Visualization and Interpretation of Multivariate Associations with Disease Risk Markers and Disease Risk—The Triplot



 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Synthetic Data
2.2. Algorithm Description
2.3. Software and Implementation
3. Results and Discussion
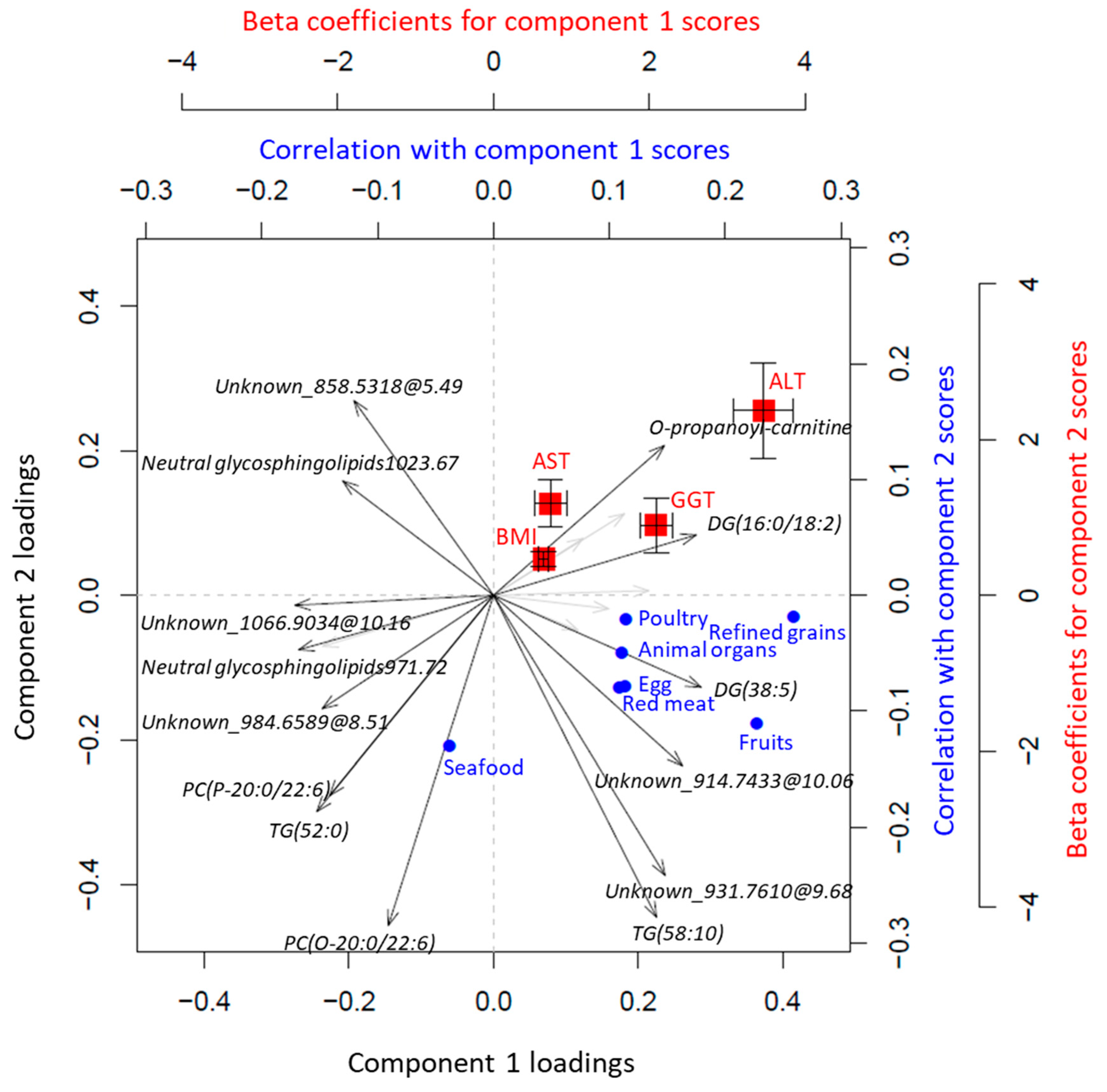
3.1. HealthyNordicDiet
3.2. CAMP
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Nishtar, S.; Niinistö, S.; Sirisena, M.; Vázquez, T.; Skvortsova, V.; Rubinstein, A.; Mogae, F.G.; Mattila, P.; Ghazizadeh Hashemi, S.H.; Kariuki, S.; et al. Time to deliver: Report of the WHO Independent High-Level Commission on NCDs. Lancet 2018, 392, 245–252. [Google Scholar] [CrossRef]
- Kuras, E.R.; Richardson, M.B.; Calkins, M.M.; Ebi, K.L.; Hess, J.J.; Kintziger, K.W.; Jagger, M.A.; Middel, A.; Scott, A.A.; Spector, J.T.; et al. Opportunities and Challenges for Personal Heat Exposure Research. Environ. Health Perspect. 2017, 125, 085001. [Google Scholar] [CrossRef] [PubMed]
- Scalbert, A.; Brennan, L.; Manach, C.; Andres-Lacueva, C.; Dragsted, L.O.; Draper, J.; Rappaport, S.M.; van der Hooft, J.J.; Wishart, D.S. The food metabolome: A window over dietary exposure. Am. J. Clin. Nutr. 2014, 99, 1286–1308. [Google Scholar] [CrossRef] [PubMed]
- Wild, C.P. Complementing the genome with “an exposome”: The outstanding challenge of environmental exposure measurement in molecular epidemiology. Cancer Epidemiol. Biomark. Prevent. A Publ. Am. Assoc. Cancer Res. Cosponsored Am. Soc. Prevent. Oncol. 2005, 14, 1847–1850. [Google Scholar] [CrossRef] [PubMed]
- Rattray, N.J.W.; Deziel, N.C.; Wallach, J.D.; Khan, S.A.; Vasiliou, V.; Ioannidis, J.P.A.; Johnson, C.H. Beyond genomics: Understanding exposotypes through metabolomics. Hum. Genom. 2018, 12, 4. [Google Scholar] [CrossRef]
- Gibbons, H.; Brennan, L. Metabolomics as a tool in the identification of dietary biomarkers. Proc. Nutr. Soc. 2017, 76, 42–53. [Google Scholar] [CrossRef]
