Model-Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification †


Abstract
:1. Introduction
- data abstraction,
- pipeline reduction,
- taint encoding,
- refinement.
- Section 5 has been revisited and expanded to better illustrate the underlying details of the approach.
- Model abstraction, taint propagation and verification have been expanded to better illustrate the underlying details of the approach.
- Tables and Figures have been added.
- Comments and explanations have been added to figures and tables.
- A full detailed example has been provided to show the feasibility of our approach.
- The correctness of the approach has been revisited and expanded: references to related state-of-the-art publications have been added.
- Section 2 provides state-of-the-art related work and background notions.
- Section 3 presents the processor architecture model.
- Section 4 gives a detailed description of an implementation of Spectre and Meltdown.
- Section 5 shows the verification approach we adopt on our case-study processor model.
- Section 6 produces experimental results to support the viability of our methodology.
- Section 7 proposes remarks and future directions in this field.
2. Preliminaries, Background, Related Works
2.1. Spectre and Meltdown Attacks
2.2. Formal Verification of Microprocessors with Out-of-Order Execution
- model reduction: a form of case split, where only a properly selected subset of possible execution traces is considered;
- data abstraction: the model behavior is over-approximated by (partially) removing/transforming data (deemed) unnecessary to the proof; assumptions have to be made so that the soundness of the approach is guaranteed, e.g., arithmetic and logic functionalities are already verified. Possible refinement steps are needed, whenever the abstraction is unsound.
2.3. Verifying Cybersecurity by Tainting
- Confidentiality: object A is confidential, while object B is public. An attacker could gain information about A by observing variations on B. In this case, the property would be that A must not flow to B.
- Integrity: object A is untrusted, while object B is trusted. An attacker could gain access to B through malicious modifications on A. Again, the property would be that A must not flow to B.
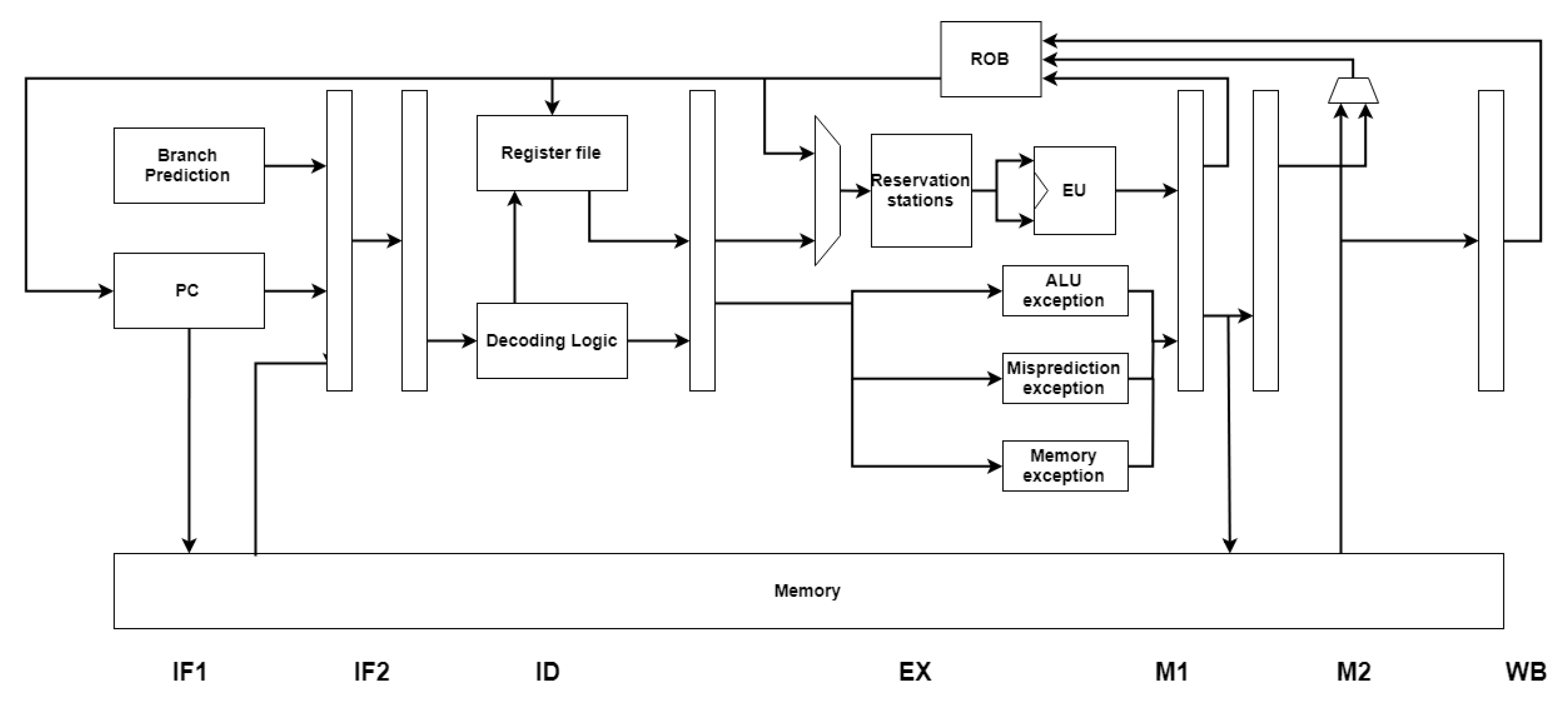
3. Processor Model
4. Attack Description
- the attacker chooses an inaccessible memory location, then the contents of that memory location is loaded into a register;
- a cache line is accessed by a transient instruction based on the secret contents of the register;
- the attacker exploits a side-channel to probe the previously accessed cache line and leaks information depending on the sensitive data saved at the chosen memory location.
| Listing 1. Attack transient instruction sequence in DLX assembly code. |
 |
4.1. Step One
4.2. Step Two
4.3. Step Three
5. Proof/Verification
