1. Introduction
Clustering is one of the data mining techniques that group data objects based on a similarity [
1]. The groups can provide important insights that are used for a broad range of applications [
2,
3,
4,
5,
6,
7,
8], such as superpixel segmentation for image clustering [
2,
3], brain cancer detection [
4], wireless sensor networks [
5,
6], pattern recognition [
7,
8], and others. We can classify clustering algorithms into centroid, hierarchy, model, graph, density, and grid-based clustering algorithms [
9]. Many algorithms address various clustering issues including scalability, noise handling, dealing with multi-dimensional datasets, the ability to discover clusters with arbitrary shapes, and the minimum dependency on domain knowledge for determining certain input parameters [
10].
Among clustering algorithms, density-based clustering algorithms can discover arbitrary shaped clusters and noise from datasets. Furthermore, density-based clustering algorithms do not require the number of clusters as an input parameter. Instead, clusters are defined as dense regions separated by sparse regions and are formed by growing due to the inter-connectivity between objects. Density-based spatial clustering of applications with noise (DBSCAN) [
11] is a well-known density-based clustering algorithm. To define dense regions which serve as clusters, DBSCAN requires two parameters:
, which represents the radius of the neighborhood of an observed object, and
, which is the minimum number of objects in the
-neighborhood of an observed object. Let
be a set of multi-dimensional objects and let the
-neighbors of an object
be
. Here, DBSCAN implements two rules:
An object is an -core object if ;
If is an -core object, all objects in should appear in the same cluster as .
The process of DBSCAN is simple. Firstly, an arbitrary
-core object
is added to an empty cluster. Secondly, a cluster grows as follows: for every
-core object
in the cluster, all objects of
are added to the cluster. This process is then repeated until the size of a cluster no longer increases. However, DBSCAN cannot easily select appropriate input parameters to form suitable clusters because the input parameters depend on prior knowledge, such as the distribution of objects and the ranges of datasets. Moreover, DBSCAN cannot find clusters of differing densities.
Figure 1 demonstrates this limitation of DBSCAN in a two-dimensional dataset
when
. If
,
is an
-core object and forms a cluster, which contains
,
,
, and
because
is satisfied. However,
and
