
Hourly PM2.5 Concentration Prediction Based on Empirical Mode Decomposition and Geographically Weighted Neural Network
Abstract
:1. Introduction
- The analysis of PM2.5 concentration in three representative cities, such as Beijing, Wuhan, and Kunming, reveals that the PM2.5 concentration has distinct nonlinearity as well as the diversity of seasonal patterns.
- The EMD-mRMR-GWNN model was developed for PM2.5 concentration prediction. This model effectively integrates the advantages of data decomposition, data reconstruction, and feature selection techniques while considering the spatial relationship of PM2.5 monitoring stations. Experimental results on datasets from three cities in China (Beijing, Wuhan, and Kunming) indicate that the proposed hybrid model performed well.
- The original PM2.5 sequence is adaptively decomposed into multiple IMFs and a residual component using EMD and classified into high-frequency and low-frequency components by the one-sample t-test, significantly reducing the prediction difficulty and model complexity.
- For prediction accuracy, considering the correlation between features and the target variable, as well as the redundancy among features, we utilize the mRMR to select the optimal feature subset. By leveraging the nonlinear modeling capability of ANN and the spatial correlation capturing ability of GWR, we build a GWNN model to predict the high-frequency and low-frequency components, which significantly improves the accuracy of PM2.5 prediction.
2. Materials and Methods
2.1. Data Description
2.2. Empirical Mode Decomposition
- Detect and extract the local maximum and local minimum in the signal x(t) and set the initial index .
- The upper envelope u(t) and lower envelope l(t) of the signal are obtained by cubic spline interpolation of the envelope between the extreme points.
- Calculate the mean value m(t) of the upper and lower envelope.
- The mean value m(t) of the upper and lower envelope is removed from the original signal x(t) to obtain a new sequence h(t).
