An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks


Abstract
:1. Introduction
- We propose a novel coarse grain task partitioning (CGTP) strategy to minimize the processing time of each computing unit based on the parallel streaming architecture, which can improve the throughput.Besides, the multi-pattern dataflows are designed for the different sizes of CNN models can be applied to each computing unit according to the configuration context.
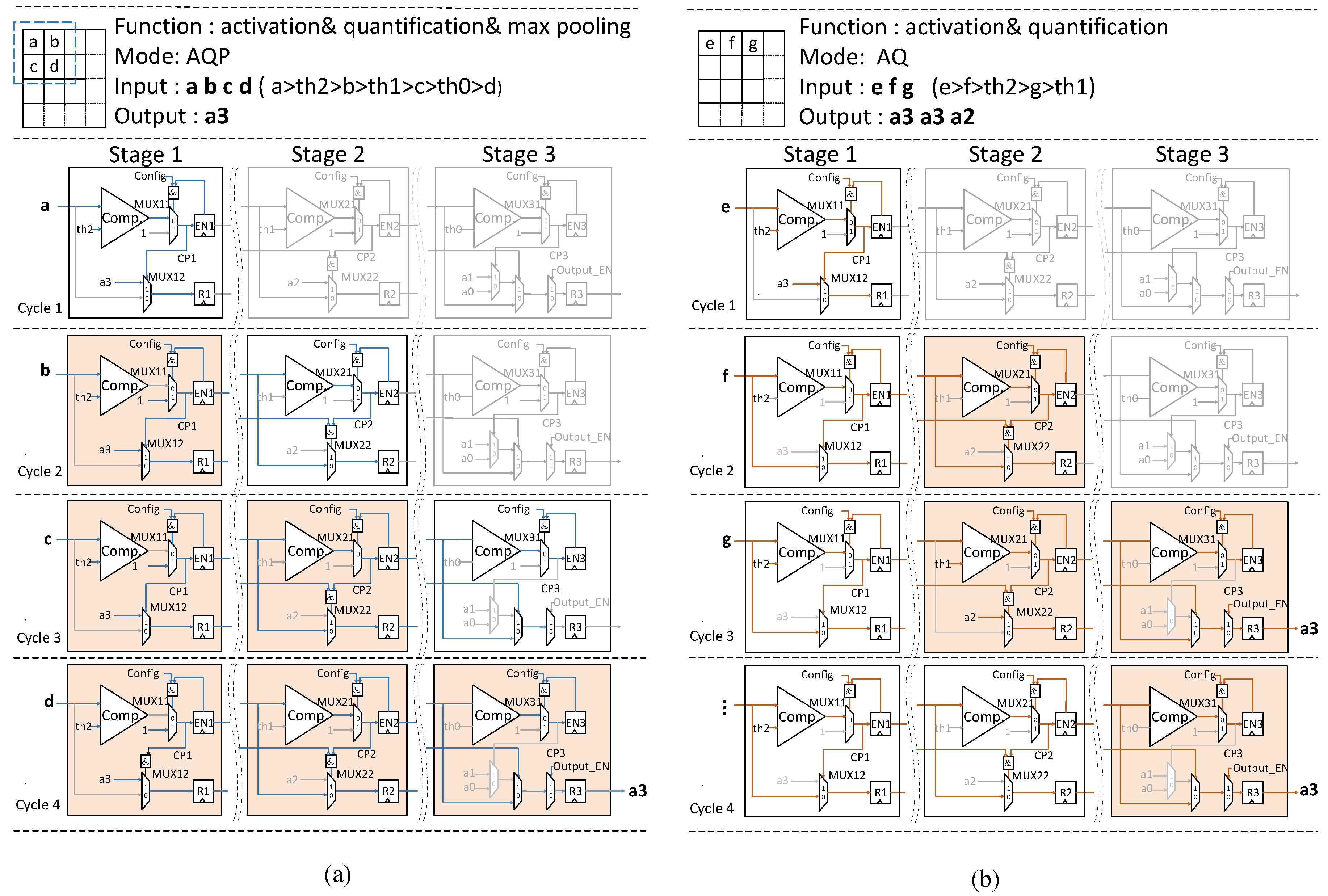
- We propose an efficient reconfigurable three-stage activation-quantification-pooling (AQP) unit, which can support two modes: AQ (processing activation and quantification) and AQP (processing activation, quantification and pooling). It means that the AQP unit can process the “possible” max-pooling layer (it does not exist after every CONV layer) without any overhead. Besides, the low power property is also exploited by the staged blocking strategy in AQP unit.
- The proposed architecture is implemented and evaluated with TSMC 40 nm technology with a core size of mm. It can achieve over TOPS/W energy efficiency and about TOPS/mm area efficiency at mW.
2. Background
2.1. Convolutional Neural Networks
2.2. Low Bit-Width CNNs
3. Efficient Parallel Streaming Architecture for Low Bit-Width CNNs
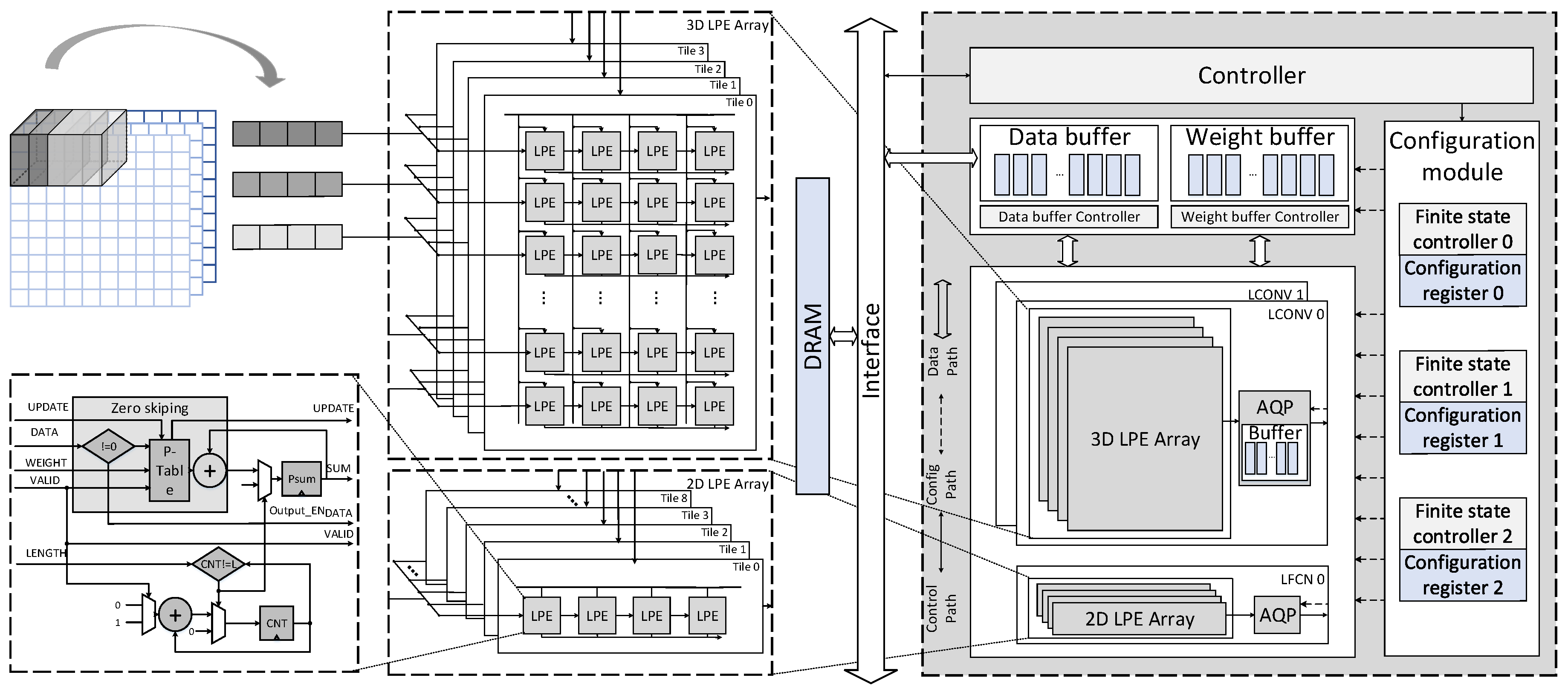
3.1. Top Architecture
- (1)
- CNNs have cascaded layers, which can be executed as sequential modules.
