Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function

 ,
,
Abstract
:1. Introduction
1.1. Literature Review
1.2. Contributions
1.3. Organization
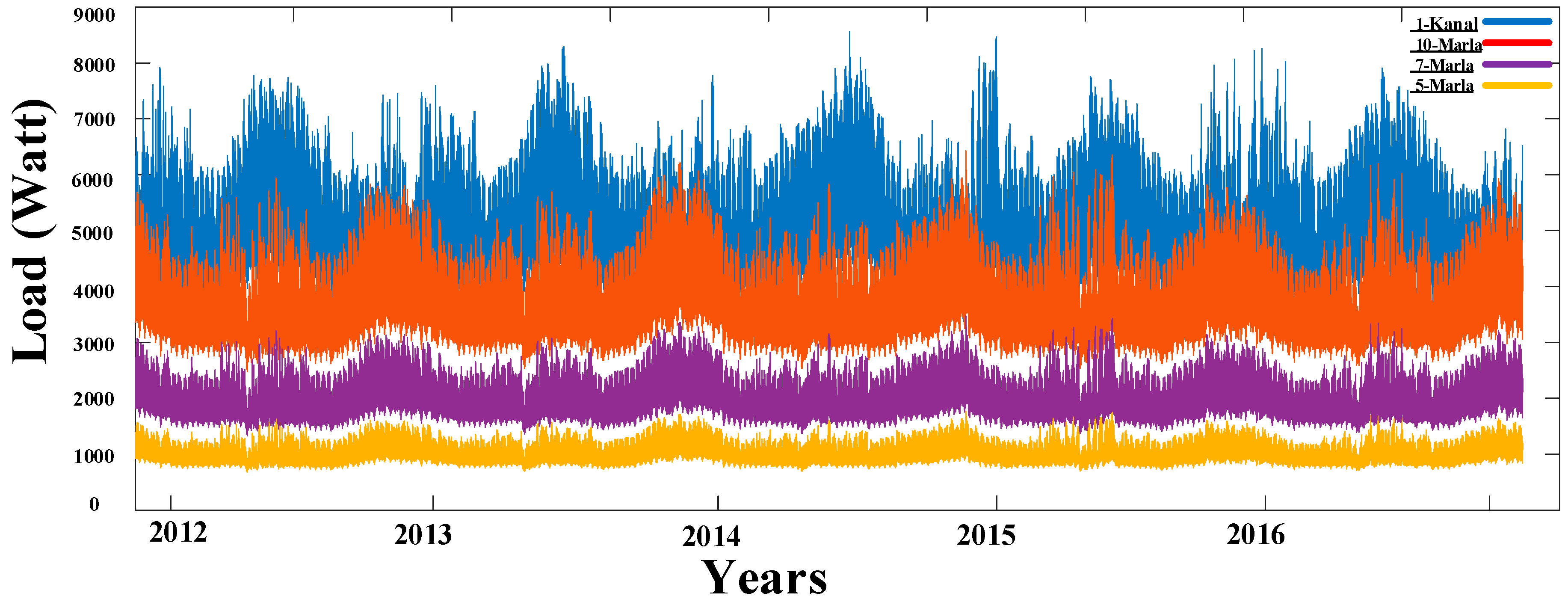
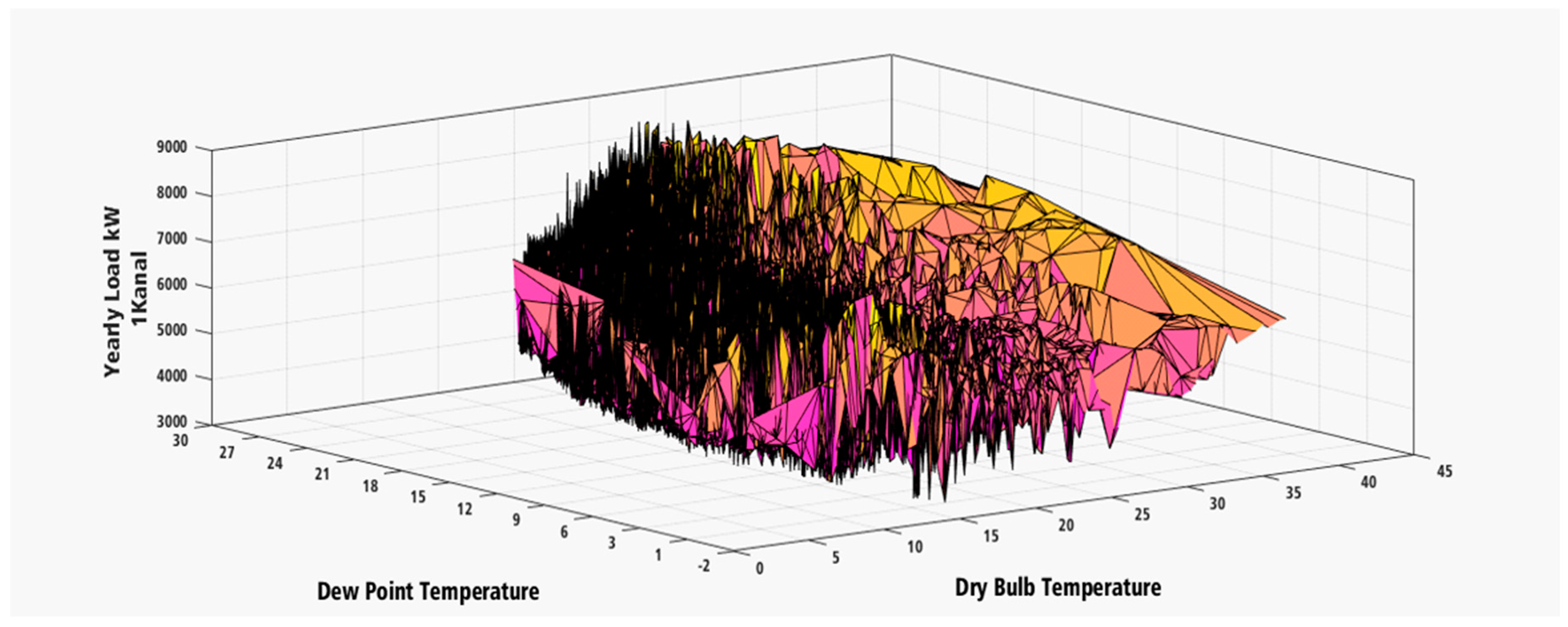
2. Load Consumption IESCO
- 1 Kanal = 10,042 Square Meter approx., Load Demand; winter (3.5 kW–8.5 kW); Summer (2.5 kW–8 kW)
- 10 Marla = 5021 Square Meter approx., Load Demand; winter (2.5 kW–6.5 kW); Summer (2 kW–6 kW)
- 7 Marla = 3514 Square Meter approx., Load Demand; winter (1 kW–3.5 kW); Summer (1 kW–3kW)
- 5 Marla = 2510 Square Meter approx., Load Demand; winter (0.5 kW–2 kW); Summer (0.5 kW–1.7 kW)
3. Load Forecasting Methods
3.1. Statistical Methods
- ARMA-Auto Regress Moving Average
- ARIMA-Auto Regress Integrated Moving Average
- State Space
- Linear Regression
ARIMA/State Space
- Apply quick Fourier transformation, remove trends, and ensure the model is stationary.
- Autocorrelation and partial autocorrelation graphs are analyzed to check if the moving average and autoregressive models are suitable. To confirm ARMA configuration, check for the extended data autocorrelation graph.
- Different ARMA model sets are tested for the lowest Akaike’s Information (AIC) and Schwartz Bayesian Information (BIC) Criterion.
