
Combining Empirical and Physics-Based Models for Solar Wind Prediction


Abstract
:1. Introduction
2. Related Works
- We present a more comprehensive and in-depth analysis of the novel loss function, derived from Ohm’s law, tailored for an ideal plasma.
- We show the superiority of our proposed loss by training five deep learning regression models.
- We explore the effect of data normalization and solar cycles on our new physics-informed model.
- We made our source code open-source in a project website (https://sites.google.com/view/solarwindprediction/, accessed on 22 April 2024) that meets the principles of Findability, Accessibility, Interoperability, and Reusability (FAIR) [24].
3. Data
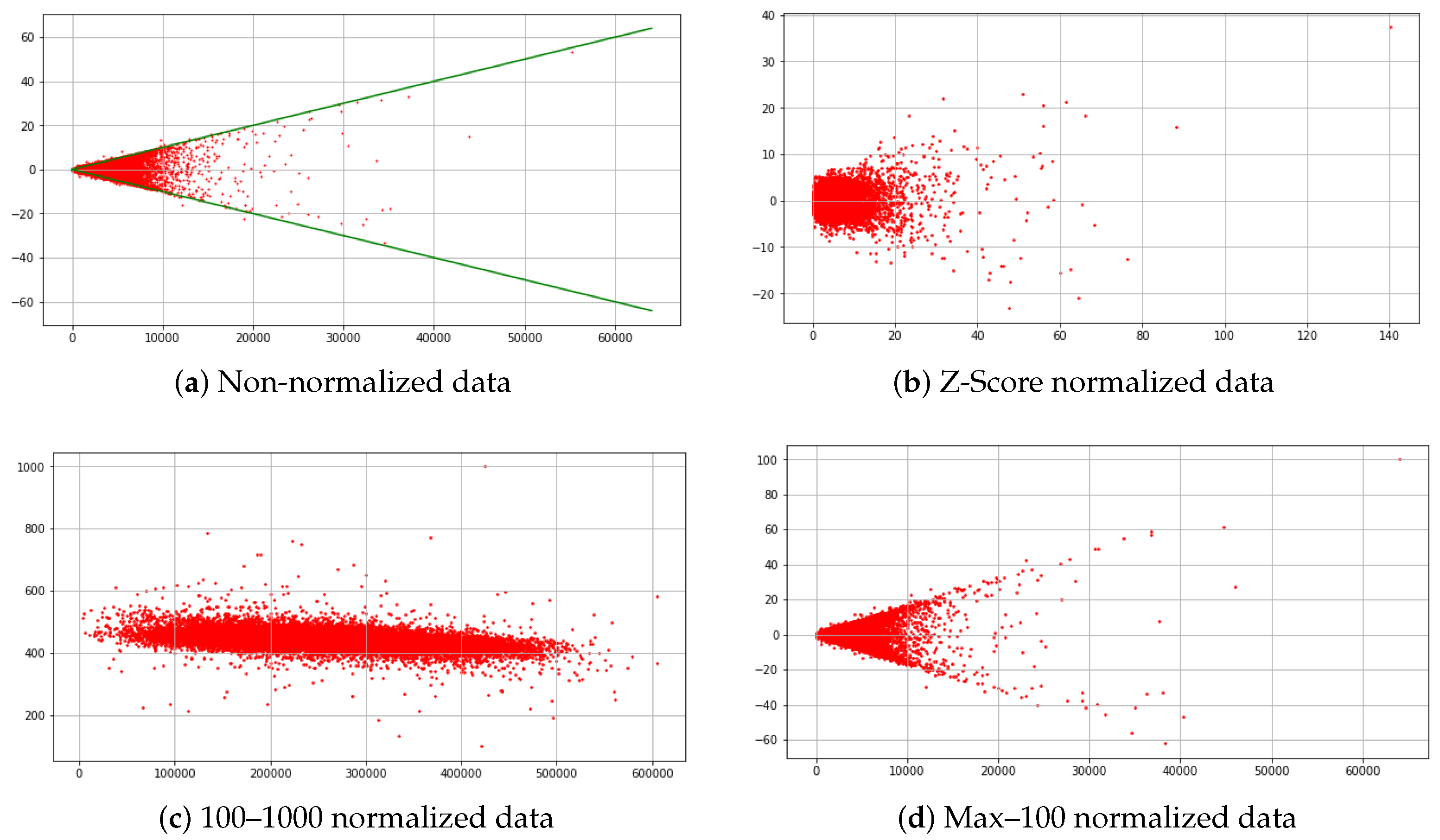
3.1. Z-Score Normalization
3.2. Min–Max Normalization
3.3. Max-Normalization
4. Ohm’s Law Constraint
5. Methodology
Deep Learning Baselines
- Convolutional Neural Networks (CNNs): CNNs are designed to process sequential data (e.g., images and maps) that have an underlying dependence between contiguous data points [32]. Since our multivariate time series data are sequences, we used a CNN model for the predictions. Prior to training the model, we used two types of kernels. The first type of kernel is one-dimensional that performs operations on the univariate time series across the time dimension. The second kernel type is two-dimensional, which performs the operation on all the variables simultaneously. This design choice ensures that the CNN model takes into consideration both of the temporal changes in variables and the interrelationships among all the variables.
