
Language Modeling on Location-Based Social Networks


Abstract
:1. Introduction
- 1.
- Propose a spatio-temporal conditioned neural language model architecture that represents time and space at different granularities and captures the sequential structure of texts. By modeling time and space at different granularities, the proposed architecture is adaptable to the specific characteristics of each data source. This has proven to be paramount according to our experiments over two LBSN datasets.
- 2.
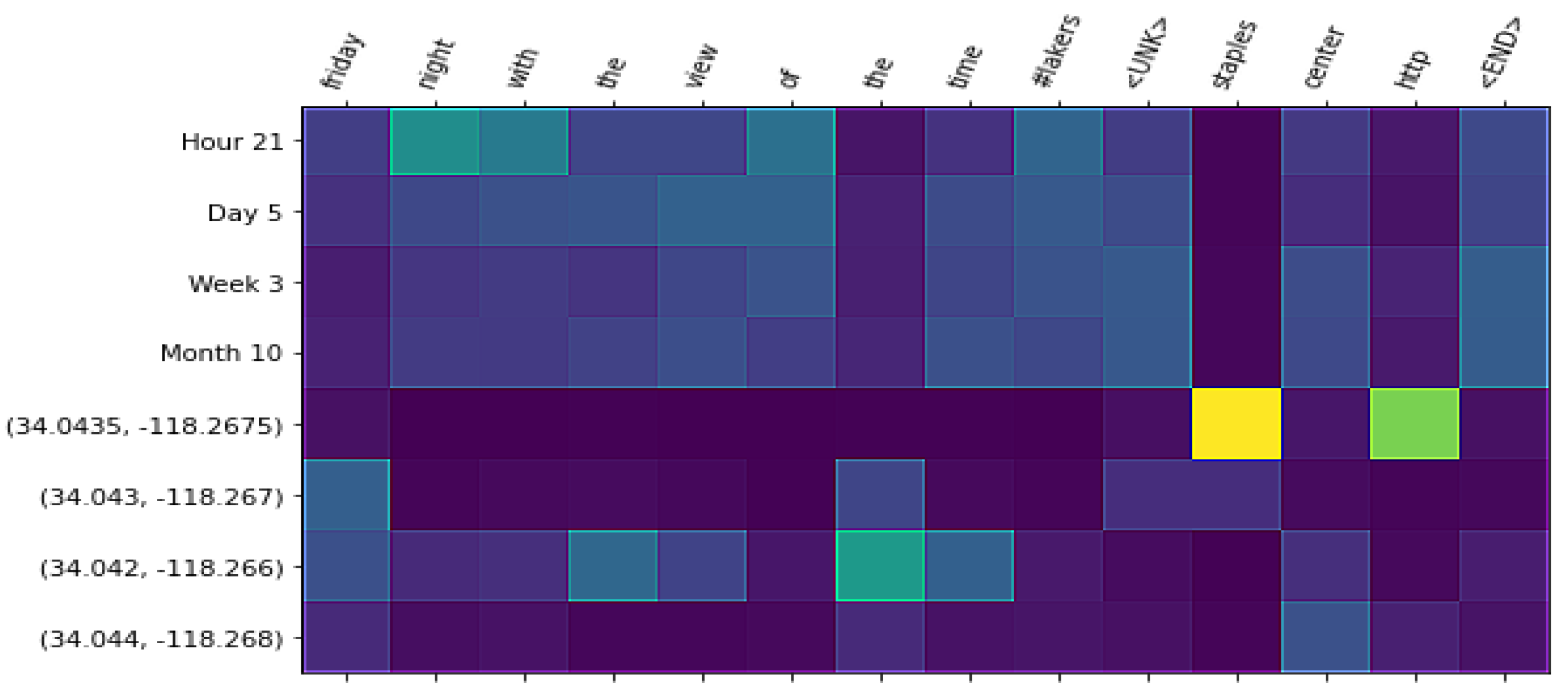
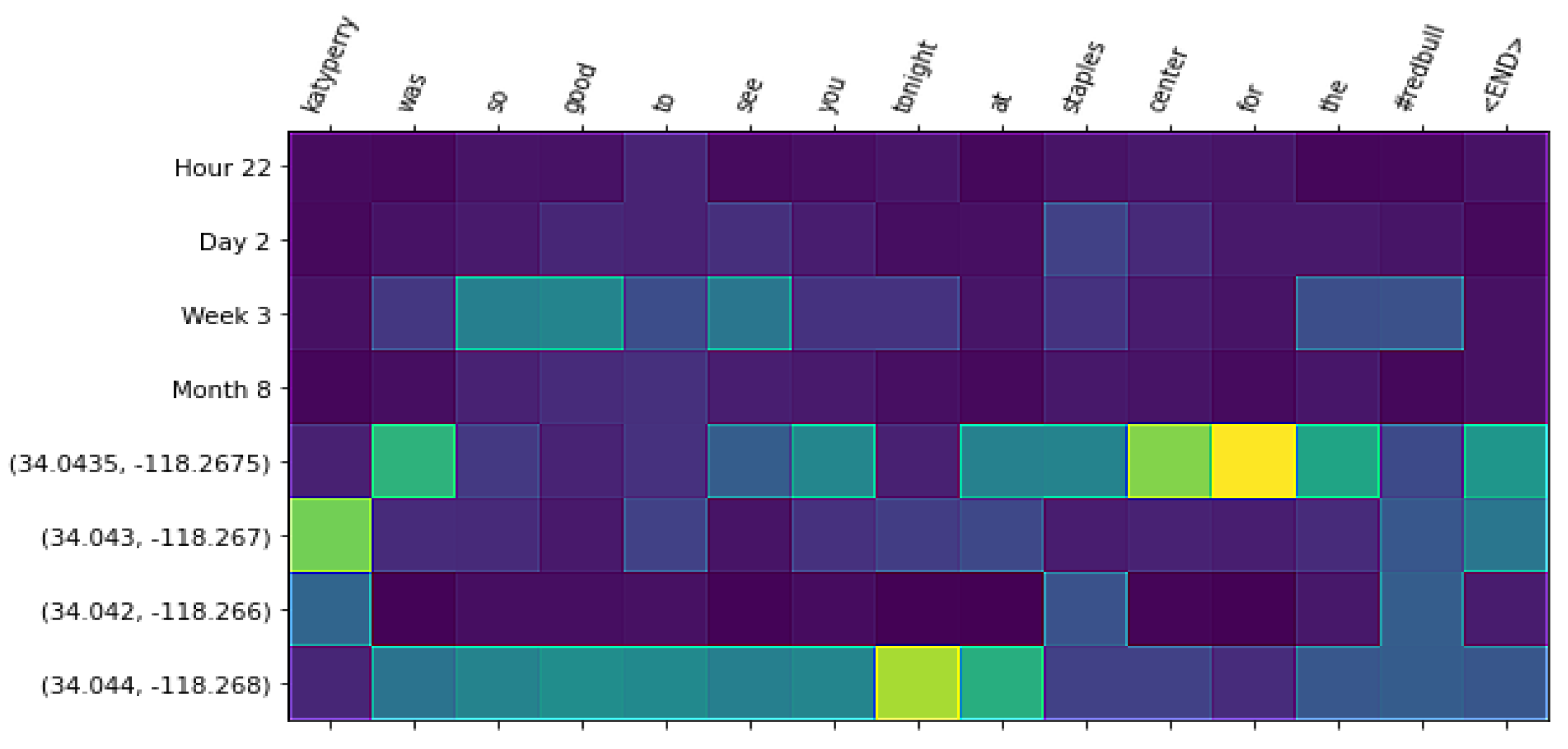
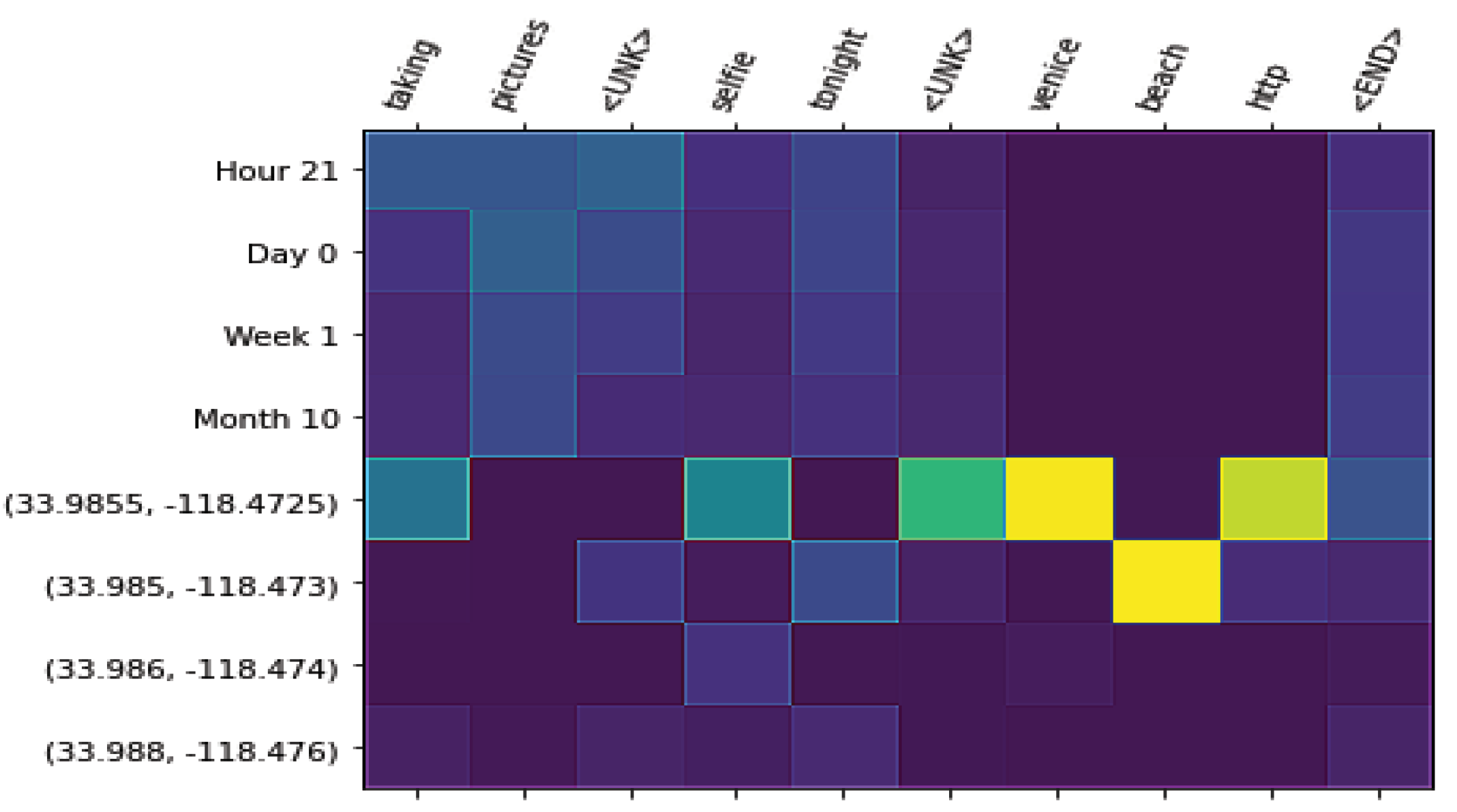
- Perform a qualitative analysis where we show visualizations that can help to gain insights into the patterns that guide language generation under spatio-temporal conditions. By modeling time and space at different granularities, we can analyze how each granularity level weighs in the representation model. For this analysis, we conducted experiments with a Transformer-based neural network. Attention-based neural networks such as the Transformer architecture have the benefit of providing insights into the importance of components of the spatio-temporal context by visualizing the attention weights.
