
Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos



Abstract
:1. Introduction
2. Literature Review
3. Methods
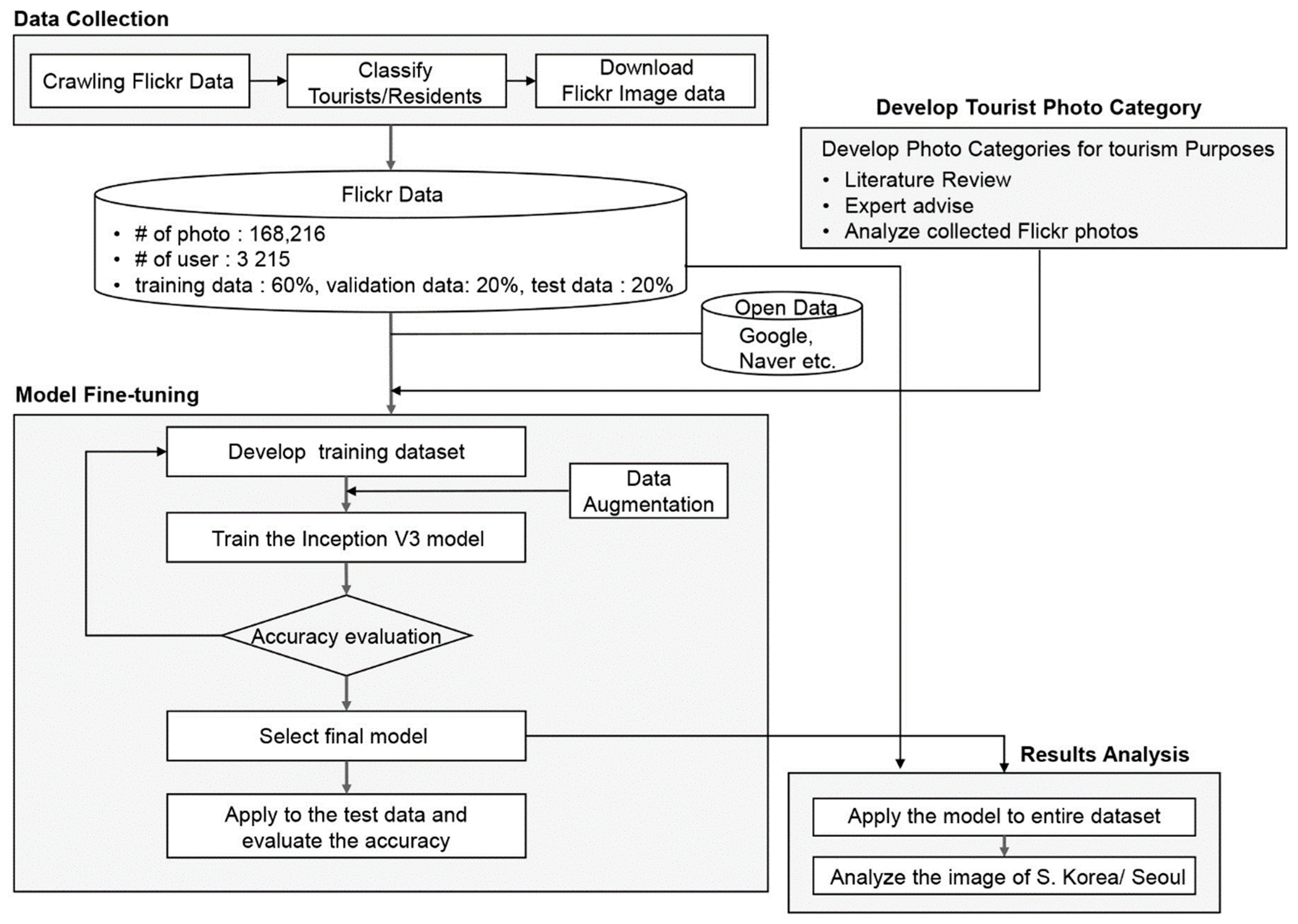
3.1. Research Process
3.2. Data Collection and Tourist Identification
3.3. Classification of Tourists’ Photos
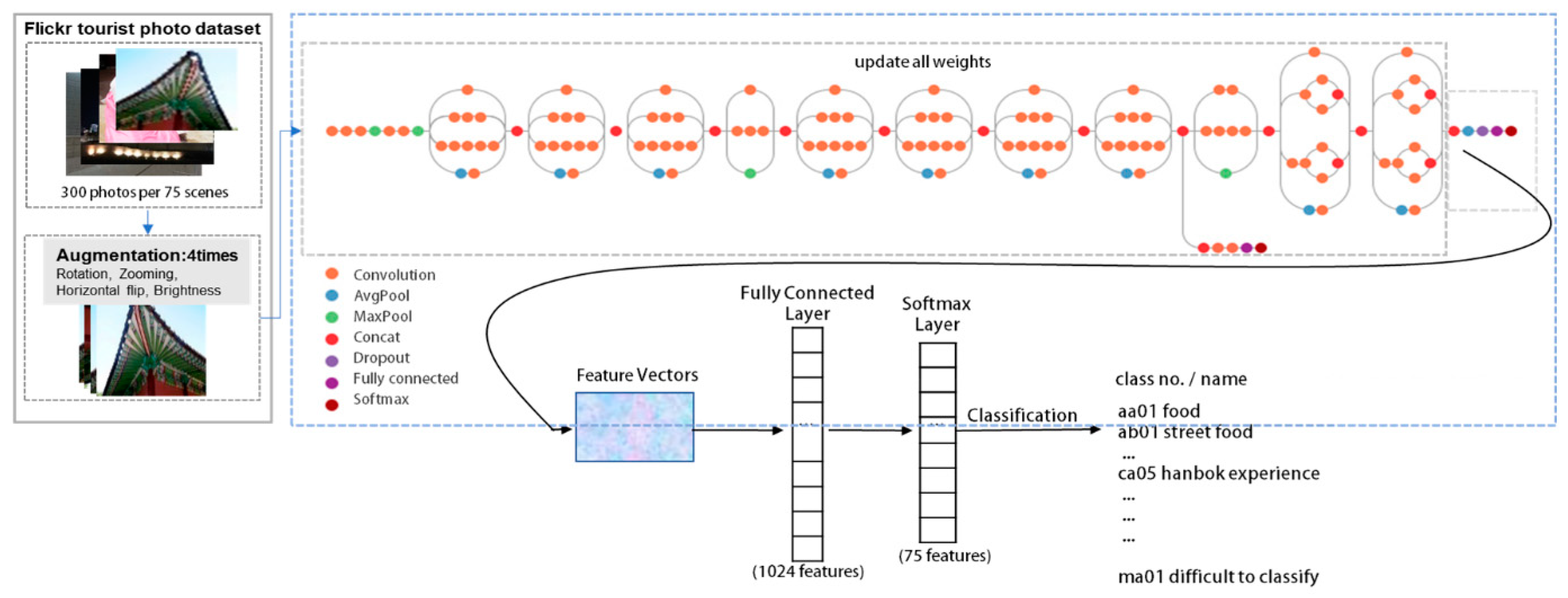
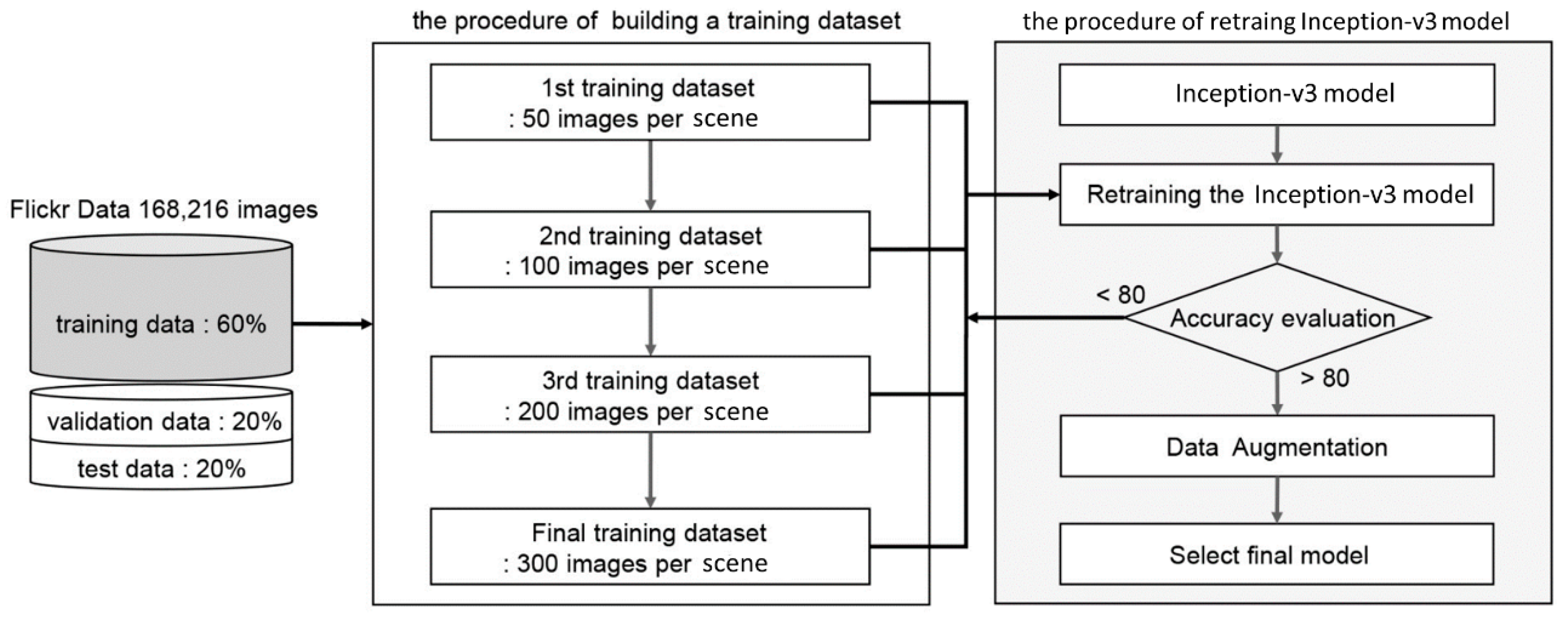
3.4. Training a Deep Learning Model for Classifying Tourists’ Photos
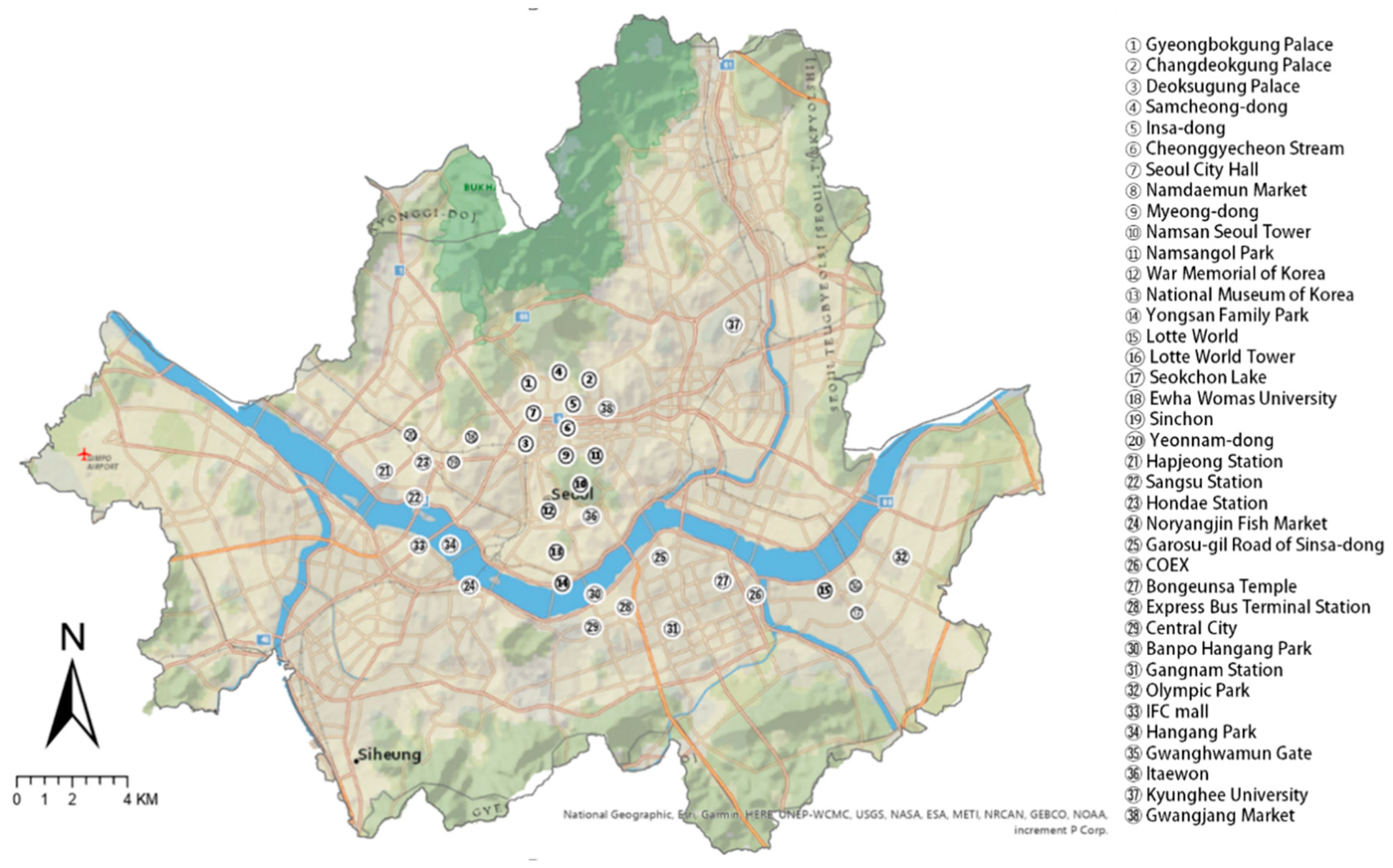
3.5. Spatial Analysis of Tourists’ Photos
4. Experiments and Results
4.1. Setup
4.2. Transfer Learning of Inception-v3 Model
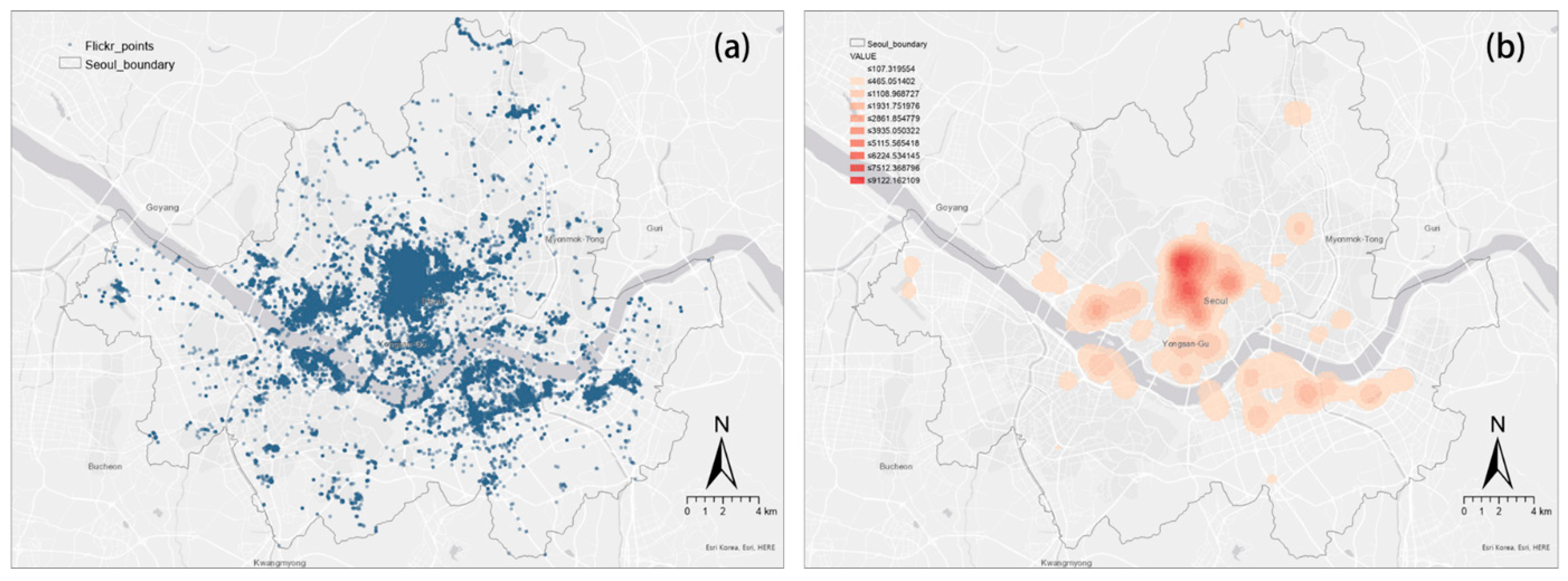
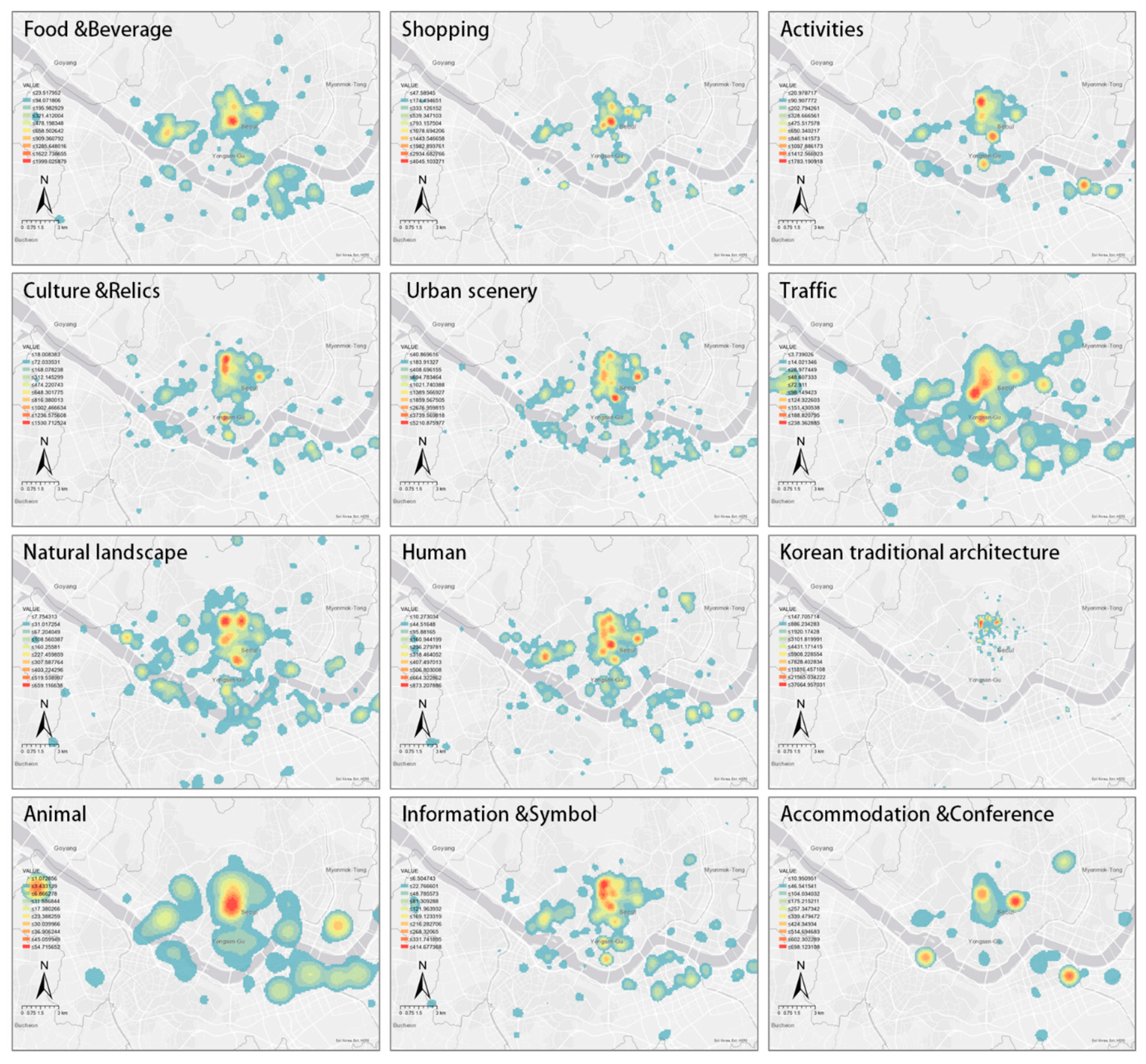
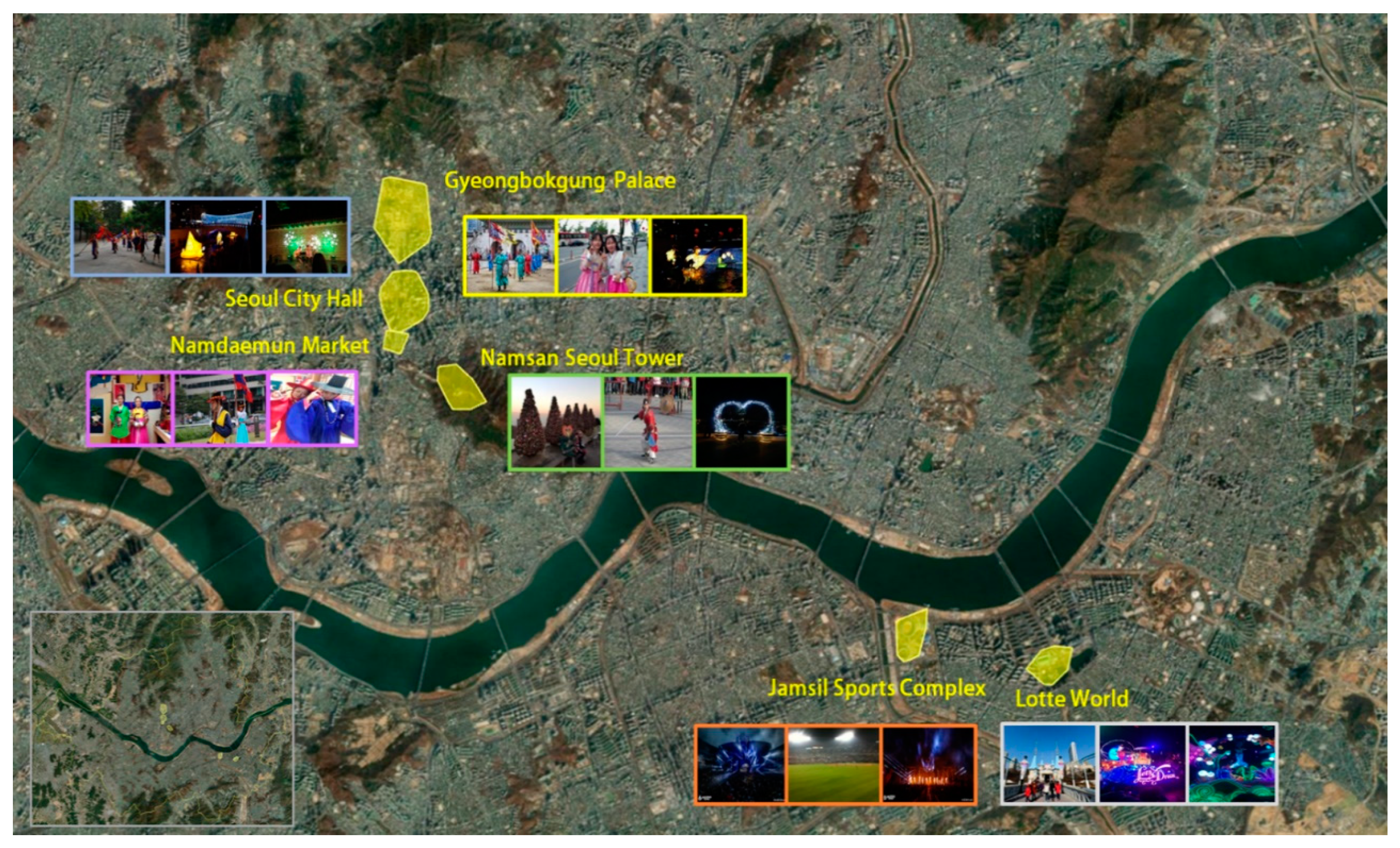
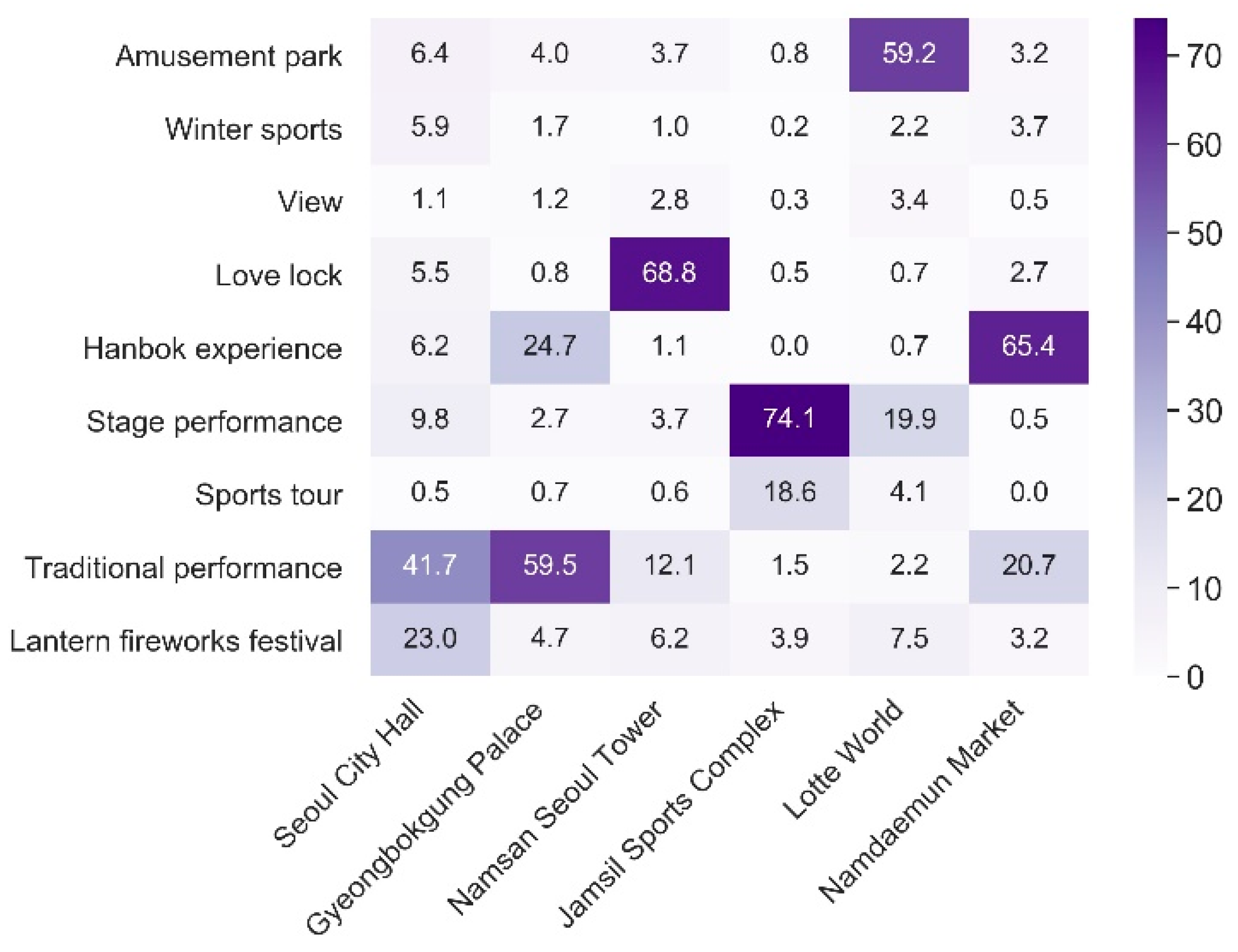
4.3. Spatial Analysis of Tourists’ Photos
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Parra-López, E.; Bulchand-Gidumal, J.; Gutiérrez-Taño, D.; Díaz-Armas, R. Intentions to use social media in organizing and taking vacation trips. Comput. Hum. Behav. 2011, 27, 640–654. [Google Scholar] [CrossRef]
- Deng, N.; Li, X.R. Feeling a destination through the “right” photos: A machine learning model for DMOs’ photo selection. Tour. Manag. 2018, 65, 267–278. [Google Scholar] [CrossRef]
- Hunter, W.C. The social construction of tourism online destination image: A comparative semiotic analysis of the visual representation of Seoul. Tour. Manag. 2016, 54, 221–229. [Google Scholar] [CrossRef]
- Kádár, B. Measuring tourist activities in cities using geotagged photography. Tour. Geogr. 2014, 16, 88–104. [Google Scholar] [CrossRef]
