
Cooperative Coverage Path Planning for Multi-Mobile Robots Based on Improved K-Means Clustering and Deep Reinforcement Learning



Abstract
:1. Introduction
- 1.
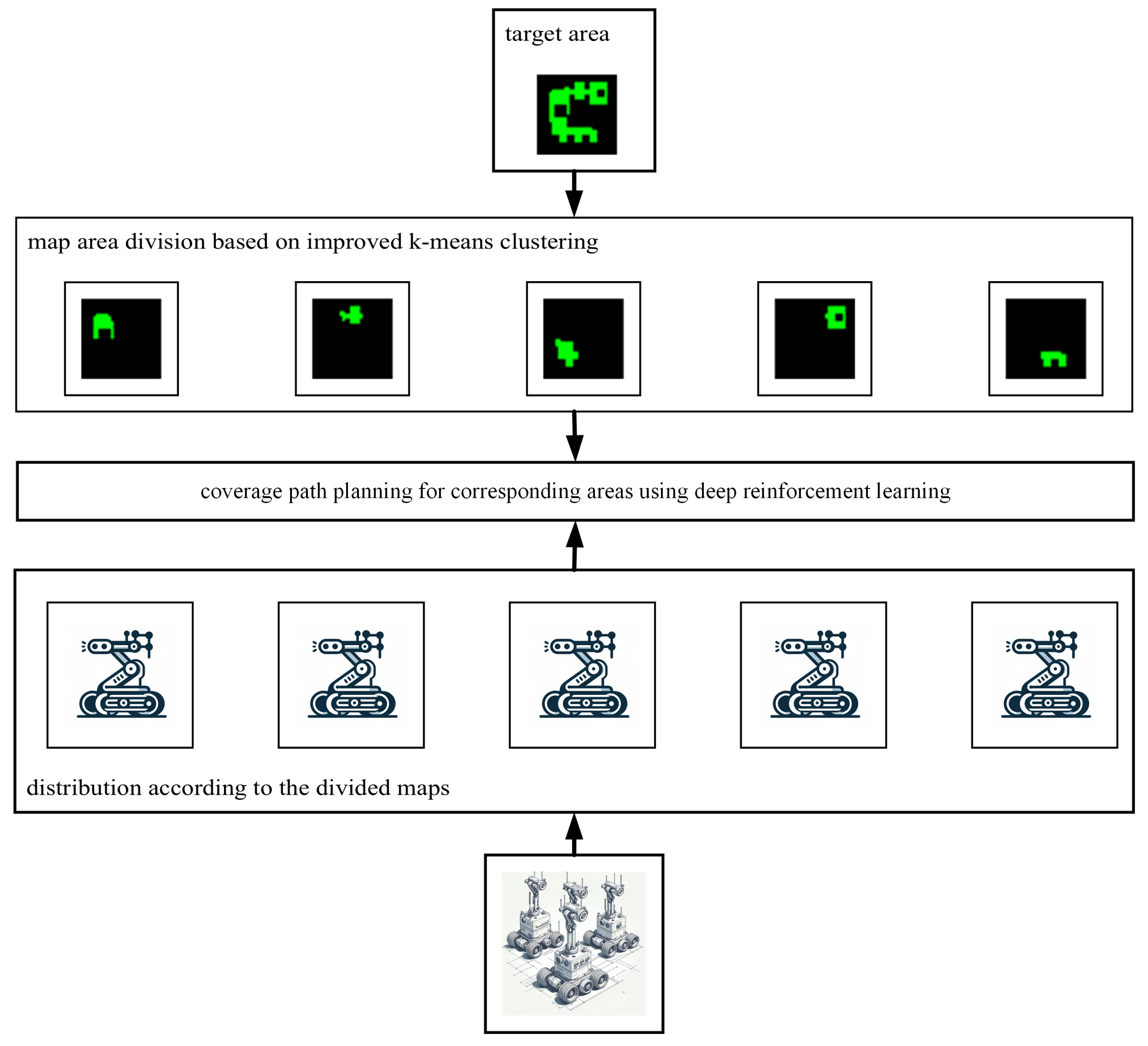
- Using the improved K-Means clustering method, the location of the initial value of k is arranged more reasonably, and a better map division effect is obtained, thus making the tasks of each robot more balanced;
- 2.
- The dueling network is introduced and the reward function of deep reinforcement learning is improved, which improves the strategy quality and learning efficiency;
