GC-YOLOv3: You Only Look Once with Global Context Block

Abstract
:1. Introduction
2. Related Works
2.1. Object Detection
2.2. Self-Attention Algorithm
2.3. Semantic Fusion
3. The Proposed Method
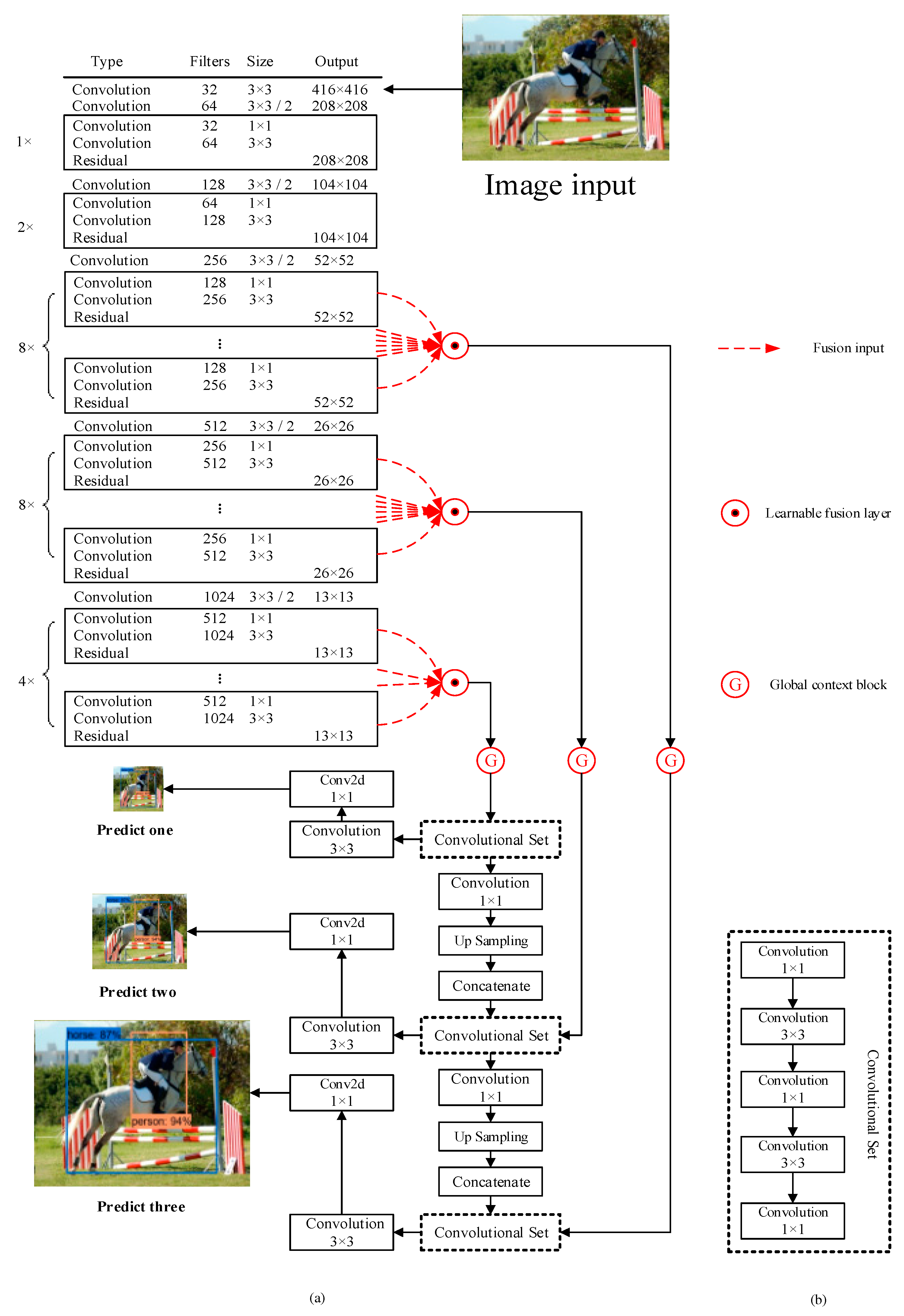
3.1. GC-YOLOv3
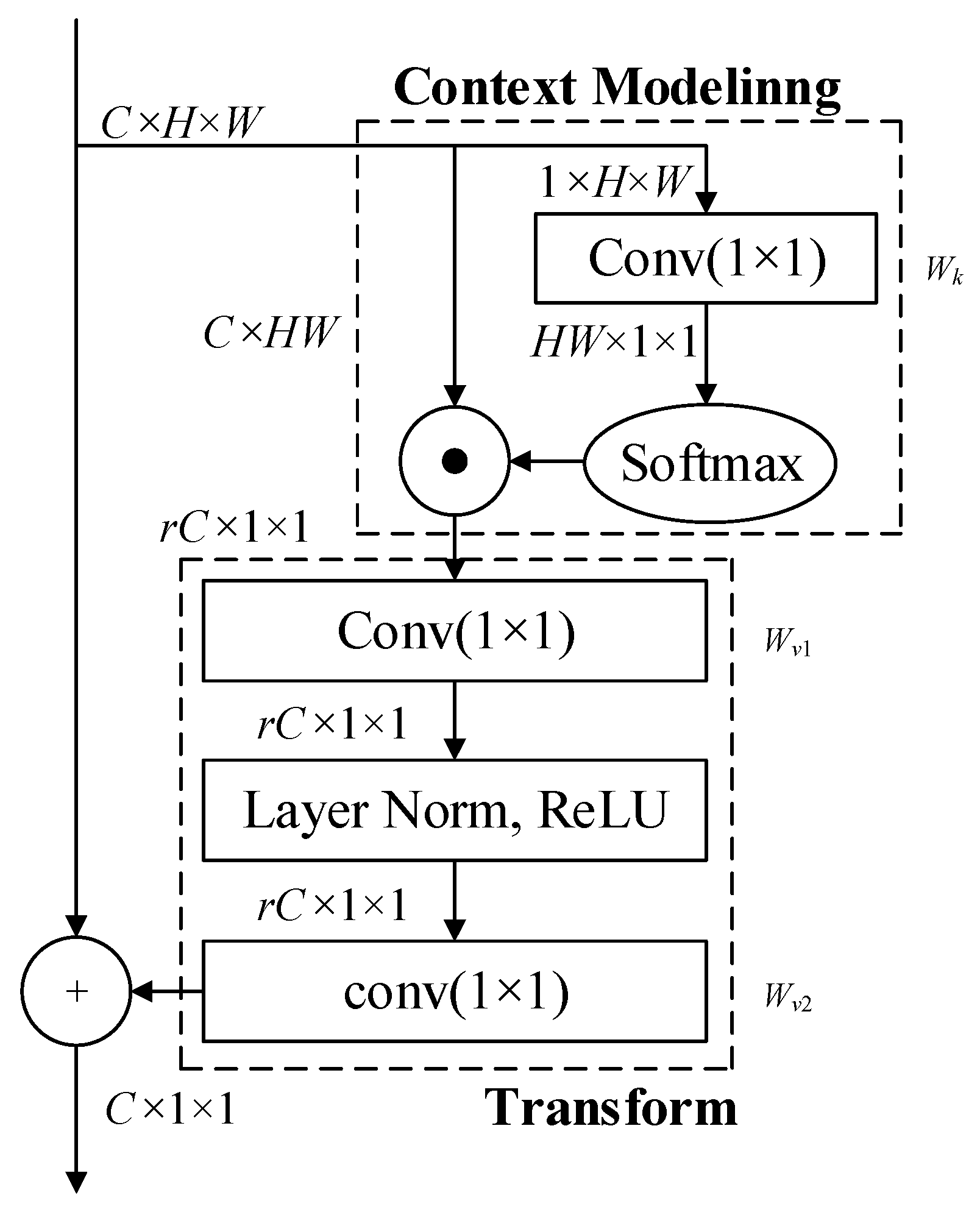
3.2. Global Context Block
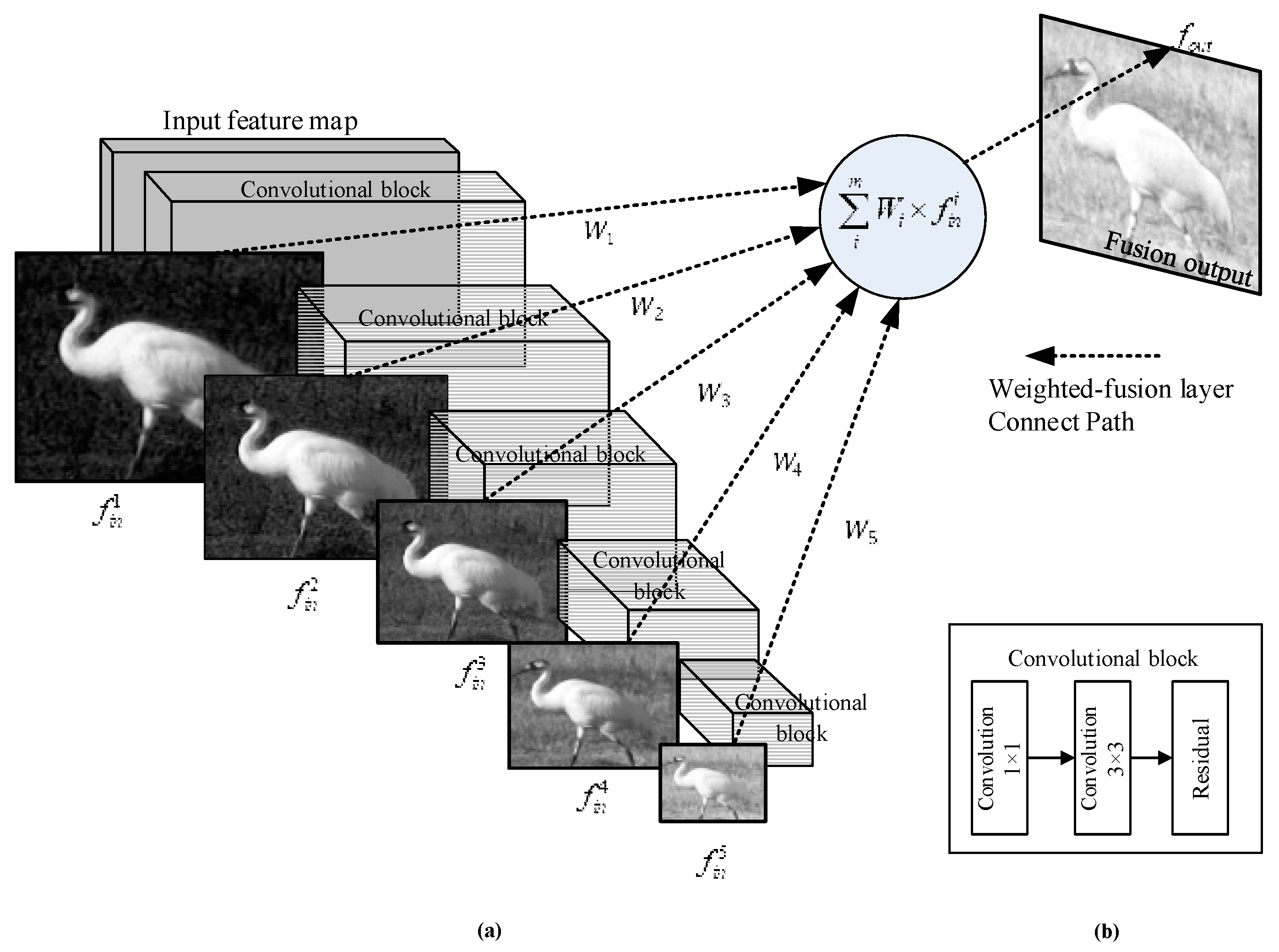
3.3. Learnable Semantic Fusion
4. Implementation
4.1. Dataset
4.2. Data Augmentation
4.3. Network Setting
5. Experiments
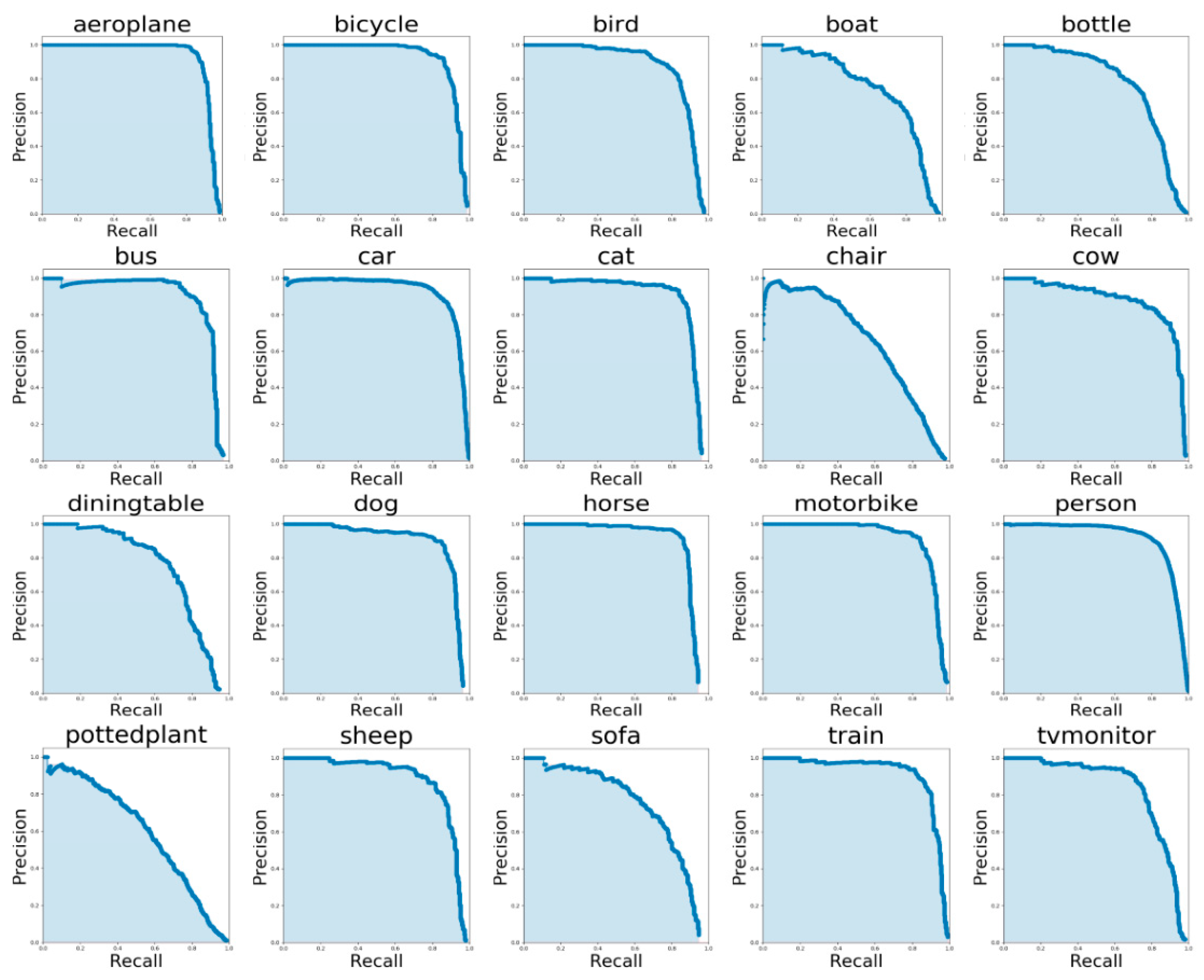
5.1. Ablation Study on PASCAL VOC 2007
5.2. Performance Improvement on PASCAL VOC 2007
5.3. Performance Improvement on COCO Dataset
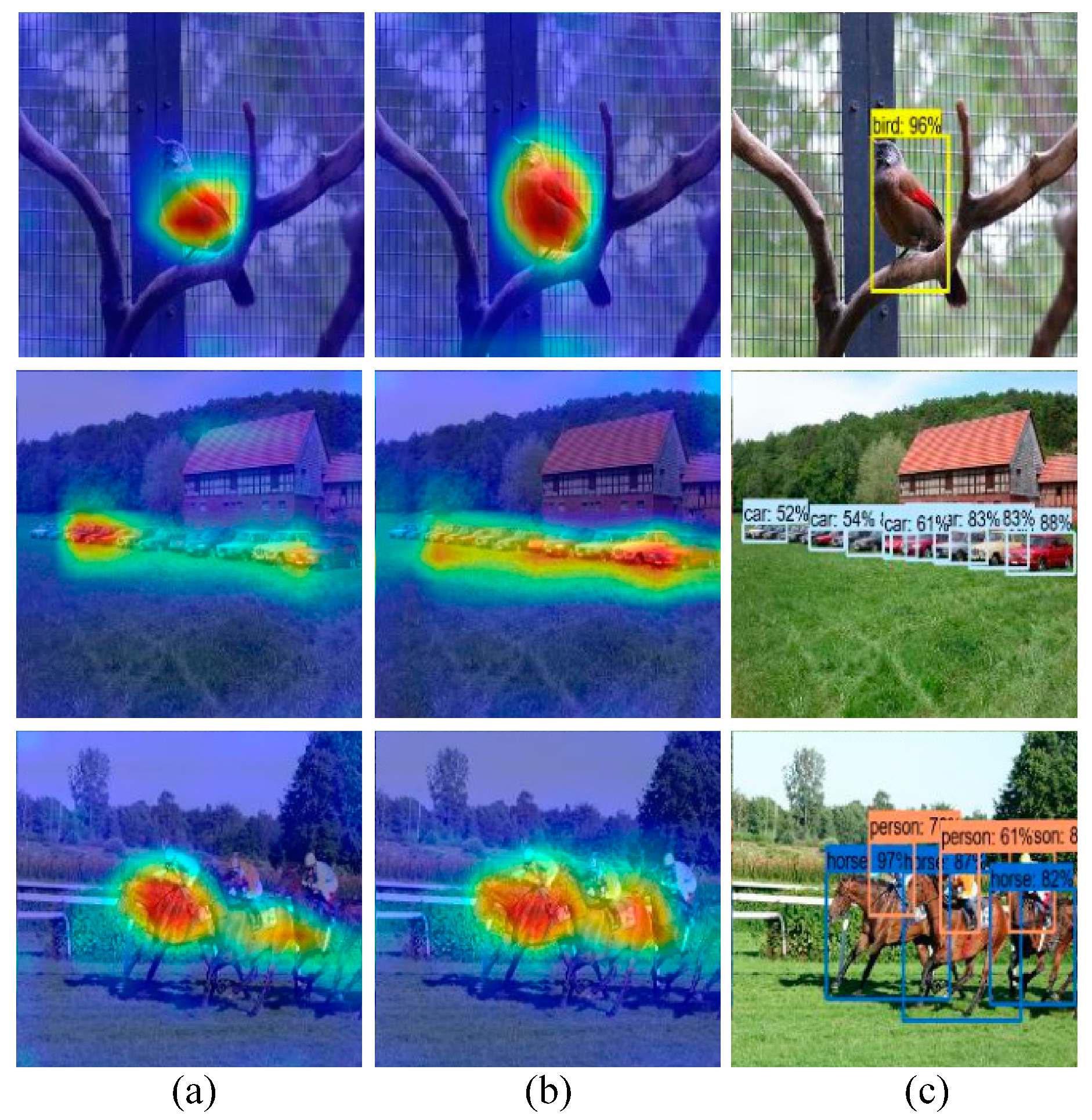
5.4. Attention Mechanism Visualization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 2, 2553–2561. [Google Scholar]
- Mortensen, E.N.; Den, H.; Shapiro, L.G. A SIFT descriptor with global context. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Viola, P.A.; Jones, M.J. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1137–1149. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26–21 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Lee, H.; Kwon, H.; Robinson, R.M.; Nothwang, W.D.; Marathe, A.M. Dynamic belief fusion for object detection. In Proceedings of the WACV 2016: IEEE Winter Conference on Application of Computer Vision, Lake Placid, NY, USA, 7–9 March 2016; pp. 1–9. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2016, arXiv:1701.06659. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J. DSOD: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1919–1927. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS: Improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wang, L.J.; Ouyang, W.L.; Wang, X.G. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26–21 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll´ar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Ana. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition Workshop, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.-F.; Shi, J.P.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Ana. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.X.; Wang, W.J.; Zhu, Y.K.; Pang, R.M.; Vasudevan, V. Searching for MobileNetV3. In Proceedings of the the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Misra, D. Mish: A self-regularized nonmonotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 336–359. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | Performance | Limitation |
|---|---|---|
| Non-local network [11] | High accuracy by using self-attention mechanism [18] | Complex computations and parameters |
| Direct fusion [12] | High accuracy by concatenating different feature maps at different levels [19] | Some internal information lost |
| Deconvolutional Single Shot Detector (DSSD) [13] | High accuracy by deepening the ResNet-101 [14] network | Too many parameters and computations |
| Deeply Supervised Object Detector (DSOD) [15] | High accuracy by taking the DenseNet [16] network as an example | Wide network |
| Soft Non-Maximum Suppression (NMS) [17] | High accuracy by reducing the confidence of scoring boxes | Valid information lost |
| Dataset | COCO 2017 | PASCAL VOC (07 + 12) |
|---|---|---|
| Number of categories | 80 | 20 |
| Number of training pictures | 117,264 | 16,551 |
| Number of testing pictures | 5000 | 4952 |
| Total sample boxes | 902,435 | 52,090 |
| Total sample boxes / total number of images | 7.4 | 2.4 |
| Type | Parameter |
|---|---|
| HSV Saturation | 50% probability |
| HSV Intensity | 50% probability |
| Random Crop | 50% probability |
| Random Affine | 50% probability |
| Random Horizontal Flip | 50% probability |
| Method | Backbone | Global Context Block | Learnable Fusion | Time (ms) | mAP (%) |
|---|---|---|---|---|---|
| YOLOv3 | Darknet53 | 25.14 | 78.6 | ||
| YOLOv3 | Darknet53 | √ | 27.18 | 80.1 | |
| YOLOv3 | Darknet53 | √ | 30.47 | 81.2 | |
| YOLOv3 | Darknet53 | √ | √ | 32.25 | 83.7 |