- García-Palomares, J.C.; Gutiérrez, J.; Mínguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Kisilevich, S.; Keim, D.; Andrienko, N.; Andrienko, G. Towards acquisition of semantics of places and events by multi-perspective analysis of geotagged photo collections. In Geospatial Visualisation; Moore, A., Drecki, I., Eds.; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2012; pp. 211–233. [Google Scholar]
- Rattenbury, T.; Naaman, M. Methods for extracting place semantics from Flickr tags. ACM Trans. Web 2009, 3, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Park, Y.; Kang, Y.; Kim, D.; Lee, J.; Kim, N. Analysis of Seoul Image of Foreign Tourists Visiting Seoul by Text Mining with Flickr Data. J. Korean Soc. for GIS 2019, 27, 11–23. [Google Scholar]
- Kurashima, T.; Iwata, T.; Irie, G.; Fujimura, K. Travel route recommendation using geotagged photos. Knowl. Inf. Syst. 2013, 37, 37–60. [Google Scholar] [CrossRef]
- Parikh, V.; Keskar, M.; Dharia, D.; Gotmare, P. A Tourist Place Recommendation and Recognition System. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 218–222. [Google Scholar]
- Zhang, J.D.; Chow, C.Y. GeoSoCa: Exploiting geographical, social and categorical correlations for point-of-interest recommendations. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 443–452. [Google Scholar]
- Pan, S.; Lee, J.; Tsai, H. Travel photos: Motivations, image dimensions, and affective qualities of places. Tour. Manag. 2014, 40, 59–69. [Google Scholar] [CrossRef]
