
Towards Narrowing the Curation Gap—Theoretical Considerations and Lessons Learned from Decades of Practice


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The issue is not, that available training and tools do not support Research Data Management, e.g., [47], but rather that by the time they find their way to researchers they might already have moved on to more sophisticated methods requiring other tools. It might therefore be necessary to focus on very basic concepts independent of specific tools instead of trying to keep up with the pace of technological change.
- Curators often lack precise understanding of the actual practice of research and consequently risk being ignored by the research community in their daily practice and vice versa A good mutual understanding would be needed to prevent obstacles that can no longer be overcome once research projects have ended, e.g., [21,42,43].
- Research practices strongly depend on a specific research community’s methods, traditions, and standards, limiting the influence of “outsiders” such as curators.
- Researchers face a competitive environment and often have little if any incentives for managing their research data and other research activities, including cooperation among researchers, in such a way that would support curation.
- Total costs (time, resources) of curation may impede digital data curation and even become exorbitantly high.
2. An Intentionally Minimalist Archiving Concept
- Self-containment The main purpose was to ensure the long-term use of the data for research occurring over decades. The archive also needed to be self-contained, i.e., not only observational data and measurements (research data in the narrow sense), but also all involved software such as models, applications, and operating systems were archived. Even hardware was preserved when necessary. Copyright issues in conflict with self-containment were avoided by limiting access to the archive to the research group.
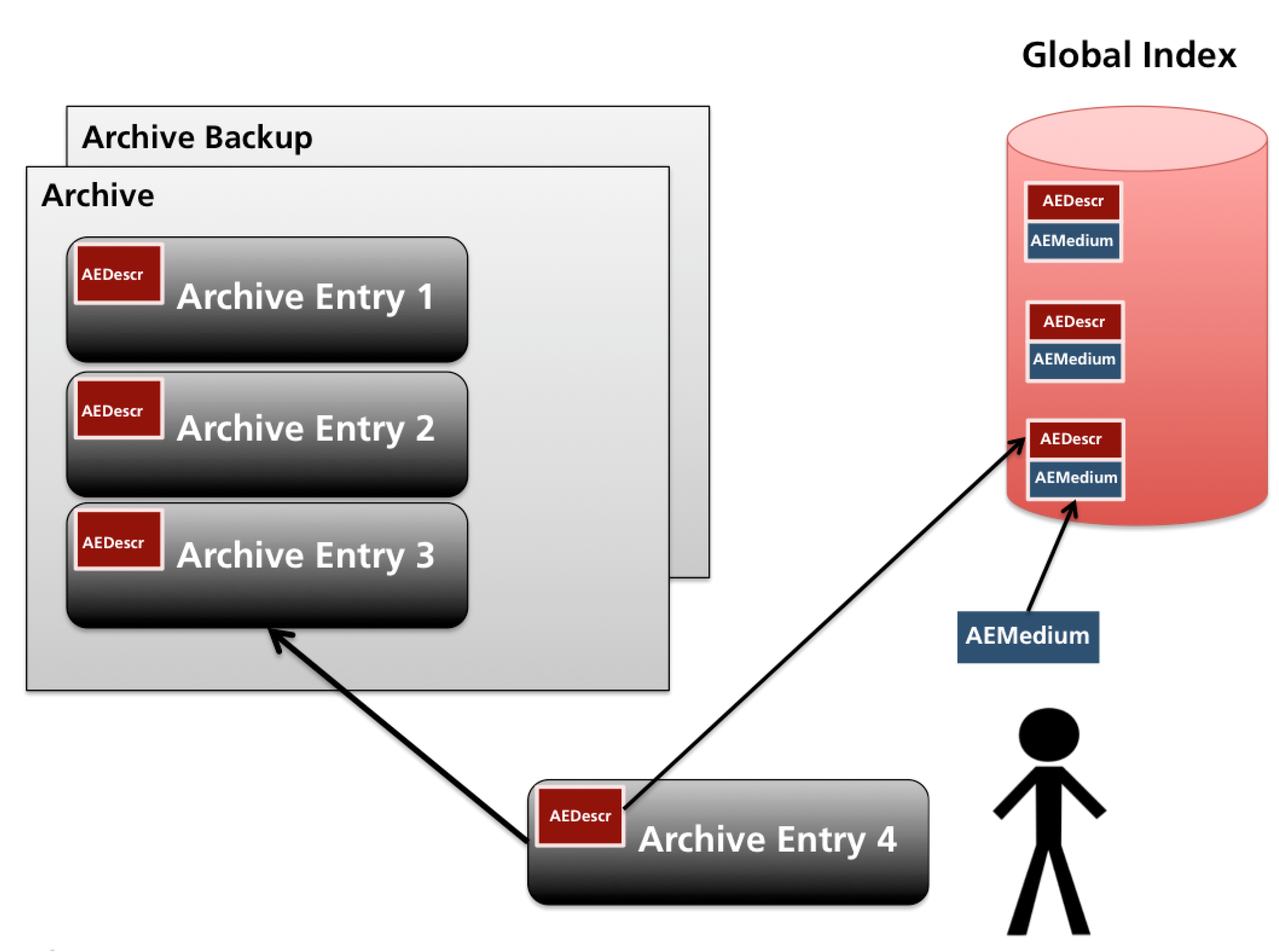
- Archive entries At the end of each project or a well-defined project phase, an archive entry was to be made (Figure 1, AEDescr). A research project was only considered really ended upon the completion of its last archive entry. Each entry comes with a description and is identified by a globally unique title and forms part of the archive. Thus, all of the archive’s meta data could anytime be reconstructed from the archive, also contributing to the self-containment of the archive.
- Meta data The meta data were split into the describing part and the media part (Figure 1, AEDescr vs. AEMedium; illustrative examples in Appendix A.1, Figure A1 vs. Figure A2), where the latter were kept outside the archive to be updated during regular maintenance, e.g., as storage media would age and require copying. Archive entries were only added and were not allowed to change in any way, regardless whether the storage media would in principle allow for overwriting or deletion. Updating of an archive entry would have to be accomplished by rearchiving an updated version. Finally data base software was not used on purpose. All these design choices served to minimize archive maintenance.
- Formats All meta data were only stored in simple ASCII encoded text files, while the actual data were typically archived in original formats. However, most critical parts, e.g., a dissertation text, were also redundantly archived as rtf, plus text files, or spreadsheets containing precious data, again redundantly, such as SYLK, plus text files (for details see Appendix A.1).
- Storage media Access to the individual archive entries depends on the file system in use, which may follow standards or not, depending on the storage media. E.g., magneto-optical disks, favoured due to their expected long lifetime of 50 years, were pragmatically formatted with the then used computer platform, possibly requiring archive maintenance at some point in time by moving affected entries to new media. CDs or DVDs were burnt according to ISO standards.
- Access and use To facilitate the retrieval, a Global Index (Figure 1, red cylinder), i.e., a global collection of archive entry descriptions, was stored redundantly outside the archive on a central file server that every researcher could access. In this ASCII text file all archive entry descriptions, extended by their media descriptions, were accumulated in chronological order. The search for a particular archive entry depends on the searching capabilities of a text editor or a command line tool such as grep. Since the primary role of the Systems Ecology Archive was to enable the internal use of data for research purposes, access was restricted to research team members only.
3. Handling of Research Data
4. Publishing and Literature Management
4.1. Scholarly Publishing
4.2. Literature Management
 ) making it necessary to use several reference manager tools (EndNote, Mendeley,
) making it necessary to use several reference manager tools (EndNote, Mendeley,  , etc. (The listed reference manager tools are listed and discussed here rather arbitrarily and no favouring nor criticism of any of these products is intended. We shortlisted here merely a few of the more popular ones as representative for many others.)). (ii) The use of such tools may be prescribed by publishers or is decided by an author team and is thus beyond the full control of the individual researcher. (iii) Many of today’s most popular reference manager tools are not based on a solid data base foundation by violating basics of data base theory (lack of a primary data base key, e.g., EndNote, Mendeley) or considering basically the researcher to be the only author of an article (e.g., EndNote) or by having insufficient provisions for reliable import, export, and updating of records (e.g., Mendeley), let alone the curation of the involved data. (iv) More or less competing meta data repositories for scientific publications are offered by many, mostly internet based services. They are typically ahead of the individual researcher and economic reasons make it necessary to make good use of such services. However, these services often employ proprietary techniques preventing the flexible use and reuse of the involved meta data within a situation where several writing techniques are forced onto the researcher. In summary, there is no one size fits all solution available and it is unlikely to come in any foreseeable future. As a consequence, researchers have to continuously adapt their writing techniques and require a flexibility that is generally far beyond what is given by any of today’s services, let alone the relevant software tools.