- A judgment is made on the new sequence h(t). If h(t) satisfies the following two conditions: the number of extreme points and the number of points crossing the zero point are equal or differ by no more than one, and the average value of the upper envelope formed by the local extreme points and the lower envelope formed by the local extreme points is zero, then h(t) is considered to be an IMF, . If h(t) does not satisfy the above conditions, h(t) is considered the original signal for the next round of iterations until the conditions are satisfied.
- The above steps are repeated until no more new IMFs can be decomposed, and the remaining signal is regarded as the residual component Res(t).
- Finally, the original signal is decomposed into multiple IMFs and a residual component.
2.3. Minimal-Redundancy-Maximal-Relevance
2.3.1. Maximal Relevance
2.3.2. Minimal Redundancy
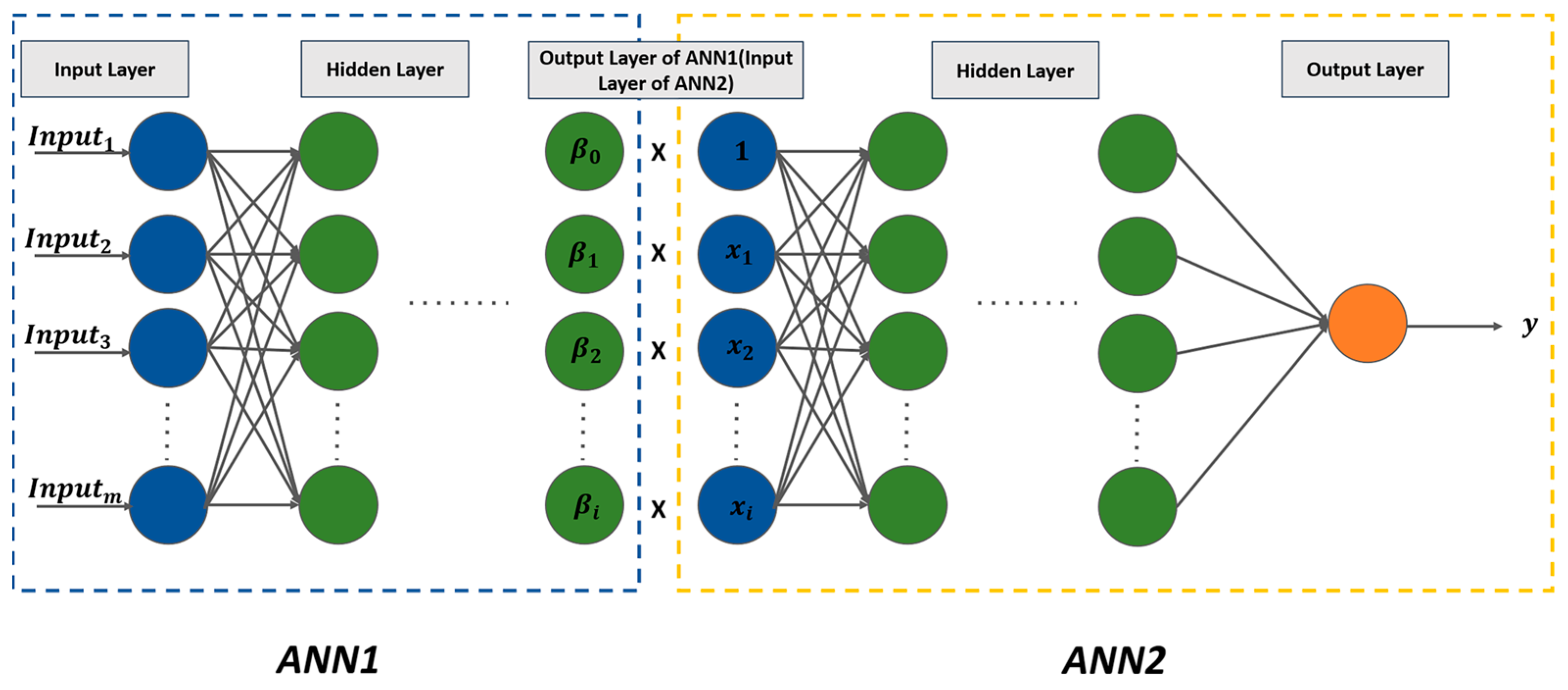
2.4. Geographically Weighted Neural Network
2.5. Proposed Model
- Firstly, the original PM2.5 sequence was decomposed into multiple IMFs and a residual component using EMD.
- To reduce the complexity, the running time, and the cumulative error of the model, the IMFs were classified and reconstructed into high-frequency component and low-frequency components using the one-sample t-test.
- SMA was employed to predict the residual component with a strong trend and autocorrelation, which avoids overfitting while ensuring prediction accuracy.
- GWNN was employed to predict the high-frequency and low-frequency components. The input of ANN1 in GWNN was the PM2.5 concentration data in the past 24 h at the stations surrounding the target station. The product of the regression coefficient β learned by ANN1 and the dependent variable x, was the input of ANN2 in GWNN. The features selected by the mRMR and the constant 1 constitute the independent variable x.
- Finally, the predicted value of each component was input into an ANN to predict the PM2.5 concentration.
