

Exploring Pan-Genomes: An Overview of Resources and Tools for Unraveling Structure, Function, and Evolution of Crop Genes and Genomes





Abstract
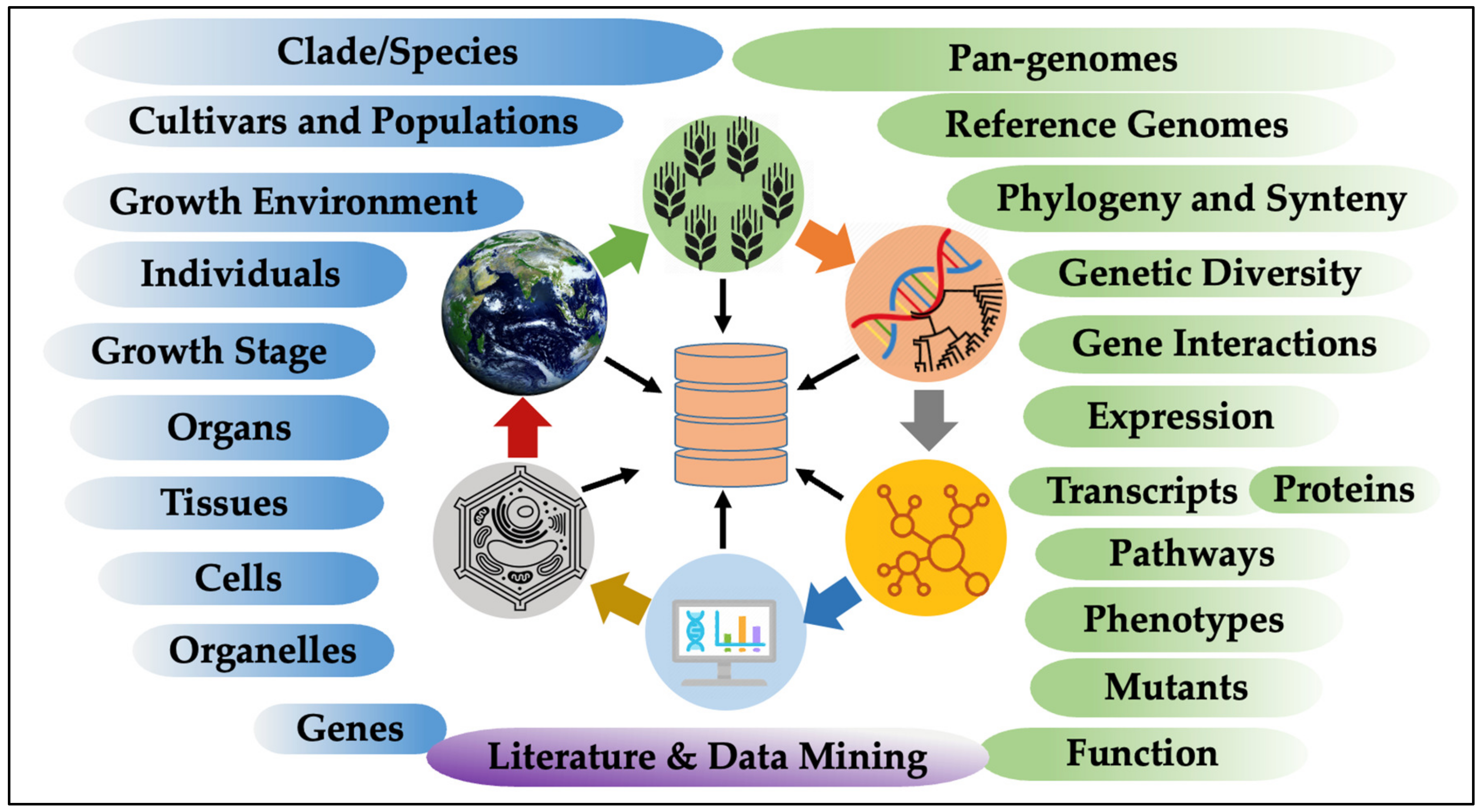
:1. Introduction
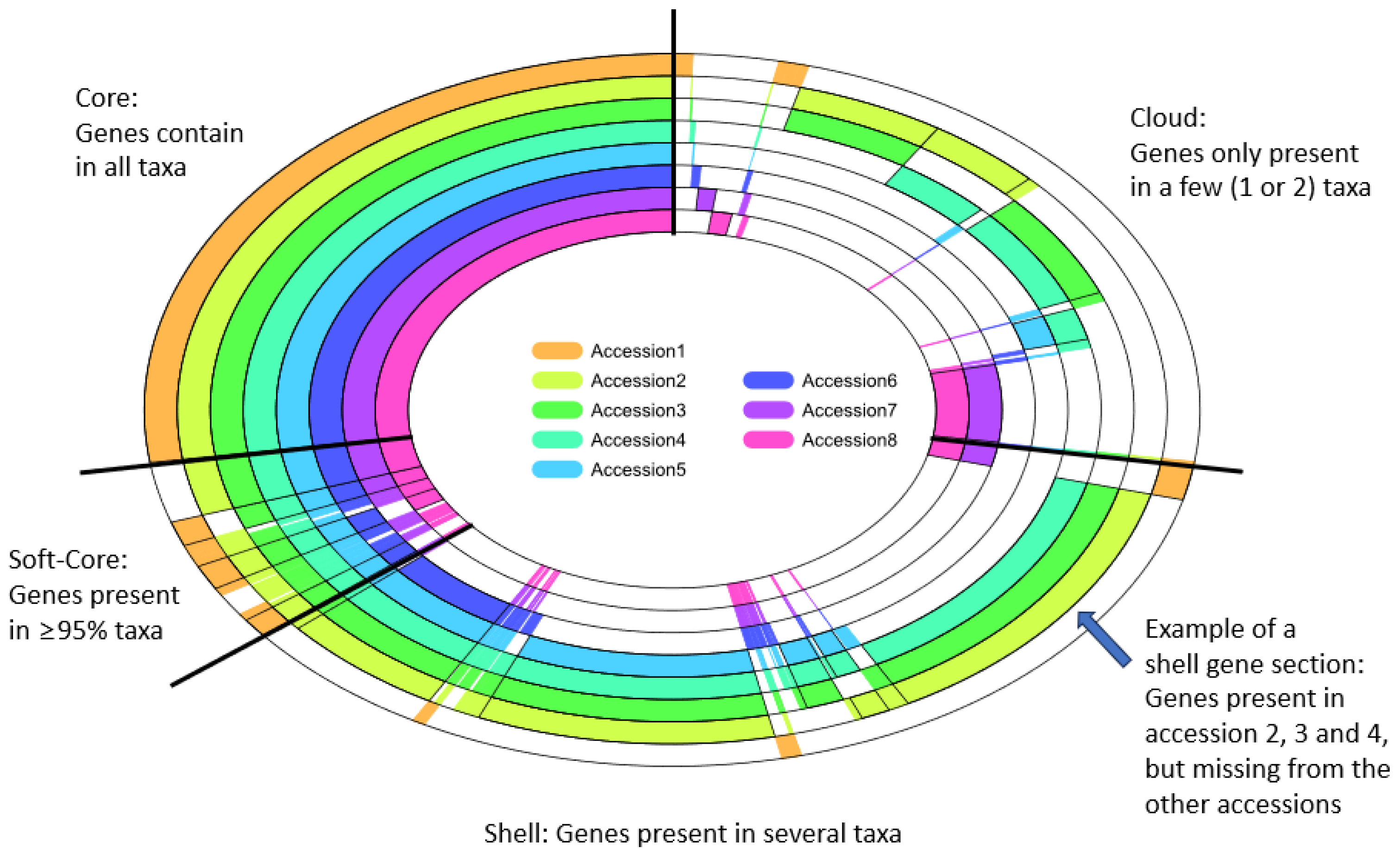
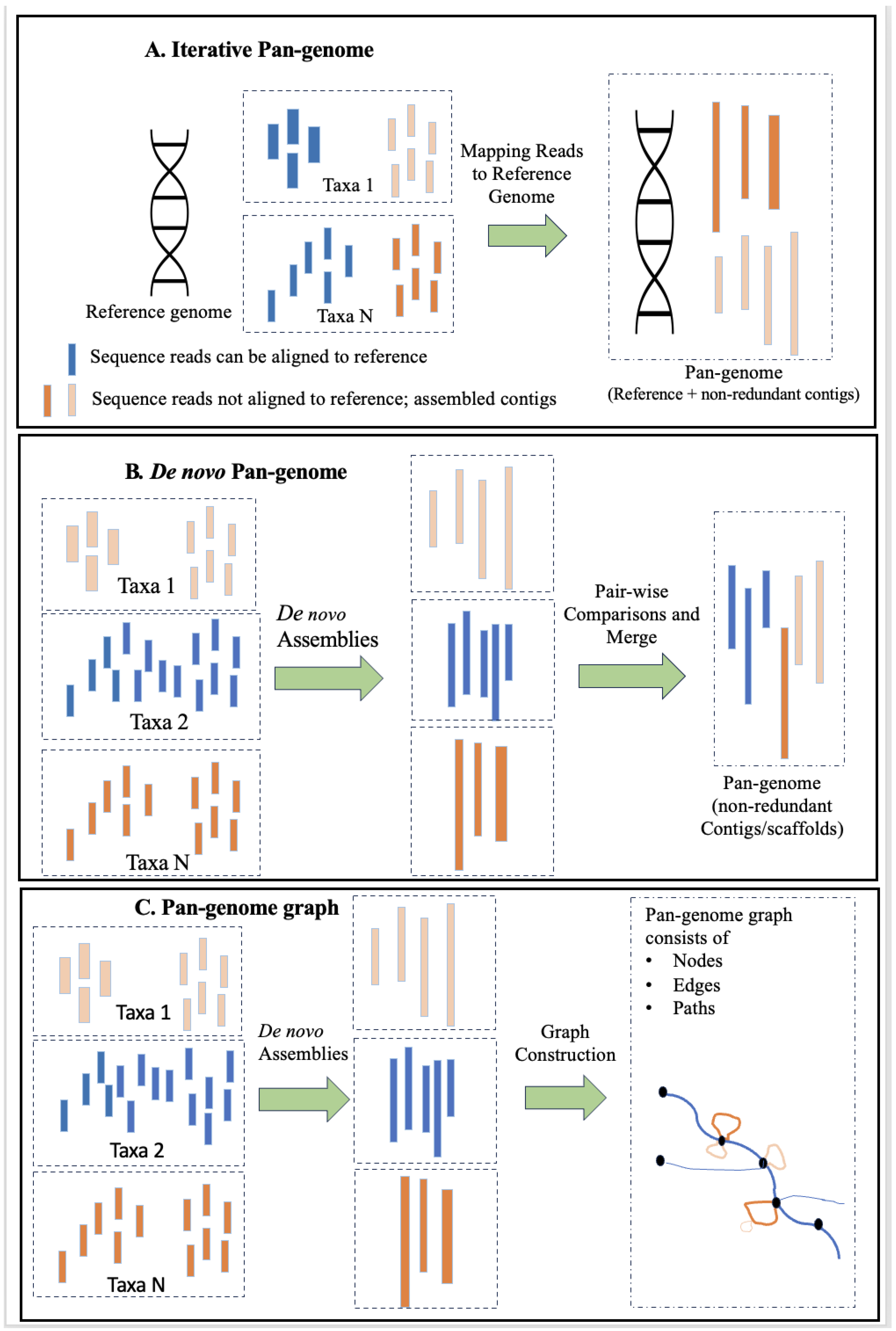
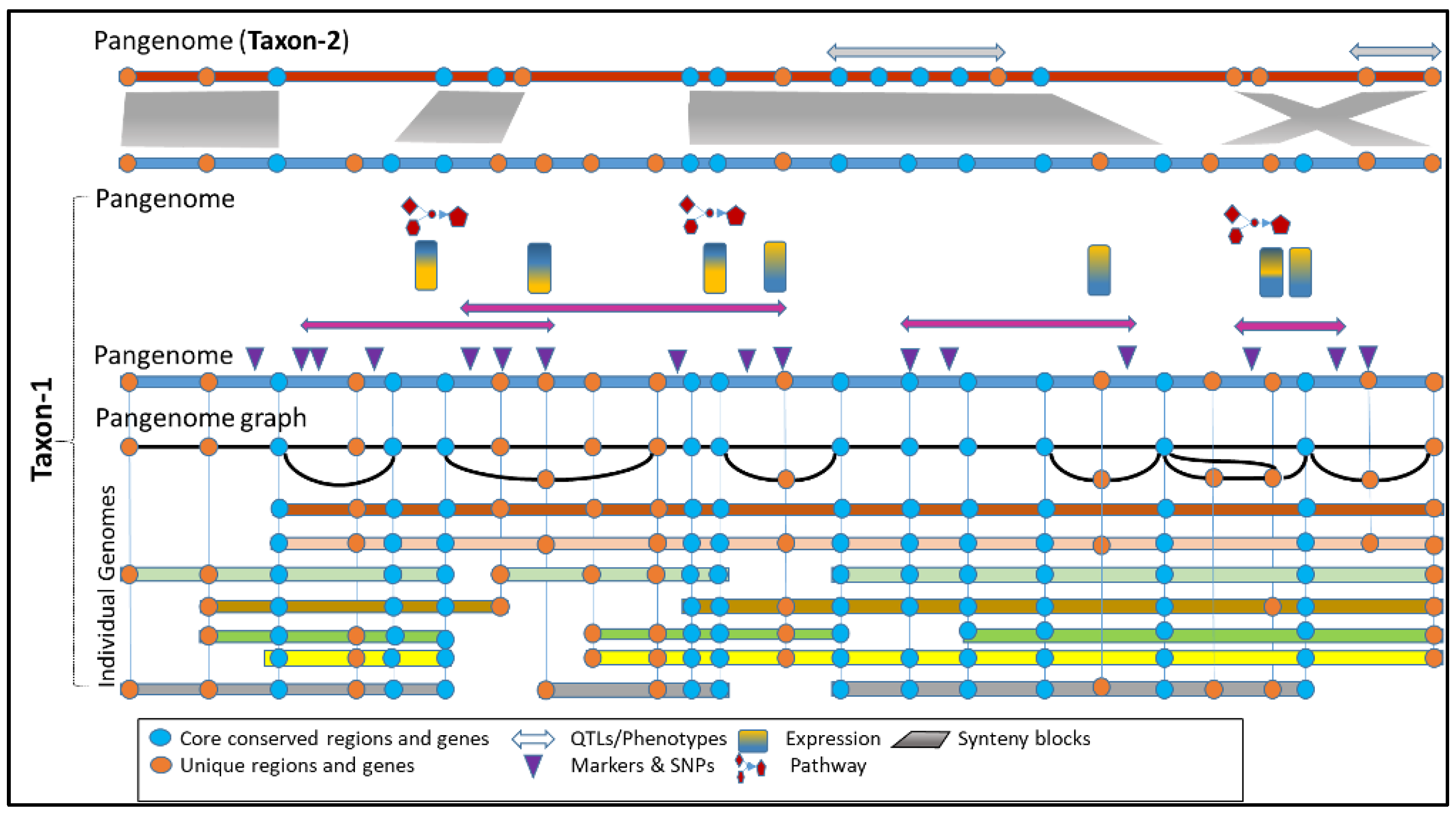
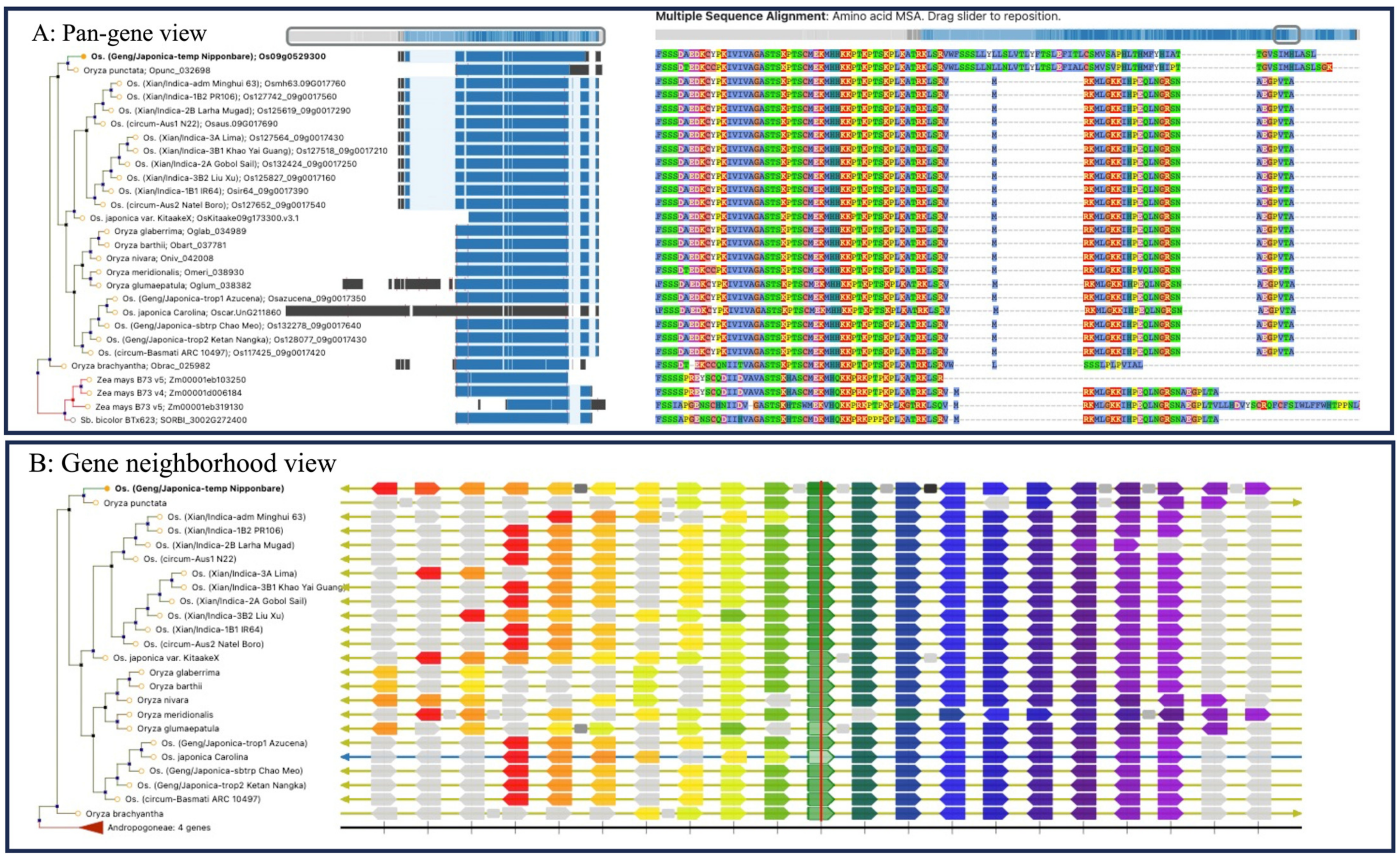
2. Pan-Genome Construction, Visualization, and Data Analysis Tools
3. A Survey of Crop Pan-Genome Portals and Data Resources
4. Plant Pan-Genomics-Driven Insights for Understanding the Basis of Agronomic Traits
5. Outlook, Opportunities, and Innovations in Plant Pan-Genome Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Computational Pan-Genomics, Consortium. Computational Pan-Genomics: Status, Promises and Challenges. Brief. Bioinform. 2018, 19, 118–135. [Google Scholar]
- Della Coletta, R.; Qiu, Y.; Ou, S.; Hufford, M.B.; Hirsch, C.N. How the Pan-Genome Is Changing Crop Genomics and Improvement. Genome Biol. 2021, 22, 3. [Google Scholar] [CrossRef] [PubMed]
- Ho, S.S.; Urban, A.E.; Mills, R.E. Structural Variation in the Sequencing Era. Nat. Rev. Genet. 2020, 21, 171–189. [Google Scholar] [CrossRef]
- Kyriakidou, M.; Tai, H.; Anglin, N.L.; Ellis, D.; Stromvik, M.V. Current Strategies of Polyploid Plant Genome Sequence Assembly. Front. Plant Sci. 2018, 9, 1660. [Google Scholar] [CrossRef] [PubMed]
- Sedlazeck, F.J.; Rescheneder, P.; Smolka, M.; Fang, H.; Nattestad, M.; von Haeseler, A.; Schatz, M.C. Accurate Detection of Complex Structural Variations Using Single-Molecule Sequencing. Nat. Methods 2018, 15, 461–468. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yu, J.; Jiang, M.; Lei, W.; Zhang, X.; Tang, H. Sequencing and Assembly of Polyploid Genomes. Methods Mol. Biol. 2023, 2545, 429–458. [Google Scholar] [PubMed]
- Sahu, S.K.; Liu, H. Long-Read Sequencing (Method of the Year 2022): The Way Forward for Plant Omics Research. Mol. Plant 2023, 16, 791–793. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Chebotarov, D.; Kudrna, D.; Llaca, V.; Lee, S.; Rajasekar, S.; Mohammed, N.; Al-Bader, N.; Sobel-Sorenson, C.; Parakkal, P.; et al. A Platinum Standard Pan-Genome Resource That Represents the Population Structure of Asian Rice. Sci. Data 2020, 7, 113. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Mauleon, R.; Hu, Z.; Chebotarov, D.; Tai, S.; Wu, Z.; Li, M.; Zheng, T.; Fuentes, R.R.; Zhang, F.; et al. Genomic Variation in 3010 Diverse Accessions of Asian Cultivated Rice. Nature 2018, 557, 43–49. [Google Scholar] [CrossRef] [PubMed]
- Schatz, M.C.; Maron, L.G.; Stein, J.C.; Hernandez Wences, A.; Gurtowski, J.; Biggers, E.; Lee, H.; Kramer, M.; Antoniou, E.; Ghiban, E.; et al. Whole Genome De Novo Assemblies of Three Divergent Strains of Rice, Oryza Sativa, Document Novel Gene Space of Aus and Indica. Genome Biol. 2014, 15, 506. [Google Scholar] [PubMed]
- Jayakodi, M.; Padmarasu, S.; Haberer, G.; Bonthala, V.S.; Gundlach, H.; Monat, C.; Lux, T.; Kamal, N.; Lang, D.; Himmelbach, A.; et al. The Barley Pan-Genome Reveals the Hidden Legacy of Mutation Breeding. Nature 2020, 588, 284–289. [Google Scholar] [CrossRef] [PubMed]
- Walkowiak, S.; Gao, L.; Monat, C.; Haberer, G.; Kassa, M.T.; Brinton, J.; Ramirez-Gonzalez, R.H.; Kolodziej, M.C.; Delorean, E.; Thambugala, D.; et al. Multiple Wheat Genomes Reveal Global Variation in Modern Breeding. Nature 2020, 588, 277–283. [Google Scholar] [CrossRef] [PubMed]
- Hirsch, C.N.; Foerster, J.M.; Johnson, J.M.; Sekhon, R.S.; Muttoni, G.; Vaillancourt, B.; Penagaricano, F.; Lindquist, E.; Pedraza, M.A.; Barry, K.; et al. Insights into the Maize Pan-Genome and Pan-Transcriptome. Plant Cell 2014, 26, 121–135. [Google Scholar] [CrossRef]
- Liu, Y.; Du, H.; Li, P.; Shen, Y.; Peng, H.; Liu, S.; Zhou, G.A.; Zhang, H.; Liu, Z.; Shi, M.; et al. Pan-Genome of Wild and Cultivated Soybeans. Cell 2020, 182, 162–176.e13. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.H.; Zhou, G.; Ma, J.; Jiang, W.; Jin, L.G.; Zhang, Z.; Guo, Y.; Zhang, J.; Sui, Y.; Zheng, L.; et al. De Novo Assembly of Soybean Wild Relatives for Pan-Genome Analysis of Diversity and Agronomic Traits. Nat. Biotechnol. 2014, 32, 1045–1052. [Google Scholar] [CrossRef]
- Song, J.M.; Guan, Z.; Hu, J.; Guo, C.; Yang, Z.; Wang, S.; Liu, D.; Wang, B.; Lu, S.; Zhou, R.; et al. Eight High-Quality Genomes Reveal Pan-Genome Architecture and Ecotype Differentiation of Brassica Napus. Nat. Plants 2020, 6, 34–45. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, W.; Chen, H.; Yang, M.; Wang, J.; Pandey, M.K.; Zhang, C.; Chang, W.C.; Zhang, L.; Zhang, X.; Tang, R.; et al. The Genome of Cultivated Peanut Provides Insight into Legume Karyotypes, Polyploid Evolution and Crop Domestication. Nat. Genet. 2019, 51, 865–876. [Google Scholar] [CrossRef] [PubMed]
- International Wheat Genome Sequencing, Consortium. Shifting the Limits in Wheat Research and Breeding Using a Fully Annotated Reference Genome. Science 2018, 361, 6403. [Google Scholar]
- Edger, P.P.; Poorten, T.J.; VanBuren, R.; Hardigan, M.A.; Colle, M.; McKain, M.R.; Smith, R.D.; Teresi, S.J.; Nelson, A.D.L.; Wai, C.M.; et al. Origin and Evolution of the Octoploid Strawberry Genome. Nat. Genet. 2019, 51, 541–547. [Google Scholar] [CrossRef] [PubMed]
- Kyriakidou, M.; Anglin, N.L.; Ellis, D.; Tai, H.H.; Stromvik, M.V. Genome Assembly of Six Polyploid Potato Genomes. Sci. Data 2020, 7, 88. [Google Scholar] [CrossRef] [PubMed]
- Shang, L.; Li, X.; He, H.; Yuan, Q.; Song, Y.; Wei, Z.; Lin, H.; Hu, M.; Zhao, F.; Zhang, C.; et al. A Super Pan-Genomic Landscape of Rice. Cell Res. 2022, 32, 878–896. [Google Scholar] [CrossRef] [PubMed]
- He, Q.; Tang, S.; Zhi, H.; Chen, J.; Zhang, J.; Liang, H.; Alam, O.; Li, H.; Zhang, H.; Xing, L.; et al. A Graph-Based Genome and Pan-Genome Variation of the Model Plant Setaria. Nat. Genet. 2023, 55, 1232–1242. [Google Scholar] [CrossRef]
- Yap, I.V.; Schneider, D.; Kleinberg, J.; Matthews, D.; Cartinhour, S.; McCouch, S.R. A Graph-Theoretic Approach to Comparing and Integrating Genetic, Physical and Sequence-Based Maps. Genetics 2003, 165, 2235–2247. [Google Scholar] [CrossRef] [PubMed]
- Tettelin, H.; Masignani, V.; Cieslewicz, M.J.; Donati, C.; Medini, D.; Ward, N.L.; Angiuoli, S.V.; Crabtree, J.; Jones, A.L.; Durkin, A.S.; et al. Genome Analysis of Multiple Pathogenic Isolates of Streptococcus Agalactiae: Implications for the Microbial Pan-Genome. Proc. Natl. Acad. Sci. USA 2005, 102, 13950–13955. [Google Scholar] [CrossRef]
- Springer, N.M.; Ying, K.; Fu, Y.; Ji, T.; Yeh, C.T.; Jia, Y.; Wu, W.; Richmond, T.; Kitzman, J.; Rosenbaum, H.; et al. Maize Inbreds Exhibit High Levels of Copy Number Variation (Cnv) and Presence/Absence Variation (Pav) in Genome Content. PLoS Genet. 2009, 5, e1000734. [Google Scholar] [CrossRef]
- Anderson, J.E.; Kantar, M.B.; Kono, T.Y.; Fu, F.; Stec, A.O.; Song, Q.; Cregan, P.B.; Specht, J.E.; Diers, B.W.; Cannon, S.B.; et al. A Roadmap for Functional Structural Variants in the Soybean Genome. G3 2014, 4, 1307–1318. [Google Scholar] [CrossRef]
- Golicz, A.A.; Bayer, P.E.; Barker, G.C.; Edger, P.P.; Kim, H.; Martinez, P.A.; Chan, C.K.; Severn-Ellis, A.; McCombie, W.R.; Parkin, I.A.; et al. The Pangenome of an Agronomically Important Crop Plant Brassica Oleracea. Nat. Commun. 2016, 7, 13390. [Google Scholar] [CrossRef]
- Tao, Y.; Luo, H.; Xu, J.; Cruickshank, A.; Zhao, X.; Teng, F.; Hathorn, A.; Wu, X.; Liu, Y.; Shatte, T.; et al. Extensive Variation within the Pan-Genome of Cultivated and Wild Sorghum. Nat. Plants 2021, 7, 766–773. [Google Scholar] [CrossRef]
- Xu, X.; Liu, X.; Ge, S.; Jensen, J.D.; Hu, F.; Li, X.; Dong, Y.; Gutenkunst, R.N.; Fang, L.; Huang, L.; et al. Resequencing 50 Accessions of Cultivated and Wild Rice Yields Markers for Identifying Agronomically Important Genes. Nat. Biotechnol. 2011, 30, 105–111. [Google Scholar] [CrossRef] [PubMed]
- Lam, H.M.; Xu, X.; Liu, X.; Chen, W.; Yang, G.; Wong, F.L.; Li, M.W.; He, W.; Qin, N.; Wang, B.; et al. Resequencing of 31 Wild and Cultivated Soybean Genomes Identifies Patterns of Genetic Diversity and Selection. Nat. Genet. 2010, 42, 1053–1059. [Google Scholar] [CrossRef]
- Gui, S.; Wei, W.; Jiang, C.; Luo, J.; Chen, L.; Wu, S.; Li, W.; Wang, Y.; Li, S.; Yang, N.; et al. A Pan-Zea Genome Map for Enhancing Maize Improvement. Genome Biol. 2022, 23, 178. [Google Scholar] [CrossRef]
- Allaby, R.G.; Ware, R.L.; Kistler, L. A Re-Evaluation of the Domestication Bottleneck from Archaeogenomic Evidence. Evol. Appl. 2019, 12, 29–37. [Google Scholar] [CrossRef]
- Tirnaz, S.; Zandberg, J.; Thomas, W.J.W.; Marsh, J.; Edwards, D.; Batley, J. Application of Crop Wild Relatives in Modern Breeding: An Overview of Resources, Experimental and Computational Methodologies. Front. Plant Sci. 2022, 13, 1008904. [Google Scholar] [CrossRef] [PubMed]
- Papa, R.; Gepts, P. Asymmetry of Gene Flow and Differential Geographical Structure of Molecular Diversity in Wild and Domesticated Common Bean (Phaseolus vulgaris L.) from Mesoamerica. Theor. Appl. Genet. 2003, 106, 239–250. [Google Scholar] [CrossRef]
- McNally, K.L.; Childs, K.L.; Bohnert, R.; Davidson, R.M.; Zhao, K.; Ulat, V.J.; Zeller, G.; Clark, R.M.; Hoen, D.R.; Bureau, T.E.; et al. Genomewide Snp Variation Reveals Relationships among Landraces and Modern Varieties of Rice. Proc. Natl. Acad. Sci. USA 2009, 106, 12273–12278. [Google Scholar] [CrossRef]
- Brozynska, M.; Furtado, A.; Henry, R.J. Genomics of Crop Wild Relatives: Expanding the Gene Pool for Crop Improvement. Plant Biotechnol. J. 2016, 14, 1070–1085. [Google Scholar] [CrossRef] [PubMed]
