

Safe Reinforcement Learning for Arm Manipulation with Constrained Markov Decision Process




Abstract
:1. Introduction
2. Background
2.1. Markov Decision Process
2.2. Soft Actor-Critic
2.3. Constrained Markov Decision Process
2.4. Lagrange Multiplier
2.5. Scalarized Expected Return
3. Related Work
3.1. Risk-Based Safety in Reinforcement Learning
3.2. Uncertainty-Based Safety in Reinforcement Learning
3.3. Constrained MDP-Based Safety in Reinforcement Learning
3.4. Reinforcement Learning Obstacle Avoidance with Arm Manipulators
4. Methodology
4.1. State Features
4.2. Reward Function
4.3. Danger Region and Cost Function
4.4. Soft-Actor Critic Training
4.5. Lambda Training
5. Results and Discussion
5.1. Neural Network Details
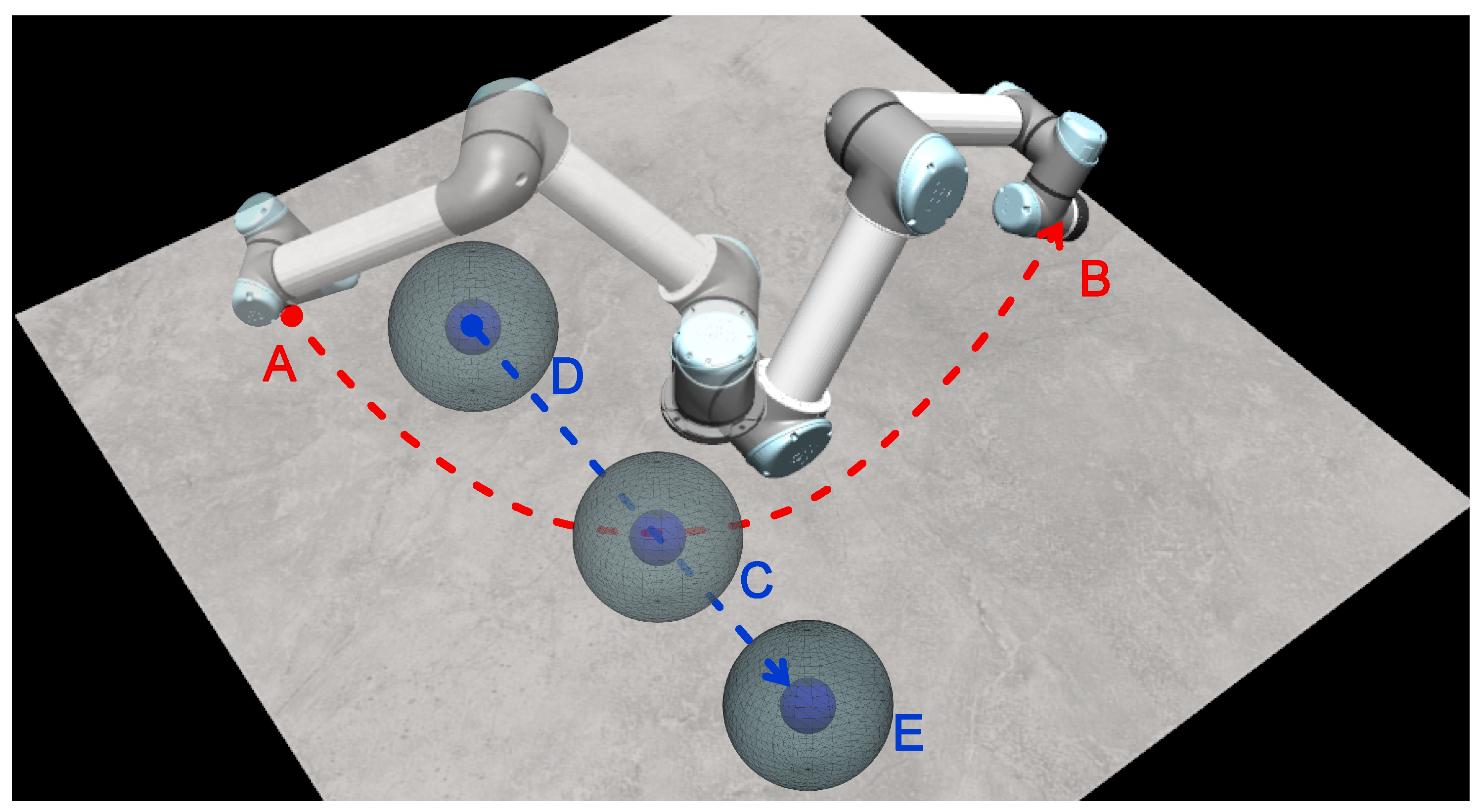
5.2. Experimental Setup
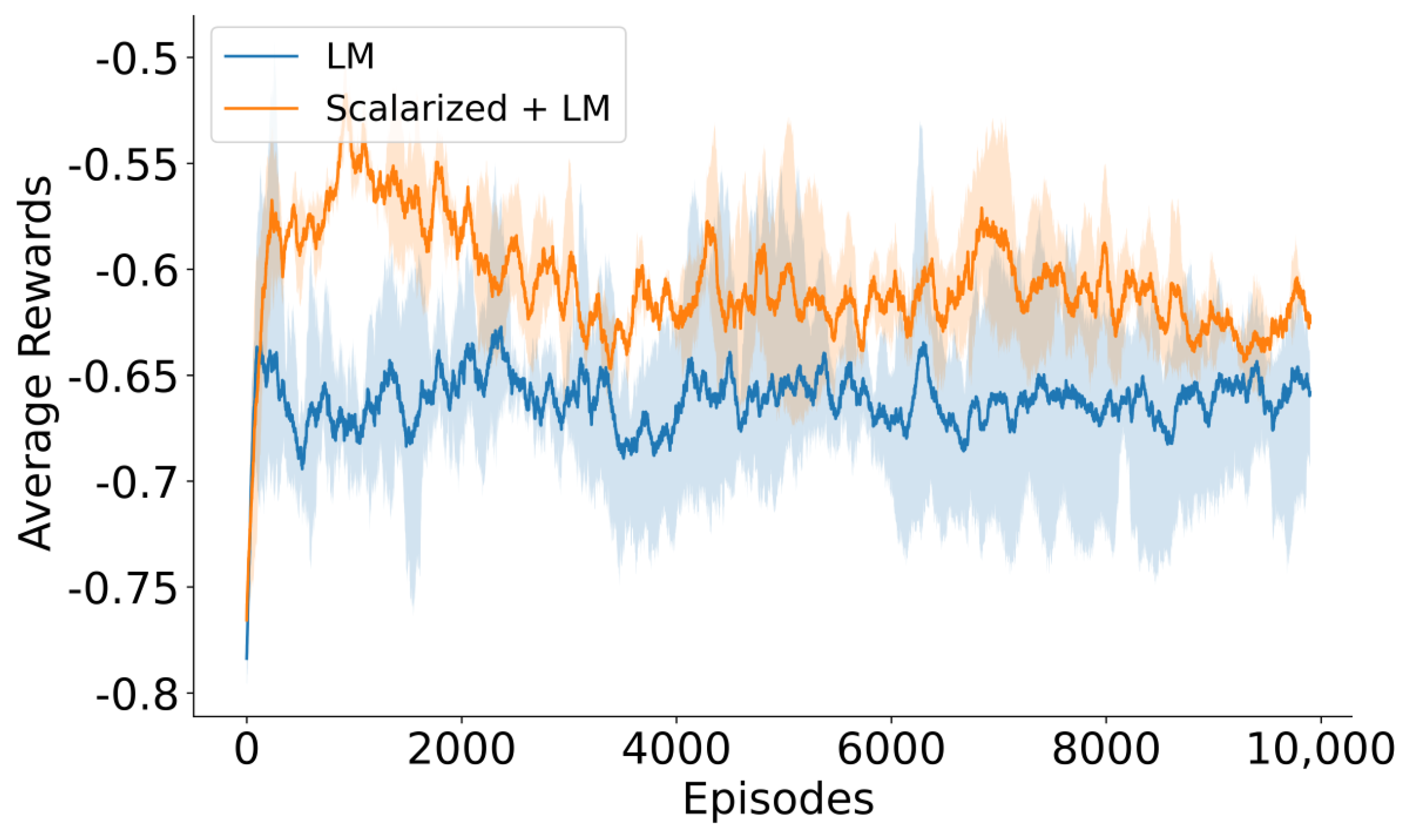
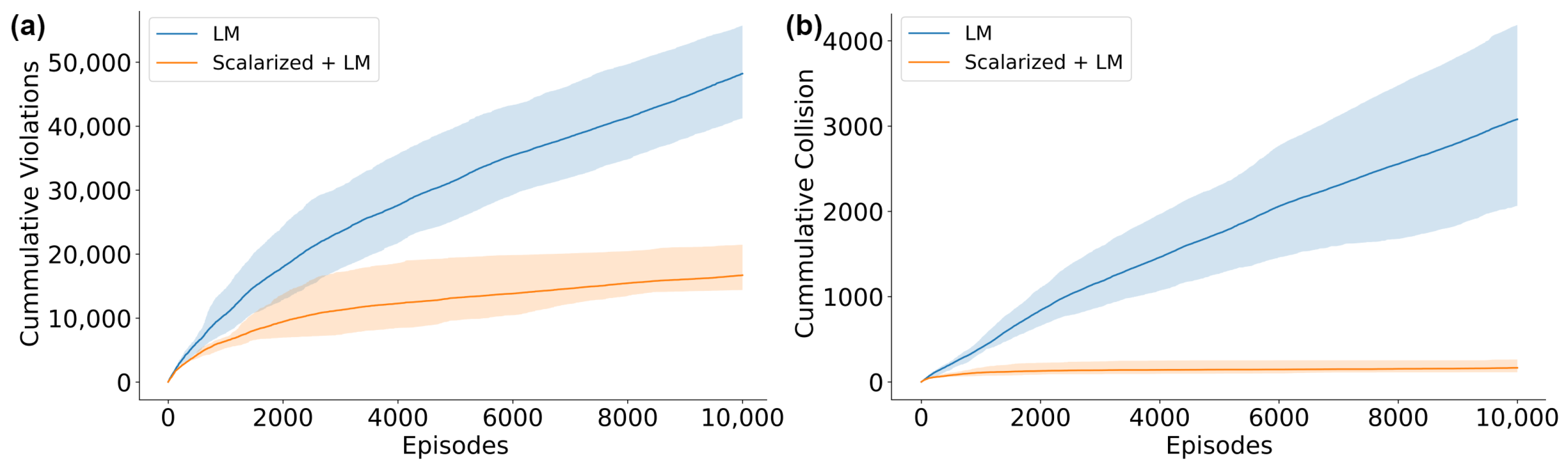
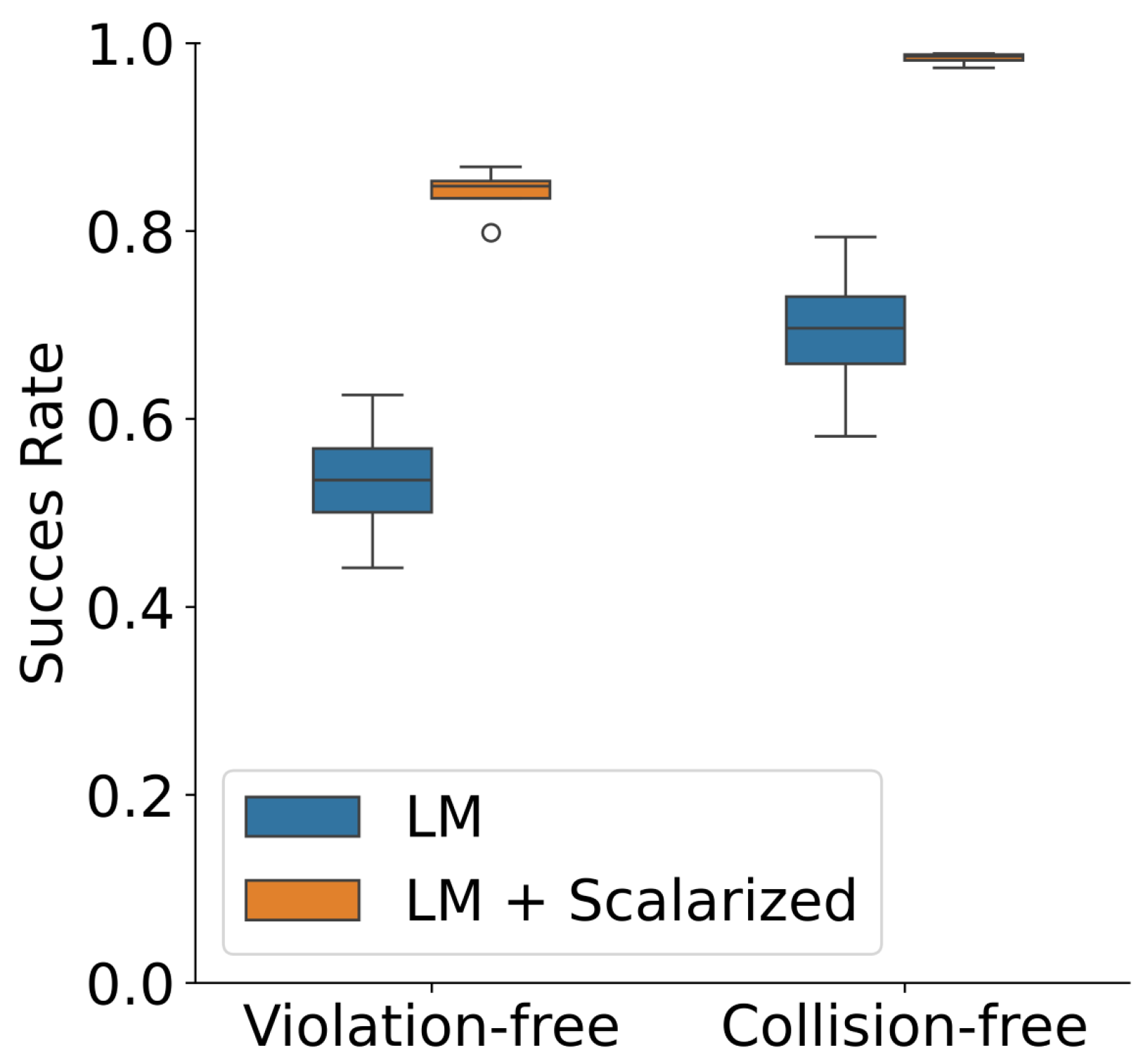
5.3. Performance Comparison
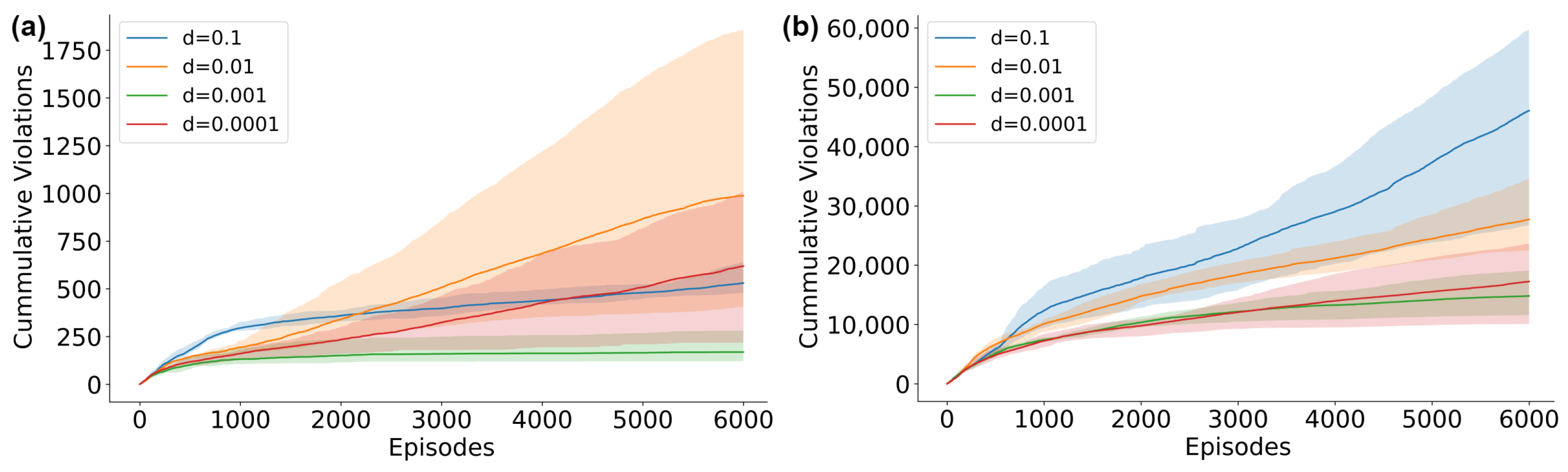
5.4. Cost Limit Parameter Analysis
5.5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CMDP | Constrained Markov decision process |
| EE | End-effector |
| LM | Lagrange multiplier |
| MDP | Markov decision process |
| RL | Reinforcement learning |
| SAC | Soft actor–critic |
| SER | Scalarized expected return |
References
- Colgate, E.; Bicchi, A.; Peshkin, M.A.; Colgate, J.E. Safety for physical human-robot interaction. In Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1335–1348. [Google Scholar]
