


A Residual Network with Efficient Transformer for Lightweight Image Super-Resolution


Abstract
:1. Introduction
- We propose a local feature extraction module that utilizes BSConv and two efficient attention modules and demonstrate its effectiveness at SR tasks.
- We propose an efficient transformer module that enhances global feature extraction without significantly increasing computational complexity. This module contributes to producing more-detailed restored images.
- We propose a strategy of local residual connections, which differs from the commonly used feature distillation approach. This strategy maintains a low parameter count and achieves excellent performance.
2. Related Work
2.1. CNN-Based Image Super-Resolution
2.2. Efficient Super-Resolution
2.3. Vision Transformer
3. Method
3.1. Network Structure
3.2. Hybrid Feature Extraction Block
3.2.1. BSConv
3.2.2. ESA and CCA
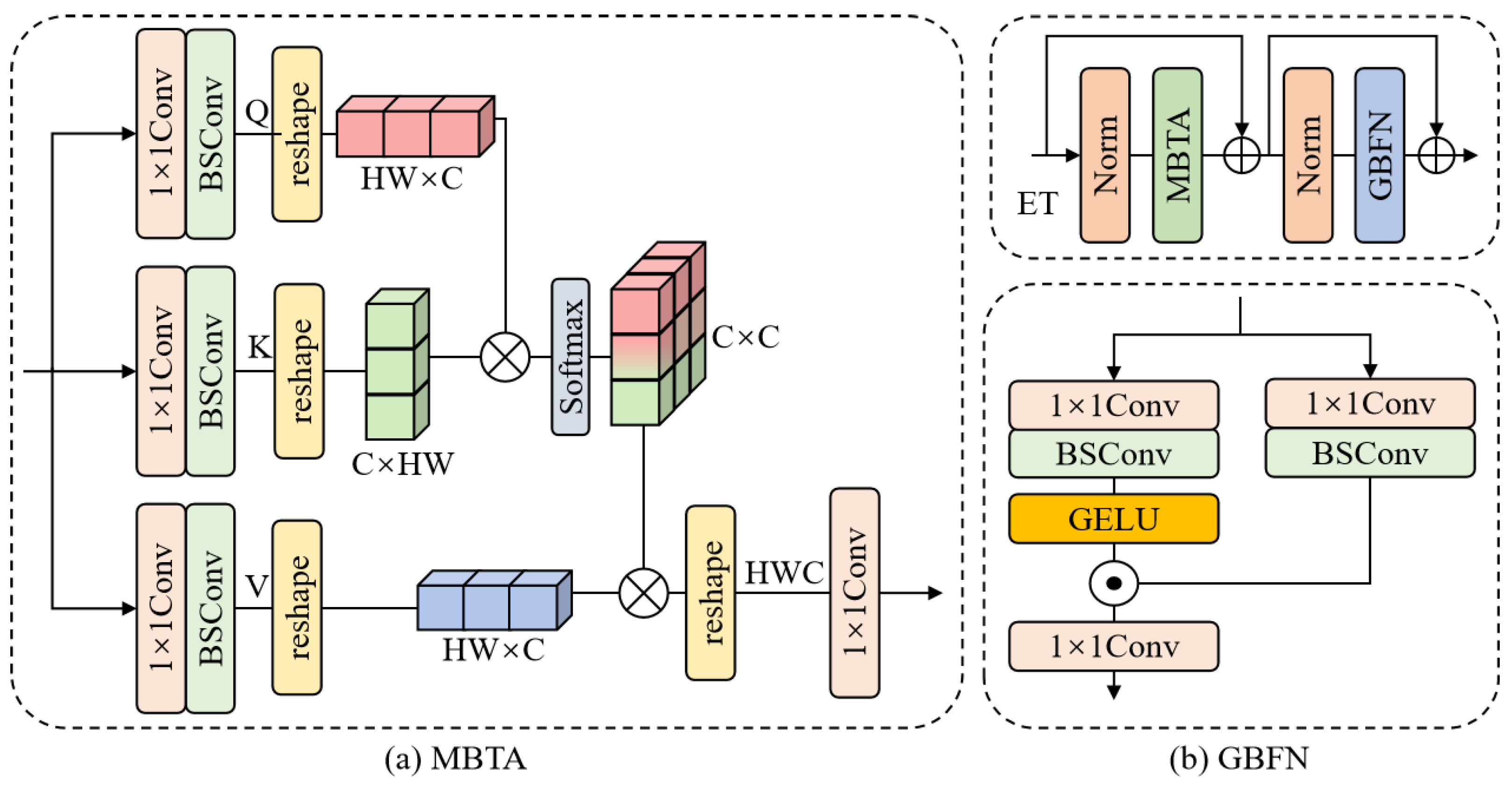
3.3. Efficient Transformer
3.3.1. Multi-BSConv Head Transposed Attention (MBTA)
3.3.2. Gated-BSConv Feed-Forward Network (GBFN)
3.4. Loss Function
4. Experiments
4.1. Experiment Setup
4.1.1. Datasets and Metrics
4.1.2. Training Details
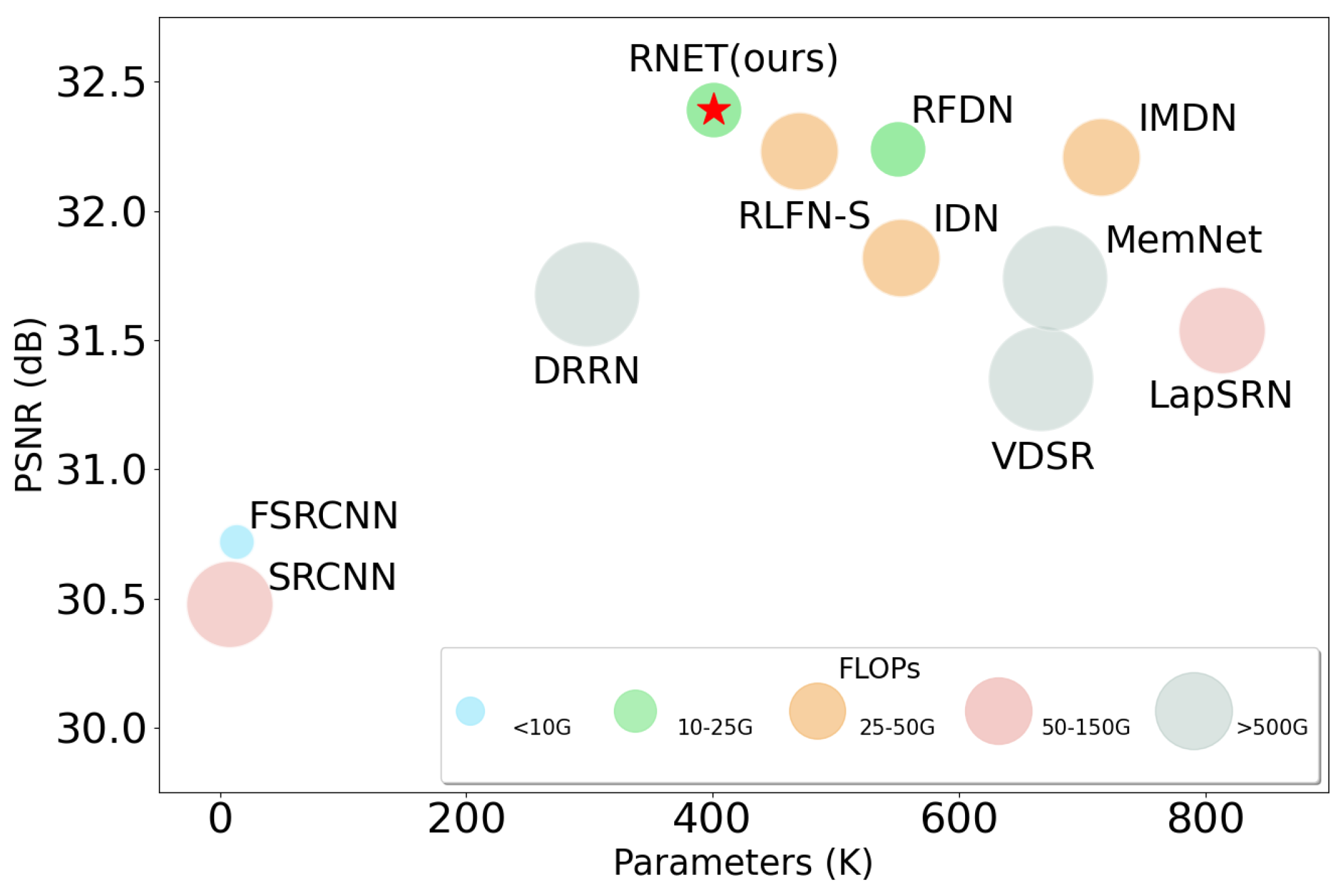
4.2. Quantitative Results
4.2.1. Comparison Results
4.2.2. Visual Results
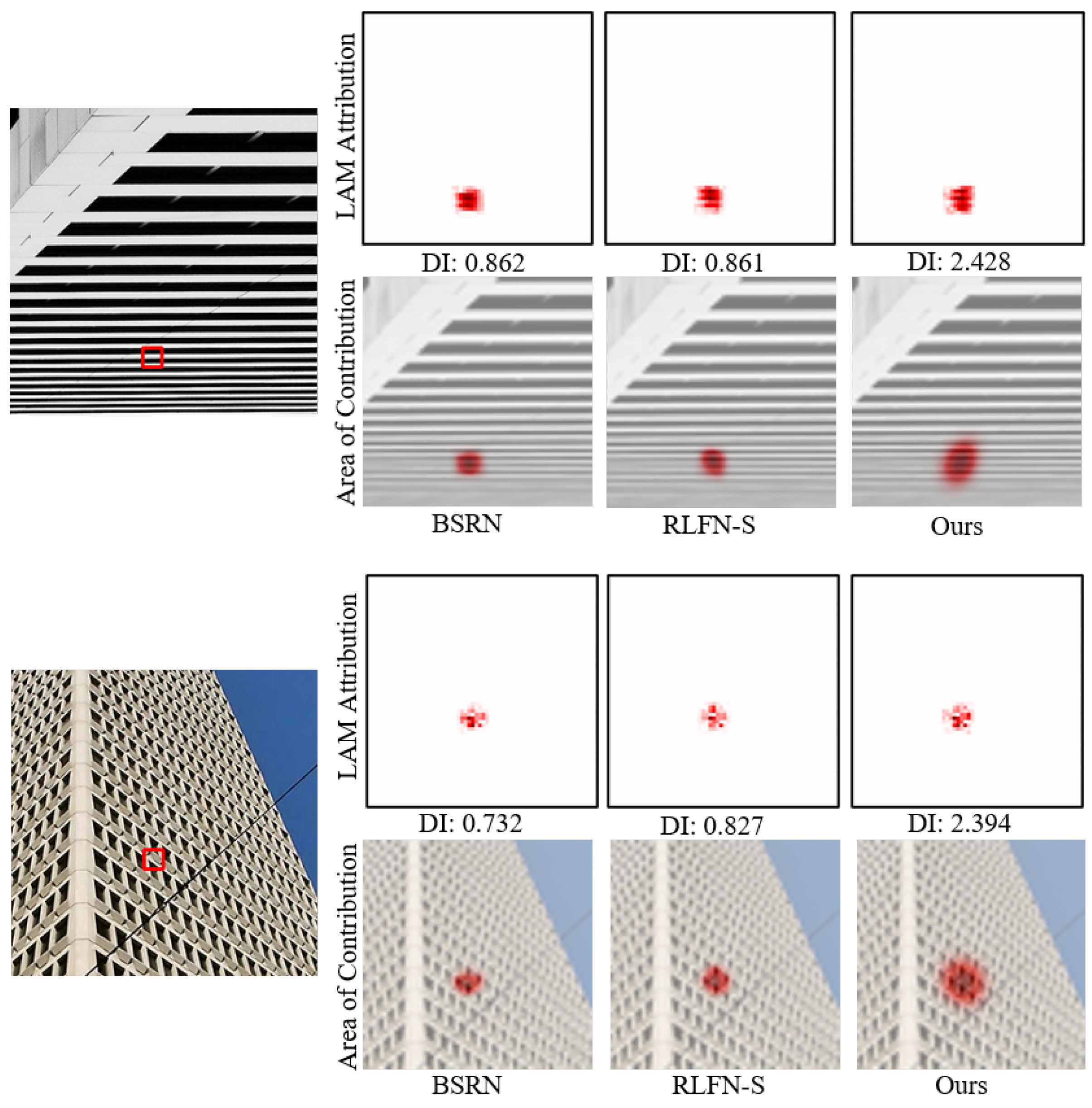
4.2.3. LAM Results
4.2.4. Computational Cost and Model Complexity Analysis
4.2.5. Comparison with Other Transformer-Based Methods
4.3. Ablation Study
4.3.1. The Depth and Width of the Network
4.3.2. Ablation Study of Efficient Transformer (ET) Block
4.3.3. Different Activation Function in HFEB
4.3.4. Effectiveness of ESA and CCA Blocks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Freeman, W.T.; Pasztor, E.C.; Carmichael, O.T. Learning low-level vision. Int. J. Comput. Vis. 2000, 40, 25–47. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Vattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Li, W.; Lu, X.; Lu, J.; Zhang, X.; Jia, J. On efficient transformer and image pre-training for low-level vision. arXiv 2021, arXiv:2112.10175. