1. Introduction
Clustering analysis is the task of grouping a set of objects in such a way that the objects in the same group (called a cluster) are more similar to each other than to those in other groups (clusters). The clustering of geospatial objects has found wide applications in the fields of image segmentation, pattern recognition, and cartographic generalization [
1,
2,
3,
4,
5]. One of the main applications of clustering in Hyperspectral Remote Sensing is dimensionality reduction [
6,
7,
8]. The clustering analysis can be used in map generalization and vectorization [
9,
10] and some new clustering algorithms are applied to the segmentation of noise and signals in time-variant scenarios [
11]. However, in reality, clustering analysis is not a specific algorithm, but a task to be solved, which can be achieved by various algorithms that differ significantly in their definitions of cluster constituents and efficiency in finding them [
12]. The popular notion of clustering in geographical information is to classify geospatial objects with small distances between clusters, called spatial clustering.
Generally, spatial clustering classifies objects according to their topological, geometric or geographic properties. There are four types of traditional spatial clustering methods: the hierarchical clustering method, partitioning clustering method, grid density clustering method and clustering method based on preference information [
13]. Selecting an appropriate clustering method depends on the individual dataset and intended use of the results. Zhou [
14] suggested an N-best pruning strategy to minimize the search space in the working flow of the hierarchical clustering method. Gelbard [
15] employed the Binary-Positive method for combining attribute information in the hierarchical structure. In addition, Chen [
16] proposed revealing latent spatial information using spatial clustering of points in direction. Most of the abovementioned methods are not automatic processes. Instead, they are limited by the users’ prior knowledge and rather sensitive to noise. As a result, little attention is paid to the identification of multi-density geospatial objects and noise.
The multi-density clustering approach has been widely discussed in spatial data-mining research. The traditional Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm was improved to cluster multi-density data, such as Knowledge Discovery and Data Clustering (KDDClus), and an incremental clustering based on automatic Eps estimation [
17,
18]. The differences between multi-density objects and noise are mainly embodied in the spatial context. Gold [
19] defined the spatial context as the “extent” of an entity, including discrete objects, networks, and surfaces, while the extent usually refers to the metric proximity between neighbouring objects in the model space. In this paper, the spatial context can be interpreted as local spatial context only. To distinguish multi-density objects from noise, it is necessary to proceed from the global spatial context of geospatial objects. The hierarchical clustering method is a process of aggregating or splitting by building a hierarchy [
20]. In general, hierarchical clustering strategies fall into two categories: agglomerative hierarchical clustering (AHC) and divisive hierarchical clustering (DHC). DHC is a “top–down” approach, that is, all the geospatial objects start in one cluster and are split into two sub-clusters by the hierarchy. Geospatial objects are seen as a whole prior to cluster splitting. The clustering strategy is very close to the global spatial context of geospatial objects.
In this paper, an unsupervised clustering algorithm is proposed to handle geospatial objects, which takes the global context characteristics into consideration, depends less on prior knowledge, and enjoys a great advantage in identifying multi-density objects and noise.
The major contributions of this paper include:
(1) Introducing the global spatial context of geospatial objects to distinguish between noise points and multi-density points.
(2) A novel divisive hierarchical clustering algorithm is proposed to manage multi-density discrete objects, designing the boundary retraction structure to implement the whole divided into two sub-clusters.
(3) A comparison between the traditional agglomerative hierarchical clustering algorithm and the dividing hierarchical clustering algorithm is presented in this paper.
In
Section 2, we will describe the algorithm flowchart of novel clustering. This is followed by a description of the key step of the algorithm, boundary retraction, which is used to find the boundary of different clusters. Then, the splitting processing of discrete points will be presented, and clustering of multi-density discrete objects based on the less prior knowledge is achieved.
Section 3 will describe a series of experiments, including the comparison with the clustering algorithms, multi-density objects clustering and spatial analysis on Wuhan’s business circle. The subject of every experiment is different.
Section 4 will conclude the paper with a summary and outlook.
2. Methods
Wu [
21] proposed a global structural method to approximate aggregation characteristics of point cluster using the convex hull hierarchical structure. The global structure of geospatial points is aimed at revealing characteristics of points by ignoring individual differences. In this section, we first introduce the design thought and principle of the clustering algorithm in
Section 2.1. We then propose a hierarchical clustering method based on the global structure analysis by establishing the boundary retraction structure in
Section 2.2 and implement the divisive clustering of multi-density geospatial objects in
Section 2.3.
2.1. Design Concept and Principle
Compared to AHC algorithms, DHC algorithms start at the top with all objects in one cluster. The cluster is split based on the global structure analysis of geospatial objects. In the process of geospatial objects clustering, the convex hull is used to describe the global structure by regarding the objects as an “organism”. Considering that spatial differentiation characteristics of the “organism” are mainly embodied between the adjacency connected clusters, the following strategies are adopted in order to explore the underlying differences of spatial clusters and split the ”organism” with an appropriate terminate condition. At first, the retracting structure of geospatial objects is built based on the convex hull borderline. Then, similar to the process of cell division, the borderline is concave so that a cluster is split into two sub-clusters when the boundaries intersect.