2.6. Prediction Performance Evaluation Metrics
3. Results and Discussion
3.1. Decomposition and Reconstruction of PM2.5 Sequence
3.1.1. Decomposition with EMD
3.1.2. Reconstruction of IMFs with the One-Sample t-Test
3.2. Feature Selection with mRMR
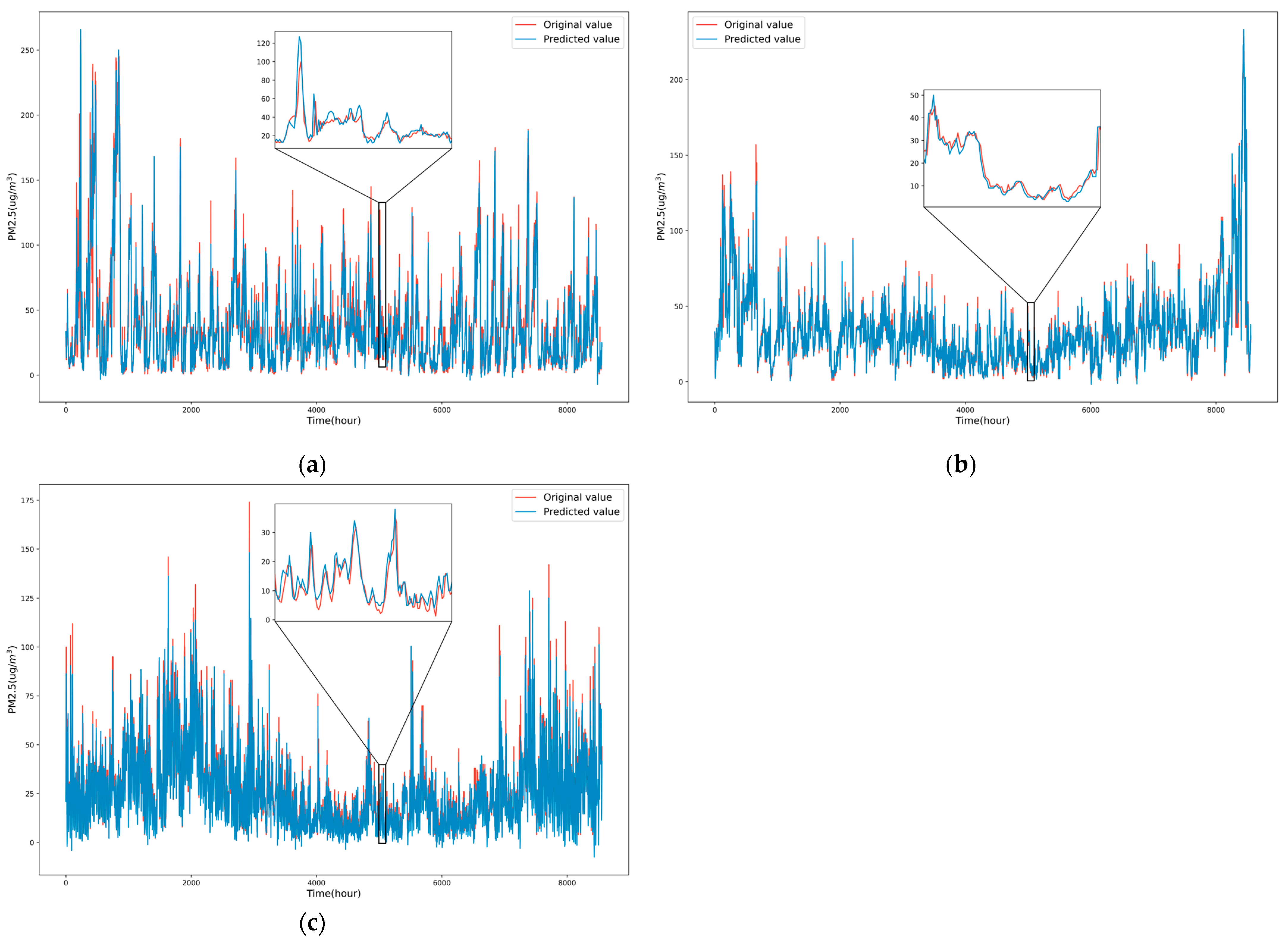
3.3. Prediction Results of EMD-mRMR-GWNN
3.4. Prediction Performance Comparison of Different Models
4. Conclusions
- The analysis of the PM2.5 concentration of Beijing, Wuhan, and Kunming reveals that Beijing had the highest and most volatile PM2.5 concentration, while Kunming had the lowest and least volatile PM2.5 concentration. The three cities have shown a declining trend in PM2.5 concentration, indicating air quality improvement. Beijing and Wuhan showed similar seasonal patterns, with the highest PM2.5 concentrations in winter and the lowest in summer. However, Kunming had its peak PM2.5 concentration during spring, showing a different seasonal pattern from Beijing and Wuhan.
- We propose a model called GWNN that combines ANN and GWR. Experiments to forecast PM2.5 concentration for the next 1 h at the Beijing 1005A, Wuhan 1328A, and Kunming 1454A stations show that GWNN RMSE decreases by a maximum of 7.05%, MAE decreases by a maximum of 10.56%, and R2 increases by a maximum of 2.19%, compared to LSTM and GRU.