3.2. Computational-Statistical Methods
Bootstrap Regression Tree
3.3. Computational Intelligent Methods
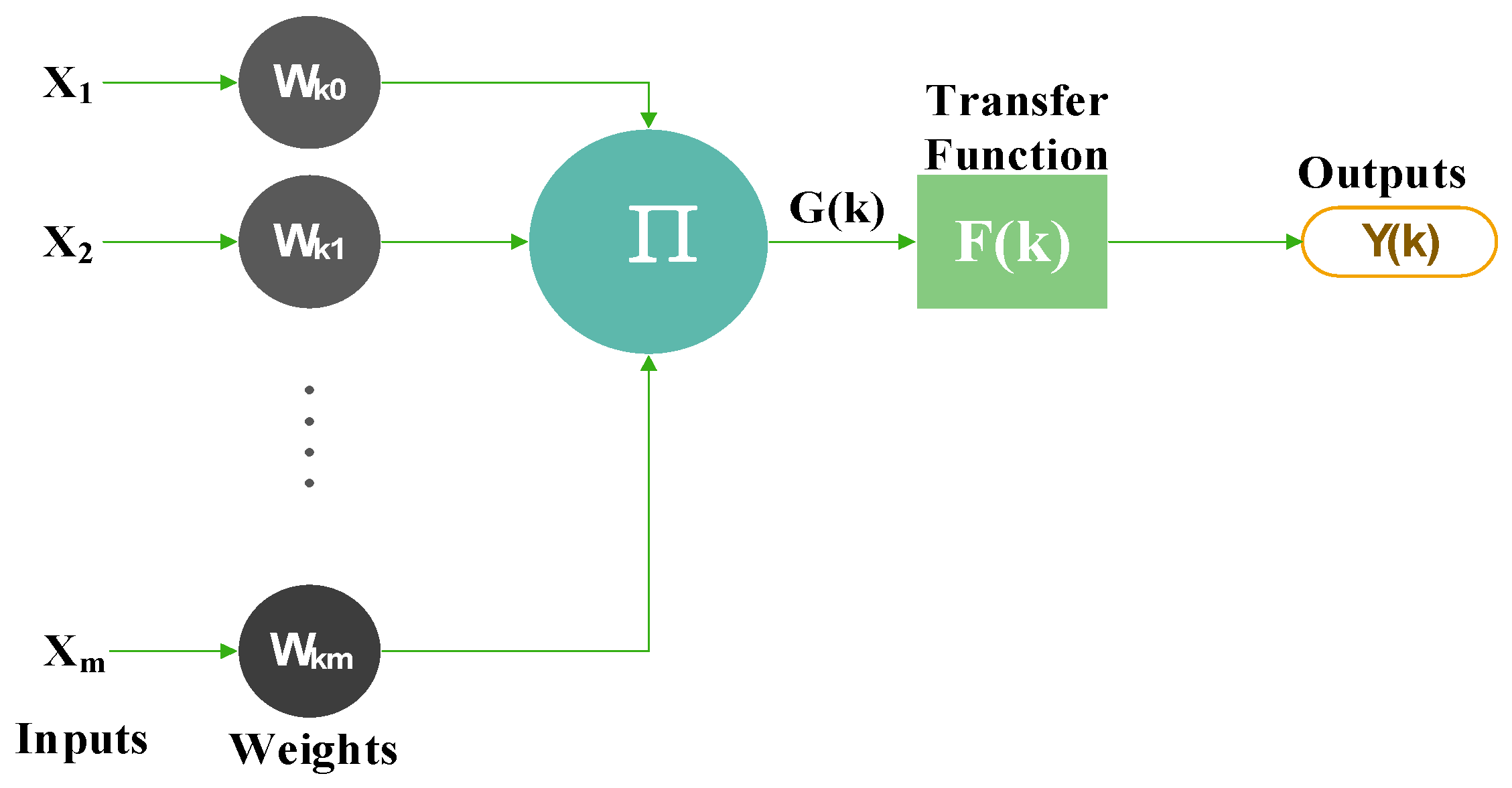
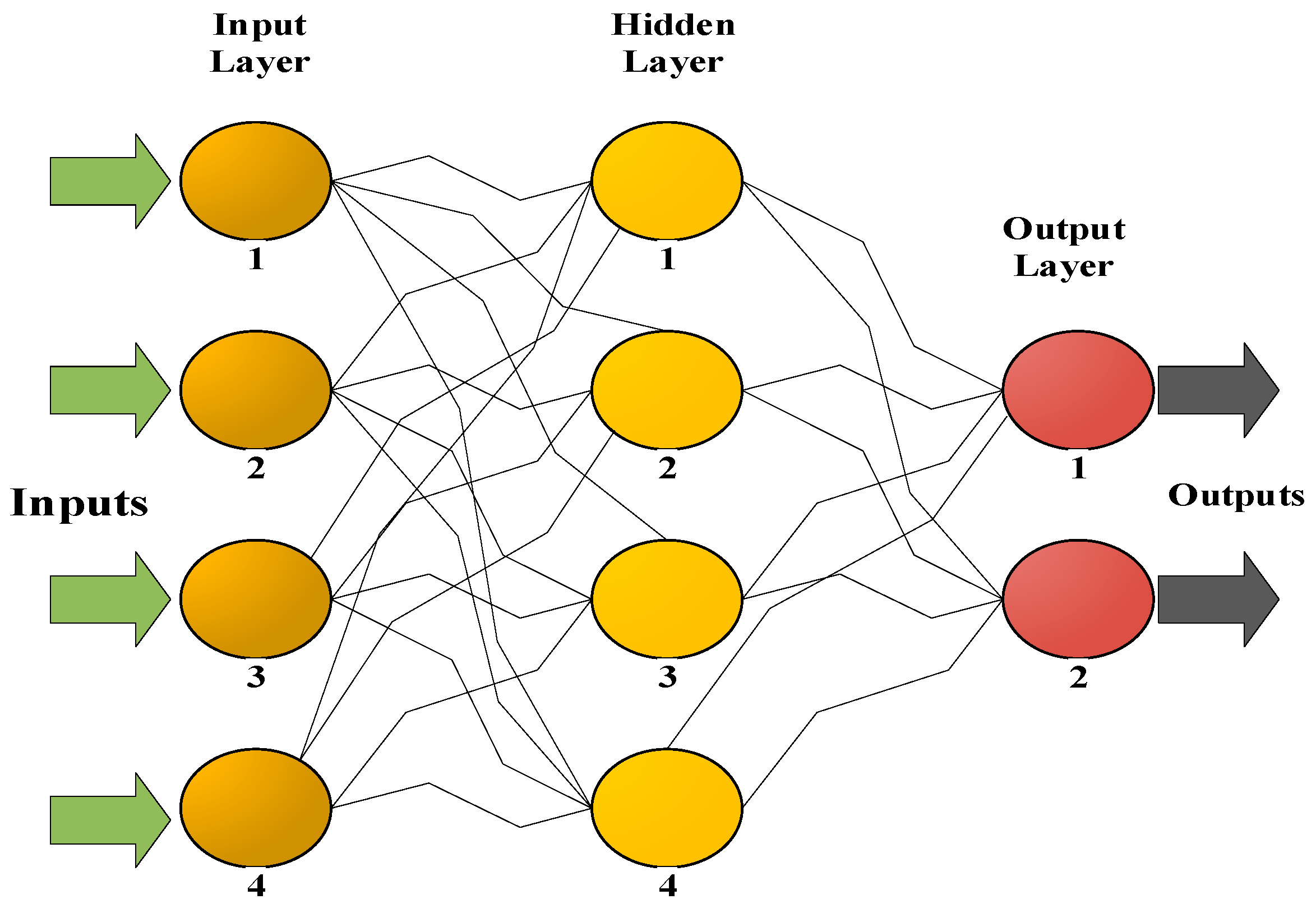
Artificial Neural Network (ANN) Description
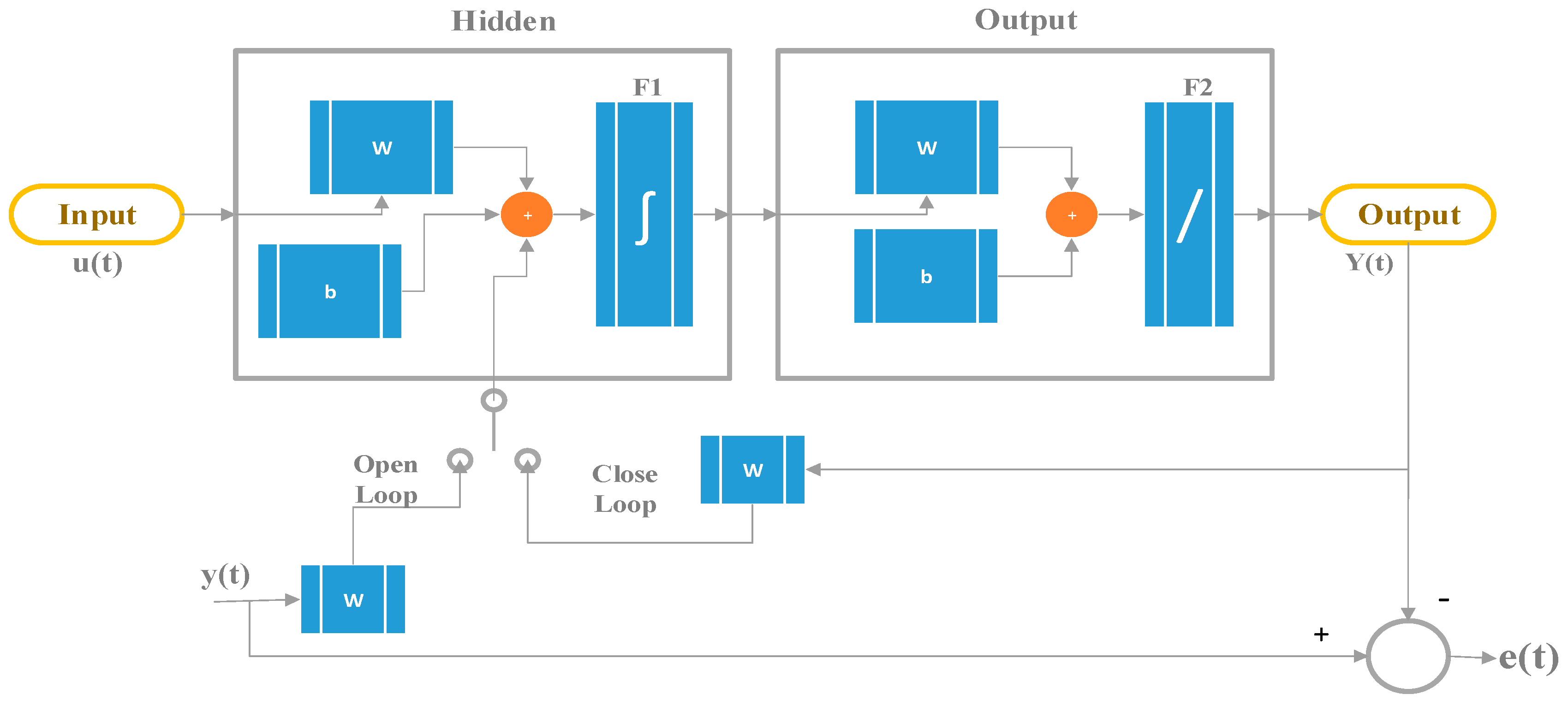
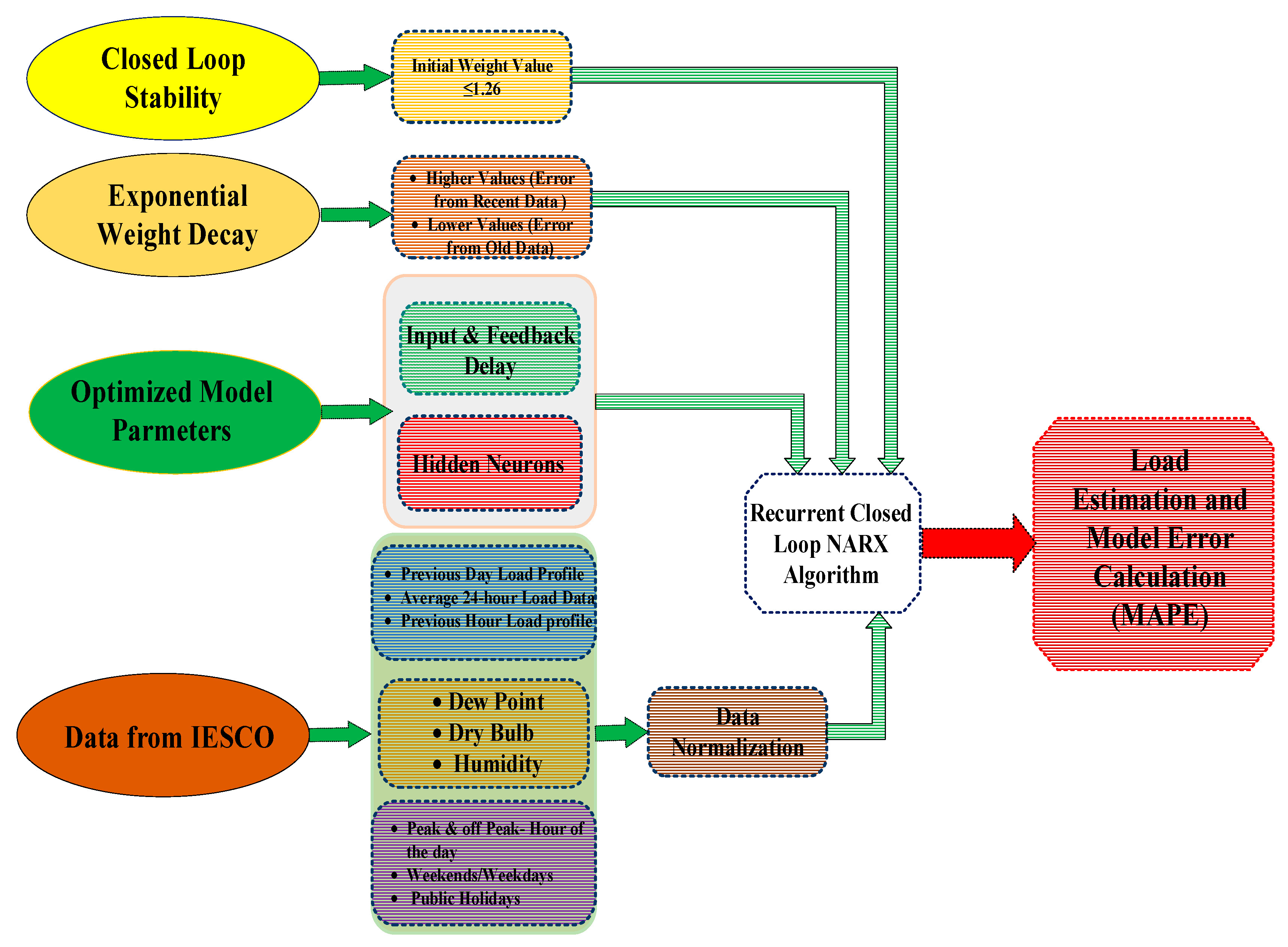
4. NARX Neural Network
4.1. NARX Architecture
4.1.1. Non Recurrent or Recurrent Network
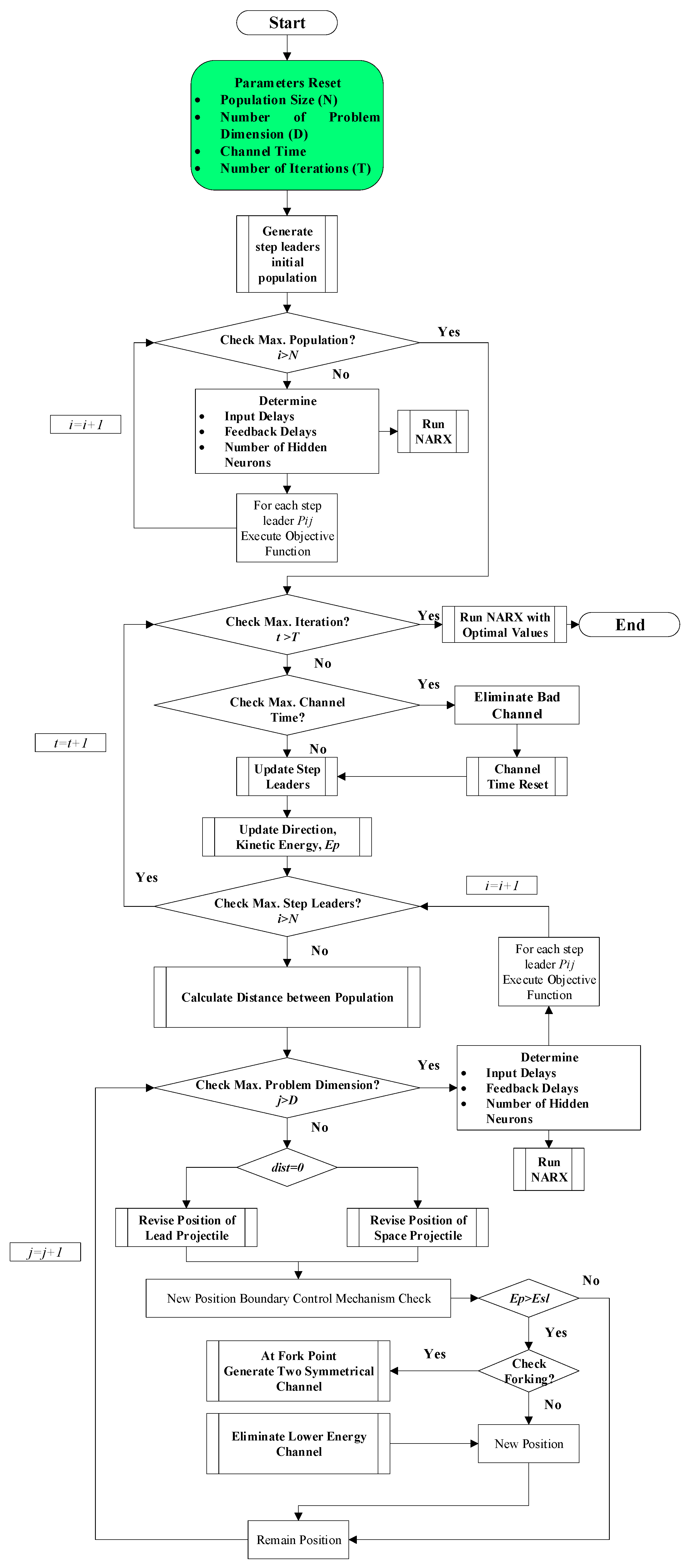
4.1.2. Optimal Parameters
Lighting Search Algorithm
- ▪
- Projectiles Properties
- ▪
- Transition State Projectile
- ▪
- Space State Projectile
- ▪
- Lead State Projectile
- ▪
- Forking Method
- With production of symmetrical channels due to collusion in nucleus, given as:The one-dimensional original and opposite projectiles are represented by and , respectively, with a and b as boundaries, a satisfied fitness value is chosen by the forking leader in order to increase the method efficacy.