- 3.
- Using the cooperation of multi-robots, the overall coverage ratio is effectively improved, and the repeated coverage and coverage paths are reduced.
2. Problem Description
2.1. Environment and Multi-Mobile Robot Model
2.2. Task Objective
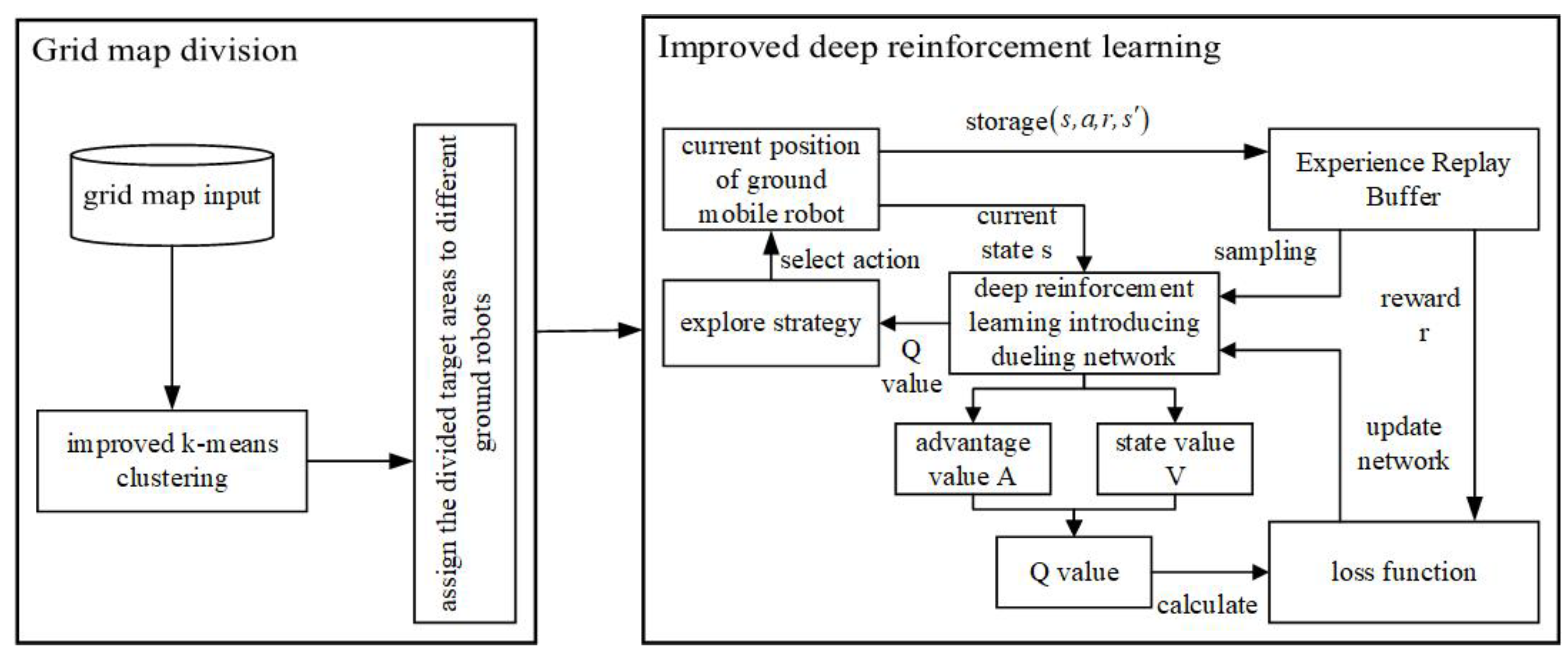
3. Proposed Method
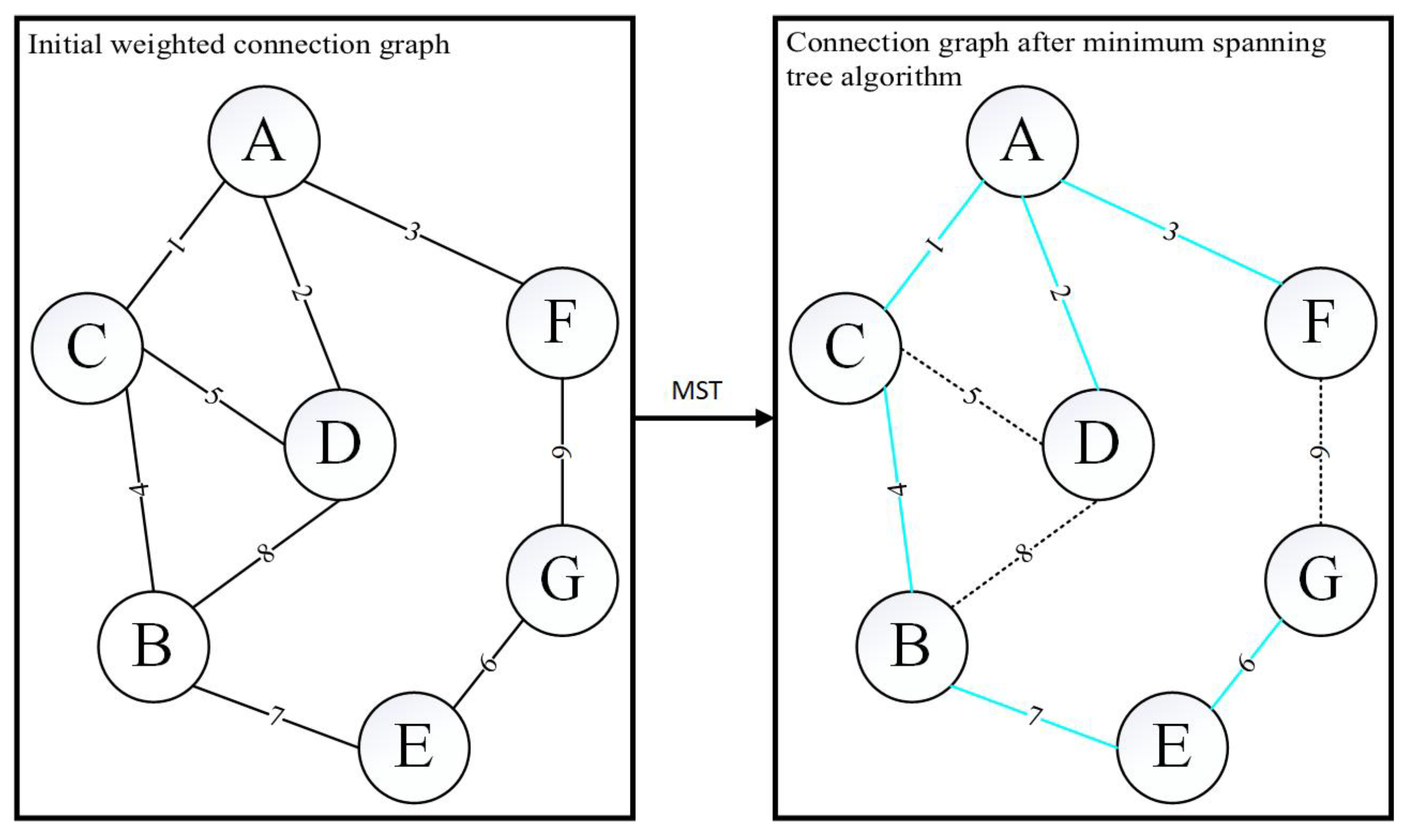
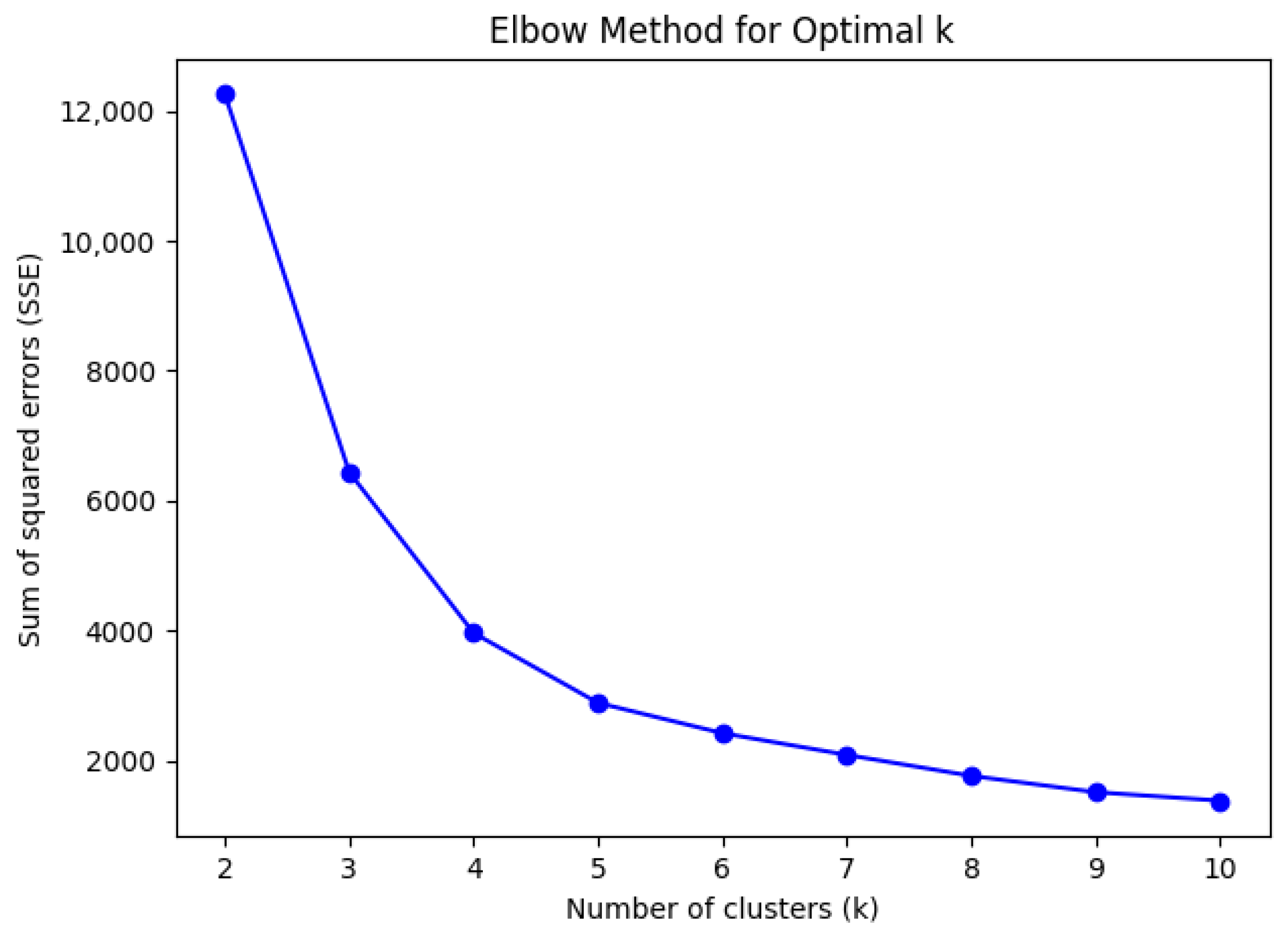
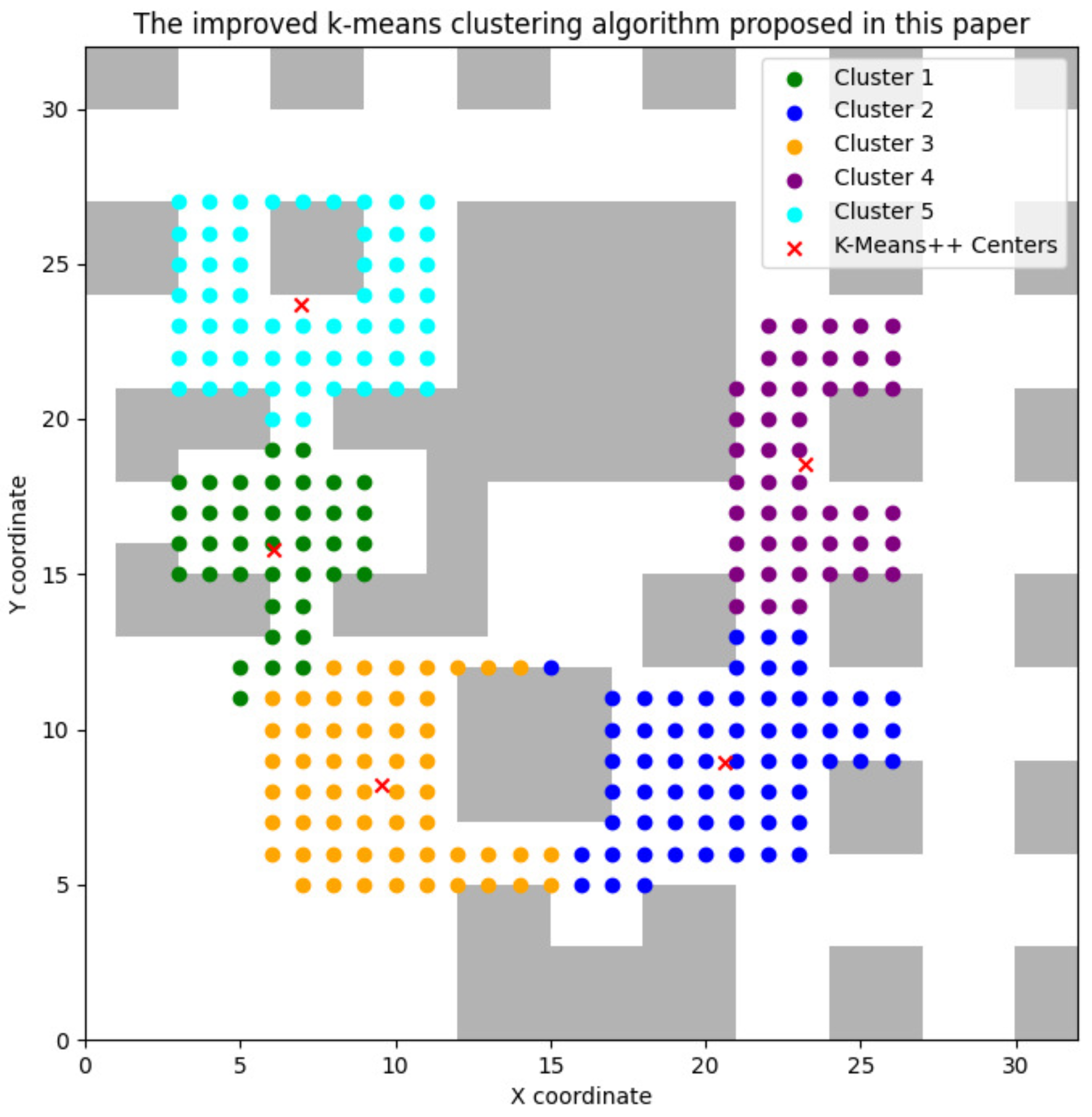
3.1. Improved K-Means Clustering Algorithm