- Beetz, M.; Chatila, R.; Hertzberg, J.; Pecora, F. AI Reasoning Methods for Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 329–356. [Google Scholar]
- Ingrand, F.; Ghallab, M. Deliberation for autonomous robots: A survey. Artif. Intell. 2017, 247, 10–44, Special Issue on AI and Robotics. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI’16, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Washington, DC, USA, 2016; pp. 2094–2100. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Gosavi, A. Reinforcement learning: A tutorial survey and recent advances. INFORMS J. Comput. 2009, 21, 178–192. [Google Scholar] [CrossRef]
- Moldovan, T.M.; Abbeel, P. Safe Exploration in Markov Decision Processes. In Proceedings of the 29th International Coference on International Conference on Machine Learning, ICML’12, Madison, WI, USA, 26 June–1 July 2012; pp. 1451–1458. [Google Scholar]
- Hans, A.; Schneegaß, D.; Schäfer, A.M.; Udluft, S. Safe exploration for reinforcement learning. In Proceedings of the ESANN, Bruges, Belgium, 23–25 April 2008; pp. 143–148. [Google Scholar]
- Altman, E. Constrained Markov Decision Processes; CRC Press: Boca Raton, FL, USA, 1999; Volume 7. [Google Scholar]
- Garcıa, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning (ICML-18), Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Bertsekas, D.P. Constrained Optimization and Lagrange Multiplier Methods; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Hayes, C.F.; Reymond, M.; Roijers, D.M.; Howley, E.; Mannion, P. Monte Carlo tree search algorithms for risk-aware and multi-objective reinforcement learning. Auton. Agents -Multi-Agent Syst. 2023, 37, 26. [Google Scholar] [CrossRef]
