1. Introduction
In recent years, the adoption of remote sensing across a wide spectrum of applications has increased rapidly. With an increase in the number of satellites launched over the last few years, there has been a deluge of Earth Observation (EO) data. However, the rate of data exploration largely lags behind the rate at which the EO data are being generated by these remote-sensing platforms [
1]. The remote-sensing imagery captured by these platforms has great potential in understanding numerous natural, as well as manmade, phenomena. This remains largely unexplored, primarily due to the sheer volume and velocity of the data. This calls for a need for innovative and efficient ways to rapidly explore and exploit EO data. The research problem of empowering machines to interpret and understand a scene as a human has been gaining lots of attention in the remote-sensing community.
The area of remote sensing scene understanding for information mining and retrieval, scene interpretation including Land Use Land Cover (LULC) classification and change detection among numerous other applications has evolved significantly over the years. Most of the research on this paradigm has been focused on the problem of information mining and retrieval from remote sensing scenes. Earlier works [
2,
3] focused on the problem of scene identification and retrieval by comparing Synthetic Aperture Radar (SAR) data of different scenes by using a model-based scene inversion approach with Bayesian inference. These works propose and discuss mathematical models for extraction of low-level physical characteristics of the 3D scenes from the 2D images. Reference [
4] introduced information fusion for scene understanding by proposing the mapping of the extracted primitive features to higher-level semantics representing urban scene elements.
There has been significant research in the area of Image Information Mining for Remote-Sensing Imagery that has led to the development of numerous Information Image Mining (IIM) frameworks in the last couple of decades. The GeoBrowse system [
5] is one of the earliest IIM systems for remote-sensing imagery. Developed on the principles of distributed computing, the system used an object-oriented relational database for data storage and information retrieval. The Knowledge-driven Information Mining (KIM) system [
6,
7] was built over References [
2,
3], and Reference [
4] proposed to use Bayesian networks to link user-defined semantic labels to a global content-index generated in an unsupervised manner. The Geospatial Information Retrieval and Indexing System (GeoIRIS) [
8] identified specialized descriptor features to extract and map particular objects from remote sensing scenes, with support for querying by spatial configuration of objects for retrieval of remote-sensing-scene tiles. The PicSOM system [
9] applied self-organized maps to optimize retrieval of images based on the content queried by the user. It also proposed supervised and unsupervised change-detection methodologies in addition to detecting manmade structures from satellite imagery. The Intelligent Interactive Image Knowledge Retrieval (I3KR) [
1] system proposed the use of domain-dependent ontologies for enhanced knowledge discovery from the Earth Observation data. It used a combination of supervised and unsupervised techniques to generate models for object classes, followed by the assignment of semantic concepts to the classes in the ontology, achieved automatically by description-logic-based inference mechanisms. The Spatial Image Information Mining Framework [
10] inspired by the I3KR [
1] focused on the modeling of directional and topological relationships between the regions in an image and the development of Spatial Semantic Graph. The SIIM also proposed a Resource Description Framework (RDF)-based model for representing an image, associating regions with classes and their relationships, both directional and topological, amongst themselves, along with the structural metadata, such as geographical coordinates and time of acquisition.
Each of the image information mining systems for remote sensing imagery mentioned above have strived to address the problem of effective retrieval of content-based information from huge remote sensing archives. Some of the recent semantics enabled IIM systems have also addressed the issue of the “semantic gap” between the low-level primitive features and high-level semantic abstractions in a remote sensing scene. However, the research problem of comprehensive understanding and interpretation of remote sensing scenes from a spatio-contextual perspective for man–machine interactions has still not been completely addressed.
Recently, a few research studies have focused on remote sensing scene captioning to interpret scenes into natural language descriptions. Reference [
11] proposed the use of a deep multi-modal neural network consisting of a convolutional neural network to extract the image features followed by a recurrent neural network trained over a dataset of image–caption pairs to generate the single sentence text descriptions. The framework proposed in Reference [
12] consists of two stages for the task of remote-sensing-image captioning: (1) Multi-Level Image Understanding, using Fully Convolutional Networks (FCNs), and (2) language generation, using a template-based approach. The first stage was designed to generate triplets from the images in the form of (ELM, ATR and RLT) representing the ground elements, their attributes and their relationships with other elements. These triples serve as input to the templating mechanism to generate appropriate natural language text descriptions. The Remote Sensing Image Captioning Dataset (RSICD) developed in Reference [
13] consists of manually generated image–sentence pairs for 10921 generic remote sensing scenes of 224 × 224 pixels size. The developed dataset was evaluated over two methods of image captioning: (1) multi-modal approach [
11] and (2) an attention-based approach proposed in Reference [
13] that uses both deterministic and stochastic manner of attention. The Collective Semantic Metric Learning (CSML) framework [
14] proposed the collective sentence representation corresponding to a single remote sensing image representation in the semantic space for a multi-sentence captioning task. With the objective of ensuring focus on the regions of interest, the Visual Aligning Attention model (VAA) [
15] proposed a novel visual aligning loss function designed to maximize the feature similarity between the extracted image feature vectors and the word embedding vectors. The Retrieval Topic Recurrent Memory Network [
16] proposed the use of topic words retrieved from the topic repository generated from the ground truth sentences at the training stage. In the testing stage, the retrieved topic words embedded into the network in the form of topic memory cells further control and guide the sentence generation process. Reference [
17] addressed the problems of (1) focusing on different spatial features at different scales and (2) semantic relationships between the objects in the remote sensing image. It proposed the use of a multi-level attention module to account for spatial features at different scales and attribute graph-based graph convolutional network to account for the semantic relationship between the objects in the remote sensing image.
The remote sensing image captioning frameworks mentioned above have addressed the problem of captioning remote sensing scenes to natural language sentences. A few recent studies in this area have focused on the semantic visual relationships between the objects in the scenes. However, the research problem of generating detailed description paragraphs consisting of multiple natural language sentences, comprehensively describing a remote sensing scene, taking into account the spatio-contextual relationships between the objects, remains largely unexplored. Moreover, the generated sentences in the abovementioned frameworks are not grounded to specific regions of the scene, and thus lack explainability. The term “grounded” in the scene description refers to the explicit mapping words or phrases in it to regions in the scene that it describes. This reinforces explainability and reliability of the scene description in its task of describing the scene in natural language.