| Algorithm 1 Improved K-Means clustering algorithm |
| Require: Input the data set X to be clustered Ensure: Output Cluster center k and data points in each cluster
|
3.2. Environment Settings
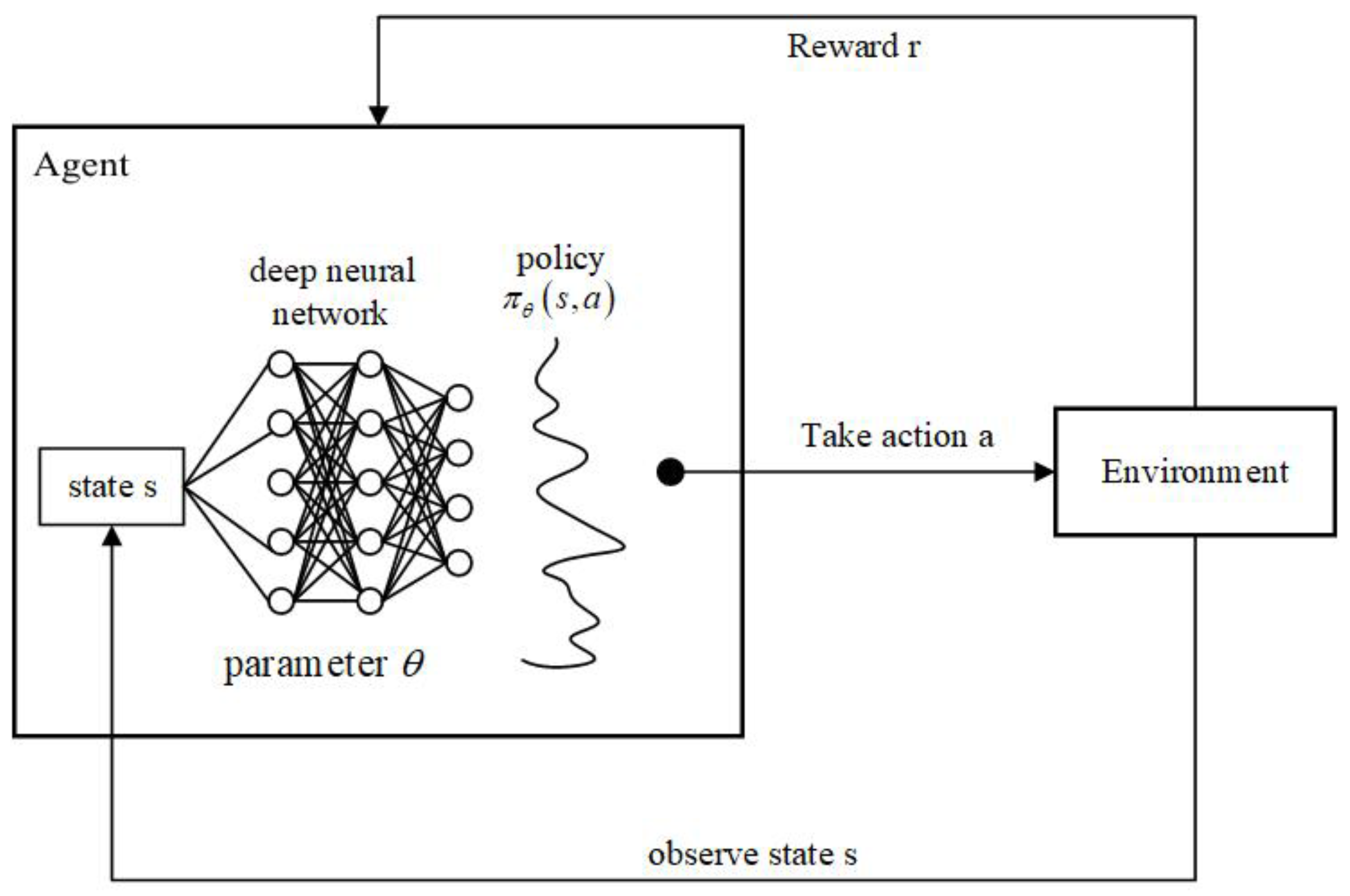
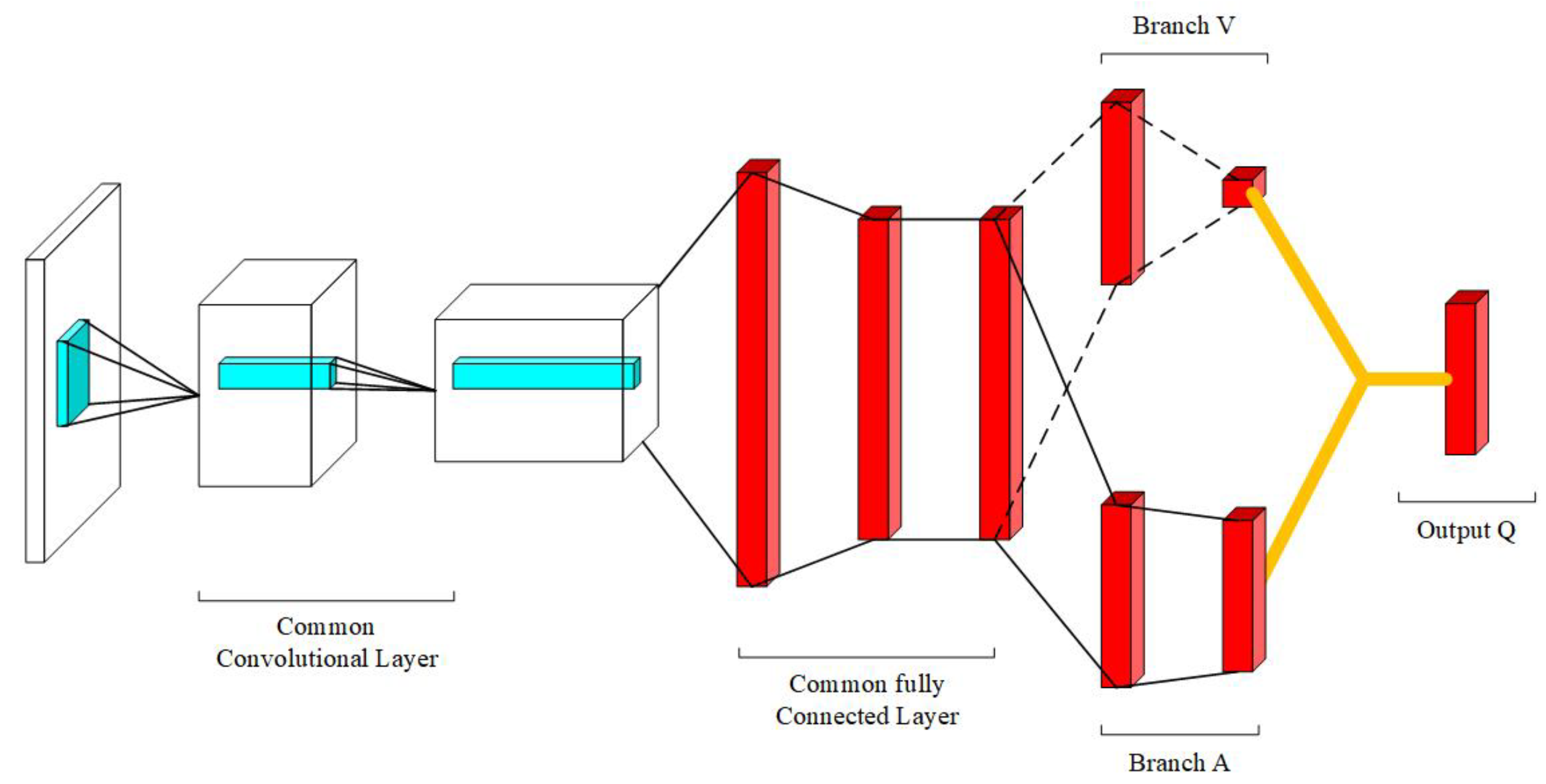
3.3. Deep Reinforcement Learning Using Dueling Network Structure
| Algorithm 2 The overall process of the algorithm |
| Require: Input the grid map to be covered, set of target coverage points X Ensure: Output the parameters , of the model
