A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets



Abstract
:1. Introduction
2. Spatio-Temporal Interpolation: Related Work and Our Strategy
2.1. Related Work
2.2. A Critical Analysis of Existing Work and Our Strategy
- (a)
- Currently, missing data in a spatio-temporal dataset are mainly estimated by using spatial interpolation methods—e.g., spatial regression models, SRT, IDW, kriging, and P-Bshade. The neglect of time dimension will lead to the loss of valuable information in the estimation of missing data; and
- (b)
- Although a few spatio-temporal interpolation methods are currently available for estimating missing data—e.g., STIDW and spatio-temporal kriging—the heterogeneity (i.e., second-order non-stationarity) of spatio-temporal data should be further considered [35].
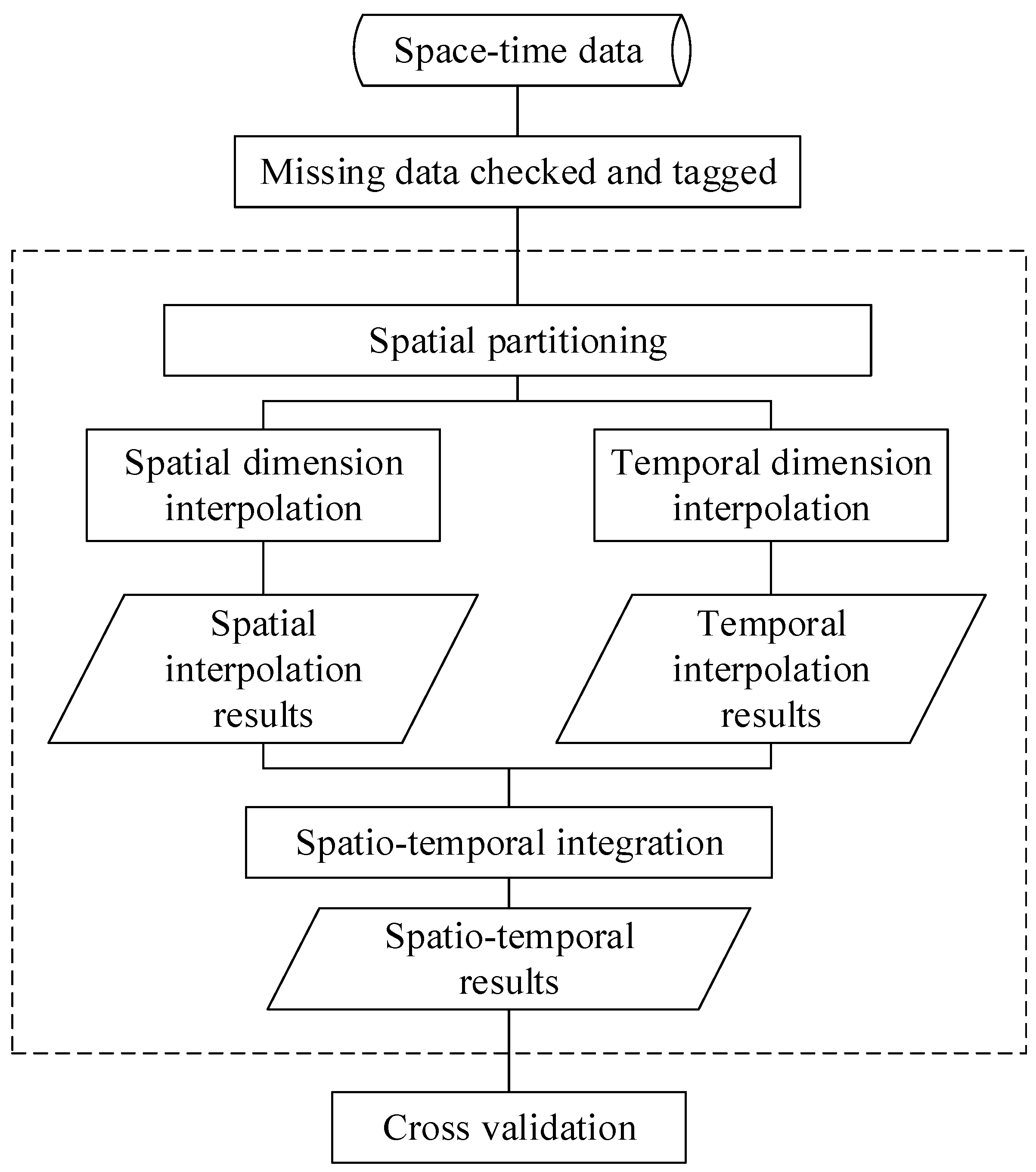
3. Hybrid Interpolation Method for Heterogeneous Spatio-Temporal Data
3.1. Heterogeneous Covariance Functions for Handling Space-Time Heterogeneity
3.2. Estimating Spatio-Temporal Missing Data by Combining Both Spatial and Temporal Information
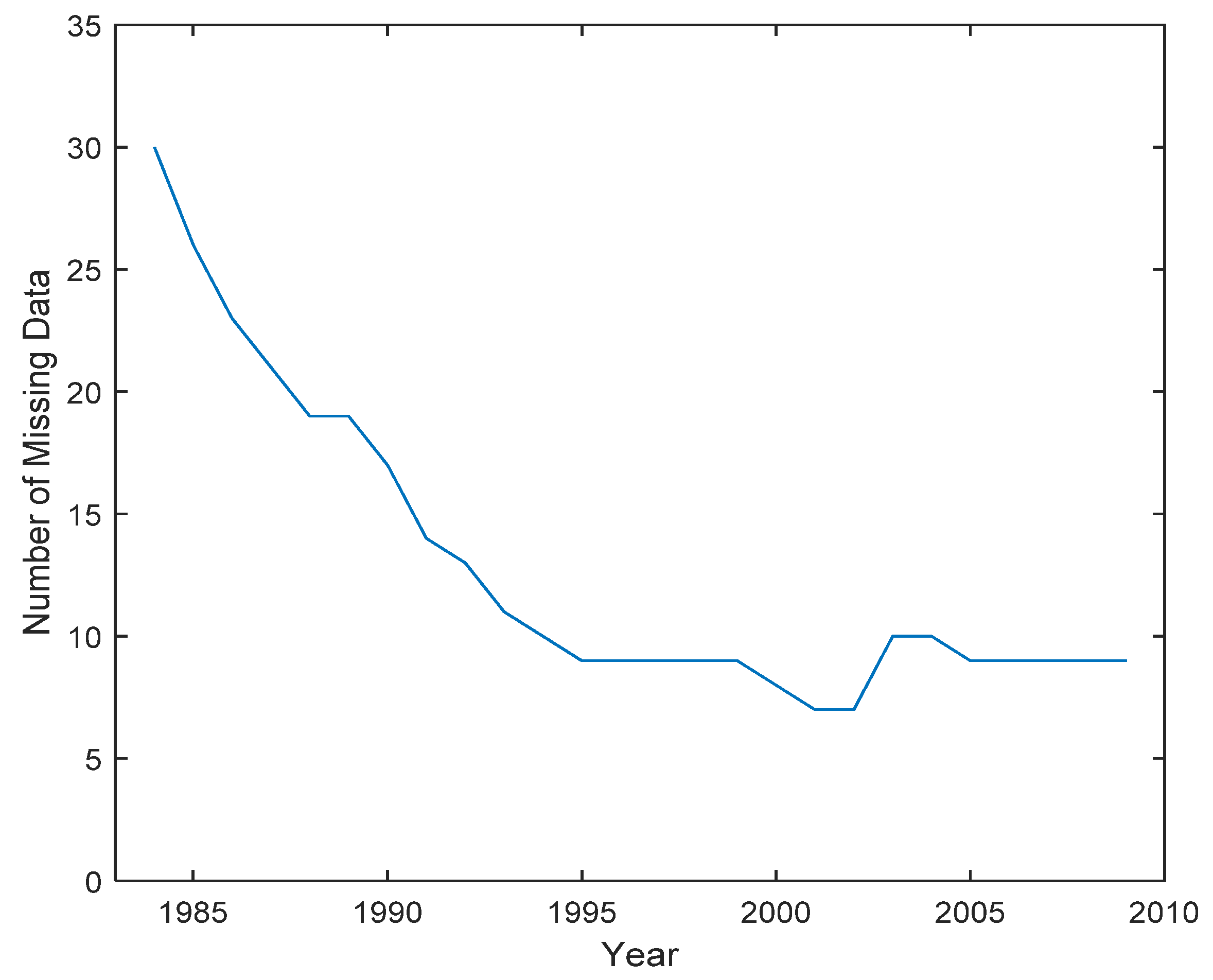
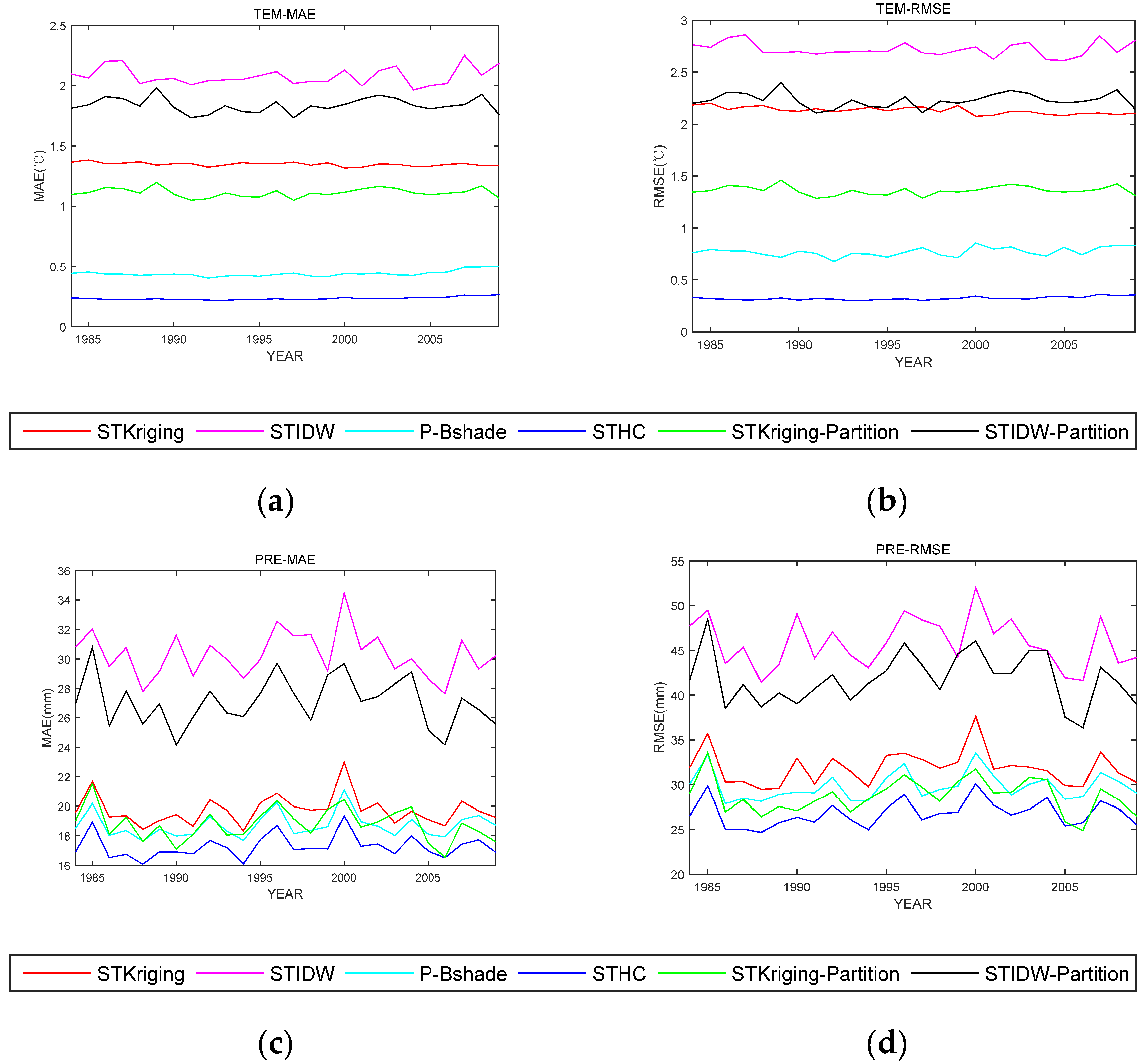
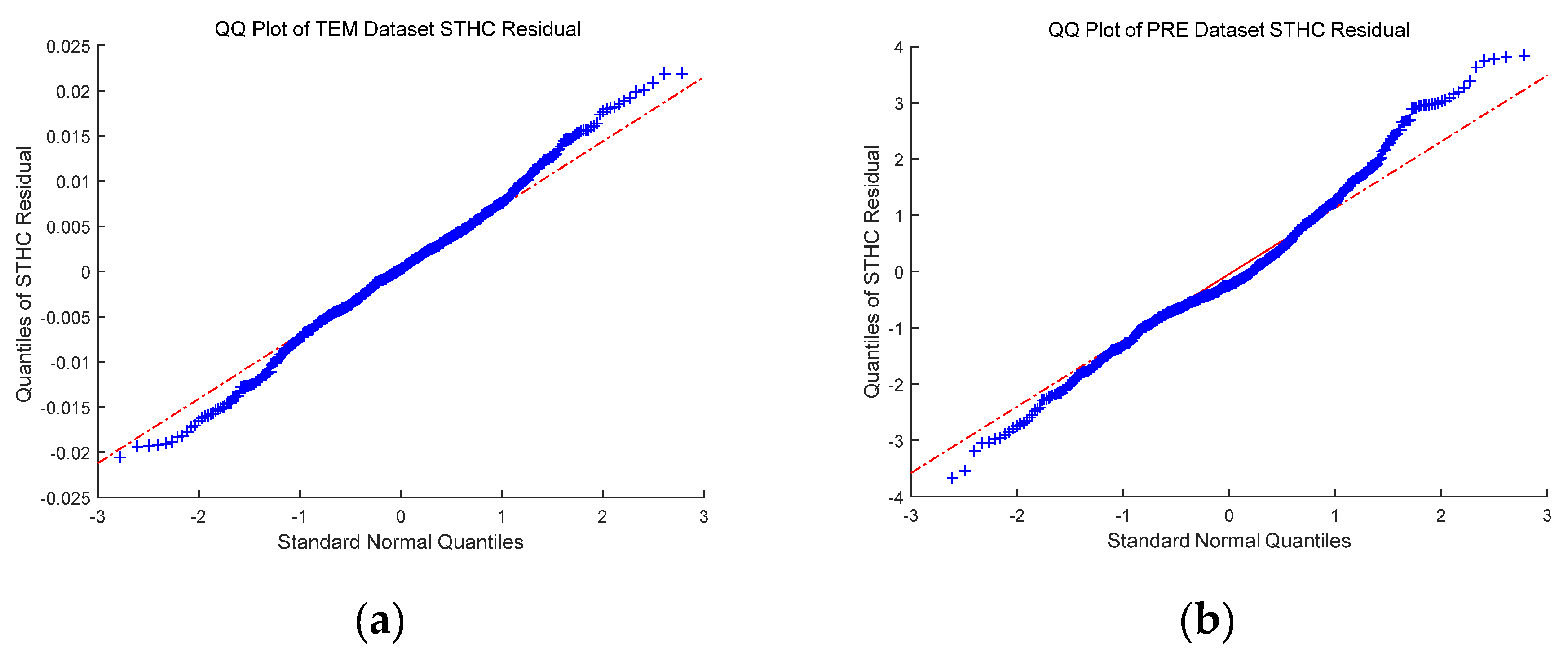
4. Experiments and Results Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Simpson, G.; Wu, Y. Accuracy and effort of interpolation and sampling: Can GIS help lower field costs? ISPRS Int. J. Geo-Inf. 2014, 3, 1317–1333. [Google Scholar] [CrossRef]
