Efficient Facial Landmark Localization Based on Binarized Neural Networks


Abstract
:1. Introduction
- (1)
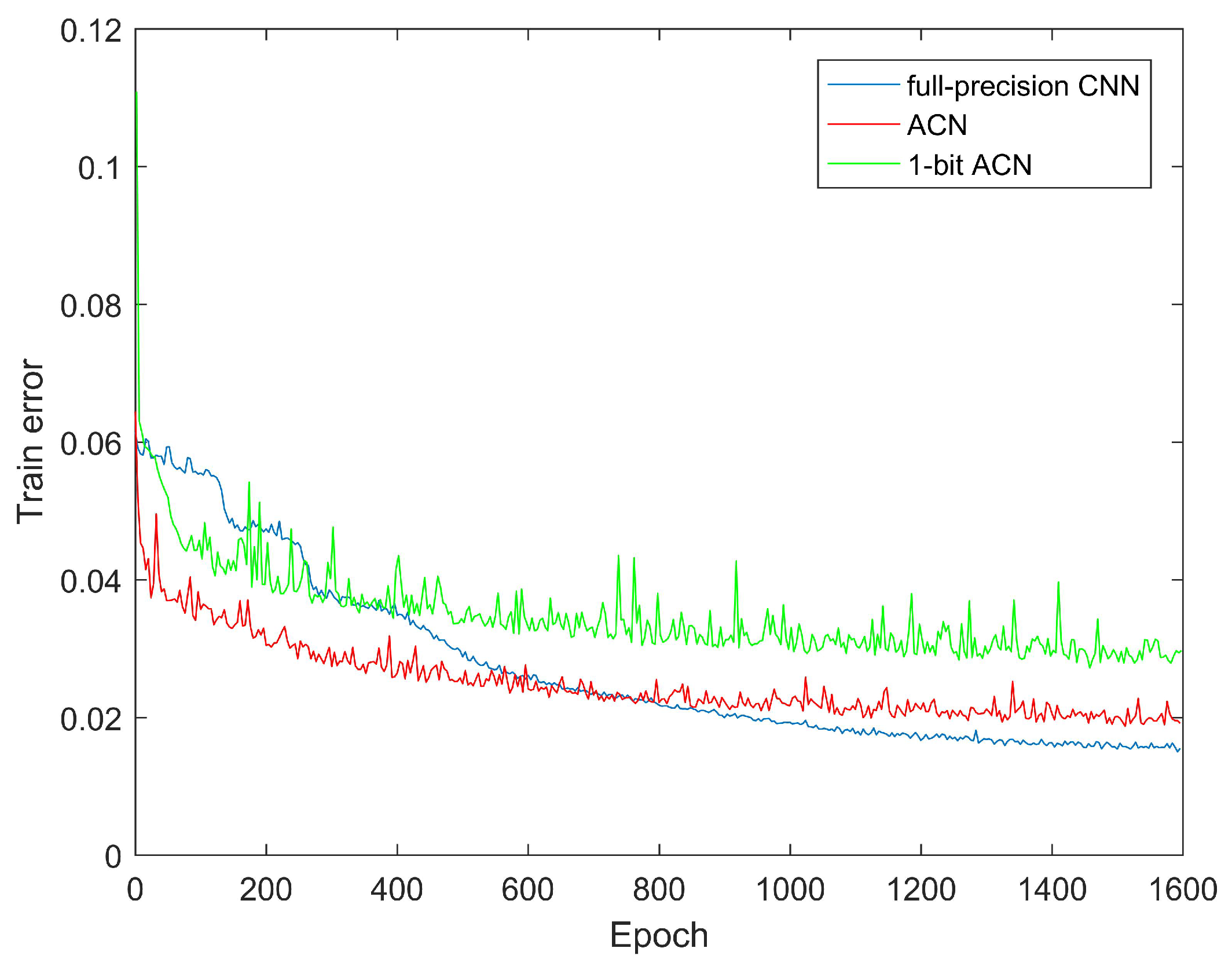
- We propose a new Amplitude Convolutional Network (ACN) for facial landmark localization, to achieve computation efficiency for resource constrained mobile devices, using binarized CNNs.
