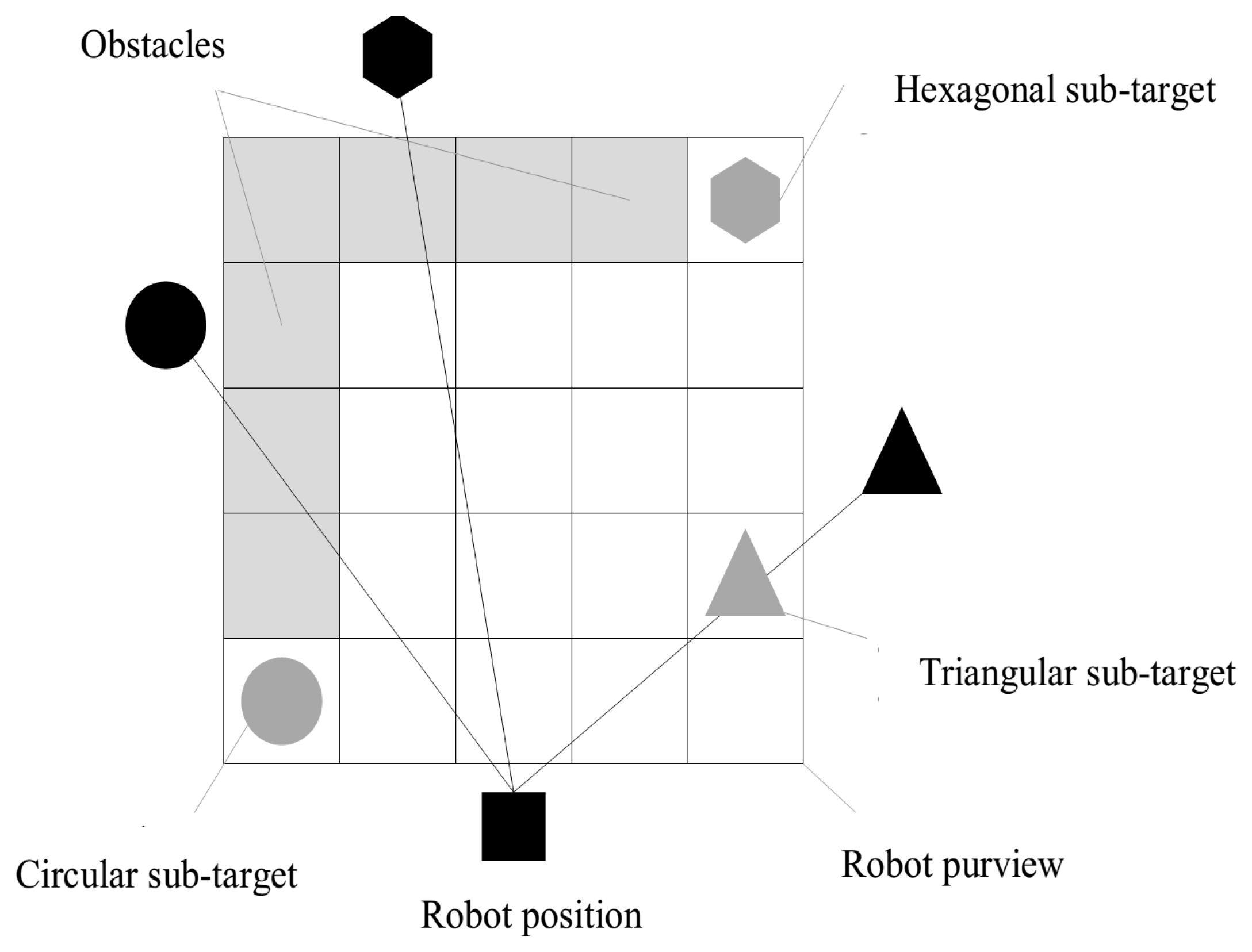
Robot Motion Planning in an Unknown Environment with Danger Space

 , ,
, ,
Abstract
:1. Introduction
2. Robot Path Planning Using Vision Sensors
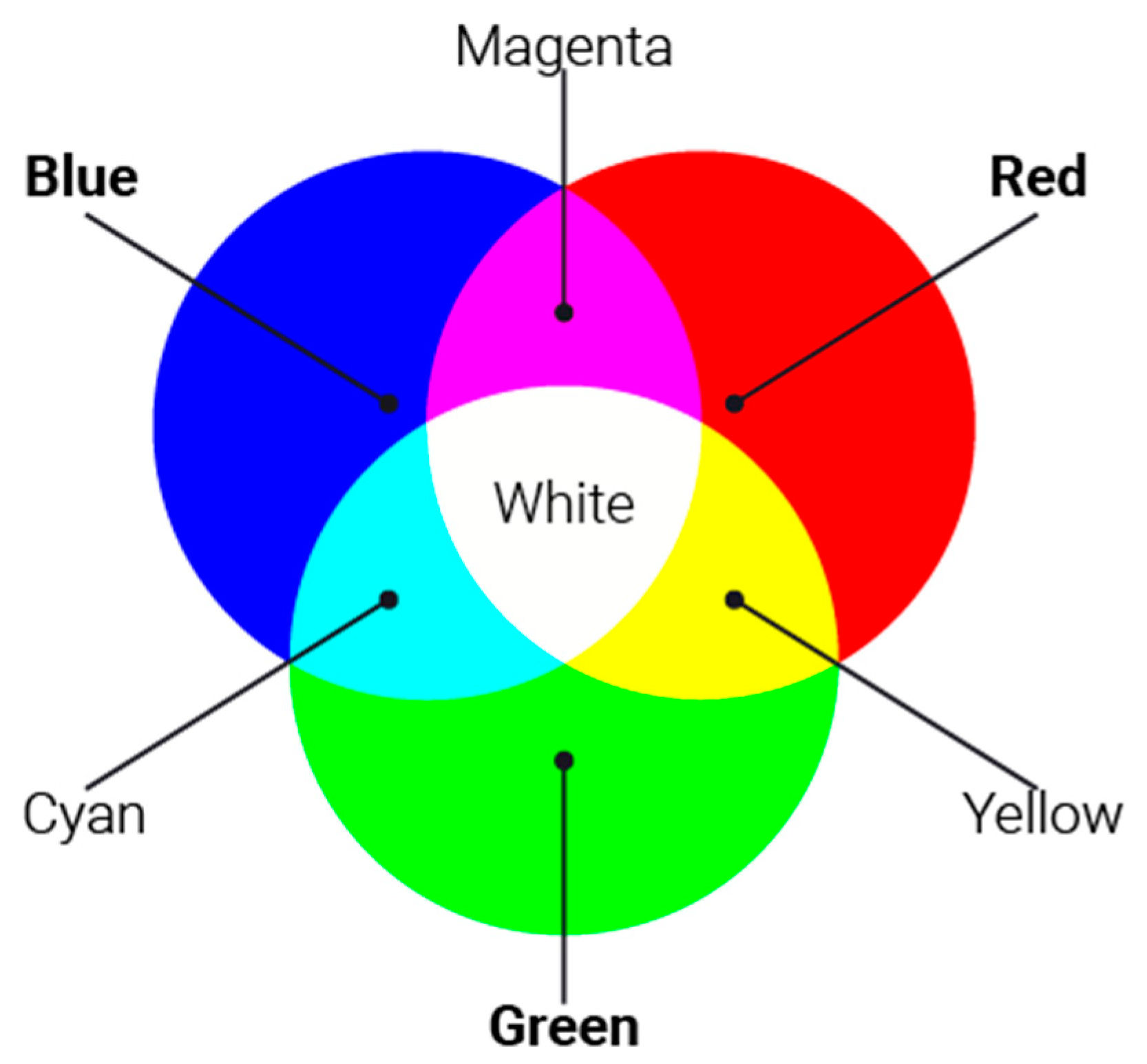
2.1. The Color Models
2.2. Low-Pass Filter