- Donaire, J.A.; Camprubí, R.; Galí, N. Tourist clusters from Flickr travel photography. Tour. Manag. Perspect. 2014, 11, 26–33. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Chen, Y.; Li, C. Discovering the tourists’ behaviors and perceptions in a tourism destination by analyzing photos’ visual content with a computer deep learning model: The case of Beijing. Tour. Manag. 2019, 75, 595–608. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–8 December 2012; pp. 1106–1114. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hussain, M.; Bird, J.J.; Faria, D.R. A study on cnn transfer learning for image classification. In Proceedings of the 18th UK Workshop on Computational Intelligence, Nottingham, UK, 5–7 September 2018; pp. 191–202. [Google Scholar]
- Zhang, K.; Chen, D.; Li, C. How are tourists different?—Reading geo-tagged photos through a deep learning model. J. Qual. Assur. Hosp. Tour. 2020, 21, 234–243. [Google Scholar] [CrossRef]
- Payntar, N.D.; Hsiao, W.L.; Covey, R.A.; Grauman, K. Learning patterns of tourist movement and photography from geotagged photos at archaeological heritage sites in Cuzco, Peru. Tour. Manag. 2020, 82, 104165. [Google Scholar] [CrossRef]
- Kim, D.; Kang, Y.; Park, Y.; Kim, N.; Lee, J. Understanding tourists’ urban images with geotagged photos using convolutional neural networks. Spat. Inf. Res. 2020, 28, 241–255. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image captioning: Transforming objects into words. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 11137–11147. [Google Scholar]
- Wu, B.; Chen, W.; Fan, Y.; Zhang, Y.; Hou, J.; Liu, J.; Zhang, T. Tencent ml-images: A large-scale multi-label image database for visual representation learning. IEEE Access 2019, 7, 172683–172693. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Wang, Y.; Li, Y. A survey on deep learning-driven remote sensing image scene understanding: Scene classification, scene retrieval and scene-guided object detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef] [Green Version]