- (2)
- multiple loops of intensive computation within a layer can be partitioned and executed in parallel conveniently.
- (3)
- the CNN accelerator should handle large batches of classification tasks based on the application requirements.
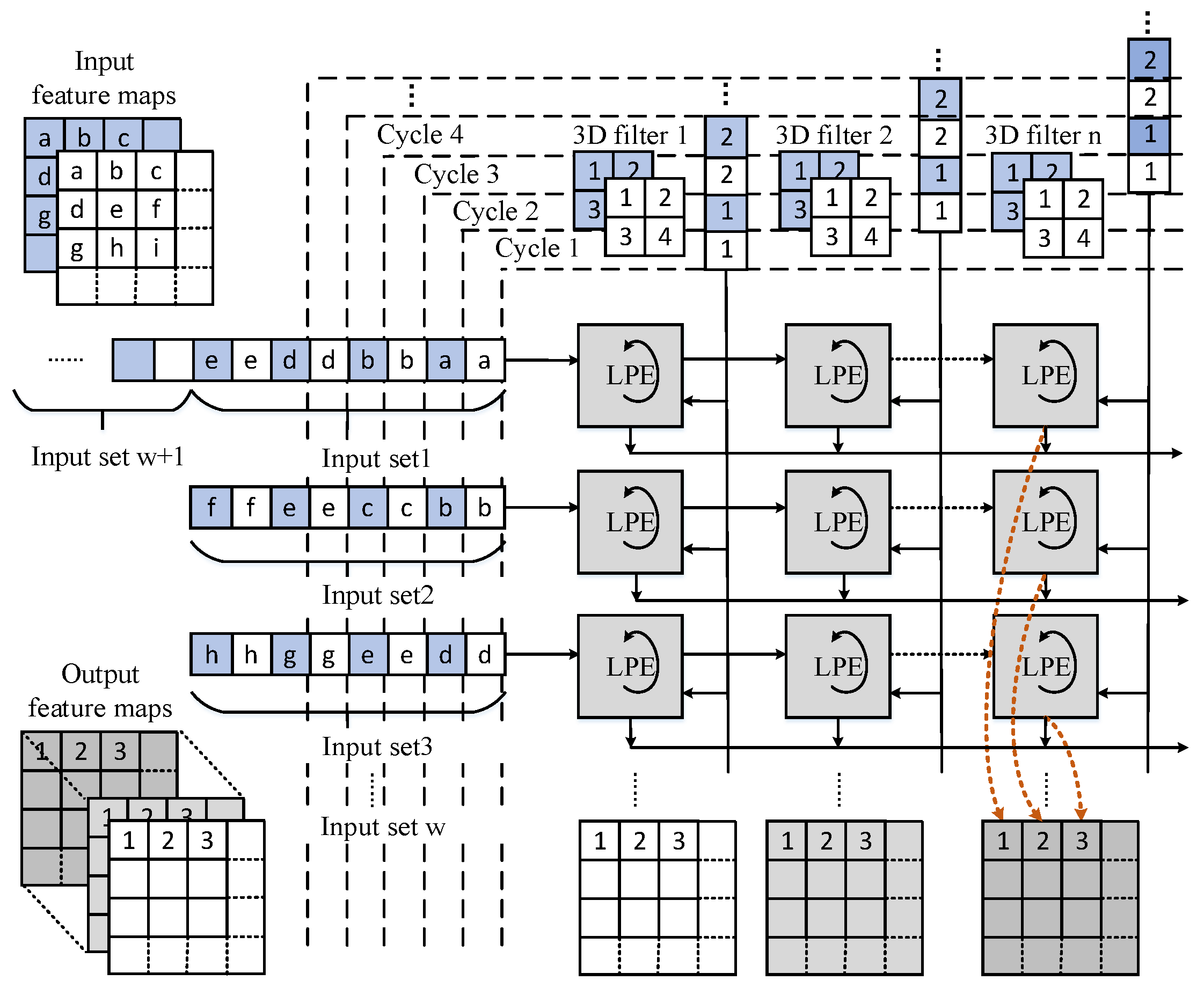
3.2. 3D Systolic-Like Array and Dataflow
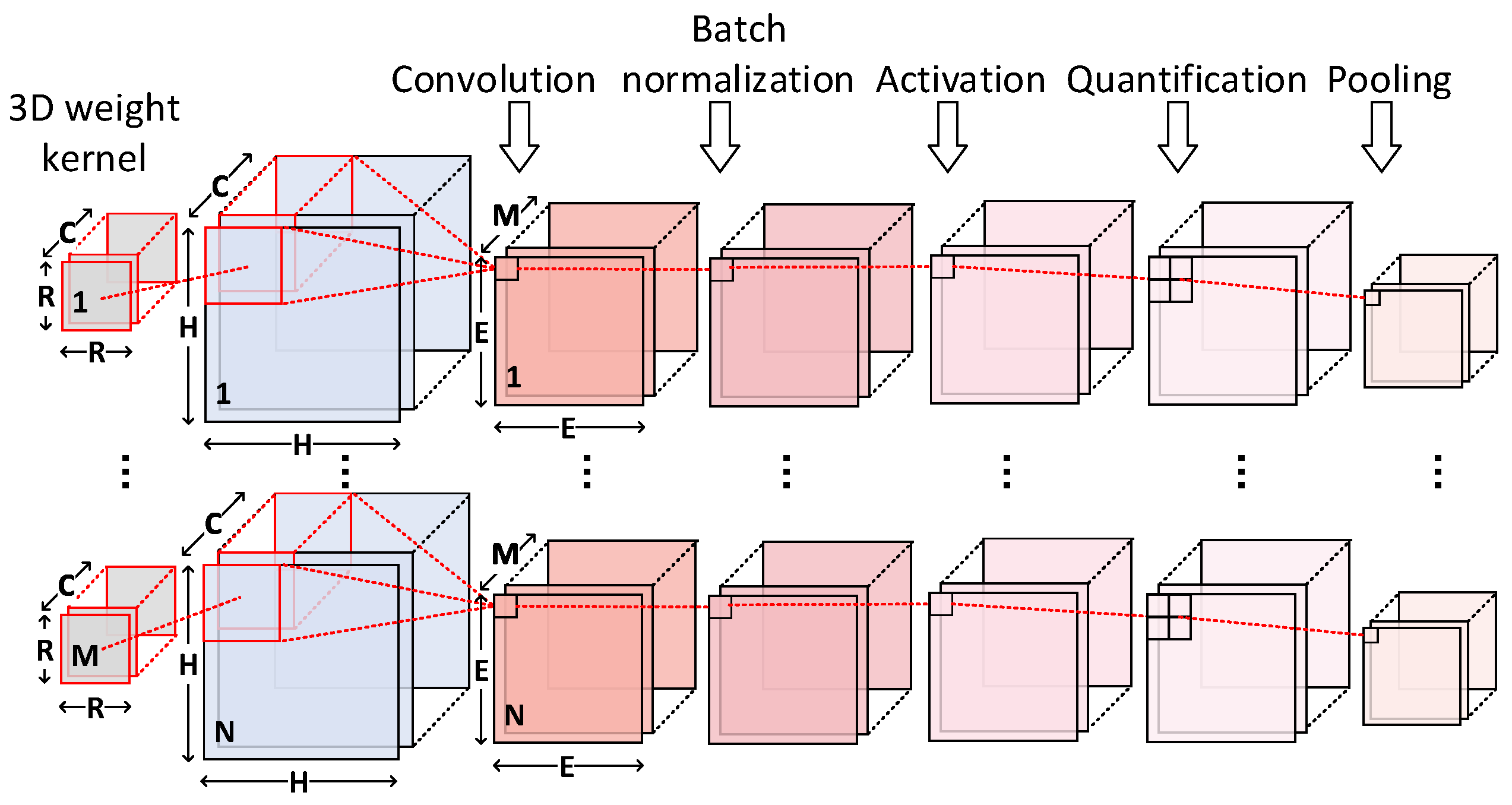
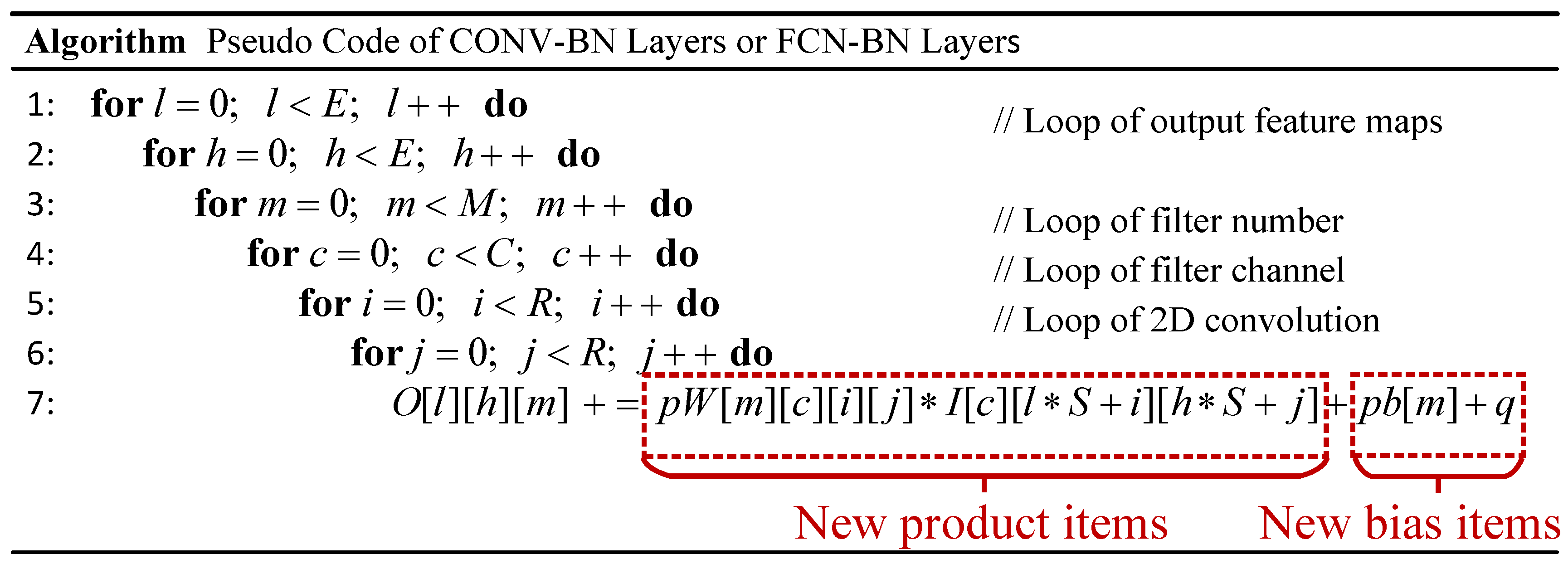
3.2.1. Merging Bit-Wise Convolution and Batch Normalization into One Step
3.2.2. 3D Systolic-Like Array
3.2.3. Multi-Pattern Dataflow
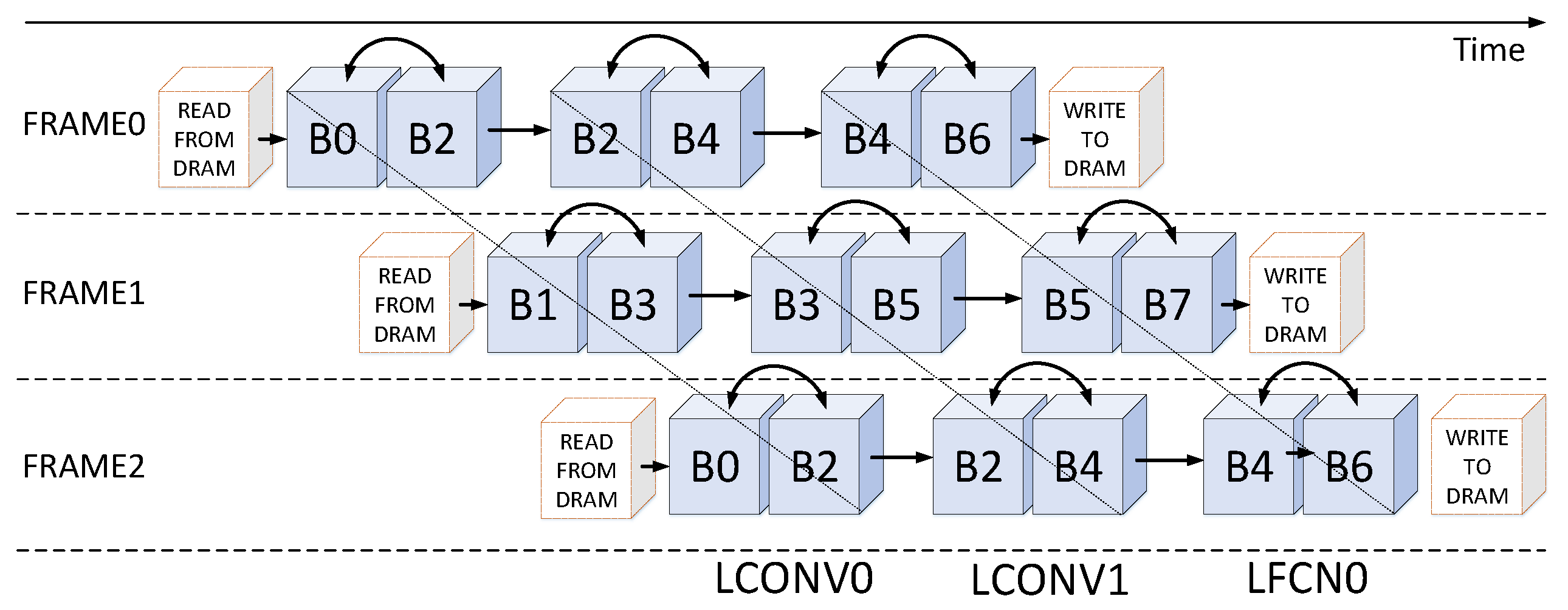
3.3. Coarse Grain Task Partitioning Strategy
| Algorithm 1 Coarse Grain Task Partitioning |
| Input: Number of CONV layers L; detailed dimensions of each CONV layer ; detailed dimensions of LCONV ; dataflow mode Output: Two groups
|
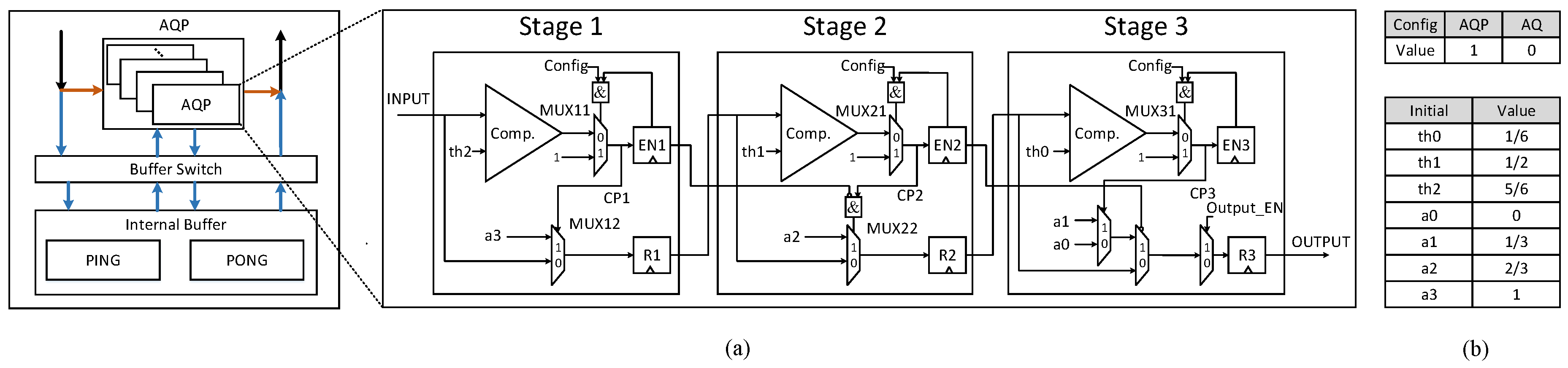
3.4. Reconfigurable Three-Stage AQP Unit
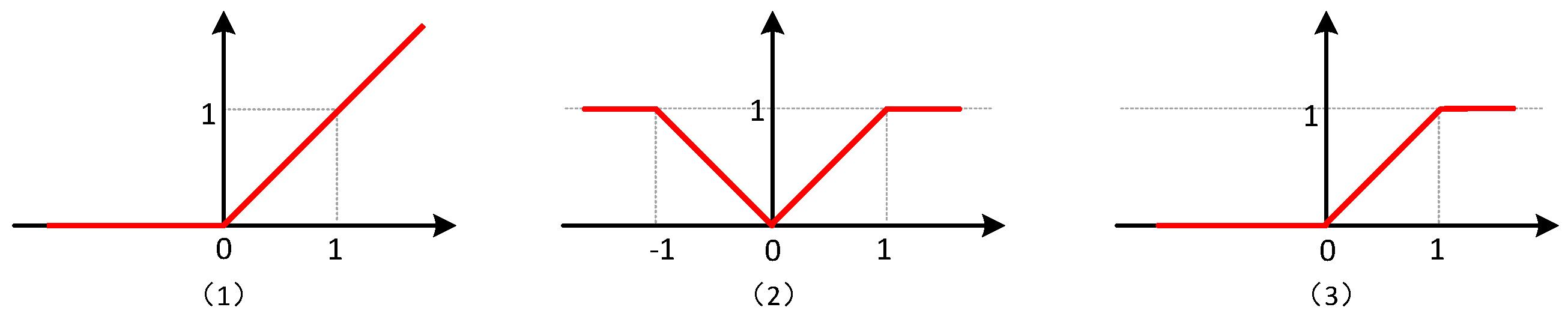
3.4.1. Modified Quantification
3.4.2. Architecture of AQP Unit and Dataflow
3.4.3. Working Process of AQP Unit under Two Modes and Staged Blocking Strategy
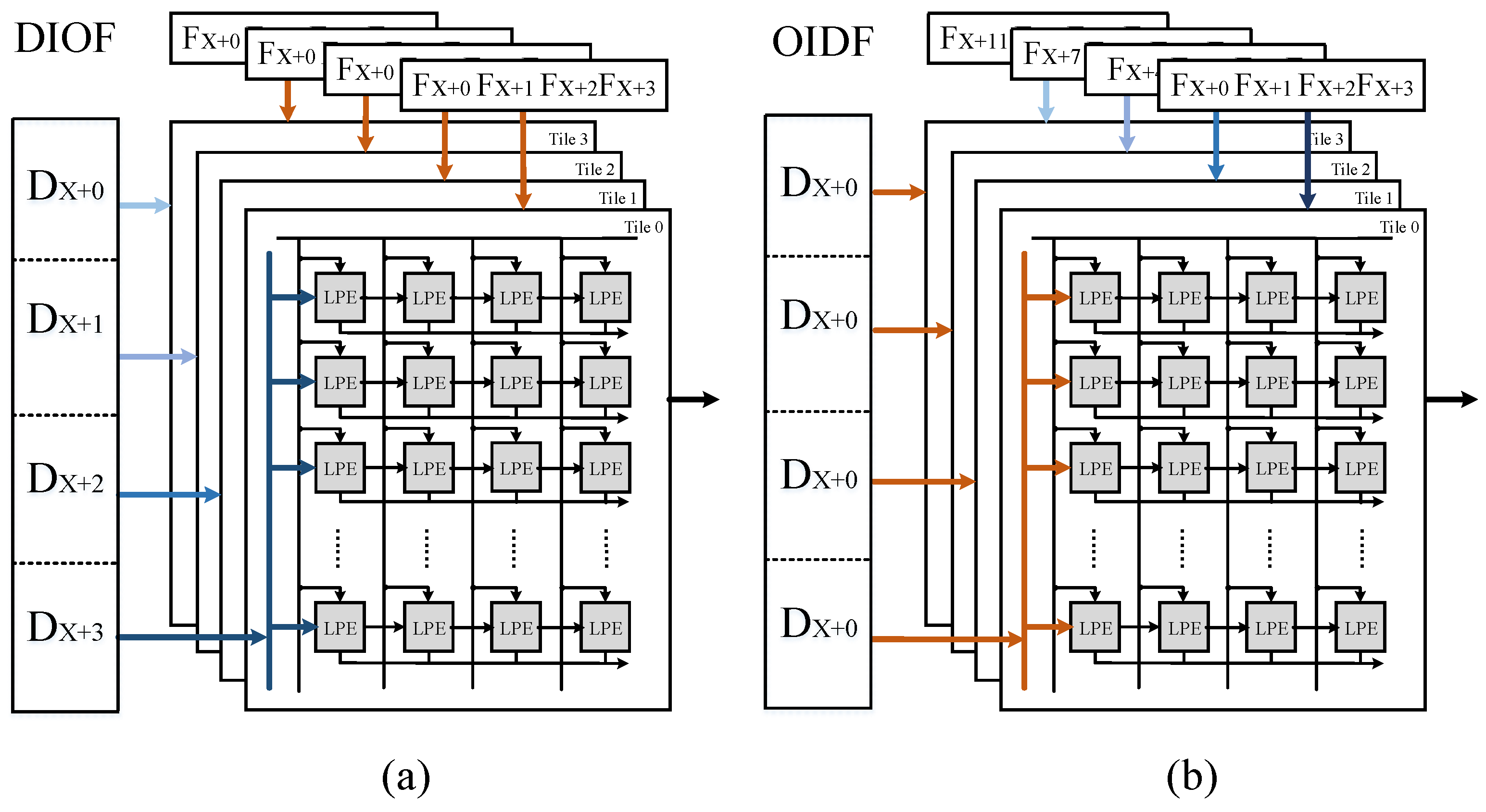
3.5. Interleaving Bank Scheduling Scheme
- Frame Level: the bank group 0 and the bank group 1 are loaded input feature maps of different frames from external memory alternatively. This means that all even-numbered bank groups are configured to provide and receive data on one frame, and all odd-numbered bank groups support another frame.
- Computing Unit Level: each computing unit corresponds to a specific set of bank groups, for example, the LCONV0 and the LCONV1 connect to the bank group 0–3 and the bank group 2–5, respectively, the LCFN0 links to the bank group 4–7.
