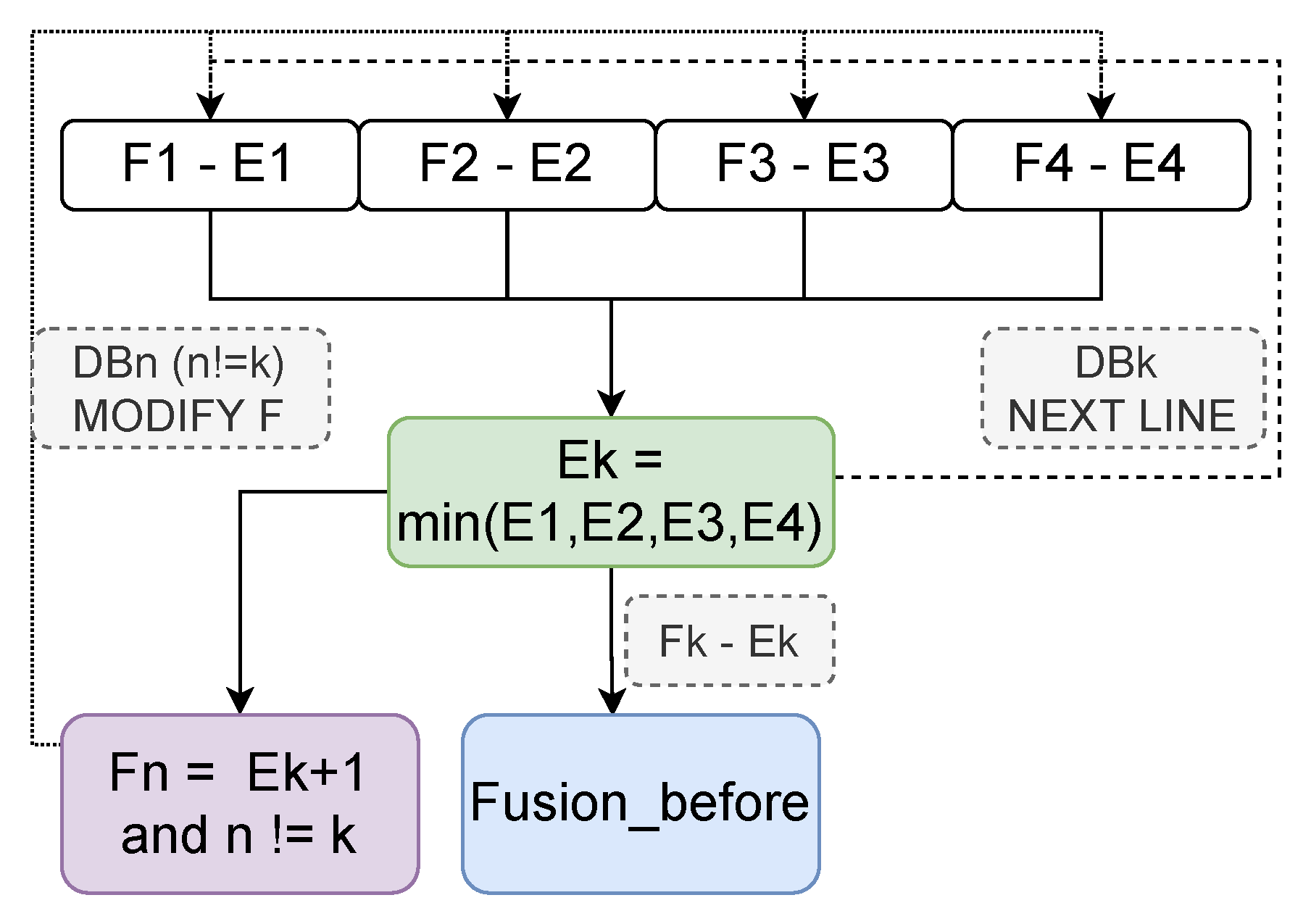
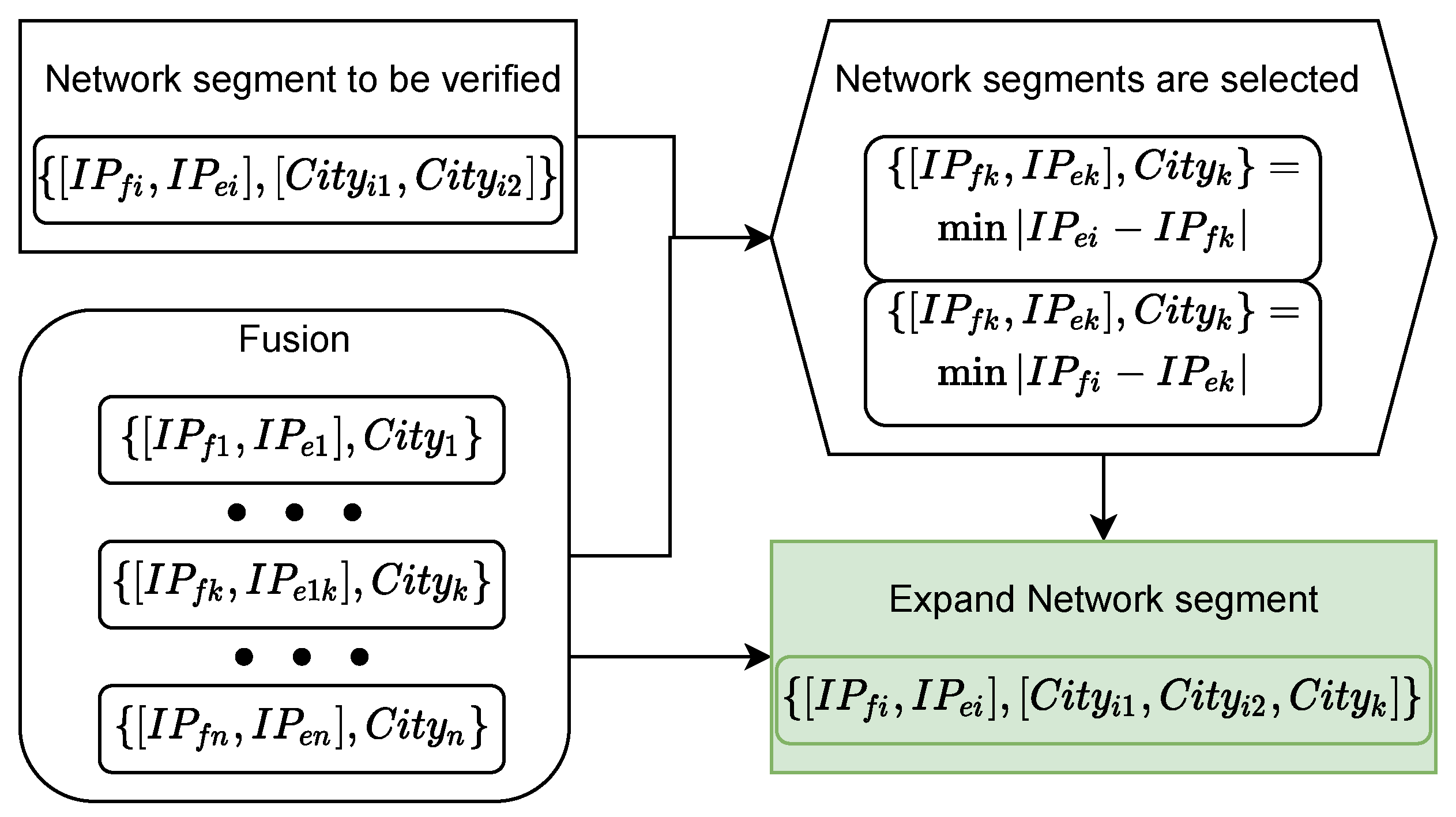
4.2. Minimum Network Segment Matching Mechanism
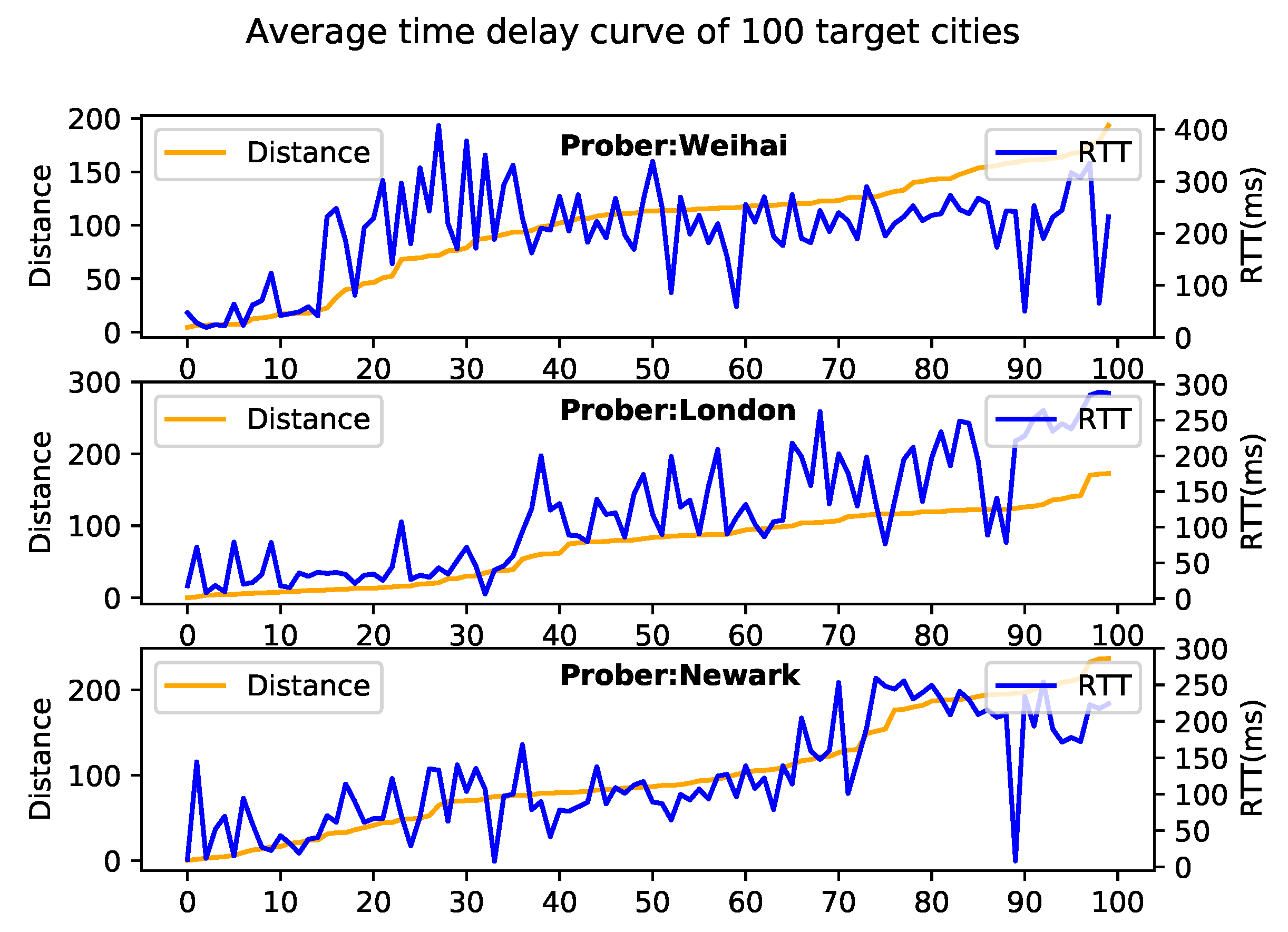
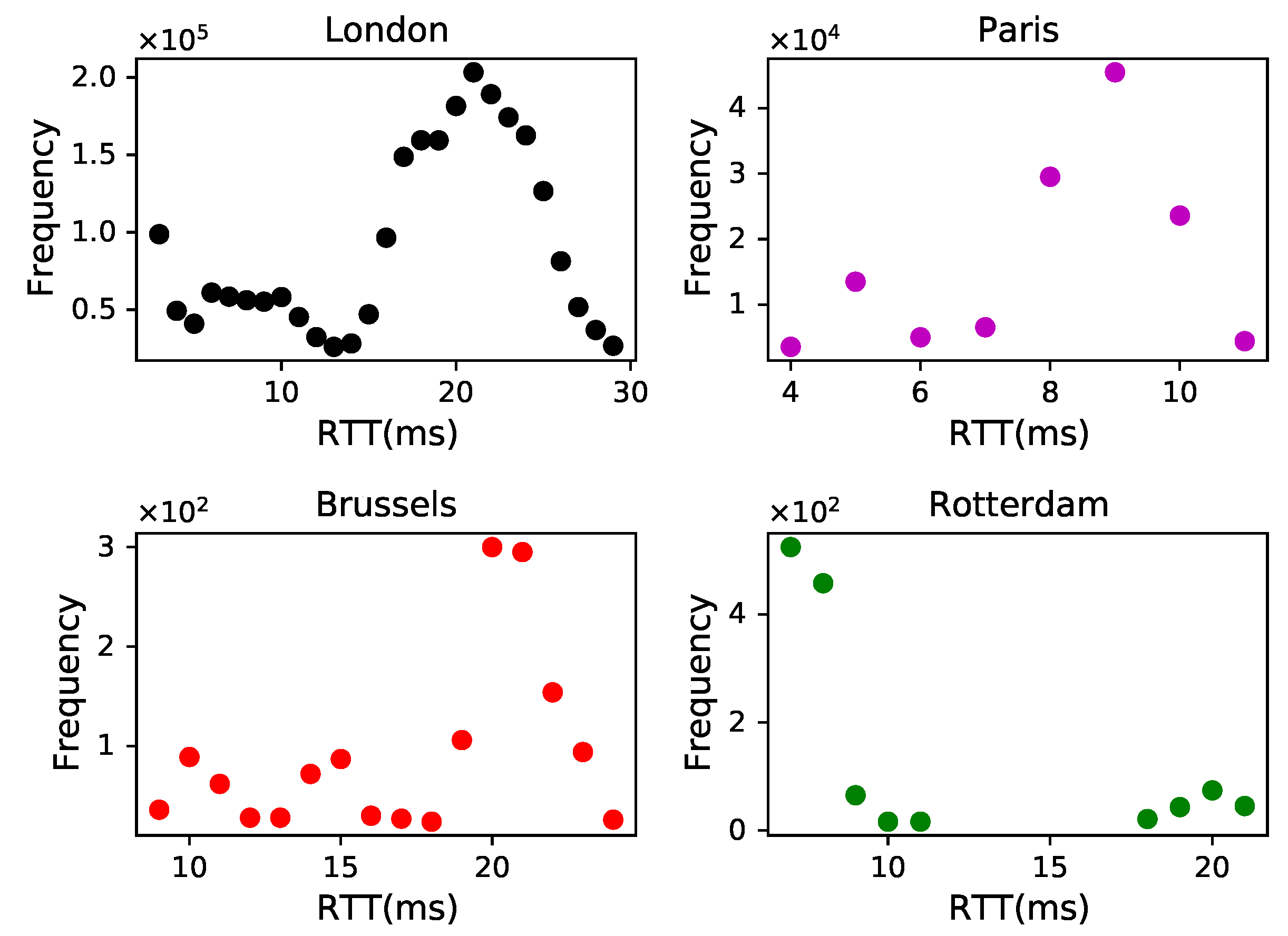
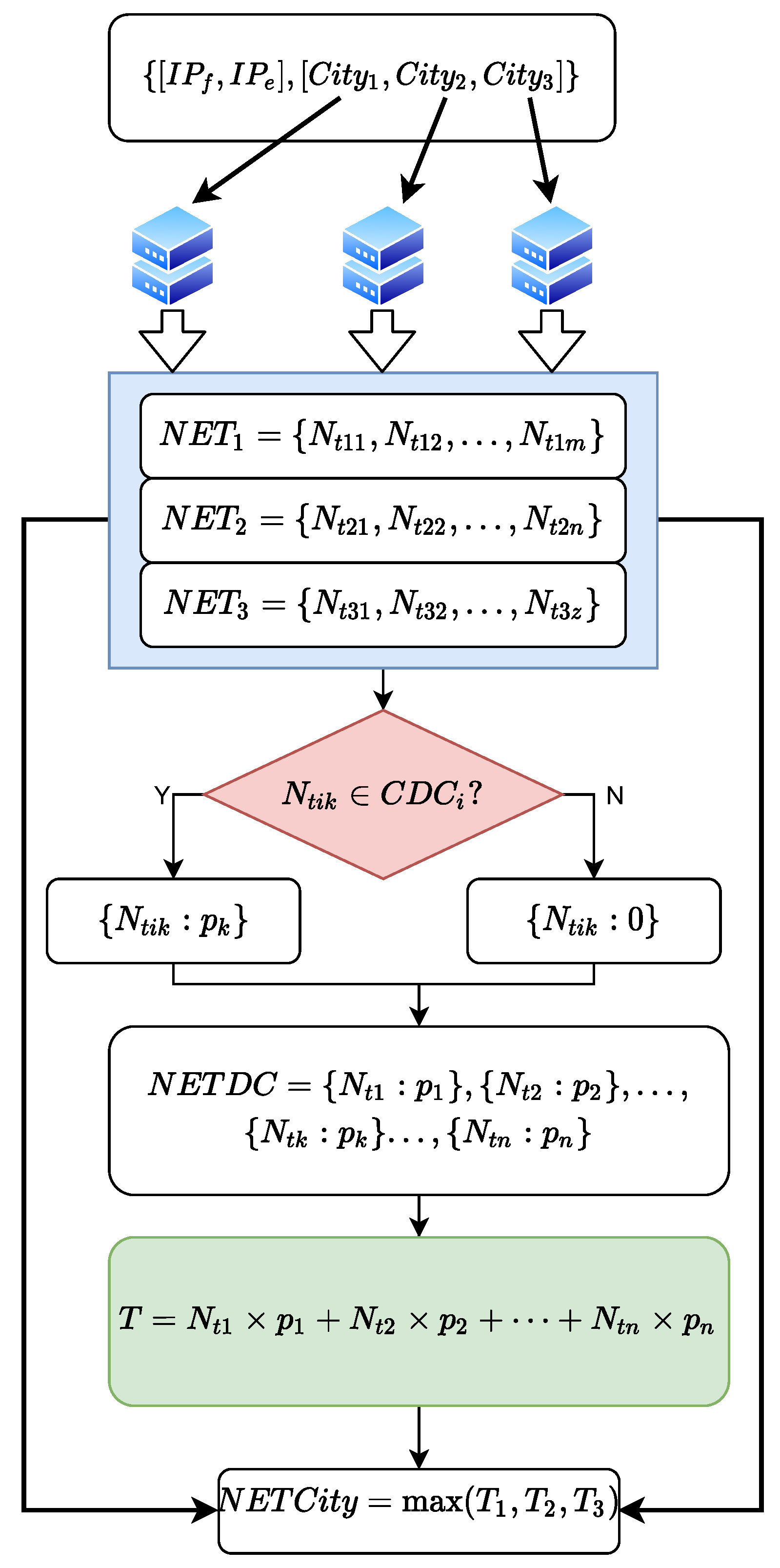
4.3. City Delay Characteristics
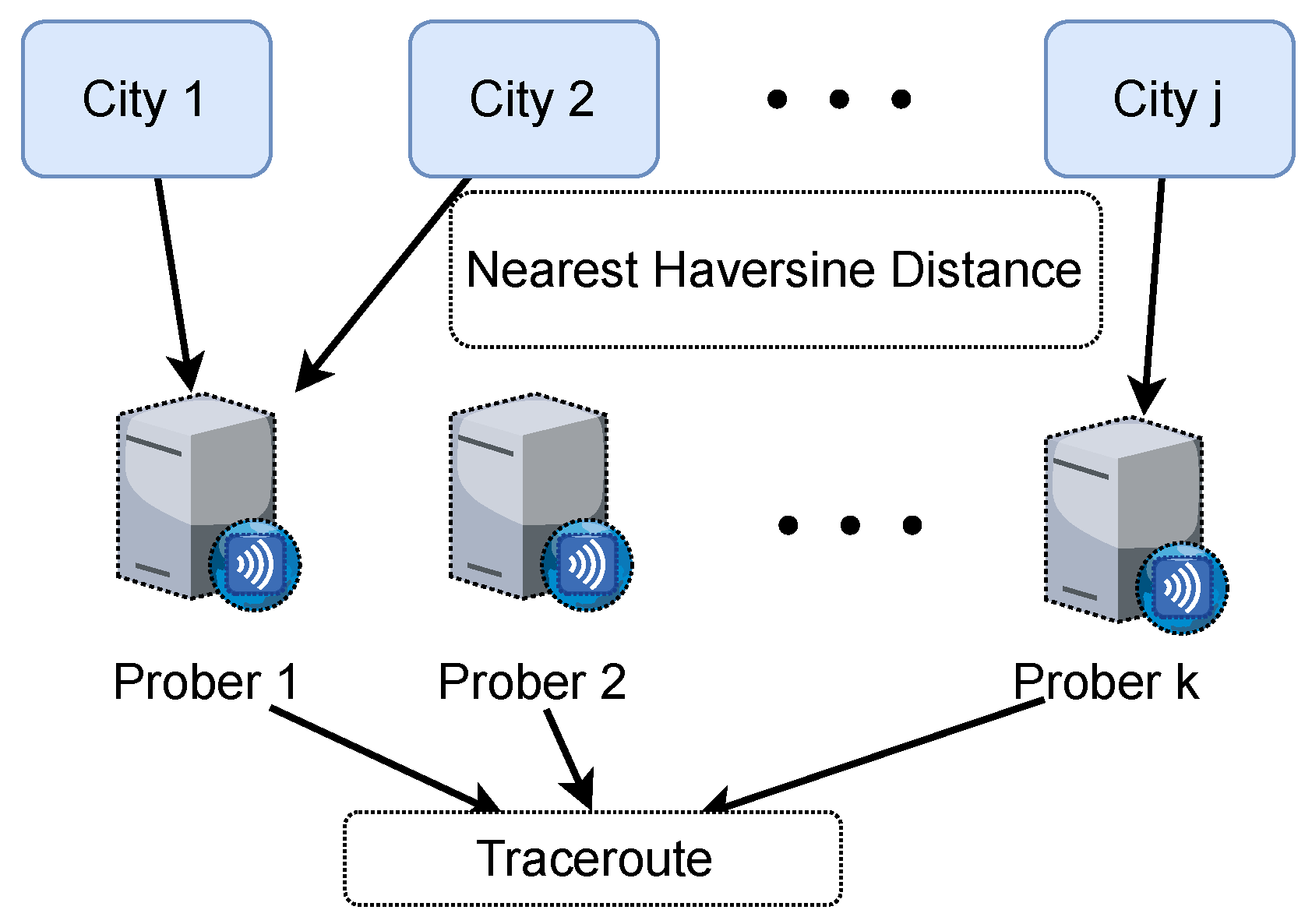
4.4. Geolocation Verification Mechanism
5. Experimentation and Evaluation
5.1. Discussion of Parameter a
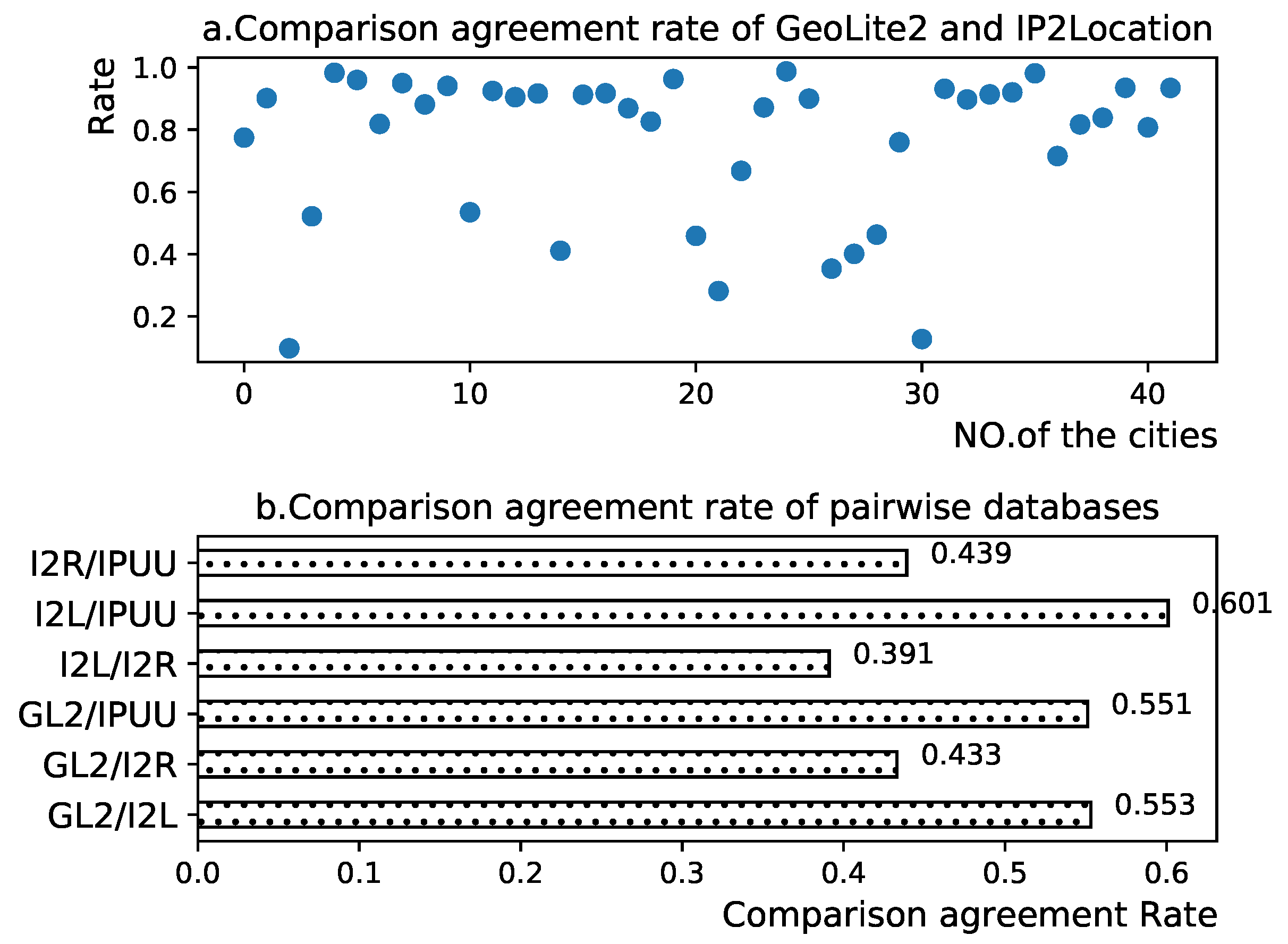
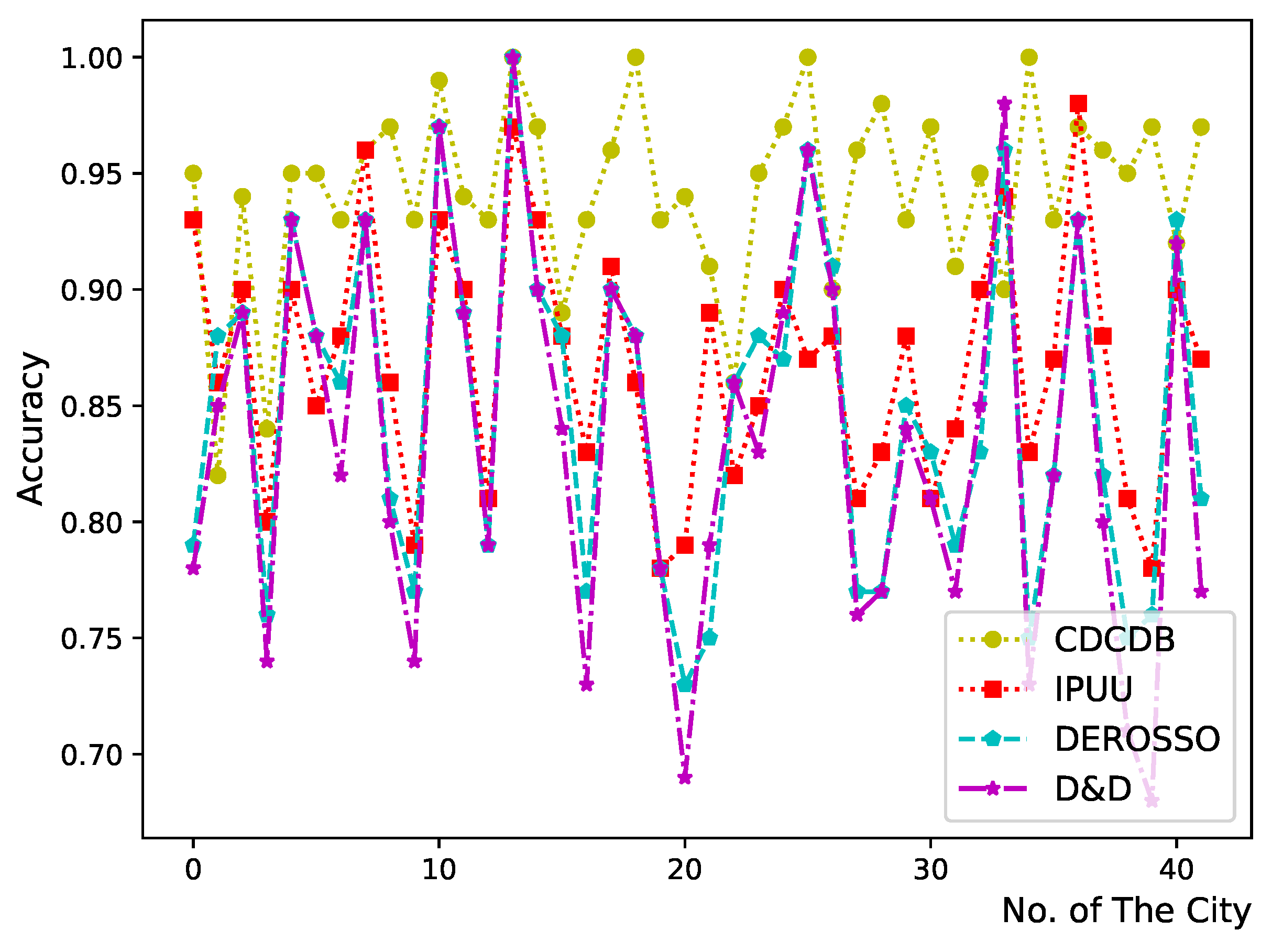
