
Evaluating the Performance of Mobile-Convolutional Neural Networks for Spatial and Temporal Human Action Recognition Analysis





Abstract
:1. Introduction
- Since most of the literature referred to high-complexity networks, our article implements an extended performance evaluation on four mobile and widely used CNNs and a tiny ViT for human action recognition with three datasets. At the same time, for the sake of completeness, a non-lightweight CNN is also tested.
- With regard to models’ evaluation, the examination is based on the following points:
- −
- Nine for the spatial analysis:
- *
- The rate of the dropout layer at and .
- *
- The previous models’ training on ImageNet and ImageNet + BU101.
- *
- The final prediction according to the average/max/voting score of 15 and 3 frames.
- −
- Six for the temporal analysis:
- *
- Classification based on all 15 outputs of RNN, long short-term memory (LSTM), and gated recurrent unit (GRU).
- *
- Classification based on the last output of RNN/LSTM/GRU.
- This work extensively evaluates known resource-efficient models and techniques in activity recognition. Our comprehensive approach can assist researchers in choosing suitable architectures, highlighting lightweight networks and techniques based on performance across three diverse datasets.
2. Related Work
2.1. Human Action Recognition through 3D-CNNs
2.2. Human Action Recognition through Multiple-Stream CNNs
2.3. Human Action Recognition through Temporal Segment Networks
2.4. Human Action Recognition through CNN + RNN
2.5. Skeleton Data Approaches
3. Materials and Methods
3.1. Neural Networks and Techniques
3.1.1. Mobile-CNNs & ResNet
3.1.2. Tiny Vision Transformer
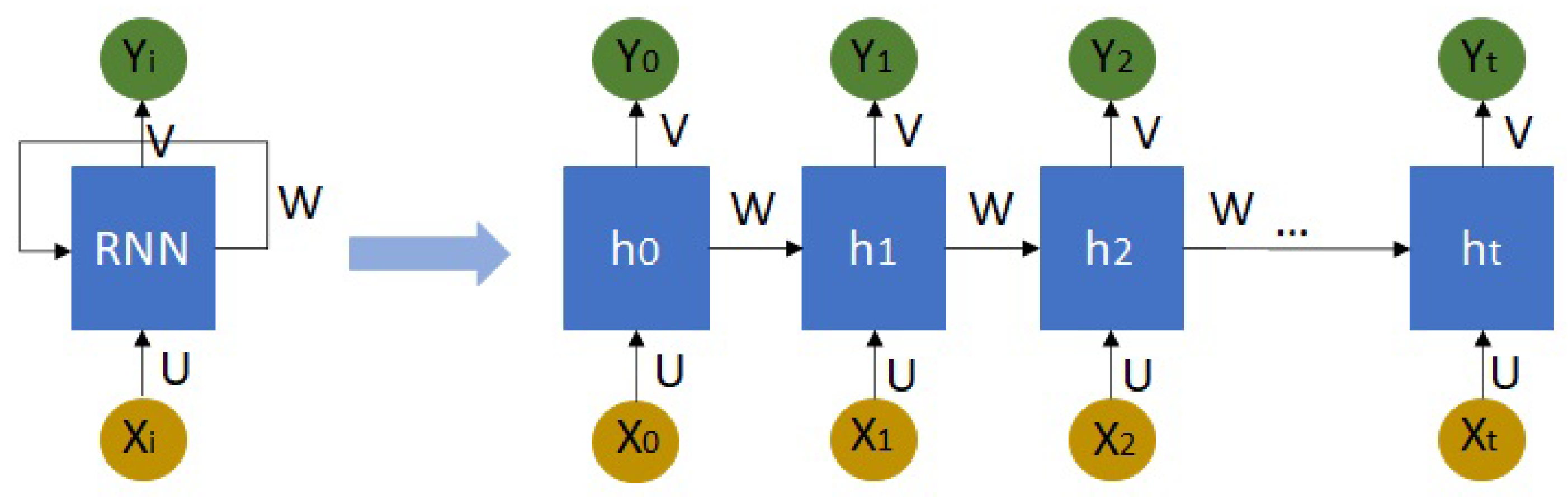
3.1.3. Recurrent Neural Networks
3.1.4. Techniques to Avoid Over-Fitting
3.2. Datasets
3.2.1. HMDB51
3.2.2. UCF101
3.2.3. NTU
3.2.4. BU101
3.3. Experimental Details
3.3.1. Previously Trained on ImageNet and BU101
3.3.2. Training
3.3.3. Testing
- by averaging the scores of all the sampled frames: ;
- by taking as a final prediction the class with the highest score:;
- by applying the voting method and taking as the final prediction the class with the most votes: .
