1. Introduction
City planning for sustainable communities requires equitable distribution of and access to healthy food options for inhabitants. This study examined the statistical association between food access on people’s health and its connection to income and mobility access. The unbalanced distribution of food may have consequences concerning health and other factors. In this study, we examined these issues in Guilford County, North Carolina. Guilford County was ranked as the highest in food scarcity in North Carolina by the Food Research and Action Center in 2020 [
1]. Since then, the county has worked to analyze the factors associated with food scarcity, studying the area’s income, education, and poverty rates. To advance Guilford County from a scarcity condition to sustainable equal distribution condition, an estimate of the scarcity situation and an analysis of the geographic areas for improvements in food access were needed. A key objective of sustainable communities is to effectively manage the health issues of their inhabitants. The process included gauging food access distribution by spatial methods, analyzing potential factors, and finding areas with remarkable numbers to start development. Recent studies have examined the distribution of food outlets and peoples’ buying habits and their food options. However, there are several studies that have presented the investigation of food outlets’ distribution geographically by integrating the health issues correlations to people’s habits or food distribution. This study focused on the density of food outlets, the health issues regarding the food outlets’ distribution, food access areas, and its correlation in terms of income, vehicle access, and health issues. Ultimately, we also simulated an improvement to provide suggestions and strategies for enabling Guilford County to become a smart, sustainable community in terms of food access.
Planning future cities requires scientists’ and planners’ points of views in solving current issues and prioritizing the service sectors according to the areas’ needs. As a result, concepts, such as smart cities, intelligent cities, sustainable cities, and creative cities, were invented. The definitions of these concepts vary from one author to another based on the planning priorities. Several models have been applied to investigate health-related issues. A socio-ecological model (SEM) is an approach that investigates health as influenced by environment, social, policy, and physical factors [
2]. SEM investigates levels of influence at the interpersonal, institutional, community, and public policy levels [
2]. This model investigated factors at each layer to understand their relationships [
3]. Nevertheless, this model estimated prediction [
4]. For instance, a study presented the application of the SEM model to investigate obesity-related variables such as vesical activities [
3]. The layers that presented the strongest on predicting childhood obesity were neighborhood characteristics, parent demographics, and parent participation in their community [
3].
According to [
5], more advanced management technology can be used to manage a city’s resources and provide security [
5]. In city planning, food access is primarily analyzed by scientists and decision makers to show its influence on the health of people living in these areas [
6]. Food security and access were measured using several methods. Several techniques and methods were applied to measure food distribution and security. Measuring the geographical location of food outlets was performed based on applying GIS methods and tools. GIS is a software manager that analyzes data based on their geographical location [
7]. GIS is applied to a wide range of problems such as natural hazards and public health [
8]. GIS methods were used in different food analyses such as buffering, kernel density estimation, and spatial clustering [
7]. More methods were applied depending on surveys and statistical data. For instance, an example method was based on the retail food environment index (RFEI) [
9]. However, some methods have limitations concerning the application and presentation of results. The RFEI method has the limitation of not covering all tracts because of the need of calculating all food outlets categories such as supermarkets [
9]. A study performed in California showed that data maples covered only 3719 out of 7049 based on the RFEI method [
9].
Techniques, such as machine learning, are now used for research related to food security, as they are highly data-driven models. Machine learning (ML) is a programming technique that is used to solve nonlinear problems efficiently. It has models and algorithms, where the algorithm executes on the data to create the model [
10]. It has serval different models to investigate relationships and compare results. The ML techniques were used to solve major problems such as classification, regression, reinforcement, and clustering [
11]. The regression analysis was applied to detect continuous metric output [
12]. Regression problems were investigated by several models, for instance, linear and nonlinear regression. These models also worked in hyper feature space for illustrating the relationship and were applied to different scientific fields [
13]. A further example is the K-nearest neighbors regression model, which presents appealing results for small data [
14]. Random forest regression models, as part of tree multioutput regression, were used to predict the variables [
12]. More than one regression analysis can be used in comparison to find the best-suited model for higher performance. A study investigated food security using machine learning models (extreme gradient boosting, random forest, and CatBoost) to predict monthly variations [
15]. This study investigated data involving food choices, income, geographical location, and climate [
15]. It showed Xgboost was the best model and better results were presented when fewer changes in time and place accrued [
15]. A further study in food security discussed the application of machine learning techniques to predict the modified retail food environment index (mRFEI) and found that a food desert differs from a food swamp thereby necessitating the application of different policies [
16].
Furthermore, sustainable communities give priority to people’s health [
5]. However, currently, it is recommended to use smart and sustainable terms as one concept, which converges the application of data-driven technologies of smart cities with the key goal of creating sustainable communities to provide an equal right to the benefits and an equal access to healthy food [
17].
Studying the distribution of food outlets involves studying the distribution of groceries, restaurants, and residents’ density. Food access can be analyzed by studying the two key elements known as a
food desert and a
food swamp. Food swamps are areas with more unhealthy food options than healthy food options [
18]. On the other hand, food deserts represent areas with low access to healthy food, and the expected distance was 500 meters, 0.3 miles, or 5–7 minutes of walking [
19]. The characteristics of food deserts include availability of inexpensive food, poor nutrition, and limited healthy items in small stores [
18]. Food insecurity is not only the critical area to be investigated. The availability of food sources is also very important. Food oases represent areas where people have an abundance of healthy food options rather than unhealthy food options [
20]. In another study, the difference between food item prices was investigated with respect to food access areas, food deserts, food swamps, and food oases, and it was determined that there were no remarkable differences in the process [
20].