| Algorithm 2 Interleaving Bank Scheduling Scheme |
|
4. Evaluation
4.1. Evaluation Metrics
4.1.1. Computation Complexity
4.1.2. Performance
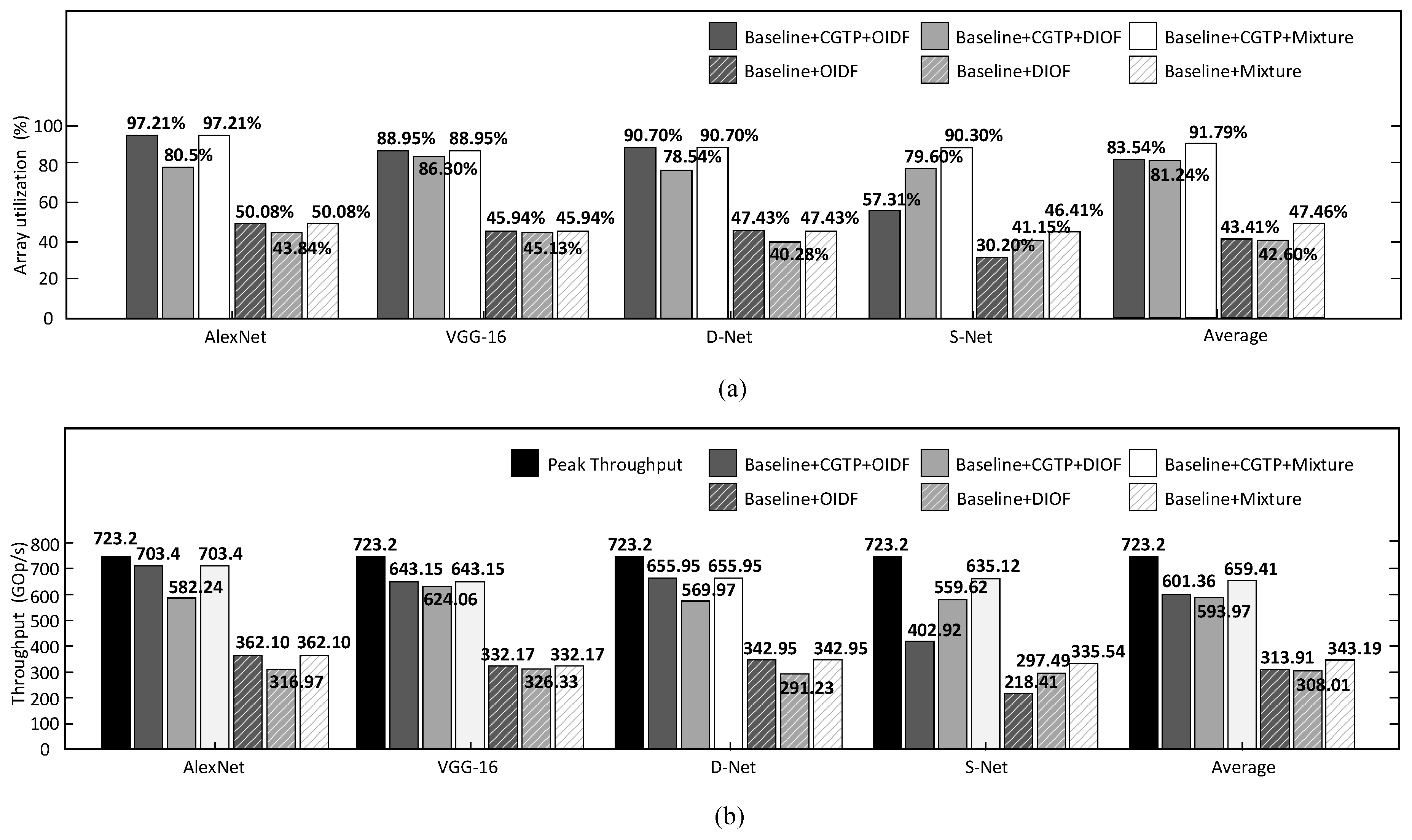
4.2. Performance Comparison
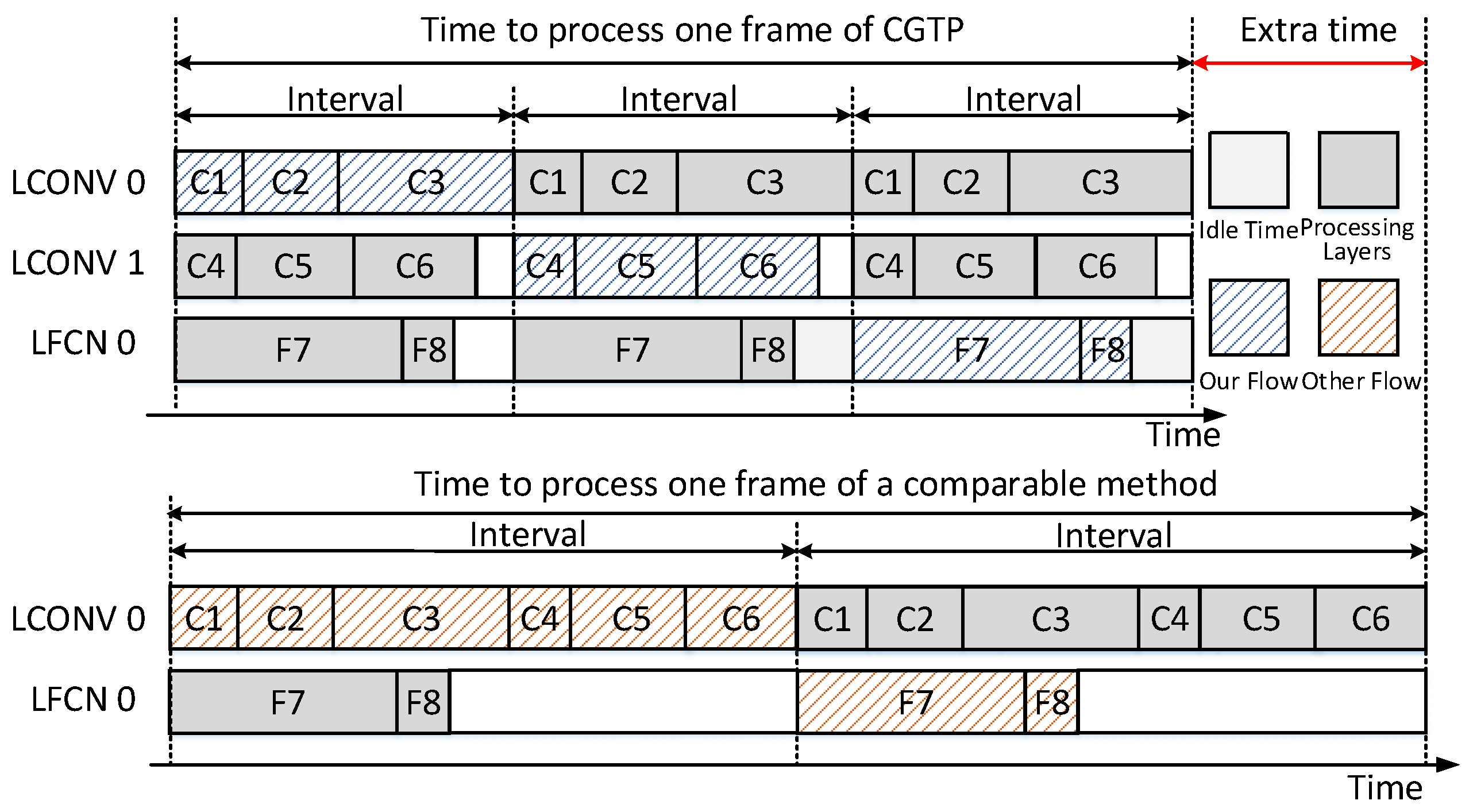
4.2.1. Analysis on CGTP Strategy
4.2.2. Analysis on Dataflow
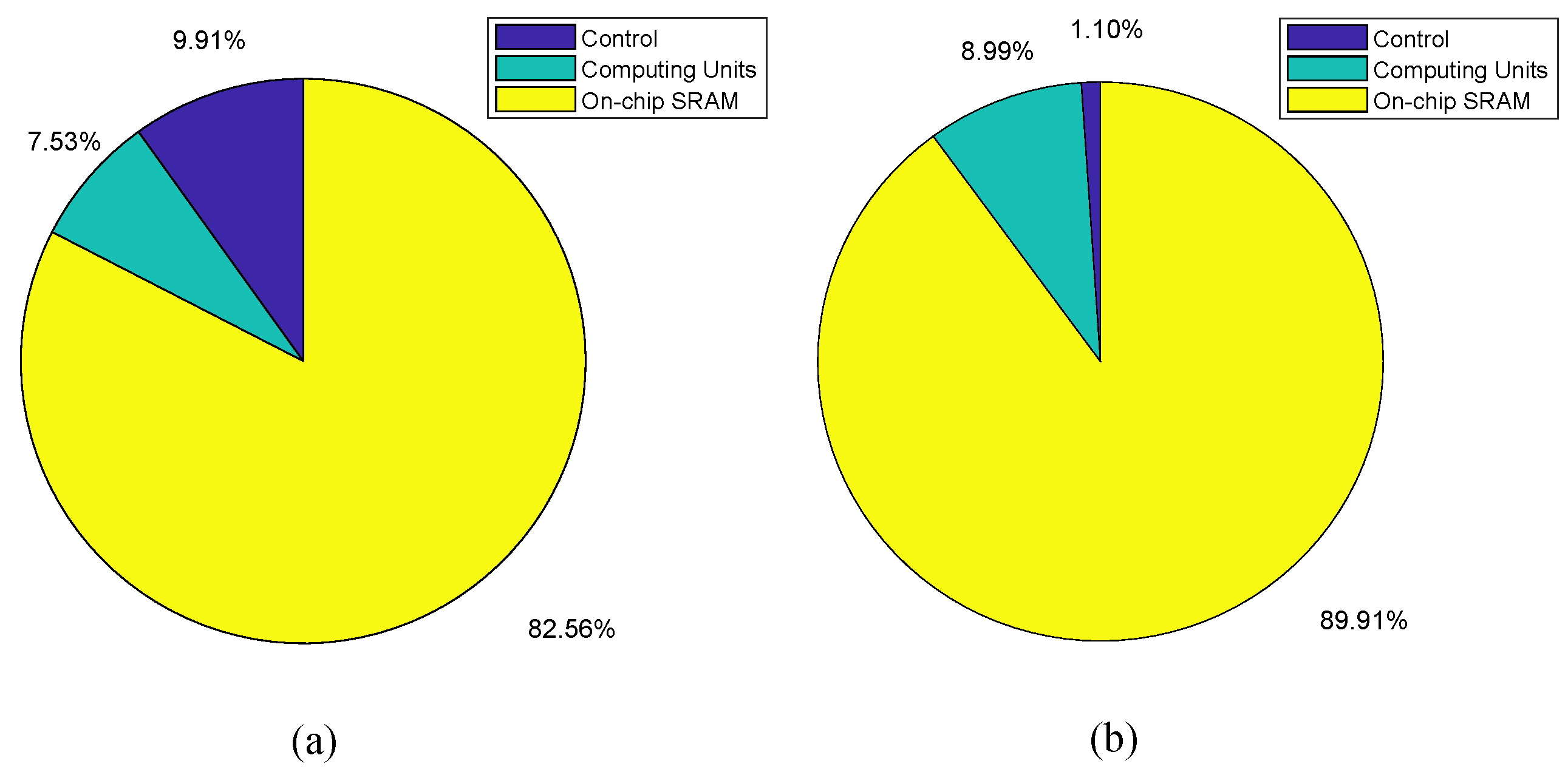
4.2.3. Synthesis Results of the Breakdown
4.2.4. Comparison with Previous Works
- The parallel streaming architecture with heterogeneous computing units can efficiently exploit the use of computing resources. Also, the CGTP strategy and the multi-pattern dataflow contribute a lot to improve the throughput respectively.
- The computing array cannot only execute the convolution or inner-product but also the batch-normalization function. Besides, the LPE is only composed of some “look-up table” registers, an adder and some logical registers.
- The AQP unit is only composed of comparators and registers. The function of activation, quantification and pooling can be implemented on the same piece of hardware simultaneously. Besides, the low power property is also exploited by the staged blocking strategy.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tang, Z.L.; Li, S.M.; Yu, L.J. Implementation of Deep Learning-Based Automatic Modulation Classifier on FPGA SDR Platform. Electronics 2018, 7, 122. [Google Scholar] [CrossRef]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-Object Detection in Traffic Scenes Based on Improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Liu, X.; Tao, Y.; Jing, L. Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network. Electronics 2018, 7, 78. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Proceedinds of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. arXiv, 2014; arXiv:1412.5567. [Google Scholar]
- Collobert, R.; Weston, J.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. Fiber 2015, 56, 3–7. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv, 2016; arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv, 2016; arXiv:1606.06160. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the ACM FPGA, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Zhang, C.; Fang, Z.; Zhou, P.; Pan, P.; Cong, J. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. In Proceedings of the ACM/IEEE ICCAD, Austin, TX, USA, 7–10 November 2016; p. 12. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Parashar, A.; Rhu, M.; Mukkara, A.; Puglielli, A.; Venkatesan, R.; Khailany, B.; Emer, J.; Keckler, S.W.; Dally, W.J. SCNN: An accelerator for compressed-sparse convolutional neural networks. In Proceedings of the ACM/IEEE ISCA, Toronto, ON, Canada, 24–28 June 2017; pp. 27–40. [Google Scholar]
- Wang, Y.; Lin, J.; Wang, Z. An Energy-Efficient Architecture for Binary Weight Convolutional Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 280–293. [Google Scholar] [CrossRef]
- Andri, R.; Cavigelli, L.; Rossi, D.; Benini, L. YodaNN: An Architecture for Ultra-Low Power Binary-Weight CNN Acceleration. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 48–60. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; He, Z.; Fan, D. A Fully Onchip Binarized Convolutional Neural Network FPGA Impelmentation with Accurate Inference. In Proceedings of the ACM ISLPED, Seattle, WA, USA, 23–25 July 2018; pp. 50:1–50:6. [Google Scholar]