, etc. (The listed reference manager tools are listed and discussed here rather arbitrarily and no favouring nor criticism of any of these products is intended. We shortlisted here merely a few of the more popular ones as representative for many others.)). (ii) The use of such tools may be prescribed by publishers or is decided by an author team and is thus beyond the full control of the individual researcher. (iii) Many of today’s most popular reference manager tools are not based on a solid data base foundation by violating basics of data base theory (lack of a primary data base key, e.g., EndNote, Mendeley) or considering basically the researcher to be the only author of an article (e.g., EndNote) or by having insufficient provisions for reliable import, export, and updating of records (e.g., Mendeley), let alone the curation of the involved data. (iv) More or less competing meta data repositories for scientific publications are offered by many, mostly internet based services. They are typically ahead of the individual researcher and economic reasons make it necessary to make good use of such services. However, these services often employ proprietary techniques preventing the flexible use and reuse of the involved meta data within a situation where several writing techniques are forced onto the researcher. In summary, there is no one size fits all solution available and it is unlikely to come in any foreseeable future. As a consequence, researchers have to continuously adapt their writing techniques and require a flexibility that is generally far beyond what is given by any of today’s services, let alone the relevant software tools. among others while authoring scientific works using Microsoft Office Word or , has shown that such a system works very well, remains efficient and supports research—in particular collaborative research—in many ways. Notably, this time-tested system is expected to support the use of existing tools in a pragmatic and flexible manner. This enables the individual researcher to switch tools on the fly, and as needed, when collaboration changes or merely when another scientific journal imposes the use of other specific tools on the researcher (e.g., Word vs. ). If tools change more permanently or other tools need to be incorporated, the system can co-evolve and even partly compensate for the many shortcomings and deficiencies that today’s more popular applications show when it comes to maintaining consistency.
among others while authoring scientific works using Microsoft Office Word or , has shown that such a system works very well, remains efficient and supports research—in particular collaborative research—in many ways. Notably, this time-tested system is expected to support the use of existing tools in a pragmatic and flexible manner. This enables the individual researcher to switch tools on the fly, and as needed, when collaboration changes or merely when another scientific journal imposes the use of other specific tools on the researcher (e.g., Word vs. ). If tools change more permanently or other tools need to be incorporated, the system can co-evolve and even partly compensate for the many shortcomings and deficiencies that today’s more popular applications show when it comes to maintaining consistency.- each participant can be globally uniquely denoted (e.g., by using the ORCID unique researcher identification.
- each publication is also globally uniquely denoted by a main key (e.g., DOI) within the distributed data base system that also identifies the owner
- all files, e.g., PDFs, associated with a given publication are named so that the file name contains the main key or allows to derive the main key to be derived
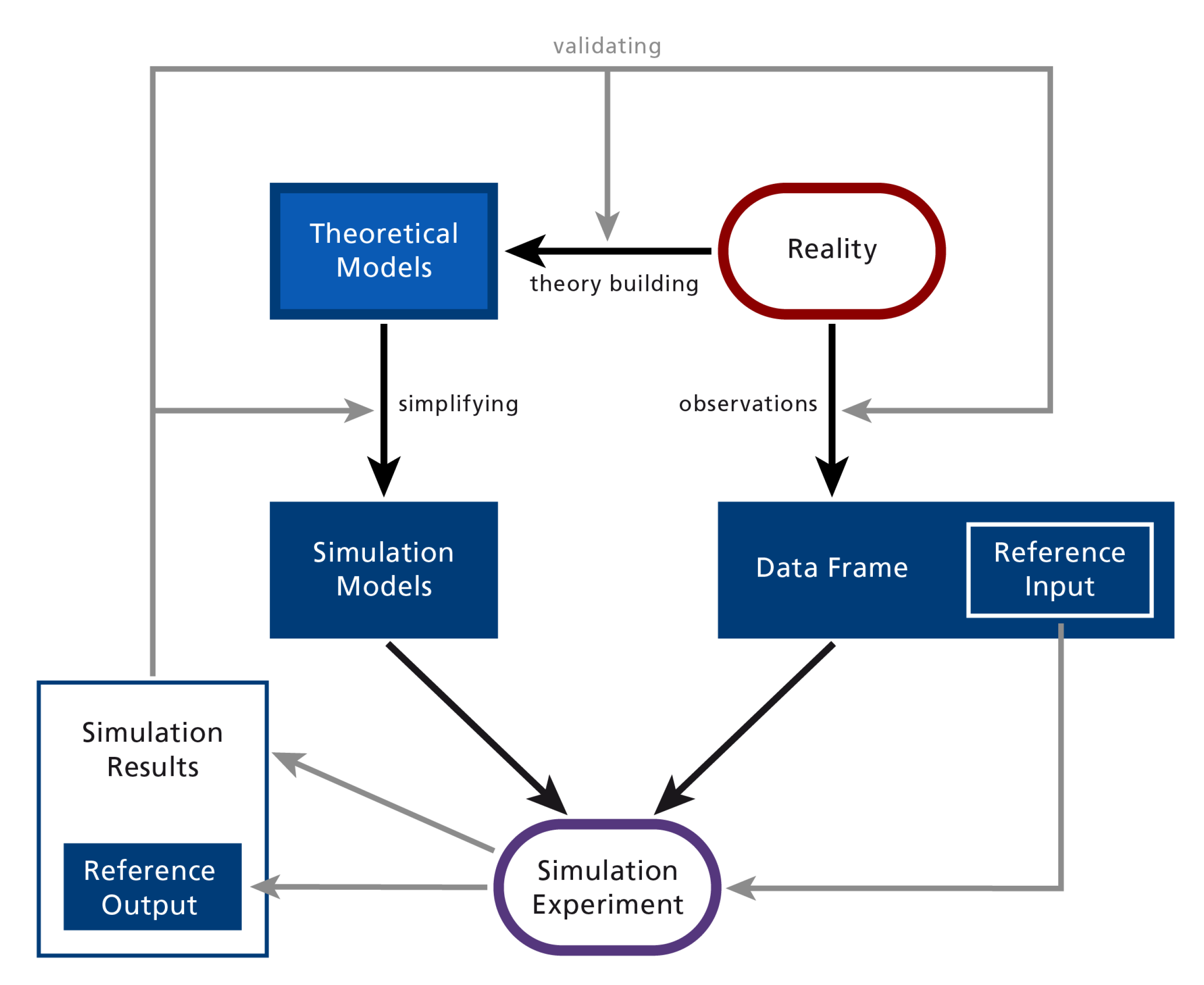
5. Theory and Models
6. General Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. Details on Archiving Concept of Terrestrial Systems Ecology Group


- (1)
- Discuss the planned entry with the group member responsible for archiving, as well as the group leader as appropriate. Is the moment right, what should be included, what was or will be archived elsewhere?
- (2)
- Prepare archive entry by moving and preparing all elements to be archived to a single folder as well as by sorting and deleting obsolete or redundant files. This step is crucial as it is where critical files are possibly transformed into file formats with a longer life expectancy (e.g., Word documents –> rtf, text, or spreadsheets –> SYLK files). Despite the principle of avoiding redundancy, the latter redundancy is intentional as it should help to maximize the archive’s long-term use. To this end additional copies are to be saved from critical documents that contain less information than their original, e.g., by force-saving a Word document in form of a plain text file hereby losing all formatting information. Thus a scientific article, if, e.g., written with Word, would be saved into the archive entry three times: (i) binary Word file (doc/docx), (ii) rtf (text file with formatting information), (iii) plain text file (text file without any formatting information). Finally to ensure reuse, e.g., for the purpose of an erratum writing or a continuation of the research, all original master files used in the preparation of figures or tables, e.g., statistical procedures such as R scripts, are included in the archive entry when archiving a scientific article, despite the publication of the latter. E.g., if using
![Ijgi 05 00091 i001]() , all
, all ![Ijgi 05 00091 i001]() -files needed as input for the full typesetting enter the archive in their original form in addition to the published PDF. The archive entry is only considered ready when procedures such as typesetting can be performed using the files in the archive. Common parts, e.g., modelling and simulation software, shared by many researchers can be left out, but such dependencies need to be discussed within the research team to ensure their parallel archiving is warranted.