3.4. Training and Testing of the RNNs
4. Experimental Results
5. Fall Recognition Analysis on the NTU Dataset
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Arseneau, S.; Cooperstock, J.R. Real-time image segmentation for action recognition. In Proceedings of the 1999 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM 1999), Conference Proceedings (Cat. No. 99CH36368), Victoria, BC, Canada, 22–24 August 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 86–89. [Google Scholar]
- Masoud, O.; Papanikolopoulos, N. A method for human action recognition. Image Vis. Comput. 2003, 21, 729–743. [Google Scholar] [CrossRef]
- Charalampous, K.; Gasteratos, A. A tensor-based deep learning framework. Image Vis. Comput. 2014, 32, 916–929. [Google Scholar] [CrossRef]
- Gammulle, H.; Ahmedt-Aristizabal, D.; Denman, S.; Tychsen-Smith, L.; Petersson, L.; Fookes, C. Continuous Human Action Recognition for Human-Machine Interaction: A Review. arXiv 2022, arXiv:2202.13096. [Google Scholar] [CrossRef]
- An, S.; Zhou, F.; Yang, M.; Zhu, H.; Fu, C.; Tsintotas, K.A. Real-time monocular human depth estimation and segmentation on embedded systems. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 55–62. [Google Scholar]
- Yin, J.; Han, J.; Wang, C.; Zhang, B.; Zeng, X. A skeleton-based action recognition system for medical condition detection. In Proceedings of the 2019 IEEE Biomedical Circuits and Systems Conference (BioCAS), Nara, Japan, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Cóias, A.R.; Lee, M.H.; Bernardino, A. A low-cost virtual coach for 2D video-based compensation assessment of upper extremity rehabilitation exercises. J. Neuroeng. Rehabil. 2022, 19, 1–16. [Google Scholar] [CrossRef]
- Moutsis, S.N.; Tsintotas, K.A.; Gasteratos, A. PIPTO: Precise Inertial-Based Pipeline for Threshold-Based Fall Detection Using Three-Axis Accelerometers. Sensors 2023, 23, 7951. [Google Scholar] [CrossRef]
- Moutsis, S.N.; Tsintotas, K.A.; Kansizoglou, I.; An, S.; Aloimonos, Y.; Gasteratos, A. Fall detection paradigm for embedded devices based on YOLOv8. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, Copenhagen, Denmark, 1 May–19 October 2023; pp. 1–6. [Google Scholar]
- Hoang, V.D.; Hoang, D.H.; Hieu, C.L. Action recognition based on sequential 2D-CNN for surveillance systems. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3225–3230. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Taitzoglou, A.; Kansizoglou, I.; Kaparos, P.; Bliamis, C.; Yakinthos, K.; Gasteratos, A. The MPU RX-4 project: Design, electronics, and software development of a geofence protection system for a fixed-wing vtol uav. IEEE Trans. Instrum. Meas. 2022, 72, 7000113. [Google Scholar] [CrossRef]
- Wei, D.; An, S.; Zhang, X.; Tian, J.; Tsintotas, K.A.; Gasteratos, A.; Zhu, H. Dual Regression for Efficient Hand Pose Estimation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6423–6429. [Google Scholar]
- Carvalho, M.; Avelino, J.; Bernardino, A.; Ventura, R.; Moreno, P. Human-Robot greeting: Tracking human greeting mental states and acting accordingly. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1935–1941. [Google Scholar]
- An, S.; Zhang, X.; Wei, D.; Zhu, H.; Yang, J.; Tsintotas, K.A. FastHand: Fast monocular hand pose estimation on embedded systems. J. Syst. Archit. 2022, 122, 102361. [Google Scholar] [CrossRef]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Robot navigation in large-scale social maps: An action recognition approach. Expert Syst. Appl. 2016, 66, 261–273. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Online Appearance-Based Place Recognition and Mapping: Their Role in Autonomous Navigation; Springer Nature: Berlin/Heidelberg, Germany, 2022; Volume 133. [Google Scholar]