| Method | Backbone | Train Data | mAP | Size | FPS | GPU |
|---|---|---|---|---|---|---|
| Faster R-CNN [7] | VGG16 | 07 + 12 | 73.2 | 1000 × 600 | 7 | Titan X |
| Faster R-CNN [7] | ResNet101 | 07 + 12 | 76.4 | 1000 × 600 | 2.4 | K40 |
| R-FCN [24] | ResNet101 | 07 + 12 | 79.5 | 1000 × 600 | 9 | Titan X |
| RetinaNet300 [25] | ResNet101 | 07 + 12 | 62.9 | 300 × 300 | 11.4 | K80 |
| RefineDet320 [25] | ResNet101 | 07 + 12 | 79.5 | 320 × 320 | 12.9 | K80 |
| SSD300 [10] | VGG16 | 07 + 12 | 77.1 | 300 × 300 | 46 | Titan X |
| SSD321 [10] | VGG16 | 07 + 12 | 77.5 | 320 × 320 | 11.2 | Titan X |
| YOLOv3 [21] | Darknet53 | 07 + 12 | 74.5 | 320 × 320 | 45.5 | Titan X |
| GC-YOLOv3 | Darknet53 | 07 + 12 | 81.3 | 320 × 320 | 39 | 1080Ti |
| RetinaNet500 [25] | ResNet101 | 07 + 12 | 72.2 | 500 × 500 | 7.1 | K80 |
| RefineDet512 [25] | VGG16 | 07 + 12 | 81.2 | 512 × 512 | 5.6 | K80 |
| SSD512 [10] | VGG16 | 07 + 12 | 79.5 | 512 × 512 | 19 | Titan X |