- (2)
- We design a new asynchronous back propagation algorithm to optimize ACNs efficiently, leading to an extremely compressed 1-bit CNNs model in an end-to-end manner.
- (3)
- ACN achieves comparable facial landmark localization performance compared with its corresponding full-precision CNN model on several benchmark datasets including CelebA, BioID, LFW and Webface.
2. Related Work
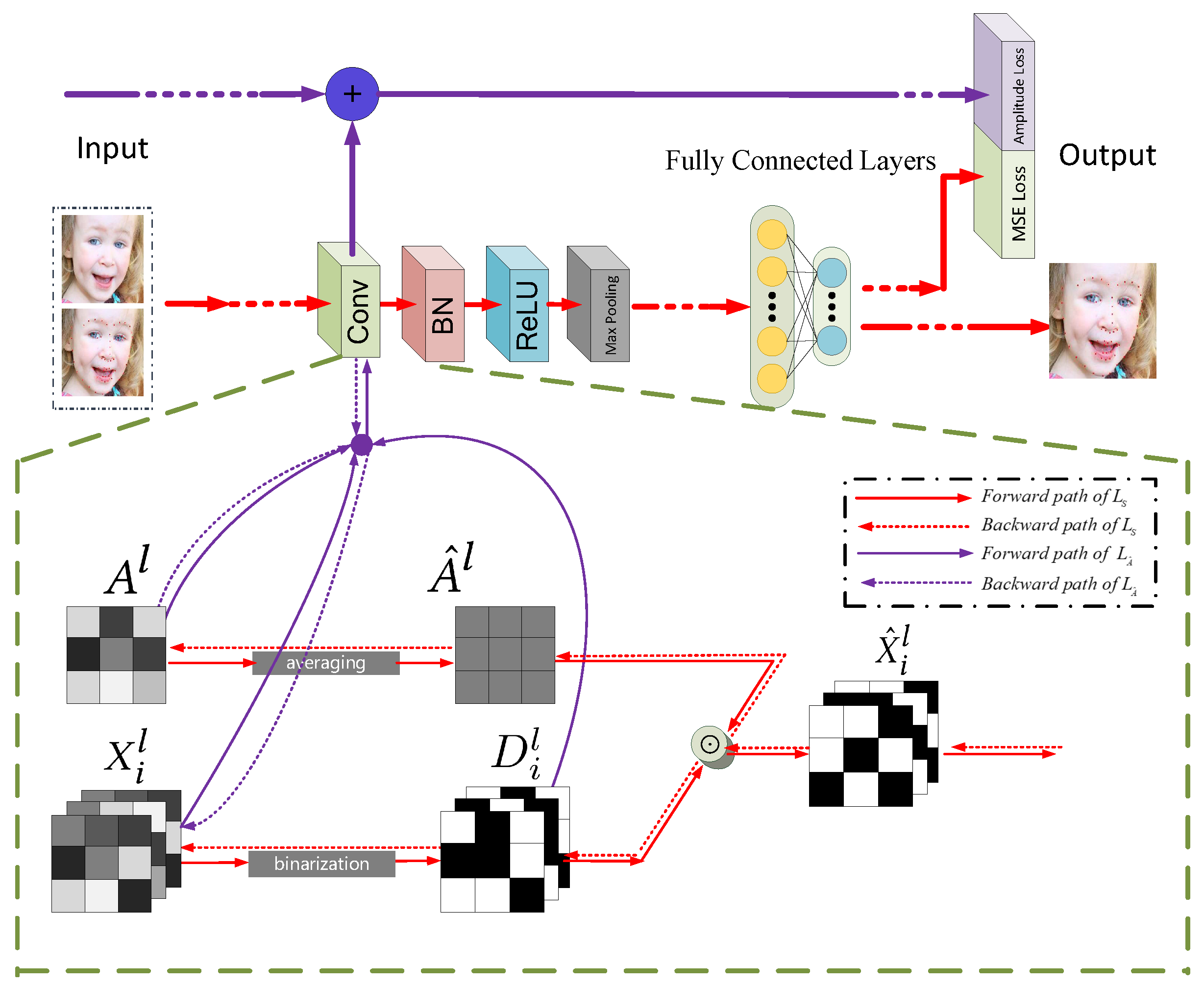
3. Amplitude Convolutional Networks
3.1. Problem Formulation
3.2. Loss Function of ACNs
3.3. Forward Propagation of ACNs
3.4. Back-Propagation Updating
3.4.1. Updating the Full-Precision Kernels
3.4.2. Updating the Amplitude Matrices
| Algorithm 1 Optimization of ACNs with the asynchronous back propagation |
|
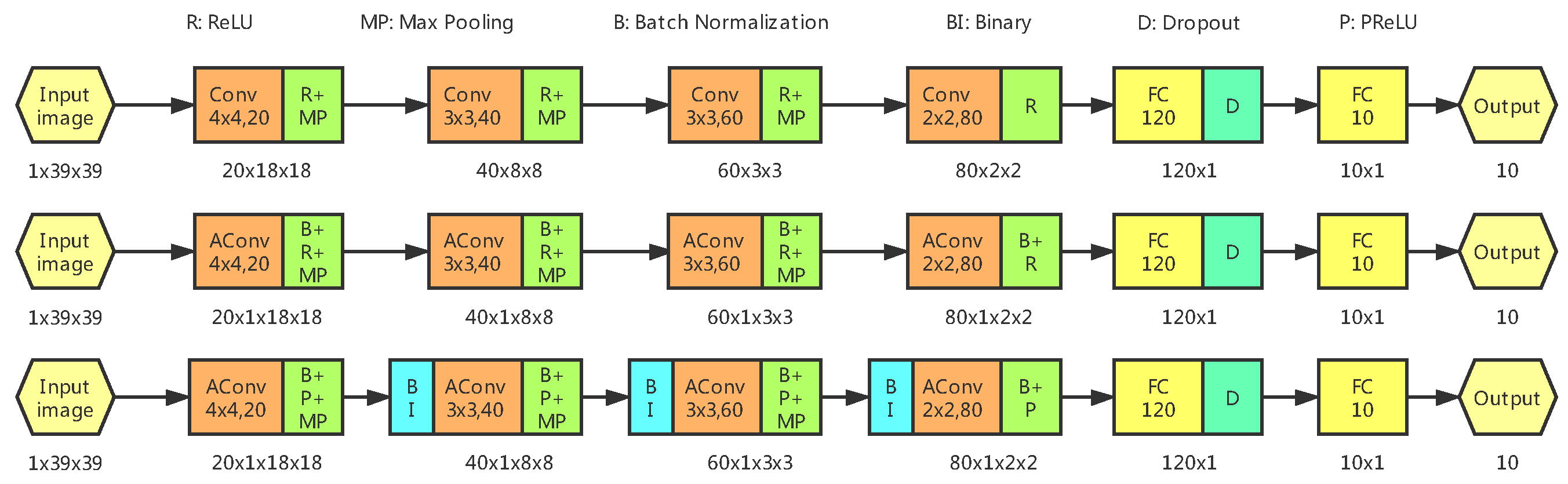
4. Implementation and Experiments
4.1. Datasets and Evaluation Metric
4.2. Implementation Details
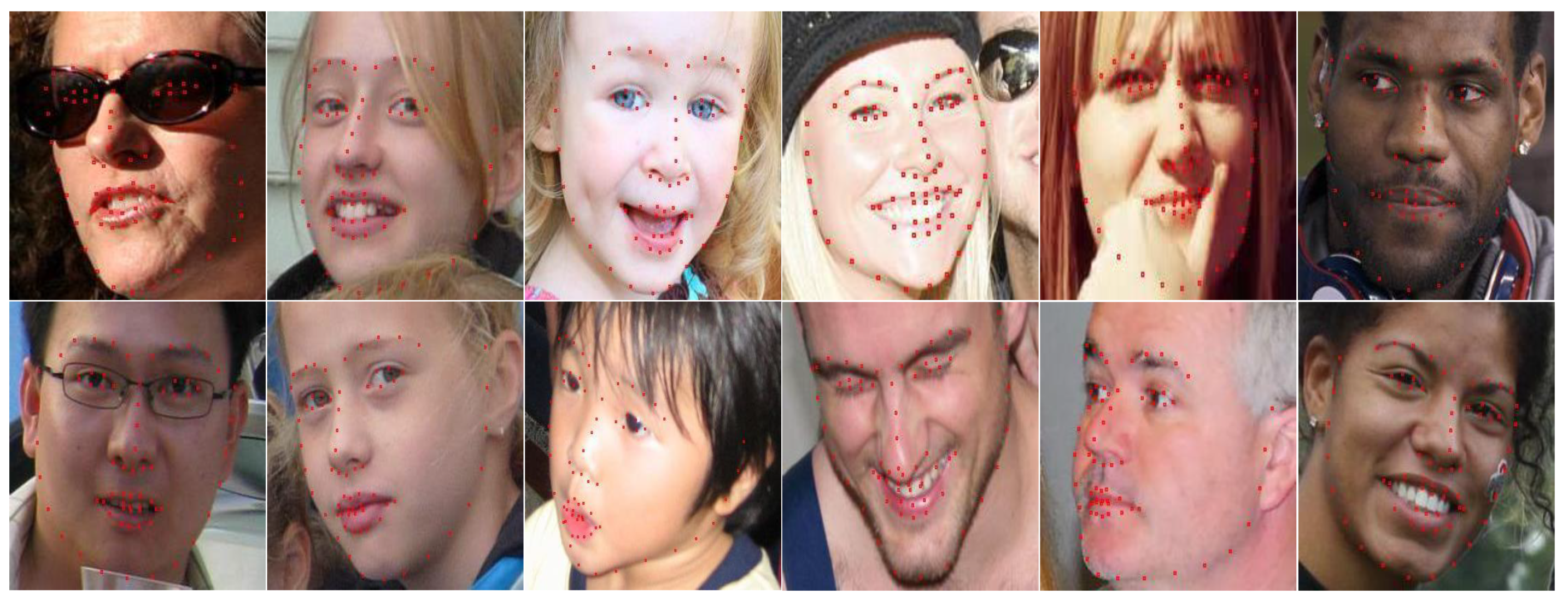
4.3. Results on LFW+Webface, CelebA and BioID
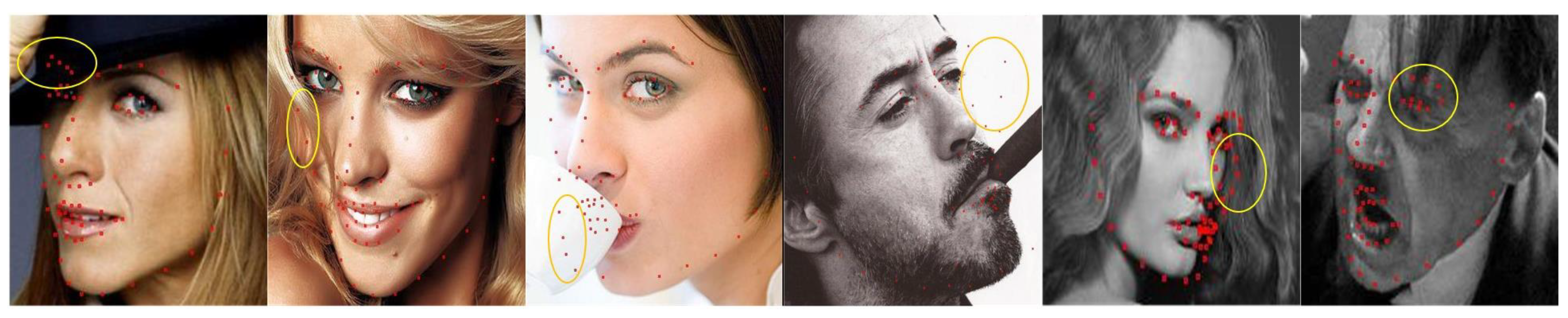
4.4. Results on 300-W
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep alignment network: A convolutional neural network for robust face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Evangelos, S.; Hatice, G.; Andrea, C. Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1113–1133. [Google Scholar]
- Corcoran, P.M.; Nanu, F.; Petrescu, S.; Bigioi, P. Real-time eye gaze tracking for gaming design and consumer electronics systems. IEEE Trans. Consum. Electron. 2012, 58, 347–355. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, P.L.; Ma, C.; Yu, J.; Hao, L. Unconstrained realtime facial performance capture. In Proceedings of the Computer Vision $ Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Yu, Q. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Boureau, Y.-L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented response networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 519–528. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to + 1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.-P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3123–3131. [Google Scholar]
- Juefei-Xu, F.; Boddeti, V.N.; Savvides, M. Local binary convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 19–28. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards accurate binary convolutional neural network. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 345–353. [Google Scholar]
- McDonnell, M.D. Training wide residual networks for deployment using a single bit for each weight. arXiv 2018, arXiv:1802.08530. [Google Scholar]
- Wang, X.; Zhang, B.; Li, C.; Ji, R.; Han, J.; Liu, J.; Cao, X. Modulated convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 840–848. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Matthews, I.; Baker, S. Active appearance models revisited. Int. J. Comput. Vis. 2004, 60, 135–164. [Google Scholar] [CrossRef] [Green Version]
- Cristinacce, D.; Cootes, T.F. Feature detection and tracking with constrained local models. BMVC 2006, 1, 3. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map fitting with constrained local models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3444–3451. [Google Scholar]
- Xiong, X.; la Torre, F.D. Supervised descent method and its applications to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face alignment at 3000 fps via regressing local binary features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1685–1692. [Google Scholar]
- Lee, D.; Park, H.; Yoo, C.D. Face alignment using cascade gaussian process regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4204–4212. [Google Scholar]
- Kowalski, M.; Naruniec, J. Face alignment using k-cluster regression forests with weighted splitting. IEEE Signal Process. Lett. 2016, 23, 1567–1571. [Google Scholar] [CrossRef] [Green Version]
- Tuzel, O.; Marks, T.K.; Tambe, S. Robust face alignment using a mixture of invariant experts. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 825–841. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Zhou, E.; Fan, H.; Cao, Z.; Jiang, Y.; Yin, Q. Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Fan, H.; Zhou, E. Approaching human level facial landmark localization by deep learning. Image Vis. Comput. 2016, 47, 27–35. [Google Scholar] [CrossRef]
- Trigeorgis, G.; Snape, P.; Nicolaou, M.A.; Antonakos, E.; Zafeiriou, S. Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4177–4187. [Google Scholar]