- Simolo, C.; Brunetti, M.; Maugeri, M.; Nanni, T. Improving estimation of missing values in daily precipitation series by a probability density function-preserving approach. Int. J. Climatol. 2010, 30, 1564–1576. [Google Scholar] [CrossRef]
- Curtarelli, M.; Leão, J.; Ogashawara, I.; Lorenzzetti, J.; Stech, J. Assessment of spatial interpolation methods to map the bathymetry of an Amazonian hydroelectric reservoir to aid in decision making for water management. ISPRS Int. J. Geo-Inf. 2015, 4, 220–235. [Google Scholar] [CrossRef]
- Tang, W.Y.; Kassim, A.H.M.; Abubakar, S.H. Comparative studies of various missing data treatment methods—Malaysian experience. Atmos. Res. 1996, 42, 247–262. [Google Scholar] [CrossRef]
- Xu, C.-D.; Wang, J.-F.; Hu, M.G.; Li, Q. Interpolation of missing temperature data at meteorological stations using P-BSHADE. J. Clim. 2013, 26, 7452–7463. [Google Scholar] [CrossRef]
- De Cesare, L.; Myers, D.E.; Posa, D. Estimating and modeling space-time correlation structures. Stat. Probab. Lett. 2001, 51, 9–14. [Google Scholar] [CrossRef]
- Kyriakidis, P.C.; Journel, A.G. Geostatistical space-time models: A review. Math. Geol. 1999, 31, 651–684. [Google Scholar] [CrossRef]
- Kilibarda, M.; Tadic, M.P.; Hengl, T.; Lukovic, J.; Bajat, B. Publicly Available Global Meteorological Data Sets: Sources, Representation, and Usability for Spatio-temporal Analysis. Available online: http://dailymeteo.org/content/publicly-available-global-meteorological-data-sets-sources-representation-and-usability (accessed on 30 November 2015).