- Bohra, A.; Kilian, B.; Sivasankar, S.; Caccamo, M.; Mba, C.; McCouch, S.R.; Varshney, R.K. Reap the Crop Wild Relatives for Breeding Future Crops. Trends Biotechnol. 2022, 40, 412–431. [Google Scholar] [CrossRef]
- McCouch, S.R.; Rieseberg, L.H. Harnessing Crop Diversity. Proc. Natl. Acad. Sci. USA 2023, 120, e2221410120. [Google Scholar] [CrossRef]
- McCouch, S. Toward a Plant Genomics Initiative: Thoughts on the Value of Cross-Species and Cross-Genera Comparisons in the Grasses. Proc. Natl. Acad. Sci. USA 1998, 95, 1983–1985. [Google Scholar] [CrossRef]
- Wurschum, T.; Rapp, M.; Miedaner, T.; Longin, C.F.H.; Leiser, W.L. Copy Number Variation of Ppd-B1 Is the Major Determinant of Heading Time in Durum Wheat. BMC Genet. 2019, 20, 64. [Google Scholar] [CrossRef]
- Knox, A.K.; Dhillon, T.; Cheng, H.; Tondelli, A.; Pecchioni, N.; Stockinger, E.J. Cbf Gene Copy Number Variation at Frost Resistance-2 Is Associated with Levels of Freezing Tolerance in Temperate-Climate Cereals. Theor. Appl. Genet. 2010, 121, 21–35. [Google Scholar] [CrossRef] [PubMed]
- Maron, L.G.; Guimaraes, C.T.; Kirst, M.; Albert, P.S.; Birchler, J.A.; Bradbury, P.J.; Buckler, E.S.; Coluccio, A.E.; Danilova, T.V.; Kudrna, D.; et al. Aluminum Tolerance in Maize Is Associated with Higher Mate1 Gene Copy Number. Proc. Natl. Acad. Sci. USA 2013, 110, 5241–5246. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.E.; Lee, T.G.; Guo, X.; Melito, S.; Wang, K.; Bayless, A.M.; Wang, J.; Hughes, T.J.; Willis, D.K.; Clemente, T.E.; et al. Copy Number Variation of Multiple Genes at Rhg1 Mediates Nematode Resistance in Soybean. Science 2012, 338, 1206–1209. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Xu, J.; Zhu, Y.; Mo, Y.; Yao, X.F.; Wang, R.; Ku, W.; Huang, Z.; Xia, S.; Tong, J.; et al. The Copy Number Variation of Osmtd1 Regulates Rice Plant Architecture. Front. Plant Sci. 2020, 11, 620282. [Google Scholar] [CrossRef]
- Wang, Y.; Xiong, G.; Hu, J.; Jiang, L.; Yu, H.; Xu, J.; Fang, Y.; Zeng, L.; Xu, E.; Xu, J.; et al. Copy Number Variation at the Gl7 Locus Contributes to Grain Size Diversity in Rice. Nat. Genet. 2015, 47, 944–948. [Google Scholar] [CrossRef]
- Bosman, R.N.; Vervalle, J.A.; November, D.L.; Burger, P.; Lashbrooke, J.G. Grapevine Genome Analysis Demonstrates the Role of Gene Copy Number Variation in the Formation of Monoterpenes. Front. Plant Sci. 2023, 14, 1112214. [Google Scholar] [CrossRef]
- Falginella, L.; Castellarin, S.D.; Testolin, R.; Gambetta, G.A.; Morgante, M.; Di Gaspero, G. Expansion and Subfunctionalisation of Flavonoid 3′,5′-Hydroxylases in the Grapevine Lineage. BMC Genom. 2010, 11, 562. [Google Scholar] [CrossRef]
- Nilsen, K.T.; Walkowiak, S.; Xiang, D.; Gao, P.; Quilichini, T.D.; Willick, I.R.; Byrns, B.; N’Diaye, A.; Ens, J.; Wiebe, K.; et al. Copy Number Variation of Tddof Controls Solid-Stemmed Architecture in Wheat. Proc. Natl. Acad. Sci. USA 2020, 117, 28708–28718. [Google Scholar] [CrossRef]
- Gao, L.; Gonda, I.; Sun, H.; Ma, Q.; Bao, K.; Tieman, D.M.; Burzynski-Chang, E.A.; Fish, T.L.; Stromberg, K.A.; Sacks, G.L.; et al. The Tomato Pan-Genome Uncovers New Genes and a Rare Allele Regulating Fruit Flavor. Nat. Genet. 2019, 51, 1044–1051. [Google Scholar] [CrossRef]
- Liu, J.; Dawe, R.K. Large Haplotypes Highlight a Complex Age Structure within the Maize Pan-Genome. Genome Res. 2023, 33, 359–370. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Zhao, X.; Mace, E.; Henry, R.; Jordan, D. Exploring and Exploiting Pan-Genomics for Crop Improvement. Mol. Plant 2019, 12, 156–169. [Google Scholar] [CrossRef] [PubMed]
- Bayer, P.E.; Golicz, A.A.; Scheben, A.; Batley, J.; Edwards, D. Plant Pan-Genomes Are the New Reference. Nat. Plants 2020, 6, 914–920. [Google Scholar] [CrossRef] [PubMed]
- Jayakodi, M.; Schreiber, M.; Stein, N.; Mascher, M. Building Pan-Genome Infrastructures for Crop Plants and Their Use in Association Genetics. DNA Res. 2021, 28, dsaa030. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Liu, J.; Zhang, H.; Liu, Z.; Wang, Y.; Xing, L.; He, Q.; Du, H. Plant Pan-Genomics: Recent Advances, New Challenges, and Roads Ahead. J. Genet. Genom. 2022, 49, 833–846. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Sun, M.; Zhang, Z.; Jin, Y.; Zhang, A.; Lin, C.; Wu, B.; He, M.; Xu, B.; Wang, J.; et al. Pangenomic Analysis Identifies Structural Variation Associated with Heat Tolerance in Pearl Millet. Nat. Genet. 2023, 55, 507–518. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Yan, F.; Hao, F.; Ye, H.; Yue, M.; Woeste, K.; Zhao, P.; Zhang, S. Pan-Genome and Transcriptome Analyses Provide Insights into Genomic Variation and Differential Gene Expression Profiles Related to Disease Resistance and Fatty Acid Biosynthesis in Eastern Black Walnut (Juglans Nigra). Hortic. Res. 2023, 10, uhad015. [Google Scholar] [CrossRef]
- Golicz, A.A.; Batley, J.; Edwards, D. Towards Plant Pangenomics. Plant Biotechnol. J. 2016, 14, 1099–1105. [Google Scholar] [CrossRef] [PubMed]
- Garrison, E.; Siren, J.; Novak, A.M.; Hickey, G.; Eizenga, J.M.; Dawson, E.T.; Jones, W.; Garg, S.; Markello, C.; Lin, M.F.; et al. Variation Graph Toolkit Improves Read Mapping by Representing Genetic Variation in the Reference. Nat. Biotechnol. 2018, 36, 875–879. [Google Scholar] [CrossRef] [PubMed]
- Rakocevic, G.; Semenyuk, V.; Lee, W.P.; Spencer, J.; Browning, J.; Johnson, I.J.; Arsenijevic, V.; Nadj, J.; Ghose, K.; Suciu, M.C.; et al. Fast and Accurate Genomic Analyses Using Genome Graphs. Nat. Genet. 2019, 51, 354–362. [Google Scholar] [CrossRef]
- Cheng, H.; Concepcion, G.T.; Feng, X.; Zhang, H.; Li, H. Haplotype-Resolved De Novo Assembly Using Phased Assembly Graphs with Hifiasm. Nat. Methods 2021, 18, 170–175. [Google Scholar] [CrossRef]
- Padgitt-Cobb, L.K.; Kingan, S.B.; Wells, J.; Elser, J.; Kronmiller, B.; Moore, D.; Concepcion, G.; Peluso, P.; Rank, D.; Jaiswal, P.; et al. A Draft Phased Assembly of the Diploid Cascade Hop (Humulus lupulus) Genome. Plant Genome 2021, 14, e20072. [Google Scholar] [CrossRef]
- Eizenga, J.M.; Novak, A.M.; Sibbesen, J.A.; Heumos, S.; Ghaffaari, A.; Hickey, G.; Chang, X.; Seaman, J.D.; Rounthwaite, R.; Ebler, J.; et al. Pangenome Graphs. Annu. Rev. Genom. Hum. Genet 2020, 21, 139–162. [Google Scholar] [CrossRef]
- Hickey, G.; Heller, D.; Monlong, J.; Sibbesen, J.A.; Siren, J.; Eizenga, J.; Dawson, E.T.; Garrison, E.; Novak, A.M.; Paten, B. Genotyping Structural Variants in Pangenome Graphs Using the Vg Toolkit. Genome Biol. 2020, 21, 35. [Google Scholar] [CrossRef]
- Vernikos, G.S. A Review of Pangenome Tools and Recent Studies. In The Pangenome: Diversity, Dynamics and Evolution of Genomes; Tettelin, H., Medini, D., Eds.; OAPEN: Cham, Switzerland, 2020; pp. 89–112. [Google Scholar] [CrossRef]
- Glick, L.; Mayrose, I. The Effect of Methodological Considerations on the Construction of Gene-Based Plant Pan-Genomes. Genome Biol. Evol. 2023, 15, evad121. [Google Scholar] [CrossRef]
- Koren, S.; Walenz, B.P.; Berlin, K.; Miller, J.R.; Bergman, N.H.; Phillippy, A.M. Canu: Scalable and Accurate Long-Read Assembly Via Adaptive K-Mer Weighting and Repeat Separation. Genome Res. 2017, 27, 722–736. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, M.; Yuan, J.; Lin, Y.; Pevzner, P.A. Assembly of Long, Error-Prone Reads Using Repeat Graphs. Nat. Biotechnol. 2019, 37, 540–546. [Google Scholar] [CrossRef] [PubMed]
- Swain, M.T.; Tsai, I.J.; Assefa, S.A.; Newbold, C.; Berriman, M.; Otto, T.D. A Post-Assembly Genome-Improvement Toolkit (Pagit) to Obtain Annotated Genomes from Contigs. Nat. Protoc. 2012, 7, 1260–1284. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Liu, C.M.; Luo, R.; Sadakane, K.; Lam, T.W. Megahit: An Ultra-Fast Single-Node Solution for Large and Complex Metagenomics Assembly Via Succinct De Bruijn Graph. Bioinformatics 2015, 31, 1674–1676. [Google Scholar] [CrossRef] [PubMed]
- Tolstoganov, I.; Bankevich, A.; Chen, Z.; Pevzner, P.A. Cloudspades: Assembly of Synthetic Long Reads Using De Bruijn Graphs. Bioinformatics 2019, 35, i61–i70. [Google Scholar] [CrossRef] [PubMed]
- Meleshko, D.; Mohimani, H.; Tracanna, V.; Hajirasouliha, I.; Medema, M.H.; Korobeynikov, A.; Pevzner, P.A. Biosyntheticspades: Reconstructing Biosynthetic Gene Clusters from Assembly Graphs. Genome Res. 2019, 29, 1352–1362. [Google Scholar] [CrossRef]
- Li, H.; Feng, X.; Chu, C. The Design and Construction of Reference Pangenome Graphs with Minigraph. Genome Biol. 2020, 21, 265. [Google Scholar] [CrossRef]
- Guarracino, A.; Heumos, S.; Nahnsen, S.; Prins, P.; Garrison, E. Odgi: Understanding Pangenome Graphs. Bioinformatics 2022, 38, 3319–3326. [Google Scholar] [CrossRef]
- Guarracino, A.; Heumos, S.; Nahnsen, S.; Prins, P.; Garrison, E. Building Pangenome Graphs. bioRxiv 2023, 535718. [Google Scholar] [CrossRef]
- Hickey, G.; Monlong, J.; Ebler, J.; Novak, A.M.; Eizenga, J.M.; Gao, Y.; Human Pangenome Reference, C.; Marschall, T.; Li, H.; Paten, B. Pangenome Graph Construction from Genome Alignments with Minigraph-Cactus. Nat. Biotechnol. 2023, 1277. [Google Scholar] [CrossRef]
- Armstrong, J.; Hickey, G.; Diekhans, M.; Fiddes, I.T.; Novak, A.M.; Deran, A.; Fang, Q.; Xie, D.; Feng, S.; Stiller, J.; et al. Progressive Cactus Is a Multiple-Genome Aligner for the Thousand-Genome Era. Nature 2020, 587, 246–251. [Google Scholar] [CrossRef] [PubMed]