are noise objects. Here, a noise object is an object that is not included in any cluster. In other words, a set of objects that cannot reach
-core objects in the clusters are defined as noise objects. On the other hand, if
,
becomes an
-core object and forms a cluster, which contains
, and
. However,
is still a noise object. As shown in the example in
Figure 1, input parameter selection in DBSCAN is problematic.
To address this disadvantage of DBSCAN, a method for ordering points to identify the clustering structure, called OPTICS [
12], was proposed. Like DBSCAN, OPTICS requires two input parameters,
, and
, and finds clusters of differing densities by creating a reachability plot. Here, the reachability plot represents an ordering of a dataset with respect to the density-based clustering structure. To create the reachability plot, OPTICS forms a linear order of objects where objects that are spatially closest become neighbors [
13].
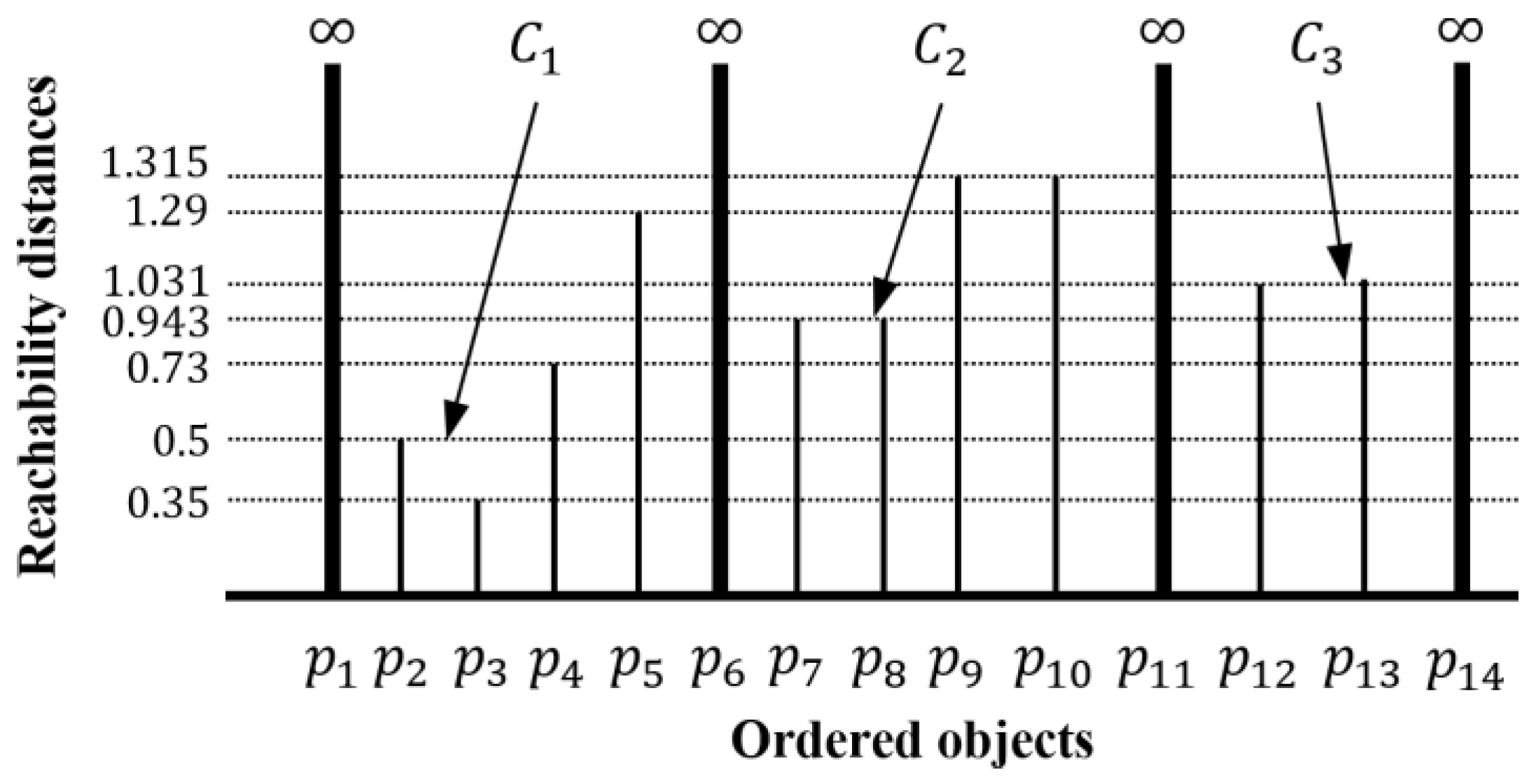
Figure 2 shows the reachability plot for a dataset
, when
and
. The horizontal axis of the reachability plot enumerates the objects in a linear order, while vertical bars display reachability distance (see Definition 2), which is the minimum distance for an object to be included in a cluster. The reachability distances for some objects (e.g.,
,
,
, and
) are infinite. In this case, an infinite reachability distance results when the distance to each object is undefined because the distance value is greater than given
. OPTICS does not provide clustering results explicitly, but the reachability plot shows the clusters for
. For example, when
, a first cluster
containing
,
, and
is found. When
, second cluster
, which contains
,
, and
is found. As
grows larger, clusters
and
continue to expand, and a third cluster
containing
,
, and
is found.
As demonstrated in
Figure 2, OPTICS addresses the limitations of input parameter selection for DBSCAN. However, OPTICS requires distance computations for all pairs of objects to create a reachability plot. In other words, OPTICS first computes an
-neighborhood for each object to identify
-core objects, and then, computes reachability distances at which
-core objects are reached from all other objects. Thus, OPTICS is computed in
time, where
is the number of objects in a dataset [
14]. Therefore, OPTICS is unsuitable for massive datasets. Prior studies have proposed many algorithms to address the running time of OPTICS, such as DeLi-Clu [
15] and SOPTICS [
16]. These algorithms improve the running time of OPTICS, but have their own limitations such as dependence on the number of dimensions, and deformation of the reachability plot.