- data abstraction: register values, along with all the units that handle these values, as well as the reorder buffer, reservation stations and execution units, are adequately abstracted. Tainting information and evaluation/propagation circuitry are then added to or replace them.
- model reduction: applying established processor verification approaches such as pipeline flushing and reduction by refinement map, we reduce speculation and parallel execution logic.
5.1. Data Abstraction and Tainting
- full data dependence: data values are fully involved in taint computation; whenever computing , actual operand data values are considered; for instance, a bitwise OR operation with all , or a multiplication with , could mask (block) a taint on the other operand ();
- full abstraction from data values: for instance, taint propagation through a binary ALU operation propagates a taint on any of the operand terms ().
- inject a taint, exploiting a mispredicted instruction which performs an invalid/protected memory access;
- transfer the taint into the (abstracted) reorder buffer, as a data expected to be committed;
- use the taint, as a data, as part of the computation of the address of a successive mispredicted memory access: the taint hits the target.
- (A)
- performs a memory access to an invalid address;
- (B)
- executes an arithmetic operation using the secret data;
- (C)
- performs a read from an array with a displacement related to the secret.
5.2. Combining Model Reduction with Abstraction
- pipeline flushing: all pipeline stages are flushed (collapsed), which simplifies the execution model of an instruction, since the next instruction is initiated only when the previous one reaches the reorder buffer;
- reorder buffer removal: ROB is reduced into a FIFO queue, which essentially delays instructions between execution and results availability into the register file; to be noted that the FIFO strategy preserves the original instruction order, assuring data dependency;
- reservation station replacement: as straightforward effect of previous pipeline flushing and ROB removal, reservation stations are bypassed (performing in fact a model reduction);
- execution units merge: considering the data abstraction performed on our model, computation parallelism is unnecessary, so just one instance of each execution unit is useful.
- consecutive instruction sequences comprise mispredicted instructions, simulating real instructions sequences made by an actual out-of-order CPU; this behavior is assured by a non-deterministic tag associated with an instruction, which marks that instruction as mispredicted (this operation is performed during the abstraction transformation, as described in Section 5.1);
- the FIFO-based delay, replacing the ROB, simulates the (illegal) taint-propagation time from source to sink; this behavior is assured by a proper FIFO queue size and a proper non-deterministic queue control of get operations, which transfer data from ROB to the register file.