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Tsintotas, K.A.; Giannis, P.; Bampis, L.; Gasteratos, A. Appearance-based loop closure detection with scale-restrictive visual features. In Proceedings of the International Conference on Computer Vision Systems, Thessaloniki, Greece, 23–25 September 2019; Springer: Cham, Switzerland, 2019; pp. 75–87. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 9–14. [Google Scholar]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef] [PubMed]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Do neural network weights account for classes centers? IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8815–8824. [Google Scholar] [CrossRef] [PubMed]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Deep feature space: A geometrical perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6823–6838. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Taitzoglou, A.; Kansizoglou, I.; Gasteratos, A. Safe UAV landing: A low-complexity pipeline for surface conditions recognition. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques (IST), Virtual, 24–26 August 2021; pp. 1–6. [Google Scholar]
- An, S.; Zhu, H.; Wei, D.; Tsintotas, K.A.; Gasteratos, A. Fast and incremental loop closure detection with deep features and proximity graphs. J. Field Robot. 2022, 39, 473–493. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Sevetlidis, V.; Papapetros, I.T.; Balaska, V.; Psomoulis, A.; Gasteratos, A. BK tree indexing for active vision-based loop-closure detection in autonomous navigation. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Athens, Greece, 28 June–1 July 2022; pp. 532–537. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Probabilistic appearance-based place recognition through bag of tracked words. IEEE Robot. Autom. Lett. 2019, 4, 1737–1744. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Tracking-DOSeqSLAM: A dynamic sequence-based visual place recognition paradigm. IET Comput. Vis. 2021, 15, 258–273. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Visual Place Recognition for Simultaneous Localization and Mapping. In Autonomous Vehicles Volume 2: Smart Vehicles; Scrivener Publishing LLC: Beverly, MA, USA, 2022; pp. 47–79. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Modest-vocabulary loop-closure detection with incremental bag of tracked words. Robot. Auton. Syst. 2021, 141, 103782. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19929–19953. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A Framework for Active Vision-Based Robot Planning using Spiking Neural Networks. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Vouliagmeni, Greece, 28 June–1 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 867–871. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10734–10742. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Huo, Y.; Xu, X.; Lu, Y.; Niu, Y.; Lu, Z.; Wen, J.R. Mobile video action recognition. arXiv 2019, arXiv:1908.10155. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Lan, Z.; Zhu, Y.; Hauptmann, A.G.; Newsam, S. Deep local video feature for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–7. [Google Scholar]
- Chenarlogh, V.A.; Jond, H.B.; Platoš, J. A Robust Deep Model for Human Action Recognition in Restricted Video Sequences. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 541–544. [Google Scholar]
- Zhang, Y.; Guo, Q.; Du, Z.; Wu, A. Human Action Recognition for Dynamic Scenes of Emergency Rescue Based on Spatial-Temporal Fusion Network. Electronics 2023, 12, 538. [Google Scholar] [CrossRef]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Attention transfer from web images for video recognition. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1–9. [Google Scholar]