|
4. Experiment and Discussion
4.1. Simulation Settings
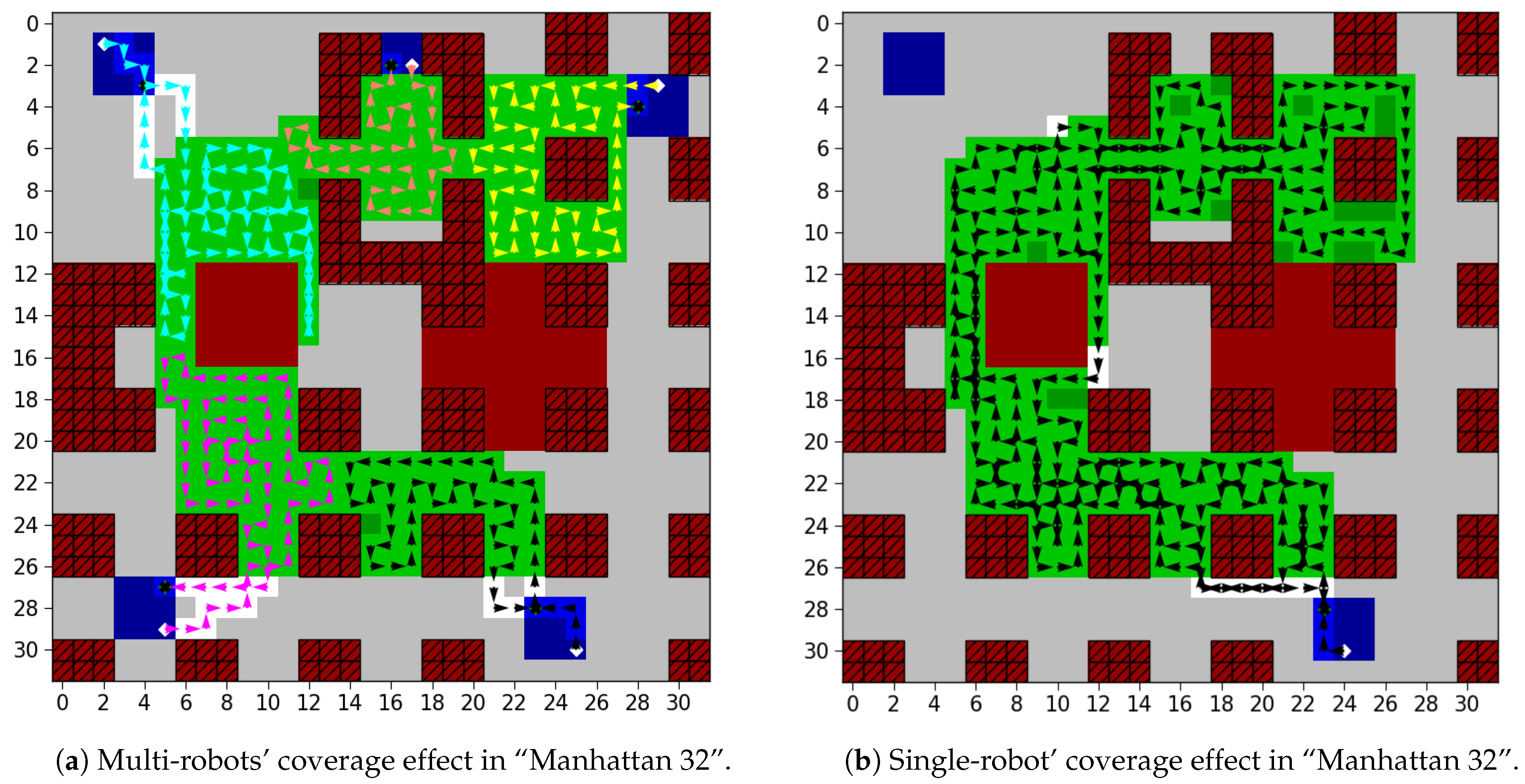
4.2. Experimental Results
- 1.
- The minimum spanning tree algorithm is introduced, and the improved K-Means clustering is used for map division in this paper, which makes the map division effect better, helps reduce the complexity of the environment, and improves the coverage effect;
- 2.
- The introduction of reward can prevent the mobile robot from entering a position that has been covered and has no uncovered area around it. At the same time, there will be guidance to guide the mobile robot to take action towards the uncovered area;
- 3.
- The dueling network is introduced to separate the state value function and the action advantage value function, which helps the mobile robot pay attention to the obstacles ahead and take actions to avoid them;
- 4.
- Using multiple mobile robots to complete the coverage task will help reduce the task complexity of each mobile robot and better complete the coverage task.