-files needed as input for the full typesetting enter the archive in their original form in addition to the published PDF. The archive entry is only considered ready when procedures such as typesetting can be performed using the files in the archive. Common parts, e.g., modelling and simulation software, shared by many researchers can be left out, but such dependencies need to be discussed within the research team to ensure their parallel archiving is warranted. - (3)
- Create meta data, i.e., the archive entry description, for the archive entry (Figure A1). Each entry has to contain information regarding project title, version, list of parts, authors, description of the content, handling (which comprises also which software and/or hardware is necessary to read the data), general remarks, whether the project is part of a sub-project and has any cross-references, the archivist and creation date.
- (4)
- Add the archive entry description (Figure A1) to the archive entry itself. Optionally—particularly useful in case of large and complex archive entries—as the very last step affecting the archives content, some file listing tools can be used to scan the entire archive entry and add a detailed and exhaustive file list part to the archive entry, again in form of a text file.
- (5)
- Decide on the type and number of storage media required, e.g., magneto-optical (MO) disks, CDs, or DVDs, typically determined by the size of the archive entry. Use disks, e.g., MO disks, previously used if not yet full and the entry fits on it. Use multiple disks, e.g., DVDs, if the archive entry is too large to fit on a single disk (n:n relationship).
- (6)
- Write the media description on the archive entry to the separate small text file. These meta data describe the storage media, location and name of the media (Figure A2).
- (7)
- Save the archive entry to the archives twice. Once the above steps are completed to the satisfaction of the peer responsible for archiving, save the ready archive entry by copying twice the entire file system branch to the target storage media. Both copies must be identical and made to the same media, e.g., MO disk, CD, or DVD.
- (8)
- Append the archive entry description to the global index stored on a central file server (Figure 1).
- (9)