- Jonkheer, E.M.; van Workum, D.M.; Sheikhizadeh Anari, S.; Brankovics, B.; de Haan, J.R.; Berke, L.; van der Lee, T.A.J.; de Ridder, D.; Smit, S. Pantools V3: Functional Annotation, Classification and Phylogenomics. Bioinformatics 2022, 38, 4403–4405. [Google Scholar] [CrossRef] [PubMed]
- Ewels, P.A.; Peltzer, A.; Fillinger, S.; Patel, H.; Alneberg, J.; Wilm, A.; Garcia, M.U.; Di Tommaso, P.; Nahnsen, S. The Nf-Core Framework for Community-Curated Bioinformatics Pipelines. Nat. Biotechnol. 2020, 38, 276–278. [Google Scholar] [CrossRef] [PubMed]
- Vaughn, J.N.; Branham, S.E.; Abernathy, B.; Hulse-Kemp, A.M.; Rivers, A.R.; Levi, A.; Wechter, W.P. Graph-Based Pangenomics Maximizes Genotyping Density and Reveals Structural Impacts on Fungal Resistance in Melon. Nat. Commun. 2022, 13, 7897. [Google Scholar] [CrossRef]
- Li, H. Minimap2: Pairwise Alignment for Nucleotide Sequences. Bioinformatics 2018, 34, 3094–3100. [Google Scholar] [CrossRef]
- Marcais, G.; Delcher, A.L.; Phillippy, A.M.; Coston, R.; Salzberg, S.L.; Zimin, A. Mummer4: A Fast and Versatile Genome Alignment System. PLoS Comput. Biol. 2018, 14, e1005944. [Google Scholar] [CrossRef] [PubMed]
- Rautiainen, M.; Marschall, T. Graphaligner: Rapid and Versatile Sequence-to-Graph Alignment. Genome Biol. 2020, 21, 253. [Google Scholar] [CrossRef] [PubMed]
- Kavya, V.N.S.; Tayal, K.; Srinivasan, R.; Sivadasan, N. Sequence Alignment on Directed Graphs. J. Comput. Biol. 2019, 26, 53–67. [Google Scholar] [CrossRef]
- Buchler, T.; Olbrich, J.; Ohlebusch, E. Efficient Short Read Mapping to a Pangenome That Is Represented by a Graph of Ed Strings. Bioinformatics 2023, 39, btad320. [Google Scholar] [CrossRef] [PubMed]
- Poplin, R.; Chang, P.C.; Alexander, D.; Schwartz, S.; Colthurst, T.; Ku, A.; Newburger, D.; Dijamco, J.; Nguyen, N.; Afshar, P.T.; et al. A Universal Snp and Small-Indel Variant Caller Using Deep Neural Networks. Nat. Biotechnol. 2018, 36, 983–987. [Google Scholar] [CrossRef] [PubMed]
- Yun, T.; Li, H.; Chang, P.C.; Lin, M.F.; Carroll, A.; McLean, C.Y. Accurate, Scalable Cohort Variant Calls Using Deepvariant and Glnexus. Bioinformatics 2021, 36, 5582–5589. [Google Scholar] [CrossRef]
- Chiang, C.; Layer, R.M.; Faust, G.G.; Lindberg, M.R.; Rose, D.B.; Garrison, E.P.; Marth, G.T.; Quinlan, A.R.; Hall, I.M. Speedseq: Ultra-Fast Personal Genome Analysis and Interpretation. Nat. Methods 2015, 12, 966–968. [Google Scholar] [CrossRef]
- Eggertsson, H.P.; Jonsson, H.; Kristmundsdottir, S.; Hjartarson, E.; Kehr, B.; Masson, G.; Zink, F.; Hjorleifsson, K.E.; Jonasdottir, A.; Jonasdottir, A.; et al. Graphtyper Enables Population-Scale Genotyping Using Pangenome Graphs. Nat. Genet. 2017, 49, 1654–1660. [Google Scholar] [CrossRef] [PubMed]
- Ebler, J.; Ebert, P.; Clarke, W.E.; Rausch, T.; Audano, P.A.; Houwaart, T.; Mao, Y.; Korbel, J.O.; Eichler, E.E.; Zody, M.C.; et al. Pangenome-Based Genome Inference Allows Efficient and Accurate Genotyping across a Wide Spectrum of Variant Classes. Nat. Genet. 2022, 54, 518–525. [Google Scholar] [CrossRef]
- Naithani, S.; Geniza, M.; Jaiswal, P. Variant Effect Prediction Analysis Using Resources Available at Gramene Database. Methods Mol. Biol. 2017, 1533, 279–297. [Google Scholar]
- Emms, D.M.; Kelly, S. Orthofinder: Phylogenetic Orthology Inference for Comparative Genomics. Genome Biol. 2019, 20, 238. [Google Scholar] [CrossRef]
- Li, L.; Stoeckert, C.J., Jr.; Roos, D.S. Orthomcl: Identification of Ortholog Groups for Eukaryotic Genomes. Genome Res. 2003, 13, 2178–2189. [Google Scholar] [CrossRef] [PubMed]
- Miller, J.B.; Pickett, B.D.; Ridge, P.G. Justorthologs: A Fast, Accurate and User-Friendly Ortholog Identification Algorithm. Bioinformatics 2019, 35, 546–552. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Chen, Y.; Guo, C.; Qi, J. Phylomcl: Accurate Clustering of Hierarchical Orthogroups Guided by Phylogenetic Relationship and Inference of Polyploidy Events. Methods Ecol. Evol. 2020, 11, 943–954. [Google Scholar] [CrossRef]
- Altenhoff, A.M.; Train, C.M.; Gilbert, K.J.; Mediratta, I.; Mendes de Farias, T.; Moi, D.; Nevers, Y.; Radoykova, H.S.; Rossier, V.; Warwick Vesztrocy, A.; et al. Oma Orthology in 2021: Website Overhaul, Conserved Isoforms, Ancestral Gene Order and More. Nucleic Acids Res. 2021, 49, D373–D379. [Google Scholar] [CrossRef]
- Persson, E.; Sonnhammer, E.L.L. Inparanoid-Diamond: Faster Orthology Analysis with the Inparanoid Algorithm. Bioinformatics 2022, 38, 2918–2919. [Google Scholar] [CrossRef]
- Naithani, S.; Gupta, P.; Preece, J.; D’Eustachio, P.; Elser, J.L.; Garg, P.; Dikeman, D.A.; Kiff, J.; Cook, J.; Olson, A.; et al. Plant Reactome: A Knowledgebase and Resource for Comparative Pathway Analysis. Nucleic Acids Res. 2020, 48, D1093–D1103. [Google Scholar] [CrossRef]
- Durant, E.; Sabot, F.; Conte, M.; Rouard, M. Panache: A Web Browser-Based Viewer for Linearized Pangenomes. Bioinformatics 2021, 37, 4556–4558. [Google Scholar] [CrossRef] [PubMed]
- Droc, G.; Martin, G.; Guignon, V.; Summo, M.; Sempere, G.; Durant, E.; Soriano, A.; Baurens, F.C.; Cenci, A.; Breton, C.; et al. The Banana Genome Hub: A Community Database for Genomics in the Musaceae. Hortic. Res 2022, 9, uhac221. [Google Scholar] [CrossRef] [PubMed]
- Yokoyama, T.T.; Sakamoto, Y.; Seki, M.; Suzuki, Y.; Kasahara, M. Momi-G: Modular Multi-Scale Integrated Genome Graph Browser. BMC Bioinform. 2019, 20, 548. [Google Scholar] [CrossRef] [PubMed]
- Wick, R.R.; Schultz, M.B.; Zobel, J.; Holt, K.E. Bandage: Interactive Visualization of De Novo Genome Assemblies. Bioinformatics 2015, 31, 3350–3352. [Google Scholar] [CrossRef]
- Beyer, W.; Novak, A.M.; Hickey, G.; Chan, J.; Tan, V.; Paten, B.; Zerbino, D.R. Sequence Tube Maps: Making Graph Genomes Intuitive to Commuters. Bioinformatics 2019, 35, 5318–5320. [Google Scholar] [CrossRef] [PubMed]
- Gonnella, G.; Niehus, N.; Kurtz, S. Gfaviz: Flexible and Interactive Visualization of Gfa Sequence Graphs. Bioinformatics 2019, 35, 2853–2855. [Google Scholar] [CrossRef]
- Mikheenko, A.; Kolmogorov, M. Assembly Graph Browser: Interactive Visualization of Assembly Graphs. Bioinformatics 2019, 35, 3476–3478. [Google Scholar] [CrossRef]
- Kunyavskaya, O.; Prjibelski, A.D. Sgtk: A Toolkit for Visualization and Assessment of Scaffold Graphs. Bioinformatics 2019, 35, 2303–2305. [Google Scholar] [CrossRef] [PubMed]
- Durbin, R. Efficient Haplotype Matching and Storage Using the Positional Burrows-Wheeler Transform (Pbwt). Bioinformatics 2014, 30, 1266–1272. [Google Scholar] [CrossRef]
- Novak, A.M.; Garrison, E.; Paten, B. A Graph Extension of the Positional Burrows-Wheeler Transform and Its Applications. Algorithms Mol. Biol. 2017, 12, 18. [Google Scholar] [CrossRef] [PubMed]
- Grytten, I.; Rand, K.D.; Nederbragt, A.J.; Storvik, G.O.; Glad, I.K.; Sandve, G.K. Graph Peak Caller: Calling Chip-Seq Peaks on Graph-Based Reference Genomes. PLoS Comput. Biol. 2019, 15, e1006731. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Zhang, S.; Hu, H.; Yuan, Y.; Dong, J.; Chen, L.; Ma, Y.; Yang, T.; Zhou, L.; et al. A Pangenome Analysis Pipeline Provides Insights into Functional Gene Identification in Rice. Genome Biol. 2023, 24, 19. [Google Scholar] [CrossRef] [PubMed]
- Tahir Ul Qamar, M.; Zhu, X.; Xing, F.; Chen, L.L. Ppspcp: A Plant Presence/Absence Variants Scanner and Pan-Genome Construction Pipeline. Bioinformatics 2019, 35, 4156–4158. [Google Scholar] [CrossRef] [PubMed]
- Harper, L.; Campbell, J.; Cannon, E.K.S.; Jung, S.; Poelchau, M.; Walls, R.; Andorf, C.; Arnaud, E.; Berardini, T.; Birkett, C.; et al. Agbiodata Consortium Recommendations for Sustainable Genomics and Genetics Databases for Agriculture. Database 2018, 2018, bay088. [Google Scholar] [CrossRef]
- Adam-Blondon, A.F.; Alaux, M.; Pommier, C.; Cantu, D.; Cheng, Z.M.; Cramer, G.R.; Davies, C.; Delrot, S.; Deluc, L.; Di Gaspero, G.; et al. Towards an Open Grapevine Information System. Hortic. Res 2016, 3, 16056. [Google Scholar] [CrossRef]
- Bolser, D.; Staines, D.M.; Pritchard, E.; Kersey, P. Ensembl Plants: Integrating Tools for Visualizing, Mining, and Analyzing Plant Genomics Data. Methods Mol. Biol. 2016, 1374, 115–140. [Google Scholar]
- Gupta, P.; Naithani, S.; Preece, J.; Kim, S.; Cheng, T.; D’Eustachio, P.; Elser, J.; Bolton, E.E.; Jaiswal, P. Plant Reactome and Pubchem: The Plant Pathway and (Bio)Chemical Entity Knowledgebases. Methods Mol. Biol. 2022, 2443, 511–525. [Google Scholar]
- Tello-Ruiz, M.K.; Naithani, S.; Gupta, P.; Olson, A.; Wei, S.; Preece, J.; Jiao, Y.; Wang, B.; Chougule, K.; Garg, P.; et al. Gramene 2021: Harnessing the Power of Comparative Genomics and Pathways for Plant Research. Nucleic. Acids Res. 2021, 49, D1452–D1463. [Google Scholar] [CrossRef] [PubMed]
- Pasha, A.; Subramaniam, S.; Cleary, A.; Chen, X.; Berardini, T.; Farmer, A.; Town, C.; Provart, N. Araport Lives: An Updated Framework for Arabidopsis Bioinformatics. Plant Cell 2020, 32, 2683–2686. [Google Scholar] [CrossRef]
- Shamimuzzaman, M.; Gardiner, J.M.; Walsh, A.T.; Triant, D.A.; Le Tourneau, J.J.; Tayal, A.; Unni, D.R.; Nguyen, H.N.; Portwood, J.L., 2nd; Cannon, E.K.S.; et al. Maizemine: A Data Mining Warehouse for the Maize Genetics and Genomics Database. Front. Plant Sci. 2020, 11, 592730. [Google Scholar] [CrossRef] [PubMed]
- Gladman, N.; Olson, A.; Wei, S.; Chougule, K.; Lu, Z.; Tello-Ruiz, M.; Meijs, I.; Van Buren, P.; Jiao, Y.; Wang, B.; et al. Sorghumbase: A Web-Based Portal for Sorghum Genetic Information and Community Advancement. Planta 2022, 255, 35. [Google Scholar] [CrossRef]