Roadmap
2. Related Work
2.1. Applications for Spatio-Temporal Text Data
2.1.1. Activity Modeling
2.1.2. Mobility Modeling
2.1.3. Event Detection
2.1.4. Event Forecasting
2.2. Models for Spatio-Temporal Text Data
2.2.1. Spatio-Temporal Topic Modeling
2.2.2. Embedding Methods
2.2.3. Analysis of Models That Leverage Spatio-Temporal Text Data
- 1.
- The sequential structure of language.
- 2.
- A unified model for representing time and space that leverage time and space at different granularities as context for language generation.
3. Proposed Solution
3.1. Language Modeling
3.2. Problem Formulation
3.3. Neural Networks for Language Modeling
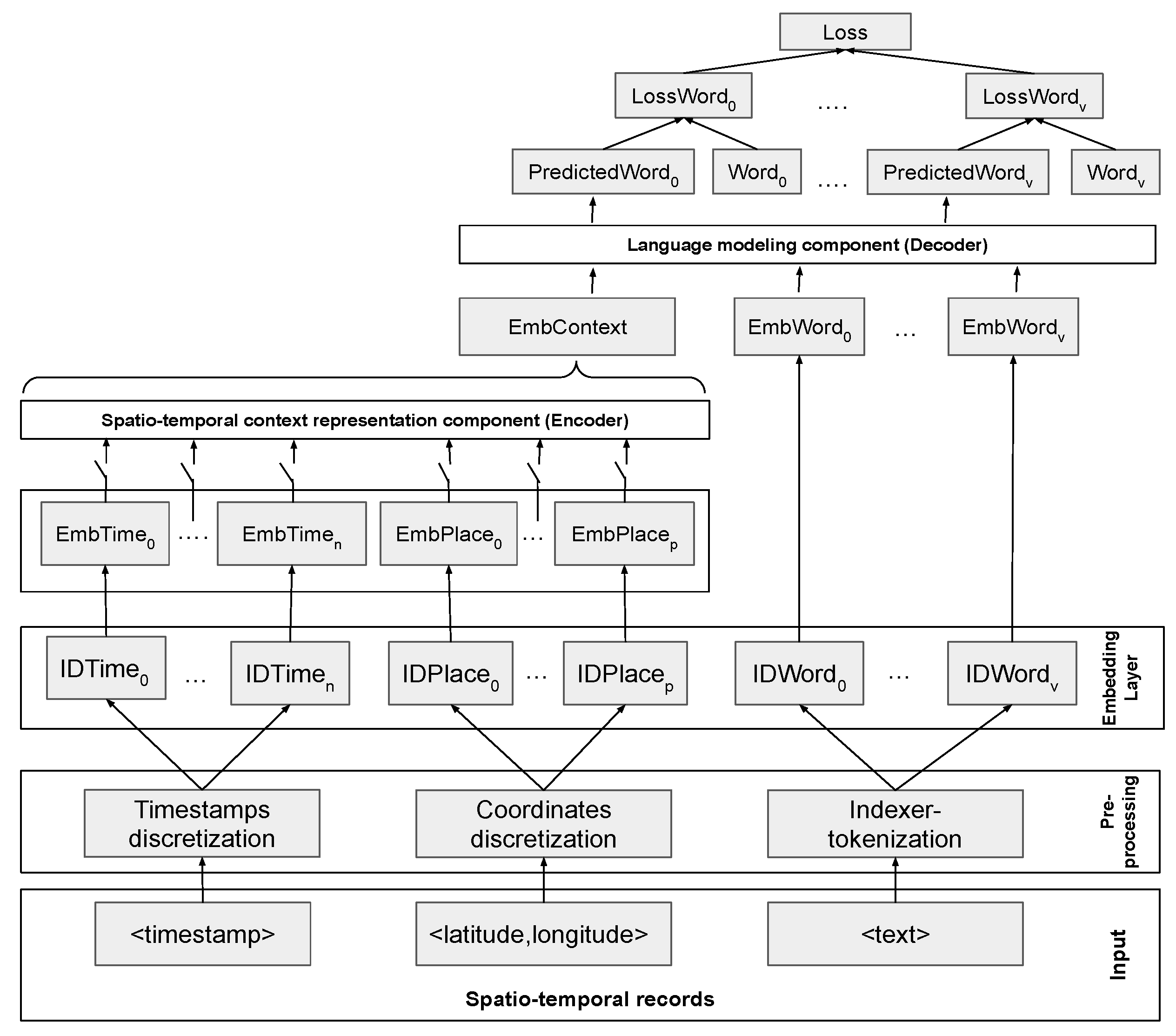
3.4. Model Description
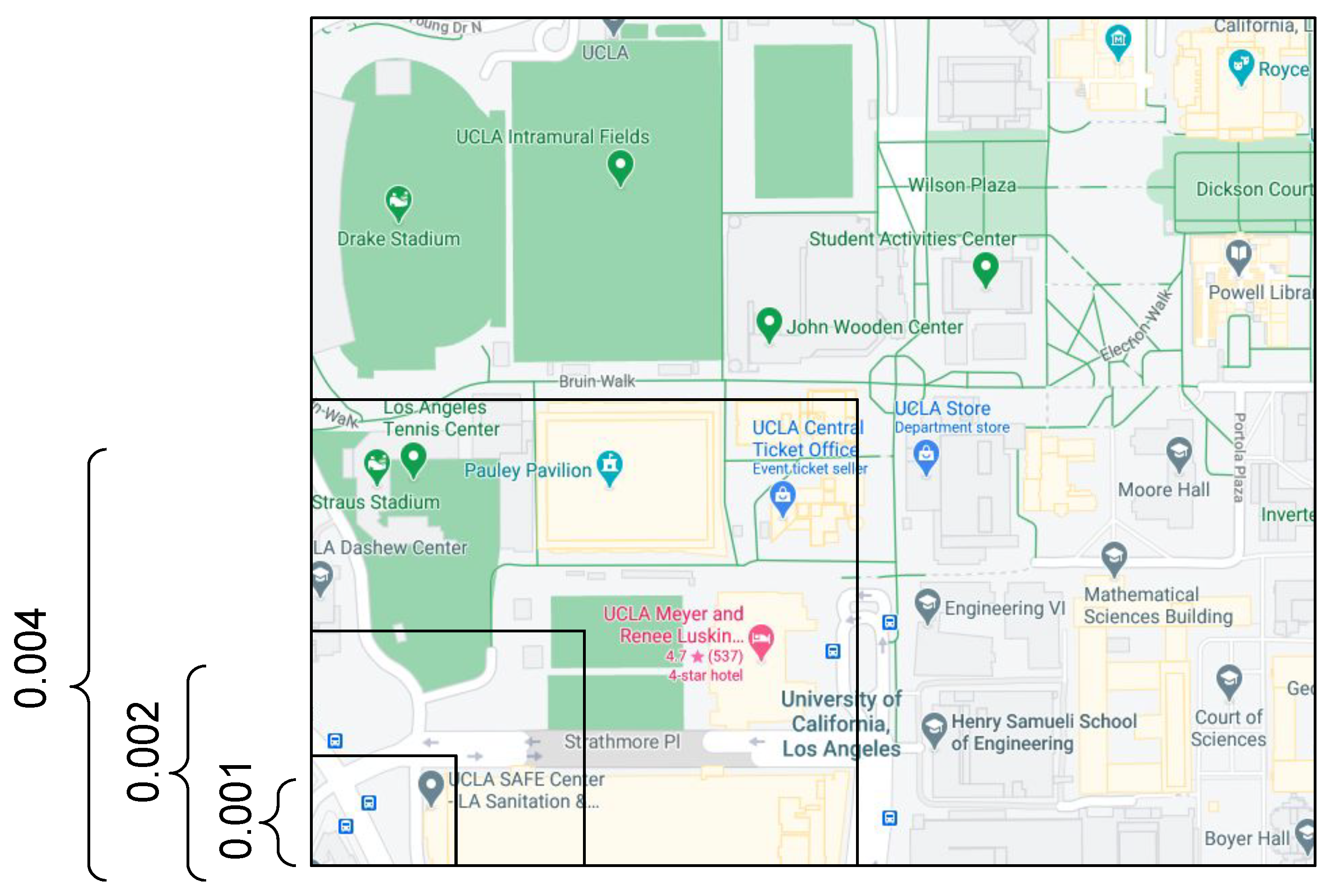
3.5. Timestamps and Geo-Coordinates Discretization
3.6. Parameters
4. Experiments
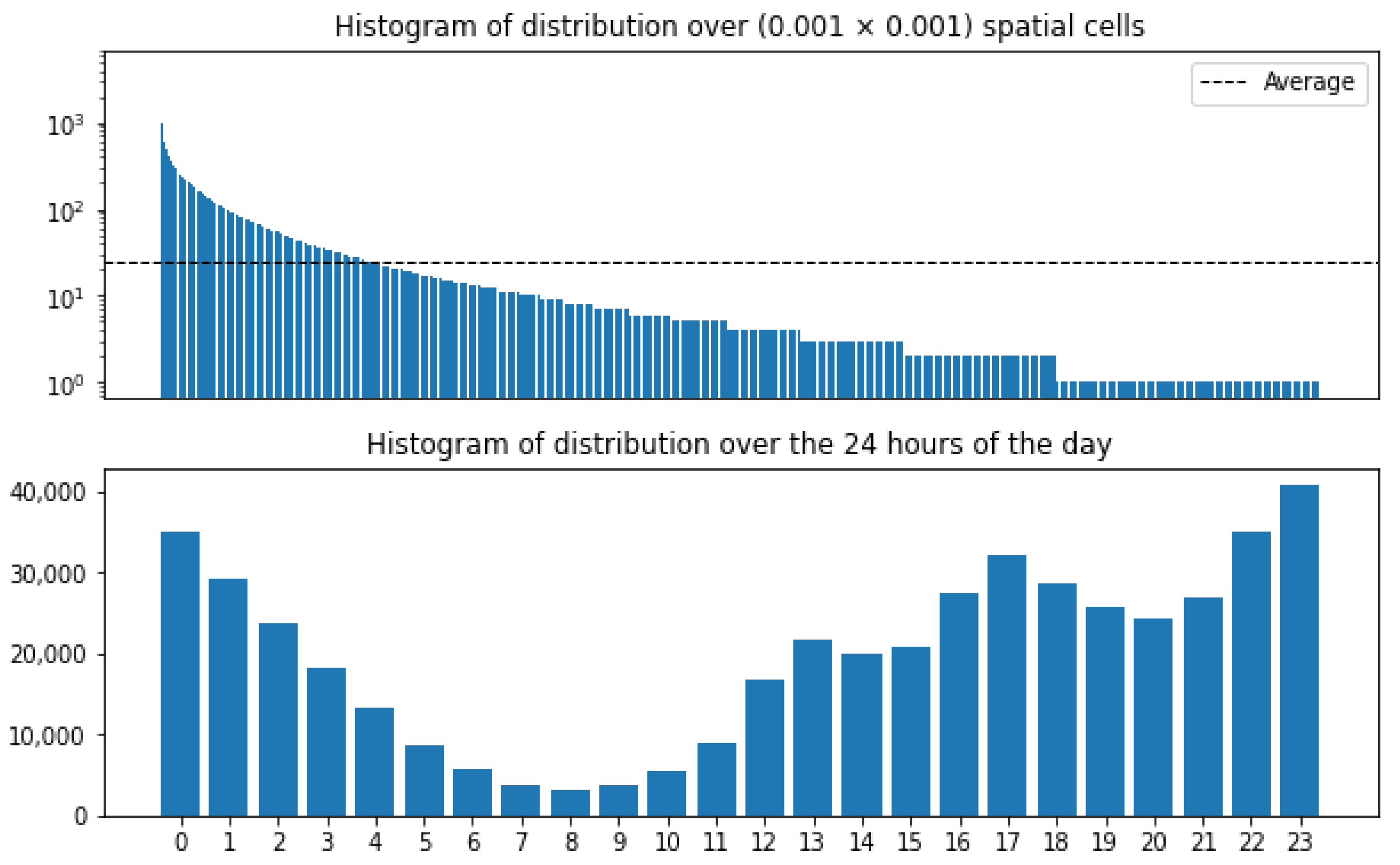
4.1. Datasets
4.2. Evaluation Methodology
4.3. Discretization Exploration
4.4. Encoder–Decoder Analysis
4.5. Spatio-Temporal Granularities Analysis
4.6. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LBSN | Location-based social networks |
References
- Zhang, C.; Zhang, K.; Yuan, Q.; Zhang, L.; Hanratty, T.; Han, J. Gmove: Group-level mobility modeling using geo-tagged social media. In Proceedings of the KDD: Proceedings. International Conference on Knowledge Discovery & Data Mining, San Francisco, CA, USA, 13–17 August 2016; p. 1305. [Google Scholar]