- For feature selection, the mRMR is introduced, which considers the relevance between features and the target variable as well as the redundancy between features. Compared to GWNN, at the Beijing 1005A, Wuhan 1328A, and Kunming 1454A stations, mRMR-GWNN RMSE decreases by a maximum of 3.38%, MAE decreases by a maximum of 8.52%, and increases by a maximum of 0.94%. The mRMR-GWNN model achieves higher prediction accuracy with fewer input features.
- The complexity of the original PM2.5 sequence is reduced by decomposing the original PM2.5 sequence into a set of IMFs and a residual component through EMD. Meanwhile, the one-sample t-test is introduced to reconstruct the IMFs into high-frequency and low-frequency components.
- The high-frequency and low-frequency components are predicted using mRMR-GWNN. The residual component is predicted using SMA. The predicted value of each component is input to an ANN for predicting PM2.5 concentration. Experiments at the Beijing 1005A, Wuhan 1328A, and Kunming 1454A stations, show that the EMD-mRMR-GWNN model outperforms baseline models. Compared to mRMR-GWNN, the RMSE of the EMD-mRMR-GWNN model decreases by a maximum of 21.33%, MAE decreases by a maximum of 14.01%, and increases by a maximum of 4.97%. Compared to LSTM and GRU, the RMSE of the EMD-mRMR-GWNN model decreases by a maximum of 29.18%, MAE decreases by a maximum of 19.85%, and increases by a maximum of 8.28%.
- Experiments to forecast PM25 concentration for the next 4, 8, and 12 h verified the stability and superiority of the EMD-mRMR-GWNN model, compared with baseline models.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pradhan, P.; Costa, L.; Rybski, D.; Lucht, W.; Kropp, J.P. A Systematic study of Sustainable Development Goal (SDG) interactions. Earth’s Future 2017, 5, 1169–1179. [Google Scholar] [CrossRef]
- Lu, J.G. Air pollution: A systematic review of its psychological, economic, and social effects. Curr. Opin. Psychol. 2020, 32, 52–65. [Google Scholar] [CrossRef]
- Yang, T.; Zhou, K.; Yang, Y. Air pollution impacts on public health: Evidence from 110 cities in Yangtze River Economic Belt of China. Sci. Total Environ. 2022, 851, 158125. [Google Scholar] [CrossRef]
- Zu, D.; Zhai, K.; Qiu, Y.; Pei, P.; Zhu, X.; Han, D. The Impacts of Air Pollution on Mental Health: Evidence from the Chinese University Students. Int. J. Environ. Res. Public Health 2020, 17, 6734. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jin, L.; Kan, H. Air pollution: A global problem needs local fixes. Nature 2019, 570, 437–439. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Ren, X.; Xiong, K.; Li, L.; Bi, X.; Wu, Q. Analysis of the driving factors of PM2.5 concentration in the air: A case study of the Yangtze River Delta, China. Ecol. Indic. 2020, 110, 105889. [Google Scholar] [CrossRef]
- Jin, H.; Chen, X.; Zhong, R.; Liu, M. Influence and prediction of PM2.5 through multiple environmental variables in China. Sci. Total Environ. 2022, 849, 157910. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Gao, X.; Li, W. A graph-based LSTM model for PM2.5 forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Nguyen, P.L.; Nguyen, K.; Le, V.B.; Ji, Y. PM2.5 Prediction Using Genetic Algorithm-Based Feature Selection and Encoder-Decoder Model. IEEE Access 2021, 9, 57338–57350. [Google Scholar] [CrossRef]
