Machine Learning Predictions of Transition Probabilities in Atomic Spectra

 ,
,
Abstract
:1. Introduction
Contributions
2. Data Representation
2.1. Electron Configuration
2.2. Term Symbol
3. Experiments
3.1. Datasets
3.2. Metrics
3.3. Model Selection
4. Results and Discussion
4.1. Intraelement Model Performance
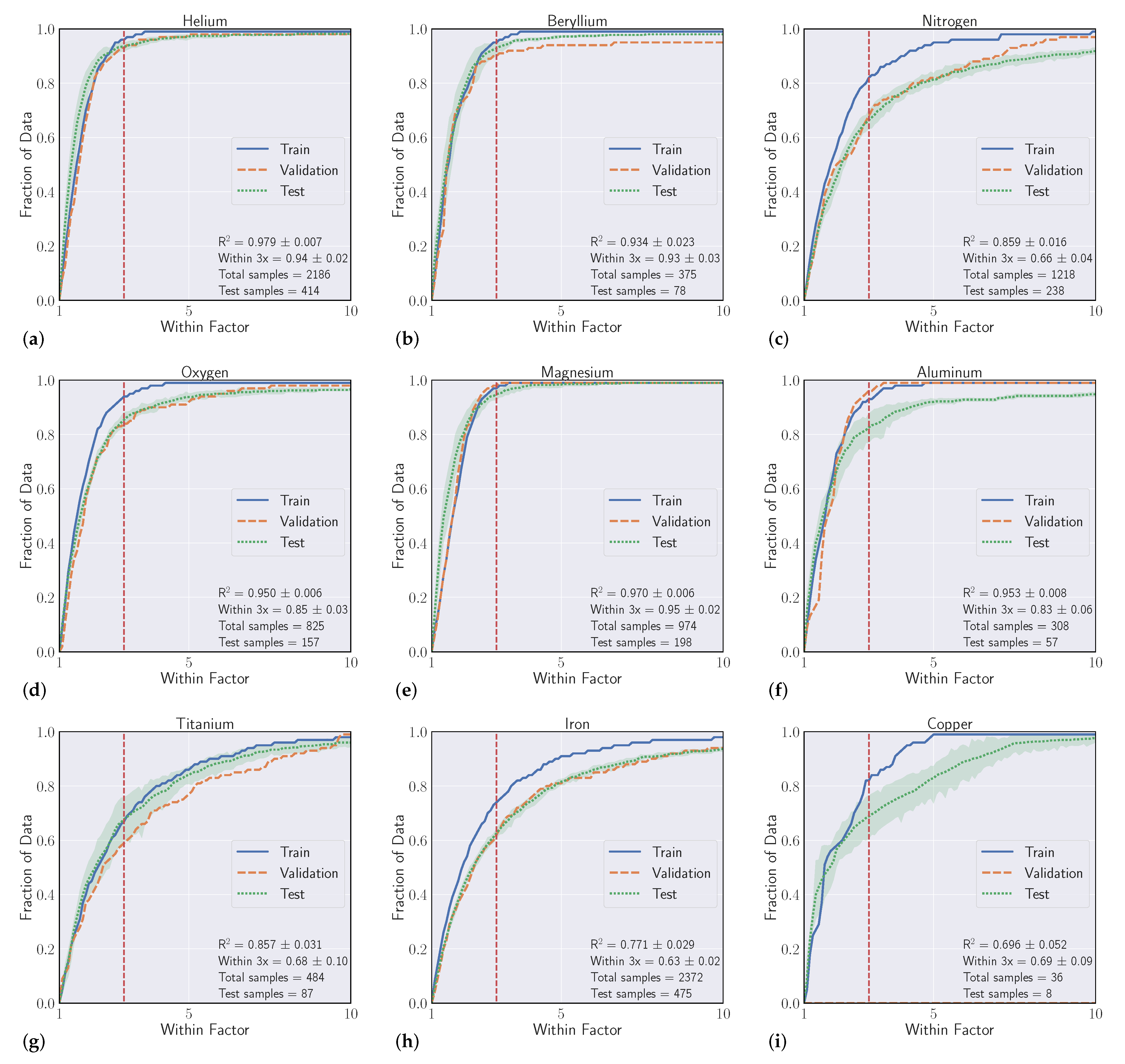
4.2. Interelement Model Performance
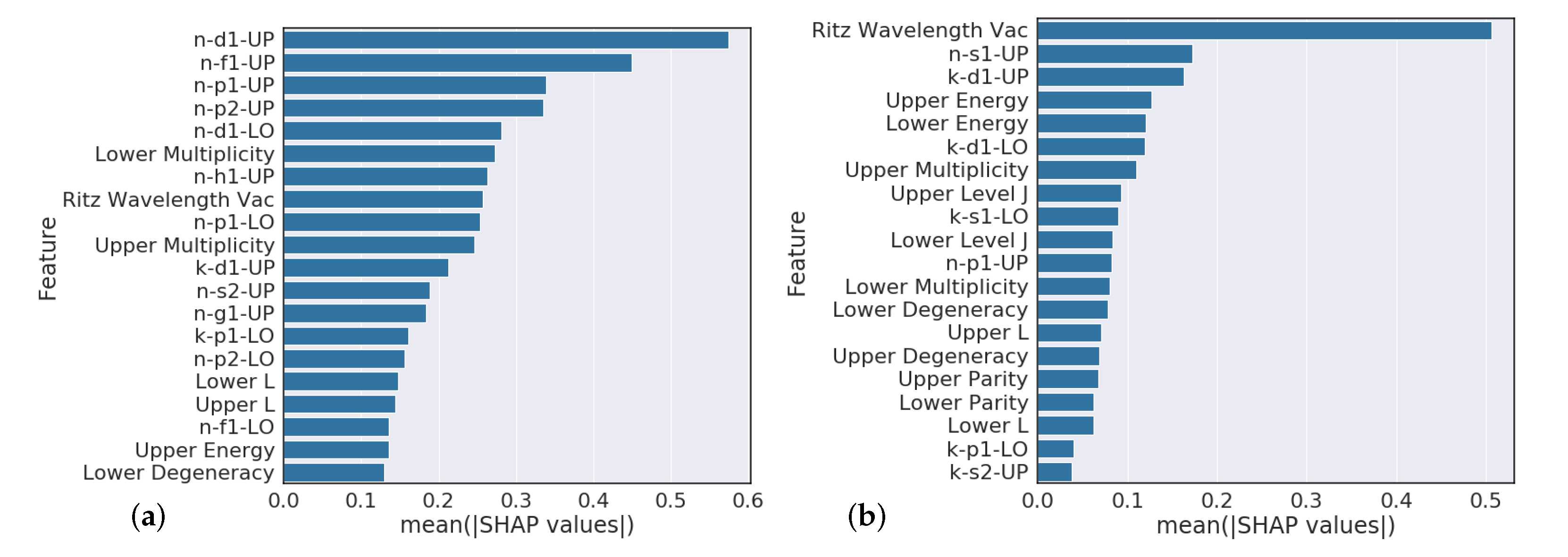
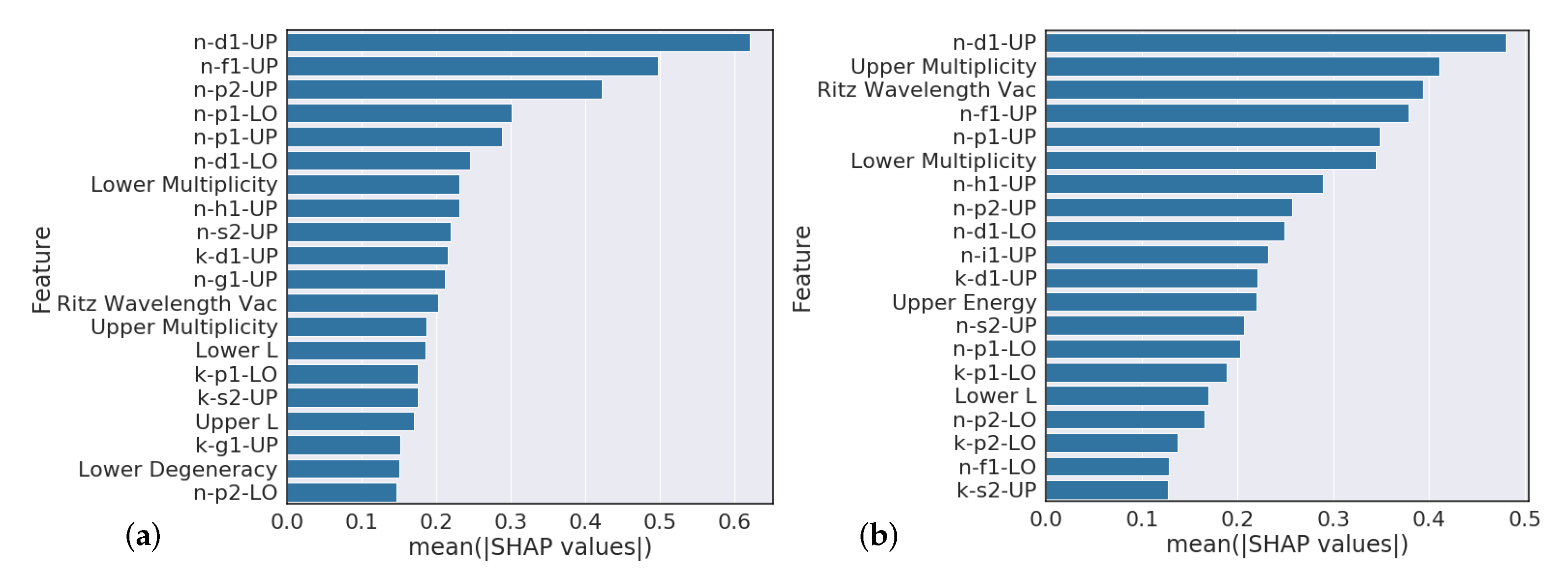
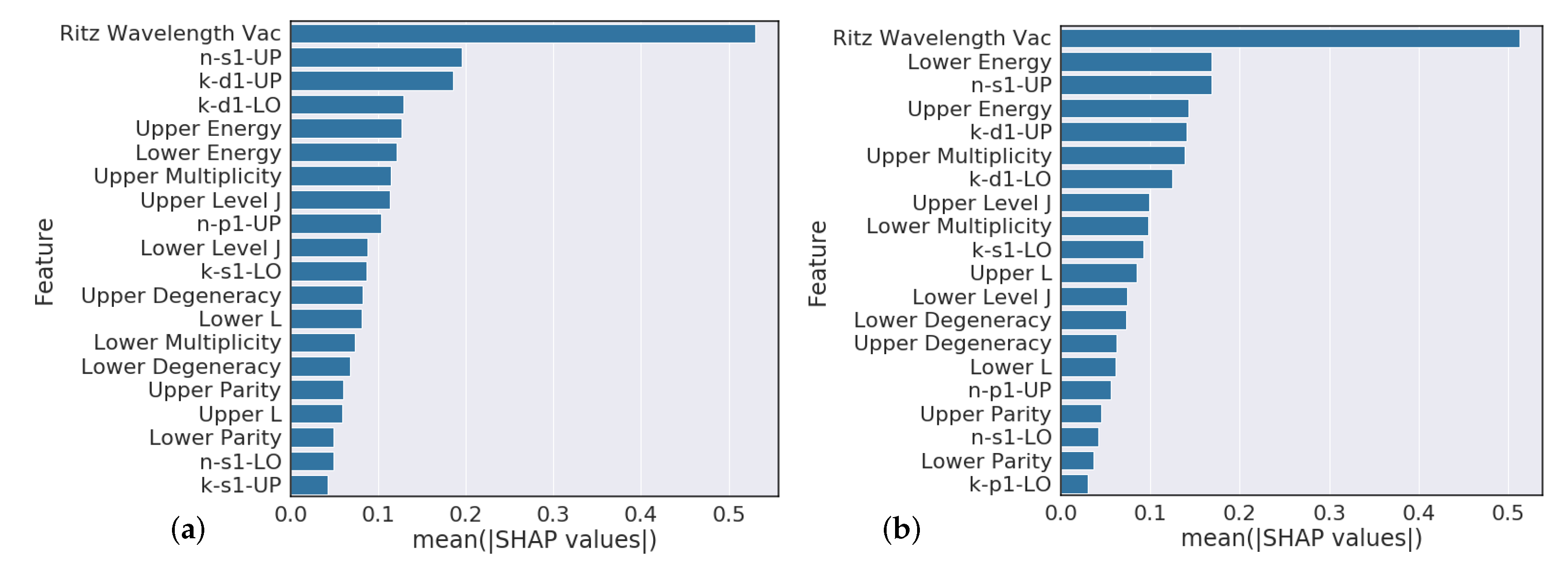
4.3. Element Model Feature Importance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASD | Atomic Spectra Database |
| FCNN | Fully Connected Neural Network |
| ML | Machine Learning |
| NIST | National Institute of Standard and Technology |
| NN | Neural Network |
| SHAP | Shapley Additive Explanations |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
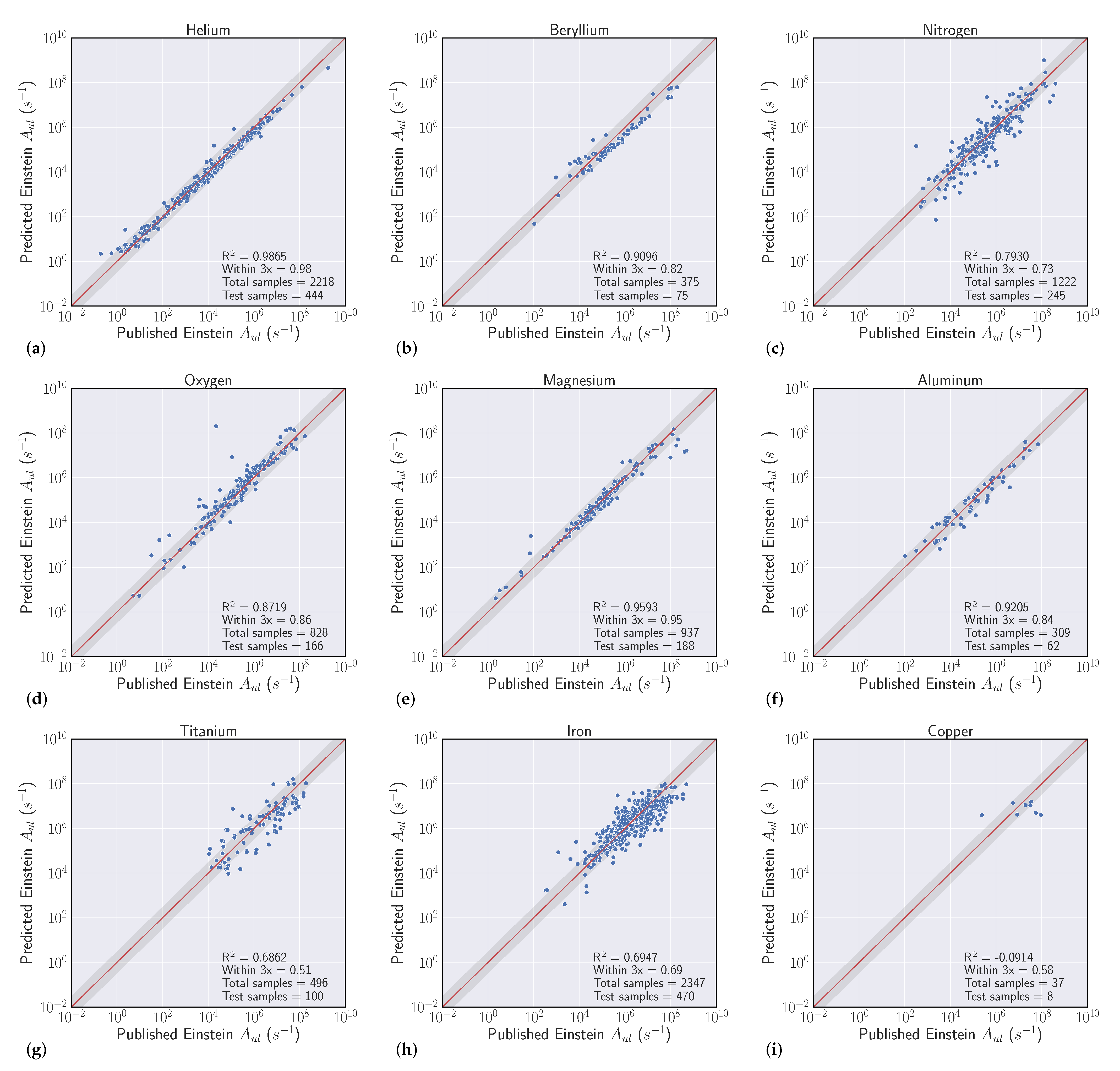
| Name | Samples | Intraelement Within 3x | Intraelement R2 | Interelement Within 3x | Interelement R2 |
|---|---|---|---|---|---|
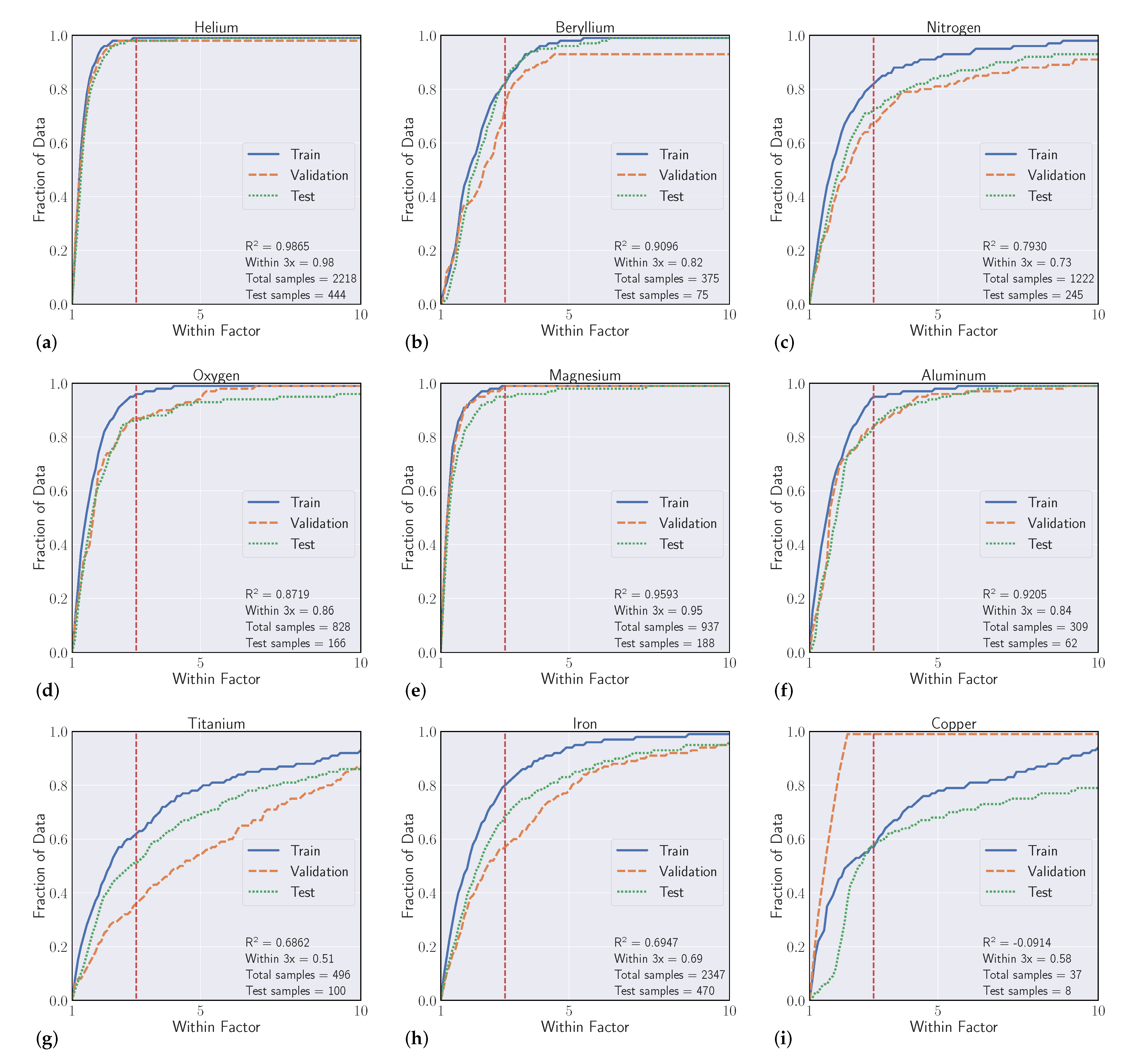
| Aluminum | 309 | 0.84 | 0.9205 | 0.83 ± 0.06 | 0.953 ± 0.008 |
| Antimony | 10 | 0.79 | −2.2836 | NA | NA |
| Argon | 428 | 0.52 | 0.4815 | NA | NA |