2.2. Boundary Retraction
Zhou [
22] took the mean distance of geospatial objects as the constraint for convex hull boundary retraction. However, it is difficult to build a retracting structure of multi-density objects using invariant parameters. In this paper, the parabola-based convex hull retraction method is proposed, which is an adaptive way to obtain a cluster boundary for multi-density geospatial objects.
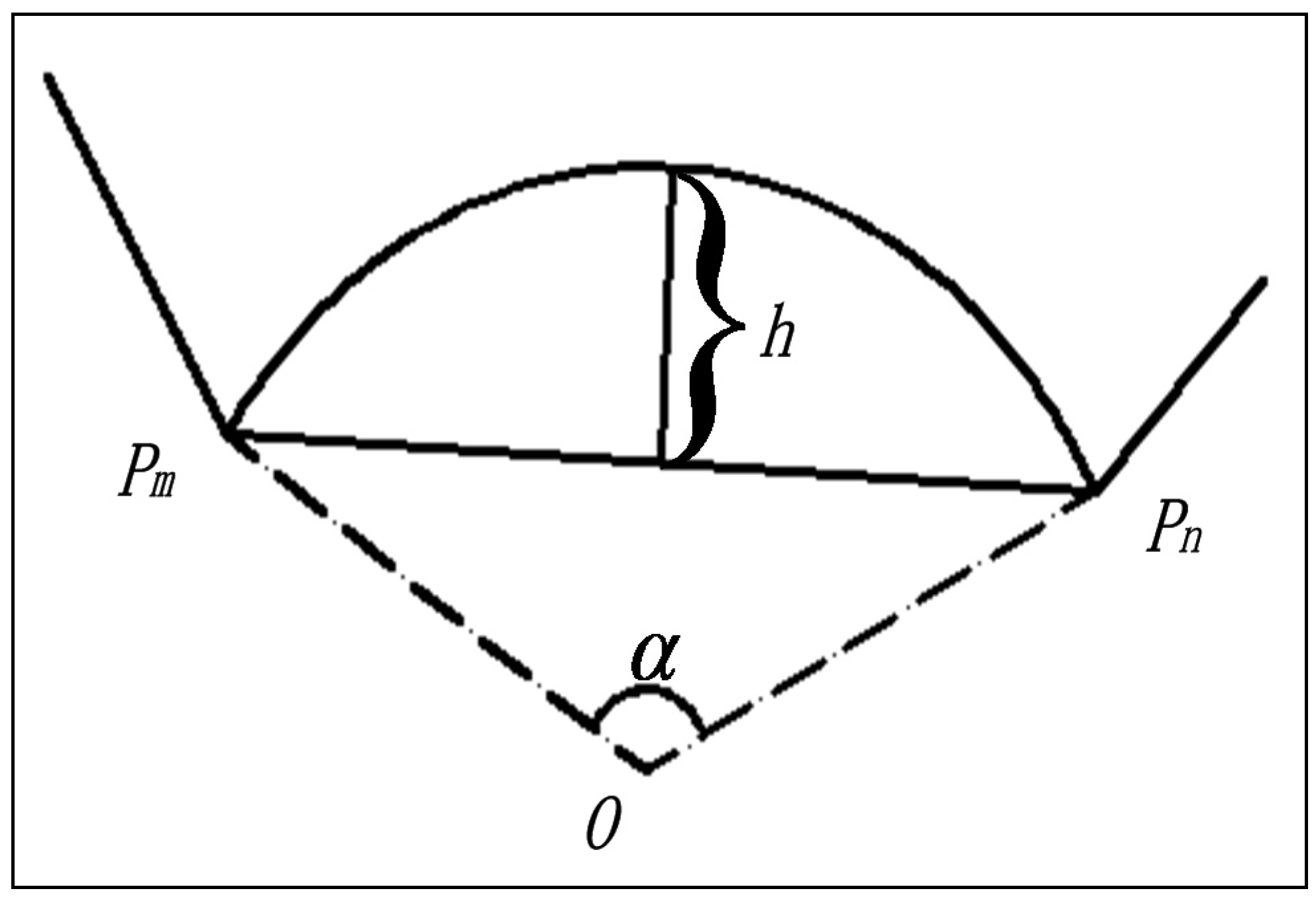
Li [
23] used an arc as a boundary to generate a retraction area. The concept of retracting accuracy (RA) is introduced to limit the accuracy of a clustering boundary. Thus, the retracting accuracy of a discrete point set P is obtained as follows:
- (a)
the convex hull Pc of the discrete point cluster P is constructed;
- (b)
an arc with the radian of α towards the inside of the convex hull is drawn through two consecutive points
Pm and
Pn in the convex hull
Pc (
Figure 1);
- (c)
the retracting accuracy α is made from the arc and line , and the retracting depth is h.
According to the arc-limited retracted method, during discrete boundary detection, the range of the retracting accuracy is in [0, π] and retracting depth is . The retracting depth will decrease with the length of the borderlines; therefore, using the arc-limited retracted method, it is difficult to make the borderlines intersect.