- Wang, J.; Xu, C.; Hu, M.; Li, Q.; Yan, Z.; Zhao, P.; Jones, P. A new estimate of the China temperature anomaly series and uncertainty assessment in 1900–2006. J. Geophys. Res.: Atmos. 2014, 119, 1–9. [Google Scholar] [CrossRef]
- De Iaco, S.; Myers, D.E.; Posa, D. Space-time variograms and a functional form for total air pollution measurements. Comput. Stat. Data Anal. 2002, 41, 311–328. [Google Scholar] [CrossRef]
- Li, L.; Revesz, P. Interpolation methods for spatio-temporal geographic data. Comput. Environ. Urban Syst. 2004, 28, 201–227. [Google Scholar] [CrossRef]
- Huang, B.; Wu, B.; Barry, M. Geographically and temporally weighted regression for modeling space-time variation in house prices. Int. J. Geogr. Inf. Sci. 2010, 24, 383–401. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data; Wiley: Hoboken, NJ, USA, 1993. [Google Scholar]
- Dutilleul, P.R.L. Spatio-Temporal Heterogeneity: Concepts and Analyses; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Goovaerts, P. Geostatistics for Natural Resources Evaluation; Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Anselin, L.; Bera, A.K.; Florax, R.; Yoon, M.J. Simple diagnostic tests for spatial dependence. Reg. Sci. Urban Econ. 1996, 26, 77–104. [Google Scholar] [CrossRef]
- Fotheringham, S.; Charlton, M.; Brunsdon, C. Geographically weighted regression: A natural evolution of the expansion method for spatial data analysis. Environ. Plan. A 1998, 30, 1905–1927. [Google Scholar] [CrossRef]
- Erdoğan, S. Modelling the spatial distribution of DEM error with geographically weighted regression: An experimental study. Comput. Geosci. 2010, 36, 34–43. [Google Scholar] [CrossRef]
- Lu, B.; Charlton, M.; Harris, P.; Fotheringham, A.S. Geographically weighted regression with a non-Euclidean distance metric: A case study using hedonic house price data. Int. J. Geogr. Inf. Sci. 2014, 28, 660–681. [Google Scholar] [CrossRef]
- Hubbard, K.G.; Goddard, S.; Sorensen, W.D.; Wells, N.; Osugi, N.N. Performance of quality assurance procedures for an applied climate information system. J. Atmos. Ocean. Technol. 2005, 22, 105–112. [Google Scholar] [CrossRef]
- Hubbard, K.G.; You, J. Sensitivity analysis of quality assurance using the spatial regression approach—A case study of the maximum/minimum air temperature. J. Atmos. Ocean. Technol. 2005, 22, 1520–1530. [Google Scholar] [CrossRef]
- Bartier, P.M.; Keller, C.P. Multivariate interpolation to incorporate thematic surface data using inverse distance weighting (IDW). Comput. Geosci. 1996, 22, 795–799. [Google Scholar] [CrossRef]
- Lu, G.Y.; Wong, D.W. An adaptive inverse-distance weighting spatial interpolation technique. Comput. Geosci. 2008, 34, 1044–1055. [Google Scholar] [CrossRef]
- Reynolds, K.M.; Madden, L.V. Analysis of epidemics using spatio-temporal autocorrelation. Phytopathology 1988, 78, 240–246. [Google Scholar] [CrossRef]
- Furrer, R.; Genton, M.G.; Nychka, D. Covariance tapering for interpolation of large spatial datasets. J. Comput. Graph. Stat. 2006, 15, 502–523. [Google Scholar] [CrossRef]
- Pardo-Iguzquiza, E.; Chica-Olmo, M. Geostatistics with the Matern semivariogram model: A library of computer programs for inference, Kriging and simulation. Comput. Geosci. 2008, 34, 1073–1079. [Google Scholar] [CrossRef]
- Pesquer, L.; Cortés, A.; Pons, X. Parallel ordinary Kriging interpolation incorporating automatic variogram fitting. Comput. Geosci. 2011, 37, 464–473. [Google Scholar] [CrossRef]
- Bhattacharjee, S.; Mitra, P.; Ghosh, S.K. Spatial interpolation to predict missing attributes in GIS using semantic Kriging. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4771–4780. [Google Scholar] [CrossRef]