| Beryllium | 375 | 0.82 | 0.9096 | 0.93 ± 0.03 | 0.934 ± 0.023 |
| Boron | 253 | 0.63 | 0.9189 | NA | NA |
| Bromine | 53 | 0.47 | 0.1994 | NA | NA |
| Cadmium | 18 | 0.35 | −0.1567 | NA | NA |
| Calcium | 136 | 0.67 | 0.6388 | NA | NA |
| Carbon | 1602 | 0.73 | 0.767 | NA | NA |
| Chlorine | 96 | 0.67 | 0.405 | NA | NA |
| Chromium | 527 | 0.68 | 0.4334 | NA | NA |
| Cobalt | 338 | 0.61 | 0.602 | NA | NA |
| Copper | 37 | 0.58 | −0.0914 | 0.69 ± 0.09 | 0.696 ± 0.052 |
| Fluorine | 118 | 0.59 | 0.0682 | NA | NA |
| Gallium | 23 | 0.7 | 0.3369 | NA | NA |
| Germanium | 26 | 0.65 | 0.2397 | NA | NA |
| Helium | 2218 | 0.98 | 0.9865 | 0.94± 0.02 | 0.979 ± 0.007 |
| Hydrogen | 138 | 0.85 | 0.8198 | NA | NA |
| Indium | 27 | 0.93 | 0.9325 | NA | NA |
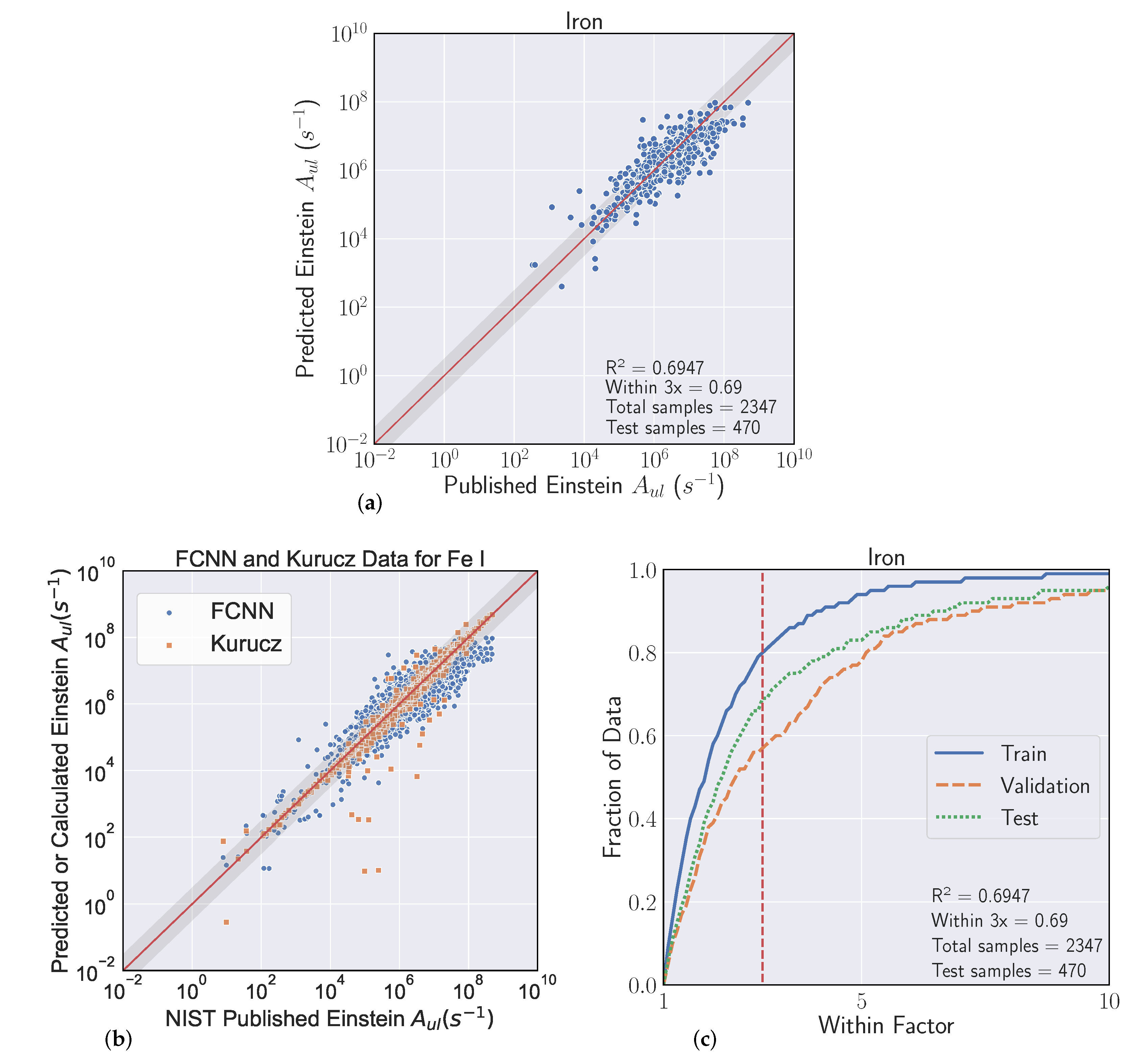
| Iron | 2347 | 0.69 | 0.6947 | 0.63 ± 0.02 | 0.771 ± 0.029 |
| Krypton | 183 | 0.29 | 0.5768 | NA | NA |
| Lithium | 257 | 0.76 | 0.9075 | NA | NA |
| Magnesium | 937 | 0.95 | 0.9593 | 0.95 ± 0.02 | 0.97± 0.006 |
| Manganese | 463 | 0.58 | 0.409 | NA | NA |
| Molybdenum | 721 | 0.8 | 0.7205 | NA | NA |
| Neon | 533 | 0.67 | 0.6891 | NA | NA |
| Nickel | 428 | 0.55 | 0.602 | NA | NA |