- Noulas, A.; Scellato, S.; Lathia, N.; Mascolo, C. Mining user mobility features for next place prediction in location-based services. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining (ICDM), Brussels, Belgium, 10–13 December 2012; pp. 1038–1043. [Google Scholar]
- Wu, F.; Li, Z.; Lee, W.C.; Wang, H.; Huang, Z. Semantic annotation of mobility data using social media. In Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Florence, Italy, 18–22 May 2015; pp. 1253–1263. [Google Scholar]
- Yin, Z.; Cao, L.; Han, J.; Zhai, C.; Huang, T. Geographical topic discovery and comparison. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 247–256. [Google Scholar]
- Zhang, C.; Zhang, K.; Yuan, Q.; Tao, F.; Zhang, L.; Hanratty, T.; Han, J. ReAct: Online Multimodal Embedding for Recency-Aware Spatiotemporal Activity Modeling. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 245–254. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th international Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Tweet analysis for real-time event detection and earthquake reporting system development. IEEE Trans. Knowl. Data Eng. 2013, 25, 919–931. [Google Scholar] [CrossRef]
- Zhao, L.; Chen, F.; Lu, C.T.; Ramakrishnan, N. Spatiotemporal event forecasting in social media. In Proceedings of the 2015 SIAM International Conference on Data Mining, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 963–971. [Google Scholar]
- Ye, M.; Shou, D.; Lee, W.C.; Yin, P.; Janowicz, K. On the semantic annotation of places in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 520–528. [Google Scholar]
- Zhang, C.; Zhang, K.; Yuan, Q.; Peng, H.; Zheng, Y.; Hanratty, T.; Wang, S.; Han, J. Regions, periods, activities: Uncovering urban dynamics via cross-modal representation learning. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 361–370. [Google Scholar]
- Baraglia, R.; Muntean, C.I.; Nardini, F.M.; Silvestri, F. LearNext: Learning to predict tourists movements. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 751–756. [Google Scholar]
- Yuan, Q.; Zhang, W.; Zhang, C.; Geng, X.; Cong, G.; Han, J. Pred: Periodic region detection for mobility modeling of social media users. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 263–272. [Google Scholar]
- Allan, J.; Carbonell, J.G.; Doddington, G.; Yamron, J.; Yang, Y. Topic Detection and Tracking Pilot Study Final Report. 1998. Available online: http://ciir.cs.umass.edu/pubfiles/ir-137.pdf (accessed on 30 October 2021).
