Salient Object Detection Combining a Self-Attention Module and a Feature Pyramid Network



Abstract
:1. Introduction
2. Related Works
2.1. Salient Object Detection
2.2. Attention Mechanism
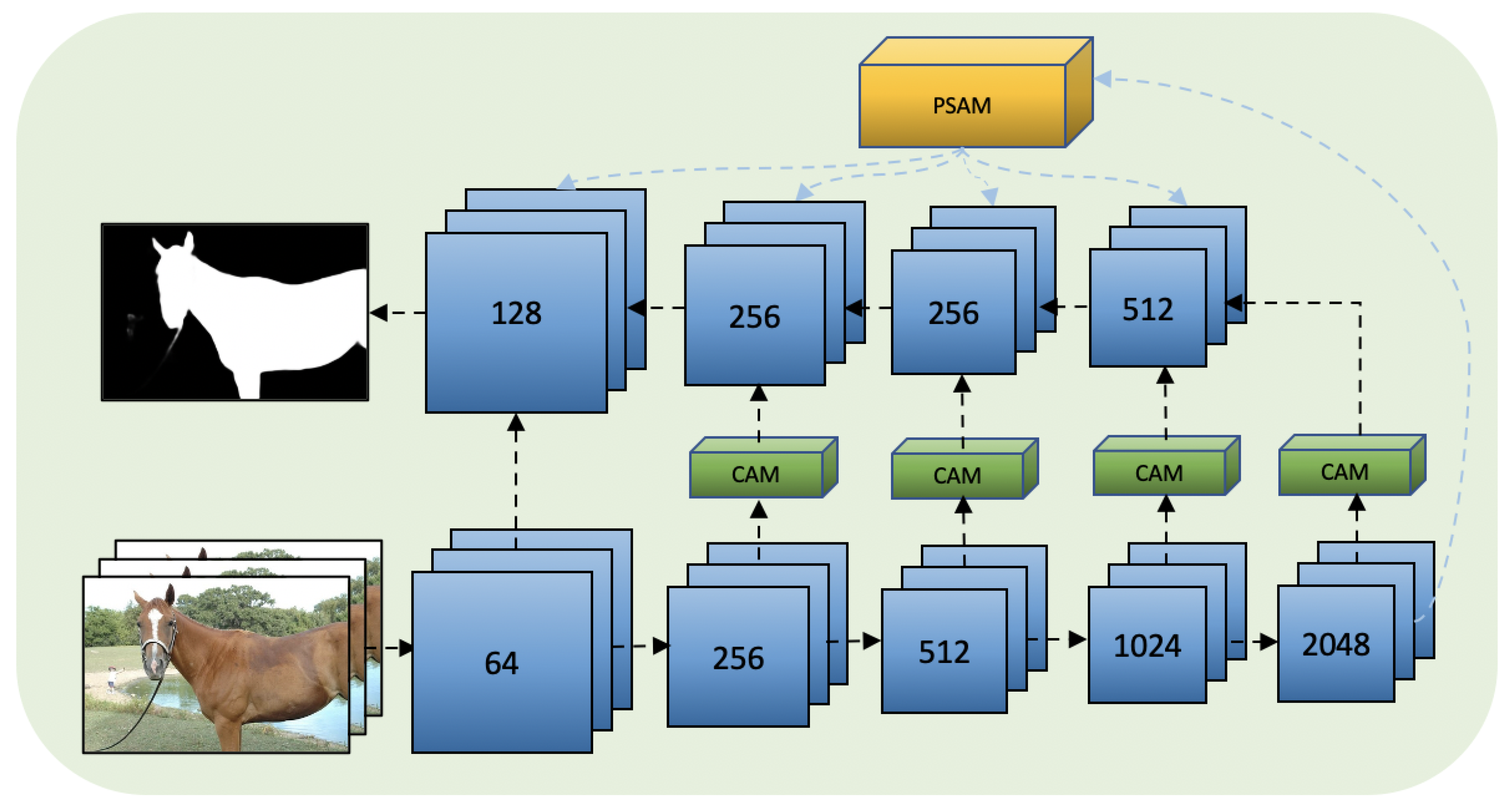
3. The Proposed Method
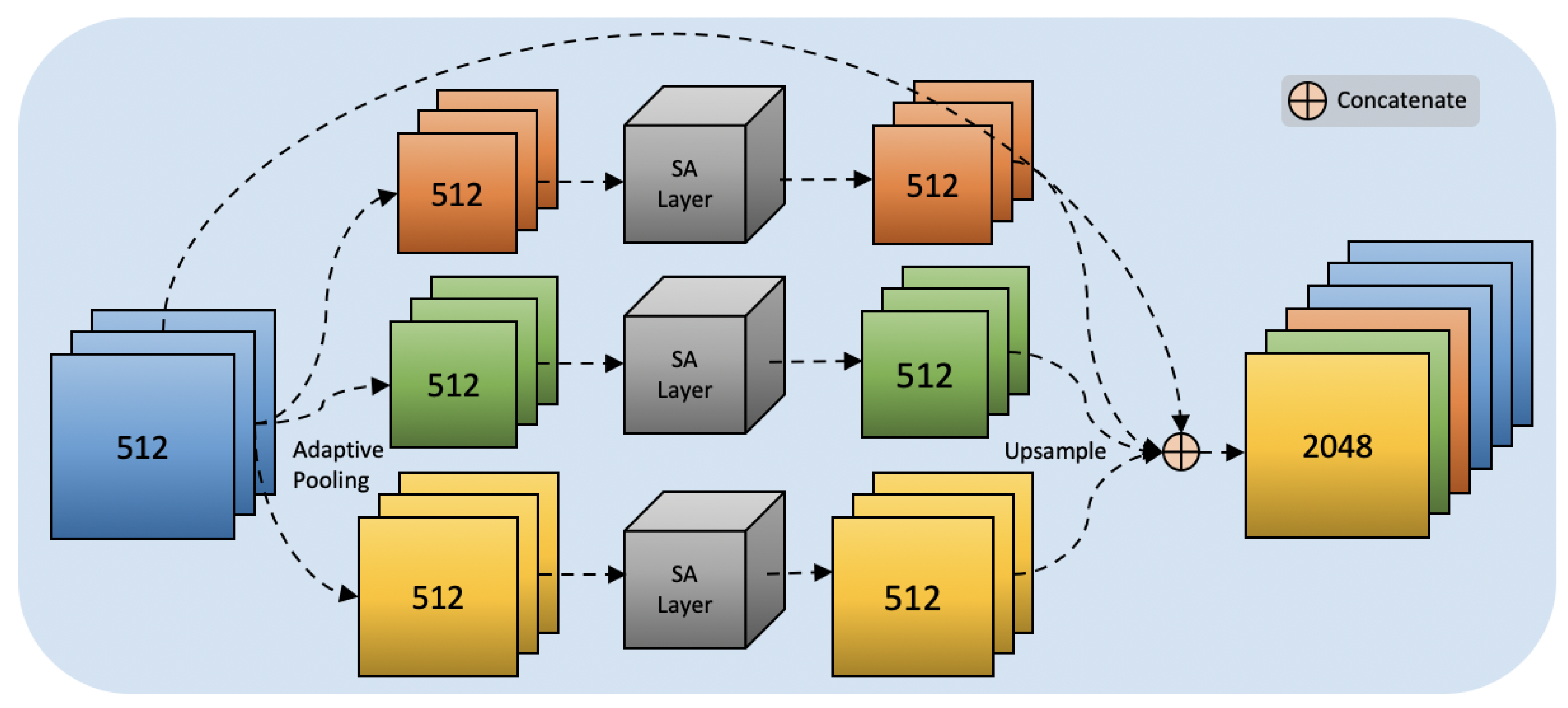
3.1. Pyramid Self-Attention Module
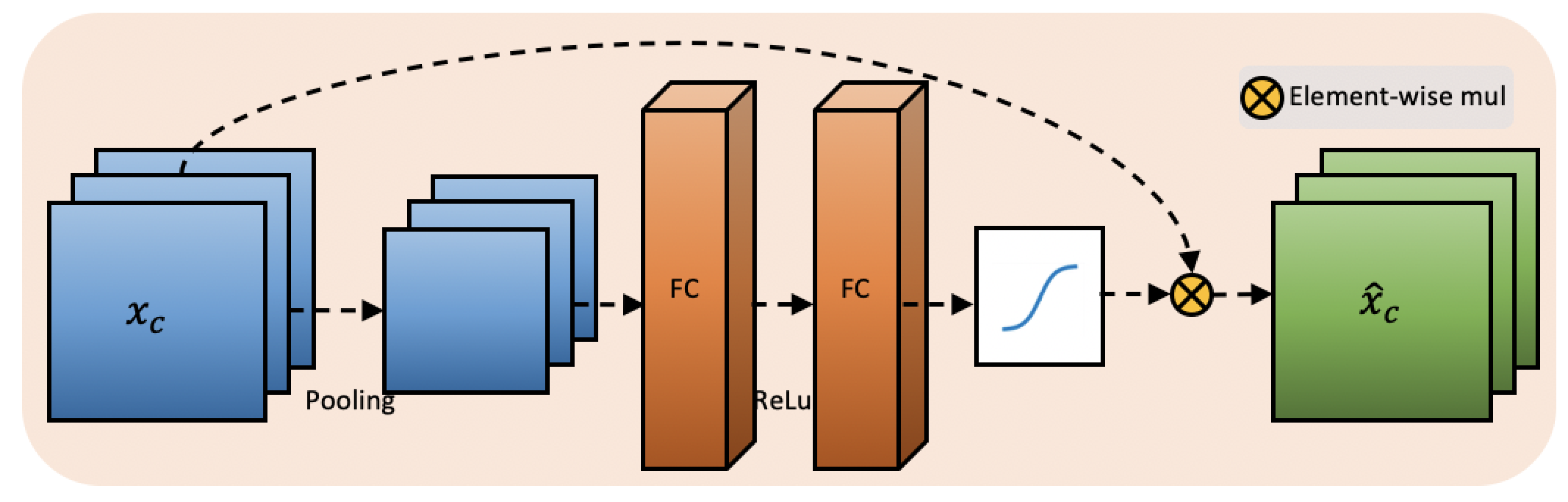
3.2. Channel-Wise Attention
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Impelmentation Details
4.3. Comparisons with State-of-the-Arts
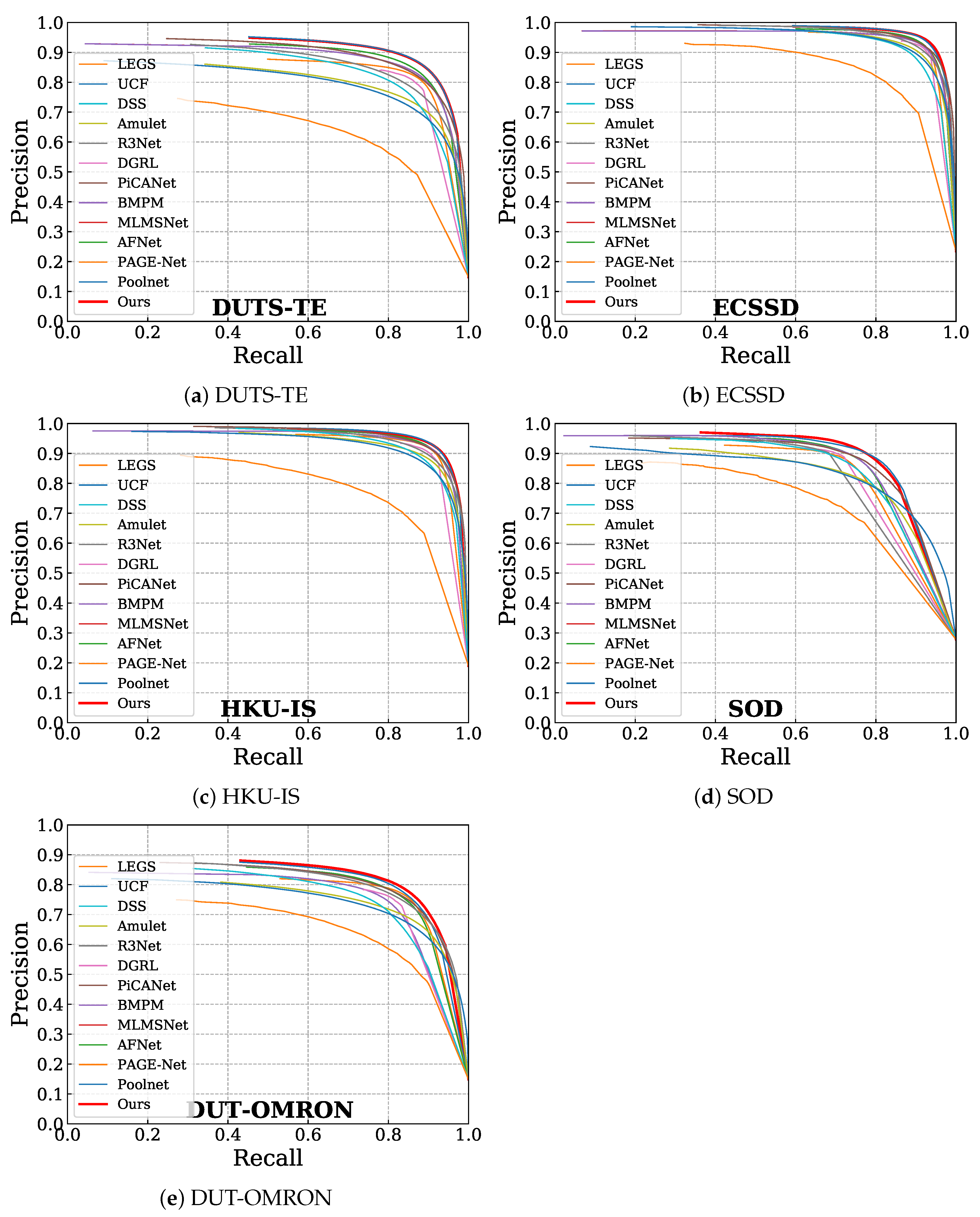
4.3.1. Quantitative Comparisons