- Residual Neural Network model (ResNet): ResNet is a deep neural network architecture that addresses the challenge of training very deep networks by introducing residual connections. Residual connections allow the network to skip over certain layers, enabling the flow of information directly from earlier layers to subsequent ones. Each residual building block consists of a set of convolutional layers followed by a shortcut connection that skips one or more layers [33]. By adding these residual connections, the network can learn residual mappings instead of directly learning the desired underlying mapping. This approach helps alleviate the vanishing gradient problem and facilitates the training of deeper networks. We used the same kernels of the CNN for the ResNet model.
- RotateNet: RotateNet leverages the idea of using a convolutional neural network (CNN) as a feature extractor to capture meaningful representations from a two-dimensional matrix. It employs a combination of convolutional and fully connected layers to process the input matrices. This equips the model with additional expertise, enabling it to generate feature detectors that efficiently predict the subsequent time steps. To do so, the network constructs a neural model that acquires the ability to differentiate between distinct geometric transformations, specifically rotations, applied to the regular multivariate time series matrix [34].
- Long Short-Term Memory (LSTM): LSTM is a type of recurrent neural network architecture designed to efficiently process and learn from sequential data. LSTM networks incorporate memory cells and gates that allow them to selectively retain and forget information over extended periods [35]. This capability helps address the vanishing gradient problem and enables LSTM networks to capture and preserve relevant information from past time steps. The memory cells in LSTM networks store and update information over time by passing it through gates, including the input gate, forget gate, and output gate. These gates regulate the flow of information, allowing the network to decide which information to store, forget, or output at each time step.
- Gated Recurrent Unit (GRU): The GRU model was introduced as a variation of the LSTM architecture with a simpler structure [36]. GRU units have a simpler structure compared to LSTM, as they combine the