- Jiao, L.; Luo, C.; Cao, W.; Zhou, X.; Wang, L. Accelerating low bit-width convolutional neural networks with embedded FPGA. In Proceedings of the IEEE FPL, Ghent, Belgium, 4–8 September 2017; pp. 1–4. [Google Scholar]
- Shen, Y.; Ferdman, M.; Milder, P. Maximizing CNN accelerator efficiency through resource partitioning. In Proceedings of the ACM/IEEE ISCA, Toronto, ON, Canada, 24–28 June 2017; pp. 535–547. [Google Scholar]
- Venieris, S.I.; Bouganis, C.S. fpgaConvNet: A Framework for Mapping Convolutional Neural Networks on FPGAs. In Proceedings of the IEEE FCCM, Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar]
- Guo, J.; Yin, S.; Ouyang, P.; Tu, F.; Tang, S.; Liu, L.; Wei, S. Bit-width Adaptive Accelerator Design for Convolution Neural Network. In Proceedings of the IEEE ISCAS, Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Liu, D. Embedded DSP Processor Design: Application Specific Instruction Set Processors; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2008. [Google Scholar]
- Venkatesh, G.; Nurvitadhi, E.; Marr, D. Accelerating Deep Convolutional Networks using low-precision and sparsity. In Proceedings of the IEEE ICASSP, New Orleans, LA, USA, 5–9 March 2017; pp. 2861–2865. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; ACM: New York, NY, USA, 2017; pp. 65–74. [Google Scholar]