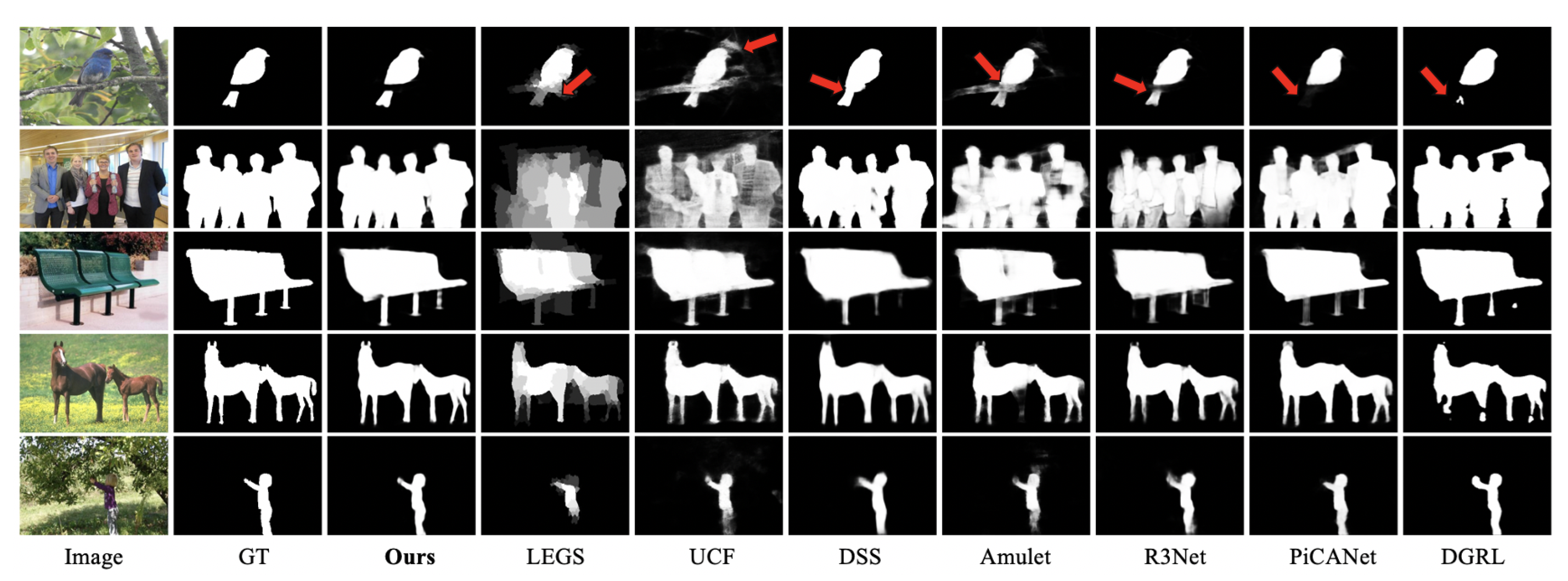
4.3.2. Qualitative Comparisons
4.4. Ablation Study
5. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Liu, T.; Huang, J.-J.; Dai, T.; Ren, G.; Stathaki, T. Gated multi-layer convolutional feature extraction network for robust pedestrian detection. arXiv 2019, arXiv:1910.11761. [Google Scholar]
- Ren, Z.; Gao, S.; Chia, L.-T.; Tsang, I.W.-H. Region-based saliency detection and its application in object recognition. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 769–779. [Google Scholar] [CrossRef]
