


Aircraft Behavior Recognition on Trajectory Data with a Multimodal Approach



Abstract
:1. Introduction
- (1)
- Provide a sophisticated recognition model on two types of trajectory data.
- (2)
- Abstract multiscale sequence and image modality features in the proposed model.
- (3)
- Present a modality-increasing approach to longitude and latitude sequences.
2. Methods
2.1. Motivation
2.2. Notations
2.3. The Proposed Methodology
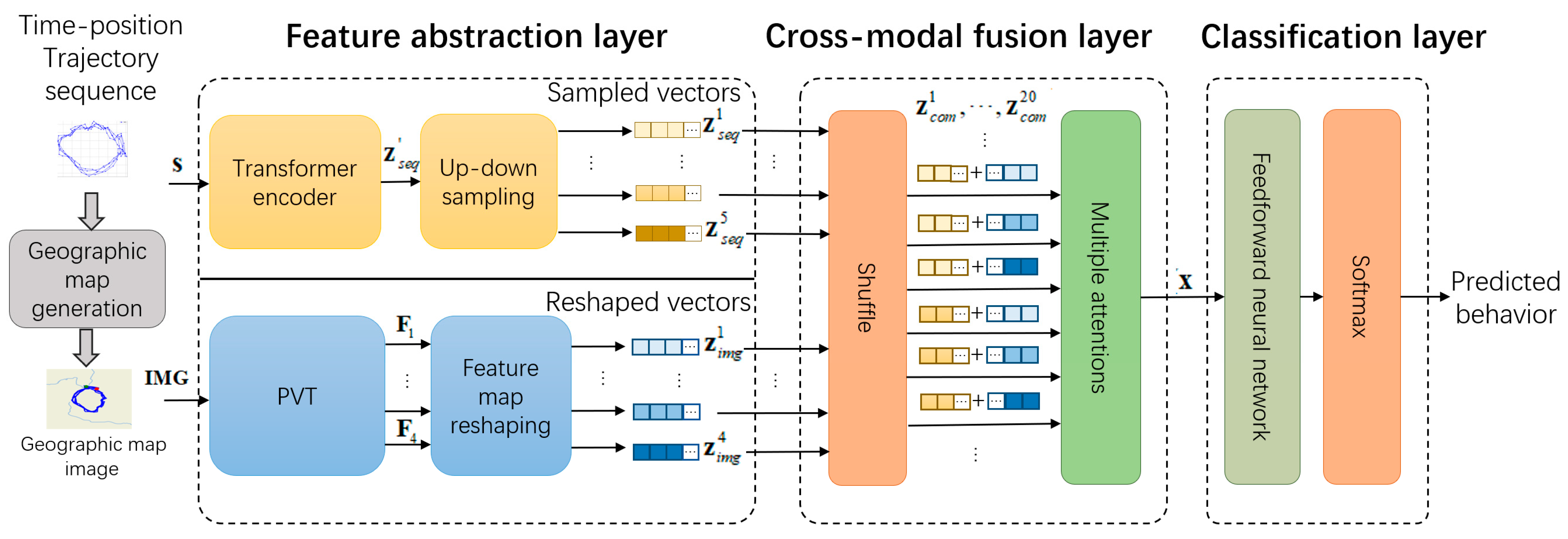
2.3.1. Framework
2.3.2. Geographic Map Generation
2.3.3. Feature Abstraction Layer
- Sequence processing
- Image processing
2.3.4. Cross-Modal Fusion Layer
2.3.5. Classification Layer
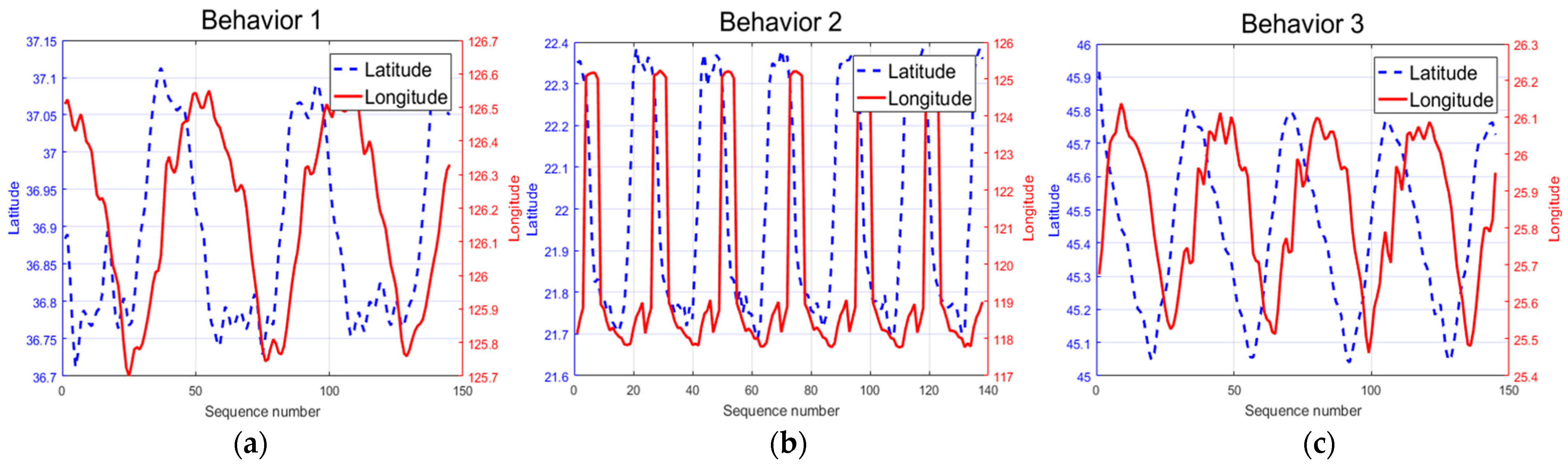
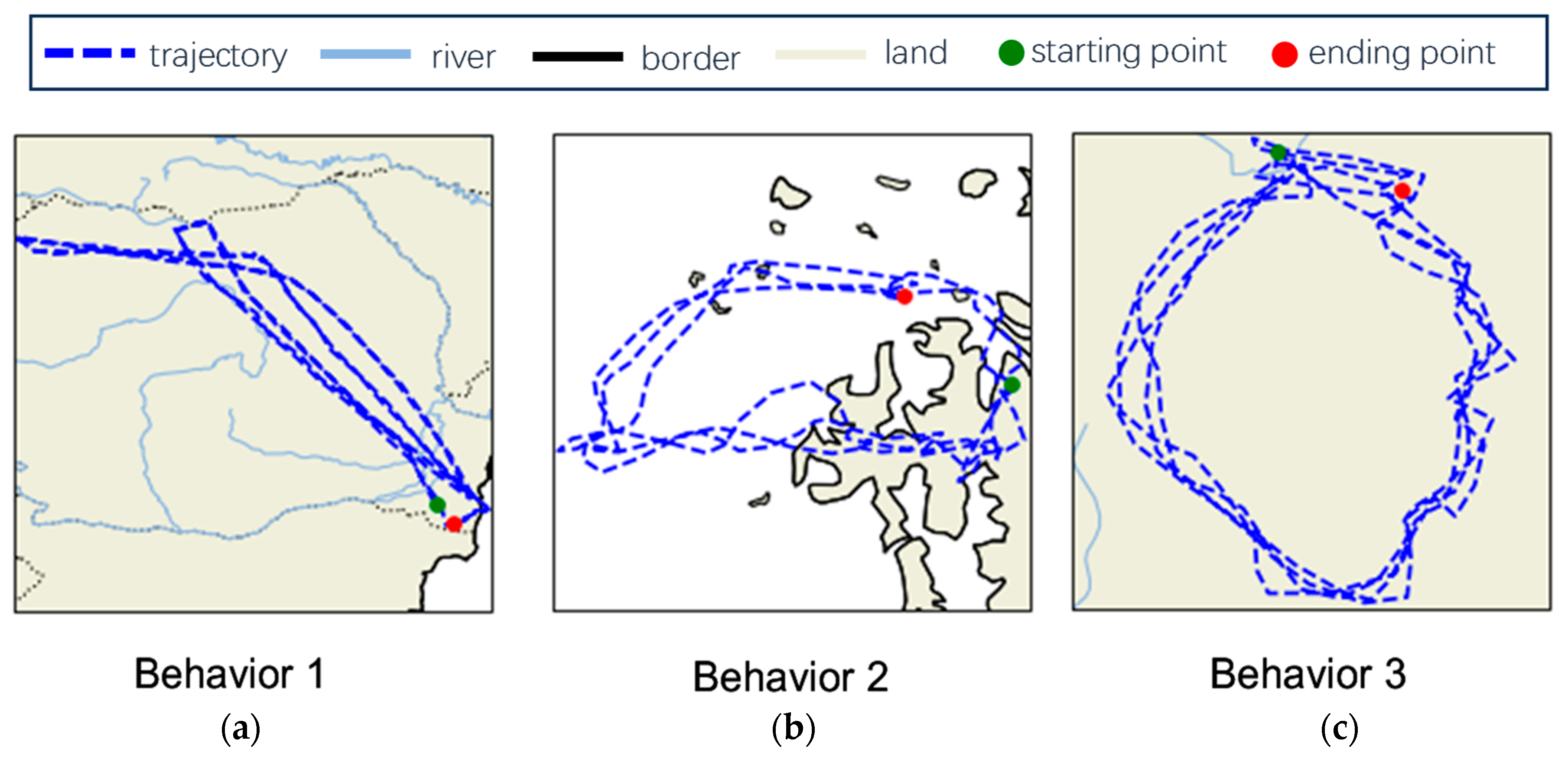
3. Dataset
- Behavior 1: Direct flighting between fixed positions;
- Behavior 2: Patrolling around a specific area;
- Behavior 3: Hovering before landing.