- Blott, M.; Preusser, T.; Fraser, N.; Gambardella, G.; O’Brien, K.; Umuroglu, Y. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. arXiv, 2018; arXiv:1809.04570. [Google Scholar]
- Song, M.; Zhao, J.; Hu, Y.; Zhang, J.; Li, T. Prediction Based Execution on Deep Neural Networks. In Proceedings of the ACM/IEEE ISCA, Los Angeles, CA, USA, 1–6 June 2018; pp. 752–763. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the ICML, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach, 6th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017. [Google Scholar]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. A Survey of FPGA Based Neural Network Accelerator. arXiv, 2018; arXiv:1712.08934. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. ACM Sigplan Not. 2014, 49, 269–284. [Google Scholar]
- Du, L.; Du, Y.; Li, Y.; Su, J.; Kuan, Y.; Liu, C.; Chang, M.F. A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 198–208. [Google Scholar] [CrossRef] [Green Version]
- Cavigelli, L.; Benini, L. Origami: A 803-gop/s/w convolutional network accelerator. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2461–2475. [Google Scholar] [CrossRef]
- Ueyoshi, K.; Ando, K.; Hirose, K.; Takamaeda-Yamazaki, S.; Kadomoto, J.; Miyata, T.; Hamada, M.; Kuroda, T.; Motomura, M. QUEST: A 7.49 TOPS multi-purpose log-quantized DNN inference engine stacked on 96MB 3D SRAM using inductive-coupling technology in 40nm CMOS. In Proceedings of the IEEE ISSCC, San Francisco, CA, USA, 11–15 February 2018; pp. 216–218. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Type | Channel Size | Channel No. | Kernel Size | Filter No. | Stride |
|---|---|---|---|---|---|---|
| 1 | INPUT | 40 × 40 | 3 | - | - | |