- Qiao, W.; Tian, W.; Tian, Y.; Yang, Q.; Wang, Y.; Zhang, J. The Forecasting of PM2.5 Using a Hybrid Model Based on Wavelet Transform and an Improved Deep Learning Algorithm. IEEE Access 2019, 7, 142814–142825. [Google Scholar] [CrossRef]
- Li, Y.; Peng, T.; Hua, L.; Ji, C.; Ma, H.; Nazir, M.S.; Zhang, C. Research and application of an evolutionary deep learning model based on improved grey wolf optimization algorithm and DBN-ELM for AQI prediction. Sustain. Cities Soc. 2022, 87, 104209. [Google Scholar] [CrossRef]
- Djalalova, I.; Monache, L.D.; Wilczak, J.M. PM2.5 analog forecast and Kalman filter post-processing for the Community Multiscale Air Quality (CMAQ) model. Atmos. Environ. 2015, 108, 76–87. [Google Scholar] [CrossRef]
- Lightstone, S.D.; Moshary, F.; Gross, B. Comparing CMAQ Forecasts with a Neural Network Forecast Model for PM2.5 in New York. Atmosphere 2017, 8, 161. [Google Scholar] [CrossRef]
- Thongthammachart, T.; Araki, S.; Shimadera, H.; Eto, S.; Matsuo, T.; Kondo, A. An integrated model combining random forests and WRF/CMAQ model for high accuracy spatiotemporal PM2.5 predictions in the Kansai region of Japan. Atmos. Environ. 2021, 262, 118620. [Google Scholar] [CrossRef]
- Cheng, F.; Feng, C.W.; Yang, Z.M.; Hsu, C.; Chan, K.W.; Lee, C.; Chang, S.C. Evaluation of real-time PM2.5 forecasts with the WRF-CMAQ modeling system and weather-pattern-dependent bias-adjusted PM2.5 forecasts in Taiwan. Atmos. Environ. 2021, 244, 117909. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, Y. Short-term PM2.5 prediction based on variational mode decomposition and machine learning methods. In Proceedings of the 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 25–27 February 2022. [Google Scholar]
- Pak, U.; Ma, J.; Wang, J.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef] [PubMed]
- Yeo, I.; Choi, Y.; Lops, Y.; Sayeed, A. Efficient PM2.5 forecasting using geographical correlation based on integrated deep learning algorithms. Neural Comput. Appl. 2021, 33, 15073–15089. [Google Scholar] [CrossRef]
- Zhu, H.; Lu, X. The Prediction of PM2.5 Value Based on ARMA and Improved BP Neural Network Model. In Proceedings of the 2016 International Conference on Intelligent Networking and Collaborative Systems (INCoS), Ostrava, Czech Republic, 7–9 September 2016. [Google Scholar]
- Yang, J.; Zhou, X. Prediction of PM2.5 Concentration Based on ARMA Model Based on Wavelet Transform. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020. [Google Scholar]
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM 2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Wu, C.; He, H.; Song, R.; Zhu, X.; Peng, Z.; Fu, Q.; Pan, J. A hybrid deep learning model for regional O3 and NO2 concentrations prediction based on spatiotemporal dependencies in air quality monitoring network. Environ. Pollut. 2023, 320, 121075. [Google Scholar] [CrossRef]
- He, Z.; Guo, Q.; Wang, Z.; Li, X. Prediction of Monthly PM2.5 Concentration in Liaocheng in China Employing Artificial Neural Network. Atmosphere 2022, 13, 1221. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.; Zhao, G.; Lian, J. Constructing a PM2.5 concentration prediction model by combining auto-encoder with Bi-LSTM neural networks. Environ. Model. Softw. 2020, 124, 104600. [Google Scholar] [CrossRef]
- Kristiani, E.; Lin, H.; Lin, J.; Chuang, Y.; Huang, C.; Yang, C. Short-Term Prediction of PM2.5 Using LSTM Deep Learning Methods. Sustainability 2022, 14, 2068. [Google Scholar] [CrossRef]