- Jaimungal, S.; Pesenti, S.M.; Wang, Y.S.; Tatsat, H. Robust Risk-Aware Reinforcement Learning. SIAM J. Financ. Math. 2022, 13, 213–226. [Google Scholar] [CrossRef]
- Geibel, P.; Wysotzki, F. Risk-Sensitive Reinforcement Learning Applied to Control under Constraints. J. Artif. Int. Res. 2005, 24, 81–108. [Google Scholar] [CrossRef]
- Mihatsch, O.; Neuneier, R. Risk-sensitive reinforcement learning. Mach. Learn. 2002, 49, 267–290. [Google Scholar] [CrossRef]
- Bossens, D.M.; Bishop, N. Explicit Explore, Exploit, or Escape (E 4): Near-optimal safety-constrained reinforcement learning in polynomial time. Mach. Learn. 2022, 112, 1–42. [Google Scholar] [CrossRef]
- Wolff, E.M.; Topcu, U.; Murray, R.M. Robust control of uncertain Markov Decision Processes with temporal logic specifications. In Proceedings of the 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 10–13 December 2012; pp. 3372–3379. [Google Scholar] [CrossRef]
- Russel, R.H.; Benosman, M.; Van Baar, J. Robust constrained-MDPs: Soft-constrained robust policy optimization under model uncertainty. arXiv 2020, arXiv:2010.04870. [Google Scholar]
- Chen, B.; Liu, Z.; Zhu, J.; Xu, M.; Ding, W.; Li, L.; Zhao, D. Context-aware safe reinforcement learning for non-stationary environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 10689–10695. [Google Scholar]
- Wachi, A.; Sui, Y. Safe reinforcement learning in constrained Markov decision processes. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 9797–9806. [Google Scholar]