Several studies investigated the influence between food distribution and other variables such as location, transportation, time, and behavior. A study of 36 counties of a suburban area showed that these areas suffered because residents needed to travel up to 30 miles for healthy food access [
21]. Another study analyzed food access in the suburban areas and rural areas of Louisiana and determined that suburban areas near urbanization had greater access to healthy food [
22]. Time could be analyzed by two dimensions including the time of events (such as weather events) and the time of source existence (such as food trucks and farmers’ markets) [
6]. For example, the accessibility of food by walking was found to be different in summer than in winter, as the time of the year and day were different. As a result, in the case of a health disaster, socially isolated communities with food scarcity were most severely affected [
23]. A study applied GIS and analyzed people’s access to transportation where the results indicated the importance of transportation access to improve people’s food choices [
24]. Another study analyzed people’s behavior using data from an application designed for people to donate food [
25]. The results showed a correlation between a higher number of donations points and more bus stops as a means of access to transportation [
25].
Analyzing food access is a complex process that includes observing the current distribution of food outlets and analyzing the residents using different methods, factors, and scenarios. These factors were transportation access to supermarkets, the ethnic group of population distribution in food deserts, economic status, and chain and non-chain stores [
26]. A study by Eckert and Shetty (2011) used block methods in geographic information systems (GIS), which applied network analysis to determine the distance between each resident and the grocery store (considering the residents’ ethnic group and income) [
27]. The result showed that there was no connection between income and ethnic group in relation to food access [
27]. Regarding chain and non-chain stores, a report by the Economic Research Service (ERS) explained that smaller stores sold smaller packages at a higher cost compared to supermarkets and non-chain stores [
26]. Moreover, they were typically situated in poorer areas [
26]. Another study showed that more options for greater food items were available with lower prices in supermarkets compared to small stores [
28].
One study on food access and its consequences examined the relationship between fast-food restaurants and obesity in the surrounding areas [
29]. The study considered two miles as the accessibility distance to analyze the health records but found no connection between obesity and fast-food accessibility [
29]. Another study in Philadelphia, which was considered the second lowest in food access among major cities nationally, concluded that many low-income and food access neighborhoods had a high number of health challenges such as diabetes, heart diseases, and cancer [
26]. An additional study also found a connection between food deserts, low income, lack of transportation, and diabetes [
30].
There have been several studies on the consequences of inadequate food distribution, and they included the number of diseases spreading. Healthy food access was a key factor in the obesity epidemic, and the high consumption of unhealthy food was a critical factor in diabetes, hypertension, cancer, high mortality rates, and life loss [
18]. There were some studies on the health risks and mortality rates regarding food access, and some of these suggested looking into the factors of these rates after mapping them. A study by Cossman and others (2003) mapped the mortality rates in every county in the United States for 30 years and determined the highest and lowest mortality rates [
31]. The study suggested looking into the continuous high mortality in a county and analyzing it to determine the involved factors [
31]. Another study looked into mapping health issues, such as tuberculosis, and the correlation with human development such as food access, income, education, and health [
32]. The study concluded that there was a connection between human development and tuberculosis [
32], where neighborhoods with less than the average income and education had higher tuberculosis rates [
32]. A further study illustrated the investigation of type 2 diabetes per county level by machine learning [
33]. Its results illustrated no correlation between the health issue and the variables of physical activities, access to exercise, and food environment [
33].
Several limitations on food access were presented in recent studies. A large percentage of studies focused on only one to two outlets or categories, and only a few investigated the effect of all types of food outlets [
34]. Another method’s limitation involved hypothesizing that people’s health was only influenced by the stores located closed to their residential location [
34]. A further limitation involved using separate methods concerning food, where nutrition studies were separated from food environment research (combining them with the support of more methods and techniques would present a comprehensive overview of food access and health consequences) [
34].
The reviewed literature illustrated that several studies focused on a few parts or variables of the overall problem regarding food access, health issues, and regional distribution. We studied all food access areas together with their influence on three health issues as a holistic case and to help local authorities in decision making for future planning. According to the literature review, food scarcity was studied in the form of a food desert and food swamp but lacked their influence on health conditions and the comparison to food abundance. The research questions in this study were:
Using GIS spatial mapping, can we find possible correlations between food access distribution and health risk issues?
Do health issues depend solely on univariate food access distribution or multivariate analysis of transportation access, income, population, and food access?
Can the linear or nonlinear ML regression models be developed for dependent variable health risks with better determinant coefficient?
This study addressed the gap by finding the correlations of food desert factors, food swamps, and food oases impacting on health issues and mortality using geospatial in-formation analysis, surveys, and machine learning techniques. Our contributions in this study included reporting the results of:
Investigating the geospatial correlation between food distribution and health issues;
Comparing the number of health issues between food access areas;
Estimating the statistical correlation between health issues and several variables;
Comparing the results of the regression analysis models regarding health issues related to several variables.
2. Materials and Methods
We examined Guilford County in North Carolina as our study area (
Figure 1) including tabular attribute data. Data were obtained from the Health Department in Greensboro based on a crude survey, USDA Environmental Atlas, and the American Community Survey. Health records were collected by the North Carolina Department of Public Health. These data were geolocated by tracts. The data included income, food outlets, health records, low transportation aces, and mortality rates. Health records included (i) high cholesterol, where cholesterol was higher than 240 mg/dL and higher than 18% lipoprotein density; (ii) high blood pressure, where the systolic was 140 mm and diastolic was 90 mm or higher; (iii) obesity as defined by the World Health Organization, when an individual’s body mass was greater than 30 [
35,
36,
37]. At the time of this study, Guilford County aimed to become a smart, sustainable community. With a population of 533,670 within 645.70 square miles, it was the third most populated county in North Carolina and was also among the top five most densely populated counties in the state of North Carolina [
20]. It was also the largest county in terms of acreage [
38,
39]. Guilford County had 118 census tracts, and it covered the cities of Greensboro and Highpoint and eight towns consisting of Gibsonville, Jamestown, Oak Ridge, Pleasant Garden, Sedalia, Stokesdale, Summerfield, and Whitsett. The county was identified primarily as a food desert in 2014 [
1]. The median household income in this county was
$51,072 [
39]. Methods (see
Figure 2) included applying GIS and regression analysis. The GIS method was selected to investigate the geographical correlation, and the regression analysis was conducted to combine it with statistical association. Regression analysis is a machine learning technique that can be applied to forecast prediction or investigate relationships [
40]. Regression models were applied (as multioutput regression and multiple linear regression) to present relationship and compare their results. The mathematical foundation lies in deriving the nonlinear relationship of the dependent variable against the multivariate independent variables. We based our nonlinear multivariate regression model with a polynomial of the order 3 and 3 independent variables giving up to 2
n − 1 coefficients. We compared this model against the other ML models and found that the random forest regression model performed better next to the nonlinear multivariate regression model. The hyper dimensional feature space transformation in the random forest technique yielded a better performance.