This paper focuses on improving OPTICS by addressing its quadratic time complexity problem. To do this, we propose a fast algorithm, called constrained OPTICS (simply, C-OPTICS). C-OPTICS uses a novel bi-directional graph structure, called the constraint graph, which consists of the vertices corresponding to each cell that partitions a given dataset. In the constraint graph, the vertices are linked by means of edges when the distance between vertices is less than an . The constraints are assigned as the weight of each edge. The main feature of C-OPTICS is that it only computes the reachability distances of the objects that satisfy the constraints, which results in a reduction of unnecessary distance computations when creating a reachability plot. We evaluated the performance of C-OPTICS through experiments with the OPTICS, DeLi-Clu, and SOPTICS algorithms. The experimental results show that C-OPTICS significantly reduces the running time compared with OPTICS, DeLi-Clu, and SOPTICS algorithms and guarantees the reachability plot identical to those by of OPTICS.
The rest of the paper is organized as follows:
Section 2 provides an overview of OPTICS, including its limitations, and describes related studies that have been performed to improve OPTICS.
Section 3 defines the concepts of C-OPTICS and describes the algorithm.
Section 4 presents an evaluation of C-OPTICS based on the results of experiments with synthetic and real datasets.
Section 5 summarizes and concludes the paper.
3. Constrained OPTICS (C-OPTICS)
3.1. Overview
We now explain the proposed algorithm, called C-OPTICS. The goal of the C-OPTICS is to reduce the total number of distance computations required to create a reachability plot because they affect the running time of OPTICS, as explained in
Section 2.1.2. To achieve this goal, C-OPTICS proceeds in three steps: (a) partitioning step, (b) graph construction step, and (c) plotting step. For the convenience of the explanation,
Figure 4 shows the process of the C-OPTICS for the two-dimensional dataset
in
Figure 1. In the partitioning step, we partition
into identical cells.
Figure 4a shows the result of partitioning, where empty cells are discarded. In the graph construction step, as shown in
Figure 4b, we construct a constraint graph that consists of vertices corresponding to the cells obtained in the partitioning step and edges linking vertices by constraints. In the plotting step, we compute the reachability distance of each object while traversing the constraint graph.
Figure 4c shows the reachability distance and linear order of each object.
C-OPTICS can obtain
-neighbors by finding adjacent cells for an arbitrary object. Thus, C-OPTICS can reduce the number of distance computations to find
-core objects. Besides, C-OPTICS only computes the reachability distances of the objects that satisfy the constraints in the constraint graph. Consequently, C-OPTICS reduce the total number of distance computations required to create a reachability plot. We explain in detail the partitioning step in
Section 3.2, the graph construction step in
Section 3.3, and the plotting step in
Section 3.4.
3.2. Partitioning Step
This subsection describes the data partitioning step for C-OPTICS. We partition a given dataset into cells of identical size with a diagonal length . Definition 3 explains the unit cell of the partitioning step.
Definition 3 (Unit cell,). We defineas a-dimensional hypercube with a diagonal lengthand straight sides, all of equal length.is a square with a diagonal lengthin two dimensions, and in three dimensionsis a cube with a diagonal length.
Here, all s have two main features. First, each has a unique identifier that is used as the location information in the dataset. We use the coordinates values of a to obtain a unique identifier. Here, the coordinates value of a represents a sequence of for each dimension in the dataset. Thus, combining the coordinates values of for all dimensions enables us to obtain the location information from a unique identifier. The location information can quickly find adjacent s within a radius for an arbitrary . Through partitioning step, we can reduce the number of distance computations in finding -neighbors of each object because the number of objects in each cell within a radius is smaller than in the entire dataset. We can further simplify the process of constructing a constraint graph in a later step. Second, each has a -dimensional minimum bounding rectangle () that encloses the contained objects. We use s to compute the distance between s to find adjacent s. We obtain all coordinates of based on the maximum and minimum values of each dimension for the contained objects. If the contains only one object, the object becomes an .