| 2 | CONV | 40 × 40 | 3 | 5 | 32 | 1 |
| 3 | MaxP | 36 × 36 | 32 | 2 | - | 2 |
| 4 | CONV | 18 × 18 | 32 | 3 | 48 | 1 |
| 5 | CONV | 18 × 18 | 48 | 3 | 64 | 1 |
| 6 | MaxP | 18 × 18 | 64 | 2 | - | 2 |
| 7 | CONV | 9 × 9 | 64 | 3 | 128 | 1 |
| 8 | CONV | 7 × 7 | 128 | 3 | 128 | 1 |
| 9 | CONV | 7 × 7 | 128 | 3 | 128 | 1 |
| 10 | FCN | 5 × 5 | 128 | - | 512 | - |
| 11 | FCN | 512 | - | - | 10 | - |
| Benchmarks | CGTP+OIDF | CGTP+DIOF | CGTP+Mixture | |||
|---|---|---|---|---|---|---|
| LCONV0 | LCONV1 | LCONV0 | LCONV1 | LCONV0 | LCONV1 | |
| AlexNet | C1–C2 | C3–C5 | C1–C2 | C3–C5 | C1–C2 | C3–C5 |
| VGG-16 | C1–C6 | C7–C13 | C1–C6 | C7–C13 | C1–C6 | C7–C13 |
| D-Net | C1–C3 | C4–C6 | C1–C3 | C4–C6 | C1–C3 | C4–C6 |
| S-Net | C1 | C2–C6 | C1–C2 | C3–C6 | C1–C2 | C3–C6 |
| Benchmarks | Utilization (%) | Effective Throughput (GOPS) | ||||||
|---|---|---|---|---|---|---|---|---|
| LCONV1 | LCONV2 | LFCN | Total | LCONV1 | LCONV2 | LFCN | Total | |
| AlexNet | 96.07% | 98.13% | 97.23% | 97.21% | 319.79 | 326.56 | 56.90 | 703.4 |
| VGG-16 | 99.47% | 92.17% | 9.49% | 88.95% | 330.54 | 306.75 | 5.86 | 643.15 |
| D-Net | 99.69% | 87.50% | 57.21% | 90.70% | 331.78 | 291.22 | 32.95 | 655.95 |
| S-Net | 99.47% | 92.17% | 9.49% | 90.30% | 331.04 | 306.75 | 54.67 | 653.03 |
| Block Index | Size [C, M, E] | # Operations [MOP] | # Clock | Time [ms] | CGTP | Time [ms] |
|---|---|---|---|---|---|---|
| C1&MaxP | 507,049 | LCONV0 | ||||
| C2&MaxP | 1,076,800 | |||||
| C3 | 718,852 | LCONV1 | ||||
| C4 | 539,140 | |||||
| C5&MaxP | ||||||
| S1 | 36 | 1,050,628 | LFCN0 | |||
| S2 | 16 | 466,948 | ||||
| S3 | 131,076 | |||||