- Dubey, A.; Naik, N.; Parikh, D.; Raskar, R.; Hidalgo, C.A. Deep learning the city: Quantifying urban perception at a global scale. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 196–212. [Google Scholar]
- Koylu, C.; Zhao, C.; Shao, W. Deep neural networks and kernel density estimation for detecting human activity patterns from Geo-tagged images: A case study of birdwatching on Flickr. ISPRS Int. J. Geo-Inf. 2019, 8, 45. [Google Scholar] [CrossRef] [Green Version]
- Yin, L.; Cheng, Q.; Wang, Z.; Shao, Z. ‘Big data’for pedestrian volume: Exploring the use of Google Street View images for pedestrian counts. Appl. Geogr. 2015, 63, 337–345. [Google Scholar] [CrossRef]
- Saikia, S.; Fidalgo, E.; Alegre, E.; Fernández-Robles, L. Object detection for crime scene evidence analysis using deep learning. In Proceedings of the 19th International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; pp. 14–24. [Google Scholar]
- Zhang, F.; Zhang, D.; Liu, Y.; Lin, H. Representing place locales using scene elements. Comput. Environ. Urban Syst. 2018, 71, 153–164. [Google Scholar] [CrossRef]
- Xing, H.; Meng, Y.; Wang, Z.; Fan, K.; Hou, D. Exploring geo-tagged photos for land cover validation with deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 141, 237–251. [Google Scholar] [CrossRef]
- Richards, D.R.; Tunçer, B. Using image recognition to automate assessment of cultural ecosystem services from social media photographs. Ecosyst. Serv. 2018, 31, 318–325. [Google Scholar] [CrossRef]