| Nitrogen | 1222 | 0.73 | 0.793 | 0.66 ± 0.04 | 0.859 ± 0.016 |
| Oxygen | 828 | 0.86 | 0.8719 | 0.85 ± 0.03 | 0.95 ± 0.006 |
| Palladium | 8 | 0.69 | −1.3638 | NA | NA |
| Phosphorus | 99 | 0.71 | 0.5899 | NA | NA |
| Potassium | 207 | 0.78 | 0.7985 | NA | NA |
| Rhodium | 111 | 0.6 | 0.6065 | NA | NA |
| Rubidium | 40 | 0.85 | 0.742 | NA | NA |
| Ruthenium | 11 | 0.42 | −8.4747 | NA | NA |
| Scandium | 260 | 0.61 | 0.688 | NA | NA |
| Silicon | 563 | 0.66 | 0.8615 | NA | NA |
| Silver | 7 | 0.88 | 0.3603 | NA | NA |
| Sodium | 496 | 0.99 | 0.9791 | NA | NA |
| Strontium | 86 | 0.3 | 0.0599 | NA | NA |
| Sulfur | 893 | 0.89 | 0.9269 | NA | NA |
| Technetium | 13 | 0.71 | −4.7655 | NA | NA |
| Tellurium | 6 | 0 | −8.9116 | NA | NA |
| Tin | 55 | 0.59 | −1.2858 | NA | NA |
| Titanium | 496 | 0.51 | 0.6862 | 0.68 ± 0.10 | 0.857 ± 0.031 |
| Vandium | 993 | 0.67 | 0.6658 | NA | NA |
| Xenon | 187 | 0.62 | 0.5887 | NA | NA |
| Yttrium | 189 | 0.45 | 0.2527 | NA | NA |
| Zinc | 16 | 0.98 | 0.9042 | NA | NA |
| Feature Name | Encoded Value |
|---|---|
| Ritz Wavelength Vac | log(516.77207 + 1) |
| Accuracy | 3 |
| n-s1-LO | 4 |
| k-s1-LO | 2 |
| n-s2-LO | 0 |
| k-s2-LO | 0 |
| n-p1-LO | 0 |
| k-p1-LO | 0 |
| n-p2-LO | 0 |