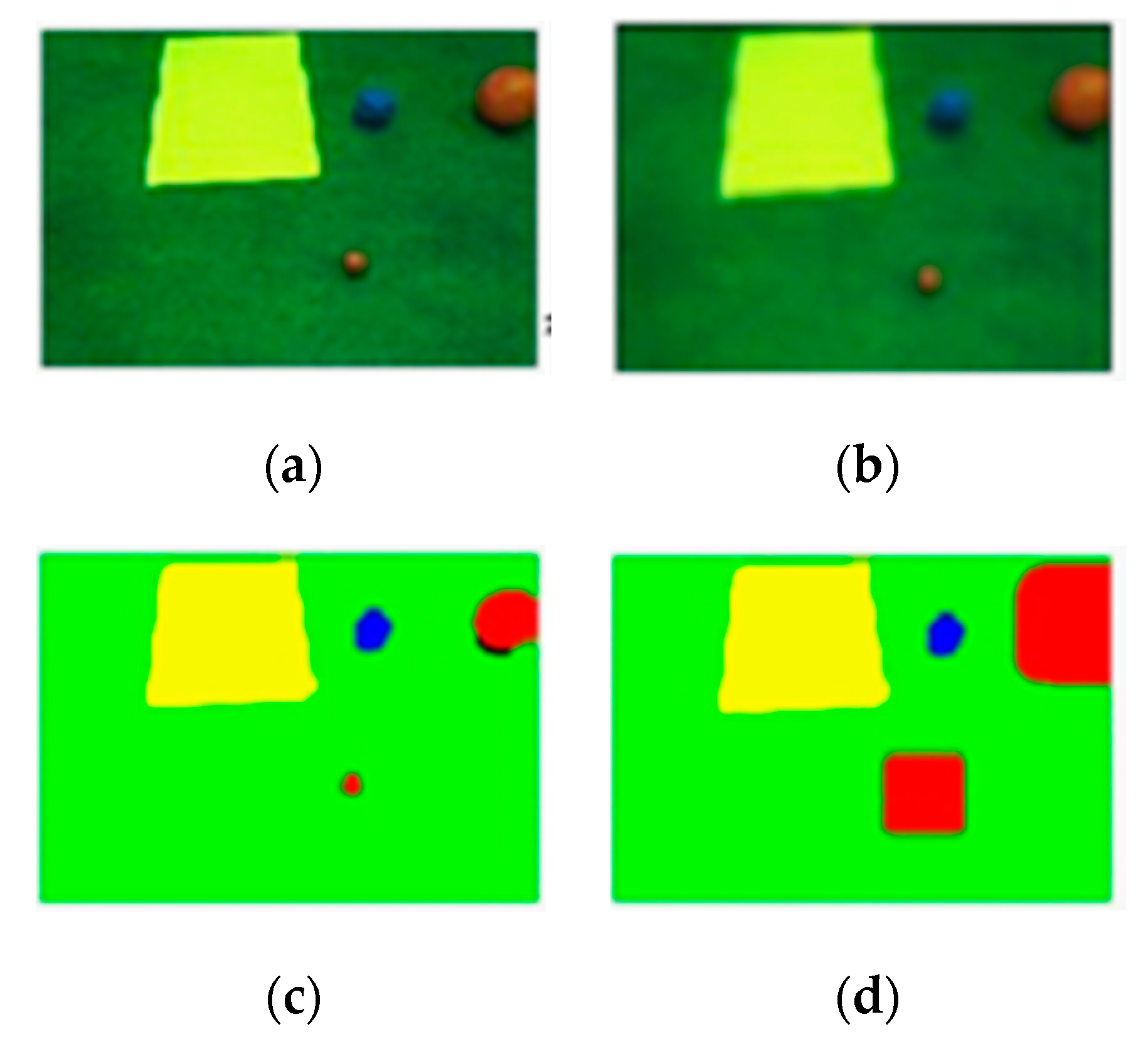
2.3. Segmentation and Mode Filter
2.4. Expansion
2.5. Schematic Structure of Vision System
3. Path Planning in the Absence of Danger Space
3.1. Synthetic Potential Field Method
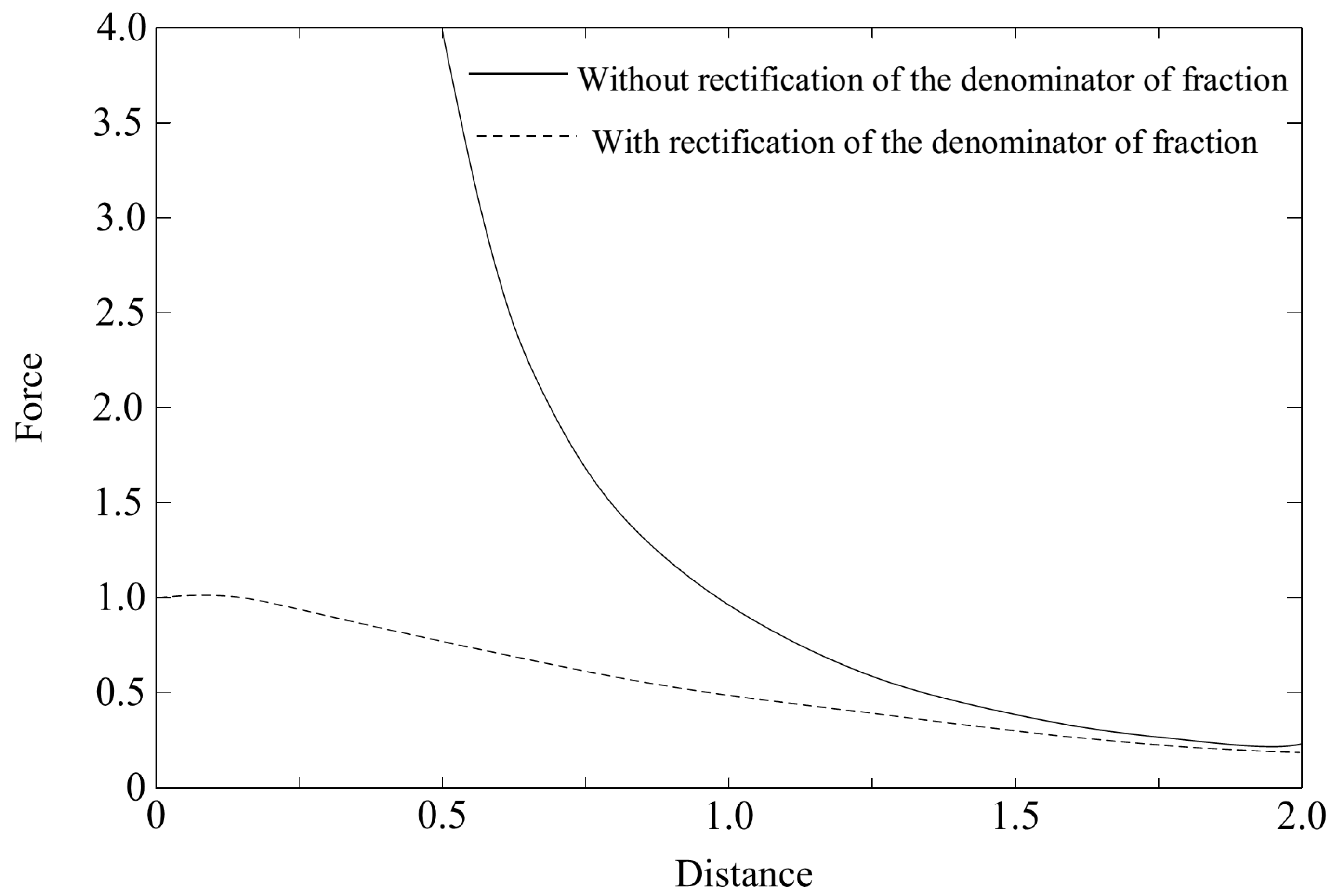