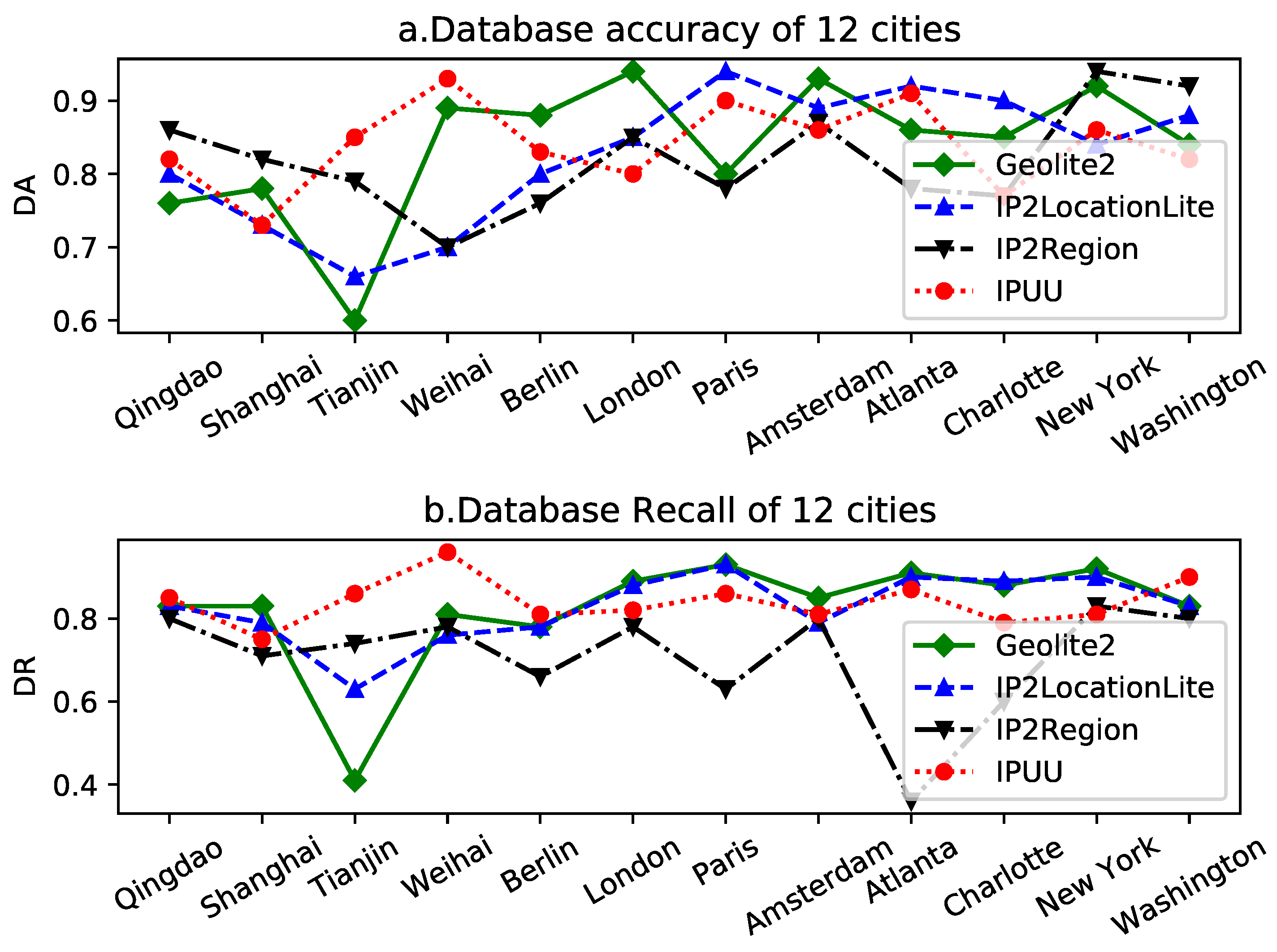
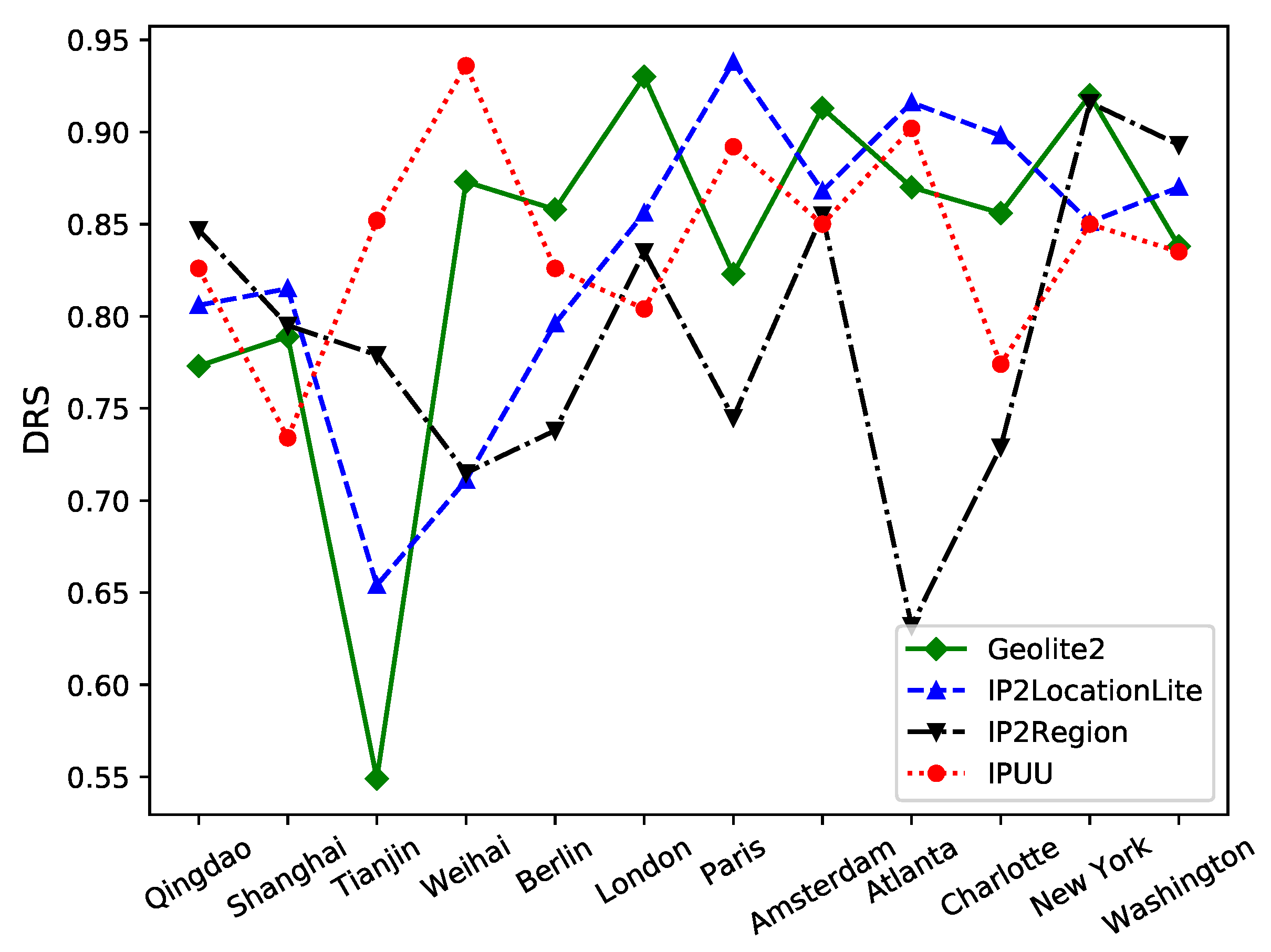
5.2. Analysis and Evaluation
- 1.
- Database Accuracy (): This metric represents the proportion of IP addresses whose geolocation aligns with both the IP geolocation database and the reference database CDCDB, relative to the total number of IPs assigned to the IP geolocation database in that city. Mathematically, it can be expressed as:
- 2.
- Database Recall (): This measure signifies the ratio of the number of IPs with