5.3. Correctness of the Approach
- Abstractions and reductions that do not affect secure information flow by taint propagation. This is a set of preliminary model transformations oriented to reduce the data width and the model behavior (pipeline and speculative execution): transformations guarantee the model functionality, and they have already been proved correct by related and state-of-the-art works on formal verification of processor designs. We do not claim any contribution in this field, and we assume them as correct
- Abstraction and reduction steps related to secure information flow by taint propagation. Though we resort to standard formalisms and transformations, we nevertheless need to show/prove that their combined application is complete and sound.
5.3.1. Model Abstraction and Reduction
- tainting does not affect the correctness of the model
- secure information flow by tainting is sound and complete.
5.3.2. Taint Encoding and Manipulation
- apply precise and narrower tainting rules, cutting off (adopting a more precise and detailed taint-propagation model) all false negatives;
- adopt an imprecise but efficient approach, thus accepting false abstract counterexamples. If this would be the case, counterexamples could be either:
- -
- post processed, leading to subsequent model refinements;
- -
- be converted into actual (equivalent) concrete counterexamples, by just exploiting them partially (e.g., by removing data and keeping control bits), as constraints for a further Bounded Model-Checking (BMC) run on the concrete model.
6. Experimental Results
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ALU | Arithmetic Logic Unit |
| BDD | Binary Decision Diagram |
| BMC | Bounded Model-Checking |
| CDB | Common Data Bus |
| EX | Execution |
| FIFO | First-in First-Out |
| HW/SW | Hardware/Software |
| IC3 | Incremental Construction of Inductive Clauses for Indubitable Correctness |
| ID | Instruction Decode |
| IF | Instruction Fetch |
| IFT | Information Flow Tracking |
| ILA | Instruction Level Abstraction |
| ISA | Instruction Set Architecture |
| MA | MicroArchitecture |
| MAR | Memory Address Register |
| MDR | Memory Data Register |
| MEM | Memory |
| OP | Micro-operation |
| OOO | Out-of-order |
| PC | Program Counter |
| PdTRAV | Politecnico di Torino Reachability Analysis and Verification |
| RAW | Read After Write |
| RISC | Reduced Instruction Set Computer |
| ROB | Reorder Buffer |
| RS | Reservation Station |
| TLB | Translation Lookaside Buffer |
| UMC | Unbounded Model-Checking |
| WB | Write-Back |
References
- Kocher, P.; Genkin, D.; Gruss, D.; Haas, W.; Hamburg, M.; Lipp, M.; Mangard, S.; Prescher, T.; Schwarz, M.; Yarom, Y. Spectre attacks: Exploiting speculative execution. arXiv 2018, arXiv:1801.01203. [Google Scholar]
- Lipp, M.; Schwarz, M.; Gruss, D.; Prescher, T.; Haas, W.; Mangard, S.; Kocher, P.; Genkin, D.; Yarom, Y.; Hamburg, M. Meltdown. arXiv 2018, arXiv:1801.01207. [Google Scholar]
- Beckers, K.; Heisel, M.; Hatebur, D. Pattern and Security Requirements; Springer: Berlin, Germany, 2015. [Google Scholar]
- Boritz, J.E. IS practitioners’ views on core concepts of information integrity. Int. J. Account. Inf. Syst. 2005, 6, 260–279. [Google Scholar] [CrossRef]
- Yarom, Y.; Falkner, K. FLUSH+ RELOAD: A high resolution, low noise, L3 cache side-channel attack. In Proceedings of the 23rd USENIX Security Symposium (USENIX Security 14), San Diego, CA, USA, 20–22 August 2014; pp. 719–732. [Google Scholar]
- Yang, B.; Wu, K.; Karri, R. Scan based side channel attack on dedicated hardware implementations of data encryption standard. In Proceedings of the 2004 International Conferce on Test, Charlotte, NC, USA, 26–28 October 2004; pp. 339–344. [Google Scholar]
- Lin, L.; Kasper, M.; Güneysu, T.; Paar, C.; Burleson, W. Trojan side-channels: Lightweight hardware trojans through side-channel engineering. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 382–395. [Google Scholar]