- Ozdikis, O.; Oguztuzun, H.; Karagoz, P. Evidential location estimation for events detected in twitter. In Proceedings of the 7th Workshop on Geographic Information Retrieval, Orlando, FL, USA, 5 November 2013; pp. 9–16. [Google Scholar]
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd sensing of traffic anomalies based on human mobility and social media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 344–353. [Google Scholar]
- Wang, S.; He, L.; Stenneth, L.; Yu, P.S.; Li, Z. Citywide traffic congestion estimation with social media. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Bellevue, WA, USA, 3–6 November 2015; p. 34. [Google Scholar]
- Wang, X.; Brown, D.E.; Gerber, M.S. Spatio-temporal modeling of criminal incidents using geographic, demographic, and Twitter-derived information. In Proceedings of the 2012 IEEE International Conference on Intelligence and Security Informatics (ISI), Washington, DC, USA, 11–14 June 2012; pp. 36–41. [Google Scholar]
- Gerber, M.S. Predicting crime using Twitter and kernel density estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Chen, X.; Cho, Y.; Jang, S.Y. Crime prediction using Twitter sentiment and weather. In Proceedings of the Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 25 April 2015; pp. 63–68. [Google Scholar]
- Mei, Q.; Liu, C.; Su, H.; Zhai, C. A probabilistic approach to spatiotemporal theme pattern mining on weblogs. In Proceedings of the 15th International Conference on World Wide Web, Edinburgh, Scotland, 23–26 May 2006; pp. 533–542. [Google Scholar]
- Eisenstein, J.; O’Connor, B.; Smith, N.A.; Xing, E.P. A latent variable model for geographic lexical variation. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 1277–1287. [Google Scholar]
- Wang, C.; Wang, J.; Xie, X.; Ma, W.Y. Mining geographic knowledge using location aware topic model. In Proceedings of the 4th ACM Workshop on Geographical Information Retrieval, Lisbon, Portugal, 9 November 2007; pp. 65–70. [Google Scholar]
- Sizov, S. Geofolk: Latent spatial semantics in web 2.0 social media. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 281–290. [Google Scholar]
- Hong, L.; Ahmed, A.; Gurumurthy, S.; Smola, A.J.; Tsioutsiouliklis, K. Discovering geographical topics in the twitter stream. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 769–778. [Google Scholar]
- Ahmed, A.; Hong, L.; Smola, A.J. Hierarchical geographical modeling of user locations from social media posts. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 25–36. [Google Scholar]
- Kling, C.C.; Kunegis, J.; Sizov, S.; Staab, S. Detecting non-gaussian geographical topics in tagged photo collections. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 603–612. [Google Scholar]
- Hofmann, T. Probabilistic latent semantic indexing. ACM SIGIR Forum. 2017, 51, 211–218. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. EMNLP 2014, 14, 1532–1543. [Google Scholar]
- Huang, X.; Li, J.; Hu, X. Label informed attributed network embedding. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 731–739. [Google Scholar]
- Zhang, C.; Liu, M.; Liu, Z.; Yang, C.; Zhang, L.; Han, J. Spatiotemporal Activity Modeling Under Data Scarcity: A Graph-Regularized Cross-Modal Embedding Approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Eisenstein, J. Introduction to Natural Language Processing; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 5–13. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; Volume 27, pp. 3104–3112. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Liu, S.; Yang, N.; Li, M.; Zhou, M. A recursive recurrent neural network for statistical machine translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 1491–1500. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the Next Location: A Recurrent Model with Spatial and Temporal Contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Yang, C.; Sun, M.; Zhao, W.X.; Liu, Z.; Chang, E.Y. A neural network approach to jointly modeling social networks and mobile trajectories. ACM Trans. Inf. Syst. (TOIS) 2017, 35, 36. [Google Scholar] [CrossRef]