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R. Multi-objective reinforced evolution in mobile neural architecture search. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2021; pp. 99–113. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Haase, D.; Amthor, M. Rethinking depthwise separable convolutions: How intra-kernel correlations lead to improved mobilenets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14600–14609. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W. Image denoising using deep CNN with batch renormalization. Neural Netw. 2020, 121, 461–473. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Ren, W.; Hu, Z.; Yang, M.H. Learning to deblur images with exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1412–1425. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Zhou, S.; Zhang, J.; Zuo, W.; Loy, C.C. Cross-scale internal graph neural network for image super-resolution. Adv. Neural Inf. Process. Syst. 2020, 33, 3499–3509. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Zhang, X.; Zeng, H.; Zhang, L. Edge-oriented convolution block for real-time super resolution on mobile devices. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4034–4043. [Google Scholar]
- Han, K.; Rezende, R.S.; Ham, B.; Wong, K.Y.K.; Cho, M.; Schmid, C.; Ponce, J. Scnet: Learning semantic correspondence. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1831–1840. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Contextual transformation network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Detail-preserving transformer for light field image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2522–2530. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 1–10. Available online: https://people.rennes.inria.fr/Aline.Roumy//publi/12bmvc_Bevilacqua_lowComplexitySR.pdf (accessed on 26 December 2023).