- Zong, M.; Wang, R.; Ma, Y.; Ji, W. Spatial and temporal saliency based four-stream network with multi-task learning for action recognition. Appl. Soft Comput. 2023, 132, 109884. [Google Scholar] [CrossRef]
- Zhu, J.; Zhu, Z.; Zou, W. End-to-end video-level representation learning for action recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 645–650. [Google Scholar]
- Ahmed, W.; Naeem, U.; Yousaf, M.H.; Velastin, S.A. Lightweight CNN and GRU Network for Real-Time Action Recognition. In Proceedings of the 2022 12th International Conference on Pattern Recognition Systems (ICPRS), Saint-Etienne, France, 7–10 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Zhou, A.; Ma, Y.; Ji, W.; Zong, M.; Yang, P.; Wu, M.; Liu, M. Multi-head attention-based two-stream EfficientNet for action recognition. Multimed. Syst. 2023, 29, 487–498. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring Plain Vision Transformer Backbones for Object Detection. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 280–296. [Google Scholar]
- Li, Z.; Li, Y.; Li, Q.; Wang, P.; Guo, D.; Lu, L.; Jin, D.; Zhang, Y.; Hong, Q. LViT: Language meets Vision Transformer in Medical Image Segmentation. IEEE Trans. Med. Imaging 2023, 1. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, R. Relative-position embedding based spatially and temporally decoupled Transformer for action recognition. Pattern Recognit. 2024, 145, 109905. [Google Scholar] [CrossRef]
- Ulhaq, A.; Akhtar, N.; Pogrebna, G.; Mian, A. Vision Transformers for Action Recognition: A Survey. arXiv 2022, arXiv:cs.CV/2209.05700. [Google Scholar]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14063–14073. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Amjoud, A.B.; Amrouch, M. Object Detection Using Deep Learning, CNNs and Vision Transformers: A Review. IEEE Access 2023, 11, 35479–35516. [Google Scholar] [CrossRef]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:abs/2103.14030. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:abs/2110.02178. [Google Scholar]
- Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y. EVA-02: A Visual Representation for Neon Genesis. arXiv 2023, arXiv:2303.11331. [Google Scholar]
- Nousi, P.; Tzelepi, M.; Passalis, N.; Tefas, A. Chapter 7—Lightweight deep learning. In Deep Learning for Robot Perception and Cognition; Iosifidis, A., Tefas, A., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 131–164. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2556–2563. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sevilla-Lara, L.; Liao, Y.; Güney, F.; Jampani, V.; Geiger, A.; Black, M.J. On the integration of optical flow and action recognition. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, Germany, 9–12 October 2018; Springer: Cham, Switzerland, 2018; pp. 281–297. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1933–1941. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Khong, V.M.; Tran, T.H. Improving human action recognition with two-stream 3D convolutional neural network. In Proceedings of the 2018 1st International Conference on Multimedia Analysis and Pattern Recognition (MAPR), Ho Chi Minh City, Vietnam, 5–6 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. arXiv 2019, arXiv:cs.CV/1812.03982. [Google Scholar]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3200–3225. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-time action recognition with deeply transferred motion vector cnns. IEEE Trans. Image Process. 2018, 27, 2326–2339. [Google Scholar] [CrossRef]
- Kim, J.H.; Won, C.S. Action recognition in videos using pre-trained 2D convolutional neural networks. IEEE Access 2020, 8, 60179–60188. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Shift Graph Convolutional Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Peng, W.; Shi, J.; Varanka, T.; Zhao, G. Rethinking the ST-GCNs for 3D skeleton-based human action recognition. Neurocomputing 2021, 454, 45–53. [Google Scholar] [CrossRef]