2.1. GIS Method
First, we developed the geospatial maps of health (
Figure 3) and mortality outcomes for Guilford County.
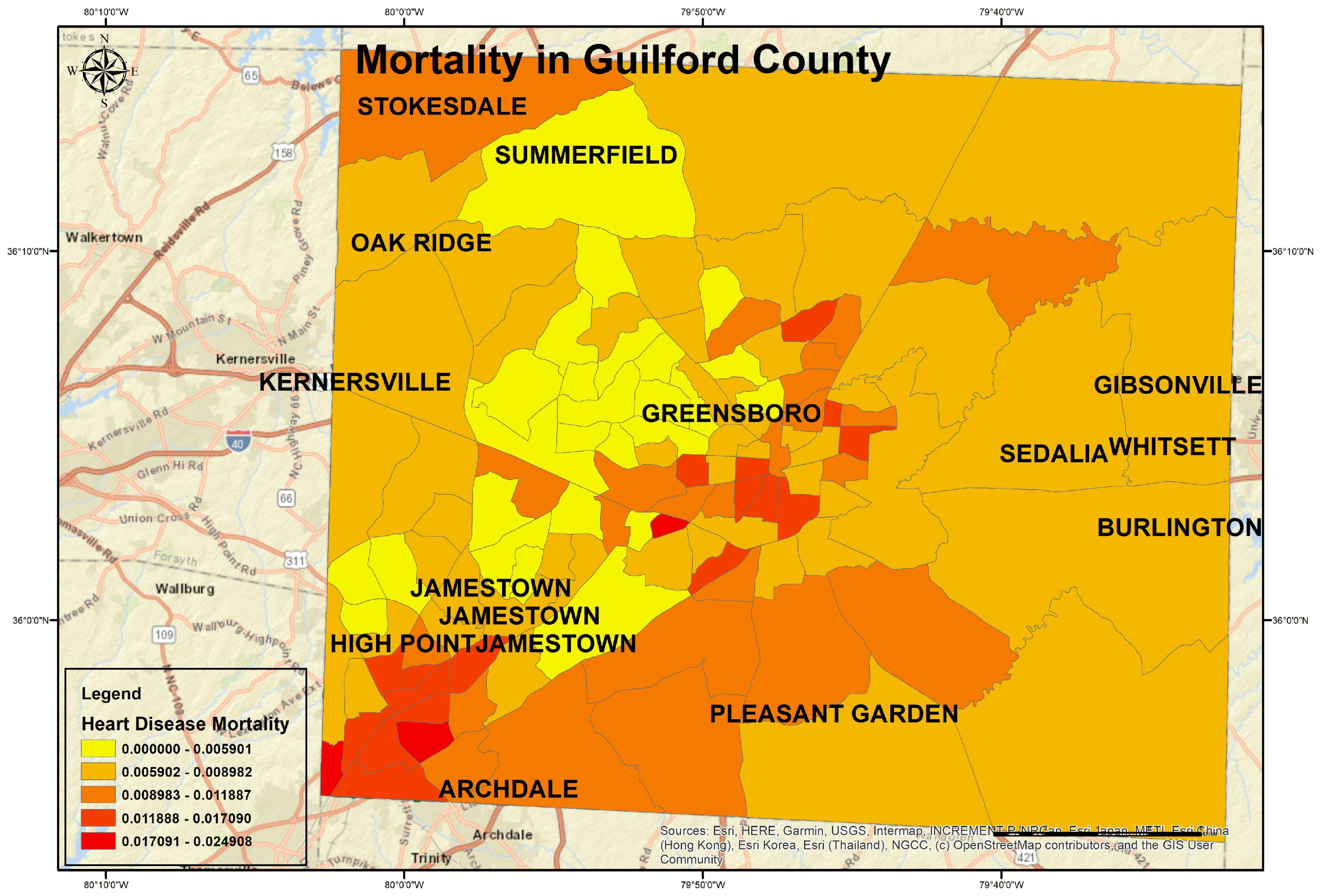
Figure 4 llustrates the geospatial map of heart disease-related mortality rates in Guilford County by percent in each census tract. The descriptive statistics of these health issues are presented in
Table 1.
The mortality rate due to the fact of heart diseases ranged between 0.002% and 0.008% per census tract.