In this study, we modified the range of retracting accuracy in [0, 2π]. At the same time, we compared the arc-based method with the new parabola-based convex hull retraction method.
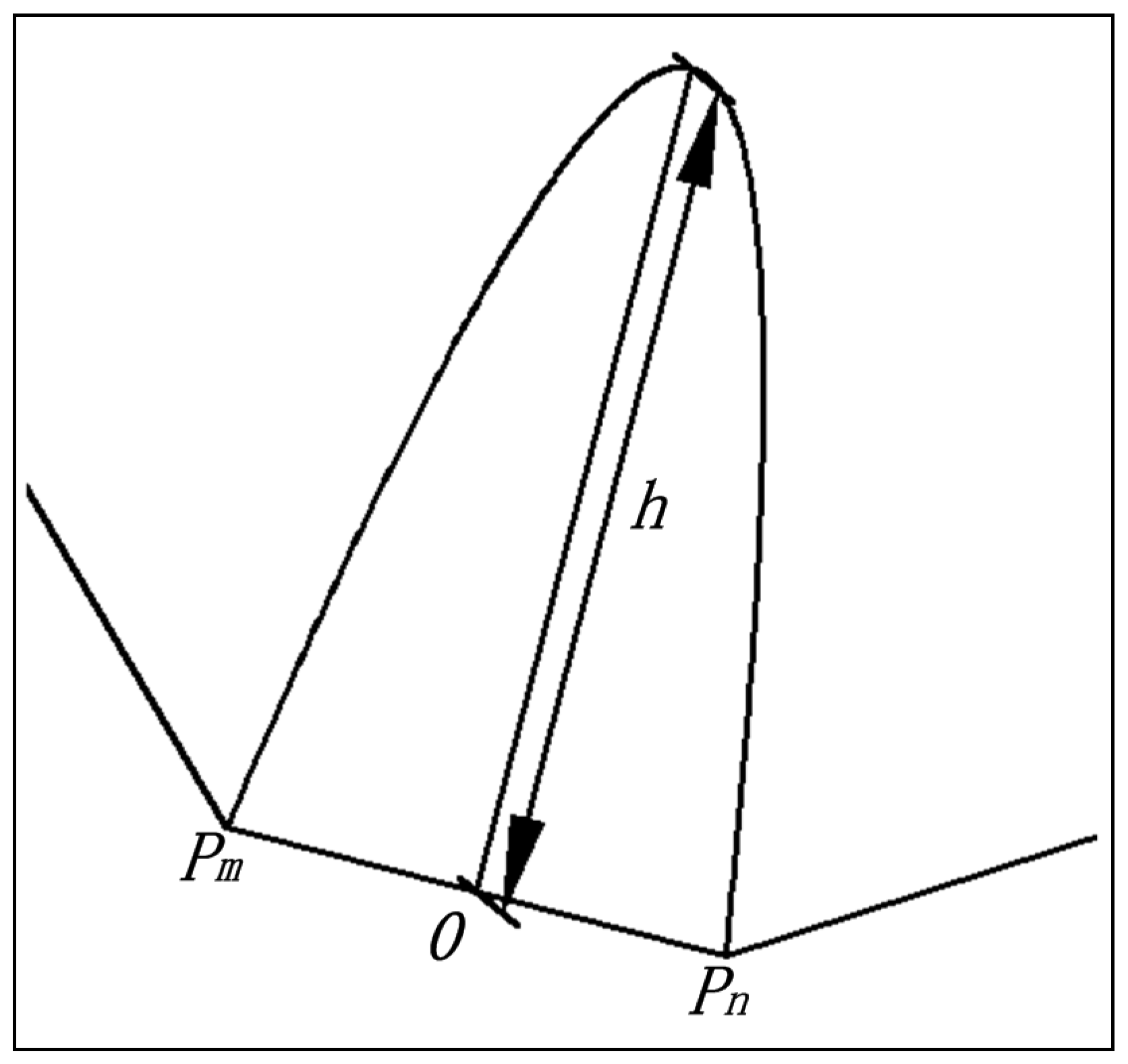
The calculation of retracting accuracy in the parabola-based convex hull retraction method is similar to the arc-based convex hull retraction method. The procedure is as follows:
- (a)
construct the convex hull Pc of the discrete point cluster P;
- (b)
draw a parabola towards the inside of the convex hull through two consecutive points
Pm and
Pn in the convex hull
Pc (
Figure 2). The midpoint of
is the origin of the parabola, and the parabolic function complies with Equation (1);
- (c)
obtain the retracting accuracy made from retracted boundary and parabola , its value is , and the retracted depth is h.
Even with the same retracting accuracy for the boundary, the retracting area will vary because the boundary retracting depth is different. Therefore, we can adjust the retracting area according to the objects’ density around the boundary when managing multi-density discrete geospatial objects.