consistent geolocation between the IP geolocation repository and the reference database CDCDB, to the total number of IPs assigned to the reference repository in that city. It can be formulated as:
- 3.
- Database Reliability Score (): This score is a weighted reconciled average of both the database accuracy () and database recall () of the IP geolocation repository. Mathematically, it can be expressed as:
- When , it signifies that and hold equal importance.
- When , it indicates a greater emphasis on .
- Conversely, when , is given more weight.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CDCDB | City delay characterization database |
| CBDR | City boundary delay range |
| CDC | City delay characteristics |
| NETDC | Network segment delay characteristics |
| Database Accuracy | |
| Database Recall | |
| Database Reliability Score |
References
- Li, Q.; Wang, Z.; Tan, D.; Song, J.; Wang, H.; Sun, L.; Liu, J. GeoCAM: An IP-Based Geolocation Service through Fine-Grained and Stable Webcam Landmarks. IEEE/ACM Trans. Netw. 2021, 29, 1798–1812. [Google Scholar] [CrossRef]
- Zhang, Y.; Deng, R.H.; Bertino, E.; Zheng, D. Robust and universal seamless handover authentication in 5G HetNets. IEEE Trans. Dependable Secur. Comput. 2019, 18, 858–874. [Google Scholar] [CrossRef]
- Liu, C.; Luo, X.; Yuan, F.; Liu, F. Rnbg: A ranking nodes based ip geolocation method. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 80–84. [Google Scholar]
- Wang, Z.; Niu, Y.; Chen, H.; Cheng, G.; Cui, J.; Zhang, Z. Target driven IP Geolocation Algorithm. J. Phys. Conf. Ser. 2021, 1861, 012002. [Google Scholar] [CrossRef]
- Rodriguez Garzon, S.; Deva, B. Geofencing 2.0: Taking location-based notifications to the next level. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 921–932. [Google Scholar]
- MaxMind. GeoIP2. 2022. Available online: https://www.maxmind.com/en/geoip2-databases/ (accessed on 30 May 2022).
- IP2Location. IP2Location. 2022. Available online: https://www.ip2location.com/database/ (accessed on 30 May 2022).