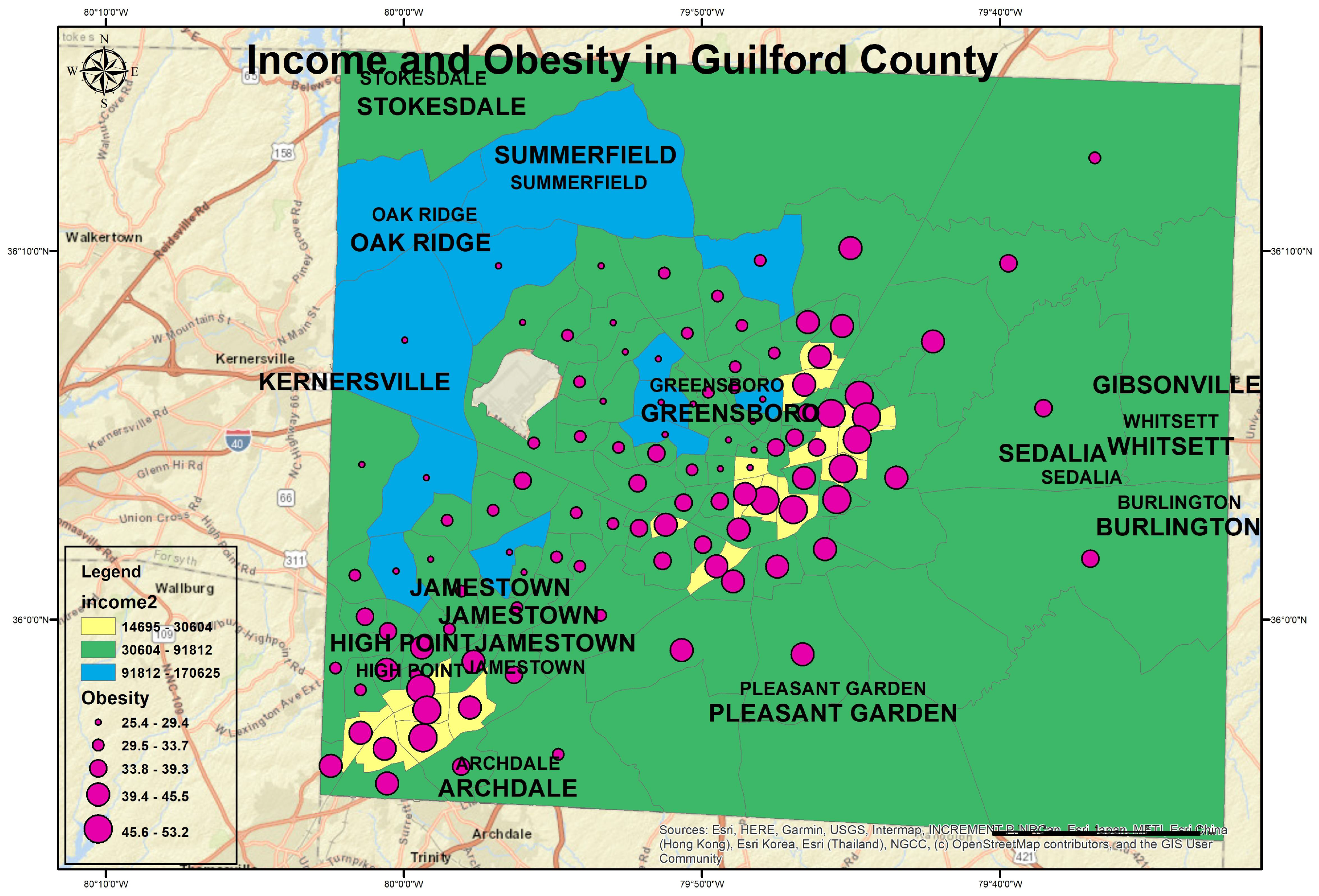
Figure 3 shows that there was a high density of obesity and high blood pressure in central Greensboro, Downtown, and Highpoint (outlined in the bounding box). It also coincided with the high density of high cholesterol issues. Notice that the density markers of high cholesterol had higher percentages than hypertension markers. These density maps were developed using the point density tool in ArcGIS software and were overlayed against the obesity density map. Interestingly, the west part of Guilford County showed low obesity numbers. However, high cholesterol and high blood pressure numbers were shown in few census tracts. The distribution of high blood pressure and high cholesterol showed a higher density around Greensboro and Highpoint, too.
Figure 5 shows the mean household income distribution of Guilford County with obesity distribution. A low income was from USD 0 to 30,604, a middle income was between USD 30,604 and 91,812, and a high income was more than USD 91,819 per year [
41]. The overall mortality rate map shows a similar pattern in the downtown Greensboro and High Point cities.
Later, we calculated the total number of healthy and unhealthy food outlets per census tract using the tabulate intersect method, which gave the result in a tabular format. Afterward, the resultant table was joined to the study area using the “Mathematical Join” option. The census tract shapefile was used to find the areas with higher unhealthy food from the intersection of healthy and unhealthy outlet maps in
Figure 6 and
Figure 7. We then performed spatial analysis using the clip tool in the ArcGIS software to find the number of health issues and the mortality rates in all three food access areas (see
Table 2).