memory and hidden state into a single unit. This simplification reduces the number of parameters and computational complexity, making GRU more computationally efficient than the LSTM. Overall, GRU provides a balance between capturing long-term dependencies and computational efficiency.
6. Experiments
6.1. Experimental Setup
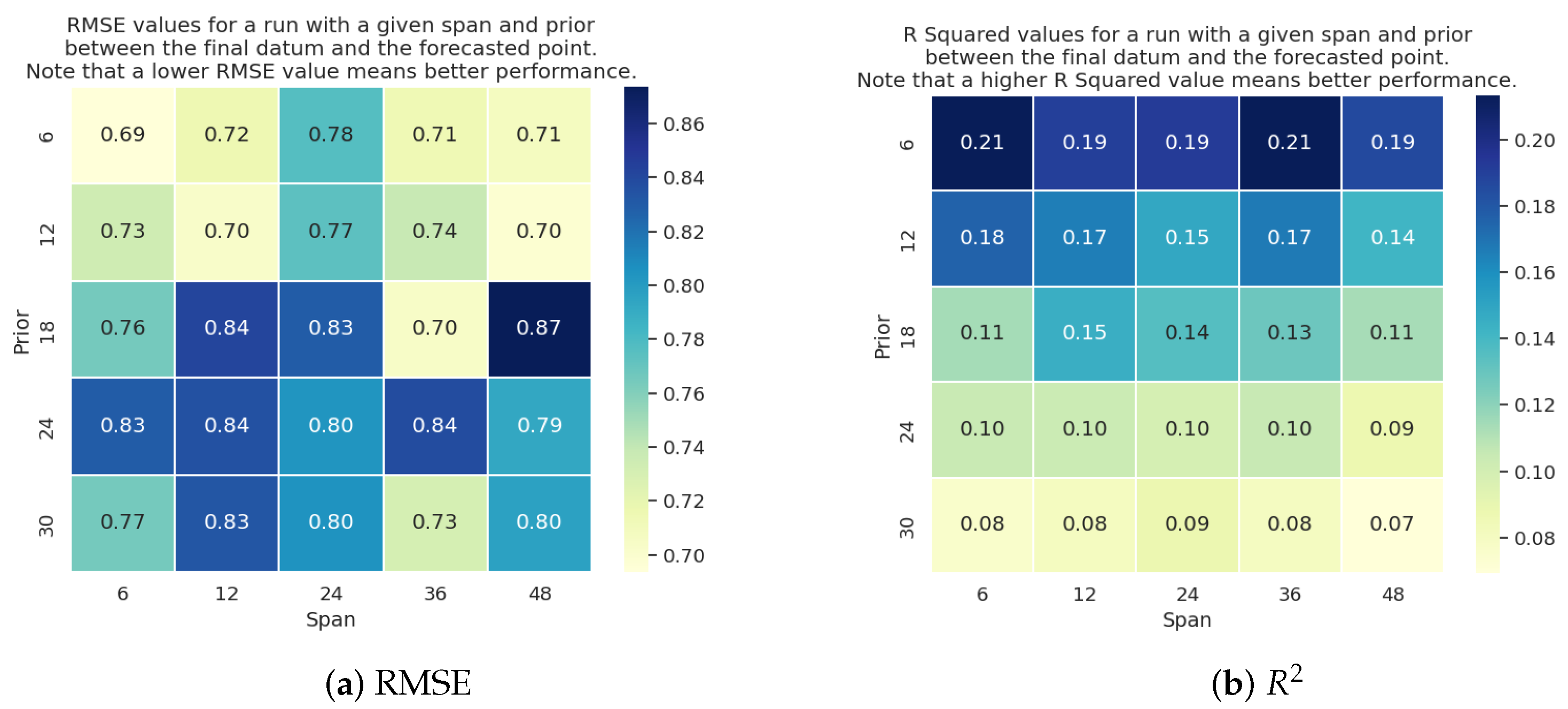
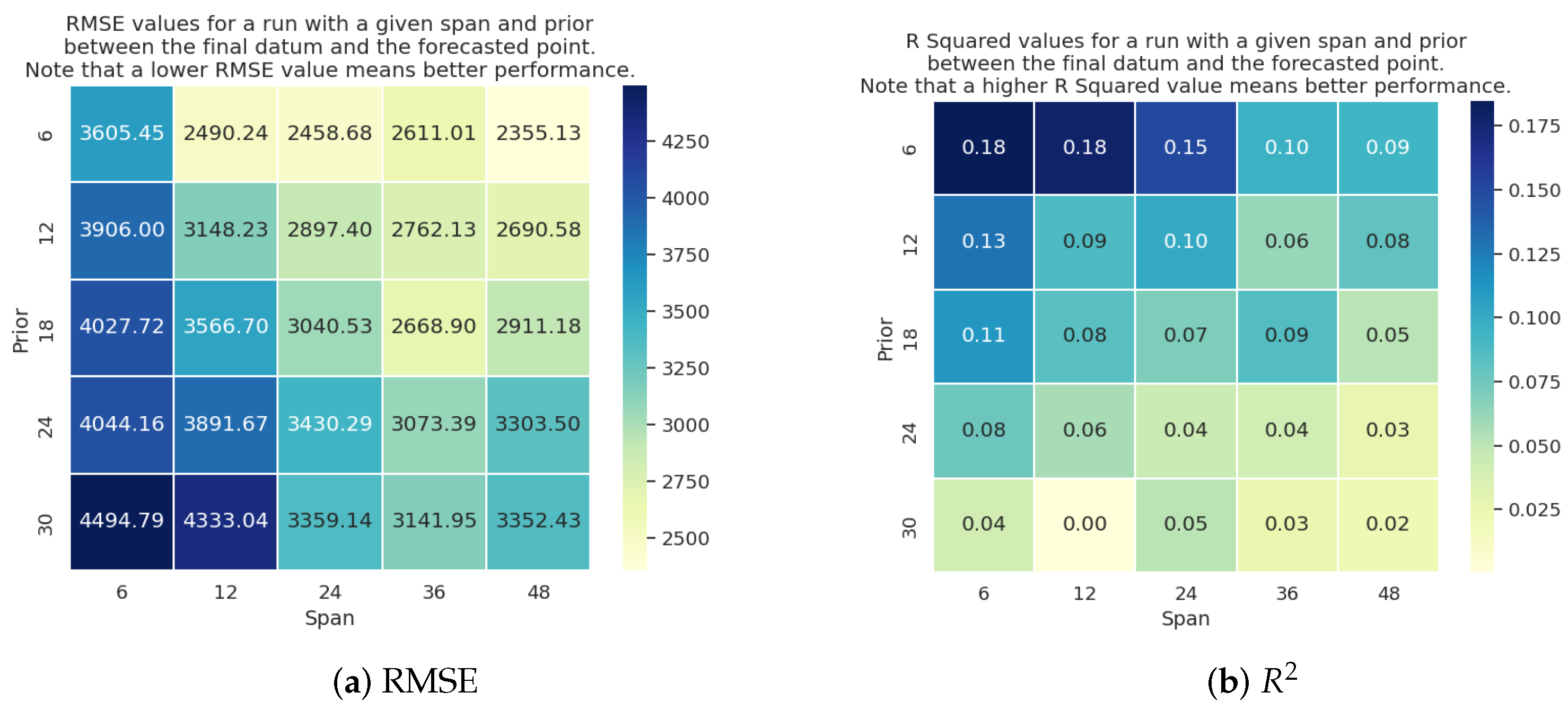
6.2. Experimental Evaluation
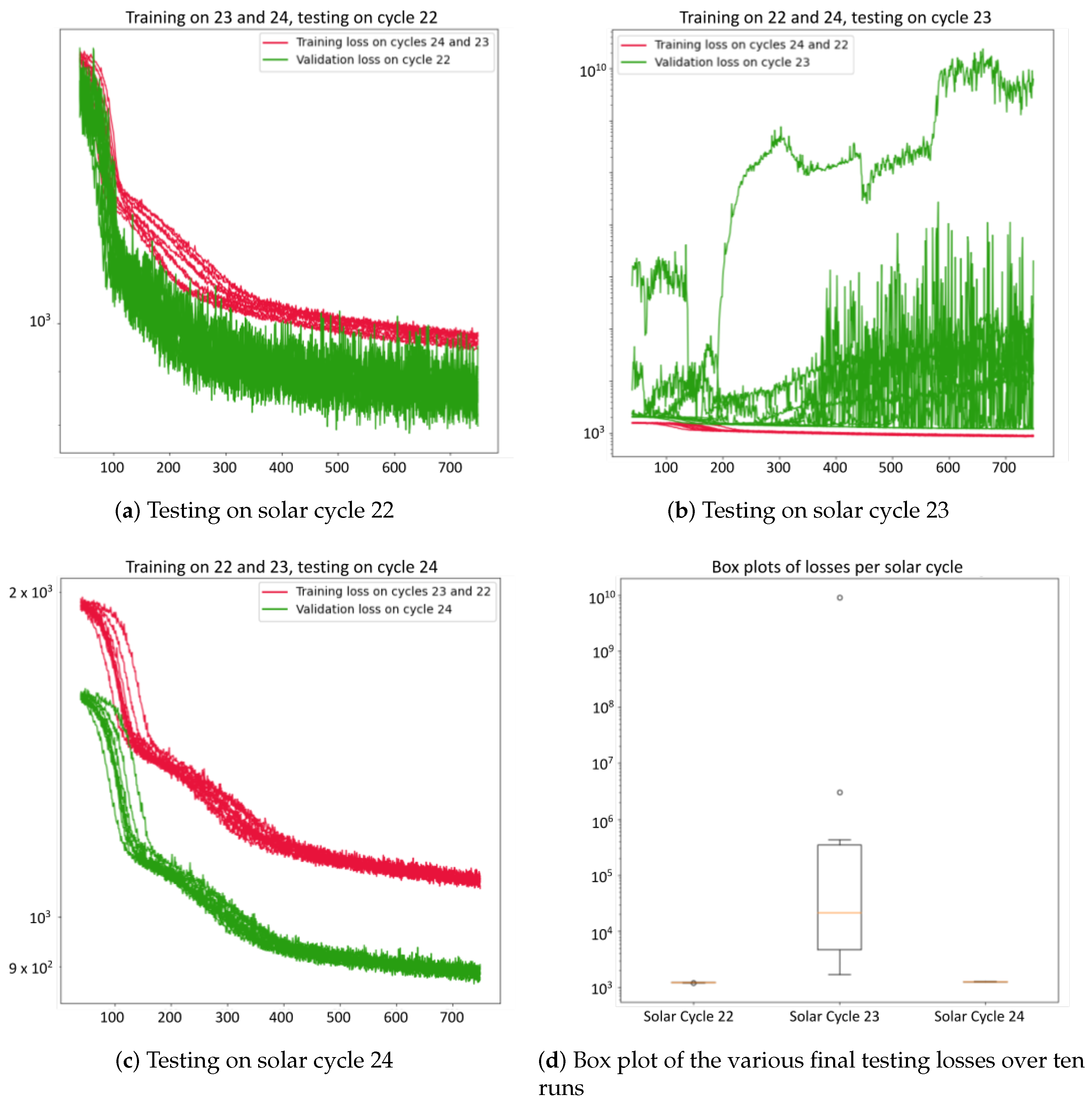
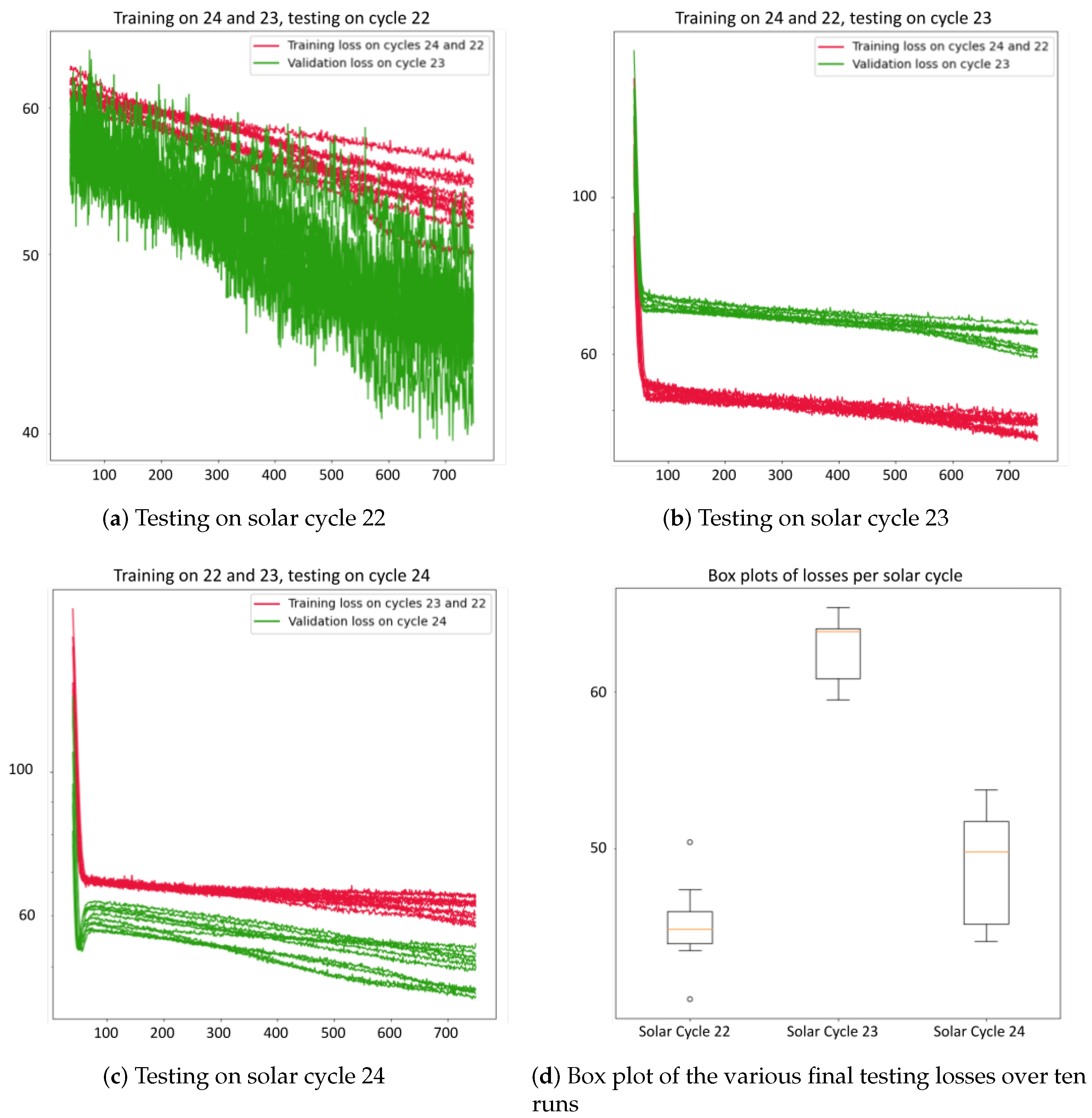
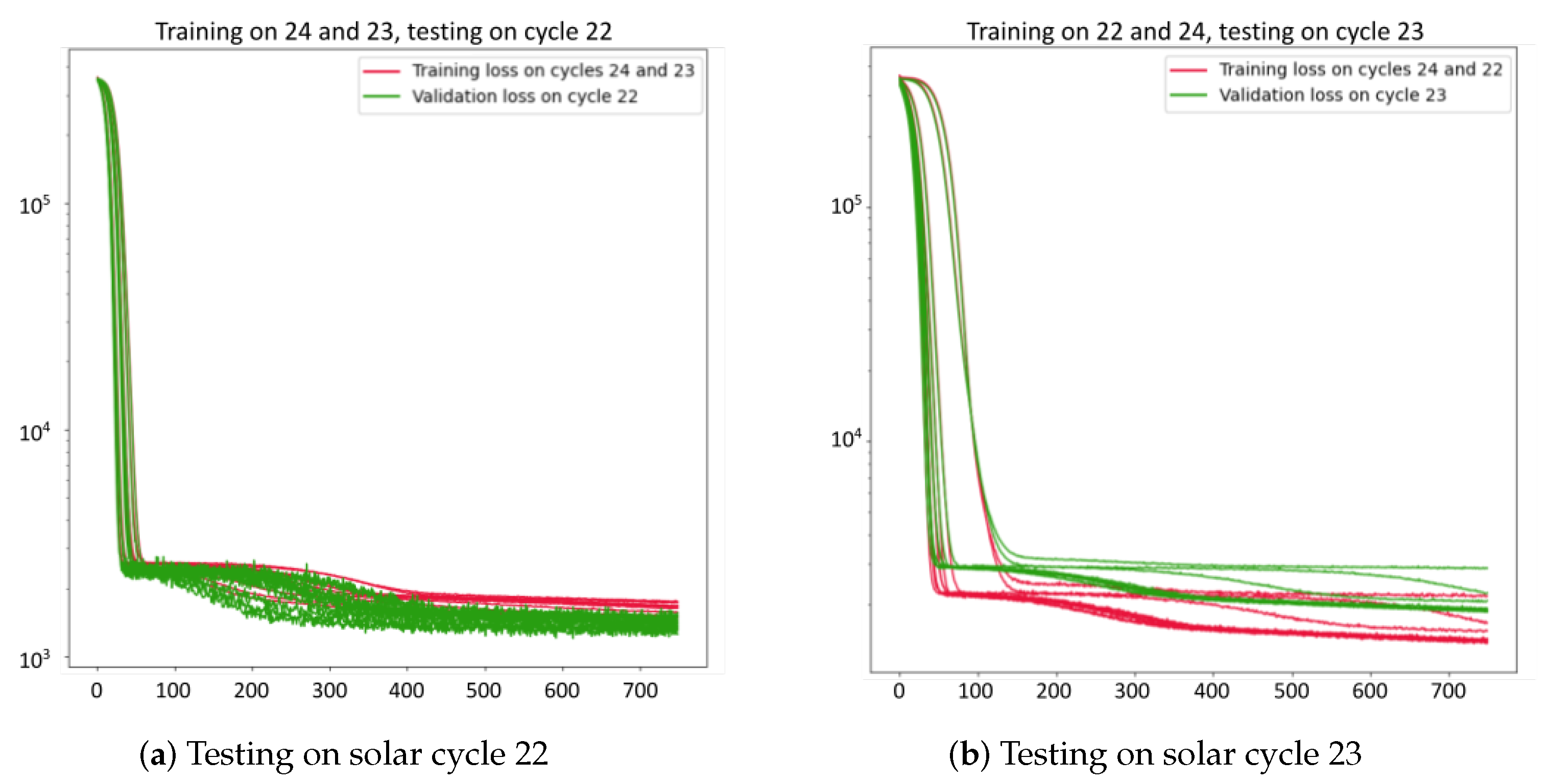
7. Case Study: Solar Cycles
- LSTM: No physics loss () and input data Z-normalized.
- CNN: Physics loss () with a weight ( = 0.3), and input data normalized from 100 to 1000.
- ResNet: Physics loss () with a weight ( = 0.0001), and input data normalized using max-normalization.
- RotateNet: Physics loss () with a weight ( = 0.003), and input data normalized from 100 to 1000.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eastwood, J.; Biffis, E.; Hapgood, M.; Green, L.; Bisi, M.; Bentley, R.; Wicks, R.; McKinnell, L.A.; Gibbs, M.; Burnett, C. The Economic Impact of Space Weather: Where Do We Stand? Risk Anal. 2017, 37, 206–218. [Google Scholar] [CrossRef]
- Boozer, A.H. Ohm’s law for mean magnetic fields. J. Plasma Phys. 1986, 35, 133–139. [Google Scholar] [CrossRef]
- Martin, S. Solar Winds Travelling at 300 km per second to Hit Earth Today. 2021. Available online: https://www.express.co.uk/news/science/1449974/solar-winds-space-weather-forecast-sunspot-solar-storm-aurora-evg (accessed on 1 May 2022).
