
A Lightweight Context-Aware Feature Transformer Network for Human Pose Estimation

Abstract
:1. Introduction
2. Related Work
2.1. Human Pose Estimation
2.2. Attention-Enhanced Convolution
2.3. HRNet
3. Methods
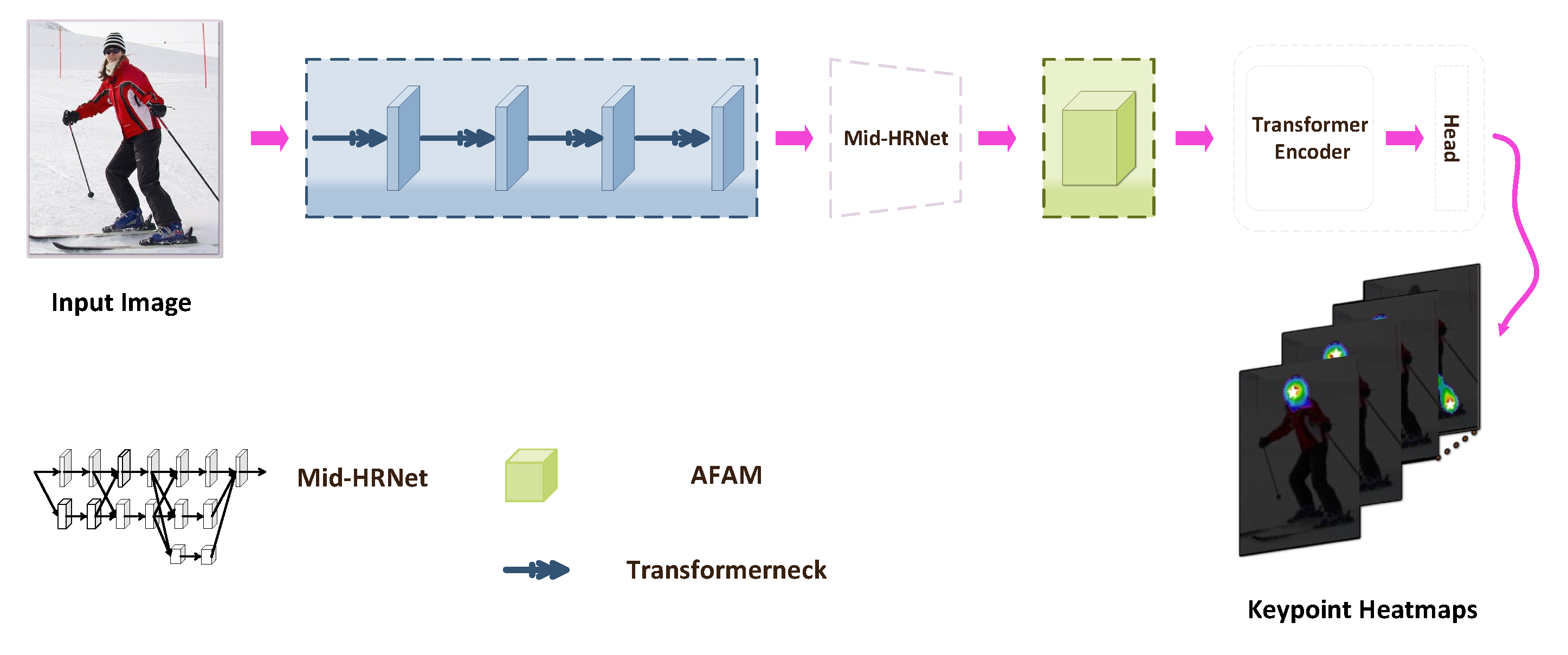
3.1. Context-Aware Feature Transformer Network (CaFTNet)
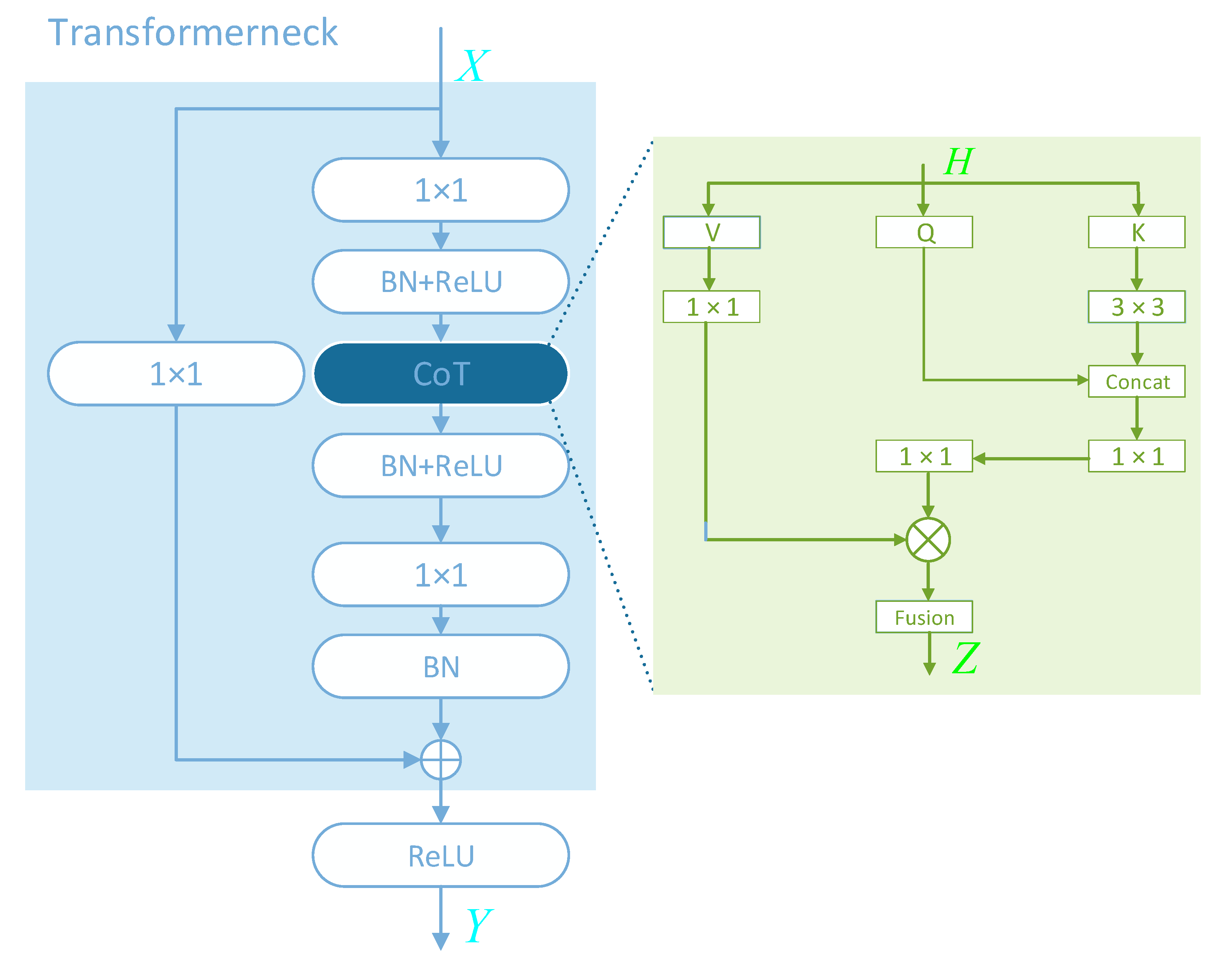
3.2. Transformerneck
| Algorithm 1: Transformerneck |
| Input: feature map |
| Output: feature map |
| 1: X <- an intermediate feature map |
| 2: X <- K |
| 3: X <- Q |
| 4: X <- V |
| 5: K1 <- use Equation (1) |
| 6: M <- use Equation (2) |
| 7: V1 <- use Equation (3) |
| 8: K2 <- use Equation (4) |
| 9: Y <- K1 + K2 |
| 10: return Y |
3.3. Attention Feature Aggregation Module (AFAM)
- (1)
- obtains the spatial context feature through a convolution and a sigmoid layer in the last row. is represented as:
- (2)
- rearranges the spatially related context features together, respectively, through two convolutions and a non-linear activation layer to obtain and . and are represented as:
- (3)
- and are multiplied element-wise to obtain an attention map with contextual relationships, which is subsequently applied to the features to recalibrate the output features . is represented as:
| Algorithm 2: AFAM |
| Input: feature map |
| Output: feature map |
| 1: F <- an intermediate feature map |
| 2: Mc <- use Equation (5) |
| 3: Fc <- use Equation (6) |
| 4: Ms <- use Equation (7) |
| 5: Fs <- use Equation (8) |
| 6: Fv <- use Equation (9) |
| 7: Fq <- use Equation (10) |
| 8: Fk <- use Equation (11) |
| 9: F1 <- use Equation (12) |
| 10: F′ <- F1 + F |
| 11: return F′ |
4. Experiments
4.1. Model Variants
4.2. Technical Details
4.3. Results on the COCO Dataset
4.3.1. Dataset and Evaluation Metrics
4.3.2. Quantitative Results
4.3.3. Qualitative Comparisons
4.4. Results on the MPII Dataset
4.4.1. Dataset and Evaluation Metrics
4.4.2. Quantitative Results
4.4.3. Qualitative Comparisons
4.5. Ablation Experiments
4.5.1. Transformerneck
4.5.2. Attention Feature Aggregation Module (AFAM)
4.5.3. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Yang, C.; Xu, Y.; Shi, J.; Dai, B.; Zhou, B. Temporal pyramid network for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 591–600. [Google Scholar]