4. Results and Discussion
4.1. Settings
4.2. Behavior Recognition Accuracy
4.3. Ablation Test
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, W.; Zhang, Z.; Huang, K. Gestalt Laws-Based Tracklets Analysis for Human Crowd Understanding. Pattern Recogn. 2018, 75, 112–127. [Google Scholar] [CrossRef]
- Gurung, S.; Lin, D.; Jiang, W.; Hurson, A.; Zhang, R. Traffic Information Publication with Privacy Preservation. ACM Trans. Intell. Syst. Technol. 2014, 5, 1–26. [Google Scholar] [CrossRef]
- Bashir, F.I.; Khokhar, A.A.; Schonfeld, D. Object Trajectory-Based Activity Classification and Recognition Using Hidden Markov Models. IEEE Trans. Image Proc. 2007, 16, 1912–1919. [Google Scholar] [CrossRef] [PubMed]
- Freedman, M.; Mumford, K.G.; Danko, A.; Hart, D.; Richardson, S.D. Demonstration of a Principal Component Analysis Trajectory Method to Assess Bioremediation Progress at a TCE-Impacted Site. Groundw. Monit. Remediat. 2023, 43, 90–97. [Google Scholar] [CrossRef]
- Bautista, M.A.; Hernández-Vela, A.; Escalera, S.; Igual, L.; Pujol, O.; Moya, J.; Violant, V.; Anguera, M.T. A Gesture Recognition System for Detecting Behavioral Patterns of ADHD. IEEE Trans. Cybernet. 2016, 46, 136–147. [Google Scholar] [CrossRef] [PubMed]
- Bashir, F.I.; Khokhar, A.A.; Schonfeld, D. Real-Time Motion Trajectory-Based Indexing and Retrieval of Video Sequences. IEEE Trans. Multimed. 2007, 9, 58–65. [Google Scholar] [CrossRef]
- Piotto, N.; Conci, N.; De Natale, F.G.B. Syntactic Matching of Trajectories for Ambient Intelligence Applications. IEEE Trans. Multimed. 2009, 11, 1266–1275. [Google Scholar] [CrossRef]
- Wang, H.; Ullah, M.M.; Klaser, A.; Laptev, I.; Schmid, C. Evaluation of Local Spatio-Temporal Features for Action Recognition. In British Machine Vision Conference (BMVC’09); BMVA Press: London, UK, 2009; pp. 124.1–124.11. [Google Scholar]
- Faria, D.R.; Dias, J. 3D Hand Trajectory Segmentation by Curvatures and Hand Orientation for Classification through a Probabilistic Approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1284–1289. [Google Scholar]
- Lee, J.-G.; Han, J.; Whang, K.-Y. Trajectory Clustering: A Partition-and-Group Framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; ACM: New York, NY, USA, 2007; pp. 593–604. [Google Scholar]
- Krajňák, V.; Naik, S.; Wiggins, S. Predicting Trajectory Behaviour via Machine-Learned Invariant Manifolds. Chem. Phys. Lett. 2022, 789, 139290. [Google Scholar] [CrossRef]
- Ruan, Y.; Zou, Y.; Chen, M.; Shen, J. Monitoring the Spatiotemporal Trajectory of Urban Area Hotspots Using the SVM Regression Method Based on NPP-VIIRS Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 415. [Google Scholar] [CrossRef]
- Poularakis, S.; Katsavounidis, I. Low-Complexity Hand Gesture Recognition System for Continuous Streams of Digits and Letters. IEEE Trans. Cybernet. 2016, 46, 2094–2108. [Google Scholar] [CrossRef]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3D Human Action Recognition by Shape Analysis of Motion Trajectories on Riemannian Manifold. IEEE Trans. Cybernet. 2015, 45, 1340–1352. [Google Scholar] [CrossRef]
- Devanne, M.; Berretti, S.; Pala, P.; Wannous, H.; Daoudi, M.; Del Bimbo, A. Motion Segment Decomposition of RGB-D Sequences for Human Behavior Understanding. Pattern Recogn. 2017, 61, 222–233. [Google Scholar] [CrossRef]