- After the number of propagation, the unsuccessful step leaders re-forward the energy. In such a case, a successful leader tip is expected to produce a channel to generate forking.
- ▪
- Optimization Algorithm
- The parameters values are declared, which includes population size, channel time, and number of iterations. Moreover, boundaries are assigned for three-dimensional numbers of hidden neurons, feedback delays, and input delays.
- 100 iterations are considered with 10-channel time.
- The hidden nodes range are set from 0–20.
- Delays are set in range 1–64.
- Step leaders are generated randomly within the bounded range for the number of hidden neurons, feedback delays, and input delays.
- Levenberg–Marquardt is used for training with a logistic sigmoid as an activation function. During training, the objective function is calculated for each step leader.
- Considering all step leaders, the iterative process is initiated to find an optimal solution.
- Considering step leader movement, the bad channel is eliminated and the channel time is resettled.
- Step leaders are estimated based on best and worst performance.
- With revised kinetic energy, Ep the network is retrained and the activation function is re-executed. For each step leader, the objective function is reassessed.
- Ejecting space particles and lead particles.
- In case the energy of space and lead projectiles greater than step leader energy, their direction and position are updated using Equations (18) and (20).
- Re-initialize the updated projectile. The network is retrained and the objective function for lead and space particles is reassessed.
- Two identical channels are formed at the fork point in the case of occurrence of forking. With the least energy, elimination of the channel time is revised.
- All values in the population are updated and the procedure is repeated until the maximum iteration limit.
- The optimal result for the number of hidden neurons, feedback delays, and input delays are utilized in the NARXNN network for the best training and validation.
4.1.3. Operating Parameters
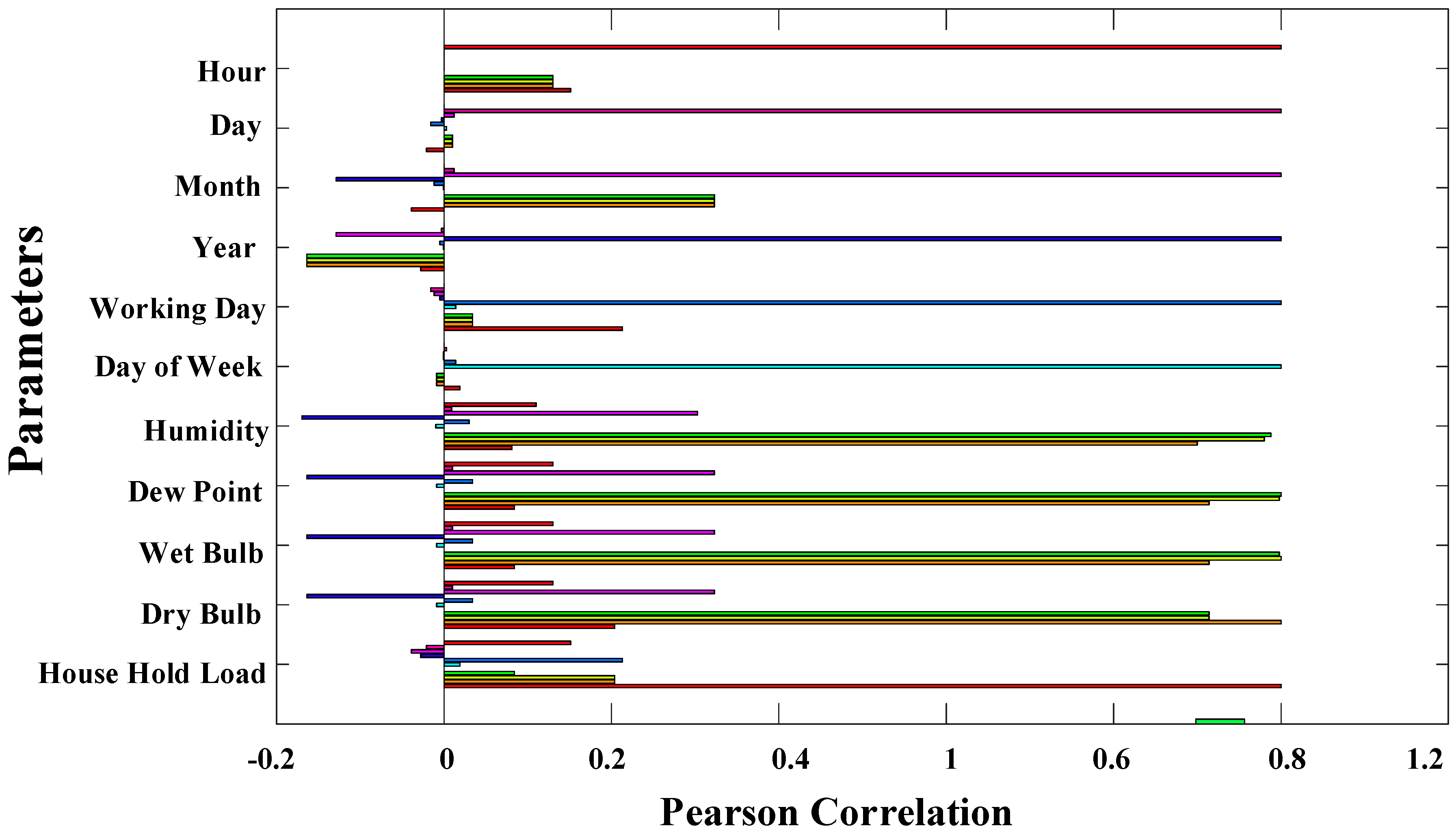
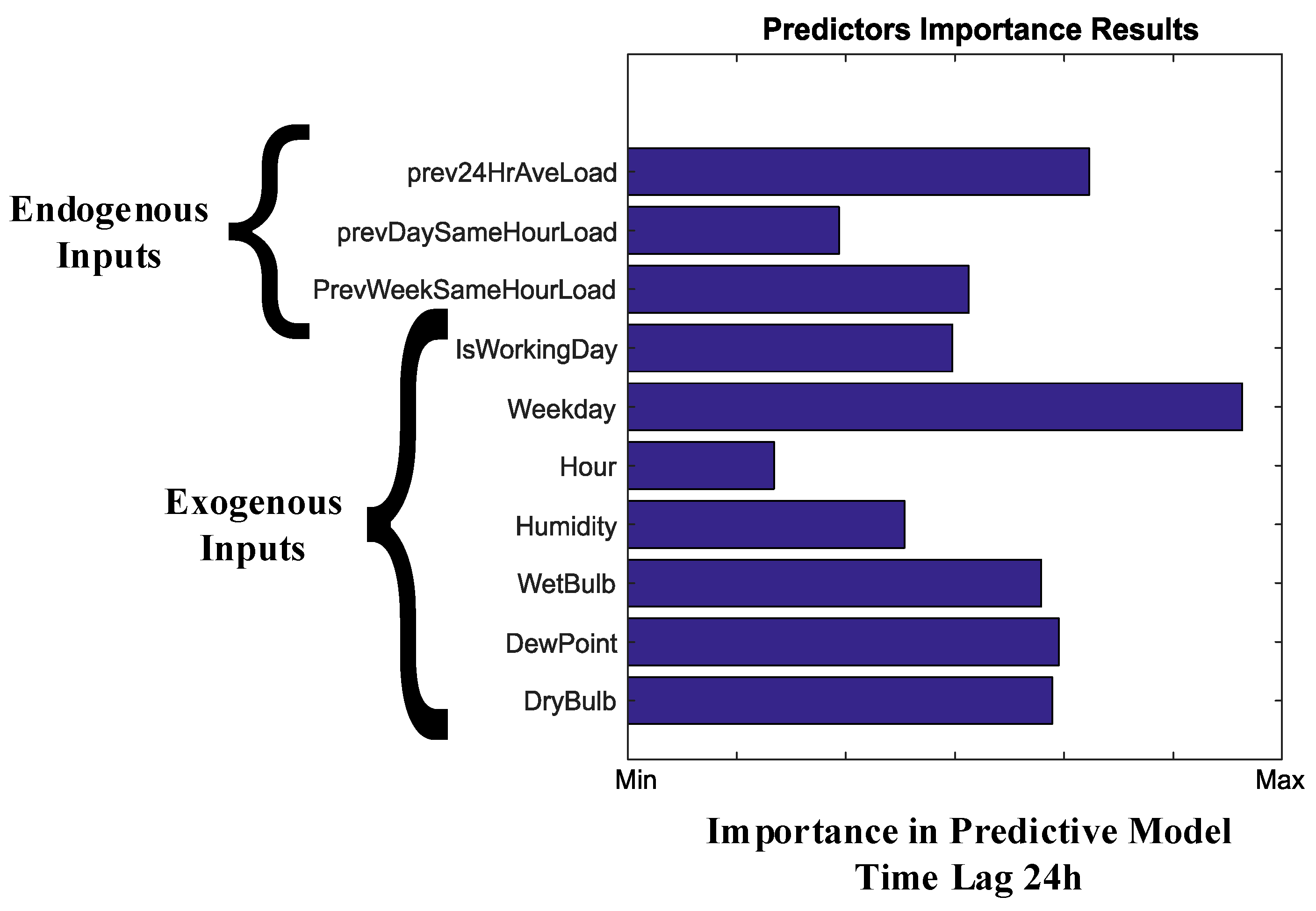
4.1.4. Parameters Selection
- Input variables are determining the number Input nodes. In the proposed case, 10 variables are taken excluding wet bulb temperature.