- Rahnama, A.; Esfahani, A.; Mansouri, A. Adaptive Frame Selection In Two Dimensional Convolutional Neural Network Action Recognition. In Proceedings of the 2022 8th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Mazandaran, Iran, 28–29 December 2022; IEEE: New York, NY, USA, 2022; pp. 1–4. [Google Scholar]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3200–3225. [Google Scholar] [CrossRef] [PubMed]
- Snower, M.; Kadav, A.; Lai, F.; Graf, H.P. 15 keypoints is all you need. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6738–6748. [Google Scholar]
- Ning, G.; Pei, J.; Huang, H. Lighttrack: A generic framework for online top-down human pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1034–1035. [Google Scholar]
- Wang, M.; Tighe, J.; Modolo, D. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11088–11096. [Google Scholar]
- Rafi, U.; Doering, A.; Leibe, B.; Gall, J. Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XX 16. Springer: New York, NY, USA, 2020; pp. 36–52. [Google Scholar]
- Kwon, O.H.; Tanke, J.; Gall, J. Recursive bayesian filtering for multiple human pose tracking from multiple cameras. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Kocabas, M.; Athanasiou, N.; Black, M.J. Vibe: Video inference for human body pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5253–5263. [Google Scholar]
- Chen, H.; Guo, P.; Li, P.; Lee, G.H.; Chirikjian, G. Multi-person 3d pose estimation in crowded scenes based on multi-view geometry. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: New York, NY, USA, 2020; pp. 541–557. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Black, M.J.; Daniilidis, K. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2252–2261. [Google Scholar]
- Qiu, H.; Wang, C.; Wang, J.; Wang, N.; Zeng, W. Cross view fusion for 3d human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4342–4351. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning delicate local representations for multi-person pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: New York, NY, USA, 2020; pp. 455–472. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Jiang, W.; Jin, S.; Liu, W.; Qian, C.; Luo, P.; Liu, S. PoseTrans: A Simple Yet Effective Pose Transformation Augmentation for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V. Springer: New York, NY, USA, 2022; pp. 643–659. [Google Scholar]