- Tu, Z.; Zhang, J.; Li, H.; Chen, Y.; Yuan, J. Joint-Bone Fusion Graph Convolutional Network for Semi-Supervised Skeleton Action Recognition. IEEE Trans. Multimed. 2023, 25, 1819–1831. [Google Scholar] [CrossRef]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Convolutional Deep Belief Networks on CIFAR-10. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2010. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Sun, Q.; Fang, Y.; Wu, L.; Wang, X.; Cao, Y. EVA-CLIP: Improved Training Techniques for CLIP at Scale. arXiv 2023, arXiv:2303.15389. [Google Scholar]
- Wightman, R. PyTorch Image Models. 2019. Available online: https://github.com/huggingface/pytorch-image-models (accessed on 6 November 2023). [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2016, arXiv:abs/1612.08083. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Wen, B.; Liu, Y. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv 2021, arXiv:abs/2104.09864. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:abs/1710.05941. [Google Scholar]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of bitcoin using machine learning. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Cambridge, UK, 21–23 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 339–343. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6645–6649. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Zargar, S.A. Introduction to Sequence Learning Models: RNN, LSTM, GRU; Department of Mechanical and Aerospace Engineering, North Carolina State University: Raleigh, NC, USA, 2021. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies; IEEE Press: Piscataway, NJ, USA, 2001. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ma, S.; Bargal, S.A.; Zhang, J.; Sigal, L.; Sclaroff, S. Do less and achieve more: Training cnns for action recognition utilizing action images from the web. Pattern Recognit. 2017, 68, 334–345. [Google Scholar] [CrossRef]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef]
- Yao, B.; Jiang, X.; Khosla, A.; Lin, A.L.; Guibas, L.; Fei-Fei, L. Human action recognition by learning bases of action attributes and parts. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1331–1338. [Google Scholar]
- Li, J.; Xu, Z.; Yongkang, W.; Zhao, Q.; Kankanhalli, M. GradMix: Multi-source transfer across domains and tasks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 3019–3027. [Google Scholar]
- Gao, G.; Liu, Z.; Zhang, G.; Li, J.; Qin, A. DANet: Semi-supervised differentiated auxiliaries guided network for video action recognition. Neural Netw. 2023, 158, 121–131. [Google Scholar] [CrossRef] [PubMed]
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231N 2015, 7, 3. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Maldonado-Bascón, S.; Iglesias-Iglesias, C.; Martín-Martín, P.; Lafuente-Arroyo, S. Fallen People Detection Capabilities Using Assistive Robot. Electronics 2019, 8, 915. [Google Scholar] [CrossRef]
- Menacho, C.; Ordoñez, J. Fall detection based on CNN models implemented on a mobile robot. In Proceedings of the IEEE International Conference on Ubiquitous Robots, Kyoto, Japan, 22–26 June 2020; pp. 284–289. [Google Scholar]
- Raza, A.; Yousaf, M.H.; Velastin, S.A. Human Fall Detection using YOLO: A Real-Time and AI-on-the-Edge Perspective. In Proceedings of the 12th International Conference on Pattern Recognition Systems (ICPRS), Saint-Etienne, France, 7–10 June 2022; pp. 1–6. [Google Scholar]