- de La Baume Pluvinel, A.; Baldet, F. Spectrum of comet morehouse (1908 c). Astrophys. J. 1911, 34, 89. [Google Scholar] [CrossRef]
- Pizzo, V. Wang-Sheeley-Arge-Enlil cone model transitions to operations. Space Weather 2011, 9. [Google Scholar] [CrossRef]
- Rotter, T.; Veronig, A.; Temmer, M.; Vršnak, B. Relation between coronal hole areas on the Sun and the solar wind parameters at 1 AU. Sol. Phys. 2012, 281, 793–813. [Google Scholar] [CrossRef]
- Feng, X. Current Status of MHD Simulations for Space Weather. In Magnetohydrodynamic Modeling of the Solar Corona and Heliosphere; Springer: Singapore, 2020; pp. 1–123. [Google Scholar] [CrossRef]
- Baker, D.N.; Poh, G.; Odstrcil, D.; Arge, C.N.; Benna, M.; Johnson, C.L.; Korth, H.; Gershman, D.J.; Ho, G.C.; McClintock, W.E.; et al. Solar wind forcing at Mercury: WSA-ENLIL model results. J. Geophys. Res. Space Phys. 2013, 118, 45–57. [Google Scholar] [CrossRef]
- Owens, M.; Lang, M.; Barnard, L.; Riley, P.; Ben-Nun, M.; Scott, C.J.; Lockwood, M.; Reiss, M.A.; Arge, C.N.; Gonzi, S. A Computationally Efficient, Time-Dependent Model of the Solar Wind for Use as a Surrogate to Three-Dimensional Numerical Magnetohydrodynamic Simulations. Sol. Phys. 2020, 295, 43. [Google Scholar] [CrossRef]
- Shugai, Y.S. Analysis of Quasistationary Solar Wind Stream Forecasts for 2010–2019. Russ. Meteorol. Hydrol. 2021, 46, 172–178. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, F. Three-Dimensional MHD Modeling of Interplanetary Solar Wind Using Self-Consistent Boundary Condition Obtained from Multiple Observations and Machine Learning. Universe 2021, 7, 371. [Google Scholar] [CrossRef]
- Luo, B.; Zhong, Q.; Liu, S.; Gong, J. A New Forecasting Index for Solar Wind Velocity Based on EIT 284 Å Observations. Sol. Phys. 2008, 250, 159–170. [Google Scholar] [CrossRef]
- Upendran, V.; Cheung, M.C.; Hanasoge, S.; Krishnamurthi, G. Solar wind prediction using deep learning. Space Weather 2020, 18, e2020SW002478. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, F. Modeling the Global Distribution of Solar Wind Parameters on the Source Surface Using Multiple Observations and the Artificial Neural Network Technique. Sol. Phys. 2019, 294, 111. [Google Scholar] [CrossRef]
- Raju, H.; Das, S. CNN-Based Deep Learning Model for Solar Wind Forecasting. Sol. Phys. 2021, 296, 134. [Google Scholar] [CrossRef]
- Leitner, M.; Farrugia, C.; Vörös, Z. Change of solar wind quasi-invariant in solar cycle 23—Analysis of PDFs. J. Atmos. Sol.-Terr. Phys. 2011, 73, 290–293. [Google Scholar] [CrossRef]
- Sun, Y.; Xie, Z.; Chen, Y.; Huang, X.; Hu, Q. Solar Wind Speed Prediction With Two-Dimensional Attention Mechanism. Space Weather 2021, 19, e2020SW002707. [Google Scholar] [CrossRef]
- van der Schaaf, A.; Xu, C.J.; van Luijk, P.; van’t Veld, A.A.; Langendijk, J.A.; Schilstra, C. Multivariate modeling of complications with data driven variable selection: Guarding against overfitting and effects of data set size. Radiother. Oncol. 2012, 105, 115–121. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.; Boubrahimi, S.F.; Bahri, O.; Hamdi, S.M. Physics-Informed Neural Networks For Solar Wind Prediction. In Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023. [Google Scholar]
- Shin, Y.; Darbon, J.; Karniadakis, G.E. On the convergence of physics informed neural networks for linear second-order elliptic and parabolic type PDEs. Commun. Comput. Phys. 2020, 28, 2042–2074. [Google Scholar] [CrossRef]
- Mishra, S.; Molinaro, R. Estimates on the generalization error of physics-informed neural networks for approximating a class of inverse problems for PDEs. IMA J. Numer. Anal. 2022, 42, 981–1022. [Google Scholar] [CrossRef]
- Zhao, J.; Feng, X.; Xiang, C.; Jiang, C. A mutually embedded perception model for solar corona. Mon. Not. R. Astron. Soc. 2023, 523, 1577–1590. [Google Scholar] [CrossRef]