- Tang, W.; Yu, P.; Wu, Y. Deeply learned compositional models for human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 190–206. [Google Scholar]
- Ren, F. Distilling Token-Pruned Pose Transformer for 2D Human Pose Estimation. arXiv 2023, arXiv:2304.05548. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Raaj, Y.; Idrees, H.; Hidalgo, G.; Sheikh, Y. Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4620–4628. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. Multi-task deep learning for real-time 3D human pose estimation and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2752–2764. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Vaswani, A. Bottleneck Transformers for Visual Recognition. arXiv 2021, arXiv:2101.11605. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. arXiv 2021, arXiv:2107.12292. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Wang, D.; Xie, W.; Cai, Y.; Li, X.; Liu, X. Transformer-based rapid human pose estimation network. Comput. Graph. 2023, 116, 317–326. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1913–1921. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1840. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, H.; Jiang, X.Y. Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation. Sensors 2022, 22, 7264. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Wang, H.; Yue, S.; Zhang, Z. Context-aware co-supervision for accurate object detection. Pattern Recognit. 2022, 121, 108199. [Google Scholar] [CrossRef]
- Zhang, J.Q.Z.; Jiang, X. Spatial Context-Aware Object-Attentional Network for Multi-Label Image Classification. IEEE Trans. Image Process. 2023, 32, 3000–3012. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: New York, NY, USA, 2014; pp. 740–755. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Samkari, E.M.; Alghamdi, M. Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Mach. Learn. Knowl. Extr. 2023, 5, 1612–1659. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5700–5709. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on multi-stage networks for human pose estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11802–11812. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11313–11322. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral human pose regression. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Layers | Heads | Flops | Params |