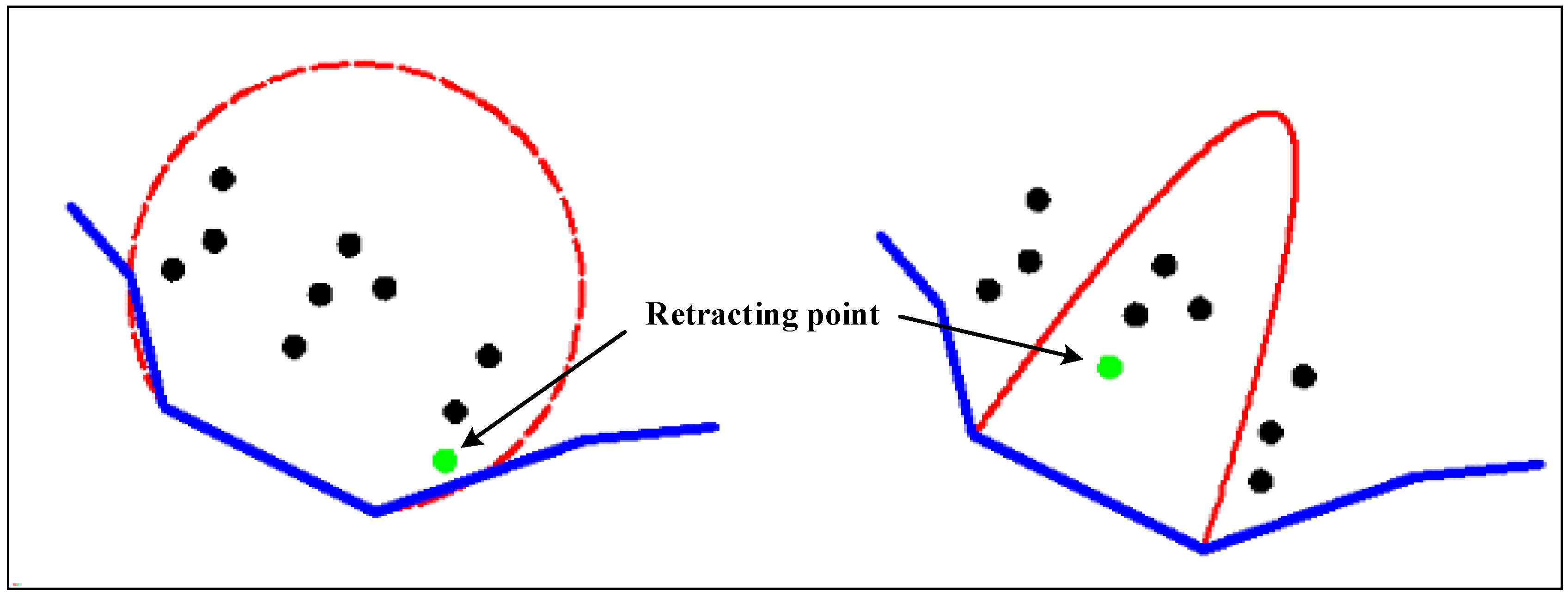
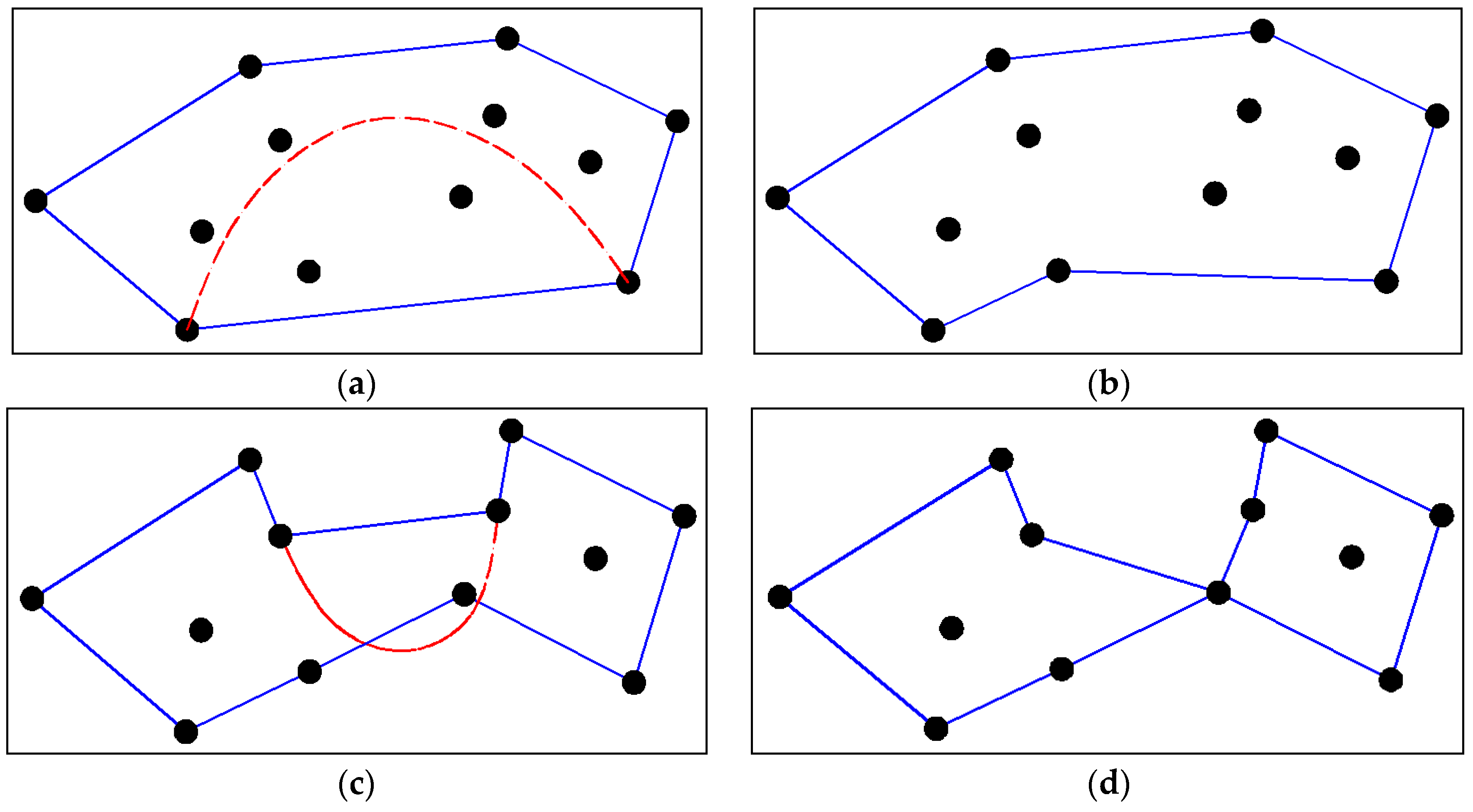
Figure 3 shows the arc and parabola retraction structure at different limiting conditions. According to the comparison, we can draw the following conclusion. With the same retracting depth, the retraction area based on arc retraction structure is larger than that based on parabola retraction structure. There are 10 points that need to be inspected in the retraction area based on arc retraction structure, but only four points need to be inspected in the retraction area based on parabola retraction structure. Therefore, the new parabola retraction structure has higher detection efficiency than that of arc retraction structure. In addition, the point chosen to retract the cluster borderline using these two methods is different. In