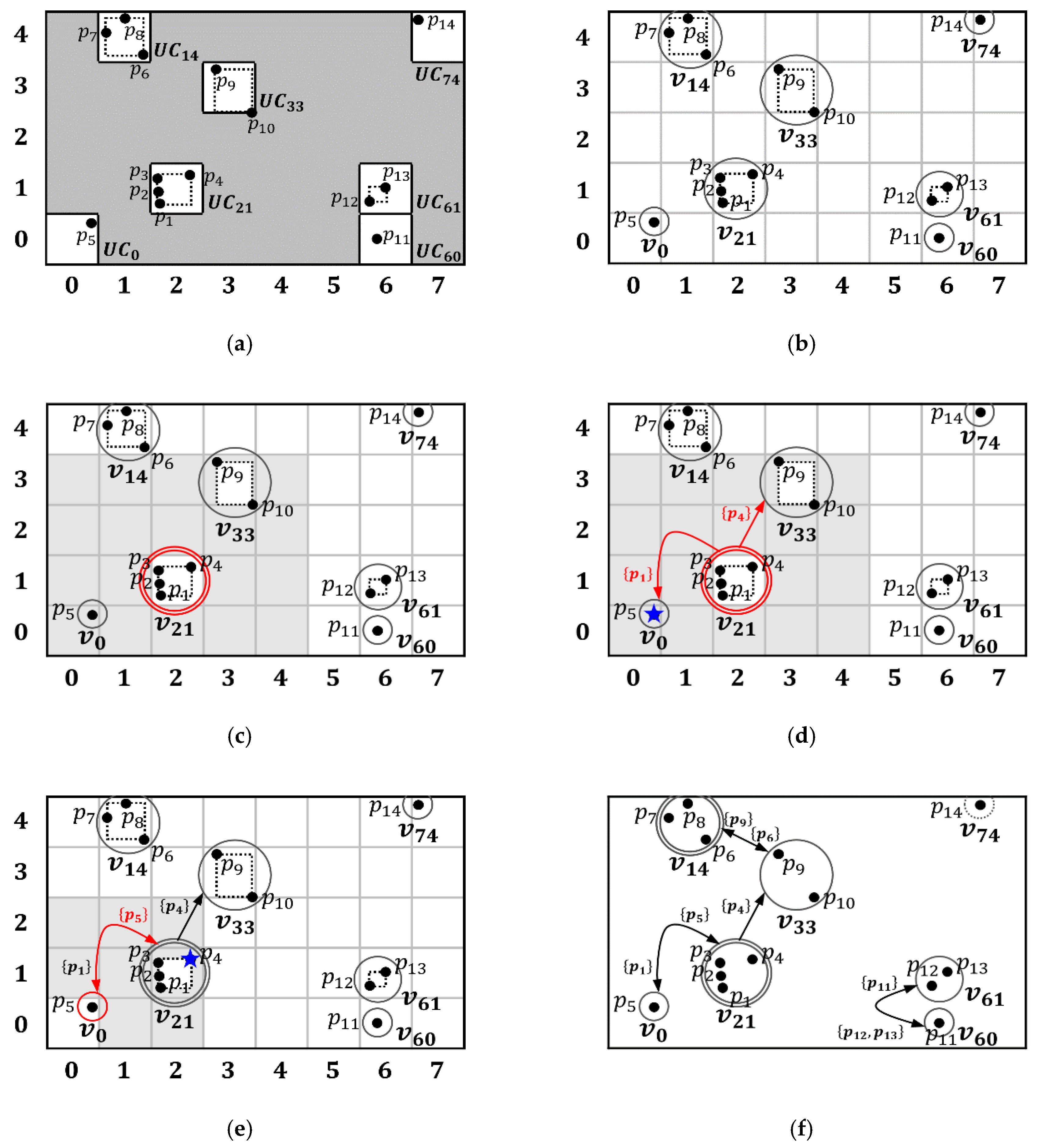
Example 1. Figure 5 shows an example of the partitioning step for the sample datasetwhen.
Figure 5a shows each objectin a two-dimensional universe.Figure 5b shows the partitioning ofintos, where each UC has the same diagonal length.Figure 5c shows empty and non-emptys. Note that we do not consider emptys. Further, we obtain the unique identifier of eachas follows. To compute the unique identifier of, we first obtain the coordinate values ofin each dimension. As shown inFigure 5c, the coordinate values ofare (2,1) in the first and second dimensions, respectively. Considering that a unique identifier ofis obtained by the combination of the coordinate values, the unique identifier ofis 21. The result of partitioning is shown inFigure 5d, whereis partitioned into sevens, with eachhaving a.