Comprehensive, explainable and contextual interpretation of a remote sensing scene is of utmost importance especially in a disaster situation such as floods. During a flood occurrence, it is crucial to understand the flood inundation and receding patterns in context to the spatial configurations of the land-use/land-cover in the flooded regions. Moreover, the contextual semantics of the flood scene are also influenced by the temporal component. As time progresses, a flooded region may either shrink in size or grow, affecting the semantics of other regions that it spatially interacts with. Therefore, there is a dire need to develop approaches that can translate the real-world ground situation during or post disaster in a way that can be easily assimilated both by humans and machines, which can lead to a response that is well orchestrated and timely.
This paper addresses the problem of remote sensing scene understanding focusing specifically on comprehensive and explainable interpretation of scenes from a spatio-contextual standpoint for effective man–machine interactions. In that regard, the novel Semantics-driven Remote Sensing Scene Understanding (Sem-RSSU) framework was developed to generate grounded explainable natural language scene descriptions from remote sensing scenes.
Figure 1 depicts comprehensive grounded spatio-contextual scene description as rendered by our proposed Semantics-driven Remote Sensing Scene Understanding (Sem-RSSU) framework for a remote sensing scene of urban floods. To the best of our knowledge, this research is the first of its kind to explore comprehensive grounded scene description rendering for remote sensing scenes using a semantics-driven approach.
The broad objective of this research is to transform a remote sensing scene to a spatio-contextual knowledge graph and further into explainable grounded natural language scene descriptions for enhanced situational awareness and effective man–machine interaction.
Major Research Contributions
Our major research contributions in this work are two-fold:
We formalize the representation and modeling of spatio-contextual knowledge in remote sensing scenes in the form of Remote Sensing Scene Knowledge Graphs (RSS-KGs), through the development of Remote Sensing Scene Ontology (RSSO)—a core ontology for an inclusive remote-sensing-scene data product. We develop a contextual domain knowledge encompassing Flood Scene Ontology (FSO), to represent concepts that proliferate during a flood scenario.
We propose and implement the end-to-end Semantics-enabled Remote Sensing Scene Understanding (Sem-RSSU) framework as a holistic pipeline for generating comprehensive grounded spatio-contextual scene descriptions, to enhance the user-level situational awareness, as well as machine-level explainability of the scenes.
In that regard, we propose (1) Ontology-driven Spatio-Contextual Triple Aggregation and (2) Scene Description Content Planning and Realization algorithms, to enable rendering of grounded explainable natural language scene descriptions from remote sensing scenes. We report and discuss our findings from the extensive evaluations of the framework.
The paper is structured as follows:
Section 2 describes the proposed Semantics-driven Remote Sensing Scene Understanding (Sem-RSSU) framework. It presents in detail the various layers and components of the framework.
Section 3 discusses the experimental setup, results with the evaluation strategies used to verify the efficacy of the framework. In
Section 4 and
Section 5, we discuss and summarize the framework and conclude with future directions of this research.
2. Framework for Semantics-Driven Remote Sensing Scene Understanding
The core focus of the Semantics enabled Remote Sensing Scene Understanding (Sem-RSSU) framework is geared towards enabling enhanced situational awareness from remote sensing scenes. It intends to enable the users/decision makers to obtain increased understanding of the situation and help make better choices to respond to it prudently. It is well understood that the greater the amount of targeted information the better are the chances to positively react to the situation. However, the information needs to be highly contextual, easily understandable and pertinent to that particular situation. Otherwise, there is a danger of information overload leading to undesired consequences. Therefore, it is essential to develop approaches that can translate the real ground situation from remote sensing scenes in a way that can be easily understood and queried upon by man and machines alike, thereby leading to an appropriate and timely response in sensitive situations such as disasters.
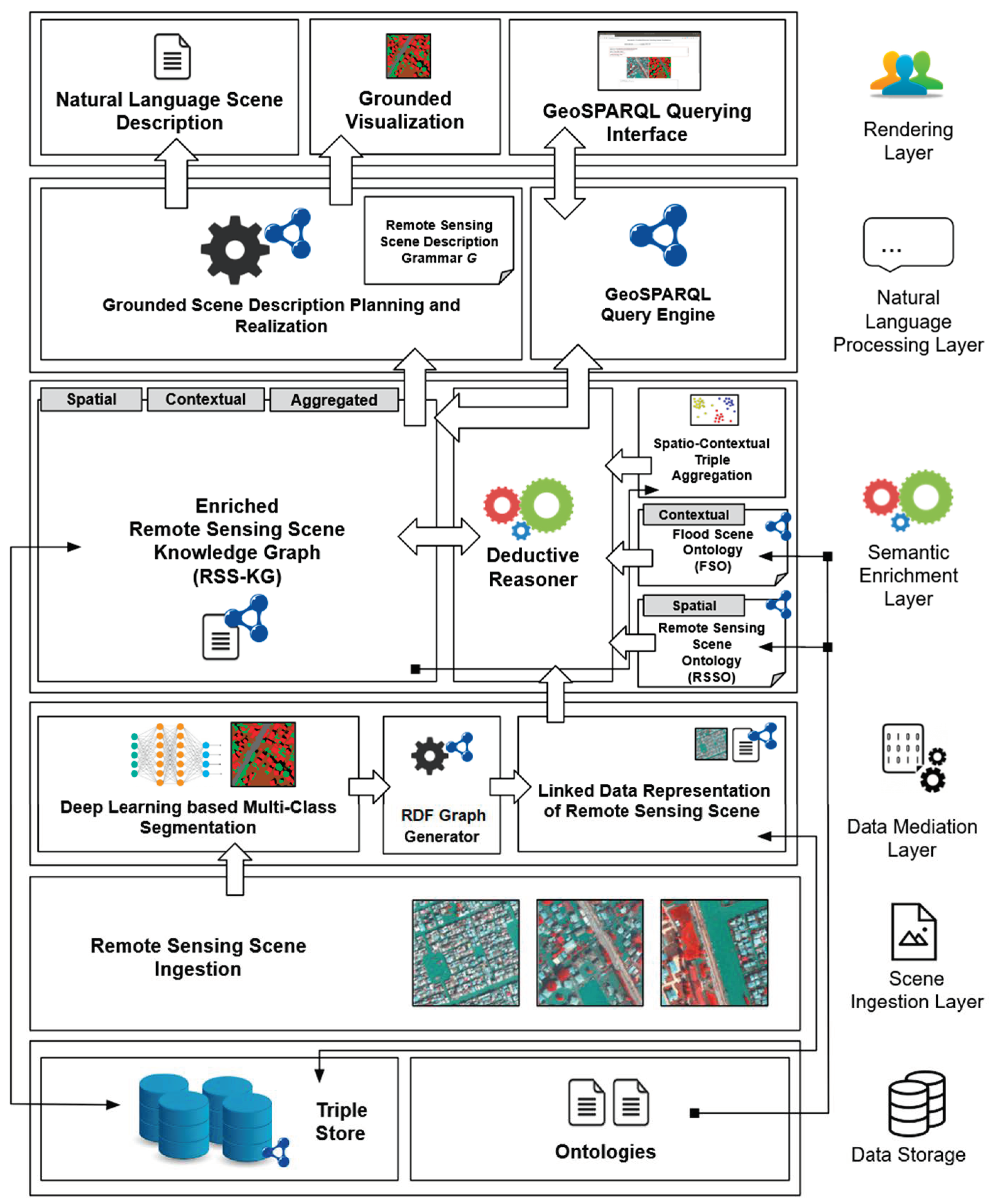
Figure 2 depicts the system architecture of the proposed framework. The framework was logically divided into 6 layers: Data Storage layer, Scene Ingestion layer, Data Mediation layer, Semantic Enrichment layer, Natural Processing layer and the Rendering layer.