- Callejo, P.; Gramaglia, M.; Cuevas, R.; Cuevas, A. A deep dive into the accuracy of IP Geolocation Databases and its impact on online advertising. IEEE Trans. Mob. Comput. 2022, 22, 4359–4373. [Google Scholar] [CrossRef]
- Gouel, M.; Vermeulen, K.; Fourmaux, O.; Friedman, T.; Beverly, R. IP geolocation database stability and implications for network research. In Proceedings of the Network Traffic Measurement and Analysis Conference, Virtual, 14–15 September 2021. [Google Scholar]
- Poese, I.; Uhlig, S.; Kaafar, M.A.; Donnet, B.; Gueye, B. IP geolocation databases: Unreliable? ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53–56. [Google Scholar] [CrossRef]
- Gharaibeh, M.; Shah, A.; Huffaker, B.; Zhang, H.; Ensafi, R.; Papadopoulos, C. A look at router geolocation in public and commercial databases. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 463–469. [Google Scholar]
- Du, B.; Candela, M.; Huffaker, B.; Snoeren, A.C.; Claffy, K. RIPE IPmap active geolocation: Mechanism and performance evaluation. ACM SIGCOMM Comput. Commun. Rev. 2020, 50, 3–10. [Google Scholar] [CrossRef]
- Shavitt, Y.; Zilberman, N. A geolocation databases study. IEEE J. Sel. Areas Commun. 2011, 29, 2044–2056. [Google Scholar] [CrossRef]
- Jiang, H.; Liu, Y.; Matthews, J.N. IP geolocation estimation using neural networks with stable landmarks. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 170–175. [Google Scholar]
- Komosny, D.; Voznak, M.; Rehman, S.U. Location accuracy of commercial IP address geolocation databases. Inf. Technol. Control 2017, 46, 333–344. [Google Scholar] [CrossRef]
- Saxon, J.; Feamster, N. GPS-based geolocation of consumer IP addresses. In Passive and Active Measurement: Proceedings of the 23rd International Conference, PAM 2022, Virtual Event, 28–30 March 2022; Springer: Cham, Switzerland, 2022; pp. 122–151. [Google Scholar]
- Huffaker, B.; Fomenkov, M.; Claffy, K.C. Geocompare: A Comparison of Public and Commercial Geolocation Databases; Technical Report; Cooperative Association for Internet Data Analysis (CAIDA): San Diego, CA, USA, 2011. [Google Scholar]
- Li, H.; Zhang, P.; Wang, Z.; Du, F.; Kuang, Y.; An, Y. Changing IP geolocation from arbitrary database query towards multi-databases fusion. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 1150–1157. [Google Scholar]
- Bo, X.; Han, L.; Yong, W. An IP geolocation database evaluation and fusion model based on data correlation and delay similarity. In Proceedings of the 2nd International Conference on Telecommunications and Communication Engineering, Beijing, China, 28–30 November 2018; pp. 231–236. [Google Scholar]
- Zu, S.; Luo, X.; Zhang, F. IP-geolocater: A more reliable IP geolocation algorithm based on router error training. Front. Comput. Sci. 2022, 16, 161504. [Google Scholar] [CrossRef]
- Zu, S.; Luo, X.; Du, S.; Wang, L. A delay deviation tolerance IP geolocation method with error estimation. Sci. Rep. 2022, 12, 13919. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Zhang, S.; Li, N.; Li, T.; Hu, X.; Feng, H.; Zhou, Q.; Liu, F.; Quan, X.; Wang, H.; et al. GraphNEI: A GNN-based network entity identification method for IP geolocation. Comput. Netw. 2023, 235, 109946. [Google Scholar] [CrossRef]
- Cozar, M.; Rodriguez, D.; Del Alamo, J.M.; Guaman, D. Reliability of IP geolocation services for assessing the compliance of international data transfers. In Proceedings of the 2022 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Genoa, Italy, 6–10 June 2022; pp. 181–185. [Google Scholar]
- Livadariu, I.; Dreibholz, T.; Al-Selwi, A.S.; Bryhni, H.; Lysne, O.; Bjørnstad, S.; Elmokashfi, A. On the accuracy of country-level IP geolocation. In Proceedings of the Applied Networking Research Workshop, Virtual, 27–30 July 2020; pp. 67–73. [Google Scholar]
- Ganelin, D.; Chuang, I. IP geolocation underestimates regressive economic patterns in MOOC usage. In Proceedings of the 11th International Conference on Education Technology and Computers, Amsterdam, The Netherlands, 28–31 October 2019; pp. 268–272. [Google Scholar]
- Xu, W.; Tao, Y.; Guan, X. Experimental comparison of free IP Geolocation services. In Security with Intelligent Computing and Big-Data Services: Proceedings of the Second International Conference on Security with Intelligent Computing and Big Data Services (SICBS-2018), Guilin, China, 14–16 December 2018; Springer: Cham, Switzerland, 2020; pp. 198–208. [Google Scholar]
- Sommers, J. A web client perspective on ip geolocation accuracy. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), IEEE, Montreal, QC, Canada, 20–22 October 2020; pp. 1–8. [Google Scholar]
- Dan, O.; Parikh, V.; Davison, B.D. IP Geolocation through Geographic Clicks. ACM Trans. Spat. Algorithms Syst. (TSAS) 2022, 8, 1–22. [Google Scholar] [CrossRef]
- Li, R.; Xu, R.; Ma, Y.; Luo, X. LandmarkMiner: Street-level network landmarks mining method for IP geolocation. ACM Trans. Internet Things 2021, 2, 1–22. [Google Scholar] [CrossRef]
- AIWEN-TECH. IPUU. 2022. Available online: https://mall.ipplus360.com/pros/IPVFourGeoDB/ (accessed on 27 April 2022).
- IP2Region. IP2Region. 2022. Available online: https://github.com/zoujingli/ip2region/ (accessed on 30 May 2022).