3.3. Graph Construction Step
In the graph construction step, we construct a constraint graph with the s obtained in the data partitioning step. Through constructing a constraint graph, we can reduce the number of distance computations to obtain the minimum reachability distance for each object. For this, we first use the s obtained in the data partitioning step as the vertices of the constraint graph. Here, a unique identifier of each is used as a unique identifier of each vertex. Thus, we can quickly find adjacent vertices because we preserve the location information of for each vertex. Additionally, we also preserve the of each . Then, we connect the vertices to define the edges. Here, we connect the vertices according to two properties: (i) the two vertices must be adjacent to each other within a radius , and (ii) an edge between two vertices must have constraints. Considering that we can quickly find the -neighborhood of each object in the dataset by the first property, we can obtain the objects that are within a radius . Thus, there is no need to compute distances with all objects. We first explain the maximum reachability distance, which is defined as Definition 4.
Definition 4 (Maximum reachability distance,). We defineas the range of a radiusat which a vertex can reach. Here, the unique identifier of a vertex is the combination of coordinate values. Thus, in-dimension,representsrange for a coordinate value of each dimension because a radiusistimes the length of a straight side ofthat corresponds to the vertex.
Figure 6 shows an example of the
for a vertex,
, in two-dimensional space. We can decompose the unique identifier of
into two coordinates values, which are (3, 3). Considering that the MRD of a vertex in the two-dimensional dataset represents a range of +2 and −2 in coordinate values of each dimension, according to Definition 4, the reachable range of each dimension is 1 to 5 in the first dimension and 1 to 5 in the second dimension. As a result, the
of
is equal to the gray area shown in
Figure 6. Through the calculation of MRD, we can find adjacent vertices within the same range and thus, avoid unnecessary calculations of distances between all vertices. In
Figure 6, adjacent vertices
and
are in the
of
.
Additionally, we use the
of each vertex to compute the distance between two vertices. We can obtain the adjacent vertices more accurately by computing the distance between the two vertices. Here, adjacent vertices obtained from
of an arbitrary vertex may not actually be vertices within a radius
because the range of
and the range of
do not precisely match. Thus, we compute the minimum distance between the
s of two vertices to find adjacent vertices within the radius
. Equation (3) represents the distance between two vertices.
where
is the distance between
and
.
is the
of a unit cell
corresponding to
. Here, if
,
is the adjacent vertex of
and vice versa.
Next, we define the constraints to link vertices that satisfy the second property. Recall from
Section 1 that the constraint graph only links vertices when the distance between vertices is less than an ε. These pairs of vertices become edges, and the constraints are assigned as weights for each edge. Here, the constraint is defined as a subset of
-core objects that can compute the minimum reachability distances of objects in different vertices. In the plotting step, we only compute the reachability distances of the objects that satisfy the constraints and thus, reduce unnecessary distance computations. Here, a constraint is satisfied if the observed object belongs to a subset of
-core objects as designated by the constraint. We first explain the linkage constraints defined as Definition 5 to obtain the
-core objects corresponding to the constraints.
Definition 5. (Linkage constraint,) For two verticesand, let an-core object inbeand let theof a vertexbe. We define the linkage constraint fromtoas a subset of-core objects in. Here, whenis an-core objectclosest to theandis the coordinates offarthest from, the-core objectsshould be closer tothan they are to.
We link two vertices when the linkage constraint between the vertices is defined according to Definition 5. Thus, we can reduce unnecessary distance computations by pruning the adjacent vertices obtained in the first property again. Furthermore, the linkage constraints guarantee the quality of the reachability plot while reducing the number of distance computations. We prove this in Lemma 1.
Lemma 1. Let the linkage constraint fromtobeforin the constraint graph. If, the minimum reachability distances for all objects contained inare determined by thepair and the core distance. In other words, the reachability distances of all objects inare determined by-core objects in.