- Ma, C. Spatio-temporal covariance functions generated by mixtures. Math. Geol. 2002, 34, 965–975. [Google Scholar] [CrossRef]
- Ma, C. Recent developments on the construction of spatio-temporal covariance models. Stochast. Environ. Res. Risk Assess. 2008, 22, 39–47. [Google Scholar] [CrossRef]
- De Iaco, S.; Myers, D.E.; Posa, D. Space-time analysis using a general product-sum model. Stat. Probab. Lett. 2001, 52, 21–28. [Google Scholar] [CrossRef]
- De Iaco, S.; Myers, D.E.; Posa, D. Non-separable space-time covariance models: Some parametric families. Math. Geol. 2002, 34, 23–42. [Google Scholar] [CrossRef]
- De Cesare, L.; Myers, D.E.; Posa, D. Product-sum covariance for space-time modeling: An environmental application. Environmetrics 2001, 12, 11–23. [Google Scholar] [CrossRef]
- Hu, M.-G.; Wang, J.-F.; Zhao, Y.; Jia, L. A B-SHADE based best linear unbiased estimation tool for biased samples. Environ. Model. Softw. 2013, 48, 93–97. [Google Scholar] [CrossRef]
- Wang, J.-F.; Li, X.-H.; Christakos, G.; Liao, Y.-L.; Zhang, T.; Gu, X.; Zheng, X.-Y. Geographical detectors-based health risk assessment and its application in the neural tube defects study of the Heshun region, China. Int. J. Geogr. Inf. Sci. 2010, 24, 107–127. [Google Scholar] [CrossRef]
- Guo, D. Regionalization with dynamically constrained agglomerative clustering and partitioning (REDCAP). Int. J. Geogr. Inf. Sci. 2008, 22, 801–823. [Google Scholar] [CrossRef]
- Kupfer, J.A.; Gao, P.; Guo, D. Regionalization of forest pattern metrics for the continental United States using contiguity constrained clustering and partitioning. Ecol. Inf. 2012, 9, 11–18. [Google Scholar] [CrossRef]
- Pelletier, B.; Dutilleul, P.; Larocque, G.; Fyles, J.W. Coregionalization analysis with a drift for multi-scale assessment of spatial relationships between ecological variables 1. Estimation of drift and random components. Environ. Ecol. Stat. 2009, 16, 439–466. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial, Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | TEM | PRE | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE (°C) | RMSE (°C) | r2 | Residual Autocorrelation | MAE (mm) | RMSE (mm) | r2 | Residual Autocorrelation | |
| STKriging | 1.43 | 2.20 | 0.990 | 0.25 | 19.93 | 38.56 | 0.864 | 0.77 |
| STIDW | 2.08 | 2.76 | 0.926 | 0.28 | 30.31 | 52.27 | 0.659 | 0.80 |
| STKriging-Partition | 1.13 | 1.45 | 0.994 | 0.23 | 19.13 | 33.39 | 0.879 | 0.72 |
| STIDW-Partition | 1.63 | 2.15 | 0.990 | 0.27 | 27.07 | 47.37 | 0.709 | 0.76 |
| P-Bshade | 0.41 | 0.50 | 0.996 | 0.25 | 18.69 | 35.20 | 0.870 | 0.68 |
| STHC | 0.23 | 0.33 | 0.998 | 0.20 | 17.26 | 31.64 | 0.909 | 0.63 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, M.; Fan, Z.; Liu, Q.; Gong, J. A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets. ISPRS Int. J. Geo-Inf. 2016, 5, 13. https://doi.org/10.3390/ijgi5020013
Deng M, Fan Z, Liu Q, Gong J. A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets. ISPRS International Journal of Geo-Information. 2016; 5(2):13. https://doi.org/10.3390/ijgi5020013
Chicago/Turabian StyleDeng, Min, Zide Fan, Qiliang Liu, and Jianya Gong. 2016. "A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets" ISPRS International Journal of Geo-Information 5, no. 2: 13. https://doi.org/10.3390/ijgi5020013
APA StyleDeng, M., Fan, Z., Liu, Q., & Gong, J. (2016). A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets. ISPRS International Journal of Geo-Information, 5(2), 13. https://doi.org/10.3390/ijgi5020013