4.3. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CPP | Coverage path Planning |
| DRL | Deep Reinforcement Learning |
| DQN | Deep Q-Network |
| DL | Deep Learning |
| RL | Reinforcement Learning |
| POMDP | Partially Observable Markov Decision Processes |
| DDQN | Double Deep Q-Network |
| CR | Coverage Ratio |
| RR | Repetition Ratio |
| CRAR | Coverage Ratio and Reached |
| SSE | Sum of Squared Errors |
References
- Fevgas, G.; Lagkas, T.; Argyriou, V.; Sarigiannidis, P. Coverage Path Planning Methods Focusing on Energy Efficient and Cooperative Strategies for Unmanned Aerial Vehicles. Sensors 2022, 22, 1235. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, C.; Lu, X.; Huang, S. Research on Complete Coverage Path Planning for Unmanned Surface Vessel. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Ordos, China, 27–28 April 2019; Volume 300, p. 022037. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, D. Research on complete coverage path planning for multi-mobile robots. In Proceedings of the 2022 China Automation Congress, Xiamen, China, 25–27 November 2022; Volume 6, pp. 291–296. [Google Scholar]
- Hoeffmann, M.; Patel, S.; Bueskens, C. Optimal Coverage Path Planning for Agricultural Vehicles with Curvature Constraints. Agriculture 2023, 13, 2112. [Google Scholar] [CrossRef]
- Yakoubi, M.A.; Laskri, M.T. The path planning of cleaner robot for coverage region using Genetic Algorithms. J. Innov. Digit. Ecosyst. 2016, 3, 37–43. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, Y.; Cheng, Y. SMURF: A Fully Autonomous Water Surface Cleaning Robot with A Novel Coverage Path Planning Method. J. Mar. Sci. Eng. 2022, 10, 1620. [Google Scholar] [CrossRef]
- Ai, B.; Jia, M.; Xu, H.; Xu, J.; Wen, Z.; Li, B.; Zhang, D. Coverage path planning for maritime search and rescue using reinforcement learning. Ocean. Eng. 2021, 241, 110098. [Google Scholar] [CrossRef]
- Peng, C.; Isler, V. Visual Coverage Path Planning for Urban Environments. IEEE Robot. Autom. Lett. 2020, 5, 5961–5968. [Google Scholar] [CrossRef]
- Xu, P.F.; Ding, Y.X.; Luo, J.C. Complete Coverage Path Planning of an Unmanned Surface Vehicle Based on a Complete Coverage Neural Network Algorithm. J. Mar. Sci. Eng. 2021, 9, 1163. [Google Scholar] [CrossRef]
- Huang, K.C.; Lian, F.L.; Chen, C.T.; Wu, C.H.; Chen, C.C. A novel solution with rapid Voronoi-based coverage path planning in irregular environment for robotic mowing systems. Int. J. Intell. Robot. Appl. 2021, 5, 558–575. [Google Scholar] [CrossRef]
- Shen, Z.; Agrawal, P.; Wilson, J.P.; Harvey, R.; Gupta, S. CPPNet: A Coverage Path Planning Network. In Proceedings of the OCEANS 2021: SAN DIEGO—PORTO, San Diego, CA, USA, 20–23 September 2021; pp. 1–5. [Google Scholar]
- Schaefle, T.R.; Mohamed, S.; Uchiyama, N.; Sawodny, O. Coverage Path Planning for Mobile Robots Using Genetic Algorithm with Energy Optimization. In Proceedings of the 2016 International Electronics Symposium (IES), Denpasar, Indonesia, 29–30 September 2016; pp. 99–104. [Google Scholar]
- Xu, N.; Zhou, W. Research on Global Coverage Path Planning of Picking Robot Based on Adaptive Ant Colony Algorithm. J. Agric. Mech. Res. 2023, 45, 213–216+221. [Google Scholar] [CrossRef]
- Zhao, Y.; Shi, Y.; Wan, X. Path Planning of Multi-UAVs Area Coverage Based on Particle Swarm Optimization. J. Agric. Mech. Res. 2024, 46, 63–67. [Google Scholar] [CrossRef]
- Kubota, N.; Fukuda, T.; Shimojima, K. Trajectory planning of cellular manipulator system using virus-evolutionary genetic algorithm. Robot. Auton. Syst. 1996, 19, 85–94. [Google Scholar] [CrossRef]
- Ni, J.; Wang, X.; Tang, M.; Cao, W.; Shi, P.; Yang, S.X. An Improved Real-Time Path Planning Method Based on Dragonfly Algorithm for Heterogeneous Multi-Robot System. IEEE Access 2020, 8, 140558–140568. [Google Scholar] [CrossRef]