- Jarolim, R.; Thalmann, J.K.; Veronig, A.M.; Podladchikova, T. Probing the solar coronal magnetic field with physics-informed neural networks. Nat. Astron. 2023, 7, 1171–1179. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Papitashvili, N.; Bilitza, D.; King, J. OMNI: A description of near-Earth solar wind environment. In Proceedings of the 40th COSPAR Scientific Assembly, Moscow, Russia, 2–10 August 2014; Volume 40. [Google Scholar]
- Mukai, T.; Machida, S.; Saito, Y.; Hirahara, M.; Terasawa, T.; Kaya, N.; Obara, T.; Ejiri, M.; Nishida, A. The Low Energy Particle (LEP) Experiment onboard the GEOTAIL Satellite. J. Geomagn. Geoelectr. 1994, 46, 669–692. [Google Scholar] [CrossRef]
- Bartlett, P.L.; Foster, D.J.; Telgarsky, M. Spectrally-Normalized Margin Bounds for Neural Networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Red Hook, NY, USA, 4–9 December 2017; pp. 6241–6250. [Google Scholar]
- Padhye, N.; Smith, C.; Matthaeus, W. Distribution of magnetic field components in the solar wind plasma. J. Geophys. Res. Space Phys. 2001, 106, 18635–18650. [Google Scholar] [CrossRef]
- Bresler, A.; Joshi, G.; Marcuvitz, N. Orthogonality properties for modes in passive and active uniform wave guides. J. Appl. Phys. 1958, 29, 794–799. [Google Scholar] [CrossRef]
- Karpatne, A.; Watkins, W.; Read, J.S.; Kumar, V. Physics-guided Neural Networks (PGNN): An Application in Lake Temperature Modeling. arXiv 2017, arXiv:1710.11431. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Towards Data Sci 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Li, S.; Jiao, J.; Han, Y.; Weissman, T. Demystifying resnet. arXiv 2016, arXiv:1611.01186. [Google Scholar]
- Golan, I.; El-Yaniv, R. Deep anomaly detection using geometric transformations. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Breuel, T.M. Benchmarking of LSTM networks. arXiv 2015, arXiv:1508.02774. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; Wu, D., Carpuat, M., Carreras, X., Vecchi, E.M., Eds.; pp. 103–111. [Google Scholar] [CrossRef]
- Case, N.A.; Wild, J.A. A statistical comparison of solar wind propagation delays derived from multispacecraft techniques. J. Geophys. Res. Space Phys. 2012, 117, 2101. [Google Scholar] [CrossRef]
- Vokhmyanin, M.V.; Stepanov, N.A.; Sergeev, V.A. On the Evaluation of Data Quality in the OMNI Interplanetary Magnetic Field Database. Space Weather 2019, 17, 476–486. [Google Scholar] [CrossRef]
- Löning, M.; Bagnall, A.; Ganesh, S.; Kazakov, V.; Lines, J.; Király, F.J. sktime: A unified interface for machine learning with time series. arXiv 2019, arXiv:1909.07872. [Google Scholar]
- Kramer, O.; Kramer, O. Scikit-learn. In Machine Learning for Evolution Strategies; Springer: Cham, Switzerland, 2016; pp. 45–53. [Google Scholar]
- Bisong, E.; Bisong, E. Matplotlib and seaborn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Springer: Cham, Switzerland, 2019; pp. 151–165. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Unit | Description |
|---|---|---|
| E | mV/m | Electric field |
| km/s | X component of the velocity | |
| km/s | Y component of the velocity | |
| km/s | Z component of the velocity | |
| nT | X component of the magnetic field | |
| nT | Y component of the magnetic field | |
| nT | Z component of the magnetic field |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johnson, R.; Filali Boubrahimi, S.; Bahri, O.; Hamdi, S.M. Combining Empirical and Physics-Based Models for Solar Wind Prediction. Universe 2024, 10, 191. https://doi.org/10.3390/universe10050191
Johnson R, Filali Boubrahimi S, Bahri O, Hamdi SM. Combining Empirical and Physics-Based Models for Solar Wind Prediction. Universe. 2024; 10(5):191. https://doi.org/10.3390/universe10050191
Chicago/Turabian StyleJohnson, Rob, Soukaina Filali Boubrahimi, Omar Bahri, and Shah Muhammad Hamdi. 2024. "Combining Empirical and Physics-Based Models for Solar Wind Prediction" Universe 10, no. 5: 191. https://doi.org/10.3390/universe10050191
APA StyleJohnson, R., Filali Boubrahimi, S., Bahri, O., & Hamdi, S. M. (2024). Combining Empirical and Physics-Based Models for Solar Wind Prediction. Universe, 10(5), 191. https://doi.org/10.3390/universe10050191