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Proceedings Eighth IEEE International Conference on Computer Vision, ICCV, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–55. [Google Scholar]
- Kong, F.; Li, M.; Liu, S.; Liu, D.; He, J.; Bai, Y.; Chen, F.; Fu, L. Residual local feature network for efficient super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 766–776. [Google Scholar]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar]
- Li, Z.; Liu, Y.; Chen, X.; Cai, H.; Gu, J.; Qiao, Y.; Dong, C. Blueprint separable residual network for efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 833–843. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | Parameters | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
| Bicubic | ×2 | - | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| SRCNN [2] | 24 K | 36.66/0.9542 | 32.45/0.9067 | 31.36/0.8879 | 29.50/0.8946 | 35.60/0.9663 | |
| FSRCNN [18] | 12 K | 37.00/0.9558 | 32.63/0.9088 | 31.53/0.8920 | 29.88/0.9020 | 36.67/0.9710 | |
| VDSR [3] | 666 K | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 | 37.22/0.9750 | |
| DRRN [30] | 298 K | 37.74/0.9591 | 33.23/0.9136 | 32.05/0.8973 | 31.23/0.9188 | 37.88/0.9749 | |
| LapSRN [31] | 251 K | 37.52/0.9591 | 32.99/0.9124 | 31.80/0.8952 | 30.41/0.9103 | 37.27/0.9740 | |
| MemNet [32] | 678 K | 37.78/0.9597 | 33.28/0.9142 | 32.08/0.8978 | 31.31/0.9195 | 37.72/0.9740 | |
| IDN [17] | 553 K | 37.83/0.9600 | 33.30/0.9148 | 32.08/0.8985 | 31.27/0.9196 | 38.01/0.9749 | |
| IMDN [22] | 694 K | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 | |
| RFDN [49] | 534 K | 38.05/0.9606 | 33.68/0.9184 | 32.16/0.8994 | 32.12/0.9278 | 38.88/0.9773 | |
| RLFN-S [50] | 454 K | 38.05/0.9607 | 33.68/0.9172 | 32.19/0.8997 | 32.17/0.9286 | -/- | |
| RNET (Ours) | 385 K | 38.10/0.9612 | 33.69/0.9190 | 32.23/0.9009 | 32.31/0.9289 | 39.01/0.9778 | |
| Bicubic | ×3 | - | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | 26.95/0.8556 |
| SRCNN [2] | 8 K | 32.75/0.9090 | 29.30/0.8215 | 28.41/0.7863 | 26.24/0.7989 | 30.48/0.9117 | |