- Append the archive entry’s media description to the global index stored on a central file server. The global index now contains all meta data allowing access to any archive entry (Figure 1).
- (10)
- Optionally store the entry’s media description to a separate, also centrally stored media index tabulating all available archive media. That index is not critical (not shown in Figure 1) and only informs the archivist when periodic maintenance is due, i.e., which parts of the archive should be copied to new media as media ages and which media descriptions need updating.
- (11)
- Finally, store the archive media, e.g., two MO-disks, two CDs, or two DVDs, in two separate locations, i.e., in a safe and an archival cabinet in another building.
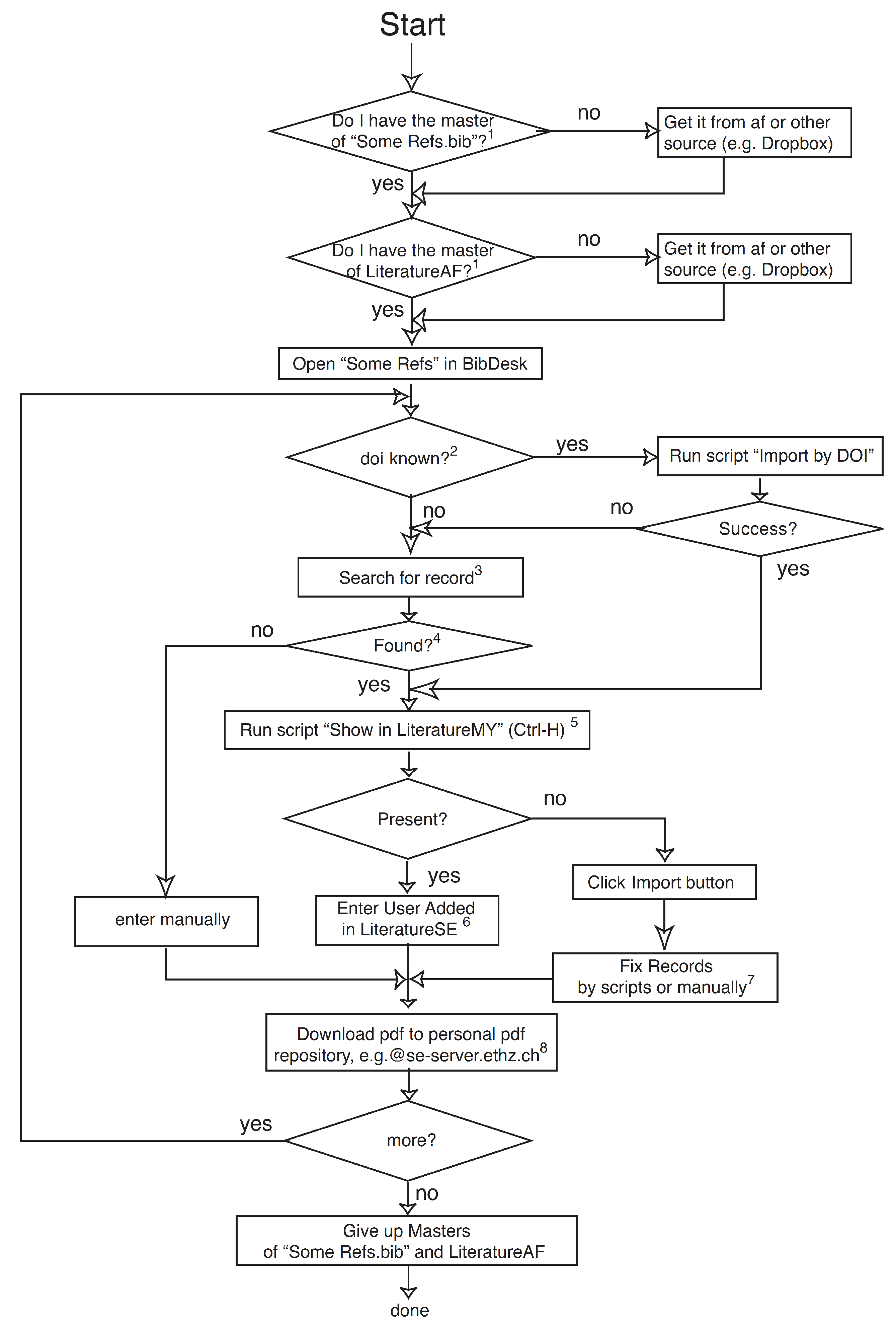
Appendix A.2. Reference Management
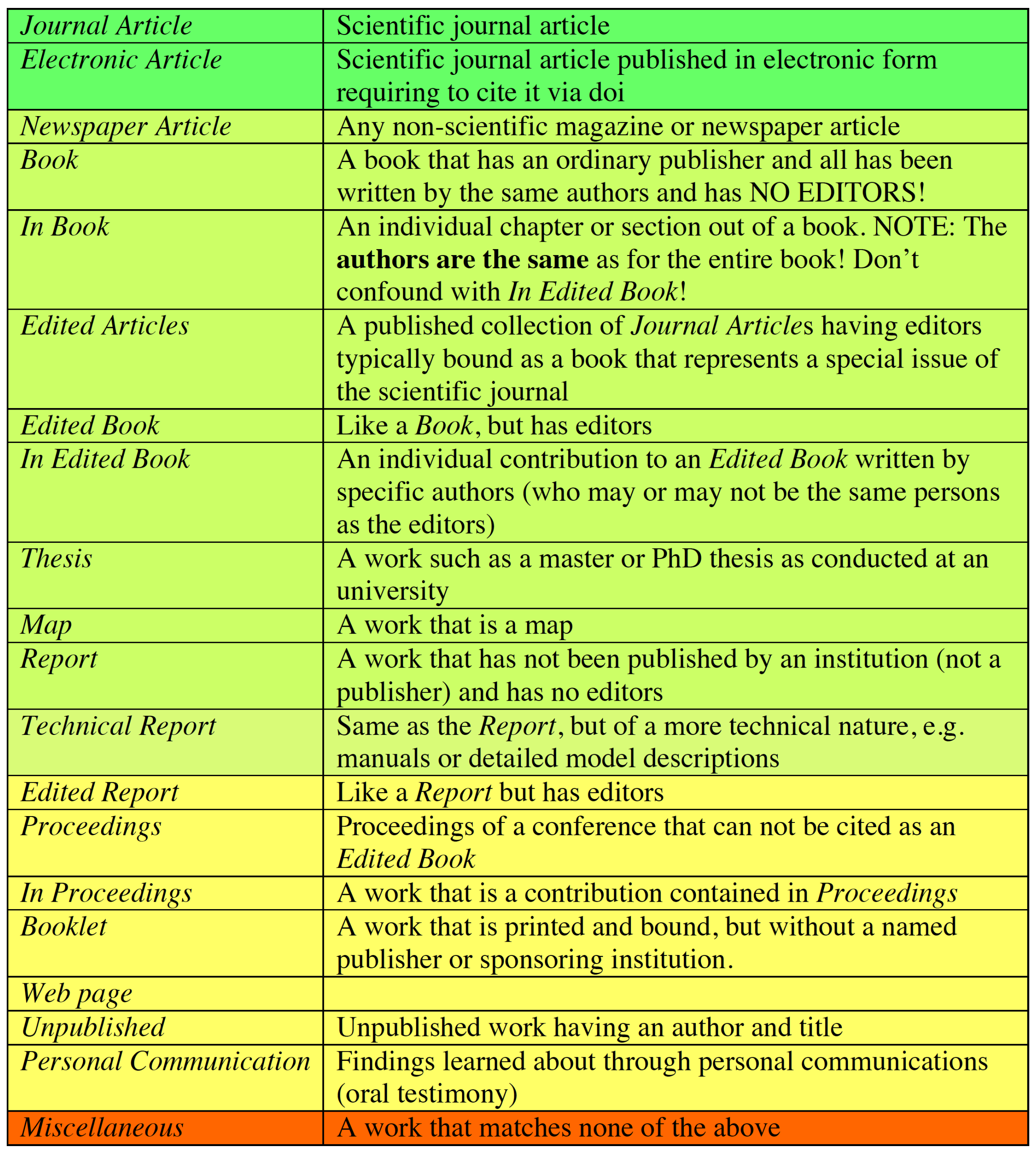
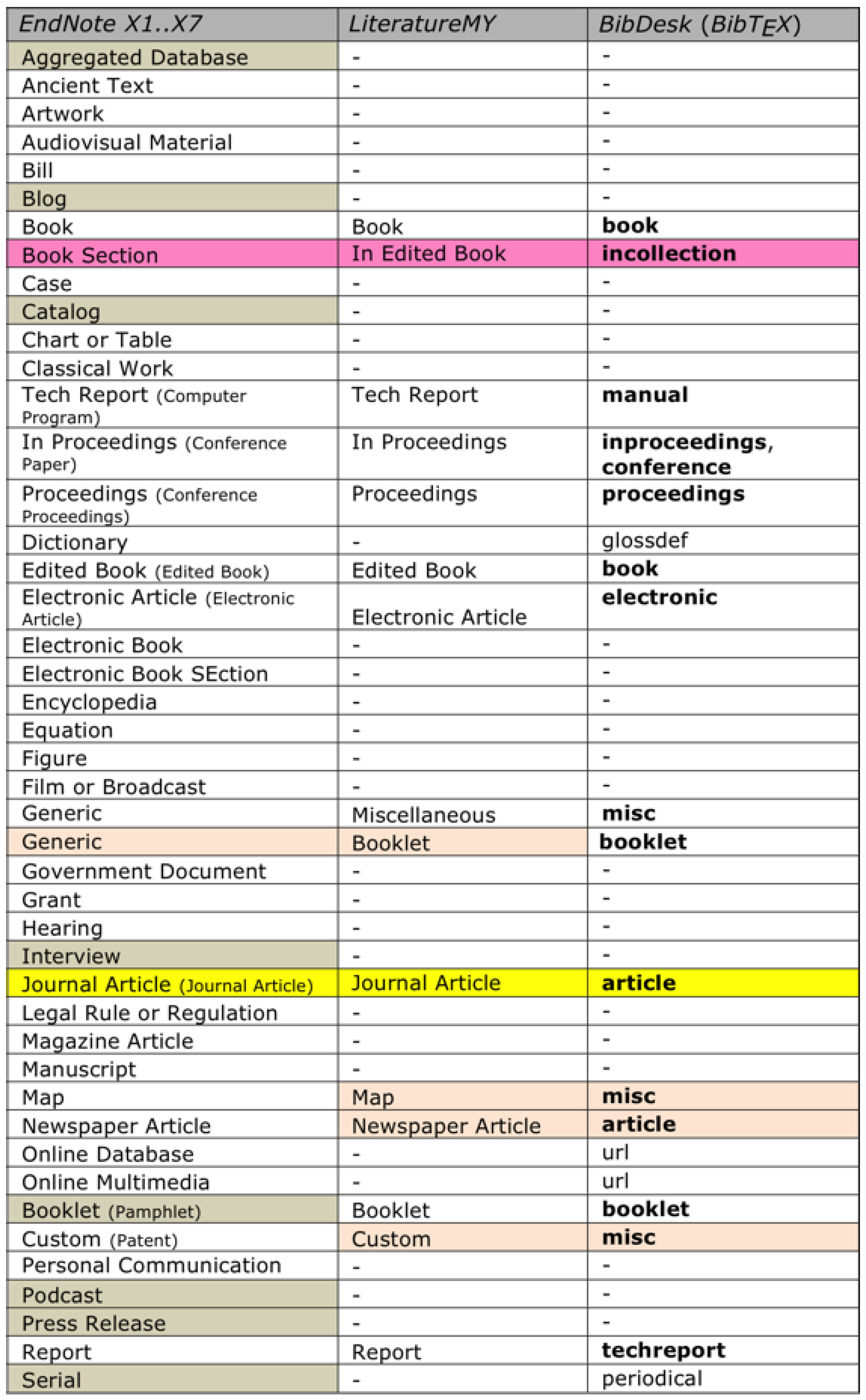
: entry types; EndNote: Reference Types; Mendeley: Type, etc.). The second column offers some explanations about the reference type and its use. The colors together with the sequence define priorities (top green highest, bottom red lowest) by which reference types ought to be used in cases where multiple possibilities exist.
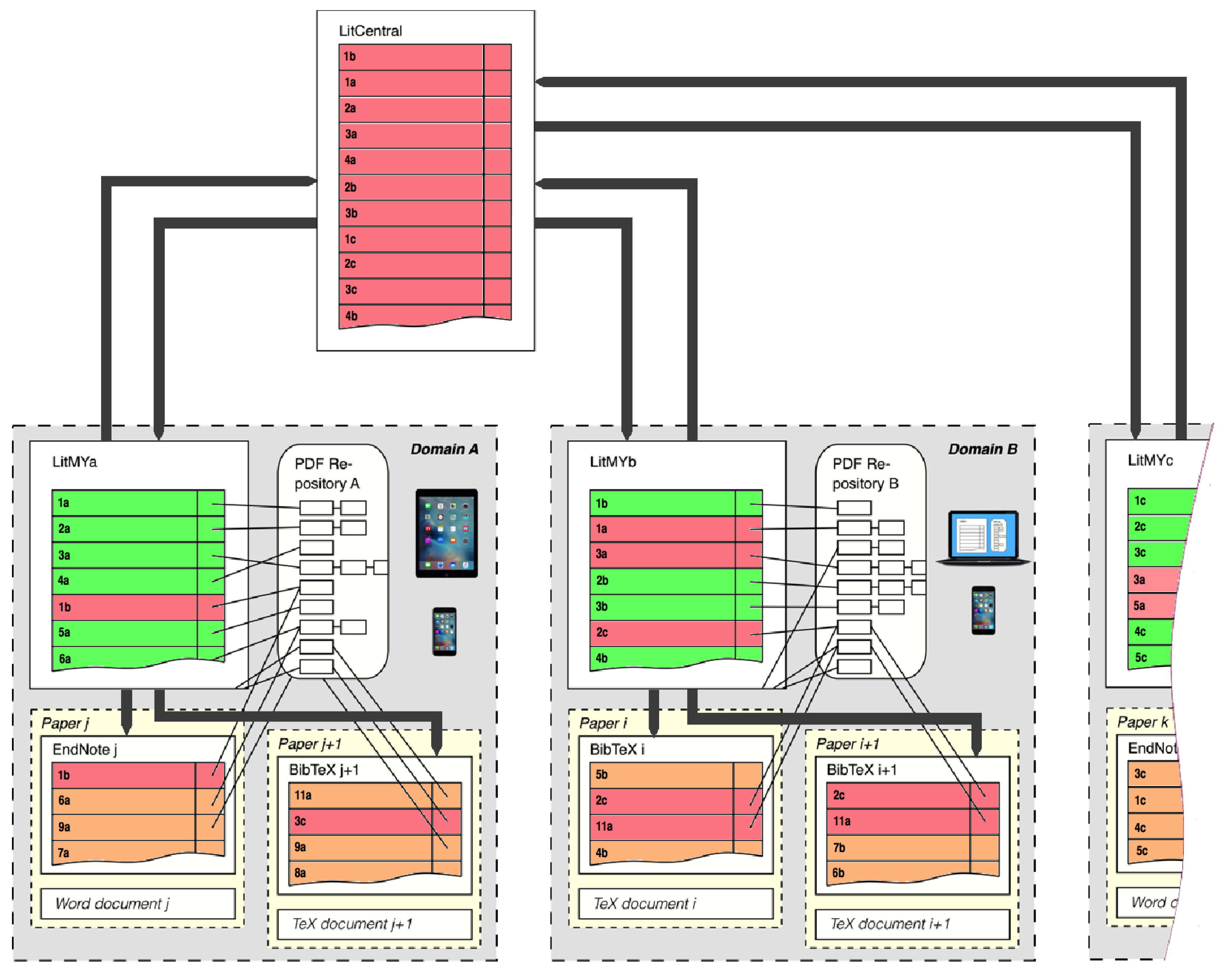
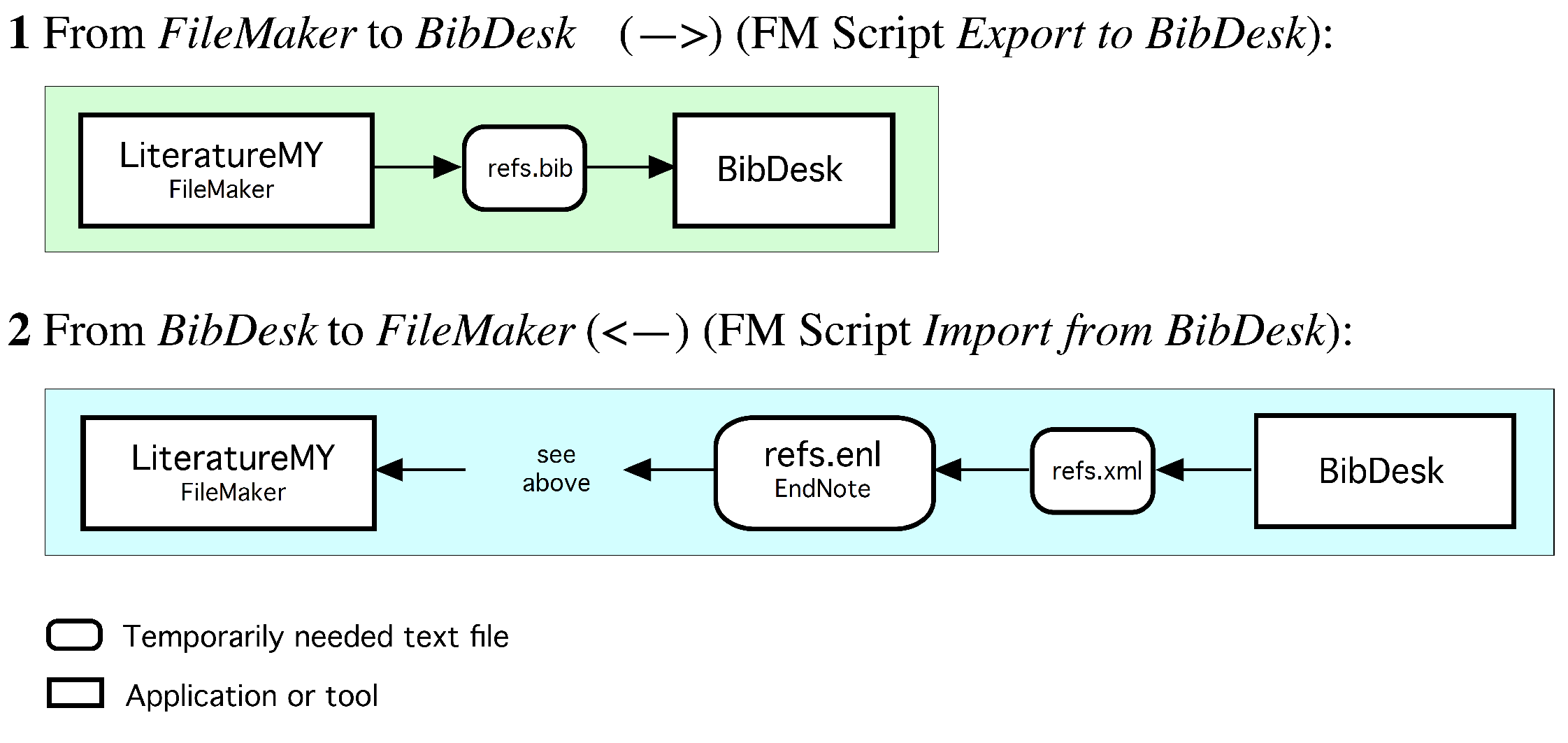
: entry types; EndNote: Reference Types; Mendeley: Type, etc.). The second column offers some explanations about the reference type and its use. The colors together with the sequence define priorities (top green highest, bottom red lowest) by which reference types ought to be used in cases where multiple possibilities exist. based BibDesk or EndNote or Mendeley. A task far from trivial. The set shown in Figure A3 has been in successful use many years and satisfies all requirements. However, it is mostly targeted for natural scientists and may not adequately support social scientists and humanities scholars. In particular, the set is likely to require some extension to serve legal scholars equally well. However, and more importantly, Figure A3 proposes reference types that are used commonly, yet surprisingly lack in some of the more popular reference managers (e.g., Mendeley). Among those are the reference types , , or , which, if lacking and consequently mix, e.g., with , prevent the generation of a proper and unambiguous list of references that, e.g., clearly distinguishes between