- Arkin, A.P.; Cottingham, R.W.; Henry, C.S.; Harris, N.L.; Stevens, R.L.; Maslov, S.; Dehal, P.; Ware, D.; Perez, F.; Canon, S.; et al. Kbase: The United States Department of Energy Systems Biology Knowledgebase. Nat. Biotechnol. 2018, 36, 566–569. [Google Scholar] [CrossRef] [PubMed]
- Yates, A.D.; Allen, J.; Amode, R.M.; Azov, A.G.; Barba, M.; Becerra, A.; Bhai, J.; Campbell, L.I.; Carbajo Martinez, M.; Chakiachvili, M.; et al. Ensembl Genomes 2022: An Expanding Genome Resource for Non-Vertebrates. Nucleic. Acids Res. 2022, 50, D996–D1003. [Google Scholar] [CrossRef]
- Naithani, S.; Preece, J.; D’Eustachio, P.; Gupta, P.; Amarasinghe, V.; Dharmawardhana, P.D.; Wu, G.; Fabregat, A.; Elser, J.L.; Weiser, J.; et al. Plant Reactome: A Resource for Plant Pathways and Comparative Analysis. Nucleic. Acids Res. 2017, 45, D1029–D1039. [Google Scholar] [CrossRef] [PubMed]
- Tello-Ruiz, M.K.; Naithani, S.; Stein, J.C.; Gupta, P.; Campbell, M.; Olson, A.; Wei, S.; Preece, J.; Geniza, M.J.; Jiao, Y.; et al. Gramene 2018: Unifying Comparative Genomics and Pathway Resources for Plant Research. Nucleic Acids Res. 2018, 46, D1181–D1189. [Google Scholar] [CrossRef] [PubMed]
- Naithani, S.; Raja, R.; Waddell, E.N.; Elser, J.; Gouthu, S.; Deluc, L.G.; Jaiswal, P. Vitiscyc: A Metabolic Pathway Knowledgebase for Grapevine (Vitis vinifera). Front. Plant Sci. 2014, 5, 644. [Google Scholar] [CrossRef]
- Naithani, S.; Partipilo, C.M.; Raja, R.; Elser, J.L.; Jaiswal, P. Fragariacyc: A Metabolic Pathway Database for Woodland Strawberry Fragaria Vesca. Front. Plant Sci. 2016, 7, 242. [Google Scholar] [CrossRef]
- Woodhouse, M.R.; Cannon, E.K.; Portwood, J.L., 2nd; Harper, L.C.; Gardiner, J.M.; Schaeffer, M.L.; Andorf, C.M. A Pan-Genomic Approach to Genome Databases Using Maize as a Model System. BMC Plant Biol. 2021, 21, 385. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Furumichi, M.; Sato, Y.; Kawashima, M.; Ishiguro-Watanabe, M. Kegg for Taxonomy-Based Analysis of Pathways and Genomes. Nucleic Acids Res. 2023, 51, D587–D592. [Google Scholar] [CrossRef] [PubMed]
- Paley, S.; Karp, P.D. The Biocyc Metabolic Network Explorer. BMC Bioinform. 2021, 22, 208. [Google Scholar] [CrossRef]
- Naithani, S.; Jaiswal, P. Pathway Analysis and Omics Data Visualization Using Pathway Genome Databases: Fragariacyc, a Case Study. Methods Mol. Biol. 2017, 1533, 241–256. [Google Scholar] [PubMed]
- Hawkins, C.; Ginzburg, D.; Zhao, K.; Dwyer, W.; Xue, B.; Xu, A.; Rice, S.; Cole, B.; Paley, S.; Karp, P.; et al. Plant Metabolic Network 15: A Resource of Genome-Wide Metabolism Databases for 126 Plants and Algae. J. Integr. Plant Biol. 2021, 63, 1888–1905. [Google Scholar] [CrossRef]
- Foerster, H.; Bombarely, A.; Battey, J.N.D.; Sierro, N.; Ivanov, N.V.; Mueller, L.A. Solcyc: A Database Hub at the Sol Genomics Network (Sgn) for the Manual Curation of Metabolic Networks in Solanum and Nicotiana Specific Databases. Database 2018, 2018, bay035. [Google Scholar] [CrossRef] [PubMed]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A Comparative Platform for Green Plant Genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef] [PubMed]
- Deng, C.H.; Naithani, S.; Kumari, S.; Cobo-Simon, I.; Quezada-Rodriguez, E.H.; Skrabisova, M.; Gladman, N.; Correll, M.J.; Sikiru, A.B.; Afuwape, O.O.; et al. Agricultural Sciences in the Big Data Era: Genotype and Phenotype Data Standardization, Utilization and Integration. Preprints 2023, 2023061013. [Google Scholar] [CrossRef]
- Sun, C.; Hu, Z.; Zheng, T.; Lu, K.; Zhao, Y.; Wang, W.; Shi, J.; Wang, C.; Lu, J.; Zhang, D.; et al. Rpan: Rice Pan-Genome Browser for Approximately 3000 Rice Genomes. Nucleic Acids Res. 2017, 45, 597–605. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Feng, Q.; Lu, H.; Li, Y.; Wang, A.; Tian, Q.; Zhan, Q.; Lu, Y.; Zhang, L.; Huang, T.; et al. Pan-Genome Analysis Highlights the Extent of Genomic Variation in Cultivated and Wild Rice. Nat. Genet. 2018, 50, 278–284. [Google Scholar] [CrossRef]
- Gui, S.; Yang, L.; Li, J.; Luo, J.; Xu, X.; Yuan, J.; Chen, L.; Li, W.; Yang, X.; Wu, S.; et al. Zeamap, a Comprehensive Database Adapted to the Maize Multi-Omics Era. iScience 2020, 23, 101241. [Google Scholar] [CrossRef] [PubMed]
- Valentin, G.; Abdel, T.; Gaetan, D.; Jean-Francois, D.; Matthieu, C.; Mathieu, R. Greenphyldb V5: A Comparative Pangenomic Database for Plant Genomes. Nucleic Acids Res. 2021, 49, D1464–D1471. [Google Scholar]
- Bayer, P.E.; Petereit, J.; Durant, E.; Monat, C.; Rouard, M.; Hu, H.; Chapman, B.; Li, C.; Cheng, S.; Batley, J.; et al. Wheat Panache: A Pangenome Graph Database Representing Presence-Absence Variation across Sixteen Bread Wheat Genomes. Plant Genome 2022, 15, e20221. [Google Scholar] [CrossRef]
- Blake, V.C.; Woodhouse, M.R.; Lazo, G.R.; Odell, S.G.; Wight, C.P.; Tinker, N.A.; Wang, Y.; Gu, Y.Q.; Birkett, C.L.; Jannink, J.L.; et al. Graingenes: Centralized Small Grain Resources and Digital Platform for Geneticists and Breeders. Database 2019, 2019, baz065. [Google Scholar] [CrossRef]
- Montenegro, J.D.; Golicz, A.A.; Bayer, P.E.; Hurgobin, B.; Lee, H.; Chan, C.K.; Visendi, P.; Lai, K.; Dolezel, J.; Batley, J.; et al. The Pangenome of Hexaploid Bread Wheat. Plant J. 2017, 90, 1007–1013. [Google Scholar] [CrossRef]
- Li, N.; He, Q.; Wang, J.; Wang, B.; Zhao, J.; Huang, S.; Yang, T.; Tang, Y.; Yang, S.; Aisimutuola, P.; et al. Super-Pangenome Analyses Highlight Genomic Diversity and Structural Variation across Wild and Cultivated Tomato Species. Nat. Genet. 2023, 55, 852–860. [Google Scholar] [CrossRef] [PubMed]
- Barchi, L.; Rabanus-Wallace, M.T.; Prohens, J.; Toppino, L.; Padmarasu, S.; Portis, E.; Rotino, G.L.; Stein, N.; Lanteri, S.; Giuliano, G. Improved Genome Assembly and Pan-Genome Provide Key Insights into Eggplant Domestication and Breeding. Plant J. 2021, 107, 579–596. [Google Scholar] [CrossRef] [PubMed]
- Ou, L.; Li, D.; Lv, J.; Chen, W.; Zhang, Z.; Li, X.; Yang, B.; Zhou, S.; Yang, S.; Li, W.; et al. Pan-Genome of Cultivated Pepper (Capsicum) and Its Use in Gene Presence-Absence Variation Analyses. New Phytol. 2018, 220, 360–363. [Google Scholar] [CrossRef]
- Zhang, B.; Huang, H.; Tibbs-Cortes, L.E.; Vanous, A.; Zhang, Z.; Sanguinet, K.; Garland-Campbell, K.A.; Yu, J.; Li, X. Streamline Unsupervised Machine Learning to Survey and Graph Indel-Based Haplotypes from Pan-Genomes. Mol. Plant 2023, 16, 975–978. [Google Scholar] [CrossRef] [PubMed]
- Torkamaneh, D.; Lemay, M.A.; Belzile, F. The Pan-Genome of the Cultivated Soybean (Pansoy) Reveals an Extraordinarily Conserved Gene Content. Plant Biotechnol. J. 2021, 19, 1852–1862. [Google Scholar] [CrossRef]
- Hubner, S.; Bercovich, N.; Todesco, M.; Mandel, J.R.; Odenheimer, J.; Ziegler, E.; Lee, J.S.; Baute, G.J.; Owens, G.L.; Grassa, C.J.; et al. Sunflower Pan-Genome Analysis Shows That Hybridization Altered Gene Content and Disease Resistance. Nat. Plants 2019, 5, 54–62. [Google Scholar] [CrossRef] [PubMed]
- Jin, S.; Han, Z.; Hu, Y.; Si, Z.; Dai, F.; He, L.; Cheng, Y.; Li, Y.; Zhao, T.; Fang, L.; et al. Structural Variation (Sv)-Based Pan-Genome and Gwas Reveal the Impacts of Svs on the Speciation and Diversification of Allotetraploid Cottons. Mol. Plant 2023, 16, 678–693. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Wang, X.; Liu, S.; Huang, Y.; Guo, Y.X.; Xie, W.Z.; Liu, H.; Tahir Ul Qamar, M.; Xu, Q.; Chen, L.L. Citrus Pan-Genome to Breeding Database (Cpbd): A Comprehensive Genome Database for Citrus Breeding. Mol. Plant 2022, 15, 1503–1505. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Qi, J.; Qin, X.; Dou, W.; Lei, T.; Hu, A.; Jia, R.; Jiang, G.; Zou, X.; Long, Q.; et al. Citgvd: A Comprehensive Database of Citrus Genomic Variations. Hortic. Res 2020, 7, 12. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Jiao, C.; Schwaninger, H.; Chao, C.T.; Ma, Y.; Duan, N.; Khan, A.; Ban, S.; Xu, K.; Cheng, L.; et al. Phased Diploid Genome Assemblies and Pan-Genomes Provide Insights into the Genetic History of Apple Domestication. Nat. Genet. 2020, 52, 1423–1432. [Google Scholar] [CrossRef] [PubMed]
- Song, J.M.; Liu, D.X.; Xie, W.Z.; Yang, Z.; Guo, L.; Liu, K.; Yang, Q.Y.; Chen, L.L. Bnpir: Brassica Napus Pan-Genome Information Resource for 1689 Accessions. Plant Biotechnol. J. 2021, 19, 412–414. [Google Scholar] [CrossRef] [PubMed]
- Qi, W.; Lim, Y.W.; Patrignani, A.; Schlapfer, P.; Bratus-Neuenschwander, A.; Gruter, S.; Chanez, C.; Rodde, N.; Prat, E.; Vautrin, S.; et al. The Haplotype-Resolved Chromosome Pairs of a Heterozygous Diploid African Cassava Cultivar Reveal Novel Pan-Genome and Allele-Specific Transcriptome Features. Gigascience 2022, 11, giac028. [Google Scholar] [CrossRef]
- Ruperao, P.; Thirunavukkarasu, N.; Gandham, P.; Selvanayagam, S.; Govindaraj, M.; Nebie, B.; Manyasa, E.; Gupta, R.; Das, R.R.; Odeny, D.A.; et al. Sorghum Pan-Genome Explores the Functional Utility for Genomic-Assisted Breeding to Accelerate the Genetic Gain. Front. Plant Sci. 2021, 12, 666342. [Google Scholar] [CrossRef]
- Varshney, R.K.; Roorkiwal, M.; Sun, S.; Bajaj, P.; Chitikineni, A.; Thudi, M.; Singh, N.P.; Du, X.; Upadhyaya, H.D.; Khan, A.W.; et al. A Chickpea Genetic Variation Map Based on the Sequencing of 3,366 Genomes. Nature 2021, 599, 622–627. [Google Scholar] [CrossRef]
- Zhao, J.; Bayer, P.E.; Ruperao, P.; Saxena, R.K.; Khan, A.W.; Golicz, A.A.; Nguyen, H.T.; Batley, J.; Edwards, D.; Varshney, R.K. Trait Associations in the Pangenome of Pigeon Pea (Cajanus cajan). Plant Biotechnol. J. 2020, 18, 1946–1954. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Golicz, A.A.; Lu, K.; Dossa, K.; Zhang, Y.; Chen, J.; Wang, L.; You, J.; Fan, D.; Edwards, D.; et al. Insight into the Evolution and Functional Characteristics of the Pan-Genome Assembly from Sesame Landraces and Modern Cultivars. Plant Biotechnol. J. 2019, 17, 881–892. [Google Scholar] [CrossRef]