|---|---|---|---|---|---|
| CaFTNet-R | ResNet | 4 | 8 | 5.29 G | 5.55 M |
| CaFTNet-H3 | HRNet-W32 | 4 | 1 | 8.46 G | 17.03 M |
| CaFTNet-H4 | HRNet-W48 | 4 | 1 | 8.73 G | 17.30 M |
| Model | Backbone | AP | AR | Flops | Params |
|---|---|---|---|---|---|
| CaFTNet-R | ResNet | 73.7 | 79.0 | 5.29 G | 5.55 M |
| CaFTNet-H3 | HRNet-W32 | 75.6 | 80.9 | 8.46 G | 17.03 M |
| CaFTNet-H4 | HRNet-W48 | 76.2 | 81.2 | 8.73 G | 17.30 M |
| Model | Input Size | AP | AR | Flops | Params |
|---|---|---|---|---|---|
| ResNet-50 [33] | 256 × 192 | 70.4 | 76.3 | 8.9 G | 34.0 M |
| ResNet-101 [33] | 256 × 192 | 71.4 | 76.3 | 12.4 G | 53.0 M |
| ResNet-152 [33] | 256 × 192 | 72 | 77.8 | 35.3 G | 68.6 M |
| TransPose-R-A3 [59] | 256 × 192 | 71.7 | 77.1 | 8.0 G | 5.2 M |
| TransPose-R-A4 [59] | 256 × 192 | 72.6 | 78.0 | 8.9 G | 6.0 M |
| CaFTNet-R | 256 × 192 | 73.7 | 79.0 | 5.29 G | 5.55 M |
| HRNet-W32 [14] | 256 × 192 | 74.7 | 79.8 | 7.2 G | 28.5 M |
| HRNet-W48 [14] | 256 × 192 | 75.1 | 80.4 | 14.6 G | 63.6 M |
| TransPose-H-A4 [59] | 256 × 192 | 75.3 | 80.3 | 17.5 G | 17.3 M |
| TransPose-H-A6 [59] | 256 × 192 | 75.8 | 80.8 | 21.8 G | 17.5 M |
| TokenPose-L/D6 [60] | 256 × 192 | 75.4 | 80.4 | 9.1 G | 20.8 M |
| TokenPose-L/D24 [60] | 256 × 192 | 75.8 | 80.9 | 11.0 G | 27.5 M |
| CaFTNet-H3 | 256 × 192 | 75.6 | 80.9 | 8.46 G | 17.03 M |
| CaFTNet-H4 | 256 × 192 | 76.2 | 81.2 | 8.73 G | 17.30 M |
| Model | Input Size | AP | Params | ||||
|---|---|---|---|---|---|---|---|
| G-RMI [18] | 357 × 257 | 64.9 | 85.5 | 71.3 | 62.3 | 70.0 | 42.6 M |
| Integral [61] | 256 × 256 | 67.8 | 88.2 | 74.8 | 63.9 | 74.0 | 45.0 M |
| CPN [52] | 384 × 288 | 72.1 | 91.4 | 80.0 | 68.7 | 77.2 | 58.8 M |
| RMPE [16] | 320 × 256 | 72.3 | 89.2 | 79.1 | 68.0 | 78.6 | 28.1 M |
| SimpleBaseline [24] | 384 × 288 | 73.7 | 91.9 | 81.8 | 70.3 | 80.0 | 68.6 M |
| HRNet-W32 [14] | 384 × 288 | 74.9 | 92.5 | 82.8 | 71.3 | 80.9 | 28.5 M |
| HRNet-W48 [14] | 256 × 192 | 74.2 | 92.4 | 82.4 | 70.9 | 79.7 | 63.6 M |
| TransPose-H-A4 [59] | 256 × 192 | 74.7 | 91.6 | 82.2 | 71.4 | 80.7 | 17.3 M |