- Borkar, V.; Jain, R. Risk-constrained Markov decision processes. IEEE Trans. Autom. Control. 2014, 59, 2574–2579. [Google Scholar] [CrossRef]
- Li, Y.; Hao, X.; She, Y.; Li, S.; Yu, M. Constrained motion planning of free-float dual-arm space manipulator via deep reinforcement learning. Aerosp. Sci. Technol. 2021, 109, 106446. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, S.; Zheng, X.; Ma, W.; Xie, X.; Liu, L. Reinforcement learning with prior policy guidance for motion planning of dual-arm free-floating space robot. Aerosp. Sci. Technol. 2023, 136, 108098. [Google Scholar] [CrossRef]
- Li, Z.; Ma, H.; Ding, Y.; Wang, C.; Jin, Y. Motion Planning of Six-DOF Arm Robot Based on Improved DDPG Algorithm. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 3954–3959. [Google Scholar] [CrossRef]
- Tang, W.; Cheng, C.; Ai, H.; Chen, L. Dual-Arm Robot Trajectory Planning Based on Deep Reinforcement Learning under Complex Environment. Micromachines 2022, 13, 564. [Google Scholar] [CrossRef] [PubMed]
- Sangiovanni, B.; Rendiniello, A.; Incremona, G.P.; Ferrara, A.; Piastra, M. Deep reinforcement learning for collision avoidance of robotic manipulators. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; IEEE: Piscateville, NJ, USA, 2018; pp. 2063–2068. [Google Scholar]
- Prianto, E.; Kim, M.; Park, J.H.; Bae, J.H.; Kim, J.S. Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef] [PubMed]