- Lafuente-Arroyo, S.; Martín-Martín, P.; Iglesias-Iglesias, C.; Maldonado-Bascón, S.; Acevedo-Rodrígue, F.J. RGB camera-based fallen person detection system embedded on a mobile platform. Expert Syst. Appl. 2022, 197, 116715. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2740–2755. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Lu, H.; Jin, J.; Hu, K. Human Action Recognition Based on Improved Two-Stream Convolution Network. Appl. Sci. 2022, 12, 5784. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | FLOPs (G) | Parameters (M) |
|---|---|---|
| ShuffleNet-v2 [49] | 0.14 | 2.3 |
| EfficientNet-b0 [52] | 0.39 | 5.3 |
| MobileNet-v3 [53] | 0.2 | 5.4 |
| GhostNet [54] | 0.14 | 5.2 |
| EVA-02-Ti [82] | 4.8 | 5.7 |
| ResNet-50 [43] | 4.19 | 25.6 |
| CNN | Train Accuracy | Test Accuracy | Epoch |
|---|---|---|---|
| ShuffleNet-v2 [49] | 92.38% | 81.08% | 23 |
| EfficientNet-b0 [52] | 98.38% | 90.04% | 8 |
| MobileNet-v3 [53] | 97.59% | 87.50% | 8 |
| GhostNet [54] | 96.91% | 86.44% | 14 |
| EVA-02-Ti [82] | 97.14% | 90.58% | 5 |
| ResNet-50 [43] | 97.97% | 90.40% | 5 |
| Image Augmentation Techniques | Probability | Transform |
|---|---|---|
| Step 1 | 0.25 | Random Image Crop (100 × 100) |
| 0.25 | Center Crop (100 × 100) | |
| 0.25 | Center Crop (224 × 224) | |
| 0.25 | No Transform | |
| Step 2 | 0.165 | Random Horizontal Flip |
| 0.165 | Random Vertical Flip | |
| 0.165 | Random Rotation 30 | |
| 0.165 | Random Affine 45 | |
| 0.165 | No Transform | |
| Step 3 | 0.2 | Color Jitter (brightness = 0.4, contrast = 0.4, hue = 0.2) |
| 0.2 | Gaussian Blur (kernel size = 3, sigma = (0.1, 0.2)) | |
| 0.2 | Random Solarize (threshold = 1) with 90% probability | |
| 0.4 | No Transform | |
| Step 4 | 1 | Image Resized (224 × 224) |
| Network | The Initial Last/Classifier Layer(s) of Networks Trained on ImageNet | Fine-Tuned Classifiers for the HMDB51 (Output = 51) and UCF101 (Output = 101), with on Dropout Layer | Fine-Tuned Classifiers for the HMDB51 (Output = 51) and UCF101 (Output = 101) with on Dropout Layer | Fine-Tuned Classifiers for the NTU (Output = 6), without a Dropout Layer |
|---|---|---|---|---|
| ShuffleNet-v2 | No Dropout Layer, FC Layer (input = 1024, output = 1000) | Dropout Layer (), FC Layer (input = 1024, output = 51/101) | Dropout Layer (), FC Layer (input = 1024, output = 51/101) | - |
| EfficientNet-b0 | Dropout Layer (), FC Layer (input = 1280, output = 1000) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | Dropout Layer (), FC Layer (input = 1280, output = 6) |
| MobileNet-v3 | Dropout Layer (), FC Layer (input = 1280, output = 1000) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | - |
| GhostNet | No Dropout Layer, FC Layer (input = 1280, output = 1000) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | Dropout Layer (), FC Layer (input = 1280, output = 51/101) | - |
| EVA-02-Ti | Dropout Layer (), FC Layer (input = 192, output = 1000) | Dropout Layer (), FC Layer (input = 192, output = 51/101) | Dropout Layer (), FC Layer (input = 192, output = 51/101) | Dropout Layer (), FC Layer (input = 192, output = 6) |
| ResNet-50 | No Dropout Layer, FC Layer (input = 2048, output = 1000) | Dropout Layer (), FC Layer (input = 2048, output = 51/101) | Dropout Layer (), FC Layer (input = 2048, output = 51/101) | No Dropout Layer, FC Layer (input = 2048, output = 6) |
| Network | Optimizer | Learning Rate | Batch Size | Capacity in GPU |
|---|---|---|---|---|
| ShuffleNet-v22 [49] | Adam | 0.0001 | 256 | ≈8615 Mb/10,240 Mb |
| EfficientNet-b0 [52] | SGD | 0.001 | 64 | ≈8309 Mb/10,240 Mb |
| MobileNet-v3 [53] | SGD | 0.0005 | 128 | ≈8889 Mb/10,240 Mb |
| GhostNet [54] | SGD | 0.001 | 128 | ≈7829 Mb/10,240 Mb |
| EVA-02-Ti [82] | Adam | 0.00001 | 64 | ≈9299 Mb/10,240 Mb |
| ResNet-50 [43] | SGD | 0.0005 | 64 | ≈8893 Mb/10,240 Mb |
| HMDB51 Split-1 | Dropout Rate = 0.8 | Dropout Rate = 0.5 | |||
|---|---|---|---|---|---|
| Network | Test Method | ImageNet | ImageNet + BU101 | ImageNet | ImageNet + BU101 |