| FSRCNN [18] | 13 K | 33.18/0.9140 | 29.37/0.8240 | 28.53/0.7910 | 26.43/0.8080 | 31.10/0.9210 | |
| VDSR [3] | 666 K | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 | 32.01/0.9340 | |
| DRRN [30] | 298 K | 34.03/0.9244 | 29.96/0.8349 | 28.95/0.8004 | 27.53/0.8378 | 32.71/0.9379 | |
| MemNet [32] | 678 K | 34.09/0.9248 | 30.00/0.8350 | 28.96/0.8001 | 27.56/0.8376 | 32.51/0.9369 | |
| IDN [17] | 553 K | 34.11/0.9253 | 29.99/0.8354 | 28.95/0.8013 | 27.42/0.8359 | 32.71/0.9381 | |
| LAPAR-A [19] | 544 K | 34.36/0.9267 | 30.34/0.8421 | 29.11/0.8054 | 28.15/0.8523 | 33.51/.09441 | |
| IMDN [22] | 703 K | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 | |
| RFDN [49] | 541 K | 34.41/0.9273 | 30.34/0.8420 | 29.09/0.8050 | 28.21/0.8525 | 33.67/0.9449 | |
| RLFN-S [50] | - | -/- | -/- | -/- | -/- | -/- | |
| RNET (Ours) | 400 K | 34.56/0.9284 | 30.43/0.8438 | 29.17/0.8080 | 28.36/0.8550 | 33.85/0.9463 | |
| Bicubic | ×4 | - | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | 24.89/0.7866 |
| SRCNN [2] | 8 K | 30.48/0.8626 | 27.50/0.7513 | 26.90/0.7101 | 24.52/0.7221 | 27.58/0.8555 | |
| FSRCNN [18] | 13 K | 30.72/0.8660 | 27.61/0.7550 | 26.98/0.7150 | 24.62/0.7280 | 27.90/0.8610 | |
| VDSR [3] | 666 K | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 | 28.83/0.8870 | |
| DRRN [30] | 298 K | 31.68/0.8888 | 28.21/0.7720 | 27.38/0.7284 | 25.44/0.7638 | 29.45/0.8946 | |
| LapSRN [31] | 813 K | 31.54/0.8852 | 28.09/0.7700 | 27.32/0.7275 | 25.21/0.7562 | 29.09/0.8900 | |
| MemNet [32] | 678 K | 31.74/0.8893 | 28.26/0.7723 | 27.40/0.7281 | 25.50/0.7630 | 29.42/0.8942 | |
| IDN [17] | 553 K | 31.82/0.8903 | 28.25/0.7730 | 27.41/0.7297 | 25.41/0.7632 | 29.41/0.8942 | |
| IMDN [22] | 715 K | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 | |
| RFDN [49] | 550 K | 32.24/0.8952 | 28.61/0.7819 | 27.57/0.7360 | 26.11/0.7858 | 30.58/0.9089 | |
| RLFN-S [50] | 470 K | 32.23/0.8961 | 28.61/0.7818 | 27.58/0.7359 | 26.15/0.7866 | -/- | |
| RNET (Ours) | 401 K | 32.39/0.8976 | 28.68/0.7837 | 27.65/0.7403 | 26.24/0.7894 | 30.67/0.9102 |
