1. Introduction
With the recent developments in technology, including Internet of Things, location tracking and location-based services such as networks and navigation are expanding indoors. To meet the high demand for vectorized indoor spatial information, studies on automatic floor plan analysis (i.e., automatically extracting indoor spatial information from floor plan images) have been recently proposed. Floor plans are a good source of indoor spatial information because they are easy to acquire and the automatic techniques based on floor plans are relatively affordable compared to other methods such as light detection and ranging (LiDAR) or manual digitalization [
1,
2,
3]. In fact, a recent study by Kim [
3] demonstrated that automatic floor plan analysis technology is more effective in terms of substitutability, completeness, supply, and demand than manual digitalization. Furthermore, there is a great demand for digitalized indoor information to obtain digital twins; however, there is a considerable portion of missing digitalized blueprints (e.g., CAD, BIM) in old buildings. Therefore, automatic floorplan analysis is attracting increased attention [
3].
Most existing studies on automatic floor plan analysis have focused on a simple format, which is appropriate for deep learning [
4]. The floor plans mostly used in previous studies are CVC (Computer Vision Center), Rakuten, and Rent 3D, whose floor plans are in a simplified format favorable for deep learning [
3,
4]. Some studies have investigated complicated floor plans, containing diverse fuzzy architectural drawings using EAIS (Electronic Architectural Information System) floor plans [
2,
4]; however, existing studies have mainly been conducted on house-scale buildings. Nevertheless, there is a high demand and expectation for indoor spatial information on large buildings, with a high probability and need for indoor navigation. For example, digital twins are required for smarter energy management across large-scale buildings [
5]. In addition, floor plan images in practice are not usually simplified for deep learning; they are complicated architectural drawings with various features. Therefore, considering the primary and practical purposes, it is necessary to consider large-scale and complicated floor plan images to extract indoor spatial information. This study aims to develop a deep learning-based automatic floor plan analysis framework suitable for large-scale and complex floor plans.