- Chen, M.; Arribas-Bel, D.; Singleton, A. Quantifying the Characteristics of the Local Urban Environment through Geotagged Flickr Photographs and Image Recognition. ISPRS Int. J. Geo-Inf. 2020, 9, 264. [Google Scholar] [CrossRef] [Green Version]
- Seresinhe, C.I.; Preis, T.; Moat, H.S. Using deep learning to quantify the beauty of outdoor places. Royal Soc. Open Sci. 2017, 4, 170170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porzi, L.; Rota Bulò, S.; Lepri, B.; Ricci, E. Predicting and understanding urban perception with convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 139–148. [Google Scholar]
- Liu, L.; Wang, H.; Wu, C. A machine learning method for the large-scale evaluation of urban visual environment. arXiv 2016, arXiv:1608.03396. [Google Scholar]
- Ilic, L.; Sawada, M.; Zarzelli, A. Deep mapping gentrification in a large Canadian city using deep learning and Google Street View. PLoS ONE 2019, 14, e0212814. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Q.; Cui, C.; Shi, C.; Song, G.; Han, X.; Yin, Y. Visual Urban Perception with Deep Semantic-Aware Network. In Proceedings of the 25th International Conference on MultiMedia Modeling, Thessaloniki, Greece, 8–11 January 2019; pp. 28–40. [Google Scholar]
- Zhang, F.; Zhou, B.; Liu, L.; Liu, Y.; Fung, H.H.; Lin, H.; Ratti, C. Measuring human perceptions of a large-scale urban region using machine learning. Landsc. Urban. Plan. 2018, 180, 148–160. [Google Scholar] [CrossRef]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Law, S.; Shen, Y.; Seresinhe, C. An application of convolutional neural network in street image classification: The case study of London. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, Redondo Beach, CA, USA, 7–10 November 2017; pp. 5–9. [Google Scholar]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, Y.; Cho, N.; Lee, J.; Yoon, J.; Lee, H. Comparison of Tourists Classification Methods of Geotagged Photos: Empirical Models and Machine Learning Approaches. J. Korean Soc. for GIS 2019, 27, 29–37. [Google Scholar] [CrossRef]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
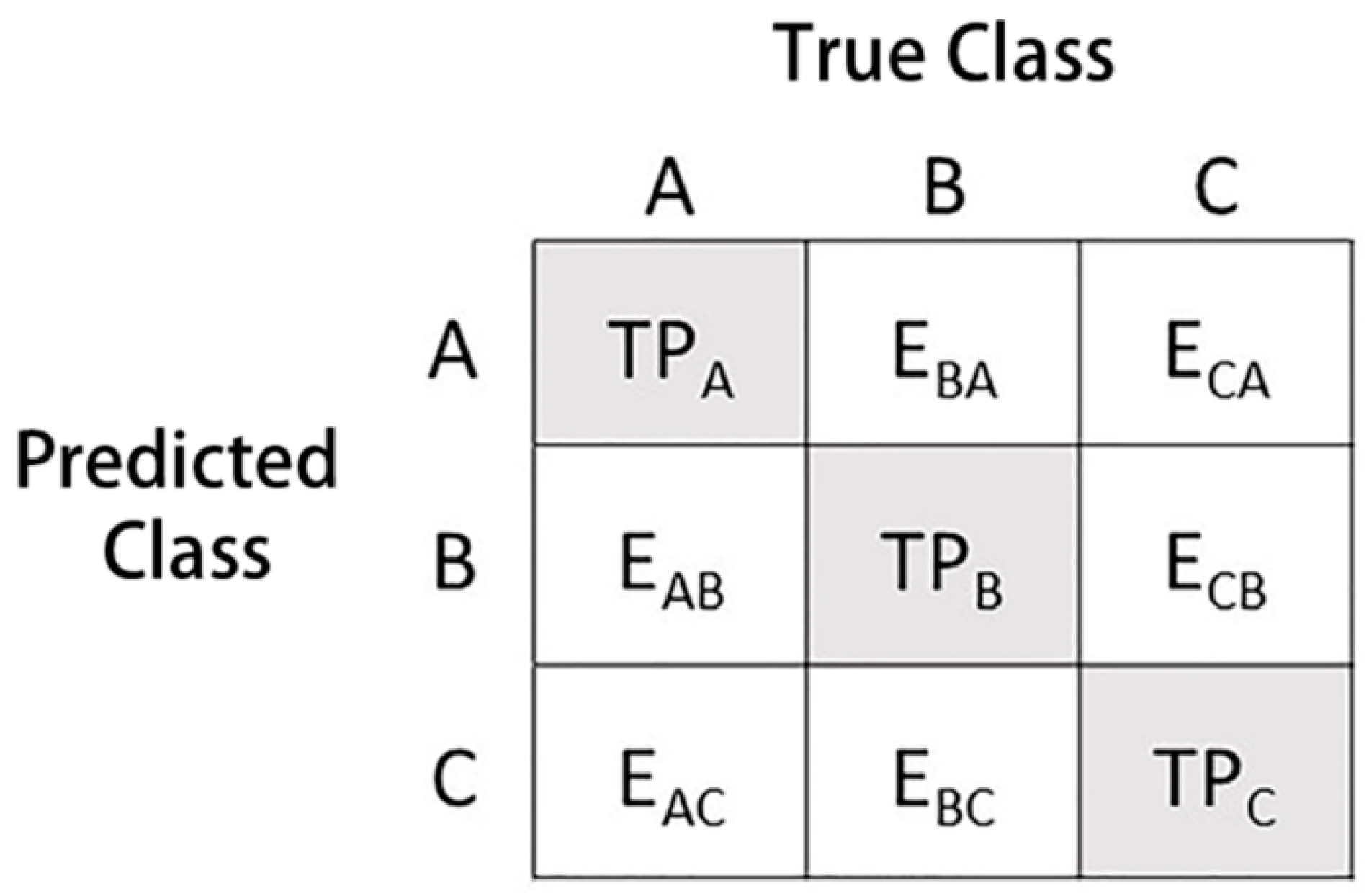
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 1–13. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Quantitative Geography: Perspectives on Spatial Data Analysis; Sage: London, UK, 2000. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Triguero, I.; García, S.; Herrera, F. Self-labeled techniques for semi-supervised learning: Taxonomy, software and empirical study. Knowl. Inf. Syst. 2015, 42, 245–284. [Google Scholar] [CrossRef]
- Gu, Y.; Leroy, G. Mechanisms for Automatic Training Data Labeling for Machine Learning. In Proceedings of the 40th International Conference on Information Systems, ICIS 2019, Munich, Germany, 15–18 December 2019. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
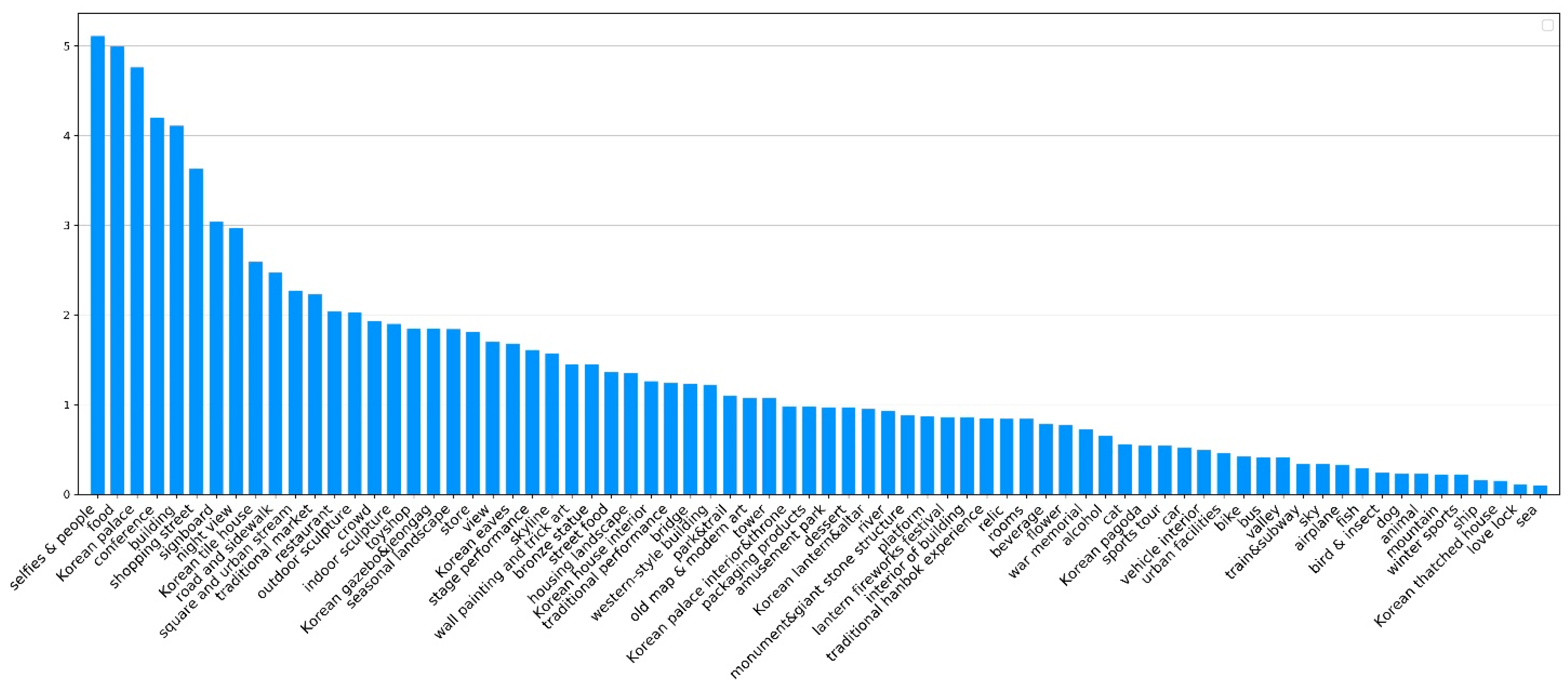
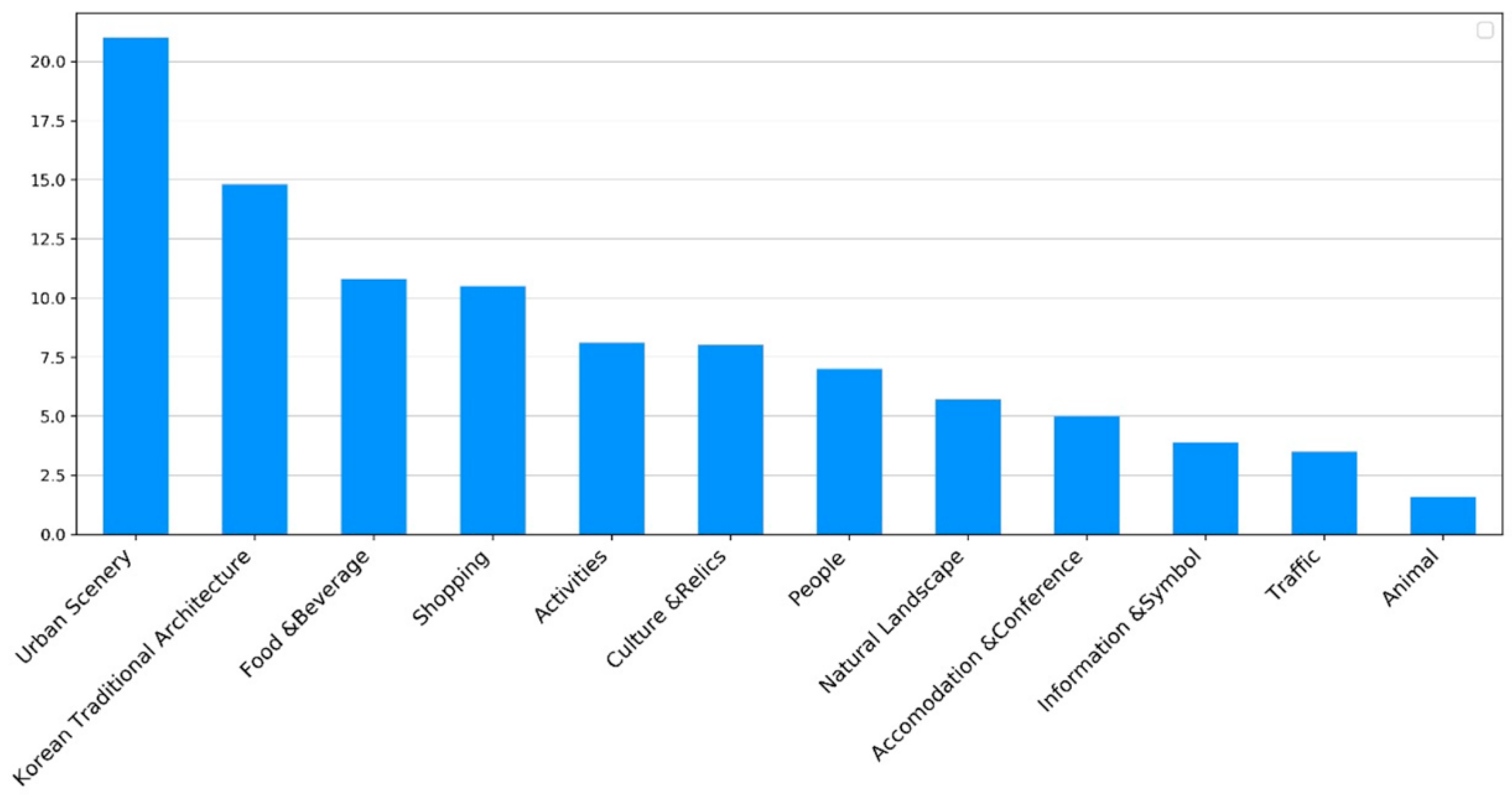
| Category | Scene |
|---|---|
| Food and Beverage | food *, street food **, dessert, beverage, alcohol *, restaurant * |
| Shopping | traditional market **, shopping street *, store, toyshop, packaging products * |