| Method | Parameters | Activations | FLOPs | Runtime | Memory |
|---|---|---|---|---|---|
| VDSR [3] | 666 K | 2.38 G | 612.6 G | 0.037 s | 340 MB |
| LapSRN [31] | 813 K | 0.58 G | 149.4 G | 0.020 s | 360 MB |
| DRRN [30] | 298 K | 24.89 G | 6796.9 G | 0.556 s | 827 MB |
| IMDN [22] | 715 K | 0.15 G | 40.9 G | 0.015 s | 228 MB |
| RLFN-S [50] | 470 K | 0.12 G | 25.6 G | 0.018 s | 170 MB |
| RNET (Ours) | 401 K | 0.17 G | 20.4 G | 0.022 s | 230 MB |
| Method | Parameters | FLOPs | Set5 PSNR/SSIM | Set14 PSNR/SSIM |
|---|---|---|---|---|
| SwinIR [11] | 897 K | 49.6 G | 32.44/0.8976 | 28.77/0.7858 |
| ESRT [53] | 751 K | 67.7 G | 32.19/0.8947 | 28.69/0.7833 |
| RNET (Ours) | 401 K | 20.4 G | 32.39/0.8976 | 28.68/0.7837 |
| Method | Parameters | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|
| d = 6 w = 32 | 139 K | 37.94/0.9607 | 33.44/0.9168 | 32.10/0.8994 | 31.72/0.9239 | 38.47/0.9767 |
| d = 6 w = 48 | 291 K | 38.04/0.9610 | 33.60/0.9184 | 32.18/0.9005 | 32.10/0.9270 | 38.78/0.9775 |
| d = 6 w = 56 | 387 K | 38.07/0.9611 | 33.63/0.9187 | 32.21/0.9008 | 32.20/0.9280 | 38.93/0.9777 |
| d = 8 w = 32 | 183 K | 37.92/0.9607 | 33.50/0.9172 | 32.13/0.8997 | 31.88/0.9251 | 38.65/0.9771 |
| d = 8 w = 48 | 385 K | 38.10/0.9612 | 33.69/0.9190 | 32.23/0.9009 | 32.31/0.9289 | 39.01/0.9778 |
| d = 8 w = 56 | 513 K | 38.11/0.9612 | 33.65/0.9187 | 32.23/0.9009 | 32.30/0.9293 | 38.99/0.9778 |
| d = 10 w = 32 | 228 K | 38.01/0.9609 | 33.51/0.9173 | 32.16/0.9001 | 32.03/0.9265 | 38.73/0.9773 |
| d = 10 w = 48 | 479 K | 38.10/0.9612 | 33.70/0.9188 | 32.24/0.9011 | 32.36/0.9295 | 39.00/0.9779 |
| d = 10 w = 56 | 638 K | 38.12/0.9613 | 33.74/0.9195 | 32.25/0.9014 | 32.47/0.9305 | 39.12/0.9779 |
| Ablation | Variant | Parameters | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| ET in P1 | 385 K | 38.10/0.9612 | 33.69/0.9190 | 32.23/0.9009 | 32.31/0.9289 | 39.01/0.9778 | |
| HFEB | ET in P2 | 380 K | 38.06/0.9612 | 33.66/0.9187 | 32.22/0.9008 | 32.29/0.9289 | 38.96/0.9778 |