| TransPose-H-A6 [59] | 256 × 192 | 75.0 | 92.2 | 82.3 | 71.3 | 81.1 | 17.5 M |
| TokenPose-L/D6 [60] | 256 × 192 | 74.9 | 90.0 | 81.8 | 71.8 | 82.4 | 20.8 M |
| TokenPose-L/D24 [60] | 256 × 192 | 75.1 | 90.3 | 82.5 | 72.3 | 82.7 | 27.5 M |
| CaFTNet-H3 | 256 × 192 | 75.0 | 90.0 | 82.0 | 71.5 | 82.5 | 17.03 M |
| CaFTNet-H4 | 256 × 192 | 75.5 | 90.4 | 82.8 | 72.5 | 83.3 | 17.30 M |
| Model | Hea | Sho | Elb | Wri | Hip | Kne | Ank | Mean | Params |
|---|---|---|---|---|---|---|---|---|---|
| SimpleBaseline-Res50 [24] | 96.4 | 95.3 | 89.0 | 83.2 | 88.4 | 84.0 | 79.6 | 88.5 | 34.0 M |
| SimpleBaseline-Res101 [24] | 96.9 | 95.9 | 89.5 | 84.4 | 88.4 | 84.5 | 80.7 | 89.1 | 53.0 M |
| SimpleBaseline-Res152 [24] | 97.0 | 95.9 | 90.0 | 85.0 | 89.2 | 85.3 | 81.3 | 89.6 | 68.6 M |
| HRNet-W32 [14] | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 | 28.5 M |
| TokenPose-L/D24 [60] | 97.1 | 95.9 | 90.4 | 86.0 | 89.3 | 87.1 | 82.5 | 90.2 | 28.1 M |
| CaFTNet-H4 | 97.2 | 96.1 | 90.5 | 86.5 | 89.3 | 86.9 | 82.8 | 90.4 | 17.3 M |
| Model | Bottleneck | Transformerneck | AP |
|---|---|---|---|
| CaFTNet-R | ✓ | 72.6 | |
| CaFTNet-R | ✓ | 73.2 | |
| CaFTNet-H | ✓ | 75.3 | |
| CaFTNet-H | ✓ | 75.7 |
| Model | Baseline | SE | ECA | CBAM | AFAM | AP |
|---|---|---|---|---|---|---|
| CaFTNet-R | ✓ | 72.6 | ||||
| CaFTNet-R | ✓ | ✓ | 72.7 | |||
| CaFTNet-R | ✓ | ✓ | 72.8 | |||
| CaFTNet-R | ✓ | ✓ | 73.0 | |||
| CaFTNet-R | ✓ | ✓ | 73.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Shi, Q.; Zhang, F. A Lightweight Context-Aware Feature Transformer Network for Human Pose Estimation. Electronics 2024, 13, 716. https://doi.org/10.3390/electronics13040716
Ma Y, Shi Q, Zhang F. A Lightweight Context-Aware Feature Transformer Network for Human Pose Estimation. Electronics. 2024; 13(4):716. https://doi.org/10.3390/electronics13040716
Chicago/Turabian StyleMa, Yanli, Qingxuan Shi, and Fan Zhang. 2024. "A Lightweight Context-Aware Feature Transformer Network for Human Pose Estimation" Electronics 13, no. 4: 716. https://doi.org/10.3390/electronics13040716
APA StyleMa, Y., Shi, Q., & Zhang, F. (2024). A Lightweight Context-Aware Feature Transformer Network for Human Pose Estimation. Electronics, 13(4), 716. https://doi.org/10.3390/electronics13040716