- Yao, D.; Zhang, C.; Huang, J.; Bi, J. SERM: A recurrent model for next location prediction in semantic trajectories. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2411–2414. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. DeepMove: Predicting Human Mobility with Attentional Recurrent Networks. In Proceedings of the 2018 World Wide Web Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, U.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners; OpenAI Blog: San Francisco, CA, USA, 2019; p. 1. [Google Scholar]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Volume 5. [Google Scholar]
- Brown, P.F.; Della Pietra, S.A.; Della Pietra, V.J.; Lai, J.C.; Mercer, R.L. An estimate of an upper bound for the entropy of English. Comput. Linguist. 1992, 18, 31–40. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Time Representation | Space Representation | Text Representation | Integration | Dataset | Evaluation Metric |
|---|---|---|---|---|---|---|
| [20] | Days in a week | City | Multinomial | Topic modeling | Blogs (2006) | - |
| [21] | - | User aggregation + Gaussian | Multinomial | Topic modeling | Twitter (2010) | Accuracy and Mean Distance |
| [23] | - | Two Gaussian | Multinomial | Topic modeling | Flickr (2010) | Accuracy |
| [22] | - | Multinomial | Multinomial | Topic modeling | News (-) | Perplexity |
| [24] | - | Clustering + Gaussian | Multinomial | Topic modeling | Twitter (2011) | Mean Distance |
| [25] | - | Hierarchical Gaussian | Multinomial | Topic modeling | Twitter (2011) | Accuracy and Mean Distance |
| [26] | - | Fisher distribution | Multinomial | Multi-Dirichlet process | Flickr (2010) | Perplexity |
| [10] | Clustering over seconds in a day | Clustering | Embedding | Multimodal embedding | Twitter (2014) Foursquare (2014) | Mean Reciprocal Rank |
| [5] | Hours in a day | Equal-sized grids | Embedding | Online multimodal embedding | Twitter (2014) Foursquare (2014) | Mean Reciprocal Rank |
| [32] | Hours in a day | Equal-sized grids | Embedding | Cross-modal embedding | Twitter (2014) Foursquare (2014) | Mean Reciprocal Rank |
| LA-TW | NY-FS | |
|---|---|---|
| Records | 1,188,405 | 479,297 |
| City | Los Angeles | New York |
| Start Date | 1 August 2014 | 25 February 2010 |
| End Date | 30 November 2014 | 16 August 2012 |
| Context | Encoder | Decoder | Dataset | Perplexity |
|---|---|---|---|---|
| [] | - | GRU | NY-FS | 10.49 |
| [] | - | Self-Attn | NY-FS | 9.13 |
| [hdwm]-alltimes | Embeddings | GRU | NY-FS | 10.02 |
| [hdwm]-alltimes | Embeddings | Self-Attn | NY-FS | 9.00 |
| [hdwm]-alltimes | Self-Attn | GRU | NY-FS | 10.14 |
| [hdwm]-alltimes | Self-Attn | Self-Attn | NY-FS | 47.15 |
| [p1p2p4p8]-allplaces | Embeddings | GRU | NY-FS | 6.51 |
| [p1p2p4p8]-allplaces | Embeddings | Self-Attn | NY-FS | 5.45 |
| [p1p2p4p8]-allplaces | Self-Attn | GRU | NY-FS | 10.13 |
| [p1p2p4p8]-allplaces | Self-Attn | Self-Attn | NY-FS | 36.62 |
| [hdwm p1p2p4p8]-all | Embeddings | GRU | NY-FS | 6.38 |
| [hdwm p1p2p4p8]-all | Embeddings | Self-Attn | NY-FS | 5.34 |
| [hdwm p1p2p4p8]-all | Self-Attn | GRU | NY-FS | 10.14 |
| [hdwm p1p2p4p8]-all | Self-Attn | Self-Attn | NY-FS | 34.93 |
| Context | Encoder | Decoder | Dataset | Perplexity |
|---|---|---|---|---|
| [] | - | GRU | LA-TW | 63.03 |
| [] | - | Self-Attn | LA-TW | 57.35 |
| [hdwm]-alltimes | Embeddings | GRU | LA-TW | 61.90 |
| [hdwm]-alltimes | Embeddings | Self-Attn | LA-TW | 56.67 |
| [hdwm]-alltimes | Self-Attn | GRU | LA-TW | 63.02 |
| [hdwm]-alltimes | Self-Attn | Self-Attn | LA-TW | 193.77 |
| [p1p2p4p8]-allplaces | Embeddings | GRU | LA-TW | 61.13 |
| [p1p2p4p8]-allplaces | Embeddings | Self-Attn | LA-TW | 54.30 |
| [p1p2p4p8]-allplaces | Self-Attn | GRU | LA-TW | 62.42 |
| [p1p2p4p8]-allplaces | Self-Attn | Self-Attn | LA-TW | 161.14 |
| [hdwm p1p2p4p8]-all | Embeddings | GRU | LA-TW | 58.88 |
| [hdwm p1p2p4p8]-all | Embeddings | Self-Attn | LA-TW | 53.85 |