To be specific, this study utilizes a Convolution Neural Network (CNN). A CNN model has been mostly used in recent automatic floor plan analysis because it is a data-driven model having been shown to outperform other traditional models in image segmentation tasks. Instead, a CNN model requires uniform size of images as input data, causing a difficulty for varied size or high-resolution inputs, which are common in large-scale building floorplans. As our goal was to interpret floor plans of large-scale buildings, we needed to make the input image uniform, regardless of each floor plan scale. Therefore, we proposed dividing floor plans into several patches of regular size so that the framework could use the strength of CNN models while minimizing the weakness.
3. Materials and Methods
3.1. Materials: Data
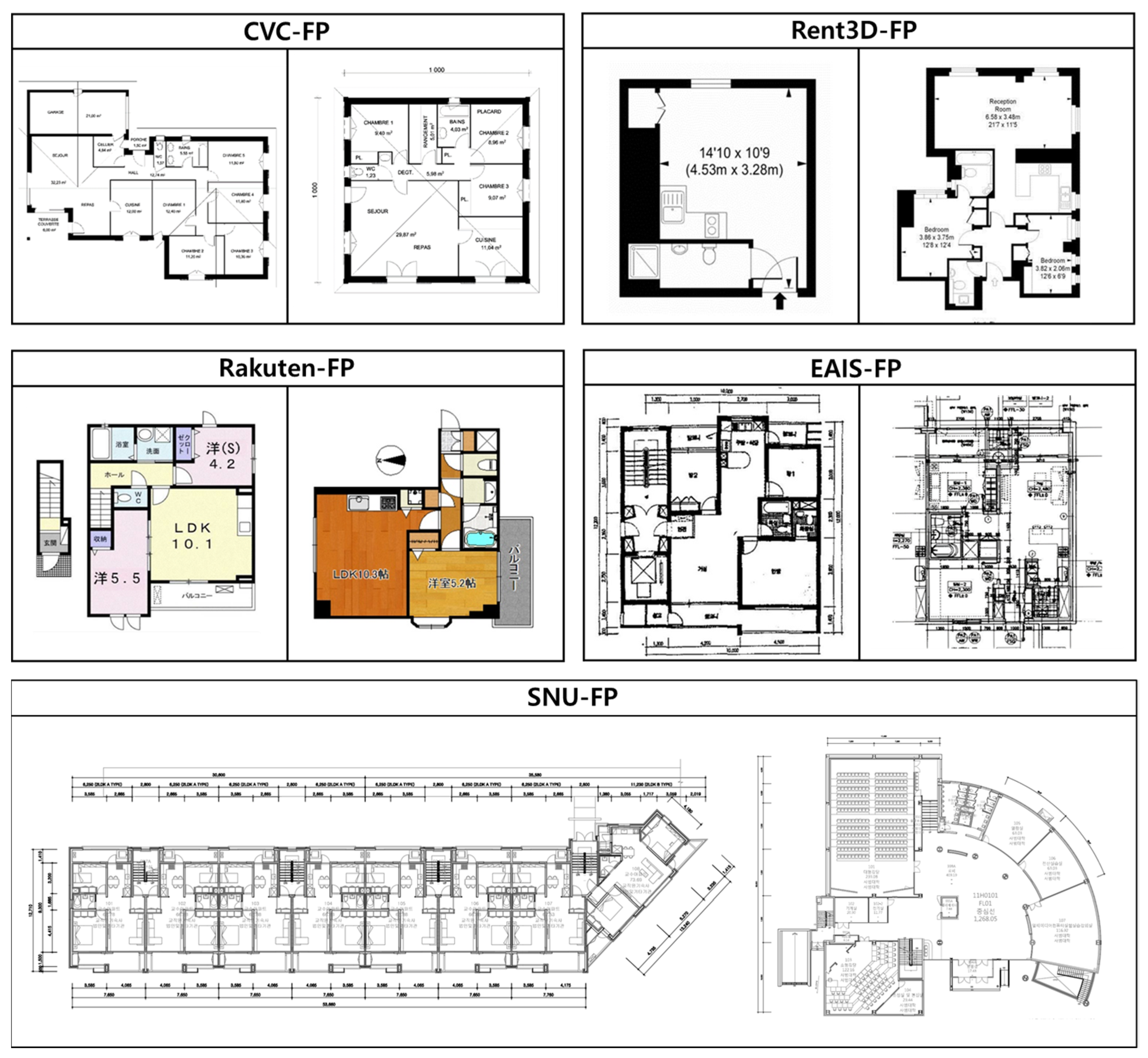
The data used in this study are scanned floor plan images of Seoul National University (SNU) buildings. The dataset was acquired from the Division of Facilities Management, SNU [
16]. The floor plans are diverse, complicated, and large. They have been drawn by various architectural designers/offices; the buildings were built over a long period, from the 1970s to the 2010s. In addition, the university complex contains various types of buildings; buildings with diagonal lines, curves, rectangular shapes, and pinwheels. The drawing style and symbols are varied, based on each architectural design office, and the floor plan contains numerical lines and symbols. In addition, it contains large public facilities, such as auditoriums, dormitories, libraries, and cafeteria buildings; at the same time, it includes drawings of large buildings and complex interior spaces compared to those used in previous research. In addition, it contains curved and diagonal walls. As the floor plan contains each floor of the building, there are many objects such as elevators and stairs that can represent interlayer connections. The images have a high resolution of more than 3000 pixels, and the proportion of the objects’ area relative to the total area in the drawing is expressed as much smaller than the existing drawings. In addition, as of April 2020, the number of SNU members is 41,426 [
17]. Library buildings have many users, including noncollege passengers. On average, four million people use the SNU library buildings in a year [
18]. The buildings covered in this study are more diverse and larger in scale than those used in previous studies, i.e., housing scale buildings. The datasets used for existing floor plan analysis and our SNU dataset can be seen in
Figure 1.