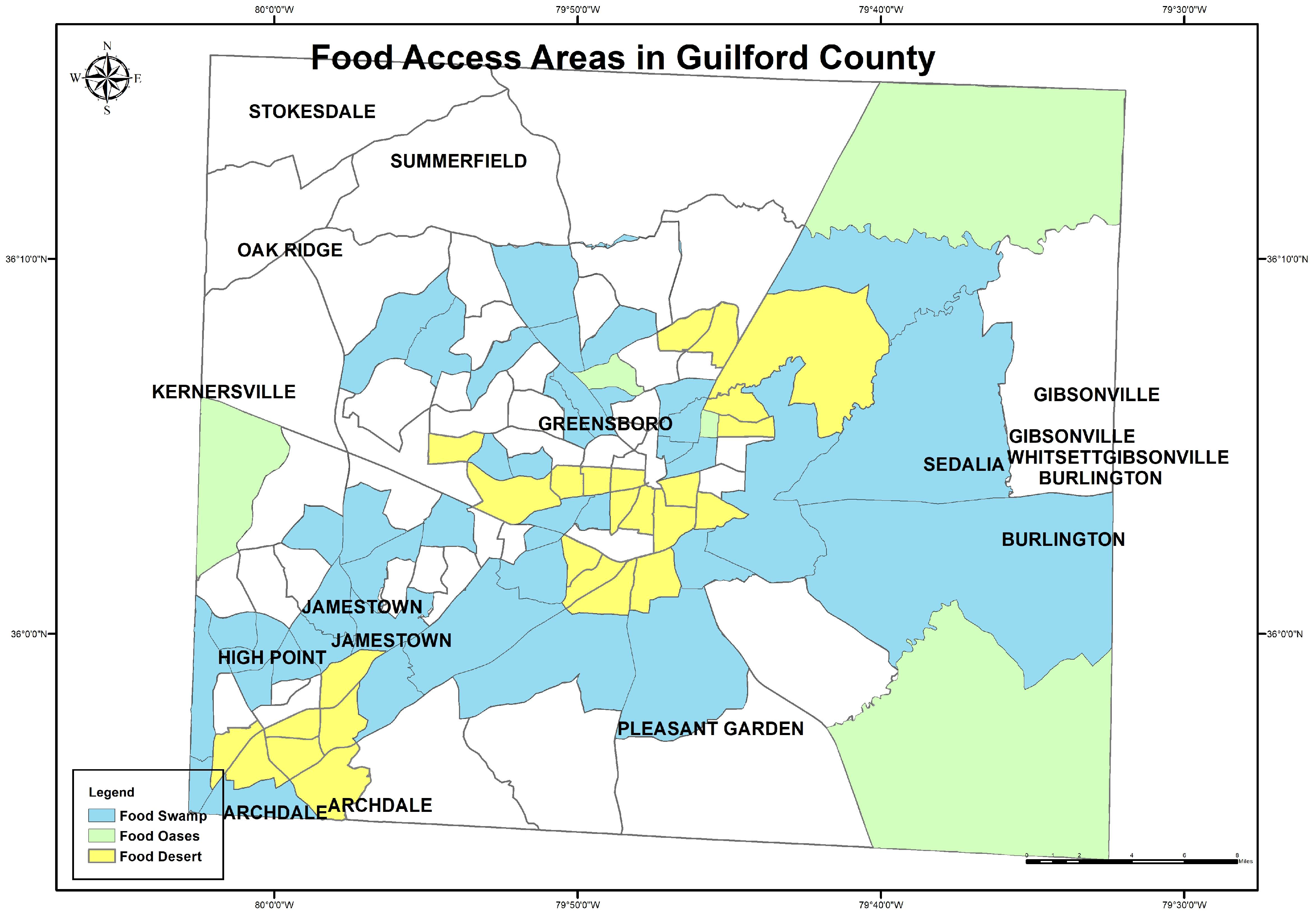
Next, we developed geospatial maps of the three food access areas. Based on healthy food access, Guilford County was divided into three food geographies: food deserts, food swamps, and food oases (
Figure 8). Food deserts were measured based on the USDA Economic Research Service definition as the census that had a poverty rate defined as more than 20–30% of its people living more than 1 mile away from a full-service supermarket [
42]. In addition, we included where the minority rate was higher, i.e., more than 30% of the total population [
43,
44]. A food desert is presented in the equation below:
Food desert = low access to supermarkets (the tracts with more than 30% of its people in more than one mile from supermarket) + low car access (households with no personal transportation) + high poverty rate + low income (<USD 30,000 p.a.).
The food desert method started by buffering 1 mile around supermarkets and applying the symmetric differences tool to find the tracts with 30% of the population living one mile away from supermarkets. After that, we applied the intersect tool to the previous layer with the layers of low income, low car access, and high poverty.
The method started by buffering 1 mile around supermarkets and applying the symmetric differences tool to find the 30% of the population that was more than one mile to supermarkets. Afterward, we applied the intersect tool to the previous layer with the layers of income and poverty. Then food deserts showed areas where residents had scarce access to nutritious food. Geospatial mapping of food deserts in Guilford County was developed by identifying areas with the following overlapping characteristics: (i) healthy and unhealthy food density (
Figure 6 and
Figure 7); (ii) high population density; (iii) high poverty and low income (
Figure 5); (iv) low access to transportation. A food desert is a census tract that has less than a 20% poverty rate and at least 30% of its population lives more than one mile from supermarkets.
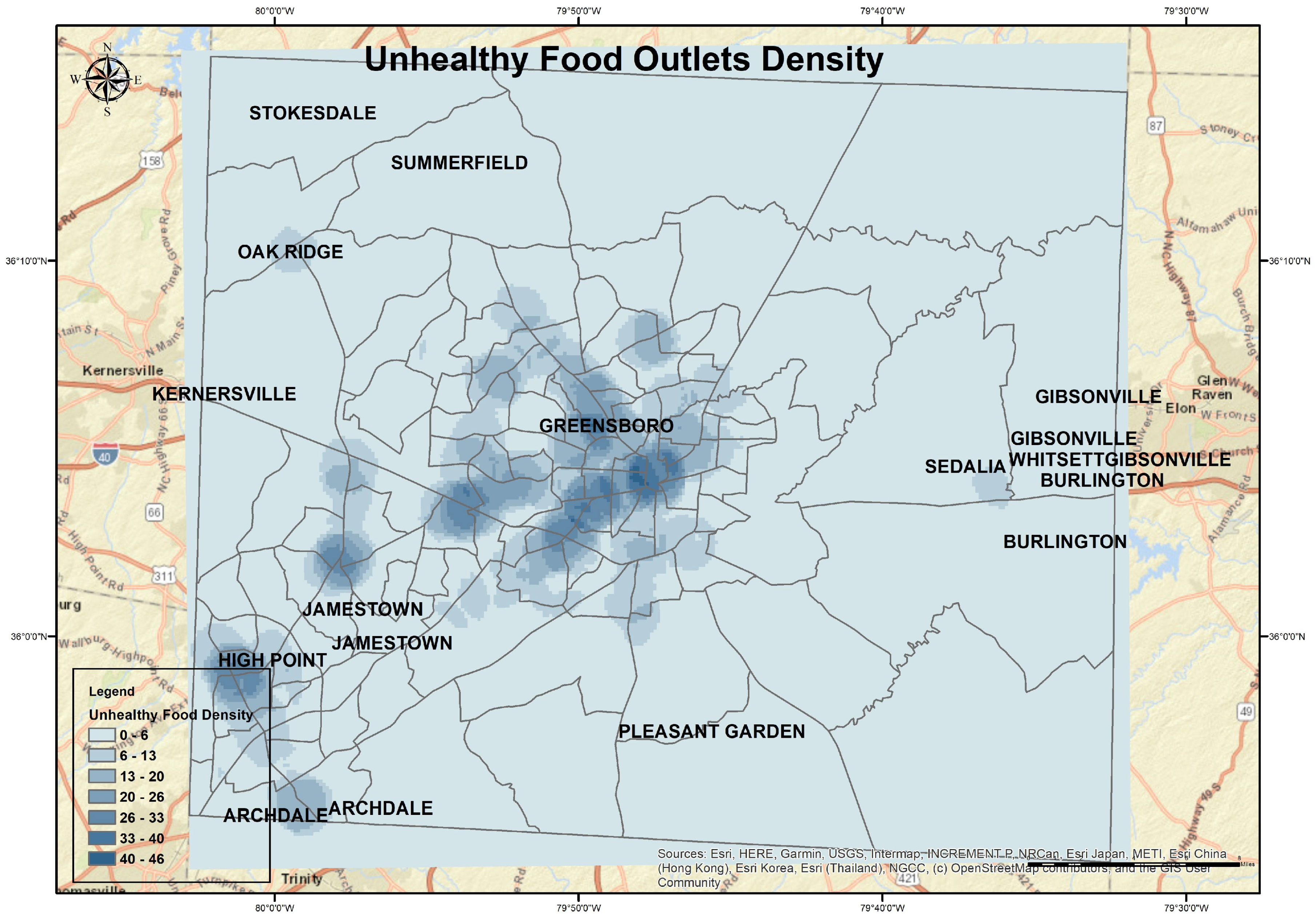
Afterward, we identified food swamps and food oases. A food swamp had more unhealthy food outlets than healthy outlets, but a food oasis had more healthy than unhealthy food options. Food outlets were categorized as healthy based on fresh food availability such as supermarkets and farmers’ markets. Unhealthy food outlets were packed, and fast food was sold in various places such as restaurants and convenience stores. To develop the food oases and swamp geo-maps, we categorized healthy and unhealthy food outlets (
Figure 6 and
Figure 7). The healthy outlets were where fresh vegetables, fruit, and meat were available. This category contained supermarkets, grocery stores, meat markets, farmers’ markets, community gardens, farm road stands, and food parties. Although the second category represented relatively unhealthy food, it comprised convenience stores, dollar stores, and restaurants. We computed the density maps for healthy and unhealthy food outlet stores (
Figure 6 and
Figure 7) using the region growing density tool. These density maps present the volume of stores for each category. For healthy food outlets, the highest number of stores ranged between 5 and 6 (dark spots in
Figure 6), and the lowest was 0−2. For unhealthy food outlets, the highest number of outlets ranged between 40 and 46 stores (dark sports in
Figure 7), and the lowest was 0–6.
We computed the descriptive statistics (i.e., mean values and standard deviation) of each health issue in these food access areas for correlation analysis. We used the clip tool additionally to merge the income layer by each food access area to compute the mean household income for