Proof. For a given dataset , let , and let the linkage constraint from to . In this case, the reachability distance of an object is determined by when . Conversely, cannot determine the reachability distance of because holds in all cases even when . Therefore, Lemma 1 is obviously true. □
Additionally, we define the state of a vertex. We can find
-core objects in the dataset without computing the distance between the objects through the states of vertices. We define the state of a vertex based on the rules of DBSCAN, and from the
s obtained in the data partitioning step. As described in
Section 1, if the number of objects contained in the
-neighborhood for an arbitrary object is greater than or equal to
, then the object is an
-core object. Here, because the diagonal length of
is
, the objects must be
-core objects when the number of objects contained in
is greater than or equal to
. Accordingly, we define three states for each vertex:
,
, and
. More precisely, the state of a vertex is defined as follows:
Definition 6. (The state of a vertex,) Let a set of adjacent vertices contained inofbeand an adjacent vertex be. The state of, which can determine whether to compute the distance of contained objects, satisfies the following conditions:
- 1.
Letbe the number of data points contained in. If,is;
- 2.
If condition 1 is not satisfied and,is;
- 3.
If both conditions 1 and 2 are not satisfied,is.
Again, we denote that objects contained in the same vertex must be -neighbor for each other. Thus, when the of a vertex is , all objects contained in are -core objects, because the of all objects is always greater than or equal to . Conversely, if the of is , all objects contained in are noise objects and are not considered anymore.
Example 2. Figure 7 shows the step-by-step constructing process of the constraint graphwhenandfor the sample dataset, using an identical dataset to that shown in Figure 5. The example starts with a partitioned dataset,, as shown in Figure 7a. First, as shown in Figure 7b, eachis mapped into the vertices of, and the unique identifier of eachis used as the unique identifier of the vertex. Second, a vertex is selected by the input sequence of objects. In our case, a vertexcontainingis selected as shown in Figure 7c. To find the adjacent vertices for, theof(i.e., gray area) is computed using Definition 4. Here, two verticesandare found as adjacent vertices of. Next, the state of,, is obtained according to Definition 6. Here, all objects inare-core objects henceisand depicted in a doubled circle. Third, as shown in Figure 7d, linkage constraints forandare obtained using Definition 5. For example, let theof a vertexbe. We first obtain the-core objects of, but we can skip this step becauseis. Next, an-core object ofclosest to,, is obtained. Becausecontains only one object, the coordinate offarthest fromis(blue star). Thus,contains onlybecause no-core object is closer tothan. Then, because the constraint betweenandis defined, the two vertices are linked by.
Figure 7e shows the linkage constraintand state of. Thecontains only one object. Thus,is(circle) due to the adjacent vertexthat contains four objects.containsand thusbecomes bidirectional. On the other hand,contains only one object and has no adjacent vertex. Thus, the state ofisand is depicted as a dotted circle. When all vertices are processed, constraint graph is constructed, as shown in Figure 7f. 3.4. Plotting Step
In the plotting step, we traverse the constraint graph to generate a reachability plot as in OPTICS. Recall from
Section 2.1.2 that OPTICS computes reachability distances for all pairs of objects to create a reachability plot. However, to create a reachability plot, only one reachability distance is required for each object. Through the constraint graph, we can reduce the reachability distance computations that do not contribute to generating the reachability plot. Here, the constraint graph identifies the reachability distance of each object required for the reachability plot by the linkage constraint. Thus, we reduce the unnecessary distance computations by only computing the distance between objects contained in the vertices which are linked to each other. We can further reduce the unnecessary distance computations by only computing the reachability distance for objects that satisfy the linkage constraints between the linked vertices. To plot a reachability plot, we traverse the constraint graph with the following rules: (i) if two objects are contained in the same vertex, the distance is computed; (ii) if two objects are contained in different vertices, only objects that satisfy the linkage constraint between two vertices are computed; (iii) the object with the closest reachability distance to the target object becomes the next target object; (iv) if no object is reachable, the next target object is selected by the input order of objects. For clarity, we provide the pseudocode, which will be referred to as the C-OPTICS procedure.