| ShuffleNet-V2 | test_15_avg | 44.30% | 44.92% | 43.59% | 45.47% |
| test_15_max | 42.03% | 44.06% | 41.48% | 43.20% | |
| test_15_vot | 43.59% | 44.92% | 43.20% | 44.84% | |
| test_3_avg | 43.36% | 45.00% | 43.44% | 44.22% | |
| test_3_max | 42.58% | 43.52% | 42.66% | 43.75% | |
| test_3_vot | 42.19% | 43.13% | 42.19% | 42.81% | |
| EfficientNet-b0 | test_15_avg | 51.49% | 55.50% | 45.11% | 54.55% |
| test_15_max | 49.39% | 51.97% | 48.10% | 51.43% | |
| test_15_vot | 51.02% | 54.48% | 49.80% | 53.53% | |
| test_3_avg | 51.02% | 54.01% | 50.27% | 53.46% | |
| test_3_max | 49.93% | 52.51% | 48.91% | 52.17% | |
| test_3_vot | 49.39% | 51.97% | 48.64% | 51.70% | |
| MobileNet-v3 | test_15_avg | 50.57% | 50.28% | 49.57% | 49.22% |
| test_15_max | 47.80% | 48.58% | 46.45% | 47.66% | |
| test_15_vot | 49.08% | 50.28% | 48.22% | 48.22% | |
| test_3_avg | 49.15% | 49.57% | 48.37% | 48.22% | |
| test_3_max | 47.94% | 48.30% | 46.59% | 47.87% | |
| test_3_vot | 47.80% | 47.87% | 47.02% | 46.95% | |
| GhostNet | test_15_avg | 47.09% | 50.21% | 49.57% | 50.14% |
| test_15_max | 45.67% | 46.54% | 46.16% | 47.02% | |
| test_15_vot | 46.38% | 49.08% | 48.44% | 49.29% | |
| test_3_avg | 46.52% | 50.07% | 48.93% | 49.43% | |
| test_3_max | 45.53% | 48.65% | 47.02% | 48.01% | |
| test_3_vot | 45.60% | 48.44% | 47.16% | 47.59% | |
| EVA-02-Ti | test_15_avg | 37.98% | 48.44% | 50.07% | 49.73% |
| test_15_max | 37.09% | 47.86% | 47.76% | 47.89% | |
| test_15_vot | 37.50% | 47.28% | 50.07% | 48.71% | |
| test_3_avg | 37.43% | 47.83% | 50.34% | 48.51% | |
| test_3_max | 38.38% | 46.74% | 48.91% | 48.23% | |
| test_3_vot | 36.82% | 46.33% | 45.51% | 47.28% | |
| ResNet | test_15_avg | 52.58% | 55.03% | 52.31% | 53.19% |
| test_15_max | 48.85% | 50.82% | 47.96% | 51.15% | |
| test_15_vot | 52.72% | 52.92% | 52.04% | 52.51% | |
| test_3_avg | 51.77% | 53.74% | 51.63% | 52.92% | |
| test_3_max | 50.27% | 52.45% | 50.27% | 51.63% | |
| test_3_vot | 50.48% | 51.56% | 50.41% | 50.82% | |
| UCF101 Split-1 | Dropout Rate = 0.8 | Dropout Rate = 0.5 | |||
|---|---|---|---|---|---|
| Network | Test Method | ImageNet | ImageNet + BU101 | ImageNet | ImageNet + BU101 |
| ShuffleNet-V2 | test_15_avg | 69.20% | 73.38% | 68.95% | 73.30% |
| test_15_max | 66.52% | 72.41% | 65.85% | 69.64% | |
| test_15_vot | 69.20% | 75.17% | 67.86% | 73.19% | |
| test_3_avg | 68.83% | 75.17% | 68.14% | 71.90% | |
| test_3_max | 67.75% | 73.24% | 67.13% | 70.93% | |
| test_3_vot | 67.49% | 73.38% | 66.69% | 70.73% | |
| EfficientNet-bo | test_15_avg | 84.11% | 86.10% | 84.08% | 85.65% |
| test_15_max | 82.28% | 83.85% | 82.02% | 83.45% | |
| test_15_vot | 83.66% | 85.33% | 83.47% | 84.98% | |
| test_3_avg | 83.45% | 85.54% | 83.40% | 84.83% | |
| test_3_max | 82.71% | 84.14% | 82.44% | 83.85% | |
| test_3_vot | 82.31% | 83.85% | 82.02% | 83.58% | |
| MobileNet-v3 | test_15_avg | 81.87% | 82.97% | 80.66% | 79.93% |
| test_15_max | 79.74% | 80.95% | 78.45% | 78.21% | |
| test_15_vot | 81.98% | 82.68% | 80.44% | 79.80% | |
| test_3_avg | 81.49% | 82.62% | 80.44% | 79.69% | |
| test_3_max | 80.50% | 81.79% | 79.07% | 79.39% | |
| test_3_vot | 80.33% | 81.44% | 79.07% | 78.66% | |
| GhostNet | test_15_avg | 81.57% | 83.16% | 82.14% | 80.06% |
| test_15_max | 79.28% | 80.25% | 79.58% | 78.23% | |
| test_15_vot | 80.87% | 82.60% | 81.84% | 79.98% | |
| test_3_avg | 81.14% | 82.41% | 81.36% | 79.88% | |
| test_3_max | 79.18% | 81.30% | 79.74% | 78.69% | |
| test_3_vot | 79.42% | 80.98% | 79.93% | 78.15% | |
| EVA-02-Ti | test_15_avg | 79.45% | 83.40% | 83.73% | 86.04% |
| test_15_max | 72.21% | 81.78% | 82.02% | 84.40% | |
| test_15_vot | 74.31% | 83.02% | 83.18% | 85.73% | |
| test_3_avg | 74.02% | 82.71% | 83.02% | 85.06% | |
| test_3_max | 73.28% | 82.10% | 82.52% | 84.56% | |