Figure 3, the chosen point is too close to the right side around the boundary line using the arc retraction structure, and the retracted boundary will form a big twist. Compared with the arc retraction structure, the point chosen to retract the boundary in the parabola area is more reasonable.
The causes of this difference can be summarized as follows. The angle of the boundary line and the tangent of the points in the parabola is smaller than 90°, and the arc retraction structure is more divergent in the geographical space. As a result, the parabola retraction structure is used to form the retraction area and implement the clustering method.
2.3. Clustering Processing
After constructing the convex hull of geospatial points and determining the value of the retracting accuracy
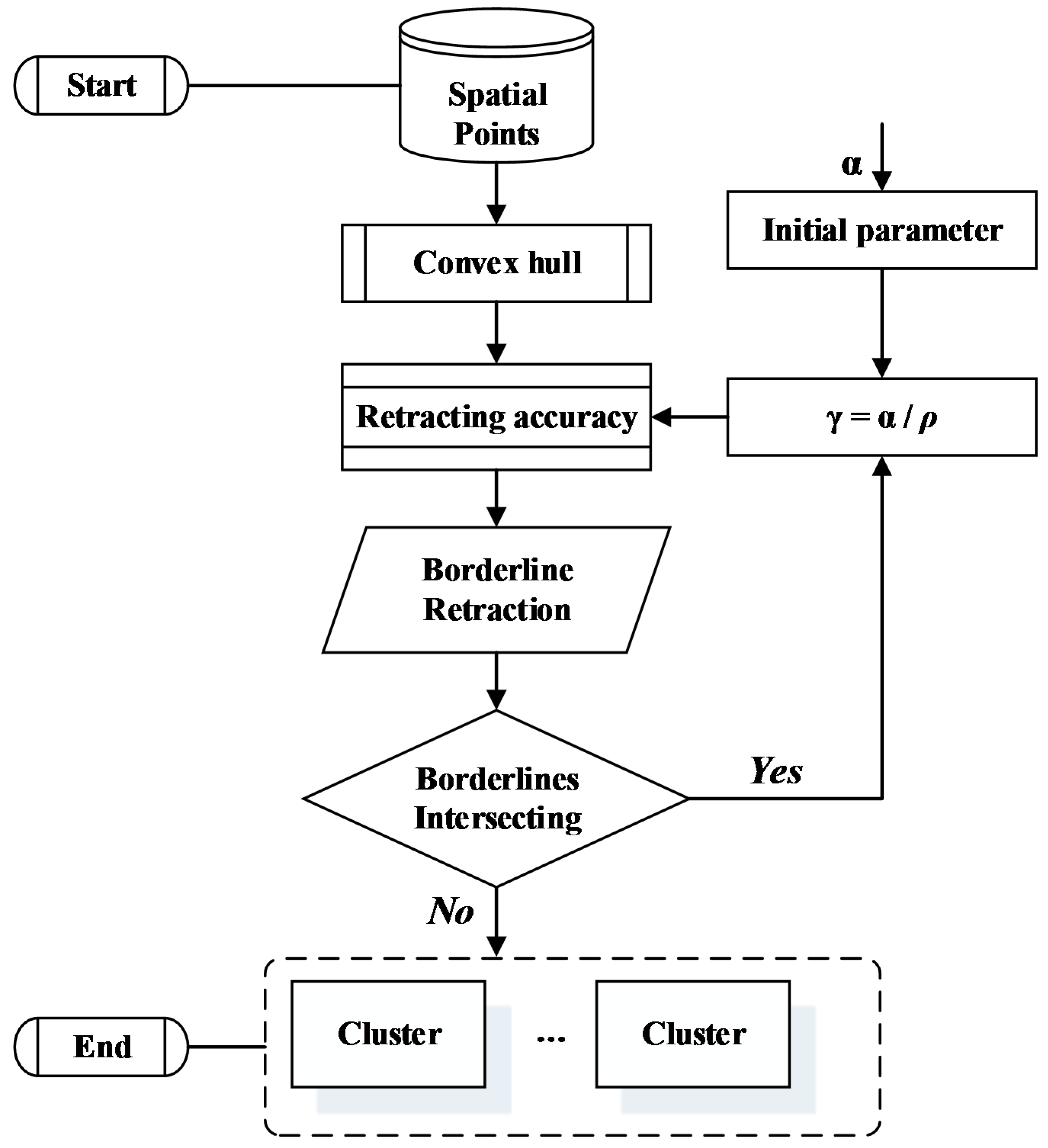
, we establish the parabola retraction area for each borderline of the convex hull. For longer borderline lengths, the cluster is easier to split between geospatial points of the borderline. It becomes possible to continuously retract the line segments where two different sub-clusters connect. The borderline retraction will not stop until the cluster is split. In
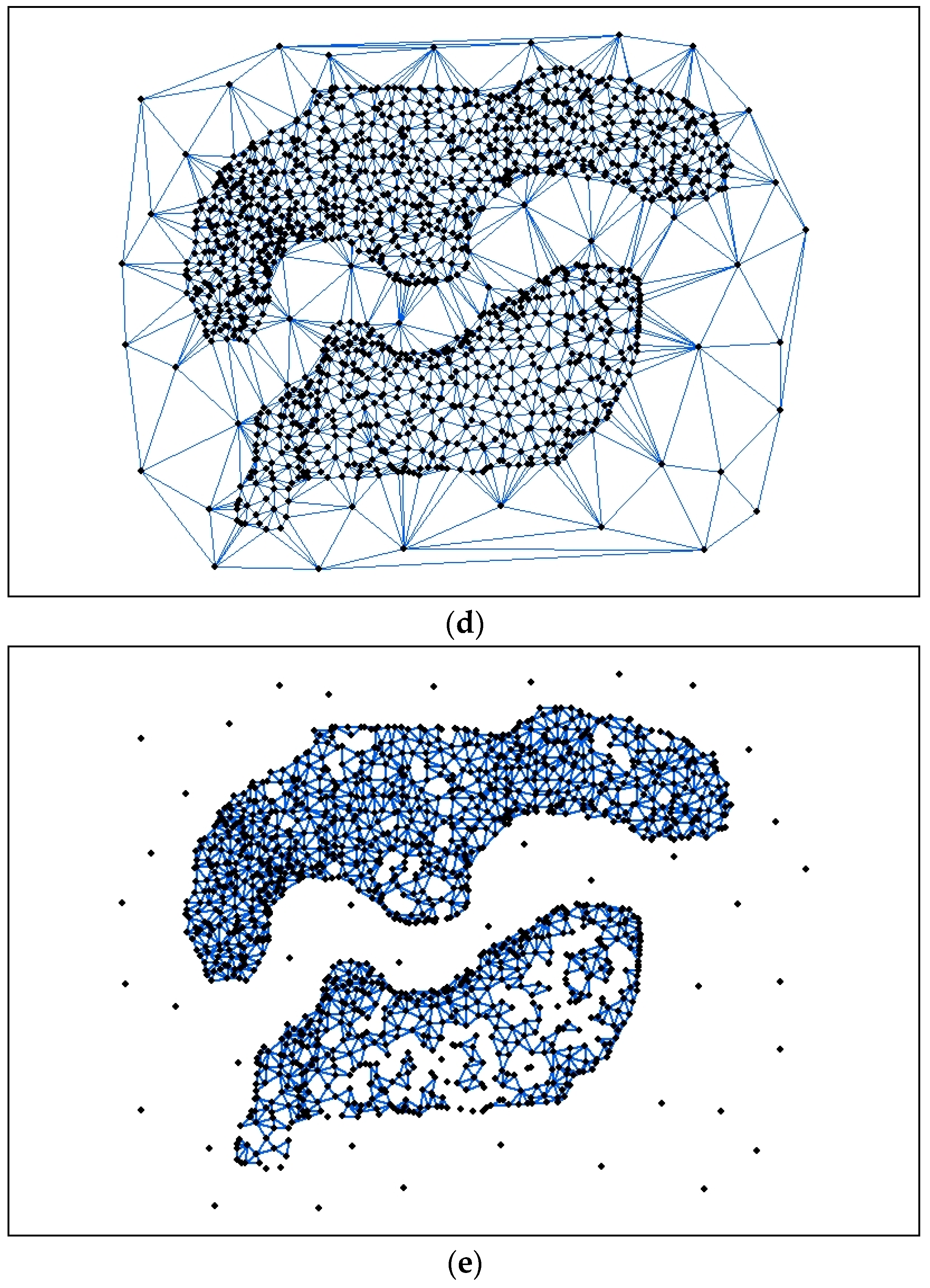
Figure 4, the flow diagram displays the divisive hierarchical clustering algorithm based on convex hull retraction.