Table 2. After developing the overall map showing the three food access areas’ geographies (
Figure 8), we compared the health records in each area to determine if there was an effect of healthy food access on health and mortality outcomes. The spatial analysis method showed positive correlations among food outlets and health issues, mortality rates, and income. The results are corroborated in
Table 2.
In
Table 2, the percentage of the population in food access areas may not provide a clear illustration of the number of people impacted by health issues. For instance, the quantity of 36.5% of the population in food deserts having high blood pressure was 38,578.674, which was higher than 37% of the population in the food jungle (consisting of 5123.39).
2.2. Multioutput Regression and Multiple Linear Regression
We used machine learning techniques to examine the quantitative analytics of population and median income on health issues by specifically applying multioutput regression and multiple linear regressions. Multioutput regressions are regression problems that involve predicting two or more numerical values given several independent variables. The multioutput algorithm is more efficient than the single-output algorithm, because the relations among outputs can be estimated simultaneously by the proposed prediction model. Moreover, application of more than one regression was necessary to compare their results. In this work, we predicted high blood pressure rates, high cholesterol rates, and obesity rates based on the inputs (independent variables) of population, income, and low car access.
The data set was divided into 80% training and 20% testing for multioutput model development. The training set contained eighty-seven (87) observations and twenty-two (22) observations in the testing set, and two different metrics: root mean square (RMS) and R-Squared (R^2) which were used to evaluate the models developed. The implementation of multioutput and multiple linear regression models was conducted with the Sklearn package in Python and MATLAB 2020a, respectively. The default parameters for the multioutput regression models are shown in
Table 3.
The below equation, based on multivariate linear regression, was applied to predict and investigate the relationship between variables, where 49.855 and 0.00029 were the coefficient for the median income variable, 13.233 was the coefficient for car access, and 0.00025 was the coefficient for the interaction between median income and low car access.
y = 49.855 − 0.00029 * MedIncome + 13.236 * Low Car Access − 0.00025 * MedIncome * Low Car Access.
4. Conclusions and Future Research
This research investigated the possibility of the geographic correlation of three health issues (i.e., high blood pressure, high cholesterol, and obesity) with food distribution and the statistical correlation with income and car access. These health issues were investigated together to provide a thorough analysis of the chronic health conditions in Guilford County. This study used geospatial technologies and machine learning techniques to provide insights into developing sustainable and healthy communities by examining the presence of food deserts, food swamps, and food oases. We demonstrated how access to healthy food options influenced health and mortality outcomes in one of the largest counties in the state of North Carolina, USA. Specifically, we co-intersected county-level data on representing food access, income distribution, and access to personal and public transportation with data on health or issues and mortality rates.