| k-p2-LO | 0 |
| n-d1-LO | 3 |
| k-d1-LO | 6 |
| n-d2-LO | 0 |
| k-d2-LO | 0 |
| n-s1-UP | 4 |
| k-s1-UP | 1 |
| n-s2-UP | 0 |
| k-s2-UP | 0 |
| n-p1-UP | 4 |
| k-p1-UP | 1 |
| n-p2-UP | 0 |
| k-p2-UP | 0 |
| n-d1-UP | 3 |
| k-d1-UP | 6 |
| n-d2-UP | 0 |
| k-d2-UP | 0 |
| Lower Level J | 4 |
| Upper Level J | 5 |
| Lower Energy | log(0 + 1) |
| Upper Energy | log(19,350.891 + 1) |
| Lower Multiplicity | 2 |
| Upper Multiplicity | 3 |
| Lower L | 2 |
| Upper L | 2 |
| Lower Parity | −1 |
| Upper Parity | 1 |
| Lower Degeneracy | 9 |
| Upper Degeneracy | 11 |
| Aki | log(1450 + 1) |
| Period | 4 |
| Group | 8 |
| Atomic Number | 26 |
| Atomic Mass | 55.845 |
| Protons | 26 |
| Neutrons | 30 |
| Electrons | 26 |
| LS-LO | 1 |
| JJ-LO | −1 |
| JL-LO | −1 |
| LS-UP | 1 |
| JJ-UP | −1 |
| JL-UP | −1 |




References
- Hanson, R.K.; Spearrin, R.M.; Goldenstein, C.S. Spectroscopy and Optical Diagnostics for Gases; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- Laurendeau, N.M. Statistical Thermodynamics: Fundamentals and Applications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Träbert, E. Critical assessment of theoretical calculations of atomic structure and transition probabilities: An experimenter’s view. Atoms 2014, 2, 15–85. [Google Scholar] [CrossRef] [Green Version]