- Zeng, R.; Liu, M.; Zhang, J.; Li, X.; Zhou, Q.; Jiang, Y. Manipulator Control Method Based on Deep Reinforcement Learning. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; IEEE: Piscateville, NJ, USA, 2020; pp. 415–420. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Q. Robotic Arm Motion Planning with Autonomous Obstacle Avoidance Based on Deep Reinforcement Learning. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Heifei, China, 25–27 July 2022; pp. 3692–3697. [Google Scholar] [CrossRef]
- Kamali, K.; Bonev, I.A.; Desrosiers, C. Real-time Motion Planning for Robotic Teleoperation Using Dynamic-goal Deep Reinforcement Learning. In Proceedings of the 2020 17th Conference on Computer and Robot Vision (CRV), Ottawa, ON, Canada, 13–15 May 2020; pp. 182–189. [Google Scholar] [CrossRef]
- Avaei, A.; van der Spaa, L.; Peternel, L.; Kober, J. An Incremental Inverse Reinforcement Learning Approach for Motion Planning with Separated Path and Velocity Preferences. Robotics 2023, 12, 61. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Algarve, 7–12 October 2012; pp. 5026–5033. [Google Scholar] [CrossRef]
- Ray, A.; Achiam, J.; Amodei, D. Benchmarking safe exploration in deep reinforcement learning. arXiv 2019, arXiv:1910.01708. [Google Scholar]
- Razaviyayn, M.; Huang, T.; Lu, S.; Nouiehed, M.; Sanjabi, M.; Hong, M. Nonconvex min-max optimization: Applications, challenges, and recent theoretical advances. IEEE Signal Process. Mag. 2020, 37, 55–66. [Google Scholar] [CrossRef]
- Singh, S.; Cohn, D. How to dynamically merge Markov decision processes. Adv. Neural Inf. Process. Syst. 1997, 10, 1057–1063. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value |
|---|---|---|
| State dimension | - | 48 |
| Action dimension | - | 6 |