- Shi, L.; Brunius, C.; Lehtonen, M.; Auriola, S.; Bergdahl, I.A.; Rolandsson, O.; Hanhineva, K.; Landberg, R. Plasma metabolites associated with type 2 diabetes in a Swedish population: A case-control study nested in a prospective cohort. Diabetologia 2018, 61, 849–861. [Google Scholar] [CrossRef]
- Shi, L.; Brunius, C.; Johansson, I.; Bergdahl, I.A.; Lindahl, B.; Hanhineva, K.; Landberg, R. Plasma metabolites associated with healthy Nordic dietary indexes and risk of type 2 diabetes-a nested case-control study in a Swedish population. Am. J. Clin. Nutr. 2018, 108, 564–575. [Google Scholar] [CrossRef]
- Saccenti, E.; Hoefsloot, H.C.J.; Smilde, A.K.; Westerhuis, J.A.; Hendriks, M.M.W.B. Reflections on univariate and multivariate analysis of metabolomics data. Metabolomics 2014, 10, 361–374. [Google Scholar] [CrossRef]
- Alonso, A.; Marsal, S.; Julià, A. Analytical methods in untargeted metabolomics: State of the art in 2015. Front. Bioeng. Biotechnol. 2015, 3, 23. [Google Scholar] [CrossRef]
- Norberg, M.; Wall, S.; Boman, K.; Weinehall, L. The Västerbotten Intervention Programme: Background, design and implications. Glob. Health Act. 2010, 3. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liao, X.; Gan, W.; Ding, X.; Gao, B.; Wang, H.; Zhao, X.; Liu, Y.; Feng, L.; Abdulkadil, W.; et al. Inverse Relationship Between Coarse Food Grain Intake and Blood Pressure Among Young Chinese Adults. Am. J. Hypertens. 2018, 32, 402–408. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Westerhuis, J.A.; Rosen, J.; Landberg, R.; Brunius, C. Variable selection and validation in multivariate modelling. Bioinformatics 2019, 35, 972–980. [Google Scholar] [CrossRef] [PubMed]
- Worley, B.; Powers, R. Multivariate Analysis in Metabolomics. Curr. Metab. 2013, 1, 92–107. [Google Scholar] [CrossRef]
- Madsen, R.; Lundstedt, T.; Trygg, J. Chemometrics in metabolomics—A review in human disease diagnosis. Anal. Chim. Acta 2010, 659, 23–33. [Google Scholar] [CrossRef] [PubMed]
- Revelle, W. Psych: Procedures for Personality and Psychological Research, Northwestern University, Evanston, Illinois, USA. Version = 1.8.12. 2018. Available online: https://CRAN.R-project.org/package=psych (accessed on 1 July 2019).