3.1.1. The Rectifier
3.1.2. Result of Synthetic Potential Field Method
3.2. Linguistic Method
3.2.1. Simplification
3.2.2. Result of Linguistic Method
3.3. Markov Decision Processes
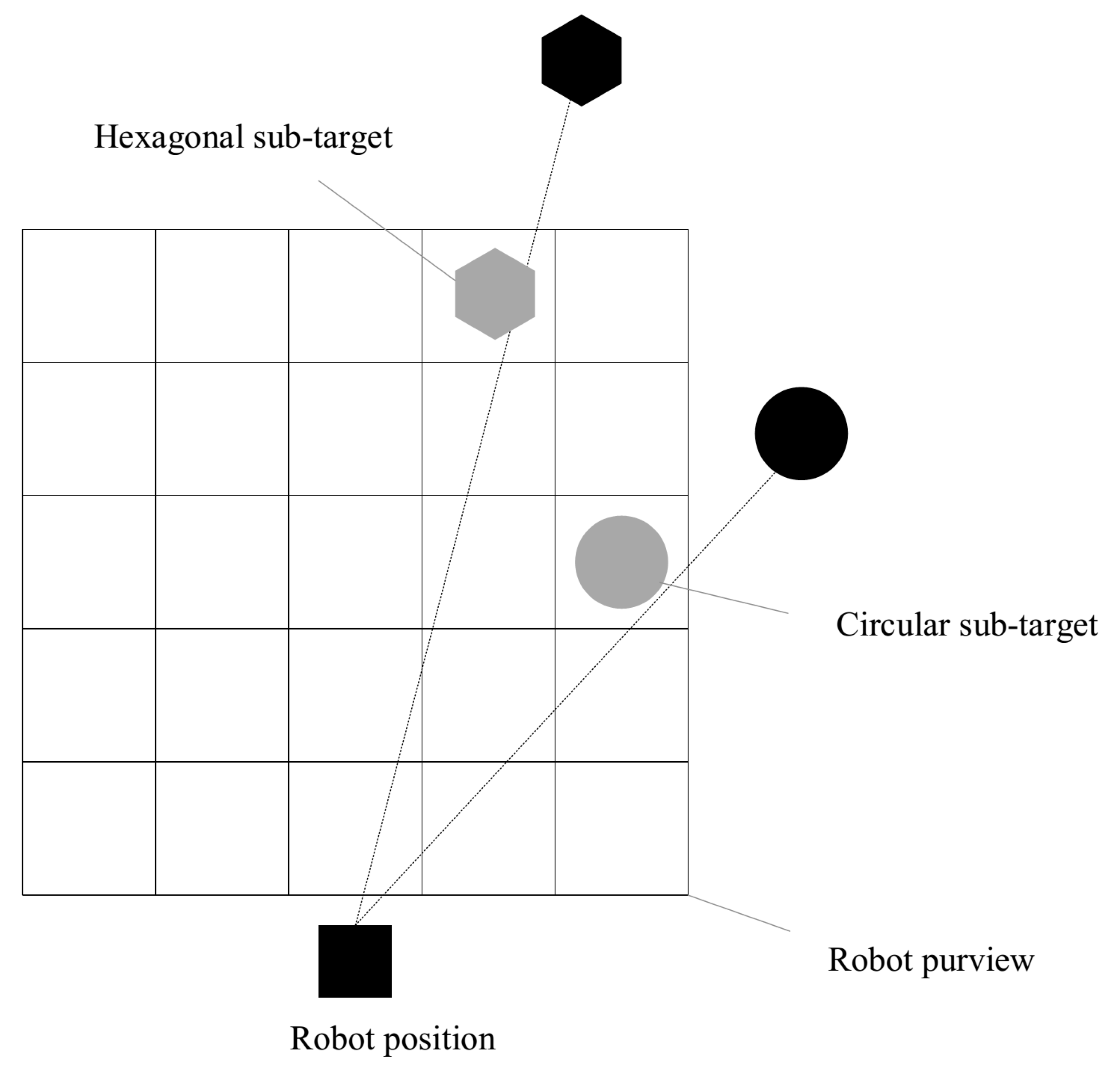
3.3.1. Path Planning
| Algorithm 1 Optimal value function. |