| Algorithm 1: C-OPTICS |
Input:
(1) : the input dataset
(2) : the constraint graph for |
Output:
(1) : a reachability plot |
| Algorithm: |
Initialize the list and the priority queue . foreachdo if then . Put into . .get Vertex(). if .iscore() then Update . while do .next(). . Put into . .get Vertex(). If .iscore() then Update. end
|
Algorithm 1 shows the C-OPTICS procedure that creates a reachability plot by traversing the constraint graph and plotting the reachability distance of each object. The inputs for C-OPTICS are the dataset and the constraint graph . The output of C-OPTICS is the reachability plot . In line 1, , a list structure representing the reachability plot, and , a priority queue structure, are initialized. Here, determines the order in which to traverse the constraint graph. In line 2, a target object is selected by the input order of objects. In line 3, the algorithm checks whether the target object has been processed. If is not processed, is set to the processed state in line 4. Then, is inputted to with reachability distance (infinite). In line 6, the vertex , which contains , is obtained. If is a , in line 7, is determined to be a noise object and the algorithm selects the next target object. If is not a , is checked as to whether is an -core object. If is not an -core object, is determined to be a noise object. In the opposite case, in line 8, the Update procedure is called to discover , after which is updated. In lines 9–14, repeated processes are performed on . The object with the highest priority in is selected as the next target object in line 10. Then, is set to the processed state in line 11. Next, in line 12, is inputted to with the computed reachability distance. Then, a vertex , which contains , is obtained. In lines 13 and 14, is updated by the Update procedure when is not and is an -core object. This process is repeated until is empty. When is empty, the unprocessed object is selected as the next target object . Thereafter, all of the above processes are repeated. When all objects are processed, is output. Here, listing the objects in results in a reachability plot.
Algorithm 2 shows the Update procedure that determines whether is updated according to the state of each vertex and linkage constraints. The inputs for the Update are the object , vertex containing , and priority queue . The output of Update is . In line 1, of is obtained. In line 2, an object is selected. In line 3, the processing state of is checked. When is processed, a new object is selected; otherwise, in line 4, a vertex containing is obtained. In line 5, is checked for whether it satisfies the linkage constraint . If satisfies , the reachability distance of to is computed and is updated. In the opposite case, the reachability distance of is not computed and thus is not updated.
| Algorithm 2: Update |
Input:
(1) : a target object of dataset
(2) : a target vertex of constraint graph
(3) : a priority queue
Output:
(4) : a priority queue |
| Algorithm: |
.getNeighbors(, ) foreachdo if then .get Vertex(). if .con() then . .update. end
|