- Revelle, W.; Rocklin, T. Very Simple Structure: An Alternative Procedure For Estimating the Optimal Number of Interpretable Factors. Multivar. Behav. Res. 1979, 14, 403–414. [Google Scholar] [CrossRef] [PubMed]
- Filzmoser, P.; Liebmann, B.; Varmuza, K. Repeated double cross validation. J. Chemom. 2009, 23, 160–171. [Google Scholar] [CrossRef]
- Westerhuis, J.A.; Hoefsloot, H.C.J.; Smit, S.; Vis, D.J.; Smilde, A.K.; van Velzen, E.J.J.; van Duijnhoven, J.P.M.; van Dorsten, F.A. Assessment of PLSDA cross validation. Metabolomics 2008, 4, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Olsson, U. Maximum likelihood estimation of the polychoric correlation coefficient. Psychometrika 1979, 44, 443–460. [Google Scholar] [CrossRef]
- Zuo, Y.; Yu, G.; Tadesse, M.G.; Ressom, H.W. Biological network inference using low order partial correlation. Methods 2014, 69, 266–273. [Google Scholar] [CrossRef] [Green Version]
- Heerman, W.J.; Jackson, N.; Hargreaves, M.; Mulvaney, S.A.; Schlundt, D.; Wallston, K.A.; Rothman, R.L. Clusters of Healthy and Unhealthy Eating Behaviors Are Associated With Body Mass Index Among Adults. J. Nutr. Educ. Behav. 2017, 49, 415–421.e1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newby, P.; Muller, D.; Hallfrisch, J.; Qiao, N.; Andres, R.; Tucker, K.L. Dietary patterns and changes in body mass index and waist circumference in adults. Am. J. Clin. Nutr. 2003, 77, 1417–1425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahn, M.B.; Bae, W.R.; Han, K.D.; Cho, W.K.; Cho, K.S.; Park, S.H.; Jung, M.H.; Suh, B.K. Association between serum alanine aminotransferase level and obesity indices in Korean adolescents. Korean J. Pediatr. 2015, 58, 165–171. [Google Scholar] [CrossRef] [PubMed]
- Salvaggio, A.; Periti, M.; Miano, L.; Tavanelli, M.; Marzorati, D. Body mass index and liver enzyme activity in serum. Clin. Chem. 1991, 37, 720–723. [Google Scholar] [PubMed]
- Cirulli, E.T.; Guo, L.; Leon Swisher, C.; Shah, N.; Huang, L.; Napier, L.A.; Kirkness, E.F.; Spector, T.D.; Caskey, C.T.; Thorens, B.; et al. Profound Perturbation of the Metabolome in Obesity Is Associated with Health Risk. Cell Metab. 2019, 29, 488–500.e2. [Google Scholar] [CrossRef] [PubMed]
- Ho, J.E.; Larson, M.G.; Ghorbani, A.; Cheng, S.; Chen, M.-H.; Keyes, M.; Rhee, E.P.; Clish, C.B.; Vasan, R.S.; Gerszten, R.E.; et al. Metabolomic Profiles of Body Mass Index in the Framingham Heart Study Reveal Distinct Cardiometabolic Phenotypes. PLoS ONE 2016, 11, e0148361. [Google Scholar] [CrossRef] [PubMed]
- Liaset, B.; Oyen, J.; Jacques, H.; Kristiansen, K.; Madsen, L. Seafood intake and the development of obesity, insulin resistance and type 2 diabetes. Nutr. Res. Rev. 2019, 32, 146–167. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Beydoun, M.A. Meat consumption is associated with obesity and central obesity among US adults. Int. J. Obes. 2009, 33, 621–628. [Google Scholar] [CrossRef] [Green Version]
- Vatanparast, H.; Whiting, S.; Hossain, A.; Mirhosseini, N.; Merchant, A.T.; Szafron, M. National pattern of grain products consumption among Canadians in association with body weight status. BMC Nutr. 2017, 3, 59. [Google Scholar] [CrossRef]
- Ham, E.; Kim, H.-J. Evaluation of fruit intake and its relation to body mass index of adolescents. Clin. Nutr. Res. 2014, 3, 126–133. [Google Scholar] [CrossRef]