- Yuan, Y.; Feng, Y.; Lu, X. Statistical Hypothesis Detector for Abnormal Event Detection in Crowded Scenes. IEEE Trans. Cybernet. 2017, 47, 3597–3608. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Li, X.; Tian, G.; Maybank, S.; Zhang, Z. An Incremental DPMM-Based Method for Trajectory Clustering, Modeling, and Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1051–1065. [Google Scholar] [PubMed]
- Wang, H.; O’Sullivan, C. Globally Continuous and Non-Markovian Crowd Activity Analysis from Videos. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 527–544. [Google Scholar]
- Zhong, C.; Jiang, Z.; Chu, X.; Liu, L. Inland Ship Trajectory Restoration by Recurrent Neural Network. J. Nav. 2019, 72, 1359–1377. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J.; Pi, L.; Song, X.; Yang, L. LSTM Based Trajectory Prediction Model for Cyclist Utilizing Multiple Interactions with Environment. Pattern Recogn. 2021, 112, 107800. [Google Scholar] [CrossRef]
- Peng, Y.; Zhang, G.; Shi, J.; Xu, B.; Zheng, L. SRA-LSTM: Social Relationship Attention LSTM for Human Trajectory Prediction. Neurocomputing 2021, 490, 258–268. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Eca-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11531–11539. [Google Scholar]
- Chen, K.; Liu, P.; Li, Z.; Wang, Y.; Lu, Y. Modeling Anticipation and Relaxation of Lane Changing Behavior Using Deep Learning. Transport. Res. Rec. 2021, 2675, 186–200. [Google Scholar] [CrossRef]
- Gan, C.; Wang, N.; Yang, Y.; Yeung, D.-Y.; Hauptmann, A.G. Devnet: A Deep Event Network for Multimedia Event Detection and Evidence Recounting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2568–2577. [Google Scholar]
- Jiang, Y.-G.; Wu, Z.; Wang, J.; Xue, X.; Chang, S.-F. Exploiting Feature and Class Relationships in Video Categorization with Regularized Deep Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 352–364. [Google Scholar] [CrossRef]
- Li, H.; Sun, J.; Xu, Z.; Chen, L. Multimodal 2D+ 3D facial expression recognition with deep fusion convolutional neural network. IEEE Trans. Multimed. 2017, 19, 2816–2831. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, L.; Liu, Q.; Yin, Y.; Cheng, L.; Zimmermann, R. Fusion of magnetic and visual sensors for indoor localization: Infrastructure-free and more effective. IEEE Trans. Multimed. 2017, 19, 874–888. [Google Scholar] [CrossRef]
- Qiao, Z.; Wu, X.; Ge, S.; Fan, W. MNN: Multimodal attentional neural networks for diagnosis prediction. In Proceedings of the 28th International Joint Conference Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5937–5943. [Google Scholar]
- Guillaumin, M.; Verbeek, J.; Schmid, C. Multimodal semisupervised learning for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 902–909. [Google Scholar]
- JGeng, J.; Miao, Z.; Zhang, X.-P. Efficient heuristic methods for multimodal fusion and concept fusion in video concept detection. IEEE Trans. Multimed. 2015, 17, 498–511. [Google Scholar]
- Xu, L.; Wu, X.; Chen, K.; Yao, L. Multi-modality sparse representation-based classification for Alzheimer’s disease and mild cognitive impairment. Comput. Methods Programs Biomed. 2015, 122, 182–190. [Google Scholar] [CrossRef] [PubMed]