The Data Storage layer consists of a triple-store to store, retrieve and update the Remote Sensing Scene Knowledge Graphs (RSS-KGs) generated from the scenes. It also stores the ontologies—the Remote Sensing Scene Ontology (RSSO) and the contextual Flood Scene Ontology (FSO)—on a disk-based storage, for deductive reasoning. The Scene Ingestion layer deals with ingesting Remote Sensing Scenes of interest into the framework for comprehensive, grounded and explainable scene description rendering.
2.1. Data Mediation
The Data Mediation layer consists of (1) the deep-learning-based multi-class segmentation component that segments the ingested scene into land-use/land-cover regions and (2) the RDF graph generator component that transforms the segmented land-use/land-cover regions in the scene to a graph representation of the scene conforming to the proposed Remote Sensing Scene Ontology.
2.1.1. Multi-Class Segmentation
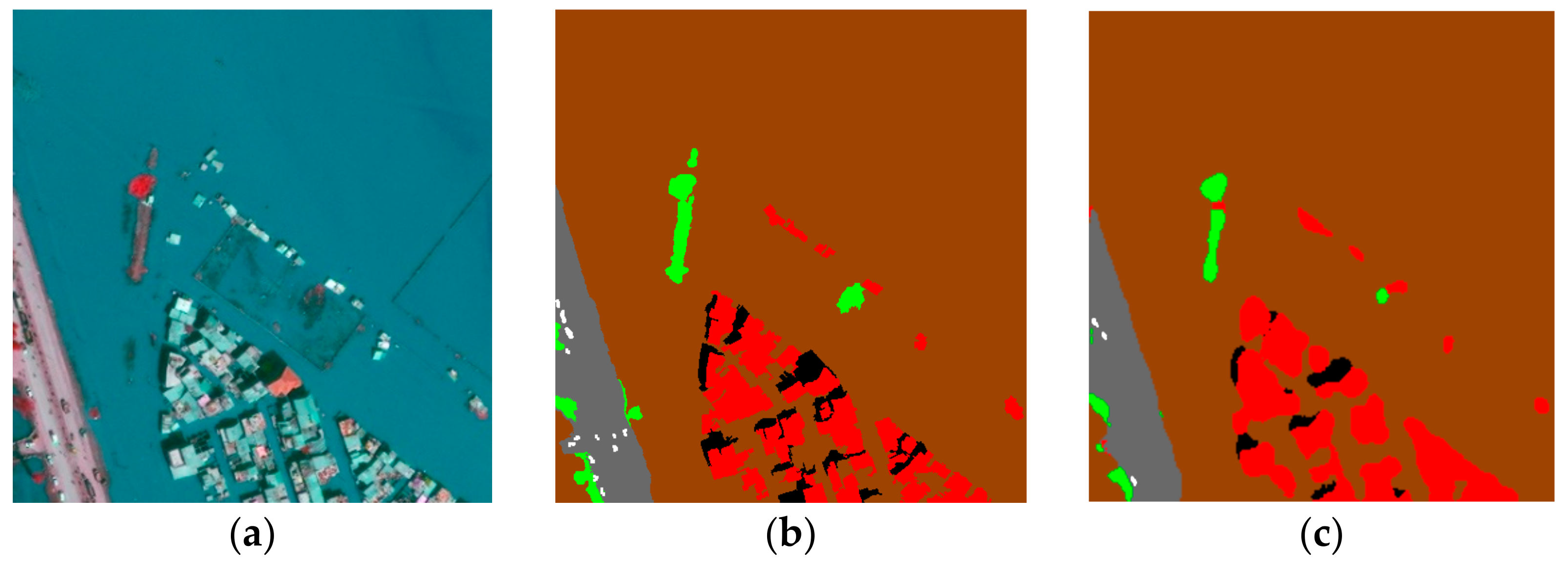
The remote sensing scene consists of multiple land-use/land-cover regions spatially interacting with one another. To infer higher level abstractions from the scene, it is essential to identify the primitive features and predict their land-use/land-cover. Each pixel in the scene is assigned a label of a land-cover, using a deep-neural-network approach. Some of the popular state-of-the-art deep-neural-network architectures based on the encoder–decoder architecture were experimented on for the urban flood dataset for this research.
The Fully Convolutional Network (FCN) [
18] architecture popularized the use of end-to-end convolutional neural networks for semantic segmentation. The FCN first introduced the use of skip connections to propagate spatial information to the decoder layers and improve the upsampling output. U-Net architecture [
19] built over the FCN, was first proposed for biomedical image segmentation and has proven to adapt well across a large spectrum of domains. It proposed a symmetric U-shaped architecture for encoding and decoding with multiple upsampling layers and using the concatenation operation instead of addition operation. The Pyramid Scene Parsing Network (PSPNet) [
20] uses dilated convolution to increase the receptive field in addition to the use of the pyramid pooling module in the encoder to capture and aggregate the global context. The SegNet [
21] architecture advocated storing and transmitting the max-pooling indices to the decoder to improve the quality of upsampling. The ResNet [
22] architecture, a Convolutional Neural Network architecture, proposed the use of residual-blocks identity-skip connections to tackle the vanishing gradient problem encountered while training deep neural networks. The ResNet and VGG-16 [
23] were used as backbone architectures for the FCN, U-Net, SegNet and PSP neural network architectures for experimenting over the urban flood dataset consisting of high-resolution remote sensing scenes captured during an urban flood event. Each of the architectures was implemented and evaluated over this dataset.