- Tehranipoor, M.; Wang, C. Introduction to Hardware Security and Trust; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Lowe-Power, J.; Akella, V.; Farrens, M.K.; King, S.T.; Nitta, C.J. A case for exposing extra-architectural state in the ISA: Position paper. In Proceedings of the 7th International Workshop on Hardware and Architectural Support for Security and Privacy, Los Angeles, CA, USA, 2 June 2018; p. 8. [Google Scholar]
- Joy Persial, G.; Prabhu, M.; Shanmugalakshmi, R. Side channel attack-survey. Int. J. Adv. Sci. Res. Rev. 2011, 1, 54–57. [Google Scholar]
- Fan, J.; Guo, X.; De Mulder, E.; Schaumont, P.; Preneel, B.; Verbauwhede, I. State-of-the-art of secure ECC implementations: A survey on known side-channel attacks and countermeasures. In Proceedings of the 2010 IEEE International Symposium on Hardware-Oriented Security and Trust (HOST), Anaheim, CA, USA, 13–14 June 2010; pp. 76–87. [Google Scholar]
- Zhou, Y.; Feng, D. Side-Channel Attacks: Ten Years after Its Publication and the Impacts on Cryptographic Module Security Testing. IACR Cryptol. EPrint Arch. 2005, 2005, 388. [Google Scholar]
- Hill, M.D.; Masters, J.; Ranganathan, P.; Turner, P.; Hennessy, J.L. On the Spectre and Meltdown Processor Security Vulnerabilities. IEEE Micro 2019, 39, 9–19. [Google Scholar] [CrossRef]
- Bennett, R.; Callahan, C.; Jones, S.; Levine, M.; Miller, M.; Ozment, A. How to live in a post-meltdown and-spectre world. Commun. ACM 2018, 61, 40–44. [Google Scholar] [CrossRef]
- Prout, A.; Arcand, W.; Bestor, D.; Bergeron, B.; Byun, C.; Gadepally, V.; Houle, M.; Hubbell, M.; Jones, M.; Klein, A.; et al. Measuring the Impact of Spectre and Meltdown. In Proceedings of the 2018 IEEE High Performance extreme Computing Conference (HPEC), Waltham, MA, USA, 25–27 September 2018; pp. 1–5. [Google Scholar]
- Patterson, D.A.; Hennessy, J.L.; Goldberg, D. Computer Architecture: A Quantitative Approach; Morgan Kaufmann: San Mateo, CA, USA, 1990; Volume 2. [Google Scholar]
- Cabodi, G.; Camurati, P.; Finocchiaro, F.; Vendraminetto, D. Model Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification. In Proceedings of the International Conference on Codes, Cryptology, and Information Security, Rabat, Morocco, 22–24 April 2019; pp. 462–479. [Google Scholar]
- Clarke, E.M.; Emerson, E.A. Design and synthesis of synchronization skeletons using branching time temporal logic. In Workshop on Logic of Programs; Springer: Berlin/Heidelberg, Germany, 1981; pp. 52–71. [Google Scholar]
- Clarke, E.M.; Emerson, E.A.; Sistla, A.P. Automatic verification of finite-state concurrent systems using temporal logic specifications. ACM Trans. Program. Lang. Syst. (TOPLAS) 1986, 8, 244–263. [Google Scholar] [CrossRef]
- Damm, W.; Pnueli, A. Verifying out-of-order executions. In Advances in Hardware Design and Verification; Springer: Berlin, Germany, 1997; pp. 23–47. [Google Scholar]
- Sawada, J.; Hunt, W.A. Processor verification with precise exceptions and speculative execution. In Proceedings of the International Conference on Computer Aided Verification, Vancouver, BC, Canada, 28 June–2 July 1998; pp. 135–146. [Google Scholar]
- Hosabettu, R.; Srivas, M.; Gopalakrishnan, G. Decomposing the proof of correctness of pipelined microprocessors. In Proceedings of the International Conference on Computer Aided Verification, Vancouver, BC, Canada, 28 June–2 July 1998; pp. 122–134. [Google Scholar]
- Hosabettu, R.; Srivas, M.; Gopalakrishnan, G. Proof of correctness of a processor with reorder buffer using the completion functions approach. In Proceedings of the International Conference on Computer Aided Verification, Trento, Italy, 6–10 July 1999; pp. 47–59. [Google Scholar]
- Burch, J.R.; Dill, D.L. Automatic verification of pipelined microprocessor control. In Proceedings of the International Conference on Computer Aided Verification, Stanford, CA, USA, 21–23 June 1994; pp. 68–80. [Google Scholar]