- Bernal, E.A.; Yang, X.; Li, Q.; Kumar, J.; Madhvanath, S.; Ramesh, P.; Bala, R. Deep temporal multimodal fusion for medical procedure monitoring using wearable sensors. IEEE Trans. Multimed. 2018, 20, 107–118. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Zhang, W.; Chen, J.; Liu, C. Multimodal classification with deep convolutional-recurrent neural networks for electroencephalography. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 767–776. [Google Scholar]
- Ma, F.; You, Q.; Xiao, H.; Chitta, R.; Zhou, J.; Gao, J. KAME: Knowledge-based attention model for diagnosis prediction in healthcare. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 743–752. [Google Scholar]
- Xu, Y.; Biswal, S.; Deshpande, S.R.; Maher, K.O.; Sun, J. RAIM: Recurrent attentive and intensive model of multimodal patient monitoring data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2565–2573. [Google Scholar]
- Kalimeri, K.; Saitis, C. Exploring multimodal biosignal features for stress detection during indoor mobility. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 53–60. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Gao, M.; Shi, G.Y. Ship-handling behavior pattern recognition using AIS sub-trajectory clustering analysis based on the T-SNE and spectral clustering algorithms. Ocean. Eng. 2020, 205, 117–132. [Google Scholar] [CrossRef]
- Chan, Z.; Collins, L.; Kasabov, N. An Efficient Greedy CGRU Algorithm for Global Gene Trajectory Clustering. Expert Syst. Appl. 2006, 30, 137–141. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Category Label | Number of Samples | Length | Modality |
|---|---|---|---|
| Behavior 1 | 720 | 512 | Sequence |
| Behavior 2 | 720 | 512 | Sequence |
| Behavior 3 | 1440 | 512 | Sequence |
| Total number | 2880 | ||
| Method | Modality | Trial | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| Spectral clustering (SP) [39] | Sequence | 83.6 | 84.3 | 82.1 | 79.9 | 75.2 | 85 | 78.9 | 77.3 | 79.9 | 86.9 | 82.3 ± 5.1 |
| Transformer [37] | Sequence | 80.1 | 71.3 | 56.2 | 60.5 | 64.8 | 65.5 | 76.6 | 64.8 | 64.8 | 80.1 | 67.2 ± 7.2 |
| Clustering-GRU (CGRU) [40] | Sequence | 87.9 | 81.4 | 89.9 | 85.2 | 87.5 | 85.8 | 89 | 80.3 | 85.1 | 80.1 | 87.2 ± 4.4 |
| Vision transformer (ViT) [41] | Image | 87.6 | 91.2 | 84.6 | 80.6 | 80.7 | 86.2 | 78.4 | 90.3 | 83.5 | 87.6 | 84.8 ± 4.2 |
| MMTS(Ours) | Sequence and image | 98.1 | 99.4 | 90.6 | 97.6 | 96.8 | 87.6 | 98.1 | 91.6 | 96.5 | 98.1 | 95.1 ± 3.9 |
| Method | Average Accuracy | Accuracy Variation |
|---|---|---|
| Full MSM Submodel 1 (without image features) | 95.1 80.8 | / |
| −14.3 | ||
| Submodel 2 (without sequence features) | 87.5 | −7.6 |
| Submodel 3 (without multiscale sequence feature extraction) | 85.7 | −9.4 |
| Submodel 4 (without cross-modal fusion) | 83.2 | −11.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Zhang, L.; Liu, T. Aircraft Behavior Recognition on Trajectory Data with a Multimodal Approach. Electronics 2024, 13, 367. https://doi.org/10.3390/electronics13020367
Zhang M, Zhang L, Liu T. Aircraft Behavior Recognition on Trajectory Data with a Multimodal Approach. Electronics. 2024; 13(2):367. https://doi.org/10.3390/electronics13020367
Chicago/Turabian StyleZhang, Meng, Lingxi Zhang, and Tao Liu. 2024. "Aircraft Behavior Recognition on Trajectory Data with a Multimodal Approach" Electronics 13, no. 2: 367. https://doi.org/10.3390/electronics13020367
APA StyleZhang, M., Zhang, L., & Liu, T. (2024). Aircraft Behavior Recognition on Trajectory Data with a Multimodal Approach. Electronics, 13(2), 367. https://doi.org/10.3390/electronics13020367