editors and authors. files, e.g., when writing papers with . The central data base storing all records owned by a user is only the FileMaker data base (green records, Figure 5). Any project specific storage of read-only copies in EndNote bibliographies or /BibDesk files (orange records, Figure 5) contains an excerpted subset of the records. Any update of green records requires a retransfer from FileMaker to the project specific files EndNote bibliographies or /BibDesk files, overwriting any orange records possibly stored there (cf. Figure A4 and Figure A5).
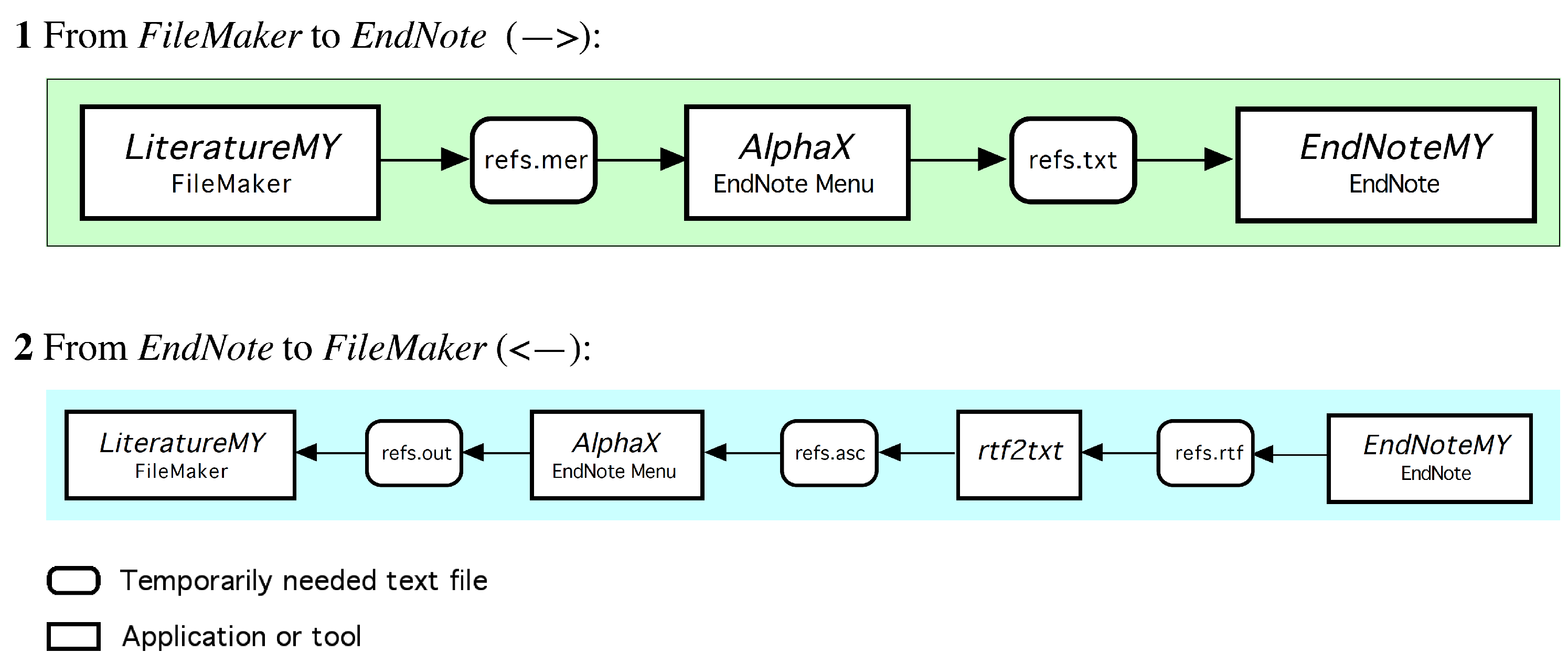
based BibDesk or EndNote or Mendeley. A task far from trivial. The set shown in Figure A3 has been in successful use many years and satisfies all requirements. However, it is mostly targeted for natural scientists and may not adequately support social scientists and humanities scholars. In particular, the set is likely to require some extension to serve legal scholars equally well. However, and more importantly, Figure A3 proposes reference types that are used commonly, yet surprisingly lack in some of the more popular reference managers (e.g., Mendeley). Among those are the reference types , , or , which, if lacking and consequently mix, e.g., with , prevent the generation of a proper and unambiguous list of references that, e.g., clearly distinguishes between editors and authors. files, e.g., when writing papers with . The central data base storing all records owned by a user is only the FileMaker data base (green records, Figure 5). Any project specific storage of read-only copies in EndNote bibliographies or /BibDesk files (orange records, Figure 5) contains an excerpted subset of the records. Any update of green records requires a retransfer from FileMaker to the project specific files EndNote bibliographies or /BibDesk files, overwriting any orange records possibly stored there (cf. Figure A4 and Figure A5). file BibDesk (see also Figure 5; BibDesk is a versatile, powerful open source manager for files). Transfers are possible in both directions, while the transfer from BibDesk to FileMaker is only used during the entering of new records. The use of any intermediate tools such as EndNote or the tcl based open source Text Editor AlphaX are fully automated and require no user intervention (cf. Figure A4).