| Input: Reward function R(s) Output: Value function V(s) Begin for all the s do end |
3.3.2. Results of Markov Decision Processes
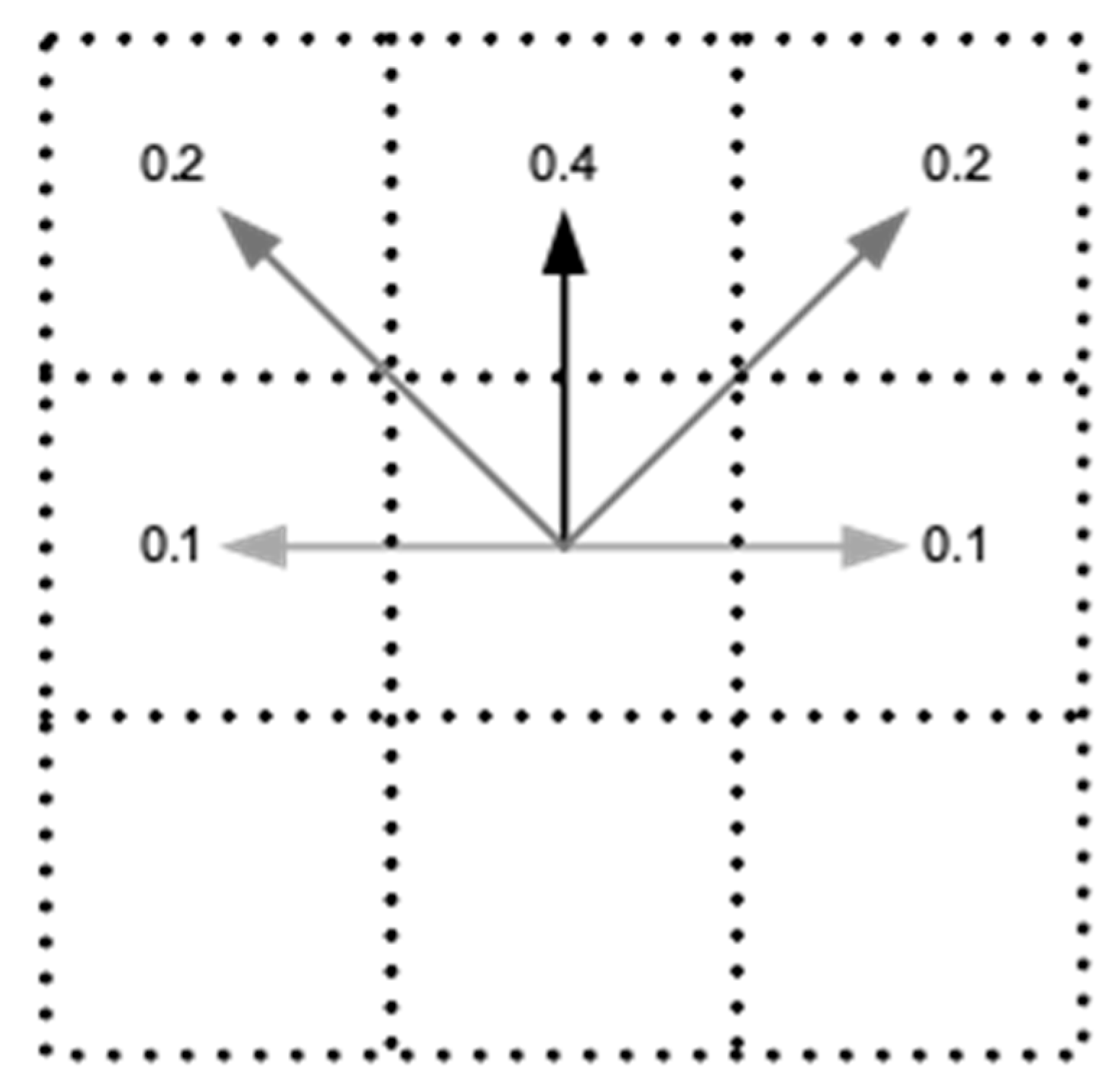
3.4. Fuzzy Markov Decision Processes
- If A1=1, then ϕ is a very small positive angle.