- Kramida, A. Critical evaluation of data on atomic energy levels, wavelengths, and transition probabilities. Fusion Sci. Technol. 2013, 63, 313–323. [Google Scholar] [CrossRef]
- Wiese, W.L. The critical assessment of atomic oscillator strengths. Phys. Scr. 1996, 1996, 188. [Google Scholar] [CrossRef]
- Baker, J. Transition Probabilities for One Electron Atoms; NIST Technical Note 1618; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2008.
- Drake, G.W.F. High precision calculations for helium. In Atomic, Molecular, and Optical Physics Handbook; Springer: New York, NY, USA, 1996; pp. 154–171. [Google Scholar]
- Wiese, W.L.; Fuhr, J.R. Accurate atomic transition probabilities for hydrogen, helium, and lithium. J. Phys. Chem. Ref. Data 2009, 38, 565–720. [Google Scholar] [CrossRef] [Green Version]
- O’Brian, T.R.; Wickliffe, M.E.; Lawler, J.E.; Whaling, W.; Brault, J.W. Lifetimes, transition probabilities, and level energies in Fe I. J. Opt. Soc. Am. B 1991, 8, 1185–1201. [Google Scholar] [CrossRef]
- Kurucz, R.L.; Bell, B. Atomic Line Data, CD-ROM, 23, 1995. Available online: https://ui.adsabs.harvard.edu/abs/1995KurCD..23.....K/abstract (accessed on 1 March 2020).