| Activities | amusement park **, winter sports *, view *, love lock **, hanbok experience **, stage performance *, sports tour *, traditional performance **, lantern fireworks festival ** |
| Culture and Relics | war memorial **, relic **, old map and modern art **, indoor sculpture, outdoor sculpture, bronze statue |
| Urban scenery | building, interior of building, housing landscape **, skyline *, mural and trick art *, western-style building, road and sidewalk, bridge, square and urban stream, tower, night view **, urban facilities |
| Traffic | car, bus, train and subway, platform, airplane, bike, ship, vehicle interior |
| Natural landscape | sky, mountain, valley, river, sea, flower, park and trail, seasonal landscape * |
| People | selfies and people, crowd |
| Korean traditional architecture | palace **, palace interior and throne **, gazebo and jeongja **, tile house **, thatched house **, house interior **, eaves **, pagoda **, lantern and altar ** |
| Animal | dog, cat, animal, fish, bird and insect |
| Information and Symbol | signboard, monument |
| Accommodation and Conference | rooms, conference |
| Others | difficult to classify |
| Training Dataset | 1st | 2nd | 3rd-1 | 3rd-2 | 4th |
|---|---|---|---|---|---|
| No. of scenes | 91 | 76 | 79 | 75 | 75 |
| No. of photos per scene | 50 | 100 | 200 | 200 | 300 |
| accuracy | 66.99% | 70.39% | 79.53% | 84.23% | 84.23% |
| Case | Data Augmentation | Number of Photos | Learning Rate | Step | Batch Size | Accuracy |
|---|---|---|---|---|---|---|
| 1 | Not applied | 22,384 | 0.0001 | 10,000 | 128 | 0.855 |
| 2 | 2 times | 44,433 | 0.0001 | 15,000 | 128 | 0.888 |
| 3 | 3 times | 65,824 | 0.0001 | 20,000 | 128 | 0.907 |