In this study, 230 SNU building floor plan image data were obtained, 200 of which were used for learning and 30 for testing. Additionally, to validate the capacity of the developed methodology for generalization to other datasets, we applied the University of Seoul (UOS) floor plan dataset to develop a patch-based deep learning framework. The indoor spatial information that is automatically extracted from the floor plan in this study has five classes: wall, door, window, stair room, and elevator. Walls and openings (doors and windows) are the fundamental indoor elements that can reconstruct indoor structures; hence, many previous studies used extracted walls and openings. In this study, we expanded the indoor elements to those that can connect floors, such as stair rooms and elevators, considering the shape of the completed building, rather than just a single floor. We manually annotated the floor plan dataset using LabelMe, which is a web-based annotation tool [
19]. All five classes are labeled as polygon-shaped, precisely portraying each building element, even if it contains a curved boundary.
3.2. Methodology
The overall framework can be divided into three phases: (1) normalized patch extraction, (2) patch-based floor plan recognition via deep networks, and (3) generation of indoor models. Conventional studies on automatic floor plan analysis rely on handcrafted features based on geometry. This methodology is useful for the extraction of simple objects, such as walls of a certain thickness with straight lines, and does not overlap with other graphics. However, this approach is limited in that it tends to specify a particular format of floor plan that cannot be generalized to other formats. In particular, when applied to large-scale complicated floor plans, this limitation is emphasized because the divergence in drawing scale is greater for large buildings than houses.
Theoretically, data-driven models with sufficient capacity to analyze complex geometric features can overcome the aforementioned limitations. However, training a model using a floor plan dataset to automatically extract indoor spatial information (e.g., walls and openings) is fundamentally challenging because the floor plan itself makes the learning process difficult. The majority of the space of floor plans is empty, but the gathering of sparse and simple geometric features such as lines and curves involves high-level information. This is challenging because of the principles of deep-learning methodology that extract and interpret images sequentially from low-level to high-level features. In particular, the scale range of floor plans for large spaces is varied, and it is computationally burdensome because the resolution is too high to apply commonly used algorithms in image processing. Furthermore, owing to the high complexity of the format, training and learning become more difficult. In particular, existing convolutional neural network (CNN) models are applicable to fixed square-sized images and have limitations in that they are unable to utilize high-resolution images owing to restrictions in computation. Because significant information is lost in the process of resizing a floor plan to a uniform size and an image of low resolution, deep learning models have been primarily developed for a particular type of drawing dataset with low resolution and a similar aspect ratio.
To address this limitation, we proposed a CNN-based framework designed for large-scale complex floor plans through patch-based learning, which uses varying scale floor plans divided into normalized patches (
Figure 2). By applying the normalized patch-to-floor plan analysis, it is possible to manage computational burden, diverse scale issues, and poor convergence on training deep networks.
3.2.1. Normalized Patch Extraction
To efficiently utilize the CNN model, high-quality learning data (i.e., data that are repeated in uniform patterns) are required. The goal of normalized patch extraction is to unify the actual distance expressed per pixel by unifying the floor plan scale. This enables consistent input delivery to the learning-based model, even with datasets containing diverse floor plan image sizes and diverse building scales. This process has a similar effect to that of normalizing data for training.
The total number of the patches can be calculated as in Equation (1). It is affected by a patch overlapping factor and the scale of the drawings as well as the total building area and the patch size.
where P is a set of patches, Ps is a patch size in the real world, α is an overlapping factor ranging from 0 to 1, κ is the scale of drawing.The first step of normalized patch extraction is to resize the image to match the scale of the floor plan and then to split it into appropriately sized patches. The appropriate size is determined to be as large as possible within the interpretable capacity, with sufficient performance for each patch with the model used for floor plan recognition. The patch size can be decided in a way of optimizing the segmentation performance. In general, a patch size shows a trade-off relationship with the segmentation performance; for example, a small patch size increases input image resolution, which is good, but decreases the field of view in the deep learning models, which results in a loss of capacity to look over neighboring objects. Considering this, we determined the appropriate patch size to the extent that the server’s memory for learning permits. In this study, a patch was set to be about the size of a square office (i.e., approximately 15 × 15 m2) which shows the best performance on SNU datasets and validates that this size works well in other datasets, such as UOS. Within our CPU (intel i5-4690, 8GB memory) and GPU (gtx 1080) specs, our proposed framework takes under 5 min even for the largest building in our dataset, which requires more than 225 patches.