| [hdwm p1p2p4p8]-all | Self-Attn | GRU | LA-TW | 63.06 |
| [hdwm p1p2p4p8]-all | Self-Attn | Self-Attn | LA-TW | 72.80 |
| Context | Cells | Dataset | Perplexity |
|---|---|---|---|
| [] | - | LA-TW | 57.35 |
| [h]—hour | 24 | LA-TW | 57.07 |
| [d]—day | 7 | LA-TW | 57.17 |
| [w]—week | 5 | LA-TW | 57.13 |
| [m]—month | 12 | LA-TW | 56.95 |
| [hdwm]—all times | 48 | LA-TW | 56.67 |
| [p1]—0.001 | 77,065 | LA-TW | 54.65 |
| [p2]—0.002 | 34,284 | LA-TW | 52.91 |
| [p4]—0.004 | 11,359 | LA-TW | 51.45 |
| [p8]—0.008 | 3283 | LA-TW | 51.30 |
| [p1p2p4p8]—allplaces | 125,992 | LA-TW | 54.30 |
| [hdwm p1p2p4p8]—all | 126,036 | LA-TW | 53.85 |
| Context | Cells | Dataset | Perplexity |
|---|---|---|---|
| [] | - | LA-TW | 57.35 |
| [p]-0.016 | 1253 | LA-TW | 52.39 |
| [p]-0.024 | 460 | LA-TW | 52.81 |
| [p]-0.032 | 197 | LA-TW | 53.32 |
| Context | Cells | Dataset | Perplexity |
|---|---|---|---|
| [] | - | NY-FS | 9.13 |
| [h]—hour | 24 | NY-FS | 8.97 |
| [d]—day | 7 | NY-FS | 9.10 |
| [w]—week | 5 | NY-FS | 9.21 |
| [m]—month | 12 | NY-FS | 9.09 |
| [hdwm]—alltimes | 48 | NY-FS | 9.00 |
| [p1]—0.001 | 17,929 | NY-FS | 5.40 |
| [p2]—0.002 | 11,260 | NY-FS | 5.74 |
| [p4]—0.004 | 6060 | NY-FS | 6.10 |
| [p8]—0.008 | 3283 | NY-FS | 6.63 |
| [p1p2p4p8]—allplaces | 38,532 | NY-FS | 5.45 |
| [hdwm p1p2p4p8]—all | 38,580 | NY-FS | 5.34 |
| Context | Cells | Dataset | Perplexity |
|---|---|---|---|
| [] | - | NY-FS | 8.31 |
| [p]—0.00075 | 21,250 | NY-FS | 5.33 |
| [p]—0.00050 | 26,431 | NY-FS | 5.22 |
| [p]—0.00025 | 35,091 | NY-FS | 5.07 |
| Context | Text Generated |
|---|---|
| (Staples Center) (34.043; ) (Concert Date) ‘7 August 2014 22:00:00’ | [‘<START>’, ‘taking’, ‘a’, ‘break’, ‘from’, ‘the’, ‘arctic’, ‘monkeys’, ‘concert’, ‘and’, ‘i’, ‘love’, ‘the’, ‘place’, ‘if’, ‘you’, ‘are’, ‘here’, ‘#staples’, ‘staplescenter’, ‘http’, ‘<END>’ |
| [‘<START>’, ‘during’, ‘the’, ‘night’, ‘#arcticmonkeys’, ‘http’, ‘<END>’] | |
| [‘<START>’, ‘arctic’, ‘monkeys’, ‘anthem’, ‘with’, ‘my’, ‘mom’, ‘at’, ‘staples’, ‘center’, ‘http’, ‘<END>’] | |
| (Staples Center) (34.043; lon = ) (Game Date) ‘31 October 2014 22:00:00’ | [‘<START>’, ‘just’, ‘posted’, ‘a’, ‘photo’, ‘105’, ‘east’, ‘los’, ‘angeles’, ‘clippers’, ‘game’, ‘http’, ‘<END>’] |
| [‘<START>’, ‘#lakers’, ‘#golakers’, ‘los’, ‘angeles’, ‘lakers’, ‘surprise’, ‘summer’, ‘-’, ‘great’, ‘job’, ‘-’, ‘lakers’, ‘nation’, ‘http’, ‘#sportsroadhouse’, ‘<END>’] | |
| [‘<START>’, ‘who’, ‘wants’, ‘to’, ‘go’, ‘to’, ‘the’, ‘lakings’, ‘game’, ‘lmao’, ‘<END>’] | |
| (Venice Beach) (33.985; ) (Date) ‘24 August 2014 13:50:00’ | [’<START>’, ‘touched’, ‘down’, ‘venice’, ‘beach’, ‘#venice’, ‘#venicebeach’, ‘http’, ‘<END>’] |
| [’<START>’, ‘venice’, ‘beach’, ‘cali’, ‘#nofilter’, ‘#venice’, ‘#venicebeach’, ‘is’, ‘rolling’, ‘great’, ‘<END>’] | |
| [’<START>’, ‘who’, ‘wants’, ‘to’, ‘go’, ‘to’, ‘venice’, ‘beach’, ‘shot’, ‘on’, ‘the’, ‘beach’, ‘<END>’] | |
| [’<START>’, ‘venice’, ‘beach’, ‘#venicebeach’, ‘#california’, ‘#travel’, ‘venice’, ‘beach’, ‘ca’, ‘http’, ‘<END>’] | |
| [’<START>’, ‘#longbeach’, ‘#venicebeach’, ‘#venice’, ‘#beach’, ‘#sunset’, ‘#venice’, ‘#venicebeach’, ‘#losangeles’, ‘#california’, ‘http’, ‘<END>’] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diaz, J.; Bravo-Marquez, F.; Poblete, B. Language Modeling on Location-Based Social Networks. ISPRS Int. J. Geo-Inf. 2022, 11, 147. https://doi.org/10.3390/ijgi11020147
Diaz J, Bravo-Marquez F, Poblete B. Language Modeling on Location-Based Social Networks. ISPRS International Journal of Geo-Information. 2022; 11(2):147. https://doi.org/10.3390/ijgi11020147
Chicago/Turabian StyleDiaz, Juglar, Felipe Bravo-Marquez, and Barbara Poblete. 2022. "Language Modeling on Location-Based Social Networks" ISPRS International Journal of Geo-Information 11, no. 2: 147. https://doi.org/10.3390/ijgi11020147
APA StyleDiaz, J., Bravo-Marquez, F., & Poblete, B. (2022). Language Modeling on Location-Based Social Networks. ISPRS International Journal of Geo-Information, 11(2), 147. https://doi.org/10.3390/ijgi11020147