- If A2 = 1, then ϕ is zero.
- If A3 = 1, then ϕ is a very small negative angle.
- If A4 = 1, then ϕ is a medium positive angle.
- If A5 = 1, then ϕ is a small positive angle.
- If A6 = 1, then ϕ is a zero angle.
- If A7 = 1, then ϕ is a small negative angle.
- If A8 = 1, then ϕ is a medium negative angle.
- If A9 = 1, then ϕ is a big positive angle.
- If A10 = 1, then ϕ is a medium positive angle.
- If A11 = 1, then ϕ is a zero angle.
- If A12 = 1, then ϕ is a medium negative angle.
- If A13 = 1, then ϕ is a big negative angle.
Result of Fuzzy Markov Decision Processes in the Absence of Danger Space.
4. Path Planning in the Presence of Danger Space
4.1. Disadvantages of Reward Calculation by Linear Relations
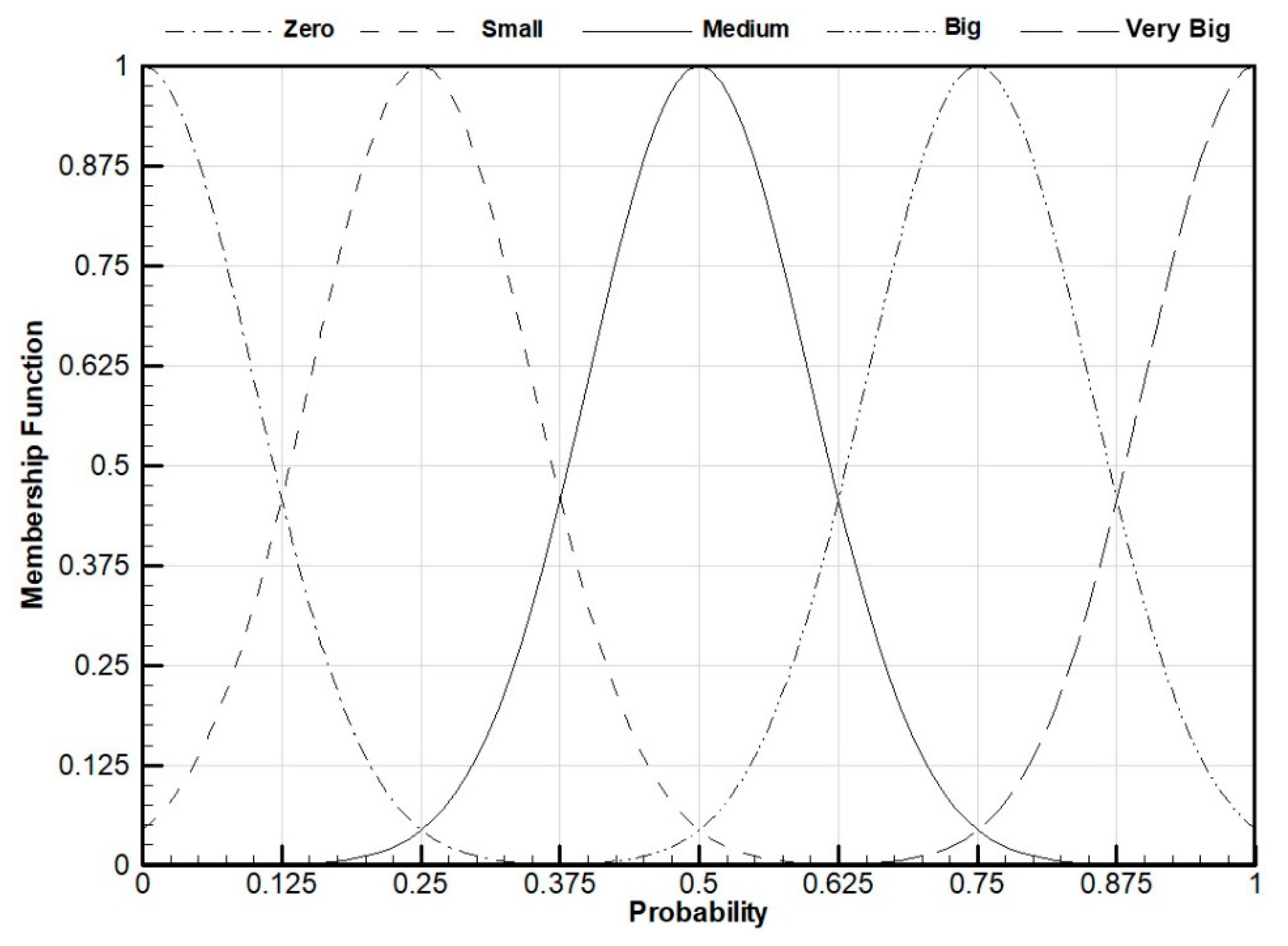
4.2. Reward Calculation by the Fuzzy Inference System
4.3. Schematic Structure of Fuzzy Markov Decision Processes
4.4. Results of Fuzzy Markov Decision Processes in the Presence of Danger Space
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lumelsky, V.J.; Skewis, T. Incorporating range sensing in the robot navigation function. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1990, 20, 1058–1069. [Google Scholar] [CrossRef]
- Taylor, K.; LaValle, S.M. I-Bug: An intensity-based bug algorithm. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 2009; pp. 3981–3986. [Google Scholar]
- Buniyamin, N.; Ngah, W.W.; Sariff, N.; Mohamad, Z. A simple local path planning algorithm for autonomous mobile robots. Int. J. Syst. Appl. Eng. Dev. 2011, 5, 151–159. [Google Scholar]
- Guruprasad, K.R. EgressBug: A real time path planning algorithm for a mobile robot in an unknown environment. In Advanced Computing, Networking and Security; Springer: Berlin, Germany, 2011; pp. 228–236. [Google Scholar]
- Xu, Q.-L.; Tang, G.-Y. Vectorization path planning for autonomous mobile agent in unknown environment. Neural Comput. Appl. 2013, 23, 2129–2135. [Google Scholar] [CrossRef]
- Hernandez, E.; Carreras, M.; Ridao, P. A comparison of homotopic path planning algorithms for robotic applications. Rob. Autom. Syst. 2015, 64, 44–58. [Google Scholar] [CrossRef]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A Review of Motion Planning Techniques for Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1135–1145. [Google Scholar] [CrossRef]
- Ravankar, A.; Ravankar, A.; Kobayashi, Y.; Hoshino, Y.; Peng, C.-C. Path smoothing techniques in robot navigation: State-of-the-art, current and future challenges. Sensors 2018, 18, 3170. [Google Scholar] [CrossRef]
- Sarkar, B.; Guchhait, R.; Sarkar, M.; Pareek, S.; Kim, N. Impact of safety factors and setup time reduction in a two-echelon supply chain management. Rob. Comput. Integr. Manuf. 2019, 55, 250–258. [Google Scholar] [CrossRef]
- Song, R.; Liu, Y.; Bucknall, R. Smoothed A* algorithm for practical unmanned surface vehicle path planning. Appl. Ocean Res. 2019, 83, 9–20. [Google Scholar] [CrossRef]
- Fu, B.; Chen, L.; Zhou, Y.; Zheng, D.; Wei, Z.; Dai, J.; Pan, H. An improved A* algorithm for the industrial robot path planning with high success rate and short length. Rob. Autom. Syst. 2018, 106, 26–37. [Google Scholar] [CrossRef]
- Foux, G.; Heymann, M.; Bruckstein, A. Two-dimensional robot navigation among unknown stationary polygonal obstacles. IEEE Trans. Rob. Autom. 1993, 9, 96–102. [Google Scholar] [CrossRef]