The following is the complete procedure of the algorithm:
Step 1: construct the minimum convex hull of geospatial points;
Step 2: construct the borderline retraction structure in sequence by traversing the geospatial points starting from the longest boundary line in the convex hull;
Step 3: assign the initial parameter value α.
The value of retracting accuracy
is determined according to the point density near the convex hull borderlines. The estimation method of point density is shown as Equation (2):
where
is the estimated point density in the convex hull,
S is the area of the convex hull, and
N is the quantity of points inside the convex hull. The calculation of boundary retracting accuracy is shown as Equation (3):
After setting the initial value of parameter
, it will be applied to the clustering algorithm. Each time a new sub-cluster is obtained, the convex hull area and the quantity of geospatial objects in the sub-cluster will change. The clustering process homogenizes the object distribution in geographical space and guarantees that retracting accuracy
converges with changing
. The best clustering results appear when the initial value of parameter α ranges between [
1,
2] based on a large number of experiments.
Step 4: retracting borderlines
There are two purposes for constructing the parabola retracting structure. One is to limit the search area to improve efficiency, and the other is to define it as a termination condition of the split clustering. We construct the retraction structure in sequence according to the length of the convex hull borderlines. The procedure is shown in
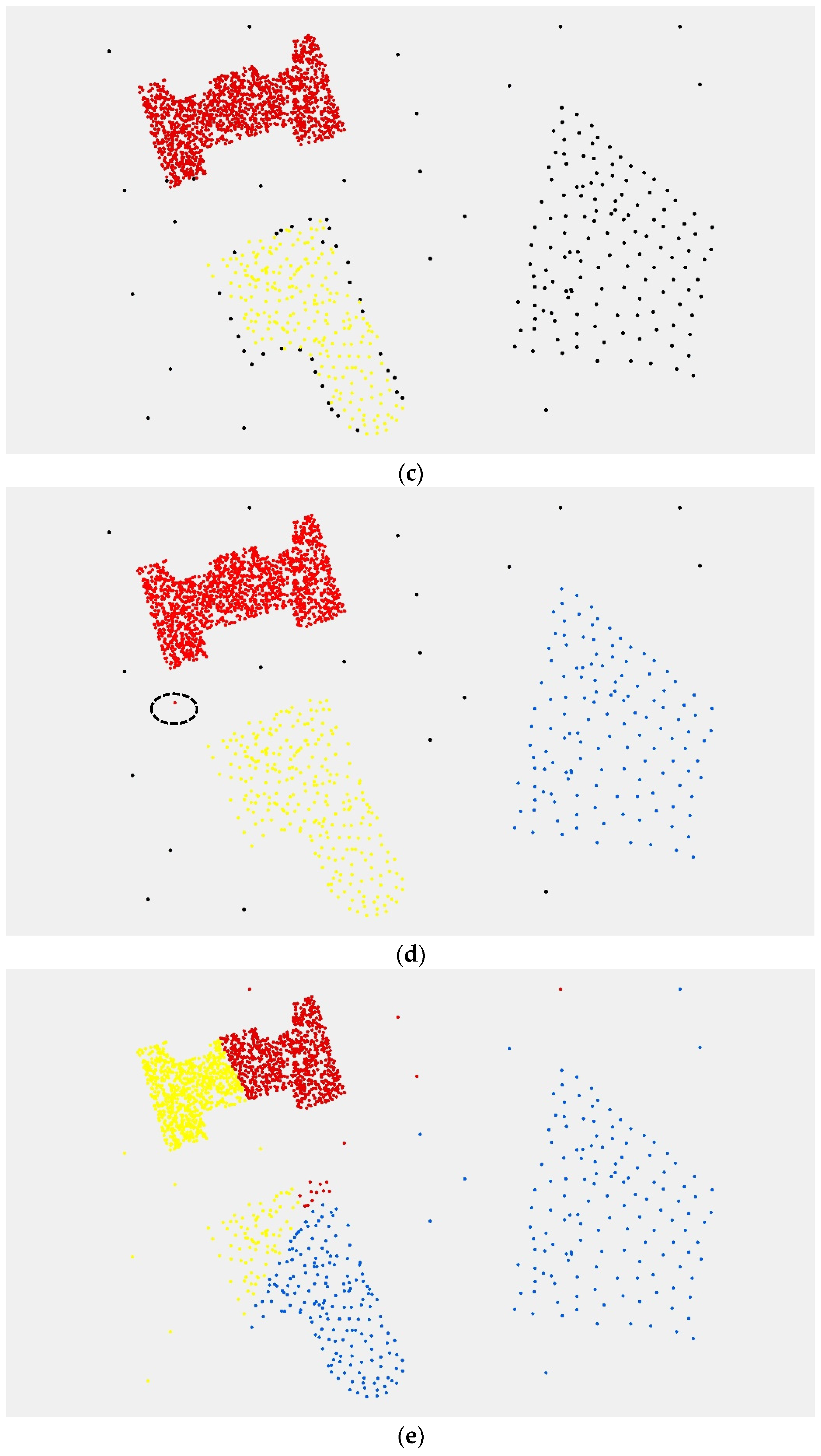
Figure 5. First, we construct the retracted structure of the longest borderline of the convex hull. Second, we find all points inside the retracting area and set the point, which is closest to the borderline as the retracting point. If objects in the area are empty, the borderline is marked as “0”.