Both ResNet and VGG-16 as backbone architectures have shown promising results [
24] for multi-class segmentation (also known as semantic Segmentation) for remote sensing scenes. The architectures for multi-class segmentation considered in Sem-RSSU were selected by considering their effectiveness and relevance for the task of segmentation and to limit the scope of the study. It must be noted that Sem-RSSU was structured to be modular and is thus amenable for use with any state-of-the-art deep neural approaches for multi-class segmentation.
2.1.2. RDF Graph Generator
The RDF Graph Generator component translates the land-use/land-cover regions from raster to a Resource Description Framework based graph representation. The semantic segmentation results (also known as classification maps) are vectorized into Well-Known Text (WKT) geometry representation based on the color labels assigned to the pixels. A predefined threshold for minimum pixels in a region to constitute an object in a knowledge graph, in this component, filters out stray and noisy pixel labels. This was implemented by using the shapely (
https://pypi.org/project/Shapely) and rasterio (
https://pypi.org/project/rasterio) libraries in Python. This process of vectorization is followed by encoding and rendering the WKT geometries in a string conforming to an RDF representation. The RDF graph representation of the remote sensing scene consists of triples corresponding to land-use/land-cover regions in the scene with their geometries and other spatial information stored in accordance with the GeoRDF (
https://www.w3.org/wiki/GeoRDF) standard by the W3C and the proposed Remote Sensing Scene Ontology (RSSO).
2.2. Semantic Enrichment Layer
Description Logic (DL) forms the fundamental building block of formalizing knowledge representation. It also forms the basis of the Web Ontology Language (OWL) used to construct ontologies. The Sem-RSSU framework proposes the formalization of remote sensing scene knowledge through the development of the Remote Sensing Scene Ontology (RSSO) and the contextual Flood Scene Ontology (FSO). The DL-based axioms discussed in this section were encoded in the proposed ontologies, to facilitate inferencing of implicit knowledge from the remote sensing scenes.
The Semantic Enrichment layer was structured in a multi-tier manner, to facilitate hierarchical semantic enrichment of the RDF graph representation of the remote sensing scenes to generate enriched Remote Sensing Scene Knowledge Graphs (RSS-KGs).
The Remote Sensing Scene Ontology (RSSO) enriches the RDF data by inferring spatial–topological and directional relationships between the land-use/land-cover regions, thereby facilitating generation of Remote Sensing Scene Knowledge Graphs (RSS-KGs). The KGs are further enriched with contextual concepts and relationships with the Flood Scene Ontology, a domain knowledge encompassing ontology that formalizes the concepts and relationships proliferating during the flood scenario. The enriched KGs are further aggregated contextually from a remote sensing scene description standpoint with the Spatio-Contextual Triple Aggregation algorithm.
An ontology-based deductive reasoner facilitates the enrichment of knowledge graphs at every tier.
Figure 3 represents the multi-tier architecture of the Semantic Reasoning layer. The multi-tier approach of semantic enrichment in the form of spatial, contextual and aggregated knowledge enables (1) modularity and (2) extensibility, thus rendering the architecture amenable for scaling and integration with other data sources (e.g., GeoNames, UK Ordnance Survey, etc.) for other remote-sensing applications.
The figure also depicts an example of the hierarchical knowledge graph enrichment process as it propagates upwards to the Natural Language Processing layer. In the Data Mediation layer, the instances of vehicles and a road are represented using the Resource Description Framework (RDF) as a graph representation of the remote sensing scene. The graph representation in RDF form is propagated to the Spatial Knowledge Enrichment layer where the RSSO enriches and transforms it into a knowledge graph by inferring spatial–topological and directional relationships between the instances. The “geo:ntpp” Non-Tangential Proper Part topological relationship from RCC8 is inferred at this stage. The knowledge graph is further propagated upward for Contextual Enrichment using the FSO. In this layer, the contextual relationship “on” is inferred and the “road” instance is further specialized to a “unaffected road” class instance. Furthermore, the knowledge graph is aggregated using Spatio-Contextual Triple Aggregation for scene description rendering where the numerous vehicle instances “on” the road are aggregated and a “traffic congestion” class instance is inferred.
2.2.1. Semantic Data Modeling in Sem-RSSU
The Sem-RSSU framework formalizes the representation of remote sensing scenes in the form of knowledge graphs through the development of ontologies. It utilizes the developed ontologies for knowledge enrichment in a modular and hierarchical form to be amenable for integration and extension for other remote sensing applications.
Ontology Development for Spatial Semantic Enrichment
The Remote Sensing Scene Ontology (RSSO) was developed to translate the RDF data representation of remote sensing scenes to knowledge graphs by inferring spatial–topological and directional concepts and relationships between the identified regions. The ontology formalizes the semantics of a generic remote sensing scene captured by a remote sensing platform. To gauge the reliability of a remote-sensing data product and ascertain its origin, the metadata bundled with the data product plays a crucial role. In that regard, the RSSO defines classes, Object and Data Properties to model the metadata of a remote sensing scene to establish comprehensive data lineage. The Data Properties “hasGroundSamplingDistance”, “hasProjection”, enumerateBands”, “hasResamplingMethod”, “hasSpectralBands”, “hasAcquisitionDateTime”, etc., along with the specifics of the remote-sensing platform stored in Object Properties collectively model the metadata of the scene.
The Anderson Land-Use/Land-Cover Classification system was used as a reference to model the LULC classes in the RSSO.
Figure 4a depicts the Classes Hierarchy, Data Properties and the Object Properties in the RSSO. The object properties were used to model and capture the topological and directional relationships between instances of different land-use/land-cover regions.
Figure 4b depicts the visualization of an instance of class “scene” and “Scene256” captured by “GeoEye-01” which is an instance of class “satellite” that is a “RemoteSensingPlatform”. A “scene” class instance has a relation with “region” class instances through the object property “hasRegions”. Thus, a scene has multiple regions within it, with each of the regions having a LULC associated with it through the “hasLULC” Data Property.
Figure 5 depicts a snippet of the Scene Knowledge Graph represented in the Resource Description Framework (RDF) form for a region “R40” in a remote sensing scene.
Ontology Development for Contextual Semantic Enrichment
The Flood Scene Ontology (FSO) introduced in Reference [
28] was further improved and enriched as a part of this study. The FSO extends the RSSO and was conceptualized to consist of comprehensive domain knowledge of the flood disaster from the perspective of remote sensing scene understanding. The ontology was developed for contextual semantic enrichment of Scene Knowledge Graphs by defining context-specific concepts and relationships proliferating during the flood scenario.
The FSO builds over the RSSO and formalizes specialized classes that are intended to be inferred from remote sensing scenes of urban floods. The following are the formal expressions, along with their natural language definitions, for some of the specialized classes that were encoded as SWRL rules in the ontology. Moreover, some of their corresponding GeoSPARQL queries that can be used as an alternate implementation instead of SWRL rules have been depicted.