- Choset, H.M.; Hutchinson, S.; Lynch, K.M.; Kantor, G.; Burgard, W.; Kavraki, L.E.; Thrun, S. Principles of Robot Motion: Theory, Algorithms, and Implementation; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Jarris, R.A. Collission-free trajectory planning using distance transforms. Mech. Eng. Trans. IE Aust. 1985, 10, 187. [Google Scholar]
- Sudhakara, P.; Ganapathy, V.; Priyadharshini, B.; Sundaran, K. Obstacle Avoidance and Navigation Planning of a Wheeled Mobile Robot using Amended Artificial Potential Field Method. Procedia Comput. Sci. 2018, 133, 998–1004. [Google Scholar] [CrossRef]
- Moreau, J.; Melchior, P.; Victor, S.; Aioun, F.; Guillemard, F. Path planning with fractional potential fields for autonomous vehicles. IFAC-PapersOnLine 2017, 50, 14533–14538. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, J.; Zhu, Z.; Yang, D.; Wu, J. Tangent navigated robot path planning strategy using particle swarm optimized artificial potential field. Optik-Int. J. Light Electron. Opt. 2018, 158, 639–651. [Google Scholar] [CrossRef]
- Matoui, F.; Boussaid, B.; Metoui, B.; Frej, G.B.; Abdelkrim, M.N. Path planning of a group of robots with potential field approach: Decentralized architecture. IFAC-PapersOnLine 2017, 50, 11473–11478. [Google Scholar] [CrossRef]
- Bayat, F.; Najafinia, S.; Aliyari, M. Mobile robots path planning: Electrostatic potential field approach. Expert Syst. Appl. 2018, 100, 68–78. [Google Scholar] [CrossRef]
- Larsen, L.; Kim, J.; Kupke, M.; Schuster, A. Automatic Path Planning of Industrial Robots Comparing Sampling-Based and Computational Intelligence Methods. Procedia Manuf. 2017, 11, 241–248. [Google Scholar] [CrossRef]
- Abdelwahed, M.F.; Saleh, M.; Mohamed, A.E. Speeding up single-query sampling-based algorithms using case-based reasoning. Expert Syst. Appl. 2018, 114, 524–531. [Google Scholar] [CrossRef]
- Perez-Lozano, T. Spatial planning: A configuration space approach. In Autonomous Robot Vehicles; Springer: New York, NY, USA, 1990. [Google Scholar]
- Schwartz, J.T.; Yap, C.-K. Algorithmic and Geometric Aspects of Robotics (Routledge Revivals); Routledge: British, UK, 2016. [Google Scholar]
- Schwartz, J.T.; Sharir, M. On the “piano movers” problem. II. General techniques for computing topological properties of real algebraic manifolds. Adv. Appl. Math. 1983, 4, 298–351. [Google Scholar] [CrossRef]
- Precup, R.-E.; Hellendoorn, H. A survey on industrial applications of fuzzy control. Comput. Ind. 2011, 62, 213–226. [Google Scholar] [CrossRef]
- Jafarzadeh, M.; Gans, N.; Tadesse, Y. Control of TCP muscles using Takagi–Sugeno–Kang fuzzy inference system. Mechatronics 2018, 53, 124–139. [Google Scholar] [CrossRef]
- Rajagopal, K.; Jahanshahi, H.; Varan, M.; Bayır, I.; Pham, V.-T.; Jafari, S.; Karthikeyan, A. A hyperchaotic memristor oscillator with fuzzy based chaos control and LQR based chaos synchronization. AEU Int. J. Electron. Commun. 2018, 94, 55–68. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Rajagopal, K.; Akgul, A.; Sari, N.N.; Namazi, H.; Jafari, S. Complete analysis and engineering applications of a megastable nonlinear oscillator. Int. J. Non Linear Mech. 2018, 107, 126–136. [Google Scholar] [CrossRef]
- Mahmoodabadi, M.J.; Jahanshahi, H. Multi-objective optimized fuzzy-PID controllers for fourth order nonlinear systems. Eng. Sci. Technol. Int. J. 2016, 19, 1084–1098. [Google Scholar] [CrossRef]