Regarding auto detection of scale, we used two different methods: (1) utilizing information from dimension lines in floor plans, and (2) extracting and utilizing the pixel size of the thinnest wall if there is no dimension line (
Figure 3). If rich information exists in the floor plan itself, it is reasonable to use it. The floor plan is drawn proportional to the actual building, and its magnification is plotted using dimension lines. Through optical character recognition (OCR), the number of labels and corresponding pixel distance can be extracted, and, as a result, the distance per pixel (i.e., scale) can be calculated. The accuracy was improved by utilizing the median value of the scales measured in several numerical lines existing within a one-floor plan. Many floor plans have missing dimension lines for various reasons, for example, when the floor plan is not an architectural drawing (e.g., real estate floor plans and evacuation guide maps). It is important to be able to respond in this case (i.e., missing dimension lines) by generalizing our methodology. Buildings are generally geometrically structured; hence, it is not necessary to specify the thinnest walls in the floor plan. Histograms with data that count the consecutive pixel distances for each x- and y-axis were drawn; then, the pixel distance to be used as a scale criterion was specified by calculating the mode. To achieve robust results, non-maximum suppression was applied to the histogram prior to mode calculation. This process allows matching the scale on the input image of various floor plan sizes, even without dimension lines.
3.2.2. Patch-Based Floor Plan Recognition via Deep Networks
The normalized patch derived from
Section 3.2.1 is used as the input in the patch-based training of the data-driven model. Each floor plan handles a different number of patches for learning because the image pixel size of the matching floor plan is disparate. In general, the floor plan has an imbalanced distribution between object classes; a white background occupies most of the space, which adversely affects the training of the CNN model. The focal loss is used to reflect a larger value when updating the weight of the model inversely proportional to the area of each class included in the training dataset. For example, in the case of elevators which are fewer in number compared to other objects, the weight of the model changes significantly once it compensates for the small proportion. In addition, because walls directly affect the closure of indoor spaces if lost in the deep network model’s output, we gave more weight to the wall than to other object classes. We set the weighted loss for the wall class to increase the accuracy of the wall, which has the greatest influence on the intact indoor model generation among various objects. In addition, to prevent redundant learning and bias in the model, certain patches that account for more than 80% of the background are excluded from learning. In the inference phase, the normalized patches are generated from the test floor plan in the same manner, and the trained model yields the segmented patches, where each class is detected based on the pixel unit.
The segmented result of the floor plan is generated by stitching the results onto each patch, while reflecting the ensembled outputs in the overlapped areas. In Equation (2), a segmentation prediction of each patch is multiplied to a translation matrix that moves images with a relative coordinate of the corresponding patch. As a result, each predicted patch makes up the entire prediction of the floor plan. Each segmented patch from the learning is combined into one, and floor plan recognition can ultimately be completed. To mitigate discrepancies and adjust the boundary of the patches, a normalized patch is generated with more than 70% overlap. The inference outputs are ensembled and averaged when combining all the segmented patches.
where Tpi is a tranlation matrix for ith patch.Deep learning is used as a data-driven model for floor plan recognition. ResNET-50 [
20] was used as the skeleton network. It was modified to improve the performance of segmentation, increase the resolution of outputs, and sharpen boundaries between objects. A 512 × 512 input pixel size was also utilized instead of 224 × 224 in a direction that increases the resolution of the output. Compared to the previous model [
20], the stride was lowered, and the L1 error was used instead of the L2 error to obtain a high-resolution output with clear boundaries. The architecture of the generator and its modifications from the original ResNet-50 are shown in
Figure 4.