- Kyaw, P.T.; Paing, A.; Thu, T.T.; Mohan, R.E.; Vu Le, A.; Veerajagadheswar, P. Coverage Path Planning for Decomposition Reconfigurable Grid-Maps Using Deep Reinforcement Learning Based Travelling Salesman Problem. IEEE Access 2020, 8, 225945–225956. [Google Scholar] [CrossRef]
- Theile, M.; Bayerlein, H.; Nai, R.; Gesbert, D.; Caccamo, M. UAV Coverage Path Planning under Varying Power Constraints using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1444–1449. [Google Scholar] [CrossRef]
- Ni, J.; Li, X.; Hua, M.; Yang, S.X. Bioinspired Neural Network-Based Q-Learning Approach for Robot Path Planning in Unknown Environments. Int. J. Robot. Autom. 2016, 31, 464–474. [Google Scholar] [CrossRef]
- Zellner, A.; Dutta, A.; Kulbaka, I.; Sharma, G. Deep recurrent Q-learning for energy-constrained coverage with a mobile robot. Neural Comput. Appl. 2023, 35, 19087–19097. [Google Scholar] [CrossRef]
- Almadhoun, R.; Taha, T.; Seneviratne, L.; Zweiri, Y. A survey on multi-robot coverage path planning for model reconstruction and mapping. SN Appl. Sci. 2019, 1, 847. [Google Scholar] [CrossRef]
- Shen, X.; Zhao, T. UAV regional coverage path planning strategy based on DDQN. Electron. Meas. Technol. 2023, 46, 30–36. [Google Scholar] [CrossRef]
- Xing, B.; Wang, X.; Yang, L.; Liu, Z.; Wu, Q. An Algorithm of Complete Coverage Path Planning for Unmanned Surface Vehicle Based on Reinforcement Learning. J. Mar. Sci. Eng. 2023, 11, 645. [Google Scholar] [CrossRef]
- Theile, M.; Bayerlein, H.; Nai, R.; Gesbert, D.; Caccamo, M. UAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 539–546. [Google Scholar]
- Ruan, G.; Chen, J.; Xu, F. Complete coverage path planning algorithm based on rolling optimization and decentralized predator-prey model. Control. Decis. 2023, 38, 2545–2553. [Google Scholar] [CrossRef]
- Luo, Z.; Feng, S.; Liu, X.; Chen, J.; Wang, R. Method of area coverage path planning of multi-unmanned cleaning vehicles based on step by step genetic algorithm. J. Electron. Meas. Instrum. 2020, 34, 43–50. [Google Scholar] [CrossRef]
- Li, L.; Shi, D.; Jin, S.; Yang, S.; Zhou, C.; Lian, Y.; Liu, H. Exact and Heuristic Multi-Robot Dubins Coverage Path Planning for Known Environments. Sensors 2023, 23, 2560. [Google Scholar] [CrossRef] [PubMed]
- Latombe, J.C. Exact Cell Decomposition. In Robot Motion Planning; Springer: Boston, MA, USA, 1991; pp. 200–247. [Google Scholar] [CrossRef]
- Choset, H. Coverage of known spaces: The boustrophedon cellular decomposition. Auton. Robot. 2000, 9, 247–253. [Google Scholar] [CrossRef]
- Choset, H.; Pignon, P. Coverage Path Planning: The Boustrophedon Cellular Decomposition. In Field and Service Robotics; Zelinsky, A., Ed.; Springer: London, UK, 1998; pp. 203–209. [Google Scholar]
- Acar, E.; Choset, H.; Rizzi, A.; Atkar, P.; Hull, D. Morse decompositions for coverage tasks. Int. J. Robot. Res. 2002, 21, 331–344. [Google Scholar] [CrossRef]
- Han, Y.; Shao, M.; Wu, Y.; Zhang, X. An Improved Complete Coverage Path Planning Method for Intelligent Agricultural Machinery Based on Backtracking Method. Information 2022, 13, 313. [Google Scholar] [CrossRef]
- Shi, W.; Huang, H.; Jiang, L. Multi-robot Path Planning for Collaborative Full- Coverage Search in Complex Environments. Electron. Opt. Control. 2022, 29, 106–111. [Google Scholar]
- Bao, C. K-means clustering algorithm: A brief review. Acad. J. Comput. Inf. Sci. 2021, 4, 37–40. [Google Scholar] [CrossRef]
- Muhammad, A.; Sebastian, K. Potential applications of unmanned ground and aerial vehicles to mitigate challenges of transport and logistics-related critical success factors in the humanitarian supply chain. Asian J. Sustain. Soc. Responsib. 2020, 5, 1–22. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.M. Refining Initial Points for K-Means Clustering. In Proceedings of the International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; Volume 98, pp. 91–99. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Salvador, S.; Chan, P. Determining the number of clusters/segments in hierarchical clustering/segmentation algorithms. In Proceedings of the ICTAI 2004: 16th IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004; Khoshgoftaar, T., Ed.; pp. 576–584. [Google Scholar]