| Effect. Throughput [GOPS] | ||||||
| Metrics | YodaNN [18] | BCNN[17] | QUEST [36] | This Work | This Work (Scaled) |
|---|---|---|---|---|---|
| TCAD 2017 | TVLSI 2018 | ISSCC 2018 | |||
| Technology [nm] | 65 | 65 | 40 | 40 | 65 |
| Voltage [V] | |||||
| On-chip SRAM [KB] | 94 | 393 | 7680 | 44 | 44 |
| Benchmark | ConvNet | VGG-16 | AlexNet | AlexNet | AlexNet |
| (Weight,Acitvation) bit-width [bit] | (1,12) | (1,16) | (1,1) | (1,2) | (1,2) |
| Working Frequency [MHz] | 480 | 380 | 300 | 800 | 492 |
| Core Power [mW] | 41 | 3300 | |||
| Core Area [mm] | |||||
| Peak Performance [GOPS] | 1500 | 7002 | 7490 | ||
| Effective Performance [GOPS] | 90 | 1752 | 6023 | ||
| Energy Efficiency [TOPS/W] | |||||
| Area Efficiency [GOPS/mm] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Fu, Y.; Song, W.; Cheng, K.; Lu, Z.; Zhang, C.; Li, L. An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks. Electronics 2019, 8, 371. https://doi.org/10.3390/electronics8040371
Chen Q, Fu Y, Song W, Cheng K, Lu Z, Zhang C, Li L. An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks. Electronics. 2019; 8(4):371. https://doi.org/10.3390/electronics8040371
Chicago/Turabian StyleChen, Qinyu, Yuxiang Fu, Wenqing Song, Kaifeng Cheng, Zhonghai Lu, Chuan Zhang, and Li Li. 2019. "An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks" Electronics 8, no. 4: 371. https://doi.org/10.3390/electronics8040371
APA StyleChen, Q., Fu, Y., Song, W., Cheng, K., Lu, Z., Zhang, C., & Li, L. (2019). An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks. Electronics, 8(4), 371. https://doi.org/10.3390/electronics8040371