- Skakkebæk, J.U.; Jones, R.B.; Dill, D.L. Formal verification of out-of-order execution using incremental flushing. In Proceedings of the International Conference on Computer Aided Verification, Vancouver, BC, Canada, 28 June–2 July 1998; pp. 98–109. [Google Scholar]
- McMillan, K.L. Verification of an implementation of Tomasulo’s algorithm by compositional model checking. In Proceedings of the International Conference on Computer Aided Verification, Vancouver, BC, Canada, 28 June–2 July 1998; pp. 110–121. [Google Scholar]
- Goel, A.; Sajid, K.; Zhou, H.; Aziz, A.; Singhal, V. BDD based procedures for a theory of equality with uninterpreted functions. In Proceedings of the International Conference on Computer Aided Verification, Vancouver, BC, Canada, 28 June–2 July 1998; pp. 244–255. [Google Scholar]
- Berezin, S.; Clarke, E.; Biere, A.; Zhu, Y. Verification of out-of-order processor designs using model checking and a light-weight completion function. Form. Methods Syst. Des. 2002, 20, 159–186. [Google Scholar] [CrossRef]
- Cadar, C.; Dunbar, D.; Engler, D.R. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs. In Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’08), San Diego, CA, USA, 8–10 December 2008; Volume 8, pp. 209–224. [Google Scholar]
- Godefroid, P.; Levin, M.Y.; Molnar, D. SAGE: Whitebox fuzzing for security testing. Commun. ACM 2012, 55, 40–44. [Google Scholar] [CrossRef]
- Suh, G.E.; Lee, J.W.; Zhang, D.; Devadas, S. Secure program execution via dynamic information flow tracking. In Proceedings of the 11th International Conference on Architectural Support for Programming Languages and Operating Systems, Boston, MA, USA, 7–13 October 2004; Volume 39, pp. 85–96. [Google Scholar]
- Tiwari, M.; Wassel, H.M.; Mazloom, B.; Mysore, S.; Chong, F.T.; Sherwood, T. Complete information flow tracking from the gates up. In Proceedings of the 14th International Conference on Architectural Support for Programming Languages and Operating Systems, Washington, DC, USA, 7–11 March 2009; Volume 44, pp. 109–120. [Google Scholar]
- Subramanyan, P.; Malik, S.; Khattri, H.; Maiti, A.; Fung, J. Verifying information flow properties of firmware using symbolic execution. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 337–342. [Google Scholar]
- Subramanyan, P.; Arora, D. Formal verification of taint-propagation security properties in a commercial SoC design. In Proceedings of the conference on Design, Automation & Test in Europe, Dresden, Germany, 24–28 March 2014; p. 313. [Google Scholar]
- Cabodi, G.; Camurati, P.; Finocchiaro, S.; Loiacono, C.; Savarese, F.; Vendraminetto, D. Secure embedded architectures: Taint properties verification. In Proceedings of the 2016 International Conference on Development and Application Systems (DAS), Suceava, Romania, 19–21 May 2016; pp. 150–157. [Google Scholar]
- Ardeshiricham, A.; Hu, W.; Marxen, J.; Kastner, R. Register transfer level information flow tracking for provably secure hardware design. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1691–1696. [Google Scholar]
- Cabodi, G.; Camurati, P.; Finocchiaro, S.F.; Savarese, F.; Vendraminetto, D. Embedded systems secure path verification at the hardware/software interface. IEEE Des. Test 2017, 34, 38–46. [Google Scholar] [CrossRef]
- Tomasulo, R.M. An efficient algorithm for exploiting multiple arithmetic units. IBM J. Res. Dev. 1967, 11, 25–33. [Google Scholar] [CrossRef]
- Jhala, R.; McMillan, K.L. Microarchitecture verification by compositional model checking. In Proceedings of the International Conference on Computer Aided Verification, Paris, France, 18–22 July 2001; pp. 396–410. [Google Scholar]
- Manolios, P.; Srinivasan, S.K. A complete compositional reasoning framework for the efficient verification of pipelined machines. In Proceedings of the 2005 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 6–10 November 2005; pp. 863–870. [Google Scholar]
- Biere, A.; Heljanko, K.; Wieringa, S. AIGER 1.9 and Beyond. 2011. Available online: fmv.jku.at/hwmcc11/beyond1.pdf (accessed on 18 September 2019).