Flooded Residential Building: A
region is termed as “
Flooded Residential Building” as per FSO, if it is a
region that has
LULC as “
Residential Building” and it is
externally connected with at least one
region that has
LULC as “
Flood Water”.
Accessible Residential Building: A
region is termed as “
Accessible Residential Building” as per FSO, if it is a
region that has
LULC as “
Flooded Residential Building” and it is externally connected with at least one
region that has
LULC as “
Unaffected Road”. This class is envisaged to be of great importance from the perspective of disaster management specially to develop standard operating procedures (SOPs) for evacuations.
Figure 10 depicts the corresponding GeoSPARQL query.
Unaffected Residential Building: A
region is termed as “
Unaffected Residential Building” as per FSO, if it is a
region that has
LULC as “
Residential Building” and it does not have an
Inferred LULC as “
Flooded Residential Building”.
Stranded Vehicle: A
region is termed as “
Stranded Vehicle” as per FSO, if it is a
region that has
LULC as “
Vehicle” and it is
externally connected with at least one
region that has
LULC as “
Flood Water”.
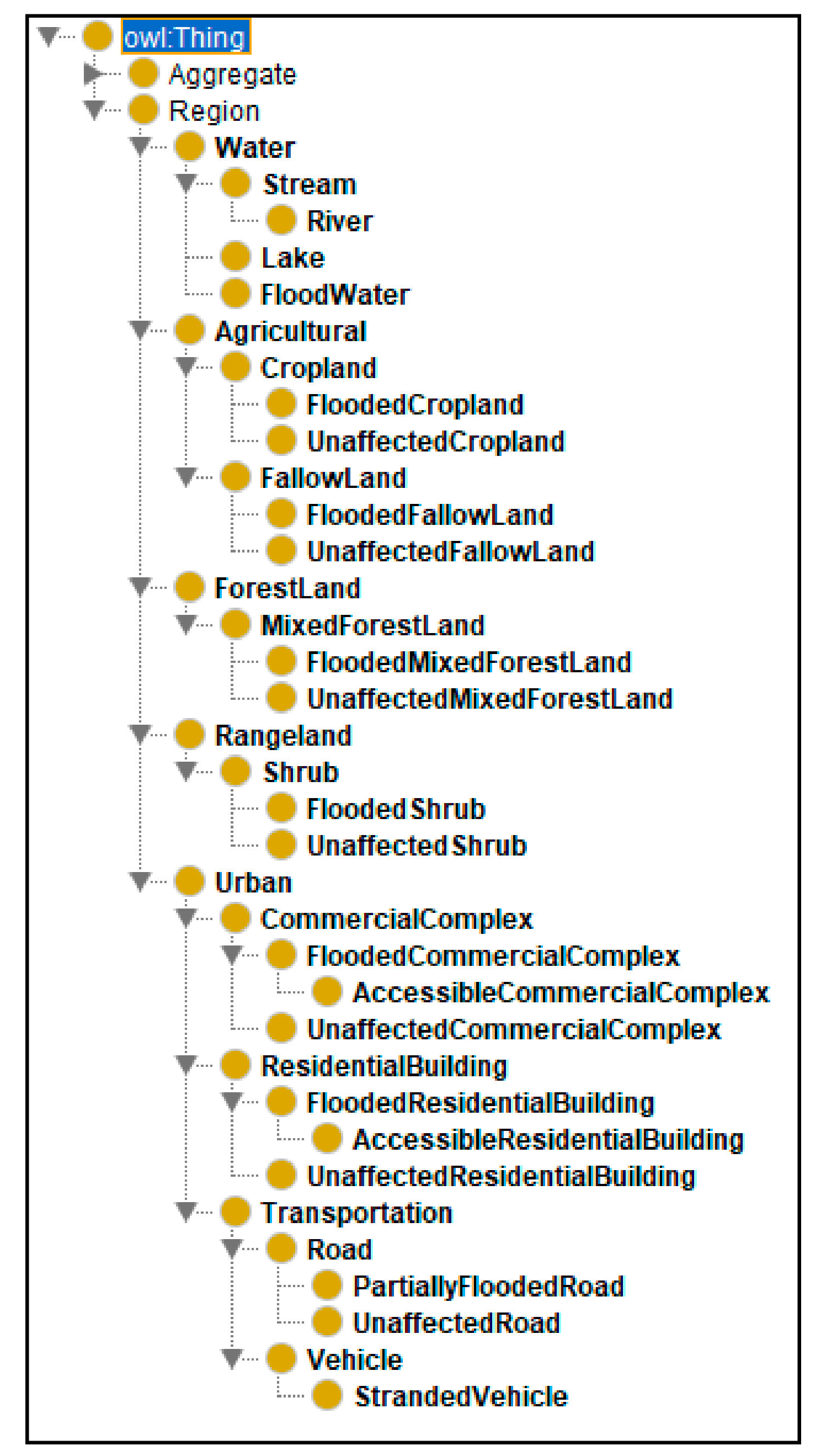
Figure 11 depicts a snapshot of the classes formalized in the proposed Flood Scene Ontology (FSO) that extends the proposed Remote Sensing Scene Ontology (RSSO).
Spatio-Contextual Aggregation in Remote Sensing Scenes
A generic remote sensing scene consists of numerous individual regions depending on the scale and resolution of the scene, with each region belonging to a particular LULC class. A natural language scene description could entail to describe each of these individual regions. However, a scene description describing every single region in the scene in natural language would lead to severe information overload and would sabotage our primary objective of enhanced situational awareness through scene descriptions. Thus, there arises a need to aggregate regions in a way that conveys the necessary information pertaining to the scene to a user in a comprehensive yet concise manner. It is evident from the works of [
29,
30] in the area of human perception and psychology that we, humans, have a natural inclination towards grouping objects in scenes based on our understanding of their interactions (spatial and contextual) with one another. This phenomenon, termed as “perceptual grouping”, was extended to regions in remote sensing scenes in the proposed Spatio-Contextual Triple Aggregation algorithm, to alleviate the issue of information overload. Reference [
31] describes a methodology with a similar objective of discovering groups of objects in generic multimedia images for scene understanding. However, they propose a Hough-transform-based approach that automatically annotates object groups in generic multimedia images with bounding boxes. The proposed Spatio-Contextual Triple Aggregation algorithm groups triples in the semantically enriched Scene Knowledge Graphs to generate aggregates that reference multiple regions in a scene that are spatially and contextually similar.