- Kurucz, R.L. Semiempirical calculation of gf values, IV: Fe II. SAO Spec. Rep. 1981, 390. Available online: http://adsabs.harvard.edu/pdf/1981SAOSR.390.....K (accessed on 5 January 2021).
- Gehren, T.; Butler, K.; Mashonkina, L.; Reetz, J.; Shi, J. Kinetic equilibrium of iron in the atmospheres of cool dwarf stars-I. The solar strong line spectrum. Astron. Astrophys. 2001, 366, 981–1002. [Google Scholar] [CrossRef] [Green Version]
- Pehlivan, A.; Nilsson, H.; Hartman, H. Laboratory oscillator strengths of Sc i in the near-infrared region for astrophysical applications. Astron. Astrophys. 2015, 582, A98. [Google Scholar] [CrossRef] [Green Version]
- Quinet, P.; Fivet, V.; Palmeri, P.; Engström, L.; Hartman, H.; Lundberg, H.; Nilsson, H. Experimental radiative lifetimes for highly excited states and calculated oscillator strengths for lines of astrophysical interest in singly ionized cobalt (Co II). Mon. Not. R. Astron. Soc. 2016, 462, 3912–3917. [Google Scholar] [CrossRef] [Green Version]
- Meggers, W.F.; Corliss, C.H.; Scribner, B.F. Tables of Spectral-Line Intensities: Arranged by Wavelengths; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1974; Volume 145.