- Xiao, S.; Feng, J.; Xing, J.; Lai, H.; Yan, S.; Kassim, A. Robust facial landmark detection via recurrent attentive-refinement networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 57–72. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Two-stage convolutional part heatmap regression for the 1st 3d face alignment in the wild (3dfaw) challenge. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 616–624. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep convolutional network cascade for facial point detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Portland, OR, USA, 23–28 June 2013; pp. 3476–3483. [Google Scholar]
- Liu, H.; Lu, J.; Feng, J.; Zhou, J. Two-stream transformer networks for video-based face alignment. IEEE Trans. Pattern Anal. Machine Intell. 2018, 40, 2546–2554. [Google Scholar] [CrossRef]
- Soudry, D.; Hubara, I.; Meir, R. Expectation backpropagation: Parameter-free training of multilayer neural networks with continuous or discrete weights. In Proceedings of the Neural Information Processing, Kuching, Malaysia, 3–6 November 2014. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3726–3734. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 94–108. [Google Scholar]
- Wu, Y.; Hassner, T.; Kim, K.; Medioni, G.; Natarajan, P. Facial landmark detection with tweaked convolutional neural networks. IEEE Transactions Pattern Anal. Mach. Intell. 2018, 40, 3067–3074. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, Z.-H.; Kittler, J.; Awais, M.; Huber, P.; Wu, X.-J. Wing loss for robust facial landmark localisation with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–22 June 2018; pp. 2235–2245. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Available online: https://www.bioid.com/facedb/ (accessed on 29 July 2020).