The Flood Scene Ontology (FSO) defines aggregate classes on similar lines as the contextual classes defined as children of the “region” class discussed earlier. However, the instances of aggregate classes are intended to logically house multiple region class children instances through the “hasCompositionOf” object property.
Figure 12 depicts some of the object properties of the FSO. The “hasCompositionOf” object property has children properties for each of the corresponding class aggregates. For example, an instance of class “FloodedResidentialBuildingAggregate” would have multiple instances of “FloodedResidentialBuilding” connected through the object property—“hasFloodedResidentialBuilding”. Thus, these object properties would help in mapping each of the aggregate instances to their component region instances. The “hasInferredAggregateName” Data Property allows the FSO to add contextually relevant names for the instance aggregates to use in the scene description. For example, multiple cars on a road can be aggregated and referenced as “traffic” or simply “vehicles” in the scene description. Such contextual knowledge from the perspective of remote sensing scene description was encoded in the FSO through SWRL rules.
The Sem-RSSU postulates the concept of Salient Region in a remote sensing scene. A salient region is defined as a region of significant importance from a spatio-contextual perspective in a scene. The concept of saliency proposed in Reference [
32] was adapted to the remote sensing scene context in Sem-RSSU. The selection of the salient region in a scene depends on the saliency measures: (1) area it covers and (2) the LULC class it belongs to. A remote sensing scene may or may not have a salient region in it. A scene can have at most one salient region. The salient region is the primary region in the scene that is proposed to act as a reference to describe all the other regions in the scene. This facilitates planning and realization of the natural language scene description for the scene. In scenes that lack a salient region, the regions are aggregated with reference to the entire scene itself and the scene description is planned and realized accordingly.
The Salient Region Selection algorithm (Algorithm 1) facilitates the selection of the salient region in the scene. The algorithm filters regions in the Scene Knowledge Graphs based on the threshold value of area and the LULC set in the contextual Flood Scene Ontology to select the most salient region. The Sem-RSSU was designed to be modular, such that the contextual ontology (FSO in this case) houses the most relevant LULC and the threshold area value for the salient region, depending on the application. In the urban flood scenario from the perspective of remote sensing scene description, the “road” LULC was selected to be the most relevant class.
Figure 12 depicts the snapshot of the aggregate classes and their corresponding object properties as formalized in the proposed Flood Scene Ontology (FSO).
| Algorithm 1 Salient Region Selection |
Input:
g: RS Scene Knowledge Graph
fso: Contextual Ontology—Flood Scene Ontology |
Output:
sr: Salient Region |
Constants:
SalientRegionLULC ← LULC_Name—defined in Contextual Ontology—fso
SalientRegionAreaThreshold ← Value—defined in Contextual Ontology—fso |
| 1. function salientRegionSelection(g, fso) |
| 2. Read g |
| 3. Initialize SalientRegionCandidates: = [] |
| 4. Initialize SalientRegionCandidateAreas: = [] |
| 5. for Region in g: |
| 6. if Region.LULC == SalientRegionLULC and |
| 7. Region.Area > SalientRegionAreaThreshold then |
| 8. SalientRegionCandidates.append(Region) |
| 9. SalientRegionCandidateAreas.append(Region.Area) |
| 10. else |
| 11. sr: = 0 |
| 12. return sr |
| 13. maxArea: = max(SalientRegionCandidateAreas) |
| 14. maxAreainde: = SalientRegionCandidateAreas.index(maxArea) |
| 15. sr: = SalientRegionCandidates[maxAreaindex] |
| 16. return sr |
| 17. end |
Figure 13 depicts the visualization of a Spatio-Contextual Triple Aggregate (Algorithm 2) generated by the algorithm in the remote sensing scene. The algorithm aggregated all the regions with Inferred LULC as “FloodedResidentialBuilding” that are to the “West” direction of the salient region with Inferred LULC as “UnaffectedRoad”. Thus, the regions visualized in red belong to a Spatio-Contextual Triple Aggregate with its “hasAggLULC” Data Property set to “FloodedResidentialBuildings”. This mapping of aggregates to their individual composition regions with the “hasCompositionOf” object property facilitates grounded scene description rendering.
| Algorithm 2 Spatio-Contextual Triple Aggregation |
Input:
g: RS Scene Knowledge Graph
sr: Salient Region
rsso: Spatial Ontology—Remote Sensing Scene Ontology
fso: Contextual Ontology—Flood Scene Ontology |
Output:
g′: Enriched Scene Knowledge Graph with Spatio-Contextual Aggregates of LULC
Regions |
Constants:
LeafNodes_LULC_Classes_List ← All Inferred LULC Class Names
- defined in Contextual Ontology—fso
LeafNodes_SpatialRelations_List ← All Inferred Spatial Relationships
Topological and Directional (Object Properties)
- defined in Spatial Ontology—rsso
- defined in Contextual Ontology—fso |
| 1. function spatioContextualTripleAggregation(g, sr, rsso, fso) |
| 2. Read g |
| 3. g′:= g |
| 4. for RegionLULC in LeafNodes_LULC_Classes_List: |
| 5. for SpatialRelation in LeafNodes_SpatialRelations_List: |
| 6. Initialize SCAggregate = [] |
| 7. for Region in g′: |
| 8. if Triple <Region, SpatialRelation, sr> in g′ and |
| 9. Region.hasInferredLULC == Region.LULC then |
| 10. SCAggregate.append(Region) |
| 11. if len(SCAggregate) > 1 then |
| 12. Insert Triple <sr, SpatialRelation, SCAggregate> into g′ |
| 13. Insert Triple <SCAggregate, hasAggLULC, RegionLULC> into g′ |
| 14. for Region in SCAggregate: |
| 15. Insert Triple <SCAggretate, hasCompositionOf, Region> into g′ |
| 16. return g′ |
| 17. end |
2.3. Natural Language Processing Layer
Most state-of-the-art research [
33,
34,
35] in image captioning deals with describing an image with a single sentence. This is feasible due to the fact that the images used in these studies are generic multimedia images and can be adequately summarized with a single sentence. Recent research [
12,
13,
17] in the area of remote sensing image captioning deals with describing a scene in a single sentence, however such description is not comprehensive and does not convey the context of the scene in its entirety. Remote sensing scenes contain numerous objects of importance that spatially interact with each other, and thus cannot be comprehensively summarized in a single sentence. Moreover, in remote sensing scenes, the context of the event when the scene was captured plays a crucial role in the scene description. A simple existential description merely informing the existence of all the objects in a scene is undesirable too. Instead a detailed contextual description of the objects in a scene based on their directional and topological interaction with one another from a contextual perspective of the event is desirable. The Natural Language Processing (NLP) layer of the Sem-RSSU framework was designed to meet this objective of comprehensive explainable and grounded spatio-contextual scene descriptions in natural language.