- Cowley, C.R.; Corliss, C.H. Moderately accurate oscillator strengths from NBS intensities–II. Mon. Not. R. Astron. Soc. 1983, 203, 651–659. [Google Scholar] [CrossRef] [Green Version]
- Henrion, G.; Fabry, M.; Remy, M. Determination of oscillator strengths for UI and UII lines. J. Quant. Spectrosc. Radiat. Transf. 1987, 37, 477–499. [Google Scholar] [CrossRef]
- Ouyang, T.; Wang, C.; Yu, Z.; Stach, R.; Mizaikoff, B.; Liedberg, B.; Huang, G.B.; Wang, Q.J. Quantitative analysis of gas phase IR spectra based on extreme learning machine regression model. Sensors 2019, 19, 5535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chatzidakis, M.; Botton, G.A. Towards calibration-invariant spectroscopy using deep learning. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, K.; Stuke, A.; Todorović, M.; Jørgensen, P.B.; Schmidt, M.N.; Vehtari, A.; Rinke, P. Deep learning spectroscopy: Neural networks for molecular excitation spectra. Adv. Sci. 2019, 6, 1801367. [Google Scholar] [CrossRef]
- Sun, C.; Tian, Y.; Gao, L.; Niu, Y.; Zhang, T.; Li, H.; Zhang, Y.; Yue, Z.; Delepine-Gilon, N.; Yu, J. Machine learning allows calibration models to predict trace element concentration in soils with generalized LIBS Spectra. Sci. Rep. 2019, 9, 1–18. [Google Scholar] [CrossRef]
- Liu, J.; Osadchy, M.; Ashton, L.; Foster, M.; Solomon, C.J.; Gibson, S.J. Deep convolutional neural networks for Raman spectrum recognition: A unified solution. Analyst 2017, 142, 4067–4074. [Google Scholar] [CrossRef] [Green Version]
- Stein, H.S.; Guevarra, D.; Newhouse, P.F.; Soedarmadji, E.; Gregoire, J.M. Machine learning of optical properties of materials–predicting spectra from images and images from spectra. Chem. Sci. 2019, 10, 47–55. [Google Scholar] [CrossRef] [Green Version]
- Lansford, J.L.; Vlachos, D.G. Infrared spectroscopy data-and physics-driven machine learning for characterizing surface microstructure of complex materials. Nat. Commun. 2020, 11, 1–12. [Google Scholar] [CrossRef]
- Kramida, A.; Ralchenko, Y.; Reader, J.; NIST ASD Team. NIST Atomic Spectra Database (ver. 5.7.1) [Online]; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019. Available online: https://physics.nist.gov/asd (accessed on 1 May 2020).
- Khalid, S.; Khalil, T.; Nasreen, S. A Survey of Feature Selection and Feature Extraction Techniques in Machine Learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Kearnes, S.; McCloskey, K.; Berndl, M.; Pande, V.; Riley, P. Molecular graph convolutions: Moving beyond fingerprints. J. Comput. Aided Mol. Des. 2016, 30, 595–608. [Google Scholar] [CrossRef] [Green Version]
- Behler, J.; Parrinello, M. Generalized neural-network representation of high-dimensional potential-energy surfaces. Phys. Rev. Lett. 2007, 98, 146401. [Google Scholar] [CrossRef]
- Willatt, M.J.; Musil, F.; Ceriotti, M. Atom-density representations for machine learning. J. Chem. Phys. 2019, 150, 154110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Motoda, H.; Liu, H. Feature Selection, Extraction, and Construction; Communication of IICM (Institute of Information and Computing Machinery): Taipei, Taiwan, 2002; pp. 67–72. [Google Scholar]
- Ladha, L.; Deepa, T. Feature Selection Methods and Algorithms. Int. J. Comput. Sci. Eng. (IJCSE) 2011, 3, 1787–1797. [Google Scholar]
- Froese Fischer, C. The Hartree–Fock Method for Atoms: A Numerical Approach; Wiley: Hoboken, NJ, USA, 1977. [Google Scholar]
- Martin, W.C.; Wiese, W. Atomic Spectroscopy: A Compendium of Basic Ideas, Notation, Data, and Formulas; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1999.
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Martin, W.; Wiese, W. Spectral Lines: Selection Rules, Intensities, Transition Probabilities, Values, and Line Strengths. 2017. Available online: https://www.nist.gov/pml/atomic-spectroscopy-compendium-basic-ideas-notation-data-and-formulas/atomic-spectroscopy (accessed on 1 May 2020).
- Kramida, A. Assessing uncertainties of theoretical atomic transition probabilities with Monte Carlo random trials. Atoms 2014, 2, 86–122. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Cowan, R.D. The Theory of Atomic Structure and Spectra; Number 3; University of California Press: Berkeley, CA, USA, 1981. [Google Scholar]
- Kumar, I.E.; Venkatasubramanian, S.; Scheidegger, C.; Friedler, S. Problems with Shapley-value-based explanations as feature importance measures. arXiv 2020, arXiv:2002.11097. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems; pp. 4765–4774. Available online: https://papers.nips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html (accessed on 5 January 2021).