- 10 hidden layers have been considered here for the best solution. The number of hidden layers can only be 1.
- The input nodes are equal to the number of hidden nodes.
- The output nodes are determined by the size of the forecasting period.
- Logistic Sigmoid is used as an activation function, which is mathematically given as:
- The Levenberg–Marquardt backpropagation is used as a learning algorithm, which is mathematically represented as:
4.1.5. Closed Loop Stability
4.1.6. Error Weight Decay
4.1.7. Performance Metrics
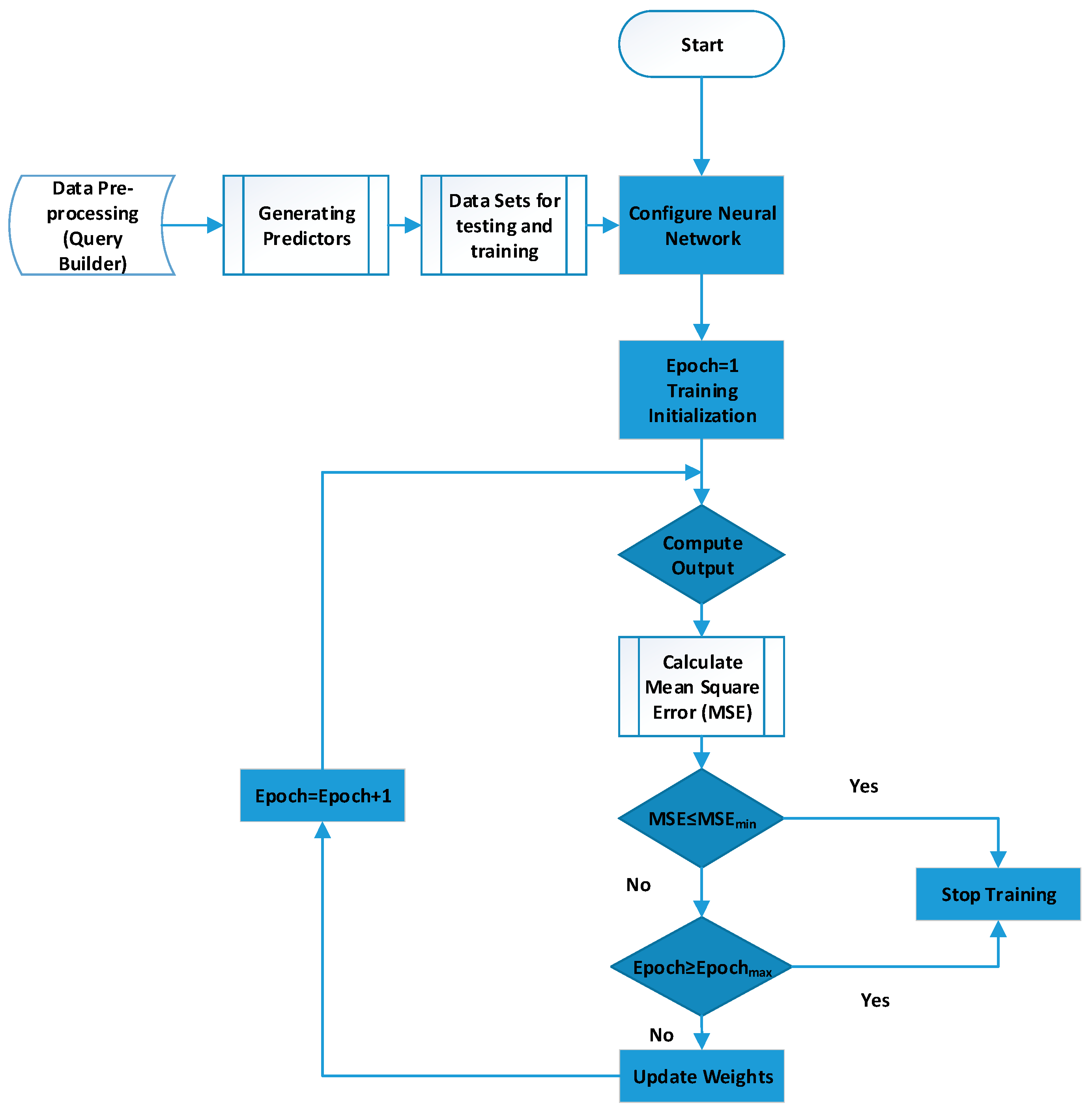
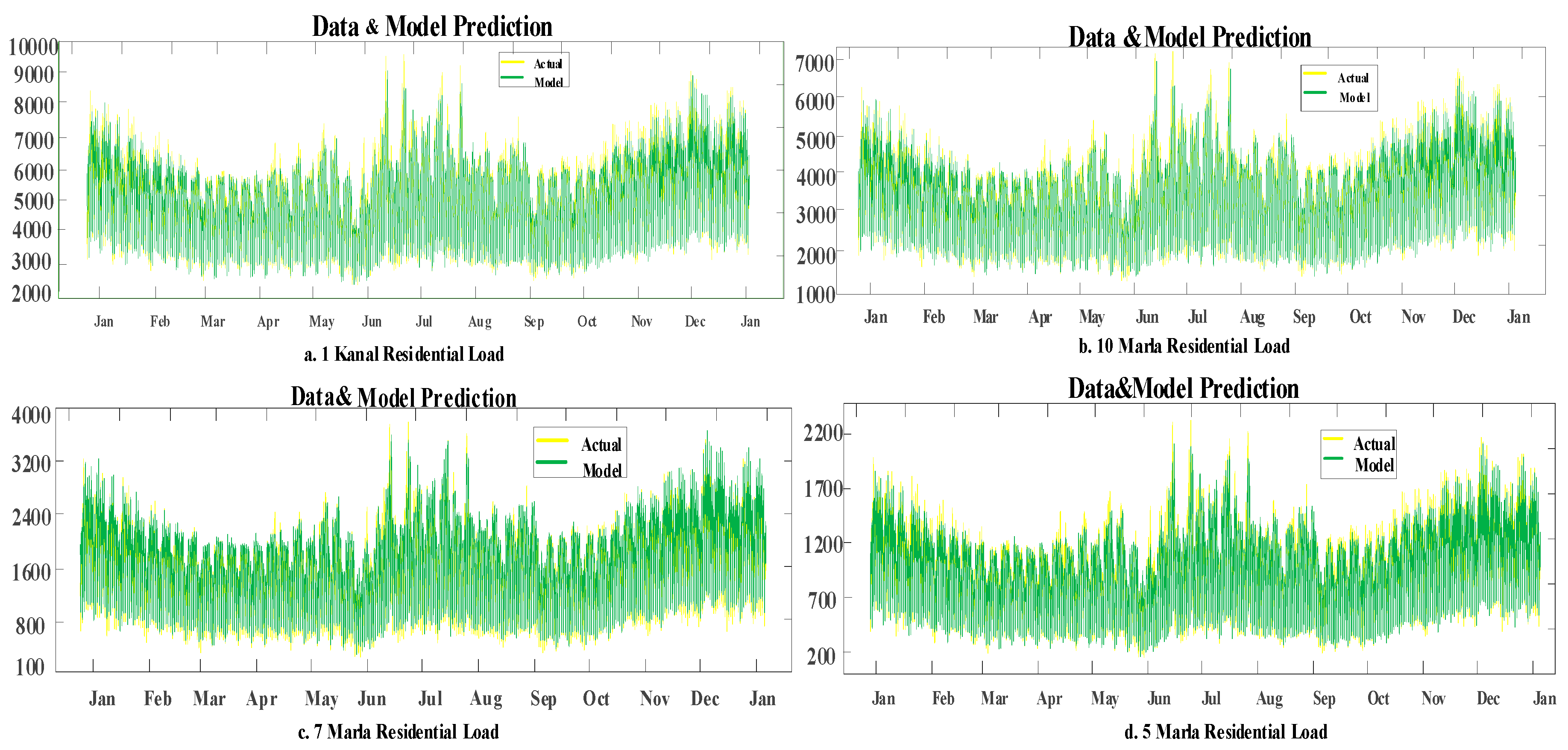
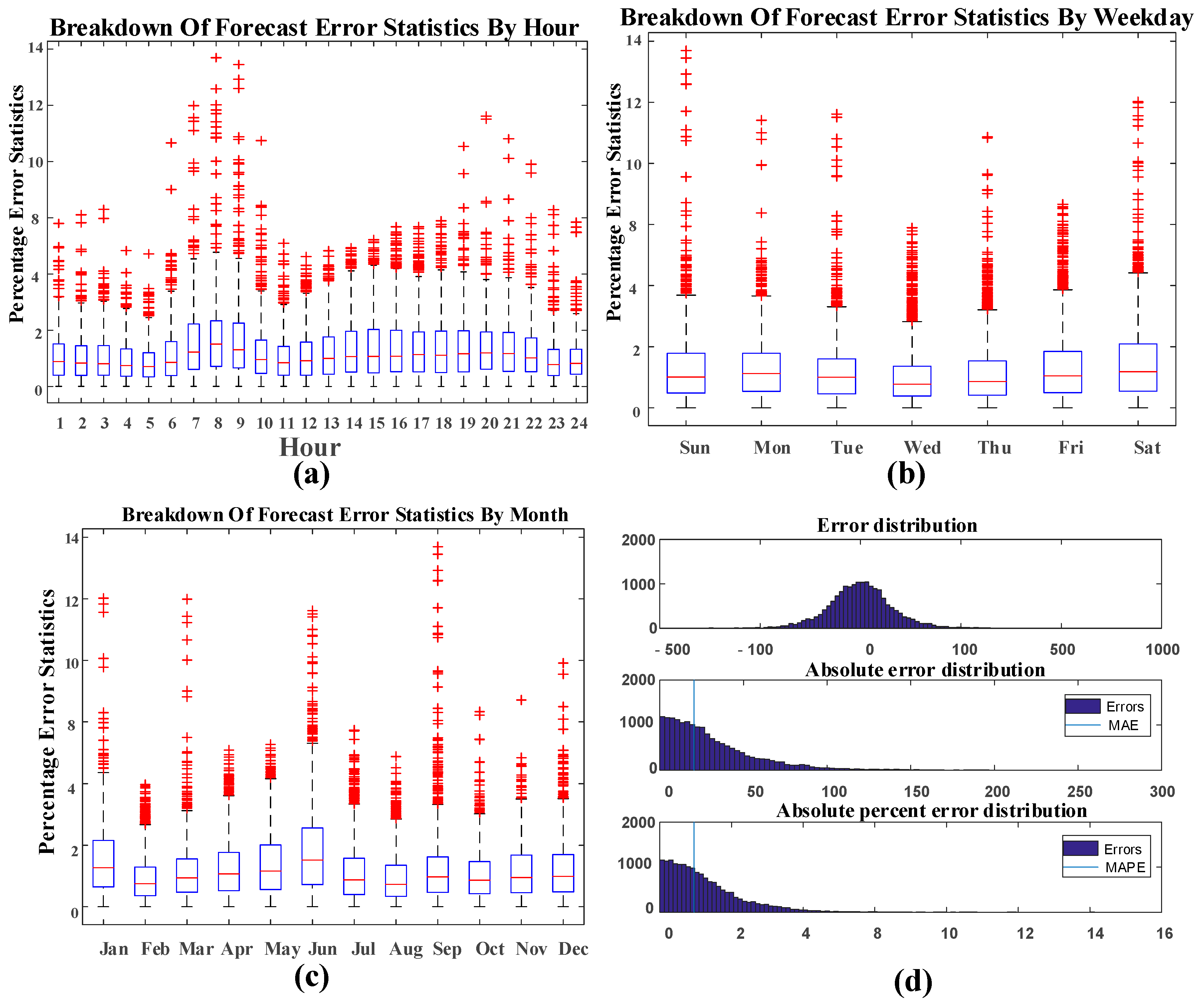
5. Simulation and Results
- Number of Neurons
- Input and Feedback time lags
- Training Data
- Training Algorithm
- Activation function for neurons
Proposed Improvement
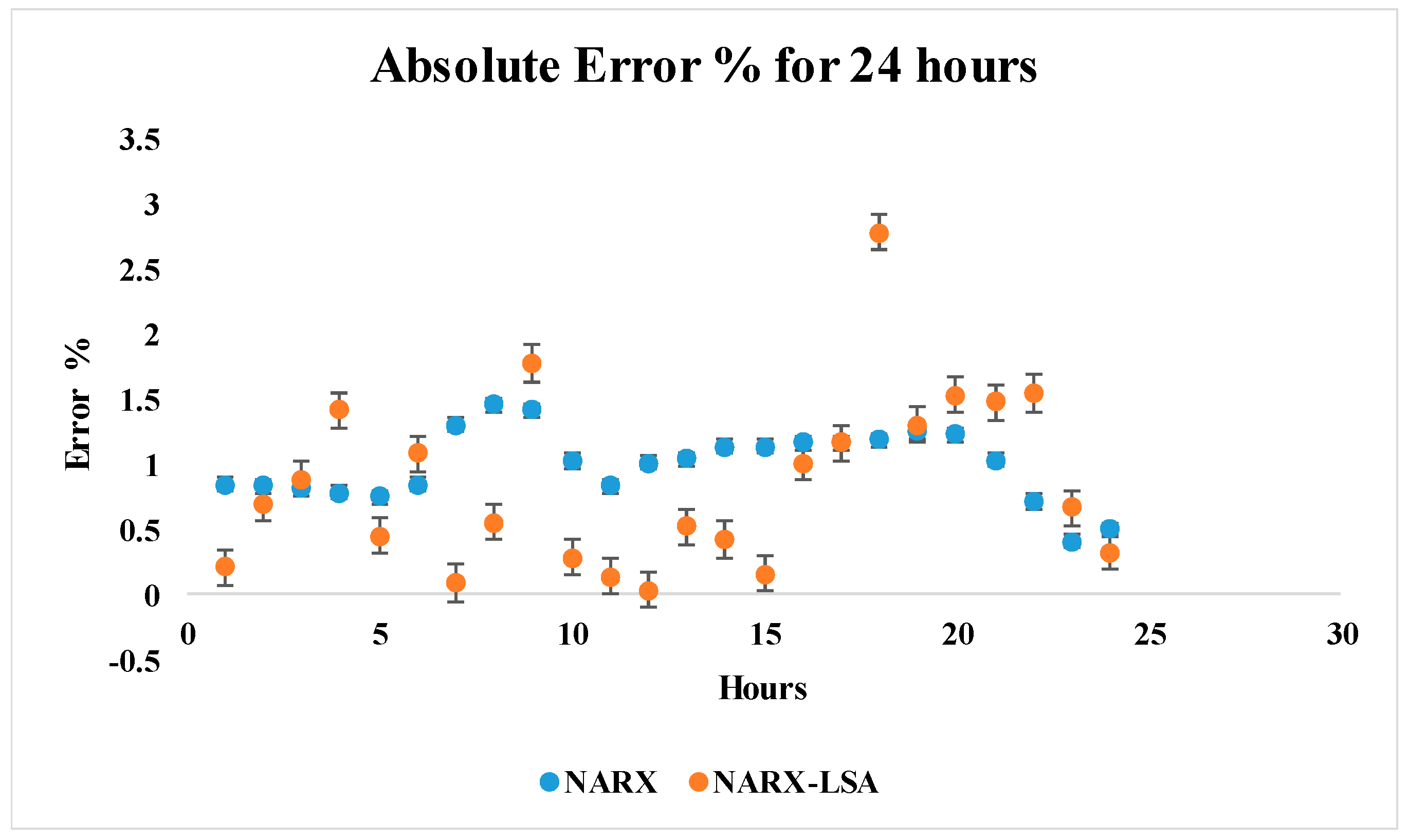
6. Results & Discussion
Future Consideration
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nengling, T.; Stenzel, J.; Hongxiao, W. Techniques of applying wavelet transform into combined model for short-term load forecasting. Electr. Power Syst. Res. 2006, 76, 525–533. [Google Scholar] [CrossRef]
- Satish, B.; Swarup, K.S.; Srinivas, S.; Rao, A.H. Effect of temperature on short term load forecasting using an integrated ANN. Electr. Power Syst. Res. 2004, 72, 95–101. [Google Scholar] [CrossRef]
- Feinberg, E.A.; Genethliou, D. Load Forecasting. Available online: http://www.almozg.narod.ru/bible/lf.pdf (accessed on 9 February 2017).
- Srivastava, A.K.; Pandey, A.S.; Singh, D. Short-Term Load Forecasting Methods: A Review. Presented at the International Conference on Emerging Trends in Electrical Electronics & Sustainable Energy Systems (ICETEESES), Sultanpur, India, 11–12 March 2016. [Google Scholar]
- Alfares, H.K.; Nazeeruddin, M. Electric load forecasting: Literature survey and classification of methods. Int. J. Syst. Sci. 2002, 33, 23–34. [Google Scholar] [CrossRef]
- Raza, M.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Ghayekhloo, M.; Menhaj, M.B.; Ghofrani, M. A hybrid short-term load forecasting with a new data-preprocessing framework. Electr. Power Syst. Res. 2015, 119, 138–148. [Google Scholar] [CrossRef]