We started by showing the food outlets’ density and health records in the county. The density measuring technique was an alternative method to creating food access maps. The RFEI measure showed only the quantitative index value and may not have covered all tracts based on the equation’s requirements. Then, we analyzed the health records in the food desert, where people had limited access to healthy food options due to the low income and low transportation access. We also created geospatial maps of food swamps and food oases. Geospatial data presented the distribution of food deserts in Greensboro and Highpoint downtowns; high income distributes in the northwest of Greensboro, in Summerfield, Oakridge, and Kernersville; high density of food outlets, both healthy and unhealthy, in Greensboro and highpoint. The results clearly showed that food swamps had a higher density of unhealthy food outlets than healthy outlets, while a food oasis had a higher density of healthier than unhealthy food options. We then compared the health records in each of these food geographies to examine any influence of healthy food access on health issues.
This study was limited to the study area of Guilford County. The county-level was practical for showing the current stage and helping local decision makers. Involving more counties for comparison would have supported the study’s hypothesis that health issues had a positive correlation with food distribution.
The results of the GIS analysis demonstrated that food deserts with low income, high population density, and low access to transportation were less sustainable, as they showed a high correlation with severe health issues and mortality. Food swamps and oases showed lower health issues and mortality rates compared to food deserts due to the availability of transportation access and income higher than poverty in these areas. The food swamp was a better option than food desert because, nonetheless, the unhealthy food options were accessible. The study’s results presented the correlation of food environment with three health issues, unlike other studies. For instance, a study analyzed the numbers of healthy and unhealthy foods and the rate of obesity and found a correlation with unhealthy food options [
45]. However, our study investigated more variables, such as income and car access, which were parts of food access areas.
Food deserts showed greater health issues. This could be related to one of the area’s characteristics: the availability of unhealthy food outlets, high poverty rates, and low access to transportation. Regarding the availability of unhealthy food, some studies showed no association between unhealthy food and health issues such as obesity and hypertension. A study applied statistical analysis to investigate the correlation between unhealthy food options and obesity and hypertension in children but found no significant correlation [
46].
Regression models were used to detect relationships and predict results. The application of several regression models was objective in comparing their results. It illustrated the most correlated variables regarding health issues for inclusion in the development plan. Moreover, illustrating these strong variables would benefit stakeholders in directing new plans and investments. Multi-output regression and multiple linear regression analyses were used to examine the correlation between independent and dependent variables in the study area. Multi-output regression is a series of independent linear regressions. There are three outputs and three inputs. The linear regression for the multioutput model coefficients and intercepts is given in the table below (
Table 8) and the parameters in
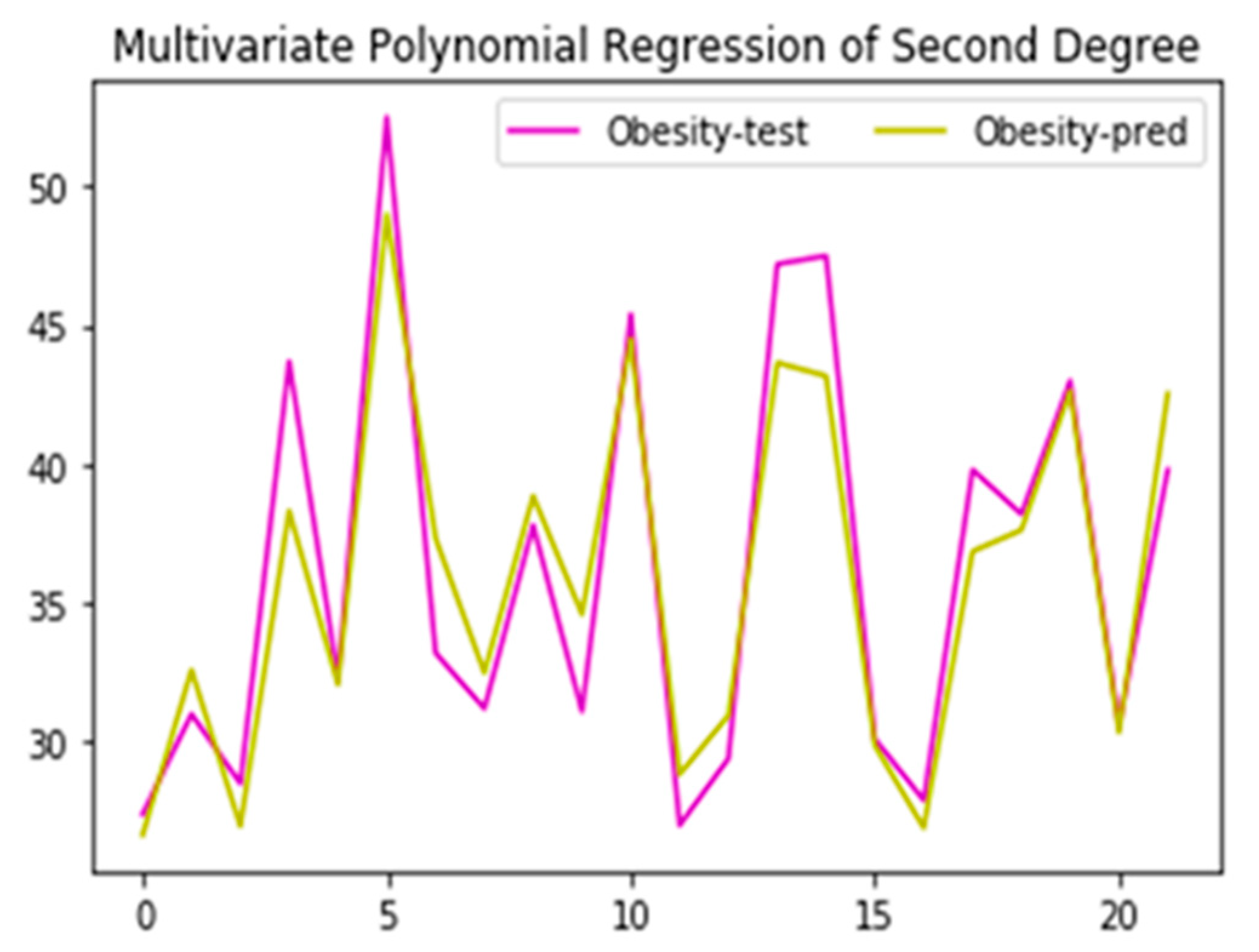
Table 3. We included different regression models for comparison and evaluated the model with the highest performance. In machine learning, it is not always straightforward that a better model will consistently give higher performances across all distributions of a data set.