| Electron Configuration 3d(D)4s4p(P°) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Subshell | s | s | p | p | d | d | ||||||
| Property | n | k | n | k | n | k | n | k | n | k | n | k |
| Encoding | 4 | 1 | 0 | 0 | 4 | 1 | 0 | 0 | 3 | 6 | 0 | 0 |
| Term Symbol | Coupling Scheme | Coupling Encoding | QN 1 | QN 2 | Parity | ||
|---|---|---|---|---|---|---|---|
| P | 1 | −1 | −1 | 0.5 | 1 | −1 | |
| (2, 3/2)° | −1 | 1 | −1 | 2 | 1.5 | 1 | |
| → or → | −1 | −1 | 1 | 0.5 | 4.5 | 1 | |
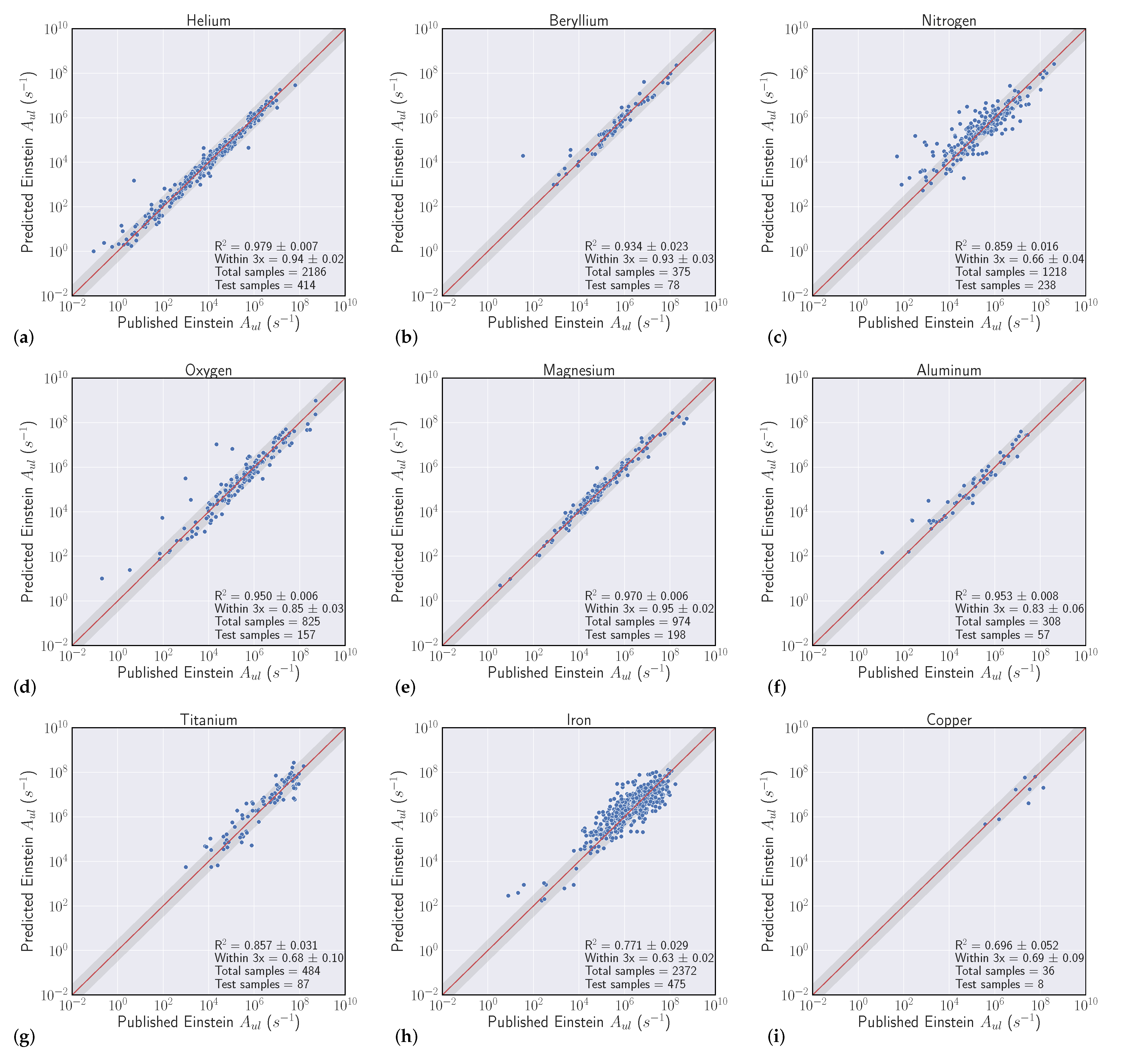
| Name | Samples | Intraelement within 3x | Intraelement R2 | Interelement within 3x | Interelement R2 |
|---|---|---|---|---|---|
| Aluminum | 309 | 0.84 | 0.9205 | 0.83 ± 0.06 | 0.953 ± 0.008 |
| Beryllium | 375 | 0.82 | 0.9096 | 0.93 ± 0.03 | 0.934 ± 0.023 |
| Copper | 37 | 0.58 | −0.0914 | 0.69 ± 0.09 | 0.696 ± 0.052 |
| Helium | 2218 | 0.98 | 0.9865 | 0.94 ± 0.02 | 0.979 ± 0.007 |
| Iron | 2347 | 0.69 | 0.6947 | 0.63 ± 0.02 | 0.771 ± 0.029 |
| Magnesium | 937 | 0.95 | 0.9593 | 0.95 ± 0.02 | 0.970 ± 0.006 |
| Nitrogen | 1222 | 0.73 | 0.793 | 0.66 ± 0.04 | 0.859 ± 0.016 |
| Oxygen | 828 | 0.86 | 0.8719 | 0.85 ± 0.03 | 0.950 ± 0.006 |
| Titanium | 496 | 0.51 | 0.6862 | 0.68 ± 0.10 | 0.857 ± 0.031 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michalenko, J.J.; Murzyn, C.M.; Zollweg, J.D.; Wermer, L.; Van Omen, A.J.; Clemenson, M.D. Machine Learning Predictions of Transition Probabilities in Atomic Spectra. Atoms 2021, 9, 2. https://doi.org/10.3390/atoms9010002
Michalenko JJ, Murzyn CM, Zollweg JD, Wermer L, Van Omen AJ, Clemenson MD. Machine Learning Predictions of Transition Probabilities in Atomic Spectra. Atoms. 2021; 9(1):2. https://doi.org/10.3390/atoms9010002
Chicago/Turabian StyleMichalenko, Joshua J., Christopher M. Murzyn, Joshua D. Zollweg, Lydia Wermer, Alan J. Van Omen, and Michael D. Clemenson. 2021. "Machine Learning Predictions of Transition Probabilities in Atomic Spectra" Atoms 9, no. 1: 2. https://doi.org/10.3390/atoms9010002
APA StyleMichalenko, J. J., Murzyn, C. M., Zollweg, J. D., Wermer, L., Van Omen, A. J., & Clemenson, M. D. (2021). Machine Learning Predictions of Transition Probabilities in Atomic Spectra. Atoms, 9(1), 2. https://doi.org/10.3390/atoms9010002