The Scene Knowledge Graph enriched with spatial and contextual semantics and having been aggregated by the Spatio-Contextual Triple Aggregation algorithm serves as an input to the Natural Language Processing layer. The individual tasks, as identified by Reference [
36], for a generic natural language generation system comprise (1) content determination, (2) document structuring, (3) aggregation, (4) lexicalization, (5) expression generation and (6) realization. The natural language generation for scene descriptions in Sem-RSSU loosely follows this approach. The Semantic Enrichment layer in Sem-RSSU inherently performs the tasks of content determination and document structuring by generating and enriching the Scene Knowledge Graph. The Spatio-Contextual Aggregation algorithm in the Semantic Enrichment layer further aggregates the graph for scene description rendering, thus performing aggregation as one of the NLG tasks. The tasks of Lexicalization, Expression Generation and Realization are performed as a part of the NLP layer in Sem-RSSU through the Grounded Scene Description Planning and Realization (GSDPR) algorithm (Algorithm 3).
The proposed Grounded Scene Description Planning and Realization (GSDPR) is the primary algorithm that is geared towards describing the regions in the scene from a spatio-contextual perspective with the salient region as a reference, using a template-based approach. The orientation of the salient region is initially determined with Salient Region Orientation Detection algorithm (Algorithm 4). It provides the primary algorithm with the information whether the salient region is oriented in the North-South or East-West direction. This is determined using the coordinates of the bounding box of the salient region geometry. This information is crucial while describing other regions in the scene with reference to the salient region.
The GSDPR algorithm initially checks for the existence of the salient region (SR) in the Scene Knowledge Graph. On detection of the SR, it detects its orientation. Depending on the orientation of the SR, it further proceeds to describe the Spatio-Contextual Triple Aggregates (determined in the Semantic Enrichment layer) against the directional orientation of the SR. If the algorithm detects that a Scene Knowledge Graph lacks a salient region, then it proceeds ahead in a similar fashion considering the entire scene geometry as a salient region and describing the regions with reference to the scene itself. For example, with a salient region “UnaffectedRoad” oriented in the “North-South” direction, All the other regions such as “FloodedResidentialBuildings”, “StrandedVehicles”, “FloodedVegetation”, etc., are described in reference to the “UnaffectedRoad” with the “East-West” direction. However, the triple aggregates whose geometry intersects with the geometry of salient region, are described along the direction of the SR orientation. For example, “Vehicles” or “Traffic” on the “UnaffectedRoad” oriented in the “North-South” direction, would be described in the “North-South” direction as well. These conditions, although specific, seem to generalize well for remote sensing scenes. The “describe” function in the GSDPR algorithm uses a templating mechanism based on the proposed Remote Sensing Scene Description Grammar G. It returns a sentence with appropriate natural language constructs describing the input triples passed to it. The “VisualizeAndMap” function is responsible for the visualization of color-coded regions mapping to the sentences generated by the “describe” function. This is implemented by visualizing the geometries of individual regions belonging to Spatio-Contextual Triple Aggregate mapped by the “hasCompositonOf” object property in the Scene Knowledge Graph. Thus, atomically describing the Spatio-Contextual Triple Aggregates and mapping their constituent regions aids in rendering grounded natural language scene descriptions.
| Algorithm 3 Grounded Scene Description Planning and Realization |
Input:
g: RS Scene Knowledge Graph
rsso: Spatial Ontology—RS Scene Ontology
fso: Contextual Ontology—Flood Scene Ontology
Output:
sd: List of Natural Language Sentences as Scene Description
groundedRegions: List of Grounded Regions Geometries corresponding to generated Natural Language Scene Description
Constants:
LeafNodes_LULC_Classes_List ← All Inferred LULC Class Names
- defined in Contextual Ontology—fso
EWDir ← [“East”, “West”]
- defined in Spatial Ontology—rsso
NSDir ← [“North”, “South”]
-defined in Spatial Ontology—rsso
1. function SceneDescriptionPlanAndRealization(g, rsso, fso, rssao)
2. Read g
3. sr: = salientRegionSelection(g, fso)
4. if len(sr) > 0 then
5. //Case with 1 Salient Region
6. srOrientation: = salientRegionOrientationDetection(g, sr)
7. if srOrientation == ‘NS’ then
8. alongSROrientation: = NSDir
9. againstSROrientation: = EWDir
10. else
11. alongSROrientation: = EWDir
12. againstSROrientation: = NSDir
13. sd.append(describe(sr))
14. groundedRegions.append(visualizeAndMap(sr))
15. g′ = spatioContextualTripleAggregation(g, sr, rsso, fso)
16. for SCTripleAggregate in g′:
17. //Check if the SCTripleAggregate intersects with SalientRegion
18. if ntpp(SCTripleAggregate.geometry, sr.geometry):
19. direction: = alongSROrientation
20. else:
21. direction: = againstSROrientation
22. for currentLULC in LeafNodes_LULC_Classes_List:
23. //Check if SCTripleAggregate has currentLULC and is oriented in direction w.r.t. SR
24. //If found then -
25. sd.append(describe(SCTripleAggregate, direction, sr))
26. groundedRegions.append(visualizeAndMap(SCTripleAggregate))
27. else:
28. //Case with 0 Salient Region
29. sr: = “thisScene”
30. g′ = spatioContextualTripleAggregation(g, sr, rsso, fso)
31. for SCTripleAggregate in g′:
32. for currentLULC in LeafNodes_LULC_Classes_List:
33. //Check if SCTripleAggregate has currentLULC and is oriented in each of the Cardinal
34. Directions w.r.t SR—Scene
35. //If found then
36. sd.append(describe(SCTripleAggregate, CardinalDirection, sr))
37. groundedRegions.append(visualizeAndMap(SCTripleAggregate))
38. end; |
| Algorithm 4 Salient Region Orientation Detection |
Input:
g: RS Scene Knowledge Graph
sr: Salient Region
Output:
orientation: Salient Region Orientation
1. function salientRegionOrientationDetection(g, sr)
2. Read g
3. Get BoundingBox Coordinates—LLX, LLY, URX and URY from g
4. Compute size of the Horizontal Side as horizontal and Vertical Side as
vertical of the
5. Bounding Box
6. if horizontal > vertical then
7. orientation = “EW”
8. else
9. orientation = “NS”
10. return orientation
11. end |
The algorithms developed in this research were implemented in Python. The RDFLib python library was used for facilitating the use of GeoSPARQL over the generated Scene Knowledge Graphs. Shapely, Descartes and Matplotlib libraries were used for rendering geometry visualizations for grounded scene descriptions.