| Discount factor | 0.99999 | |
| Initial temperature parameter | 0.05 | |
| Cost limit | d | 0.001 |
| Initial lambda | −10 | |
| Lambda learning rate | - | 0.001 |
| Softplus Beta | 0.5 | |
| Network learning rate | - | 0.0001 |
| Soft-update parameter | - | 0.005 |
| Object (radius) | O | 0.2 |
| Sphere (radius) | H | 0.35 |
| Replay buffer | D | 300,000 |
| Batch size | - | 256 |
| Action range in radians | - | ±0.0698132 |
| Alpha () | 0.05 | 0.1 | 0.2 | 0.3 | 0.4 |
|---|---|---|---|---|---|
| Violations | 14,812.75 | 15,188.5 | 21,314.0 | 15,845.25 | 24,864.25 |
| Collision | 168.75 | 214.75 | 681.5 | 256.0 | 590.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adjei, P.; Tasfi, N.; Gomez-Rosero, S.; Capretz, M.A.M. Safe Reinforcement Learning for Arm Manipulation with Constrained Markov Decision Process. Robotics 2024, 13, 63. https://doi.org/10.3390/robotics13040063
Adjei P, Tasfi N, Gomez-Rosero S, Capretz MAM. Safe Reinforcement Learning for Arm Manipulation with Constrained Markov Decision Process. Robotics. 2024; 13(4):63. https://doi.org/10.3390/robotics13040063
Chicago/Turabian StyleAdjei, Patrick, Norman Tasfi, Santiago Gomez-Rosero, and Miriam A. M. Capretz. 2024. "Safe Reinforcement Learning for Arm Manipulation with Constrained Markov Decision Process" Robotics 13, no. 4: 63. https://doi.org/10.3390/robotics13040063
APA StyleAdjei, P., Tasfi, N., Gomez-Rosero, S., & Capretz, M. A. M. (2024). Safe Reinforcement Learning for Arm Manipulation with Constrained Markov Decision Process. Robotics, 13(4), 63. https://doi.org/10.3390/robotics13040063