| 4 | 4 times | 86,693 | 0.0001 | 25,000 | 128 | 0.919 |
| 5 | 5 times | 106,541 | 0.0001 | 30,000 | 128 | 0.921 |
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | |
|---|---|---|---|---|---|
| Top 1 accuracy | 73.51% | 72.45% | 72.78% | 72.99% | 72.73% |
| Top 5 accuracy | 91.82% | 92.00% | 91.96% | 92.07% | 92.00% |
| Recall | 0.7489 | 0.7613 | 0.7610 | 0.7607 | 0.7631 |
| Precision | 0.6858 | 0.6957 | 0.7000 | 0.7036 | 0.7015 |
| F1-score | 0.7159 | 0.7270 | 0.7292 | 0.731025 | 0.731021 |
| Training | Validation | Test | |
|---|---|---|---|
| Top 1 accuracy | 91.9% | 79.58% | 85.77% |
| Top 5 accuracy | - | 92.66% | 95.69% |
| F1-score | - | 0.7946 | 0.8485 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Y.; Cho, N.; Yoon, J.; Park, S.; Kim, J. Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos. ISPRS Int. J. Geo-Inf. 2021, 10, 137. https://doi.org/10.3390/ijgi10030137
Kang Y, Cho N, Yoon J, Park S, Kim J. Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos. ISPRS International Journal of Geo-Information. 2021; 10(3):137. https://doi.org/10.3390/ijgi10030137
Chicago/Turabian StyleKang, Youngok, Nahye Cho, Jiyoung Yoon, Soyeon Park, and Jiyeon Kim. 2021. "Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos" ISPRS International Journal of Geo-Information 10, no. 3: 137. https://doi.org/10.3390/ijgi10030137
APA StyleKang, Y., Cho, N., Yoon, J., Park, S., & Kim, J. (2021). Transfer Learning of a Deep Learning Model for Exploring Tourists’ Urban Image Using Geotagged Photos. ISPRS International Journal of Geo-Information, 10(3), 137. https://doi.org/10.3390/ijgi10030137