- Li, J.; Yuan, D.; Wang, P.; Wang, Q.; Sun, M.; Liu, Z.; Si, H.; Xu, Z.; Ma, Y.; Zhang, B.; et al. Cotton Pan-Genome Retrieves the Lost Sequences and Genes During Domestication and Selection. Genome Biol. 2021, 22, 119. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, J.; Li, Y.; Jiang, B.; Wang, X.; Xu, W.H.; Wang, Y.Q.; Zhang, P.T.; Zhang, Y.J.; Kong, X.D. Pan-Genome Analysis Reveals the Abundant Gene Presence/Absence Variations among Different Varieties of Melon and Their Influence on Traits. Front. Plant Sci. 2022, 13, 835496. [Google Scholar] [CrossRef]
- Li, H.; Wang, S.; Chai, S.; Yang, Z.; Zhang, Q.; Xin, H.; Xu, Y.; Lin, S.; Chen, X.; Yao, Z.; et al. Graph-Based Pan-Genome Reveals Structural and Sequence Variations Related to Agronomic Traits and Domestication in Cucumber. Nat. Commun. 2022, 13, 682. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Q.; Edger, P.P.; Xue, L.; Qiong, L.; Lu, J.; Zhang, Y.; Cao, Q.; Yocca, A.E.; Platts, A.E.; Knapp, S.J.; et al. Evolutionary History and Pan-Genome Dynamics of Strawberry (Fragaria spp.). Proc. Natl. Acad. Sci. USA 2021, 118, 5. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Tu, R.; Ruan, Z.; Chen, C.; Peng, Z.; Zhou, X.; Sun, L.; Hong, Y.; Chen, D.; Liu, Q.; et al. Photoperiod and Gravistimulation-Associated Tiller Angle Control 1 Modulates Dynamic Changes in Rice Plant Architecture. Theor. Appl. Genet. 2023, 136, 160. [Google Scholar] [CrossRef]
- Yu, B.; Lin, Z.; Li, H.; Li, X.; Li, J.; Wang, Y.; Zhang, X.; Zhu, Z.; Zhai, W.; Wang, X.; et al. Tac1, a Major Quantitative Trait Locus Controlling Tiller Angle in Rice. Plant J. 2007, 52, 891–898. [Google Scholar] [CrossRef]
- Boukail, S.; Macharia, M.; Miculan, M.; Masoni, A.; Calamai, A.; Palchetti, E.; Dell’Acqua, M. Genome Wide Association Study of Agronomic and Seed Traits in a World Collection of Proso Millet (Panicum miliaceum L.). BMC Plant Biol. 2021, 21, 330. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Y.; Peng, J.; Fan, B.; Xu, D.; Wu, J.; Cao, Z.; Gao, Y.; Wang, X.; Li, S.; et al. High-Quality Genome Assembly and Pan-Genome Studies Facilitate Genetic Discovery in Mung Bean and Its Improvement. Plant Commun. 2022, 3, 100352. [Google Scholar] [CrossRef]
- D’Hont, A.; Denoeud, F.; Aury, J.M.; Baurens, F.C.; Carreel, F.; Garsmeur, O.; Noel, B.; Bocs, S.; Droc, G.; Rouard, M.; et al. The Banana (Musa acuminata) Genome and the Evolution of Monocotyledonous Plants. Nature 2012, 488, 213–217. [Google Scholar] [CrossRef] [PubMed]
- Fernie, A.R.; Aharoni, A. Pan-Genomic Illumination of Tomato Identifies Novel Gene-Trait Interactions. Trends Plant Sci. 2019, 24, 882–884. [Google Scholar] [CrossRef]
- Huff, M.; Hulse-Kemp, A.M.; Scheffler, B.E.; Youngblood, R.C.; Simpson, S.A.; Babiker, E.; Staton, M. Long-Read, Chromosome-Scale Assembly of Vitis Rotundifolia Cv. Carlos and Its Unique Resistance to Xylella Fastidiosa Subsp. Fastidiosa. BMC Genom. 2023, 24, 409. [Google Scholar] [CrossRef]
- Oren, E.; Dafna, A.; Tzuri, G.; Halperin, I.; Isaacson, T.; Elkabetz, M.; Meir, A.; Saar, U.; Ohali, S.; La, T.; et al. Pan-Genome and Multi-Parental Framework for High-Resolution Trait Dissection in Melon (Cucumis melo). Plant J. 2022, 112, 1525–1542. [Google Scholar] [CrossRef] [PubMed]
- Hasan, N.; Choudhary, S.; Naaz, N.; Sharma, N.; Laskar, R.A. Recent Advancements in Molecular Marker-Assisted Selection and Applications in Plant Breeding Programmes. J. Genet. Eng. Biotechnol. 2021, 19, 128. [Google Scholar] [CrossRef]
- Garrido-Cardenas, J.A.; Mesa-Valle, C.; Manzano-Agugliaro, F. Trends in Plant Research Using Molecular Markers. Planta 2018, 247, 543–557. [Google Scholar] [CrossRef]
- Moncada, P.; McCouch, S. Simple Sequence Repeat Diversity in Diploid and Tetraploid Coffea Species. Genome 2004, 47, 501–509. [Google Scholar] [CrossRef]
- McCouch, S.R.; Chen, X.; Panaud, O.; Temnykh, S.; Xu, Y.; Cho, Y.G.; Huang, N.; Ishii, T.; Blair, M. Microsatellite Marker Development, Mapping and Applications in Rice Genetics and Breeding. Plant Mol. Biol. 1997, 35, 89–99. [Google Scholar] [CrossRef]
- Tanksley, S.D.; McCouch, S.R. Seed Banks and Molecular Maps: Unlocking Genetic Potential from the Wild. Science 1997, 277, 1063–1066. [Google Scholar] [CrossRef]
- Morales, K.Y.; Singh, N.; Perez, F.A.; Ignacio, J.C.; Thapa, R.; Arbelaez, J.D.; Tabien, R.E.; Famoso, A.; Wang, D.R.; Septiningsih, E.M.; et al. An Improved 7k Snp Array, the C7air, Provides a Wealth of Validated Snp Markers for Rice Breeding and Genetics Studies. PLoS ONE 2020, 15, e0232479. [Google Scholar] [CrossRef]
- Miller, J.R.; Zhou, P.; Mudge, J.; Gurtowski, J.; Lee, H.; Ramaraj, T.; Walenz, B.P.; Liu, J.; Stupar, R.M.; Denny, R.; et al. Hybrid Assembly with Long and Short Reads Improves Discovery of Gene Family Expansions. BMC Genom. 2017, 18, 541. [Google Scholar] [CrossRef]
- Cheng, C.; Fei, Z.; Xiao, P. Methods to Improve the Accuracy of Next-Generation Sequencing. Front. Bioeng. Biotechnol. 2023, 11, 982111. [Google Scholar] [CrossRef] [PubMed]
- Myburg, A.A.; Grattapaglia, D.; Tuskan, G.A.; Hellsten, U.; Hayes, R.D.; Grimwood, J.; Jenkins, J.; Lindquist, E.; Tice, H.; Bauer, D.; et al. The Genome of Eucalyptus Grandis. Nature 2014, 510, 356–362. [Google Scholar] [CrossRef]
- Shulaev, V.; Sargent, D.J.; Crowhurst, R.N.; Mockler, T.C.; Folkerts, O.; Delcher, A.L.; Jaiswal, P.; Mockaitis, K.; Liston, A.; Mane, S.P.; et al. The Genome of Woodland Strawberry (Fragaria vesca). Nat. Genet. 2011, 43, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Sun, H.; Gao, L.; Branham, S.; McGregor, C.; Renner, S.S.; Xu, Y.; Kousik, C.; Wechter, W.P.; Levi, A.; et al. A Citrullus Genus Super-Pangenome Reveals Extensive Variations in Wild and Cultivated Watermelons and Sheds Light on Watermelon Evolution and Domestication. Plant Biotechnol. J. 2023, 6, 544282. [Google Scholar] [CrossRef]
- Naithani, S.; Dikeman, D.A.; Garg, P.; Al-Bader, N.; Jaiswal, P. Beyond Gene Ontology (Go): Using Biocuration Approach to Improve the Gene Nomenclature and Functional Annotation of Rice S-Domain Kinase Subfamily. PeerJ 2021, 9, e11052. [Google Scholar] [CrossRef]
- Naithani, S.; Komath, S.S.; Nonomura, A.; Govindjee, G. Plant Lectins and Their Many Roles: Carbohydrate-Binding and Beyond. J. Plant Physiol. 2021, 266, 153531. [Google Scholar] [CrossRef]
- Monaco, M.K.; Sen, T.Z.; Dharmawardhana, P.D.; Ren, L.; Schaeffer, M.; Naithani, S.; Amarasinghe, V.; Thomason, J.; Harper, L.; Gardiner, J.; et al. Maize Metabolic Network Construction and Transcriptome Analysis. Plant Genome 2013, 6, 1–12. [Google Scholar] [CrossRef]
- Jaiswal, P.; Usadel, B. Plant Pathway Databases. Methods Mol. Biol. 2016, 1374, 71–87. [Google Scholar]
- Naithani, S.; Nonogaki, H.; Jaiswal, P. Exploring Crossroads between Seed Development and Stress-Response. In Mechanism of Plant Hormone Signaling under Stress; Pandey, G.K., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2017; pp. 415–454. [Google Scholar] [CrossRef]
- Gene Ontology, C.; Aleksander, S.A.; Balhoff, J.; Carbon, S.; Cherry, J.M.; Drabkin, H.J.; Ebert, D.; Feuermann, M.; Gaudet, P.; Harris, N.L.; et al. The Gene Ontology Knowledgebase in 2023. Genetics 2023, 224, iyad031. [Google Scholar] [CrossRef]
- Cooper, L.; Jaiswal, P. The Plant Ontology: A Tool for Plant Genomics. Methods Mol. Biol. 2016, 1374, 89–114. [Google Scholar]
- Walls, R.L.; Cooper, L.; Elser, J.; Gandolfo, M.A.; Mungall, C.J.; Smith, B.; Stevenson, D.W.; Jaiswal, P. The Plant Ontology Facilitates Comparisons of Plant Development Stages across Species. Front. Plant Sci. 2019, 10, 631. [Google Scholar] [CrossRef]
- Naithani, S.; Mohanty, B.; Elser, J.; D’Eustachio, P.; Jaiswal, P. Biocuration of a Transcription Factors Network Involved in Submergence Tolerance During Seed Germination and Coleoptile Elongation in Rice (Oryza sativa). Plants 2023, 12, 1. [Google Scholar] [CrossRef] [PubMed]
- Naithani, S.; Dharmawardhana, P.; Nasrallah, J.B. SCR. In Handbook of Biologically Active Peptides; Kastin, A.J., Ed.; Elsevier Science: Amsterdam, Netherlands, 2013; pp. 58–66. ISBN 978-0-12-385095-9. [Google Scholar]
- Bolger, M.; Schwacke, R.; Usadel, B. Mapman Visualization of Rna-Seq Data Using Mercator4 Functional Annotations. Methods Mol. Biol. 2021, 2354, 195–212. [Google Scholar] [PubMed]
- Naithani, S.; Gupta, P.; Preece, J.; Garg, P.; Fraser, V.; Padgitt-Cobb, L.K.; Martin, M.; Vining, K.; Jaiswal, P. Involving Community in Genes and Pathway Curation. Database 2019, 2019, bay146. [Google Scholar] [CrossRef]
- Gupta, P.; Geniza, M.; Naithani, S.; Phillips, J.L.; Haq, E.; Jaiswal, P. Chia (Salvia hispanica) Gene Expression Atlas Elucidates Dynamic Spatio-Temporal Changes Associated with Plant Growth and Development. Front. Plant Sci. 2021, 12, 667678. [Google Scholar] [CrossRef]
- Hendre, P.S.; Muthemba, S.; Kariba, R.; Muchugi, A.; Fu, Y.; Chang, Y.; Song, B.; Liu, H.; Liu, M.; Liao, X.; et al. African Orphan Crops Consortium (Aocc): Status of Developing Genomic Resources for African Orphan Crops. Planta 2019, 250, 989–1003. [Google Scholar] [CrossRef]
- Chang, Y.; Liu, H.; Liu, M.; Liao, X.; Sahu, S.K.; Fu, Y.; Song, B.; Cheng, S.; Kariba, R.; Muthemba, S.; et al. The Draft Genomes of Five Agriculturally Important African Orphan Crops. Gigascience 2019, 8, giy152. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool Name and URL | Remarks and Citation |