- Metaxiotis, K.; Kagiannas, A.; Askounis, D.; Psarras, J. Artificial intelligence in short term electric load forecasting: A state-of-the-art survey for the researcher. Energy Convers. Manag. 2003, 44, 1525–1534. [Google Scholar] [CrossRef]
- Hahn, H.; Meyer-Nieberg, S.; Pickl, S. Electric load forecasting methods: Tools for decision making. Eur. J. Oper. Res. 2009, 199, 902–907. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Bennett, C.; Stewart, R.A.; Lu, J. Autoregressive with exogenous variables and neural network short-term load forecast models for residential low voltage distribution networks. Energies 2014, 7, 2938–2960. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J. Short-Term Load Forecasting for Microgrids Based on Artificial Neural Networks. Energies 2013, 6, 1385–1408. [Google Scholar] [CrossRef] [Green Version]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sanchez-Esguevillas, A.; Sanjuan, J.; Gonzalez, L.; Lloret, J. Improved short-term load forecasting based on two-stage predictions with artificial neural networks in a microgrid environment. Energies 2013, 6, 4489–4507. [Google Scholar] [CrossRef]
- Fattaheian, S.; Fereidunian, A.; Gholami, H.; Lesani, H. Hour-ahead demand forecasting in smart grid using support vector regression (SVR). Int. Trans. Electr. Energy Syst. 2014, 24, 1650–1663. [Google Scholar] [CrossRef]
- Mahmoud, T.S.; Habibi, D.; Hassan, M.Y.; Bass, O. Modelling self-optimised short term load forecasting for medium voltage loads using tunning fuzzy systems and Artificial Neural Networks. Energy Convers. Manag. 2015, 106, 1396–1408. [Google Scholar] [CrossRef]
- Lei, J.; Jin, T.; Hao, J.; Li, F. Short-term load forecasting with clustering–regression model in distributed cluster. Clust. Comput. 2017, 1–11. [Google Scholar] [CrossRef]
- Buitrago, J.; Abdulaal, A.; Asfour, S. Electric load pattern classification using parameter estimation, clustering and artificial neural networks. Int. J. Power Energy Syst. 2015, 35, 167–174. [Google Scholar] [CrossRef]
- Abdulaal, A.; Buitrago, J.; Asfour, S. Electric Load Pattern Classification for Demand-side Management Planning: A Hybrid Approach. In Software Engineering and Applications: Advances in Power and Energy Systems; ACTA Press: Marina del Rey, CA, USA, 2015. [Google Scholar]
- Gajowniczek, K.; Nafkha, R.; Ząbkowski, T. Electricity peak demand classification with artificial neural networks. Ann. Comput. Sci. Inf. Syst. 2017, 11, 307–315. [Google Scholar] [Green Version]