- Yang, J.; Wang, Y.K.; Yao, X.; Lin, C.T. Adaptive initialization method for K-means algorithm. Front. Artif. Intell. 2021, 4, 740817. [Google Scholar] [CrossRef]
- Shi, F.; Neumann, F.; Wang, J. Time complexity analysis of evolutionary algorithms for 2-hop (1,2)-minimum spanning tree problem. Theor. Comput. Sci. 2021, 893, 159–175. [Google Scholar] [CrossRef]
- He, Z.; Pang, H.; Bai, Z.; Zheng, L.; Liu, L. An Improved Dueling Double Deep Q Network Algorithm and Its Application to the Optimized Path Planning for Unmanned Ground Vehicle. In Proceedings of the SAE 2023 Intelligent and Connected Vehicles Symposium, Nanchang, China, 22–23 September 2023. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; van Hasselt, H.; Lanctot, M.; de Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Balcan, M., Weinberger, K., Eds.; Volume 48, pp. 1995–2003. [Google Scholar]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. Proc. VLDB Endow. 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Dornaika, F.; El Hajjar, S. Single phase multi-view clustering using unified graph learning and spectral representation. Inf. Sci. 2023, 645, 119366. [Google Scholar] [CrossRef]
- Borlea, I.D.; Precup, R.E.; Borlea, A.B. Improvement of K-means Cluster Quality by Post Processing Resulted Clusters. Procedia Comput. Sci. 2022, 199, 63–70. [Google Scholar] [CrossRef]
- Mihalache, S.; Burileanu, D. Speech Emotion Recognition Using Deep Neural Networks, Transfer Learning, and Ensemble Classification Techniques. Rom. J. Inf. Sci. Technol. 2023, 26, 375–387. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | |
|---|---|---|
| 1,175,302 | Trainable parameters | |
| 2 | Number of conv. layers | |
| 16 | Number of conv. kernels | |
| 5 | Conv. kernel size | |
| 50,000 | Experience pool size | |
| m | 128 | Small batch sample size |
| Symbol | Description |
|---|---|
 | Departure and return area |
 | Prohibited area |
 | Need to cover area |
 | Obstacle area |
 | Remaining need to be covered area |
| Metrics | Average Silhouette Coefficient | Calinski–Harabasz Index | Davies–Bouldin Index | Iteration |
|---|---|---|---|---|
| K-Means | 0.375 | 91.59 | 0.843 | 7.16 |
| K-Means++ | 0.396 | 93.78 | 0.792 | 4.66 |
| K-MeansII | 0.402 | 95.73 | 0.778 | 4.61 |
| Improved K-Means | 0.412 | 101.790 | 0.770 | 4.58 |
| Metrics | CR | RR | Reached | CRAC |
|---|---|---|---|---|
| Multi-mobile robots | 0.990 | 1.180 | 0.989 | 0.98 |
| Single-mobile robot | 0.690 | 1.460 | 0.985 | 0.682 |
| Metrics | CR | RR |
|---|---|---|
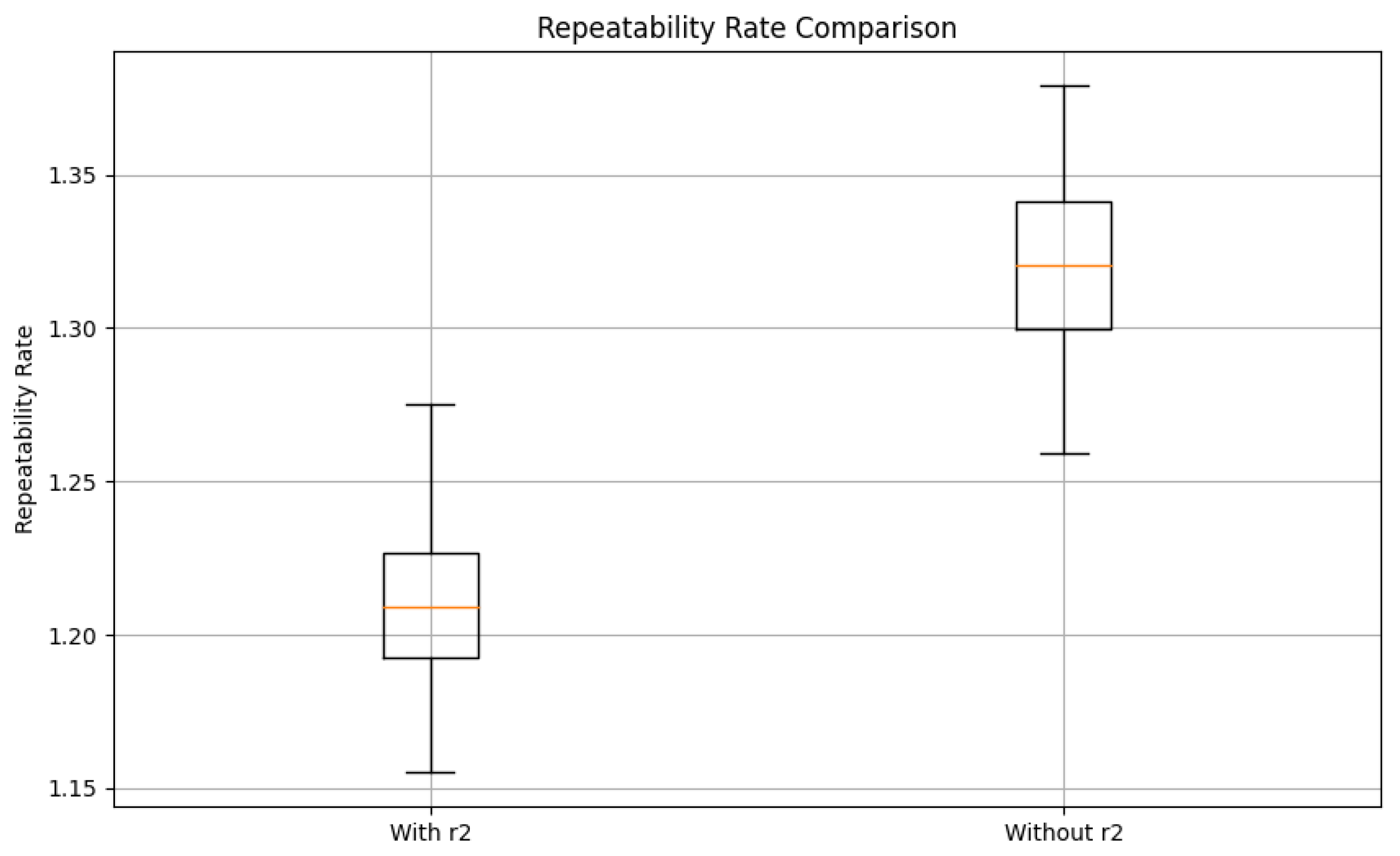
| Add reward | 0.987 | 1.21 |
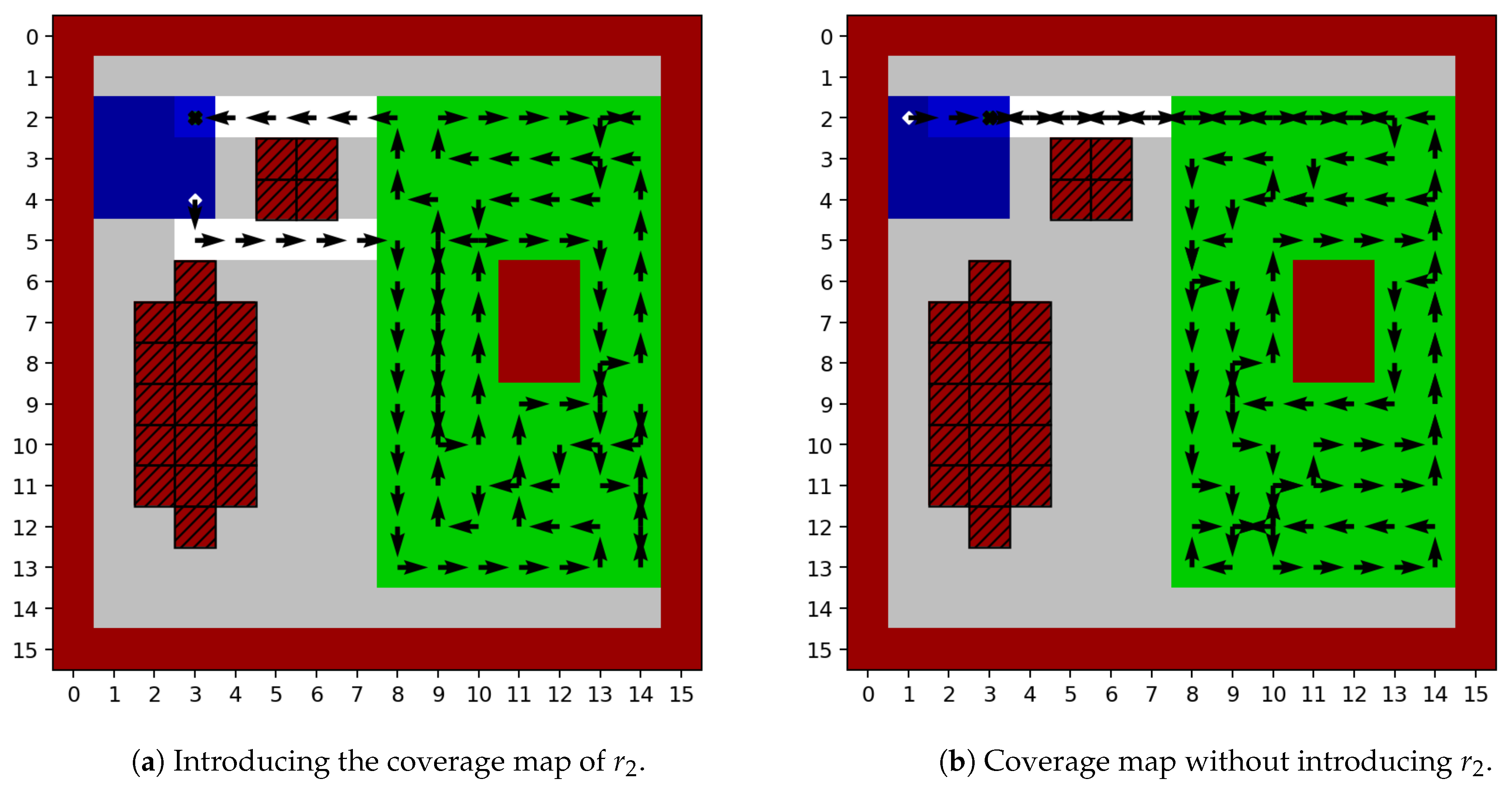
| Without reward | 0.98 | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Gu, Y.; Tang, G.; Ke, C.; Gu, Y. Cooperative Coverage Path Planning for Multi-Mobile Robots Based on Improved K-Means Clustering and Deep Reinforcement Learning. Electronics 2024, 13, 944. https://doi.org/10.3390/electronics13050944
Ni J, Gu Y, Tang G, Ke C, Gu Y. Cooperative Coverage Path Planning for Multi-Mobile Robots Based on Improved K-Means Clustering and Deep Reinforcement Learning. Electronics. 2024; 13(5):944. https://doi.org/10.3390/electronics13050944
Chicago/Turabian StyleNi, Jianjun, Yu Gu, Guangyi Tang, Chunyan Ke, and Yang Gu. 2024. "Cooperative Coverage Path Planning for Multi-Mobile Robots Based on Improved K-Means Clustering and Deep Reinforcement Learning" Electronics 13, no. 5: 944. https://doi.org/10.3390/electronics13050944
APA StyleNi, J., Gu, Y., Tang, G., Ke, C., & Gu, Y. (2024). Cooperative Coverage Path Planning for Multi-Mobile Robots Based on Improved K-Means Clustering and Deep Reinforcement Learning. Electronics, 13(5), 944. https://doi.org/10.3390/electronics13050944