- Zhang, D.; Meng, D.; Zhao, L.; Han, J. Bridging saliency detection to weakly supervised object detection based on self-paced curriculum learning. arXiv 2017, arXiv:1703.01290. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Schillaci, G.; Bodiroža, S.; Hafner, V.V. Evaluating the effect of saliency detection and attention manipulation in human-robot interaction. Int. J. Soc. Robot. 2013, 5, 139–152. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Yue, J.; Zhang, Y. Rgb-d saliency detection: Dataset and algorithm for robot vision. In Proceedings of the International Conference on Robotics and Biomimetics, Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1028–1033. [Google Scholar]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1354–1362. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Ma, Y.-F.; Lu, L.; Zhang, H.-J.; Li, M. A user attention model for video summarization. In Proceedings of the International Conference on Multimedia. 2002, pp. 533–542. Available online: https://dl.acm.org/doi/abs/10.1145/641007.641116 (accessed on 1 September 2020).
- Simakov, D.; Caspi, Y.; Shechtman, E.; Irani, M. Summarizing visual data using bidirectional similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.-M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2014, 5, 117–150. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3917–3926. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 7479–7489. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1448–1457. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3907–3916. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Morgan Kaufmann Pub: Burlington, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. arXiv 2019, arXiv:1906.05909. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 7132–7141. Available online: https://arxiv.org/abs/1709.01507 (accessed on 1 September 2020).