file BibDesk (see also Figure 5; BibDesk is a versatile, powerful open source manager for files). Transfers are possible in both directions, while the transfer from BibDesk to FileMaker is only used during the entering of new records. The use of any intermediate tools such as EndNote or the tcl based open source Text Editor AlphaX are fully automated and require no user intervention (cf. Figure A4).
file BibDesk (see also Figure 5; BibDesk is a versatile, powerful open source manager for files). Transfers are possible in both directions, while the transfer from BibDesk to FileMaker is only used during the entering of new records. The use of any intermediate tools such as EndNote or the tcl based open source Text Editor AlphaX are fully automated and require no user intervention (cf. Figure A4).
file BibDesk (see also Figure 5; BibDesk is a versatile, powerful open source manager for files). Transfers are possible in both directions, while the transfer from BibDesk to FileMaker is only used during the entering of new records. The use of any intermediate tools such as EndNote or the tcl based open source Text Editor AlphaX are fully automated and require no user intervention (cf. Figure A4). .
.
.
.
Appendix A.3. Modelling and Simulation

References
- Bunge, M. Scientific Research I: The Search for System; Studies in the Foundations Methodology and Philosophy of Science; Springer: Berlin, Germany, 1967. [Google Scholar]
- Bunge, M. Scientific Research II: The Search for Truth; Studies in the Foundations Methodology and Philosophy of Science; Springer: Berlin, Germany, 1967. [Google Scholar]
- Popper, K.R. Conjectures and Refutations: The Growth of Scientific Knowledge; Routledge & Kegan Paul: New York, NY, USA, 1963. [Google Scholar]
- Popper, K. Objective Knowledge: An Evolutionary Approach; Clarendon Press: Oxford, UK, 1972. [Google Scholar]
- Pearce-Moses, R. A Glossary of Archival and Records Terminology; The Society of American Archivists (SAA): Chicago, IL, USA, 2005. [Google Scholar]
- Whyte, A.; Job, D.; Giles, S.; Lawrie, S. Meeting curation challenges in a neuroimaging group. Int. J. Digit. Curation 2008, 3, 171–181. [Google Scholar] [CrossRef]
- Baltensweiler, W.; Fischlin, A. The larch bud moth in the Alps. In Dynamics of Forest Insect Populations: Patterns, Causes, Implications; Berryman, A.A., Ed.; Plenum Publishing Corporation: New York, NY, USA, 1988; Volume 1, pp. 331–351. [Google Scholar]
- Baltensweiler, W.; Fischlin, A. On methods of analyzing ecosystems: Lessons from the analysis of forest-insect systems. Ecol. Stud. 1987, 61, 401–415. [Google Scholar]
- Fischlin, A.; Baltensweiler, W. Systems analysis of the larch bud moth system. Part I: The larch-larch bud moth relationship. Mitt. Schweiz. Ent. Ges. 1979, 52, 273–289. [Google Scholar]
- Ruchti, J.; Fischlin, A.; Strässler, E. DDLDML. Hilfsprogramm für PASCAL Programmierer zur Definition und Verwaltung von INFOSYS-Datenfiles (MANUAL); Institut für Phytomedizin ETHZ (vormals Entomologisches Institut ETHZ): Zürich, Switzerland, 1978. [Google Scholar]
- Consultative Committee for Space Data Systems and Secretariat (CCSDS). Reference Model for an Open Archival Information System (OAIS)—Recommended Practice; CCSDS: Washington, DC, USA, 2012. [Google Scholar]
- Andre, P.Q.C.; Besser, H.; Elkington, N.; Garrett, J.; Gladney, H.; Hedstrom, M.; Hirtle, P.B.; Hunter, K.; Kelly, R.; Kresh, D.; et al. Preserving Digital Information: Report of the Task Force on Archiving of Digital Information; The Commission on Preservation and Access and The Research Libraries Group (RLG): New York, NY, USA, 1996. [Google Scholar]
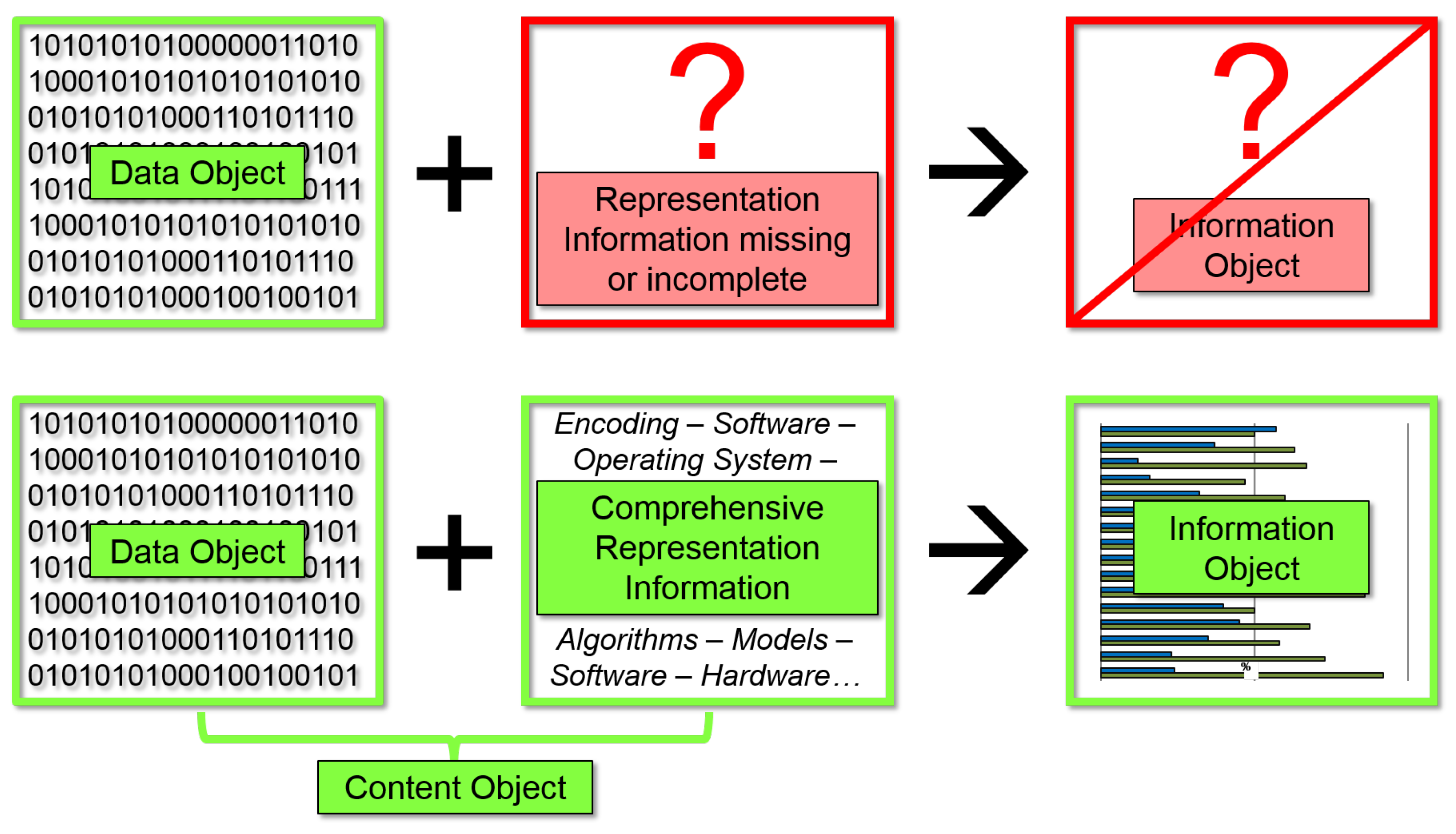
- Knight, G.; Pennock, M. Data without meaning: Establishing the significant properties of digital research. Int. J. Digit. Curation 2009, 4, 159–174. [Google Scholar] [CrossRef]
- Hsu, L.; Martin, R.L.; McElroy, B.; Litwin-Miller, K.; Kim, W. Data management, sharing, and reuse in experimental geomorphology: Challenges, strategies, and scientific opportunities. Geomorphology 2015, 244, 180–189. [Google Scholar] [CrossRef]
- Stafford, N. Science in the digital age. Nature 2010, 467, S19–S21. [Google Scholar] [CrossRef] [PubMed]
- Beagrie, N.; Lavoie, B.; Woollard, M. Keeping Research Data SAFE 2; JISC: Salisbury, UK, 2010. [Google Scholar]
- Beagrie, N.; Chruszcz, J.; Lavoie, B. Keeping Research Data Safe: A Cost Model and Guidance for UK Universities; JISC: Salisbury, UK, April 2008. [Google Scholar]
- Deridder, J.L. Benign neglect: Developing life rafts for digital content. Inf. Technol. Libr. 2011, 30, 71–74. [Google Scholar] [CrossRef]
- Kuipers, T.; van der Hoeven, J. Insights into Digital Preservation of Research Output in Europe: PARSE-Insight Survey Report D3.6; PARSE.Insight Project—Permanent Access to the Records of Science in Europe: Didcot, UK, 2010. [Google Scholar]
- Waller, M.; Sharpe, R. Mind the Gap—Assessing Digital Preservation Needs in The UK; Digital Preservation Coalition (DPC): York, UK, 2006. [Google Scholar]
- Nelson, B. Data sharing: Empty archives. Nature 2009, 461, 160–163. [Google Scholar] [CrossRef] [PubMed]
- Pryor, G. (Ed.) Managing Research Data; Facet Publishing: London, UK, 2012.