3.2.3. Generation of Indoor Models
The result of floorplan recognition is a raster data type with pixel-wise classification. It contains only approximate geometric information, which does not contain topology and semantic information as indoor spatial information. Therefore, processing is required to convert the floorplan recognition results into indoor models. As the first step in the conversion process, we converted the extracted raster data into vectorized objects represented by relative coordinates. Raster-to-vector conversion did not require complex algorithms, because complicated formats in the floor plan had already been analyzed/simplified through the deep learning model, and only simple forms of the geometry features remained. A simple algorithm based on the Hough transformation [
21] enabled us to generate vectorized objects with curves and straight lines. Objects that could be used as boundaries of rooms (e.g., walls, doors, windows) were represented by one-layer polylines, whereas objects that needed volume (e.g., stair room, elevators) were represented by polygons. For non-curved linear objects, post-processing was performed to comply with the Manhattan-rule, which averages the coordinates of the connected objects. Consequently, topology information for the indoor models was generated. In addition, a model that detects closed space (i.e., walls, windows, and doors) and creates space to separate buildings by space was developed. Stair rooms and elevators were stored as linked objects in each space, in addition to geometric information. To prevent the deep learning models from losing topology information due to missing objects, postprocessing, which connects the close gaps between walls and objects and adds virtual wall objects, was performed; the room space was subsequently divided. There was a possibility that the door may have not been detected or combined (e.g., when the door does not exist); however, the topology information retains minimum information loss because the space is divided into open boundaries (penetrating space) by virtual walls.
4. Results
The results of the deep learning segmentation and the generated indoor model are shown in
Table 1. As can be seen in the table, the input image of the SNU floor plan has diverse features. It has various scales and shapes, and some of the floor plans contain diagonal and curved walls that were not usually explored in previous studies. The result of patch-based deep learning segmentation shows clear recognition, which is sufficient for generating indoor models. Indoor models are vectorized indoor spatial information that can be used to reconstruct 2D or 3D indoor structures. The results of the indoor model (in
Table 1, line vector) show that the floor plan’s pattern is sufficiently implemented and completed as a supplement to the deep learning segmentation result.
The test images were newly selected in this study because no existing studies used test sets for SNU data. To train the 230 images in the datasets, we split the SNU data into 200 images for training and 30 images for testing while maintaining diverse building types. The precision and recall of the deep learning results were approximately 89% and 86%, respectively, showing a similar performance to recent related studies (see
Table 2). Notably, the performance for the window was relatively low because wall and window objects in the SNU dataset are hardly distinguishable and missing windows are usually detected as a wall, which means it does not significantly affect the room division when generating the indoor model. However, stairs show an irregular and unrepeating pattern, thus yielding a low recall value in pixel-based evaluation. For automatic floor plan analysis, good performance in segmentation tasks cannot guarantee good performance on vector (indoor model) results [
4]. The deep learning segmentation result is a mediated product for indoor models [
4]; therefore, it is necessary to evaluate the indoor model itself.
Generally, the evaluation of indoor models for automatic floor plan analysis is conducted through either a wall segmentation task or a room-detection task [
22]. Because our goal was to reconstruct indoor structures, we selected the room-detection task as an evaluation process. The evaluation protocol for the room-detection task resulted in a detection rate (DR) and recognition accuracy (RA) based on the match score table [
23], which was characterized by reflecting the exact one-to-one matches as well as the partial one-to-many and many-to-one matches based on vector evaluation. In particular, we utilized the same metric for evaluating the floor plan analysis from previous studies [
4,
9]. When calculating the match-scores of the predicted room and ground truth, the acceptance and rejection thresholds used to determine whether each pair matched were 0.5 and 0.05, respectively. In addition, an evaluation of the walls was replaced with an evaluation of the closed space implemented through the walls (i.e., room) because the evaluation of a single wall is less relevant to the reproduction performance of the entire structure.
Table 3 shows an evaluation of the room-detection task for our proposed method using the SNU_FP data. The proposed model resulted in an 89% detection rate and 86% recognition accuracy, and overall, it exhibited a slightly higher performance except for the door object compared to the pixel-based assessment shown in
Table 2. This is because our framework complements the deep learning results while generating the final indoor model. For example, the stair room shows a relatively low score on the pixel-based evaluation, but a higher score on the vector evaluation. This is due to the model successfully identifying most of the stairs, despite failing to detect a precise boundary.