- Zavlangas, P.G.; Tzafestas, S.G.; Althoefer, K. Fuzzy obstacle avoidance and navigation for omnidirectional mobile robots. In Proceedings of the ESIT’2000, Aachen, Germany, 14–15 September 2000; pp. 375–382. [Google Scholar]
- Al Yahmedi, A.S.; Fatmi, M.A. Fuzzy logic based navigation of mobile robots. In Recent Advances in Mobile Robotics; IntechOpen: London, UK, 2011. [Google Scholar]
- Iancu, I.; Colhon, M.; Dupac, M. A Takagi-Sugeno type controller for mobile robot navigation. In Proceedings of the 4th WSEAS international conference on computational intelligence, man-machine systems and cybernetics, Miami, FL, USA, 17–19 November 2005; pp. 29–34. [Google Scholar]
- Michel, P.; Chestnutt, J.; Kuffner, J.; Kanade, T. Vision-guided humanoid footstep planning for dynamic environments. In Proceedings of the 5th IEEE-RAS International Conference on Humanoid Robots, Tsukuba, Japan, 5 December 2005; pp. 13–18. [Google Scholar]
- Nakhaei, A.; Lamiraux, F. Motion planning for humanoid robots in environments modeled by vision. In Proceedings of the 8th IEEE-RAS International Conference on Humanoid Robots, Daejeon, South Korea, 1–3 December 2008; pp. 197–204. [Google Scholar]
- Sabe, K.; Fukuchi, M.; Gutmann, J.S.; Ohashi, T.; Kawamoto, K.; Yoshigahara, T. Obstacle avoidance and path planning for humanoid robots using stereo vision. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; pp. 592–597. [Google Scholar]
- Michel, P.; Chestnutt, J.; Kagami, S.; Nishiwaki, K.; Kuffner, J.; Kanade, T. Online environment reconstruction for biped navigation. In Proceedings of the IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; pp. 3089–3094. [Google Scholar]
- Chestnutt, J.; Kuffner, J.; Nishiwaki, K.; Kagami, S. Planning biped navigation strategies in complex environments. In Proceedings of the IEEE International Conference on Humanoid Robotics, Taipei, Taiwan, 14–19 September 2003. [Google Scholar]
- Okada, K.; Inaba, M.; Inoue, H. Walking navigation system of humanoid robot using stereo vision based floor recognition and path planning with multi-layered body image. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 27–31 October 2003; pp. 2155–2160. [Google Scholar]
- Zhang, Y.; Gong, D.-W.; Zhang, J.-H. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013, 103, 172–185. [Google Scholar] [CrossRef]
- Purcaru, C.; Precup, R.-E.; Iercan, D.; Fedorovici, L.-O.; David, R.-C. Hybrid PSO-GSA robot path planning algorithm in static environments with danger zones. In Proceedings of the 17th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 11–13 October 2013; pp. 434–439. [Google Scholar]
- Zhang, H.-M.; Li, M.-L.; Yang, L. Safe Path Planning of Mobile Robot Based on Improved A* Algorithm in Complex Terrains. Algorithms 2018, 11, 44. [Google Scholar] [CrossRef]
- Cheng, D.K. Field and Wave Electromagnetics; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Fakoor, M.; Kosari, A.; Jafarzadeh, M. Revision on fuzzy artificial potential field for humanoid robot path planning in unknown environment. Int. J. Adv. Mechatron. Syst. 2015, 6, 174–183. [Google Scholar] [CrossRef]
- NAO-Construction. Available online: http://doc.aldebaran.com/2-1/family/robots/dimensions_robot.html (accessed on 17 August 2018).