- Charlton, K.; Kowal, P.; Soriano, M.M.; Williams, S.; Banks, E.; Vo, K.; Byles, J. Fruit and vegetable intake and body mass index in a large sample of middle-aged Australian men and women. Nutrients 2014, 6, 2305–2319. [Google Scholar] [CrossRef] [PubMed]
- Hosomi, R.; Yoshida, M.; Fukunaga, K. Seafood consumption and components for health. Glob. J. Health Sci. 2012, 4, 72–86. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.-H.; Steffen, L.M.; Jacobs, D.R., Jr. Association between serum γ-glutamyltransferase and dietary factors: The Coronary Artery Risk Development in Young Adults (CARDIA) Study. Am. J. Clin. Nutr. 2004, 79, 600–605. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Zhou, Y.; Chen, S.H.; Zhao, X.L.; Ran, L.; Zeng, X.L.; Wu, Y.; Chen, J.L.; Kang, C.; Shu, F.R.; et al. Fish Oil Supplements Lower Serum Lipids and Glucose in Correlation with a Reduction in Plasma Fibroblast Growth Factor 21 and Prostaglandin E2 in Nonalcoholic Fatty Liver Disease Associated with Hyperlipidemia: A Randomized Clinical Trial. PLoS ONE 2015, 10, e0133496. [Google Scholar] [CrossRef]
- Gupta, V.; Mah, X.J.; Garcia, M.C.; Antonypillai, C.; van der Poorten, D. Oily fish, coffee and walnuts: Dietary treatment for nonalcoholic fatty liver disease. World J. Gastroenterol. 2015, 21, 10621–10635. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Description |
|---|---|
| First layer: Latent variable (LV) modeling | |
| Custom a | Perform LV modeling of high-dimensional (metabolomics) data. |
| makeTPO() a | Initiate a triplot object (TPO) from LV model |
| Second layer: Correlations | |
| makeCorr() or custom b | Perform correlation analysis between LV observation scores and exposures or covariates. |
| addCorr() | Add correlation results to the TPO. |
| Third layer: Associated risk | |
| crudeCLR(), crudeLR(), or custom c | Calculate risk associations (i.e., odds ratio or hazard ratio) in (conditional) logistic regression or association with intermediate risk markers (i.e., beta coefficient) in linear regression. |
| addRisk() | Add risk associations to the TPO. |
| Visualizations | |
| checkTPO() | Generate a heatmap visualizing correlations and risk associations to identify relevant LVs for the triplot visualization. |
| triplot() | Create a triplot containing LV analysis results, correlations, and risk associations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schillemans, T.; Shi, L.; Liu, X.; Åkesson, A.; Landberg, R.; Brunius, C. Visualization and Interpretation of Multivariate Associations with Disease Risk Markers and Disease Risk—The Triplot. Metabolites 2019, 9, 133. https://doi.org/10.3390/metabo9070133
Schillemans T, Shi L, Liu X, Åkesson A, Landberg R, Brunius C. Visualization and Interpretation of Multivariate Associations with Disease Risk Markers and Disease Risk—The Triplot. Metabolites. 2019; 9(7):133. https://doi.org/10.3390/metabo9070133
Chicago/Turabian StyleSchillemans, Tessa, Lin Shi, Xin Liu, Agneta Åkesson, Rikard Landberg, and Carl Brunius. 2019. "Visualization and Interpretation of Multivariate Associations with Disease Risk Markers and Disease Risk—The Triplot" Metabolites 9, no. 7: 133. https://doi.org/10.3390/metabo9070133
APA StyleSchillemans, T., Shi, L., Liu, X., Åkesson, A., Landberg, R., & Brunius, C. (2019). Visualization and Interpretation of Multivariate Associations with Disease Risk Markers and Disease Risk—The Triplot. Metabolites, 9(7), 133. https://doi.org/10.3390/metabo9070133