- Ayris, P.; Davies, R.; McLeod, R.; Miao, R.; Shenton, H.; Wheatley, P. The LIFE2 Final Project Report; Final Report (22/08/08); JISC, British Library, University College London, LIBER: London, UK, 2008. [Google Scholar]
- Burton, A.; Groenewegen, D.; Love, C.; Treloar, A.; Wilkinson, R. Making research data available in Australia. IEEE Intell. Syst. 2012, 27, 40–43. [Google Scholar] [CrossRef]
- Davidson, J.; Jones, S.; Molloy, L.; Kejser, U.B. Emerging good practice in managing research data and research information within UK universities. Proecedia Comput. Sci. 2014, 33, 215–222. [Google Scholar] [CrossRef]
- Kuipers, T.; van der Hoeven, J. Insights into Digital Preservation of Research Output in Europe: PARSE-Insight Survey Report; Insight Report D3.4; PARSE.Insight Project—Permanent Access to the Records of Science in Europe: Didcot, UK, 2009. [Google Scholar]
- Neuroth, H.; Strathmann, S.; Oßwald, A.; Scheffel, R.; Klump, J.; Ludwig, J. (Eds.) Digital Curation of Research Data—Experiences of a Baseline Study in Germany; Verlag Werner Hülsbusch: Glückstadt, Germany, 2013.
- OpenAIRE. OpenAIRE Horizon2020 Factsheets: Open Research Data Pilot in Horizon 2020. 2015. Available online: www.openaire.eu/or-data-pilot-factsheet (accessed on 3 June 2016).
- Pryor, G.; Jones, S.; Collins, E.; Whyte, A. (Eds.) Delivering Research Data Management Services: Fundamentals of Good Practice; Facet Publishing: London, UK, 2014.
- Tenopir, C.; Birch, B.; Allard, S. Academic Libraries and Research Data Services: Current Practices and Plans for the Future; Association of College and Research Libraries (ACRL): Chicago, IL, USA, 2012. [Google Scholar]
- Tenopir, C.; Sandusky, R.J.; Allard, S.; Birch, B. Research data management services in academic research libraries and perceptions of librarians. Libr. Inf. Sci. Res. 2014, 36, 84–90. [Google Scholar] [CrossRef]
- Palaiologk, A.S.; Economides, A.A.; Tjalsma, H.D.; Sesink, L.B. An activity-based costing model for long-term preservation and dissemination of digital research data: The case of DANS. Int. J. Digit. Libr. 2012, 12, 195–214. [Google Scholar] [CrossRef]
- Kejser, U.B.; Nielsen, A.B.; Thirifays, A. Cost model for digital preservation: cost of digital migration. Int. J. Digit. Curation 2011, 6, 255–267. [Google Scholar] [CrossRef]
- Carlson, D. A lesson in sharing. Nature 2011, 469, 293–293. [Google Scholar] [CrossRef] [PubMed]
- Björk, B.C.; Hedlund, T. A formalised model of the scientific publication process. Online Inf. Rev. 2004, 28, 8–21. [Google Scholar] [CrossRef]
- Thomas, A.; Campbell, L.M.; Barker, P.; Hawksey, M. (Eds.) Into the Wild: Technology for Open Educational Resources; University of Bolton: Bolton, UK, 2012.
- Van den Eynden, V.; Bishop, L. Sowing the Seed: Incentives and Motivations for Sharing Research Data, a Researcher’s Perspective; UK Data Archive, University of Essex: Essex, UK, 2014. [Google Scholar]
- Chu, H. Research methods in library and information science: A content analysis. Libr. Inf. Sci. Res. 2015, 37, 36–41. [Google Scholar] [CrossRef]
- Tammaro, A.M.; Casarosa, V. Research data management in the curriculum: An interdisciplinary approach. Proecedia Comput. Sci. 2014, 38, 138–142. [Google Scholar] [CrossRef]
- Jones, S. How to Develop a Data Management and Sharing Plan; DCC How-to Guides; Digital Curation Centre (DCC): Edinburgh, Scotland, 2011. [Google Scholar]
- Verbaan, E.; Cox, A.M. Occupational sub-cultures, jurisdictional struggle and third space: Theorising professional service responses to research data management. J. Acad. Libr. 2014, 40, 211–219. [Google Scholar] [CrossRef]
- Goodman, A.; Pepe, A.; Blocker, A.W.; Borgman, C.L.; Cranmer, K.; Crosas, M.; Di Stefano, R.; Gil, Y.; Groth, P.; Hedstrom, M.; et al. Ten simple rules for the care and feeding of scientific data. PLoS Comput. Biol. 2014, 10, e1003542. [Google Scholar] [CrossRef] [PubMed]
- Foster, N.F.; Gibbons, S. Understanding faculty to improve content recruitment for institutional repositories. D-Lib Mag. 2005, 11, 1–12. [Google Scholar] [CrossRef]
- Tenopir, C.; King, D.W. The use and value of scientific journals: past, present and future. Serials 2001, 14, 113–120. [Google Scholar] [CrossRef]
- Tenopir, C.; King, D.W.; Spencer, J.; Wu, L. Variations in article seeking and reading patterns of academics: What makes a difference? Libr. Inf. Sci. Res. 2009, 31, 139–148. [Google Scholar] [CrossRef]
- Morrow, T.; Beagrie, N.; Jones, M.; Chruszcz, J. A Comparative Study of E-Journal Archiving Solutions; Joint Information Systems Committee (JISC): Bristol, UK, 2008. [Google Scholar]
- Sutter, R.D.; Wainscott, S.B.; Boetsch, J.R.; Palmer, C.J.; Rugg, D.J. Practical guidance for integrating data management into long-term ecological monitoring projects. Wildl. Soc. Bull. 2015, 39, 451–463. [Google Scholar] [CrossRef]
- Waldrop, M.M. The origins of personal computing. Sci. Am. 2001, 285, 84–91. [Google Scholar] [CrossRef] [PubMed]
- Treloar, A.; Harboe-Ree, C. Data management and the curation continuum: How the Monash experience is informing repository relationships. In Proceedings of 14th Victorian Association for Library Automation, Conference and Exhibition, Melbourne, VIC, Australia, 5–7 February 2008.