The natural language scene descriptions generated by the NLP layer in Sem-RSSU conform to the following Remote Sensing Scene Description Grammar G. G is a Context-Free Grammar (CFG) in the research area of linguistics and is used to generate restricted languages. The grammar defines production rules specific to remote sensing scene description application context using the parameters T, N, S and R (Algorithm 5).
| Algorithm 5 Remote Sensing Scene Description Grammar G |
G = (T, N, S, R)
T is a finite alphabet of Terminals
N is a finite set of Non-Terminals
S is the Start Symbol and S є N
R is the finite set of Production Rules of the form N → (N ∪ T)*
T = {flooded buildings, accessible buildings, unaffected buildings, unaffected roads, vehicles, stranded vehicles, traffic, flooded vegetation, unaffected vegetation, road, scene, spread across, to the, of, on, east, west, north, south, there, the, a, an, is, are}
N = {ZeroSalientRegion, OneSalientRegion, DescribeSalientRegion, Pronoun, AuxiliaryVerb, Article, SalientRegion, DescribeSpatioContextualAggregate, SpatialReference, DirectionalReference}
S = DescriptionSentence
R = {
<DescriptionSentence> → <ZeroSalientRegion> | <OneSalientRegion>
<OneSalientRegion> → <DescribeSalientRegion> | <DescribeSpatioContextualAggregate>
<ZeroSalientRegion> → <DescribeSpatioContextualAggregate>
<DescribeSalientRegion> → <Pronoun> <AuxiliaryVerb> <Article> <SalientRegion>
<DescribeSpatioContextualAggregate> → <Pronoun> <AuxiliaryVerb>
<SpatioContextualAggregates> <SpatialReference> . <SalientRegion>
<SpatioContextualAggregates> → flooded buildings | accessible buildings | unaffected buildings | unaffected roads | vehicles | stranded vehicles | traffic | flooded vegetation | unaffected vegetation
<SalientRegion> → road | scene
<SpatialReference> → spread across <Article> | to the <DirectionalReference> of <Article> | on <Article>
<DirectionalReference> → east | west | north | south
<Pronoun> → there
<Article> → the | a | an
<AuxiliaryVerb> → is | are
} |
The natural language scene description of remote sensing scenes generated by G can be defined as follows:
The grammar is invoked for every call to the “describe” function in the GSDPR algorithm. Thus, the natural language scene descriptions rendered by Sem-RSSU for remote sensing scenes can be derived and verified by parsing the proposed Remote Sensing Scene Description Grammar G.
The Rendering layer involves the generated Natural Language Scene Description in text form and its corresponding color-coded visualization depicting grounded mappings of the sentences in the description to the regions in the scene. This reinforces the explainability of the generated scene descriptions by Sem-RSSU. The figure below depicts the front-end of a web-based application implementing the Sem-RSSU framework to browse, preview, render grounded scene descriptions, query and visualize remote sensing scenes.
The web-based application depicted in
Figure 14, uses Python with RDFLib and GraphDB triple-store at the back-end with REST based API calls originating from the user interactions and renders the scene descriptions, responses and visualizations over the web page.
5. Conclusions and Future Directions
The Semantics-driven Remote Sensing Scene Understanding (Sem-RSSU) framework presented in this paper aims for enhanced situational awareness from remote sensing scenes through the rendering of comprehensive grounded natural language scene descriptions from a spatio-contextual standpoint. Although the flood disaster was chosen as a test scenario for demonstrating the utility of comprehensive scene understanding, Sem-RSSU can also be applied to monitoring other disasters, such as earthquakes, forest fires, hurricanes, landslides, etc., as well as urban sprawl analysis and defense-related scenarios, such as hostile surveillance in conflicted zones. It is envisaged that Sem-RSSU would lay the foundation for semantics-driven frameworks for natural language scene description rendering for comprehensive information dissemination for application scenarios such as disasters, surveillance of hostile territories, urban sprawl monitoring, etc., among other remote sensing applications.
The framework proposes the amalgamation of a deep learning and a knowledge-based approach, thereby leveraging (1) deep learning for multi-class segmentation and (2) deductive reasoning for mining implicit knowledge. The framework advocates the transformation of remote sensing scenes to Scene Knowledge Graphs formalized through the development of Remote Sensing Scene Ontology (RSSO). The ontology models the representation of a generic remote sensing scene in the form of knowledge graphs by defining concepts related to the scene’s lineage and land-use/land-cover regions and the spatial relationships between them. The contextual Flood Scene Ontology developed as a part of this research defines concepts and relationships that are pertinent during a flood disaster in an urban landscape. The ontology thus demonstrates Sem-RSSU’s adaptability to different application contexts. The Remote Sensing Scene Ontology (
http://geosysiot.in/rsso/ApplicationSchema) and Flood Scene Ontology (
http://geosysiot.in/fso/ApplicationSchema) have been published on the web, for reference. The framework proposes and implements the Spatio-Contextual Triple Aggregation and Grounded Scene Description Planning and Realization Algorithms to (1) aggregate Scene Knowledge Graphs for aiding in scene description rendering from a spatio-contextual perspective and (2) render mappings between regions in the scene and generated sentences in the scene description respectively. It also defines the Remote Sensing Scene Description Grammar that the rendered natural language scene descriptions conform to. The GeoSPARQL Query Interface of the framework enables querying and visualization over the inferred Scene Knowledge Graphs, thus allowing users to further explore and analyze the remote sensing scene. Extensive evaluation of individual components of the framework inspires confidence and demonstrates the efficacy of Sem-RSSU.
Although the approach for grounded natural language scene description rendering in Sem-RSSU produces fair results, it would be interesting to explore and compare with a neural approach to translate Scene Knowledge Graphs to natural language. In addition to the use of directional and topological relations, it would be beneficial to explore the use of inferred qualitative spatial relations, such as “near”, “around” and “next to”, in the future, to generate more natural scene descriptions. Moreover, the temporal component in natural language scene descriptions for depicting evolving remote sensing scenes has remained largely unexplored. The future directions of this research are (1) to explore neural approaches, to render natural language scene descriptions from Scene Knowledge Graphs; (2) to explore the use of inferred qualitative spatial relations, to improve the naturalness of the rendered scene descriptions; and (3) to explore the temporal component in Scene Knowledge Graphs, to aid in rendering natural language scene descriptions of rapidly evolving remote sensing scenes over time.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}