- Chae, S.; Shin, J.; Kwon, S.; Lee, S.; Kang, S.; Lee, D.H. PM10 and PM2.5 real-time prediction models using an interpolated convolutional neural network. Sci. Rep. 2021, 11, 11952. [Google Scholar] [CrossRef]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef]
- Wang, W.; Tang, Q. Combined model of air quality index forecasting based on the combination of complementary empirical mode decomposition and sequence reconstruction. Environ. Pollut. 2023, 316, 120628. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Zheng, L. Complementary ensemble empirical mode decomposition and independent recurrent neural network model for predicting air quality index. Appl. Soft Comput. 2022, 131, 109757. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Ding, Z.; Chen, H. An enhanced interval PM2.5 concentration forecasting model based on BEMD and MLPI with influencing factors. Atmos. Environ. 2020, 223, 117200. [Google Scholar] [CrossRef]
- Lai, X.; Li, H.; Pan, Y. A combined model based on feature selection and support vector machine for PM2.5 prediction. J. Intell. Fuzzy Syst. 2021, 40, 10099–10113. [Google Scholar] [CrossRef]
- Lin, L.; Liang, Y.; Liu, L.; Zhang, Y.; Xie, D.; Yin, F.; Ashraf, T. Estimating PM2.5 Concentrations Using the Machine Learning RF-XGBoost Model in Guanzhong Urban Agglomeration, China. Remote Sens. 2022, 14, 5239. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.; Chang, L.; Kao, I.; Wang, Y.; Kang, C. Multi-output support vector machine for regional multi-step-ahead PM2.5 forecasting. Sci. Total Environ. 2019, 651, 230–240. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, G.; Chen, F.; He, Y. A hybrid-wavelet model applied for forecasting PM2.5 concentrations in Taiyuan city, China. Atmos. Pollut. Res. 2019, 10, 1884–1894. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Feng, L.; Wang, Y.; Zhang, Z.; Du, Q. Geographically and temporally weighted neural network for winter wheat yield prediction. Remote Sens. Environ. 2021, 262, 112514. [Google Scholar] [CrossRef]
- Zhao, C.; Ju, S.; Xue, Y.; Ren, T.; Ji, Y.; Xue, C. China’s energy transitions for carbon neutrality: Challenges and opportunities. Carbon Neutrality 2022, 1, 7. [Google Scholar] [CrossRef]
- Yuan, X.L.; Liu, X.; Zuo, J. The development of new energy vehicles for a sustainable future: A review. Renew. Sustain. Energy Rev. 2015, 42, 298–305. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.X. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Liang, Y.; Niu, D.; Hong, W. Short term load forecasting based on feature extraction and improved general regression neural network model. Energy 2019, 166, 653–663. [Google Scholar] [CrossRef]
- Huh, J.; Youn, J.; Park, P.; Jeon, K.; Park, S. Development of a Prediction Model for Daily PM2.5 in Republic of Korea by Using an Artificial Neutral Network. Appl. Sci. 2023, 13, 3575. [Google Scholar] [CrossRef]
- Lu, B.; Ge, Y.; Qin, K.; Zheng, J.H. A Review on Geographically Weighted Regression. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1356–1366. [Google Scholar]
- Tang, M.; Acharya, T.D.; Niemeier, D. Black Carbon Concentration Estimation with Mobile-Based Measurements in a Complex Urban Environment. ISPRS Int. J. Geo-Inf. 2023, 12, 290. [Google Scholar] [CrossRef]
- Guo, M.; Miao, N.; Sun, S.; Xu, C.; Zhang, G.M.; Zhang, L.; Zhang, R.; Zheng, J.; Chen, C.; Jia, Z.; et al. Estimation and Analysis of Air Pollutant Emissions from On-Road Vehicles in Changzhou, China. Atmosphere 2024, 15, 192. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| PM2.5 concentration at the time t − n (previous nth hour to time t) | |