The main purpose of extracting indoor spatial information in vector form from floor plan images is to reconstruct indoor building structures. To show the application of our result in a compatible way, we converted our indoor models into Java OpenStreetMap Editor plugins [
24], and IndoorGML (OGC standard for an open data model and XML schema for indoor spatial information) [
25], which have the potential to be compatible with 3D modeling programs such as Sketchup, BIM, and Open Street Map (see
Figure 5). In addition, it can be integrated adaptively with other standards such as CityGML [
26], making the 3D indoor models compatibly expanding to the surrounded outdoor city models, beyond the building level.
The 3D indoor models can be used for a variety of purposes, such as the creation of digital twins for smart cities or the development of real estate information services. Our findings can also be combined with existing researches regarding the indoor navigation supporting system in the land administration domain model [
27] or the localization and positioning aspect considering partitioning in indoor spaces [
28]. In particular, since our framework enabled automatic extract of indoor spatial information in vector format on a large-scale complex building, the application aspect of indoor navigation would be more emphasized in cooperation with such researches such as human navigation usage in 3D indoor construction [
29,
30], the indoor navigation system for emergency evacuation [
31,
32,
33], and so on.
6. Conclusions
The demand for indoor spatial information is increasing, and automatic floor plan analysis is gaining more attention as an affordable means of acquiring indoor spatial information [
2,
3,
4]. In this context, this study presents a patch-based deep learning network and a framework for reconstructing indoor space for more complex and large-scale buildings as compared to previous studies. We utilized a CNN to overcome its limitation on interpreting varied size or high-resolution inputs, commonly found in floor plans of large-scale buildings. As input data, SNU dataset (200 for learning, 30 for testing) was used, which contains various types of data drawn by various architectural offices from the 1970s to the 2010s, containing large-scale buildings with diagonal lines, curves, rectangular shapes, and pinwheels. The floor plan images of the SNU dataset have a high resolution of more than 3000 pixels. To unify the actual distance expressed per pixel by unifying the floor plan scale, we normalized the patch consistent input delivery to the learning-based model, even with datasets containing diverse sizes and scales. The segmented result of the floor plan was generated by stitching the results on each patch, while reflecting the ensembled outputs in the overlapped areas. After raster to vector conversion, the indoor model of walls, windows, rooms, stair rooms, and elevators was generated. The performance showed detection rate (87.77%) and recognition accuracy (85.53%), similar to that of existing studies that used a relatively unified and organized format with a regular scale.
The main implications of our work can be summarized into three aspects. First, this study enabled the automatic extraction of indoor elements from complicated and variously scaled floor plan images with high performance. The fundamental purpose of reconstructing indoor structures is to interpret or navigate large-scale complex buildings rather than simple housing scales. Second, this study extracted indoor elements not only for reconstructing the interior space geometry, but also for connectivity with other floors. Unlike existing studies, this study extracted stair rooms and elevators to connect with other stories. This can facilitate automatic floor plan analysis to reconstruct the indoor space in a floor as well as a whole building. Third, this study enabled the reconstruction of indoor space and converted it to a standard format that can be utilized for other purposes. Based on the results of our generated indoor models, it is possible to construct 3D-based indoor models such as JOSM-based indoor models or IndoorGML. These are open-source-based indoor formats; hence, it is possible to utilize the results depending on the subjects.
This study has limitations in that it can only train the SNU dataset as a sample for complex and large-scale buildings due to the difficulty in securing data. However, if large-scale and navigable buildings such as multiplex shopping malls can be included, our proposed framework can be trained into a more reliable model. In future research, we plan to further extract and assemble the topology information of the buildings, given that our proposed framework includes an expandable indoor model. Nevertheless, this study is significant in that it expands the practical aspect of automatic floor plan analysis as it covers large-scale floor plans that have been excluded from previous research. This study enables the recognition of floor plan datasets for large-scale buildings in complex and diverse formats, which extends the application of automatic floor plan analysis technology.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