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. arXiv 2019, arXiv:1903.00179. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 815–828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Movahedi, V.; Elder, J.H. Design and perceptual validation of performance measures for salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–27 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann Pub: Burlington, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3183–3192. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning uncertain convolutional features for accurate saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 212–221. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.-A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3127–3135. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.-H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A bi-directional message passing model for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1741–1750. [Google Scholar]
- Wu, R.; Feng, M.; Guan, W.; Wang, D.; Lu, H.; Ding, E. A mutual learning method for salient object detection with intertwined multi-supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 January 2019; pp. 8150–8159. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1623–1632. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | DUTS-TE | ECSSD | HKU-IS | SOD | DUT-OMRON | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F-Score | MAE | F-Score | MAE | F-Score | MAE | F-Score | MAE | F-Score | MAE | |
| LEGS [38] | 0.654 | 0.138 | 0.827 | 0.118 | 0.770 | 0.118 | 0.733 | 0.196 | 0.669 | 0.133 |
| UCF [39] | 0.771 | 0.117 | 0.910 | 0.078 | 0.888 | 0.074 | 0.803 | 0.164 | 0.734 | 0.132 |
| DSS [29] | 0.813 | 0.064 | 0.907 | 0.062 | 0.900 | 0.050 | 0.837 | 0.126 | 0.760 | 0.074 |
| Amulet [40] | 0.778 | 0.085 | 0.914 | 0.059 | 0.897 | 0.051 | 0.806 | 0.141 | 0.743 | 0.098 |
| R3Net [41] | 0.824 | 0.066 | 0.924 | 0.056 | 0.910 | 0.047 | 0.840 | 0.136 | 0.788 | 0.071 |
| PiCANet [43] | 0.851 | 0.054 | 0.931 | 0.046 | 0.922 | 0.042 | 0.853 | 0.102 | 0.794 | 0.068 |
| DGRL [42] | 0.828 | 0.050 | 0.922 | 0.041 | 0.910 | 0.036 | 0.845 | 0.104 | 0.774 | 0.062 |
| BMPM [44] | 0.851 | 0.048 | 0.928 | 0.045 | 0.920 | 0.039 | 0.855 | 0.107 | 0.774 | 0.064 |
| PAGE-Net [16] | 0.838 | 0.051 | 0.931 | 0.042 | 0.920 | 0.036 | 0.841 | 0.111 | 0.791 | 0.062 |
| MLMSNet [45] | 0.852 | 0.048 | 0.928 | 0.045 | 0.920 | 0.039 | 0.855 | 0.107 | 0.774 | 0.064 |
| AFNet [46] | 0.863 | 0.045 | 0.935 | 0.042 | 0.925 | 0.036 | 0.856 | 0.109 | 0.797 | 0.057 |
| PoolNet [45] | 0.880 | 0.040 | 0.944 | 0.039 | 0.933 | 0.032 | 0.870 | 0.101 | 0.803 | 0.056 |
| Ours | 0.879 | 0.040 | 0.944 | 0.038 | 0.931 | 0.034 | 0.874 | 0.104 | 0.813 | 0.056 |
| Method | DUTS-TE | ECSSD | HKU-IS | SOD | DUT-OMRON | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F-Score | MAE | F-Score | MAE | F-Score | MAE | F-Score | MAE | F-Score | MAE | |
| Baseline | 0.856 | 0.045 | 0.933 | 0.045 | 0.921 | 0.037 | 0.848 | 0.116 | 0.785 | 0.059 |
| Baseline+PSAM | 0.876 | 0.041 | 0.940 | 0.042 | 0.928 | 0.034 | 0.857 | 0.121 | 0.803 | 0.056 |
| Baseline+PSAM+CA | 0.879 | 0.040 | 0.944 | 0.038 | 0.931 | 0.034 | 0.874 | 0.104 | 0.813 | 0.056 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, G.; Dai, T.; Barmpoutis, P.; Stathaki, T. Salient Object Detection Combining a Self-Attention Module and a Feature Pyramid Network. Electronics 2020, 9, 1702. https://doi.org/10.3390/electronics9101702
Ren G, Dai T, Barmpoutis P, Stathaki T. Salient Object Detection Combining a Self-Attention Module and a Feature Pyramid Network. Electronics. 2020; 9(10):1702. https://doi.org/10.3390/electronics9101702
Chicago/Turabian StyleRen, Guangyu, Tianhong Dai, Panagiotis Barmpoutis, and Tania Stathaki. 2020. "Salient Object Detection Combining a Self-Attention Module and a Feature Pyramid Network" Electronics 9, no. 10: 1702. https://doi.org/10.3390/electronics9101702
APA StyleRen, G., Dai, T., Barmpoutis, P., & Stathaki, T. (2020). Salient Object Detection Combining a Self-Attention Module and a Feature Pyramid Network. Electronics, 9(10), 1702. https://doi.org/10.3390/electronics9101702