- Ząbkowski, T.; Gajowniczek, K.; Szupiluk, R. Grade analysis for energy usage patterns segmentation based on smart meter data. In Proceedings of the 2015 IEEE 2nd International Conference on Cybernetics (CYBCONF), Gdynia, Poland, 24–26 June 2015; pp. 234–239. [Google Scholar]
- Singh, S.; Yassine, A. Big Data Mining of Energy Time Series for Behavioral Analytics and Energy Consumption Forecasting. Energies 2018, 11, 452. [Google Scholar] [CrossRef]
- Ekonomou, L.; Christodoulou, C.; Mladenov, V. A Short-Term Load Forecasting Method Using Artificial Neural Networks and Wavelet Analysis. Int. J. Power Syst. 2016, 1, 64–68. [Google Scholar]
- Ekonomou, L.; Oikonomou, D. Application and comparison of several artificial neural networks for forecasting the Hellenic daily electricity demand load. In Proceedings of the 7th WSEAS International Conference on Artificial Intelligence, Knowledge Engineering and Data Bases, Cairo, Egypt, 29–31 December 2008; pp. 67–71. [Google Scholar]
- Easley, M.; Haney, L.; Paul, J.; Fowler, K.; Wu, H. Deep neural networks for short-term load forecasting in ERCOT system. In Proceedings of the IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 8–9 February 2018. [Google Scholar]
- Shareef, H.; Ibrahim, A.A.; Mutlag, A.H. Lightning search algorithm. Appl. Soft Comput. 2015, 36, 315–333. [Google Scholar] [CrossRef]
- Krogh, A.; Moody, J.; Hanson, S.; Hertz, J.A. A simple weight decay can improve generalization. Adv. Neural Inf. Process. Syst. 1995, 4, 950–957. [Google Scholar]
- Hinton, G.E. Learning translation invariant recognition in a massively parallel networks. In Proceedings of the International Conference on Parallel Architectures and Languages Europe, Eindhoven, The Netherlands, 15–19 June 1987; pp. 1–13. [Google Scholar]
- Moody, J.E. Note on generalization, regularization and architecture selection in nonlinear learning systems. In Proceedings of the Neural Networks for Signal Processing—1991 IEEE Workshop, Princeton, NJ, USA, 30 September–1 October 1991; pp. 1–10. [Google Scholar]
- User, S. IESCO Annual Performance Reports. Daily, Monthly and Quarterly Data. Available online: http://www.iesco.com.pk/index.php/customer-services/dailymonthly-yearly-data (accessed on 20 January 2018).