|---|---|
| Genome assembly | |
| Hifiasm https://github.com/chhylp123/hifiasm (accessed on 13 September 2023). | Constructs haplotype-resolved assemblies from accurate HiFi Reads [60]. |
| Canu https://github.com/marbl/canu (accessed on 13 September 2023). | Assembles genomes of any size from single molecule sequences and provides graphical fragment assembly that can be integrated with complementary phasing and scaffolding methods [66]. |
| Flye https://github.com/fenderglass/Flye (accessed on 13 September 2023). | Assembles single molecule, long-read sequencing data into genomes using repeat graphs [67]. |
| PAGIT https://www.sanger.ac.uk/tool/pagit (accessed on 13 September 2023). | PAGIT is a package of tools for generating high-quality draft genome sequences by ordering contigs, closing gaps, correcting sequence errors, and transferring annotation. PAGIT is compiled for Linux/UNIX systems and is available as a virtual machine [68]. |
| MEGAHIT https://github.com/voutcn/megahit (accessed on 13 September 2023). | Ultra-fast NGS assembler for metagenomes [69]. |
| SPADes https://cab.spbu.ru/software/spades/ (accessed on 13 September 2023). | A set of genome assembly and analysis tools that can use long- and short-read sequence data [70,71]. |
| Pan-genome graph construction, normalization, identification of structural variants, and visualization | |
| Vgtools: vg construct, vg call, vg giraffe, vg map or vg mpmap https://github.com/vgteam/vg (accessed on 13 September 2023). | Toolset for eukaryotic pan-genome graph construction, read mapping, variant calling, and graph visualization [58]. |
| Minigraph https://github.com/lh3/minigraph (accessed on 13 September 2023). | Tool for graph construction, mapping, and variant calling [72]. |
| ODGI https://github.com/pangenome/odgi (accessed on 13 September 2023). | Optimized Dynamic Genome/Graph Implementation (ODGI) is a tool suite representing graphs, including structurally complex regions, with minimal memory overhead [73]. It is a pan-genome toolbox with more than 30 tools to transform, analyze, simplify, validate, annotate, and visualize pan-genome graphs. |
| PGGB https://github.com/pangenome/pggb (accessed on 13 September 2023). | Uses ODGI as the backbone for pan-genome graph construction, normalization, and visualization [74]. |
| MGRgraph https://github.com/LeilyR/Multi-genome-Reference (accessed on 13 September 2023). | An algorithm for building a multi-genome graph. |
| Cactus https://github.com/ComparativeGenomicsToolkit/cactus (accessed on 13 September 2023). | A reference-free multiple genome alignment program that can use progressive mode to build pan-genome across different species [75,76] |
| PanTools https://pantools.readthedocs.io/en/latest/user_guide/install.html (accessed on 13 September 2023). | A platform for pan-genome graph construction, read mapping, phylogeny analysis, pan-graph query, and pan-gene annotation [77]. |
| Smoothxg https://github.com/pangenome/smoothxg (accessed on 13 September 2023). | A tool for local reconstruction of variation graphs. |
| nf-core/pangenome https://github.com/nf-core/pangenome (accessed on 13 September 2023). | Nextflow pipeline for all-vs-all alignment, pan-genome graph construction, normalization, remove redundancy, and visualization (through ODGI) [78]. |
| SeqWish https://github.com/ekg/seqwish (accessed on 13 September 2023). | Builds a variation graph from pairwise alignments [73]. |
| PanPipe https://github.com/USDA-ARS-GBRU/PanPipes (accessed on 13 September 2023). | An end-to-end pan-genome graph construction and genetic analysis pipeline [79]. |
| PanGene https://github.com/lh3/pangene (accessed on 13 September 2023). | Used for ortholog and paralog analysis and for building pan-gene graphs. |
| Minimap2 https://github.com/lh3/minimap2 (accessed on 13 September 2023). | A fast DNA or long mRNA sequence aligner to a reference genome [80]. |
| NGMLR https://github.com/philres/ngmlr (accessed on 13 September 2023). | This program aligns PacBio long reads to genomes for detecting complex structural variations [5]. |
| MUMmer4 https://mummer.sourceforge.net/ (accessed on 13 September 2023). https://github.com/mummer4/mummer (accessed on 13 September 2023). | A genome-to-genome aligner tool [81]. |
| GraphAligner https://github.com/maickrau/GraphAligner (accessed on 13 September 2023). | A tool for aligning long reads to genome graphs [82]. |
| V-ALIGN https://github.com/tcsatc/V-ALIGN (accessed on 13 September 2023). | V-ALIGN allows gapped sequence alignment directly on the input graph and supports affine and linear gaps [83]. |
| PaSGAL https://github.com/ParBLiSS/PaSGAL (accessed on 13 September 2023). | Parallel Sequence to Graph Aligner (PaSGAL) facilitates local sequence alignment of sequences to variation graphs, splicing graphs, etc. |
| GED-MAP https://github.com/thomas-buechler-ulm/gedmap (accessed on 13 September 2023). | A tool for mapping short-read sequence data to the pan-genome graph [84]. |
| DeepVariant https://github.com/google/deepvariant (accessed on 13 September 2023). | A deep learning-based variant caller that uses sequence read alignments in BAM and CRAM format to produce image tensors and convolutional neural networks to identify universal SNP and small-indel variants [85,86]. |
| SpeedSeq https://github.com/hall-lab/speedseq (accessed on 13 September 2023). | A platform for alignment, variant calling, and functional annotation [87]. |
| graphTyper https://github.com/DecodeGenetics/graphtyper (accessed on 13 September 2023). | This graph-based variant caller realigns short-read sequence data to a pan-genome for discovering sequence variants [88]. |
| PanGenie https://github.com/eblerjana/pangenie (accessed on 13 September 2023). | An alignment-free Kmer-based genotyper for structural variation detection on pan-genome graphs. It uses short-read sequencing data to genotype a broad spectrum of genetic variation [89]. |
| VEP https://ensembl.gramene.org/tools.html (accessed on 13 September 2023). | The Variant Effect Prediction (VEP) tool helps in analyzing the consequences of sequence variations on transcript structure and gene function [90]. |
| OrthoFinder https://github.com/davidemms/OrthoFinder (accessed on 13 September 2023). | This method is used for finding orthologs in proteomes [91]. |
| OrthoMCL https://orthomcl.org/orthomcl/app (accessed on 13 September 2023). | A scalable method for constructing orthology groups from eukaryotic proteomes [92]. |
| JustOrthologs https://github.com/ridgelab/JustOrthologs/ (accessed on 13 September 2023). | JustOrthologs is a fast ortholog identification algorithm that uses the conservation of gene structure [93]. |
| PhyloMCL https://sourceforge.net/projects/phylomcl/files/Materials/ (accessed on 13 September 2023). | PhyloMCL provides accurate clustering of hierarchical orthogroups guided by phylogenetic relationships and inference of polyploidy events [94]. |
| OMA https://github.com/DessimozLab/OmaStandalone/tree/v2.4.0 (accessed on 13 September 2023). https://omabrowser.org/oma/home/ (accessed on 13 September 2023). | Orthologous Matrix (OMA) is a method for ortholog identification from genomes [95]. |
| InParanoid-Diamond https://bitbucket.org/sonnhammergroup/inparanoid/src (accessed on 13 September 2023). | The tool is used for the identification of gene-orthologs and gene family clustering [96]. This is used for orthology projection in the Plant Reactome (https://plantreactome.gramene.org) [97]. |
| Panache https://github.com/SouthGreenPlatform/panache (accessed on 13 September 2023). | A web-based tool for viewing linearized pan-genomes [98]. For example, the banana genome hub [99]. |
| MoMI-G https://github.com/MoMI-G/MoMI-G/ (accessed on 13 September 2023). | Genome graph browser for viewing structural variations. Users can filter and visualize annotations and inspect read alignments over the genome graph [100]. |
| panGraphViewer https://github.com/TF-Chan-Lab/panGraphViewer (accessed on 13 September 2023). | panGraphViewer, based on Python3, is used for pan-genome graph visualization and runs on all major operating systems. |
| Bandage https://rrwick.github.io/Bandage/ (accessed on 13 September 2023). | An interactive tool for visualizing de novo assembled genomes [101]. |
| Bandage-NG https://github.com/asl/BandageNG (accessed on 13 September 2023). | GUI program to interact with assembly graphs based on the Open Graph Drawing Framework (OGDF) and Open Graph Algorithms and Data Structures Framework). |
| sequenceTubeMaps https://github.com/vgteam/sequenceTubeMap (accessed on 13 September 2023). | Interactive visualization of genomes [102]. |
| GfaViz https://github.com/ggonnella/gfaviz (accessed on 13 September 2023). | Interactive visualization of Graphical Fragment Assembly (GFA) genome graphs [103]. |
| AGB https://github.com/almiheenko/AGB (accessed on 13 September 2023). | Assembly Graph Browser (AGB) is used for constructing and visualizing large assembly graphs and repeat sequence analysis [104]. |
| IGGE https://github.com/immersivegraphgenomeexplorer/IGGE (accessed on 13 September 2023). | An interactive graph genomes browser. |
| GFAViewer https://lh3.github.io/gfatools/ (accessed on 13 September 2023). | Used for online visualization of GFA files. |
| SGTK https://github.com/olga24912/SGTK (accessed on 13 September 2023). | The scaffold graph toolkit is used for the construction and interactive visualization of scaffold graphs using sequencing data [105]. |