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Cheng, L. Face alignment by coarse-to-fine shape searching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dong, X.; Yu, S.I.; Weng, X.; Wei, S.E.; Yang, Y.; Sheikh, Y. Supervision-by-registration: An unsupervised approach to improve the precision of facial landmark detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Miao, X.; Zhen, X.; Liu, X.; Deng, C.; Athitsos, V.; Huang, H. Direct shape regression networks for end-to-end face alignment. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5040–5049. [Google Scholar]
- Lv, J.; Shao, X.; Xing, J.; Cheng, C.; Xi, Z. A deep regression architecture with two-stage re-initialization for high performance facial landmark detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X: full-precision kernel | : binarized kernel | A: amplitude matrix |
| F: feature map | D: s direction | : generated from A |
| i: kernel index | g: input feature map index | h: output feature map index |
| m: facial landmark index | l: layer index | M: number of facial landmarks |
| S: number of examples |
| Network Kernels | #Param. | Model | LFW+Webface | CelebA | BioID |
|---|---|---|---|---|---|
| 10-20-40-80 | 0.06M | full-precision CNN | 2.1532 | 2.2503 | 1.7286 |
| ACN | 2.2436 | 2.2344 | 1.8395 | ||
| 1-bit ACN | 3.1224 | 2.7782 | 2.8510 | ||
| 20-40-60-80 | 0.09M | full-precision CNN | 2.0600 | 2.1256 | 1.6690 |
| ACN | 2.1925 | 2.1538 | 1.7769 | ||
| 1-bit ACN | 3.0633 | 2.5067 | 2.4555 | ||
| 40-60-80-100 | 0.15M | full-precision CNN | 2.0190 | 2.0608 | 1.6750 |
| ACN | 1.9429 | 1.9091 | 1.6064 | ||
| 1-bit ACN | 2.8099 | 2.4284 | 2.4298 | ||
| 20-20-40-40- 60-60-80-80 | 0.16M | full-precision CNN | 1.8994 | 2.0194 | 1.4668 |
| ACN | 1.9000 | 2.1663 | 1.4045 | ||
| 1-bit ACN | 3.1091 | 2.9447 | 2.6785 |
| Methods | 300-W | AFLW | ||
|---|---|---|---|---|
| Common | Challenging | Full Set | ||
| SDM [22] | 5.57 | 15.40 | 7.52 | 5.43 |
| LBF [24] | 4.95 | 11.98 | 6.32 | 4.25 |
| MDM [31] | 4.83 | 10.14 | 5.88 | - |
| TCDCN [38] | 4.80 | 8.60 | 5.54 | - |
| CFSS [44] | 4.73 | 9.98 | 5.76 | 3.92 |
| DSRN [47] | 4.12 | 9.68 | 5.21 | 1.86 |
| Two-Stage [48] | 4.36 | 7.56 | 4.99 | 2.17 |
| CPM(baseline) [46] | 3.39 | 8.14 | 4.36 | 2.33 |
| ACN | 3.67 | 7.36 | 4.39 | 2.28 |
| 1-bit ACN | 4.16 | 8.97 | 5.10 | 2.91 |
| Method | Memory Saving | Speedup | Common | Challenging | Full Set |
|---|---|---|---|---|---|
| XNOR-Net | 32× | 58× | 5.97 | 12.43 | 7.24 |
| ACN | 32× | - | 3.67 | 7.36 | 4.39 |
| 1-bit ACN | 32× | 58× | 4.16 | 8.97 | 5.10 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, X.; Ma, T.; Yue, H.; Wang, X.; Zhang, B. Efficient Facial Landmark Localization Based on Binarized Neural Networks. Electronics 2020, 9, 1236. https://doi.org/10.3390/electronics9081236
Chen H, Zhang X, Ma T, Yue H, Wang X, Zhang B. Efficient Facial Landmark Localization Based on Binarized Neural Networks. Electronics. 2020; 9(8):1236. https://doi.org/10.3390/electronics9081236
Chicago/Turabian StyleChen, Hanlin, Xudong Zhang, Teli Ma, Haosong Yue, Xin Wang, and Baochang Zhang. 2020. "Efficient Facial Landmark Localization Based on Binarized Neural Networks" Electronics 9, no. 8: 1236. https://doi.org/10.3390/electronics9081236
APA StyleChen, H., Zhang, X., Ma, T., Yue, H., Wang, X., & Zhang, B. (2020). Efficient Facial Landmark Localization Based on Binarized Neural Networks. Electronics, 9(8), 1236. https://doi.org/10.3390/electronics9081236