- 2005 ASHRAE Handbook. Design Conditions for ISLAMABAD (CIV/MIL), Pakistan. 2005. Available online: http://cms.ashrae.biz/weatherdata/STATIONS/415710_s.pdf (accessed on 1 February 2018).
- AAI-hamadi, H.; Soliman, S.A. Long term/Mid term electric load forecasting based on short-term correlation and annual growth. Electr. Power Syst. Res. 2005, 74, 353–361. [Google Scholar] [CrossRef]
- Pappas, S.S.; Ekonomou, L.; Karamousantas, D.C.; Chatzarakis, G.E.; Katsikas, S.K.; Liatsis, P. Electricity demand loads modeling using autoregressive moving average (arma) models. Energy 2008, 33, 1353–1360. [Google Scholar] [CrossRef]
- Lee, C.; Ko, C. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors; Department of Statistics University of California: Berkeley, CA, USA, 1994. [Google Scholar]
- Kalaitzakis, K.; Stavrakakis, G.S.; Anagnostakis, E.M. Short-term load forecasting based on artificial neural networks parallel implementation. Electr. Power Syst. Res. 2002, 63, 185–196. [Google Scholar] [CrossRef]
- Senjyu, T.; Takara, H.; Uezato, K.; Funabashi, T. One hour load orecasting using Nueral network. IEEE Trans. Power Syst. 2002, l7, 113–118. [Google Scholar] [CrossRef]
- Ning, Y.; Liu, Y.; Zhang, H.; Ji, Q. Comparison of different BP neural network models for short-term load forecasting. In Proceedings of the 2010 IEEE International Conference on Intelligent Computing and Intelligent Systems, Xiamen, China, 29–31 October 2010; Volume 3, pp. 433–438. [Google Scholar]
- Haykin, S. Neural Networks-A comprehensive foundation. In Neural Network A—Comperhensice Foundation, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Upadhyay, K.G.; Tripathi, M.M.; Singh, S.N. An Approach to Short Term Load Forecasting using Market Price Signal. In Proceedings of the International Conference on Distribution (CIRED), Vienna, Austria, 21–24 May 2007. [Google Scholar]
- Venturini, M. Simulation of compressor transient behavior through recurrent neural network models. J. Turbomach 2006, 128, 444–454. [Google Scholar] [CrossRef]
- Irigoyen, E.; Pinzolas, M. Numerical bounds to assure initial local stability of narx multilayer perceptrons and radial basis functions. Neurocomputing 2008, 72, 539–547. [Google Scholar] [CrossRef]
- Abbas, F.; Habib, S.; Feng, D.; Yan, Z. Optimizing Generation Capacities Incorporating Renewable Energy with Storage Systems Using Genetic Algorithms. Electronics 2018, 7, 100. [Google Scholar] [CrossRef]
- Rasool, A.; Yan, X.; Rasool, H.; Guo, H.; Asif, M. VSG Stability and Coordination Enhancement under Emergency Condition. Electronics 2018, 7, 202. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hour | FitNet Absolute Error% | BRT Absolute Error% | ARMAX Absolute Error% | State Space Absolute Error% | NARX Absolute Error% |
|---|---|---|---|---|---|
| 1 | 2.38 | 2.49 | 1.15 | 1.27 | 0.84 |
| 2 | 2.31 | 2.71 | 1.49 | 1.20 | 0.83 |
| 3 | 2.13 | 3.11 | 0.61 | 5.18 | 0.81 |
| 4 | 2.02 | 2.02 | 1.49 | 8.82 | 0.78 |
| 5 | 2.15 | 2.06 | 1.99 | 1.77 | 0.75 |
| 6 | 2.57 | 4.01 | 1.63 | 0.97 | 0.84 |
| 7 | 3.71 | 6.52 | 1.85 | 2.41 | 1.30 |
| 8 | 4.63 | 5.83 | 2.73 | 6.45 | 1.45 |
| 9 | 3.91 | 2.46 | 2.05 | 2.08 | 1.41 |
| 10 | 2.71 | 1.42 | 1.02 | 3.58 | 1.02 |
| 11 | 2.85 | 1.46 | 1.11 | 2.01 | 0.83 |
| 12 | 2.45 | 2.01 | 1.02 | 0.78 | 1.01 |
| 13 | 3.21 | 2.56 | 1.10 | 1.88 | 1.04 |
| 14 | 3.13 | 2.51 | 1.32 | 2.51 | 1.13 |
| 15 | 3.24 | 2.51 | 1.35 | 3.83 | 1.13 |
| 16 | 2.95 | 2.47 | 1.89 | 1.18 | 1.16 |
| 17 | 3.15 | 2.06 | 1.90 | 3.31 | 1.16 |
| 18 | 3.12 | 2.45 | 1.17 | 1.80 | 1.18 |
| 19 | 3.17 | 4.01 | 0.98 | 1.81 | 1.25 |
| 20 | 3.25 | 3.92 | 1.68 | 1.19 | 1.22 |
| 21 | 3.24 | 2.51 | 1.22 | 2.21 | 1.03 |
| 22 | 3.35 | 2.49 | 0.78 | 4.15 | 0.71 |
| 23 | 2.86 | 2.13 | 0.65 | 3.17 | 0.41 |
| 24 | 2.75 | 2.41 | 0.87 | 0.85 | 0.50 |
| Maximum | 4.63 | 6.52 | 2.73 | 8.82 | 1.45 |
| RMSE | 9.83 | 9.75 | 4.73 | 8.09 | 2.61 |
| MAPE% | 2.97 | 2.84 | 1.43 | 2.68 | 0.99 |
| Methods | Advantage | Disadvantage |
|---|---|---|
| ARIMA/State Space |
|
|
| Decision Tree |
|
|
| FitNet |
|
|
| NARX-LSA-EWD |
|
|
| Training Function | Activation Function | ClosedLoop-NARX-LSA MAPE | Closed Loop-NARX-LSA (Exponential Weight Decay) MAPE |
|---|---|---|---|
| Levenberg-Marquadt | Logistic Sigmoid | 0.85 | 0.821 |
| Levenberg-Marquadt | Hyperbolic Tangent | 2.04 | 2.01 |
| Bayesian Regularization | Logistic Sigmoid | 1.22 | 1.02 |
| Bayesian Regularization | Hyperbolic Tangent | 1.11 | 0.89 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, F.; Feng, D.; Habib, S.; Rahman, U.; Rasool, A.; Yan, Z. Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function. Electronics 2018, 7, 432. https://doi.org/10.3390/electronics7120432
Abbas F, Feng D, Habib S, Rahman U, Rasool A, Yan Z. Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function. Electronics. 2018; 7(12):432. https://doi.org/10.3390/electronics7120432
Chicago/Turabian StyleAbbas, Farukh, Donghan Feng, Salman Habib, Usama Rahman, Aazim Rasool, and Zheng Yan. 2018. "Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function" Electronics 7, no. 12: 432. https://doi.org/10.3390/electronics7120432
APA StyleAbbas, F., Feng, D., Habib, S., Rahman, U., Rasool, A., & Yan, Z. (2018). Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function. Electronics, 7(12), 432. https://doi.org/10.3390/electronics7120432