- Cabodi, G.; Nocco, S.; Quer, S. Benchmarking a model checker for algorithmic improvements and tuning for performance. Form. Methods Syst. Des. 2011, 39, 205–227. [Google Scholar] [CrossRef]
- Cabodi, G.; Camurati, P.; Garcia, L.; Murciano, M.; Nocco, S.; Quer, S. Speeding up Model Checking by Exploiting Explicit and Hidden Verification Constraints. In Proceedings of the Conference on Design, Automation and Test in Europe (DATE 2009), Nice, France, 20–24 April 2009; pp. 1686–1691. [Google Scholar]
- Cabodi, G.; Nocco, S.; Quer, S. Strengthening Model Checking Techniques With Inductive Invariants. IEEE Trans. CAD Integr. Circuits Syst. 2009, 28, 154–158. [Google Scholar] [CrossRef]
- Cabodi, G.; Nocco, S. Optimized Model Checking of Multiple Properties. In Proceedings of the Design, Automation and Test in Europe (DATE 2011), Grenoble, France, 14–18 March 2011; pp. 543–546. [Google Scholar]
- Cabodi, G.; Palena, M.; Pasini, P. Interpolation with Guided Refinement: Revisiting Incrementality in SAT-based Unbounded Model Checking. In Proceedings of the 2014 Formal Methods in Computer-Aided Design (FMCAD), Lausanne, Switzerland, 21–24 October 2014; pp. 43–50. [Google Scholar]
- Cabodi, G.; Loiacono, C.; Vendraminetto, D. Optimization techniques for Craig Interpolant compaction in Unbounded Model Checking. In Proceedings of the 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 1417–1422. [Google Scholar]



{kind=link}
{kind=link}
| Register | Concrete | Abstract |
|---|---|---|
| ⋮ | ⋮ | ⋮ |
| Concrete | Abstract | |
|---|---|---|
| Data abstraction + Tainting | ||
| Data evaluation | ||
| Taint propagation | - |
| Instruction | Symbolic | Concrete |
|---|---|---|

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cabodi, G.; Camurati, P.; Finocchiaro, F.; Vendraminetto, D. Model-Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification. Electronics 2019, 8, 1057. https://doi.org/10.3390/electronics8091057
Cabodi G, Camurati P, Finocchiaro F, Vendraminetto D. Model-Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification. Electronics. 2019; 8(9):1057. https://doi.org/10.3390/electronics8091057
Chicago/Turabian StyleCabodi, Gianpiero, Paolo Camurati, Fabrizio Finocchiaro, and Danilo Vendraminetto. 2019. "Model-Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification" Electronics 8, no. 9: 1057. https://doi.org/10.3390/electronics8091057
APA StyleCabodi, G., Camurati, P., Finocchiaro, F., & Vendraminetto, D. (2019). Model-Checking Speculation-Dependent Security Properties: Abstracting and Reducing Processor Models for Sound and Complete Verification. Electronics, 8(9), 1057. https://doi.org/10.3390/electronics8091057