- Gharaibeh, M. Characterizing the Visible Address Space to Enable Efficient Continuous IP Geolocation. Ph.D. Thesis, Colorado State University, Fort Collins, CO, USA, 2020. [Google Scholar]
- Gan, Y.; Zhang, H.; Liu, Y.; He, L. IP Geolocation Method Based on Neighbor IP Sequences. In Proceedings of the 2020 6th International Symposium on System and Software Reliability (ISSSR), IEEE, Chengdu, China, 24–25 October 2020; pp. 46–51. [Google Scholar]
- Zhao, Q.; Wang, F.; Huang, C.; Yu, C. Improving IP geolocation databases based on multi-method classification. In Proceedings of the 2020 IEEE 14th International Conference on Anti-counterfeiting, Security, and Identification (ASID), Xiamen, China, 30 October–1 November 2020; pp. 44–48. [Google Scholar]
- Marchetta, P.; Botta, A.; Katz-Bassett, E.; Pescapé, A. Dissecting round trip time on the slow path with a single packet. In Passive and Active Measurement: Proceedings of the 15th International Conference, PAM 2014, Los Angeles, CA, USA, 10–11 March 2014; Springer: Cham, Switzerland, 2014; pp. 88–97. [Google Scholar]
- Zhao, F.; Luo, X.; Gan, Y.; Zu, S.; Cheng, Q.; Liu, F. IP Geolocation based on identification routers and local delay distribution similarity. Concurr. Comput. Pract. Exp. 2019, 31, e4722. [Google Scholar] [CrossRef]
- Van Brummelen, G.; Hamm, E.A. Heavenly mathematics: The forgotten art of spherical trigonometry. Aestimatio Sources Stud. Hist. Sci. 2014, 11, 127–130. [Google Scholar] [CrossRef]
- CAIDA. Macroscopic Internet Topology Data Kit. 2022. Available online: https://www.caida.org/catalog/datasets/internet-topology-data-kit/ (accessed on 14 June 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
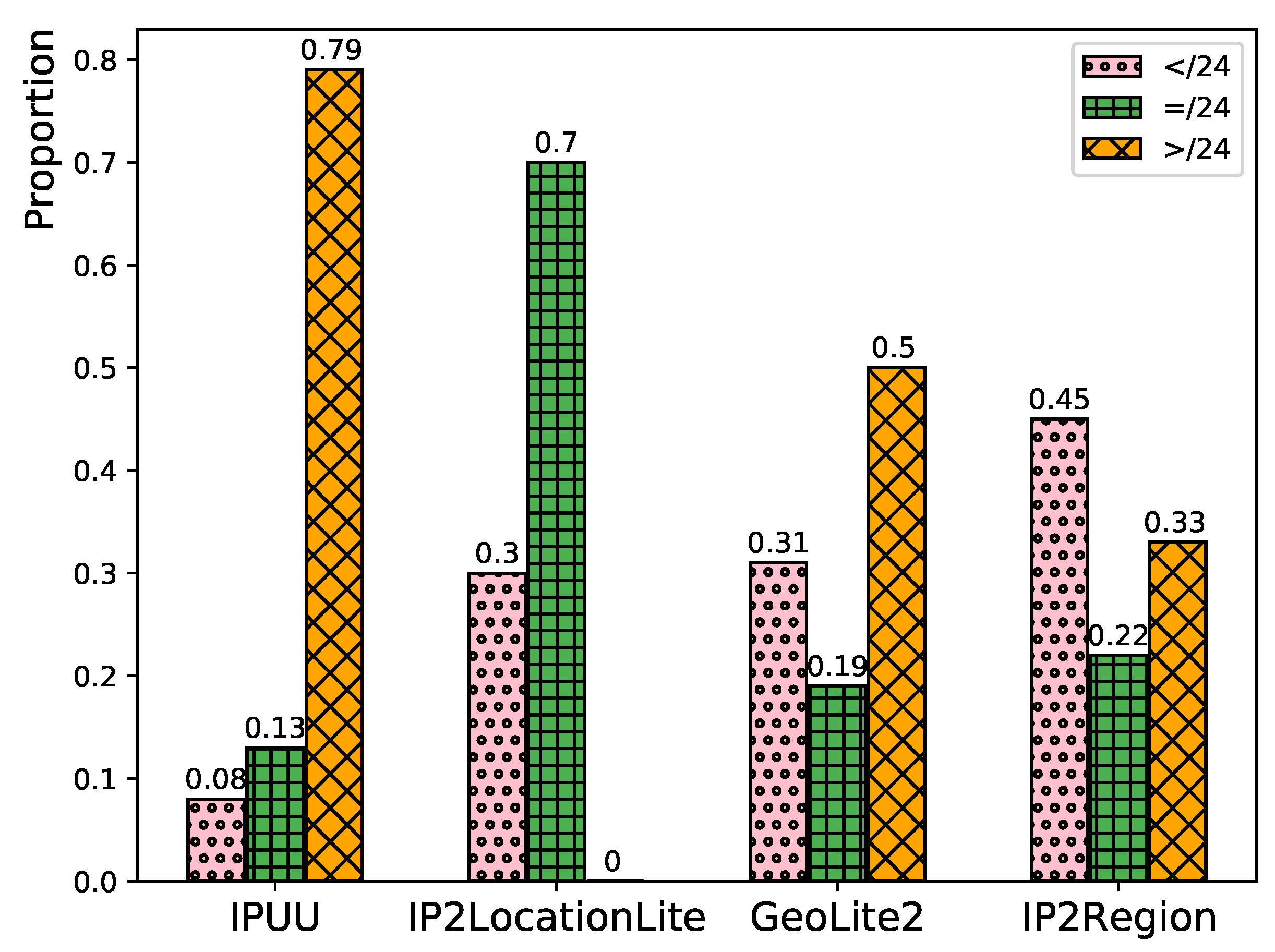
| Database | Network Segments | Coverage | |||
|---|---|---|---|---|---|
| ALL | Country | City | Country | City | |
| IPUU | 13,704,888 | 13,701,348 | 10,838,666 | 99.97% | 79.08% |
| IP2LocationLite | 3,841,655 | 3,834,796 | 3,831,202 | 99.82% | 99.73% |
| GeoLite2 | 3,463,148 | 3,463,046 | 3,463,046 | 99.99% | 99.99% |
| IP2Region | 1,023,551 | 1,023,533 | 338,311 | 99.99% | 33.05% |
| Parameter | Delay Range (ms) | Proportion of Remain IPs |
|---|---|---|
| a = 100 | 49 | 66% |
| a = 200 | 79 | 90% |
| a = 1000 | 101 | 95% |
| Parameter | Delay Range (ms) | Proportion of Remain IPs |
|---|---|---|
| a = 100 | 26.78 | 74.5% |
| a = 200 | 40.21 | 83.8% |
| a = 1000 | 72.57 | 91.4% |
| Database | NO. of Net-Segments | High-Quality Network Segments | City Coverage |
|---|---|---|---|
| CDCDB | 16,274,675 | 15,005,250 | 99.99% |
| IPUU | 13,704,888 | 10,826,862 | 79% |
| GeoLite2 | IP2LocationLite | IP2Region | IPUU | |
|---|---|---|---|---|
| Average | 83.3% | 83.2% | 78.99% | 84% |
| Variance | 0.009 | 0.006 | 0.0063 | 0.0028 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Y.; Zhang, Z.; Liu, Y.; Chen, E.; Li, N. Evaluation Method of IP Geolocation Database Based on City Delay Characteristics. Electronics 2024, 13, 15. https://doi.org/10.3390/electronics13010015
Xie Y, Zhang Z, Liu Y, Chen E, Li N. Evaluation Method of IP Geolocation Database Based on City Delay Characteristics. Electronics. 2024; 13(1):15. https://doi.org/10.3390/electronics13010015
Chicago/Turabian StyleXie, Yuancheng, Zhaoxin Zhang, Yang Liu, Enhao Chen, and Ning Li. 2024. "Evaluation Method of IP Geolocation Database Based on City Delay Characteristics" Electronics 13, no. 1: 15. https://doi.org/10.3390/electronics13010015
APA StyleXie, Y., Zhang, Z., Liu, Y., Chen, E., & Li, N. (2024). Evaluation Method of IP Geolocation Database Based on City Delay Characteristics. Electronics, 13(1), 15. https://doi.org/10.3390/electronics13010015