| Maffer https://github.com/pangenome/maffer (accessed on 13 September 2023). | It converts sorted graphs to multiple alignment format (MAF). |
| Gfatools https://github.com/lh3/gfatools (accessed on 13 September 2023). | A set of tools to parse, subgraph, and convert GFA or rGFA format to FASTA/BED format. |
| Pgge https://github.com/pangenome/pgge (accessed on 13 September 2023). | It is a pan-genome graph evaluator |
| WGT https://github.com/Kuanhao-Chao/Wheeler_Graph_Toolkit (accessed on 13 September 2023). | This package contains tools and algorithms for recognizing, visualizing, and generating Wheeler graphs. |
| GBWT https://github.com/jltsiren/gbwt (accessed on 13 September 2023). | A tool used for haplotype matching and storage using the positional Burrows-Wheeler Transform (PBWT) approach [106,107]. |
| Spodgi https://github.com/pangenome/spodgi (accessed on 13 September 2023). | Convert ODGI genome graph file to SPARQL database. |
| GraphPeakCaller https://github.com/uio-bmi/graph_peak_caller (accessed on 13 September 2023). | A tool for calling transcription factor peaks on graph-based reference genomes using ChIP-seq data [108]. |
| PSVCP https://github.com/wjian8/psvcp_v1.01 (accessed on 13 September 2023). | It is a pan-genome analysis pipeline (PSVCP) to construct a pan-genome, call structural variants, and run population genotyping. It was used for rice pan-genome [109]. |
| ppsPCP http://cbi.hzau.edu.cn/ppsPCP/ (accessed on 13 September 2023). | It is designed specifically for constructing fully annotated plant pan-genomes. It scans presence/absence variants [110]. |
| Pan-Genome Resource | Remarks |
|---|---|
| Gramene Link: https://www.gramene.org/pansites (accessed on 13 September 2023). Species: maize, rice, grapevine, and sorghum. | Gramene hosts 128 reference plant genomes [115] and pan-genome sites for maize, rice, grapevine, and sorghum. |
| SorghumBase Link: https://www.sorghumbase.org (accessed on 13 September 2023). Species: sorghum. | SorghumBase portal hosts a sorghum pan-genome browser comprising five sorghum reference genome assemblies and genetic variant information for natural diversity panels and ethyl methanesulfonate (EMS)-induced mutant populations [118]. |
| RPAN Link: https://cgm.sjtu.edu.cn/3kricedb (accessed on 13 September 2023). In addition to RPAN, the data and analyzed outputs from 3K RGP are available at the following websites: http://snp-seek.irri.org/ (accessed on 13 September 2023). http://www.rmbreeding.cn/index.php (accessed on 13 September 2023). http://www.ricecloud.org (accessed on 13 September 2023). https://aws.amazon.com/public-data-sets/3000-rice-genome (accessed on 13 September 2023). Species: rice (O. sativa) and its wild relatives. | The Rice Pan-genome Browser (RPAN) hosts genomic variation data from 3010 diverse rice accessions [8,9,133,134]. It contains ~370 Mbp IRGSP genome and ~260 Mbp novel sequences comprising 50,995 genes (23,914 core genes). RPAN provides a phylogenetic tree browser to view the phylogeny of rice accessions and a genome browser to view gene annotation and presence-absence variations. Users can access pan-gene views and associated genetic variations. |
| RiceSuperPIRdb Link: http://www.ricesuperpir.com (accessed on 13 September 2023). Species: 251 genomes representing domesticated rice accessions and wild relatives (202 O. sativa, 28 O. rufipogan, 11 O. glaberrima, and 10 O. barthii accessions). | The RiceSuperPIRdb hosts a genome browser for the rice super pan-genome built using reference-free, high-quality whole genome alignment of 251 independent genome assemblies. Genome annotations and node-specific K-mer spectrum pan-genome graphs are available for each assembly. In addition, genetic variation graphs support linking query data and the identification of lineage-specific haplotypes for trait-associated genes [21]. |
| PanOryza Link: https://panoryza.org (accessed on 13 September 2023). Species: magic-16 rice accessions; see https://panoryza.org (accessed on 13 September 2023). | PanOryza provides consistency in the rice gene annotation across all rice varieties and the rice pan-genome browser supported by the JBrowse genome browser. |
| MaizeGDB Link: https://nam-genomes.org (accessed on 13 September 2023). Species: maize. | MaizeGDB hosts 48 maize genomes, including 26 high-quality PacBio genome assemblies of the Nested Associated Mapping (NAM) population founder lines. It allows users to connect genomes, gene models, expression, methylome, sequence variations, structural variations, transposable elements, etc., across the maize pan-genome supported by the Jbrowse browser [125]. |
| ZEAMAP Link: www.zeamap.com (accessed on 13 September 2023). Species: maize. | The ZEAMAP database incorporates multiple annotated reference genomes, data from transcriptomes, open chromatin regions, chromatin interactions, high-quality genetic variants, phenotypes, metabolomics, genetic maps, population structures, and populational DNA methylation signals from maize inbred lines [135]. |
| GreenPhylDB Link: https://www.greenphyl.org/cgi-bin/index.cgi (accessed on 13 September 2023). Species: 46 plant species and 19 pan-genomes, including rice, maize, banana, grape, and cacao. In addition, it hosts 27 reference genomes. | GreenPhylDB is part of the South Green Bioinformatics platform (https://www.southgreen.fr) [136]. It aids exploration of gene families and homologous relationships among plant genomes. |
| The Wheat Panache Web Portal Link: http://www.appliedbioinformatics.com.au/wheat_panache (accessed on 13 September 2023). Species: wheat. | This wheat pan-genome graph visualization is supported by the Panache tool. It allows users to explore structural variations across the selected wheat accessions [137]. |
| GrainGenes Link: https://wheat.pw.usda.gov/GG3/pangenome (accessed on 13 September 2023). Species: wheat, barley, rye, oat. | GrainGenes hosts molecular and phenotype data for wheat, barley, rye, oat, etc., including several genome assemblies, genome browsers, and a T. aestivum (bread wheat) pan-genome [138]. |
| Wheat Pan-genome Link: http://appliedbioinformatics.com.au/cgi-bin/gb2/gbrowse/WheatPan/ (accessed on 13 September 2023). Species: bread wheat (Triticum aestivum). | The wheat Pan-genome facilitates comparison of an improved reference for the Chinese Spring wheat genome with 18 wheat cultivars [139]. |
| SGN Links: https://solgenomics.net (accessed on 13 September 2023). Subsites: http://solomics.agis.org.cn/tomato/tool/jbrowse_nav (accessed on 13 September 2023). https://solgenomics.net/projects/tgg (accessed on 13 September 2023). https://solgenomics.net/organism/Solanum_melongena/genome (accessed on 13 September 2023). Species: tomato, potato, petunia, and eggplant. | The Solanaceae Genomics Network (SGN) database hosts pan-genome data for tomato and eggplant. International Tomato Genome Sequencing Project produced the tomato pan-genome data consisting of genome assemblies from 46 accessions (22 Solanum lycopersicum, 13 Solanum lycopersicum var. cerasiforme; and 11 Solanum pimpinellifolium) [140]. For details about the eggplant pan-genome and pan-plastome data, see Barchi et al., 2021 [141]. |
| PepperPan Link: http://www.pepperpan.org:8012/ (accessed on 13 September 2023). Species: Capsicum annuum (pepper) and its wild relatives. | The PepperPan was constructed by mapping the sequences of 383 pepper cultivars to the Zunla-1 genome as the reference [142]. The novel contig sequences (accession number GWHAAAT00000000) are available at http://bigd.big.ac.cn/gwh. |
| BRIDGEcereal Link: https://bridgecereal.scinet.usda.gov (accessed on 13 September 2023). Species: wheat, maize, barley, sorghum, and rice. | The Blastn Recovered Insertion and Deletion near Gene Explorer (BRIDGEcereal) web application supports mining publicly accessible pan-genomes of five major cereal crops, including wheat, maize, barley, sorghum, and rice [143]. It facilitates the identification of potential indels (insertion or deletions) for genes of interest. |
| PanSoy Link: https://www.soybase.org/projects/SoyBase.C2021.01.php (accessed on 13 September 2023). Species: Glycine soja (wild soybean) and Glycine max (soybean). | PanSoy is a soybean pan-genome assembly consisting of the genome sequence data from 204 phylogenetically and geographically distinct soybean accessions (GmHapMap collection). It was built using the de novo genome assembly method [144]. |
| Sunflower Genome Database Link: https://www.sunflowergenome.org (accessed on 13 September 2023). Species: Helianthus annuus (sunflower). | Sunflower pan-genome was generated using sequence from 287 cultivated lines, 17 Native American landraces, and 189 wild accessions representing 11 compatible wild species. Raw data used for pan-genome construction is available at NCBI, and SNP data is available at the Sunflower Genome Database [145]. |
| COTTONOMICS Link: http://cotton.zju.edu.cn (accessed on 13 September 2023). Species: cotton. | It provides genome-wide, gene-scale structural variations detected from 11 assembled allopolyploid cotton genomes and is linked to important agronomic traits [146]. |
| BGH Link: https://banana-genome-hub.southgreen.fr (accessed on 13 September 2023). Species: Musa Ensete, and genomics data of 15 Musaceae species. | The Banana Genome Hub (BGH), a web-based platform, supports users in exploring genes and gene families, gene expression patterns, associated SNP markers, etc. Users can also view chromosome structures, synteny, presence, absence variation, and genome ancestry mosaics [99]. |