- Bellman, R. A Markovian decision process. J. Math. Mechanics 1957, 679–684. [Google Scholar] [CrossRef]
- Kolobov, A. Planning with Markov decision processes: An AI perspective. Synth. Lect. Artif. Intell. Mach. Learn. 2012, 6, 1–210. [Google Scholar]
- Fakoor, M.; Kosari, A.; Jafarzadeh, M. Humanoid robot path planning with fuzzy Markov decision processes. J. Appl. Res. Technol. 2016, 14, 300–310. [Google Scholar] [CrossRef]
- Hu, Q.; Yue, W. Markov Decision Processes withTheir Applications; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Sheskin, T.J. Markov Chains and Decision Processes for Engineers and Managers; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Axis x | Axis y | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| i | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| j | |||||||||||
| 1 | VSN | VSN | Z | VSP | VSP | VSP | VSP | VSN | VSN | VSN | |
| 2 | VSN | VSN | Z | VSP | VSP | VSN | SN | SN | SN | VSN | |
| 3 | SP | SN | Z | SP | SP | SN | MN | MN | MN | SN | |
| 4 | MN | MN | Z | MP | MP | MN | BN | VBN | BN | MN | |
| 5 | BN | VBN | Z | VBP | BP | MN | VBN | VBN | VBN | MN | |
| Axis x | Axis y | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| i | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| j | |||||||||||
| 1 | VSP | VSP | Z | VSN | VSN | VSP | VSP | VSP | VSP | VSP | |
| 2 | VSP | VSP | Z | VSN | VSN | VSP | SP | SP | SP | VSP | |
| 3 | SP | SP | Z | SN | SN | SP | MP | MP | MP | SP | |
| 4 | MP | MP | Z | MN | MN | MP | BP | VBP | BP | MP | |
| 5 | BP | VBP | Z | VBN | BN | MP | VBP | VBP | VBP | BP | |
| 1 | 2 | 3 | 4 | 5 | |
| 1 | 29 | 26 | 25 | 26 | 29 |
| 2 | 20 | 17 | 14 | 17 | 20 |
| 3 | 14 | 10 | 9 | 10 | 14 |
| 4 | 8 | 5 | 4 | 5 | 8 |
| 5 | 5 | 2 | 1 | 2 | 5 |
| - | - | - | Robot | - | - |
| 1 | 2 | 3 | 4 | 5 | |
| 1 | - | - | - | - | - |
| 2 | - | - | - | - | - |
| 3 | - | X1 | X2 | X3 | - |
| 4 | X4 | X5 | X6 | X7 | X8 |
| 5 | X9 | X10 | X11 | X12 | X13 |
| - | - | - | Robot | - | - |
| Rule | Obstacle | Danger | Free | Target | Reward |
|---|---|---|---|---|---|
| 1 | Big | Zero | Zero | Small | 0.1 Target |
| 2 | Medium | Medium | |||
| 3 | Small | Small | |||
| 4 | Small | Zero | |||
| 5 | Small | Medium | |||
| 6 | Zero | Medium | |||
| 7 | Small | Small | Zero | Medium | 0.2 Target |
| 8 | Zero | Small | |||
| 9 | Small | Zero | Zero | Big | 0.25 Target |
| 10 | Zero | Big | Zero | Small | 0.333 Target |
| 11 | Zero | Medium | Small | Small | 0.5 Target |
| 12 | Zero | Small | Medium | Small | 0.667 Target |
| 13 | Zero | Medium | Zero | Medium | 0.75 Target |
| 14 | Small | Small | |||
| 15 | Zero | Big | Small | ||
| 16 | Zero | Zero | Zero | Very Big | Target |
| 17 | Small | Big | |||
| 18 | Zero | Medium | Medium | ||
| 19 | Small | Big | |||
| 20 | Small | Big | Zero | Zero | 0.4 Obstacle |
| 21 | Medium | Small | |||
| 22 | Small | Medium | |||
| 23 | Medium | Small | Small | Zero | 0.6 Obstacle |
| 24 | Big | Zero | Small | Zero | 0.8 Obstacle |
| 25 | Medium | Medium | |||
| 26 | Very Big | Zero | Zero | Zero | Obstacle |
| 27 | Big | Small | |||
| 28 | Medium | Medium | |||
| 29 | Zero | Small | Big | Zero | 0.25 Danger |
| 30 | Zero | Medium | Medium | Zero | 0.5 Danger |
| 31 | Zero | Very Big | Zero | Zero | Danger |
| 32 | Small | Zero | Big | ||
| 33 | Zero | Big | Small | ||
| 34 | Zero | Zero | Very Big | Zero | Free |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jahanshahi, H.; Jafarzadeh, M.; Sari, N.N.; Pham, V.-T.; Huynh, V.V.; Nguyen, X.Q. Robot Motion Planning in an Unknown Environment with Danger Space. Electronics 2019, 8, 201. https://doi.org/10.3390/electronics8020201
Jahanshahi H, Jafarzadeh M, Sari NN, Pham V-T, Huynh VV, Nguyen XQ. Robot Motion Planning in an Unknown Environment with Danger Space. Electronics. 2019; 8(2):201. https://doi.org/10.3390/electronics8020201
Chicago/Turabian StyleJahanshahi, Hadi, Mohsen Jafarzadeh, Naeimeh Najafizadeh Sari, Viet-Thanh Pham, Van Van Huynh, and Xuan Quynh Nguyen. 2019. "Robot Motion Planning in an Unknown Environment with Danger Space" Electronics 8, no. 2: 201. https://doi.org/10.3390/electronics8020201
APA StyleJahanshahi, H., Jafarzadeh, M., Sari, N. N., Pham, V. -T., Huynh, V. V., & Nguyen, X. Q. (2019). Robot Motion Planning in an Unknown Environment with Danger Space. Electronics, 8(2), 201. https://doi.org/10.3390/electronics8020201