| test_3_vot | 72.67% | 81.54% | 81.97% | 84.30% | |
| ResNet | test_15_avg | 85.09% | 87.39% | 85.20% | 87.45% |
| test_15_max | 82.65% | 85.09% | 82.84% | 84.96% | |
| test_15_vot | 84.83% | 86.55% | 84.77% | 86.71% | |
| test_3_avg | 84.80% | 86.68% | 84.56% | 86.71% | |
| test_3_max | 83.87% | 85.46% | 83.21% | 85.75% | |
| test_3_vot | 83.24% | 85.12% | 83.02% | 85.33% | |
| NTU—6 Classes | Test Method | |||||
|---|---|---|---|---|---|---|
| Network | test_15_avg | test_15_max | test_15_vot | test_3_avg | test_3_max | test_3_vot |
| EfficientNet-bo | 85.59% | 80.38% | 80.84% | 84.20% | 81.65% | 79.45% |
| EVA-02-Ti | 86.27% | 82.00% | 79.86% | 84.84% | 82.29% | 78.64% |
| ResNet-50 | 85.46% | 82.06% | 79.34% | 84.72% | 82.46% | 79.45% |
| Network for Feature Extraction | |||||
|---|---|---|---|---|---|
| EfficientNet-b0 | EVA-02-Ti | ResNet-50 | |||
| HMDB51 Split-1 | RNN | Final output | 51.71% | 47.96% | 48.82% |
| All outputs | 55.54% | 53.20% | 54.45% | ||
| LSTM | Final output | 52.50% | 50.78% | 52.42% | |
| All outputs | 55.85% | 52.96% | 54.21% | ||
| GRU | Final output | 52.18% | 49.06% | 51.09% | |
| All outputs | 55.54% | 50.94% | 54.84% | ||
| Average score of the spatial analysis | 55.50% | 50.07% | 55.03% | ||
| UCF101 Split-1 | RNN | Final output | 82.61% | 82.92% | 82.95% |
| All outputs | 85.65% | 85.79% | 86.71% | ||
| LSTM | Final output | 84.73% | 84.79% | 86.69% | |
| All outputs | 85.26% | 85.79% | 86.36% | ||
| GRU | Final output | 83.87% | 84.57% | 84.98% | |
| All outputs | 85.82% | 85.46% | 87.22% | ||
| Average score of the spatial analysis | 86.10% | 86.04% | 87.45% | ||
| NTU—6 classes | RNN | Final output | 95.70% | 97.20% | 96.48% |
| All outputs | 96.39% | 97.63% | 97.07% | ||
| LSTM | Final output | 95.24% | 96.28% | 94.92% | |
| All outputs | 95.83% | 96.48% | 95.96% | ||
| GRU | Final output | 94.20% | 95.18% | 95.89% | |
| All outputs | 96.28% | 95.31% | 95.37% | ||
| Average score of the spatial analysis | 85.59% | 86.27% | 85.46% | ||
| NTU 6 Classes | NTU as 2 Classes (Fall or Daily Action) | ||||
|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | ||
| EfficientNet-bo | Frames—3 | 83.50% | 95.28% | 97.53% | 87.66% |
| Frames—15 | 85.36% | 95.65% | 97.86% | 89.18% | |
| RNN—15 | 96.39% | 96.01% | 99.33% | 96.36% | |
| EVA-02-Ti | Frames—3 | 85.19% | 94.56% | 98.20% | 90.62% |
| Frames—15 | 86.31% | 92.75% | 98.00% | 89.51% | |
| RNN—15 | 97.63% | 96.73% | 99.53% | 97.44% | |
| ResNet-50 | Frames—3 | 84.06% | 92.75% | 98.13% | 82.52% |
| Frames—15 | 85.69% | 94.20% | 98.60% | 92.52% | |
| RNN—15 | 97.07% | 96.37% | 99.06% | 95.00% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moutsis, S.N.; Tsintotas, K.A.; Kansizoglou, I.; Gasteratos, A. Evaluating the Performance of Mobile-Convolutional Neural Networks for Spatial and Temporal Human Action Recognition Analysis. Robotics 2023, 12, 167. https://doi.org/10.3390/robotics12060167
Moutsis SN, Tsintotas KA, Kansizoglou I, Gasteratos A. Evaluating the Performance of Mobile-Convolutional Neural Networks for Spatial and Temporal Human Action Recognition Analysis. Robotics. 2023; 12(6):167. https://doi.org/10.3390/robotics12060167
Chicago/Turabian StyleMoutsis, Stavros N., Konstantinos A. Tsintotas, Ioannis Kansizoglou, and Antonios Gasteratos. 2023. "Evaluating the Performance of Mobile-Convolutional Neural Networks for Spatial and Temporal Human Action Recognition Analysis" Robotics 12, no. 6: 167. https://doi.org/10.3390/robotics12060167
APA StyleMoutsis, S. N., Tsintotas, K. A., Kansizoglou, I., & Gasteratos, A. (2023). Evaluating the Performance of Mobile-Convolutional Neural Networks for Spatial and Temporal Human Action Recognition Analysis. Robotics, 12(6), 167. https://doi.org/10.3390/robotics12060167