| SSD513 [10] | ResNet101 | 07 + 12 | 80.6 | 513 × 513 | 6.8 | Titan X |
| YOLOv3 [21] | Darknet53 | 07 + 12 | 78.6 | 544 × 544 | 40 | Titan X |
| GC-YOLOv3 | Darknet53 | 07 + 12 | 83.7 | 544 × 544 | 31 | 1080Ti |
| Model | Train Data | Test Data | [email protected] | FPS |
|---|---|---|---|---|
| R-FCN (416) [24] | COCO2017 trainval | COCO2017 test-dev | 51.9 | 12 |
| SSD (300) [10] | COCO2017 trainval | COCO2017 test-dev | 41.2 | 46 |
| SSD (321) [10] | COCO2017 trainval | COCO2017 test-dev | 45.4 | 16 |
| SSD (500) [10] | COCO2017 trainval | COCO2017 test-dev | 46.5 | 19 |
| SSD (513) [10] | COCO2017 trainval | COCO2017 test-dev | 50.4 | 8 |
| DSSD (321) [13] | COCO2017 trainval | COCO2017 test-dev | 46.1 | 12 |
| DSSD (513) [13] | COCO2017 trainval | COCO2017 test-dev | 53.3 | 6 |
| Retinanet-50(500) [25] | COCO2017 trainval | COCO2017 test-dev | 50.9 | 14 |
| Retinanet-101(500) [25] | COCO2017 trainval | COCO2017 test-dev | 53.1 | 11 |
| Retinanet-101(800) [25] | COCO2017 trainval | COCO2017 test-dev | 57.5 | 5 |
| YOLOv2(608) [20] | COCO2017 trainval | COCO2017 test-dev | 48.1 | 40 |
| YOLOv3(416) [21] | COCO2017 trainval | COCO2017 test-dev | 55.3 | 35 |
| YOLOv4(416) [26] | COCO2017 trainval | COCO2017 test-dev | 62.8 | 38 |
| GC-YOLOv3(416) | COCO2017 trainval | COCO2017 test-dev | 55.5 | 28 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Deng, H. GC-YOLOv3: You Only Look Once with Global Context Block. Electronics 2020, 9, 1235. https://doi.org/10.3390/electronics9081235
Yang Y, Deng H. GC-YOLOv3: You Only Look Once with Global Context Block. Electronics. 2020; 9(8):1235. https://doi.org/10.3390/electronics9081235
Chicago/Turabian StyleYang, Yang, and Hongmin Deng. 2020. "GC-YOLOv3: You Only Look Once with Global Context Block" Electronics 9, no. 8: 1235. https://doi.org/10.3390/electronics9081235
APA StyleYang, Y., & Deng, H. (2020). GC-YOLOv3: You Only Look Once with Global Context Block. Electronics, 9(8), 1235. https://doi.org/10.3390/electronics9081235