| without ET | 135 K | 37.75/0.9601 | 33.22/0.9152 | 32.01/0.8983 | 31.39/0.9209 | 38.01/0.9756 | |
| ET | BSConv | 385 K | 38.10/0.9612 | 33.69/0.9190 | 32.23/0.9009 | 32.31/0.9289 | 39.01/0.9778 |
| DWConv | 384 K | 38.06/0.9601 | 33.63/0.9189 | 32.22/0.9003 | 32.23/0.9273 | 38.86/0.9766 |
| Activate Function | Parameters | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|
| GELU | 385 K | 38.08/0.9611 | 33.66/0.9184 | 32.21/0.9008 | 32.24/0.9287 | 38.94/0.9777 |
| ReLU | 385 K | 38.08/0.9612 | 33.69/0.9189 | 32.21/0.9008 | 32.23/0.9285 | 38.90/0.9777 |
| LeakyReLU | 385 K | 38.10/0.9612 | 33.69/0.9190 | 32.23/0.9009 | 32.31/0.9289 | 39.01/0.9778 |
| ESA | CCA | Parameters | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| ✗ | ✗ | 393 K | 32.29/0.8964 | 28.61/0.7823 | 27.59/0.7388 | 26.14/0.7863 | 30.47/0.9081 |
| ✗ | ✓ | 397 K | 32.31/0.8967 | 28.62/0.7823 | 27.60/0.7388 | 26.16/0.7863 | 30.58/0.9094 |
| ✓ | ✗ | 397 K | 32.32/0.8970 | 28.65/0.7829 | 27.61/0.7393 | 26.18/0.7873 | 30.64/0.9099 |
| ✓ | ✓ | 401 K | 32.39/0.8976 | 28.68/0.7837 | 27.65/0.7403 | 26.24/0.7894 | 30.67/0.9102 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, F.; Li, S.; Zhou, Z.; Shi, Y. A Residual Network with Efficient Transformer for Lightweight Image Super-Resolution. Electronics 2024, 13, 194. https://doi.org/10.3390/electronics13010194
Yan F, Li S, Zhou Z, Shi Y. A Residual Network with Efficient Transformer for Lightweight Image Super-Resolution. Electronics. 2024; 13(1):194. https://doi.org/10.3390/electronics13010194
Chicago/Turabian StyleYan, Fengqi, Shaokun Li, Zhiguo Zhou, and Yonggang Shi. 2024. "A Residual Network with Efficient Transformer for Lightweight Image Super-Resolution" Electronics 13, no. 1: 194. https://doi.org/10.3390/electronics13010194
APA StyleYan, F., Li, S., Zhou, Z., & Shi, Y. (2024). A Residual Network with Efficient Transformer for Lightweight Image Super-Resolution. Electronics, 13(1), 194. https://doi.org/10.3390/electronics13010194