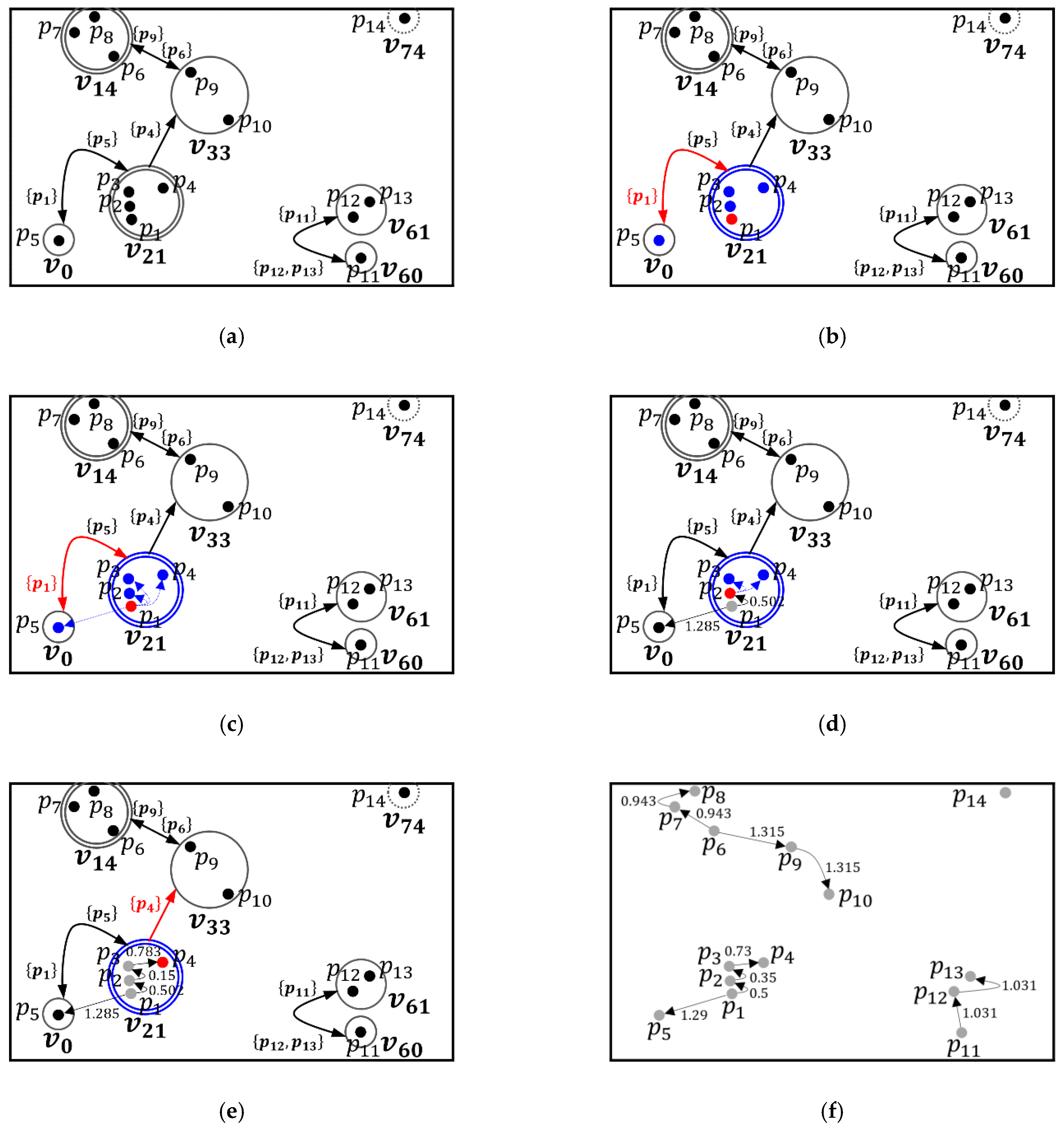
Example 3. Figure 8 shows the step-by-step clustering process of the plotting step for the sample dataset. Here, this example assumes thatand, and a constraint graphis created, as shown inFigure 8a. First, a target objectis selected by the input sequence of objects. Thus,is selected (red dot), as shown inFigure 8b. Second, a vertexcontainingis obtained (blue circle) and the-neighborhood of,, is obtained (blue dots). Becauseis satisfied,contained in a vertexis also a neighbor of. Conversely, becauseis not satisfied, two objectsandcontained in a vertexare not neighbors of.
Third, as shown in Figure 8c, the reachability distance of each object, which is contained in, is computed foraccording to Definition 2. Fourth, an objecthaving the closest reachability distance tois selected as the next target object as shown in Figure 8d (red dot). Then, the above process is repeated for. Note that only objects contained inare considered because no linkage constraint is satisfied. Figure 8e shows the process for. Wheresatisfies, however, two objectsandare not neighbors ofbecauseandare greater than. Thus, the next target object is not selected. In this case, the next target object is selected by the input order of objects which are not processed. The above process is repeated for all unprocessed objects, creating a unidirectional graph structure that represents the reachability plot, as shown in Figure 8f. 5. Conclusions
In this paper, we proposed C-OPTICS, which improves the running time of OPTICS by reducing the unnecessary distance computations to address the quadratic time complexity issue of OPTICS. C-OPTICS partitions a -dimensional dataset into unit cells which have identical diagonal length and constructs a constraint graph. Subsequently, C-OPTICS only computes the reachability distance for each object that appears in the reachability plot through linkage constraints in the constraint graph.
We conducted experiments on synthetic and real datasets to confirm the scalability and efficiency of C-OPTICS. Specifically, C-OPTICS outperformed state-of-the-art algorithms. Experimental results show that C-OPTICS addressed the quadratic time complexity of OPTICS. Specifically, the running time with regard to the data size is improved by as much as 102 times over DeLi-Clu. In addition, the running time is improved up to nine times over SOPTICS, which creates an approximate reachability plot. We also conducted experiments on dimensionality. These experimental results show that C-OPTICS has robust clustering quality and linear time complexity regardless of the size of the dimensions.
Future research can consider methods by which the proposed algorithm can be improved. For example, C-OPTICS can be improved by having it construct a constraint graph without depending on a radius . This can provide a solution to the worst case of C-OPTICS. In addition, C-OPTICS can be improved to enable GPU-based parallel processing to accelerate the construction of the constraint graph.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}