| CPBD Links: http://citrus.hzau.edu.cn/ (accessed on 13 September 2023). Species: sweet orange (Citrus sinensis), mandarin (Citrus reticulata), pummelo (Citrus grandis), grapefruit (Citrus paradisi), and lemon (Citrus limon). | The Citrus Pan-genome to Breeding Database (CPBD) was built using 23 genomes of 17 citrus species and has genetic variation data from 167 citrus accessions mapped to two reference genomes [147]. |
| CitGVD Links: http://citgvd.cric.cn/home/index (accessed on 13 September 2023). Species: citrus accessions. | The Citrus Genome Database (CitGVD) hosts genomic data, genetic variation data, and built-in analysis tools. It contains 1493258964 non-redundant SNPs, INDELs, and 84 phenotypes from 346 citrus individuals. Users can browse/search annotated genetic variations and visualize results graphically in a genome browser or tabular outputs [148]. |
| Apple pan-genome Link: http://bioinfo.bti.cornell.edu/apple_genome (accessed on 13 September 2023). Species: apple (Malus domestica) and its wild progenitors M. sieversii and M. sylvestris. | Apple pan-genome was constructed using phased diploid genome assemblies of Malus domestica cv. Gala, M. sieversii, and M. sylvestris, and 91 sequenced genomes of additional accessions [149]. |
| BnPIR Link: http://cbi.hzau.edu.cn/bnapus (accessed on 13 September 2023). Species: Brassica oleracea, Brassica macrocarpa (cultivated and wild cabbage), Brassica napus. | The Brassica napus pan-genome information resource (BnPIR) hosts eight high-quality B. napus reference genomes generated using PacBio sequencing and re-sequencing data from 1688 rapeseed accessions. It provides a pan-gene module, pan-genome Browser, and synteny data. It also hosts multi-omics data and common bioinformatics tools [150]. |
| Cassava pan-genome Link: https://cassavabase.org/ (accessed on 13 September 2023). Species: cassava (Manihot esculenta). | Two high-quality, chromosome-scale haploid genome assemblies for African cassava cultivar TME204 (resistant to cassava mosaic diseases caused by African cassava mosaic viruses) were generated using a combination of short-read and long-read sequencing methods (Illumina PE reads, PacBio CLRs, and HiFi reads [151]. |
| Other public pan-genome data available (not yet included in crop databases or supported by Genome Browser and associated tools) | |
| Pearl millet Link: http://117.78.45.2:91/home (accessed on 13 September 2023). Species: pearl millet. | Pearl millet pan-genome was constructed using whole genome assemblies of 11 accessions generated using a combination of PacBio long-read sequences, Bionano optical mapping data, Hi-C data, and Illumina short-read sequence data [55]. |
| Sorghum pan-genome Link: The bulk data is available at http://dataverse.icrisat.org/dataset.xhtml?persistentId=doi:10.21421/D2/RIO2QM (accessed on 13 September 2023). Species: sorghum. | This pan-genome was assembled using iterative mapping of whole-genome sequence data from 176 sorghum accessions to a sorghum reference assembly v3.0.1 from Phytozome [152]. It has 209935 assembled contig sequences from 176 sorghum accessions. This data represent 35,719 genes (including 34,211 genes from reference). |
| Barley pan-genome Link: https://bitbucket.org/ipk_dg_public/barley_pangenome/src/master/ (accessed on 13 September 2023). https://galaxy-web.ipk-gatersleben.de/libraries (accessed on 13 September 2023). Species: barley cultivars and a wild relative. | This first-generation barley pan-genome consists of chromosome-scale sequence assemblies for the 20 barley varieties (including landraces, cultivars, and wild barley from global barley diversity collection) and whole-genome shotgun sequencing data from additional 300 barley accessions [11]. |
| Soybean pan-genome The genetic diversity data is available at https://figshare.com/s/689ae685ad2c368f2568 (accessed on 13 September 2023). SNPs and small indels data from the 2,898 accessions are available at (http://bigd.big.ac.cn/gvm/getProjectDetail?project=GVM000063 (accessed on 13 September 2023). Species: Glycine soja (wild soybean), Glycine max (soybean). | This graph-based pan-genome assembly was generated using de novo genome assemblies of 26 representative soybean accessions [14]. The sequencing data, assembled chromosomes, unplaced scaffolds, and annotations from this project are available at the Genome Sequence Archive and Genome Warehouse database in BIG Data Center (https://bigd.big.ac.cn/gsa/index.jsp) under Accession Number PRJCA002030. |
| Chickpea pan-genome Links: Pan-genome assembly and annotations: https://doi.org/10.6084/m9.figshare.16592819 (accessed on 13 September 2023). The variant calls: https://cegresources.icrisat.org/cicerseq (accessed on 13 September 2023). | The chickpea pan-genome consists of genome sequence data from 3366 chickpea lines (including 3171 cultivated and 195 wild accessions) [153]. Additional data, including Manhattan and QQ-plots for Genome-Wide Association Study (GWAS) analysis, is available at https://doi.org/10.6084/m9.figshare.15015309. |
| Pigeon pea Link: https://research-repository.uwa.edu.au/en/datasets/pigeon-pea-pangenome-contig-assembly-annotation-snps-pav (accessed on 13 September 2023). Species: pigeon pea (Cajanus cajan). | The pigeon pea pan-genome consists of genome sequence data from 89 pigeon pea accessions, including 70 from South Asia, 8 from sub-Saharan Africa, 7 from South East Asia, 2 from Mesoamerica, and 1 from Europe. This pan-genome was generated using the reference genome assembly (C. cajan_V1.0) and iterative mapping and assembly method [154]. |
| Sesame pan-genome Species: sesame (Sesamum indicum L.). | The sesame pan-genome was constructed by mapping genome sequence data from two landraces, S. indicum cv. Baizhima and Mishuozhima and two cultivars, Yuzhi11 and Swetha, to the S. indicum var. Zhongzhi13 reference genome [155]. |
| Cotton Variome Links: Genetic variation is available at https://www.ncbi.nlm.nih.gov/bioproject/PRJNA576032 and https://figshare.com/s/cb3c104782a1dcd90ab0 (accessed on 13 September 2023). Species: Gossypium hirsutum and Gossypium barbadense. | Cotton Variome provides genetic variation data from 1961 cotton accessions [156]. |
| Melon pan-genome Link: https://figshare.com/articles/dataset/melon_pangenome/17195072 (accessed on 13 September 2023). | Pan-genome of Cucumismelo L. consists of genome sequence data from 297 accessions [157]. |
| Cucumber pan-genome Data availability: Genome assemblies of the 11 cucumber accessions have been deposited in NCBI GenBank under the accession number PRJNA657438. | The cucumber pan-genome graph was constructed using genome sequence data from 11 representative accessions from the 115-line core collection. The genome assemblies were generated using long-read and short-read sequence data [158]. |
| Strawberry pan-genome The genome assembly and annotation files are available in the Genome Database for Rosaceae. The pan-genome browser or query support is not available. Link: https://www.rosaceae.org/species/fragaria/all (accessed on 13 September 2023). Species: cultivated and wild strawberry. | This strawberry pan-genome was generated using chromosome-scale reference genome assemblies of five diploid strawberry species (Fragaria mandschurica, Fragaria daltoniana, Fragaria pentaphylla, F. nilgerrensis, and F. viridis) and genome resequencing data of 128 accessions [159]. |
| Walnut pan-genome Link:https://db.cngb.org/search/project/CNP0001209 (accessed on 13 September 2023). Species: walnut (Juglans nigra). | A high-quality reference genome assembly of black walnut (Juglans nigra) genotype NWAFU168 was constructed using short-read and long-read sequence data (Illumina, Pacbio, and Hi-C). A Walnut pan-genome was built using this reference genome and mapping sequence data from 74 walnut accessions [56]. |
| SalviaGDB Link: https://salviagdb.org/ (accessed on 13 September 2023). Species: Salvia hispanica (Chia), S. miltiorrhiza (Danshen), S. bowleyana (nan Denshen), S. splendens (sage), and S. rosmarinus (rosemary). | The high-quality genome assembly and annotations of orphan crop Salvia hispanica (Chia) (4 genomes), and one each for the herbs used in culinary and traditional medicine. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naithani, S.; Deng, C.H.; Sahu, S.K.; Jaiswal, P. Exploring Pan-Genomes: An Overview of Resources and Tools for Unraveling Structure, Function, and Evolution of Crop Genes and Genomes. Biomolecules 2023, 13, 1403. https://doi.org/10.3390/biom13091403
Naithani S, Deng CH, Sahu SK, Jaiswal P. Exploring Pan-Genomes: An Overview of Resources and Tools for Unraveling Structure, Function, and Evolution of Crop Genes and Genomes. Biomolecules. 2023; 13(9):1403. https://doi.org/10.3390/biom13091403
Chicago/Turabian StyleNaithani, Sushma, Cecilia H. Deng, Sunil Kumar Sahu, and Pankaj Jaiswal. 2023. "Exploring Pan-Genomes: An Overview of Resources and Tools for Unraveling Structure, Function, and Evolution of Crop Genes and Genomes" Biomolecules 13, no. 9: 1403. https://doi.org/10.3390/biom13091403
APA StyleNaithani, S., Deng, C. H., Sahu, S. K., & Jaiswal, P. (2023). Exploring Pan-Genomes: An Overview of Resources and Tools for Unraveling Structure, Function, and Evolution of Crop Genes and Genomes. Biomolecules, 13(9), 1403. https://doi.org/10.3390/biom13091403