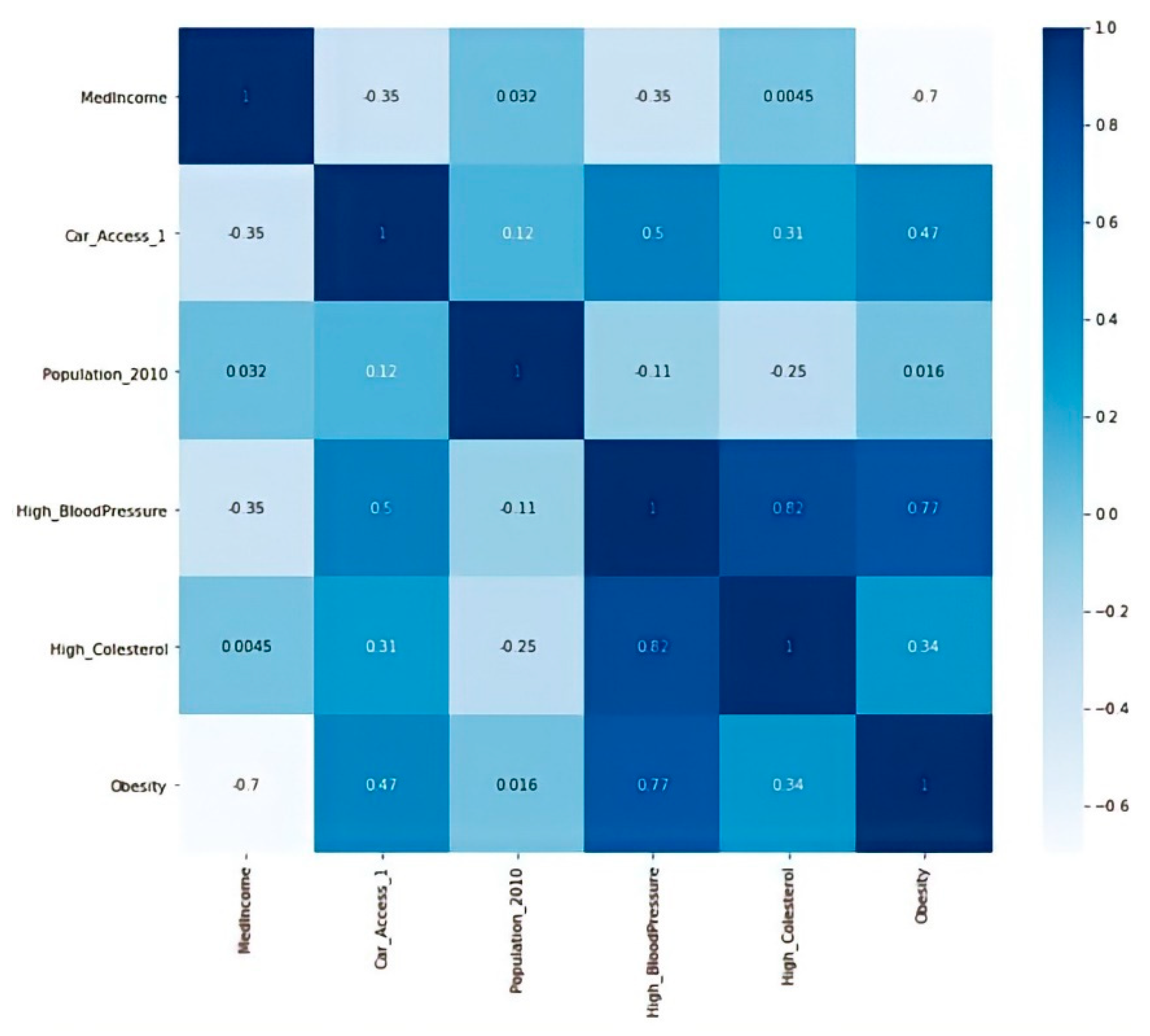
The obesity and high-cholesterol output variables showed high positive and negative correlations (R2 = 0.79 and −0.81), respectively, based on the independent variables of low car access, population, and median income. The obesity and high cholesterol variables were modeled using random forest and decision trees for the above performance. In contrast, the linear and nonlinear regression models could only help to predict the dependent variable obesity with an R2 value greater than 0.80.
The correlation matrix results illustrated a strong, negative relationship between income and obesity and a positive relationship between independent variables, high blood pressure, and high cholesterol. In addition, it presented the correlation between obesity and income. There was more of a correlation of the independent variable with obesity than between high blood pressure and high cholesterol.
Overall, our results suggested that when compared to food swamps and food oases, food deserts would be the most vulnerable and would probably experience the highest mortality rates in the case of health-related disasters. The presence of such food deserts challenges the sustainable community goals of city and county administrators and directs the need for development in these areas for better future planning.
Future studies may examine the long-term statistical association of food with respect to commercial and governmental policies implemented and its impact on people’s health and conditions. More specific future studies may investigate the low rate of health issues in food swamp areas. Moreover, future research may investigate the increase in health issues and potential cause(s) in various areas over time and recommend possible solutions.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}