| PM10 concentration at the time t − n | |
| SO2 concentration at the time t − n | |
| NO2 concentration at the time t − n | |
| O3 concentration at the time t − n | |
| CO concentration at the time t − n | |
| High-frequency component value at the time t − n | |
| Low-frequency component value at the time t − n |
| Station | Prediction Performance Evaluation Metric | ||
|---|---|---|---|
| RMSE | MAE | ||
| Beijing 1005A Station | 8.9714 | 5.4614 | 0.9435 |
| Wuhan 1328A Station | 5.7730 | 3.2199 | 0.9514 |
| Kunming 1454A Station | 5.3323 | 3.6039 | 0.9286 |
| Station | Comparative Models | Prediction Performance Evaluation Metric | ||
|---|---|---|---|---|
| RMSE | MAE | |||
| Beijing 1005A Station | LSTM | 10.4934 | 6.2824 | 0.9227 |
| GRU | 10.5864 | 6.2223 | 0.9213 | |
| GWNN | 9.8403 | 6.2026 | 0.9320 | |
| mRMR-GWNN | 9.5402 | 5.6744 | 0.9361 | |
| EMD-mRMR-GWNN | 8.9714 | 5.4614 | 0.9435 | |
| Wuhan 1328A Station | LSTM | 6.5348 | 3.9133 | 0.9377 |
| GRU | 6.4942 | 3.7342 | 0.9384 | |
| GWNN | 6.4606 | 3.5002 | 0.9391 | |
| mRMR-GWNN | 6.2692 | 3.3808 | 0.9426 | |
| EMD-mRMR-GWNN | 5.7730 | 3.2199 | 0.9514 | |
| Kunming 1454A Station | LSTM | 7.5294 | 4.4959 | 0.8576 |
| GRU | 7.0243 | 4.4414 | 0.8761 | |
| GWNN | 7.0149 | 4.3063 | 0.8764 | |
| mRMR-GWNN | 6.7782 | 4.1910 | 0.8846 | |
| EMD-mRMR-GWNN | 5.3323 | 3.6039 | 0.9286 | |
| Station | Model | Improvement Percentage of Prediction Performance Evaluation Metric | ||
|---|---|---|---|---|
| RMSE | MAE | |||
| Beijing 1005A Station | M3 vs. M1 | 6.22% | 1.27% | 1.00% |
| M3 vs. M2 | 7.05% | 0.32% | 1.16% | |
| M4 vs. M3 | 3.05% | 8.52% | 0.44% | |
| M5 vs. M4 | 5.96% | 3.75% | 0.79% | |
| M5 vs. M1 | 14.50% | 13.07% | 2.25% | |
| M5 vs. M2 | 15.26% | 12.23% | 2.41% | |
| Wuhan 1328A Station | M3 vs. M1 | 1.14% | 10.56% | 0.15% |
| M3 vs. M2 | 0.52% | 6.27% | 0.07% | |
| M4 vs. M3 | 2.96% | 3.41% | 0.38% | |
| M5 vs. M4 | 7.91% | 4.76% | 0.93% | |
| M5 vs. M1 | 11.66% | 17.72% | 1.46% | |
| M5 vs. M2 | 11.11% | 13.77% | 1.39% | |
| Kunming 1454A Station | M3 vs. M1 | 6.83% | 4.22% | 2.19% |
| M3 vs. M2 | 0.13% | 3.04% | 0.03% | |
| M4 vs. M3 | 3.38% | 2.68% | 0.94% | |
| M5 vs. M4 | 21.33% | 14.01% | 4.97% | |
| M5 vs. M1 | 29.18% | 19.85% | 8.28% | |
| M5 vs. M2 | 24.09% | 18.86% | 5.99% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Hu, C. Hourly PM2.5 Concentration Prediction Based on Empirical Mode Decomposition and Geographically Weighted Neural Network. ISPRS Int. J. Geo-Inf. 2024, 13, 79. https://doi.org/10.3390/ijgi13030079
Chen Y, Hu C. Hourly PM2.5 Concentration Prediction Based on Empirical Mode Decomposition and Geographically Weighted Neural Network. ISPRS International Journal of Geo-Information. 2024; 13(3):79. https://doi.org/10.3390/ijgi13030079
Chicago/Turabian StyleChen, Yan, and Chunchun Hu. 2024. "Hourly PM2.5 Concentration Prediction Based on Empirical Mode Decomposition and Geographically Weighted Neural Network" ISPRS International Journal of Geo-Information 13, no. 3: 79. https://doi.org/10.3390/ijgi13030079
APA StyleChen, Y., & Hu, C. (2024). Hourly PM2.5 Concentration Prediction Based on Empirical Mode Decomposition and Geographically Weighted Neural Network. ISPRS International Journal of Geo-Information, 13(3), 79. https://doi.org/10.3390/ijgi13030079