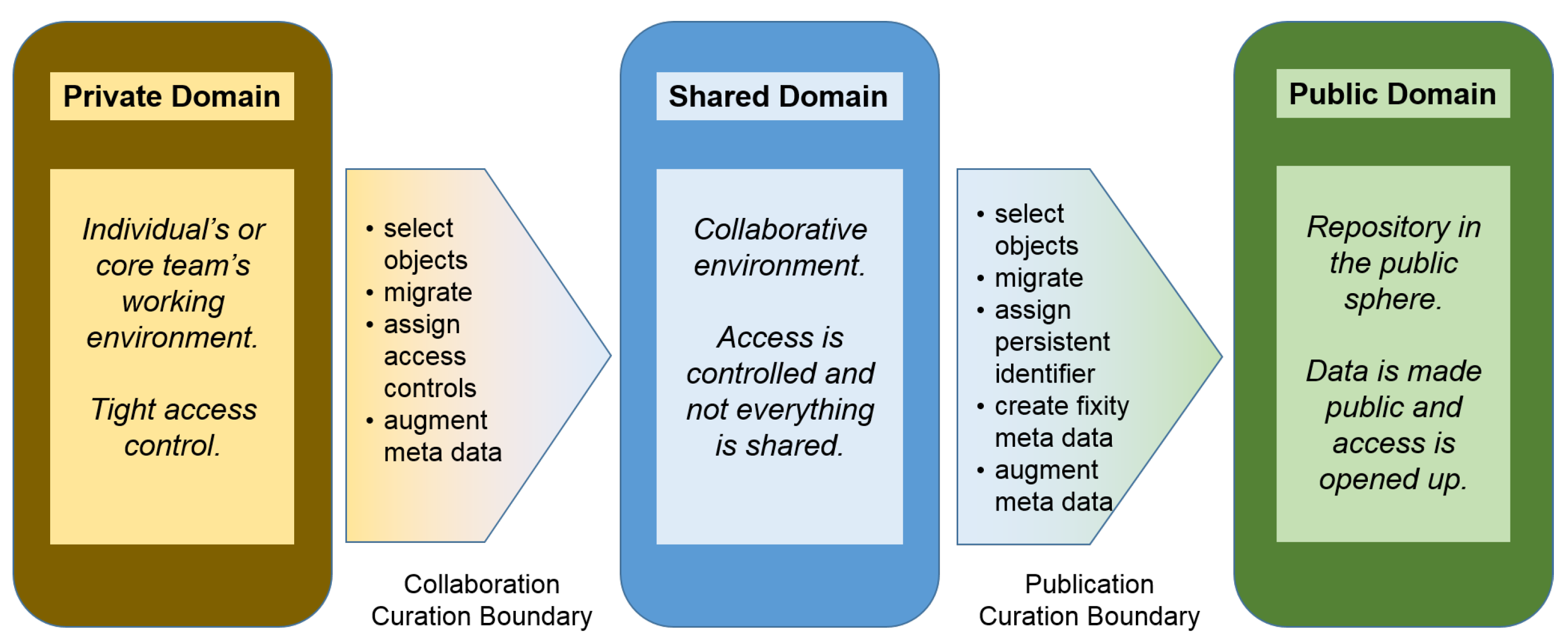
- Treloar, A. Private Research, Shared Research, Publication, and the Boundary Transitions, Version 1.4.3, 19 Mar 2012. Available online: andrew.treloar.net (accessed on 8 June 2016).
- CCSDS. Space Data and Information Transfer Systems—Open Archival Information System (OAIS)—Reference Model; ISO 14721:2012; Consultative Committee for Space Data Systems and International Organization for Standardization (ISO): Geneva, Switzerland, 2012. [Google Scholar]
- Bongulielmi, A.P.; Cellier, F.E. On the usefulness of deterministic grammars for simulation languages. ACM SIGSIM Simul. Digest 1984, 15, 14–36. [Google Scholar] [CrossRef]
- Zumstein, P.; Stöhr, M. Zur Nachnutzung von bibliographischen Katalog- und Normdaten für die persönliche Literaturverwaltung und Wissensorganisation. ABI Tech. 2015, 35, 210–221. [Google Scholar] [CrossRef] [Green Version]
- Zeigler, B.P. The five elements. In Theory of Modelling and Simulation, 1st ed.; Robert, E., Ed.; Krieger Publishing Company Inc.: Malabar, FL, USA, 1976; pp. 27–49. [Google Scholar]
- Zeigler, B.P. Multilevel multiformalism modeling: An ecosystem example. In Theoretical Systems Ecology; Halfon, E., Ed.; Academic Press: New York, NY, USA, 1979; pp. 17–54. [Google Scholar]
- Zeigler, B.P. Theory of Modelling and Simulation, 1st ed.; Robert, E., Ed.; Krieger Publishing Company Inc.: Malabar, FL, USA, 1976. [Google Scholar]
- Wymore, A.W. Theory of systems. In Handbook of Software Engineering; Vick, C.R., Ramamoorthy, C.V., Eds.; Van Nostrand Reinhold Company: New York, NY, USA, 1984; pp. 119–133. [Google Scholar]
- Fischlin, A. Interactive modeling and simulation of environmental systems on workstations. In Analysis of Dynamic Systems in Medicine, Biology, and Ecology; Möller, D.P.F., Richter, O., Eds.; Springer: Berlin, Germany, 1991; Volume 275, pp. 131–145. [Google Scholar]
- Nemecek, T. The Role of Aphid Behavior in the Epidemiology of Potato Virus Y: A Simulation Study; Diss. ETH No. 10086; Swiss Federal Institute of Technology: Zürich, Switzerland, 1993. [Google Scholar]
- Androulakis, S.; Buckle, A.M.; Atkinson, I.; Groenewegen, D.; Nicholas, N.; Treloar, A.; Beitz, A. ARCHER—E-Research tools for research data management. Int. J. Digit. Curation 2009, 4, 22–33. [Google Scholar] [CrossRef]
- Kunkel, R.; Sorg, J.; Kolditz, O.; Rink, K.; Klump, J.; Gasche, R.; Neidl, F. TEODOOR—A spatial data infrastructure for terrestrial observation data. In Proceedings of the 2013 IEEE 10th International Conference on Networking, Sensing and Control (ICNSC), Evry, France, 10–12 April 2013; pp. 242–245.
- Steffen, W.L.; Walker, B.H.; Ingram, J.S.I. Global Change and Terrestrial Ecosystems: The Operational Plan; Global Change Report No. 21; International Geosphere-Biosphere Program (IGBP): Stockholm, Sweden, 1992. [Google Scholar]
- GCTE - Global Change and Terrestrial Ecosystems. Available online: www.igbp.net/researchprojects/igbpcoreprojectsphaseone/globalchangeandterrestrialecosystems.4.1b8ae20512db692f2a680009018.html (accessed on 3 June 2016).
- Seitzinger, S.P.; Gaffney, O.; Brasseur, G.; Broadgate, W.; Ciais, P.; Claussen, M.; Erisman, J.W.; Kiefer, T.; Lancelot, C.; Monks, P.S.; et al. International Geosphere–Biosphere Programme and Earth system science: three decades of co-evolution. Anthropocene 2015, 12, 3–16. [Google Scholar] [CrossRef]









© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sesartić, A.; Fischlin, A.; Töwe, M. Towards Narrowing the Curation Gap—Theoretical Considerations and Lessons Learned from Decades of Practice. ISPRS Int. J. Geo-Inf. 2016, 5, 91. https://doi.org/10.3390/ijgi5060091
Sesartić A, Fischlin A, Töwe M. Towards Narrowing the Curation Gap—Theoretical Considerations and Lessons Learned from Decades of Practice. ISPRS International Journal of Geo-Information. 2016; 5(6):91. https://doi.org/10.3390/ijgi5060091
Chicago/Turabian StyleSesartić, Ana, Andreas Fischlin, and Matthias Töwe. 2016. "Towards Narrowing the Curation Gap—Theoretical Considerations and Lessons Learned from Decades of Practice" ISPRS International Journal of Geo-Information 5, no. 6: 91. https://doi.org/10.3390/ijgi5060091
APA StyleSesartić, A., Fischlin, A., & Töwe, M. (2016). Towards Narrowing the Curation Gap—Theoretical Considerations and Lessons Learned from Decades of Practice. ISPRS International Journal of Geo-Information, 5(6), 91. https://doi.org/10.3390/ijgi5060091