Figure 5 shows a complete process of borderline retracting and the cluster division. If the nearest point inside the retracting area belongs to the borderline point, as shown in
Figure 5c, the cluster will be divided into two sub-clusters.
Figure 5d shows the result of division. We can find that two sub-clusters share a common point after dividing. We can determine which sub-cluster the common point belongs to based on the distance from the point to the nearest point of the sub-cluster.
Step 5: sub-cluster partitions
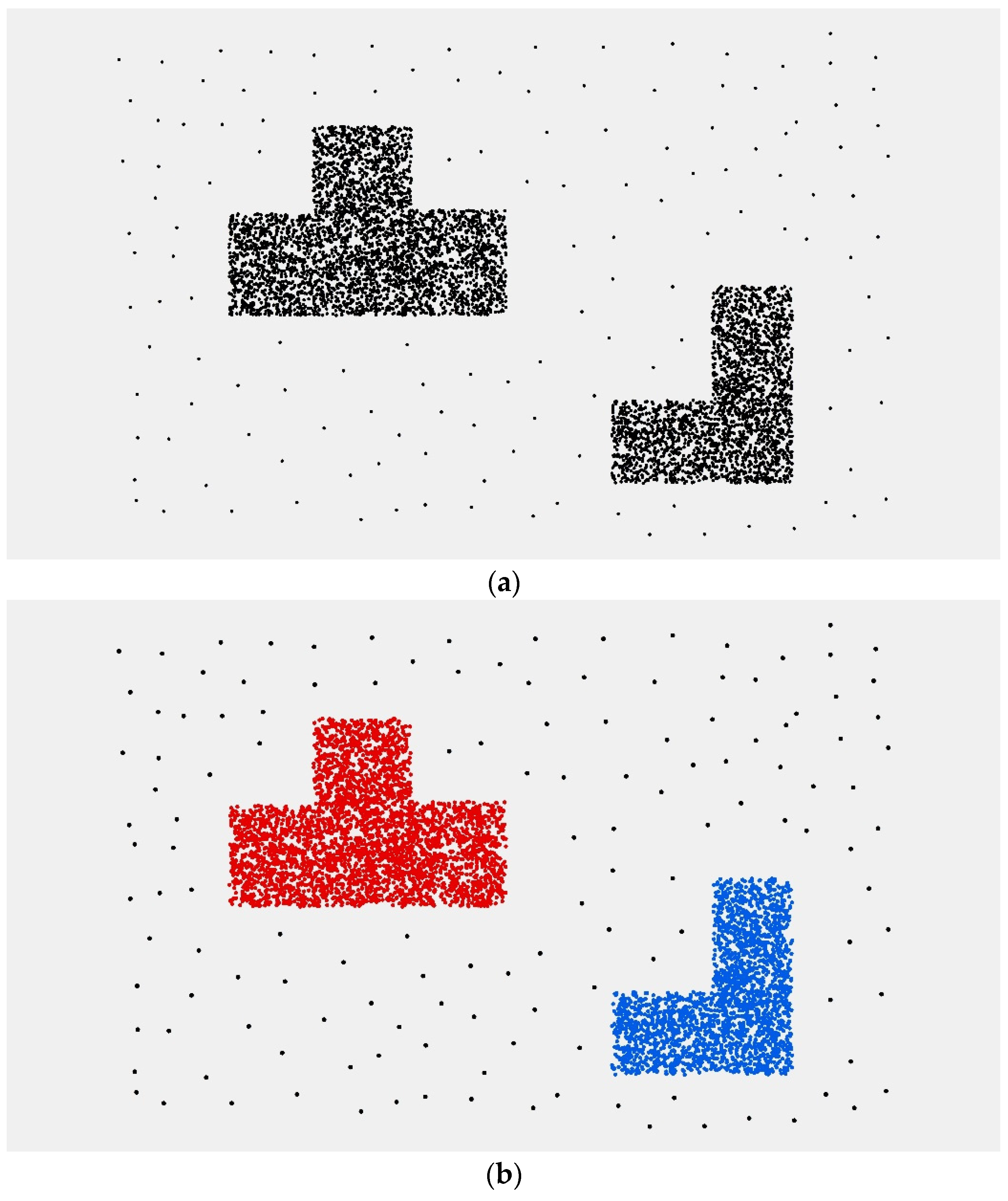
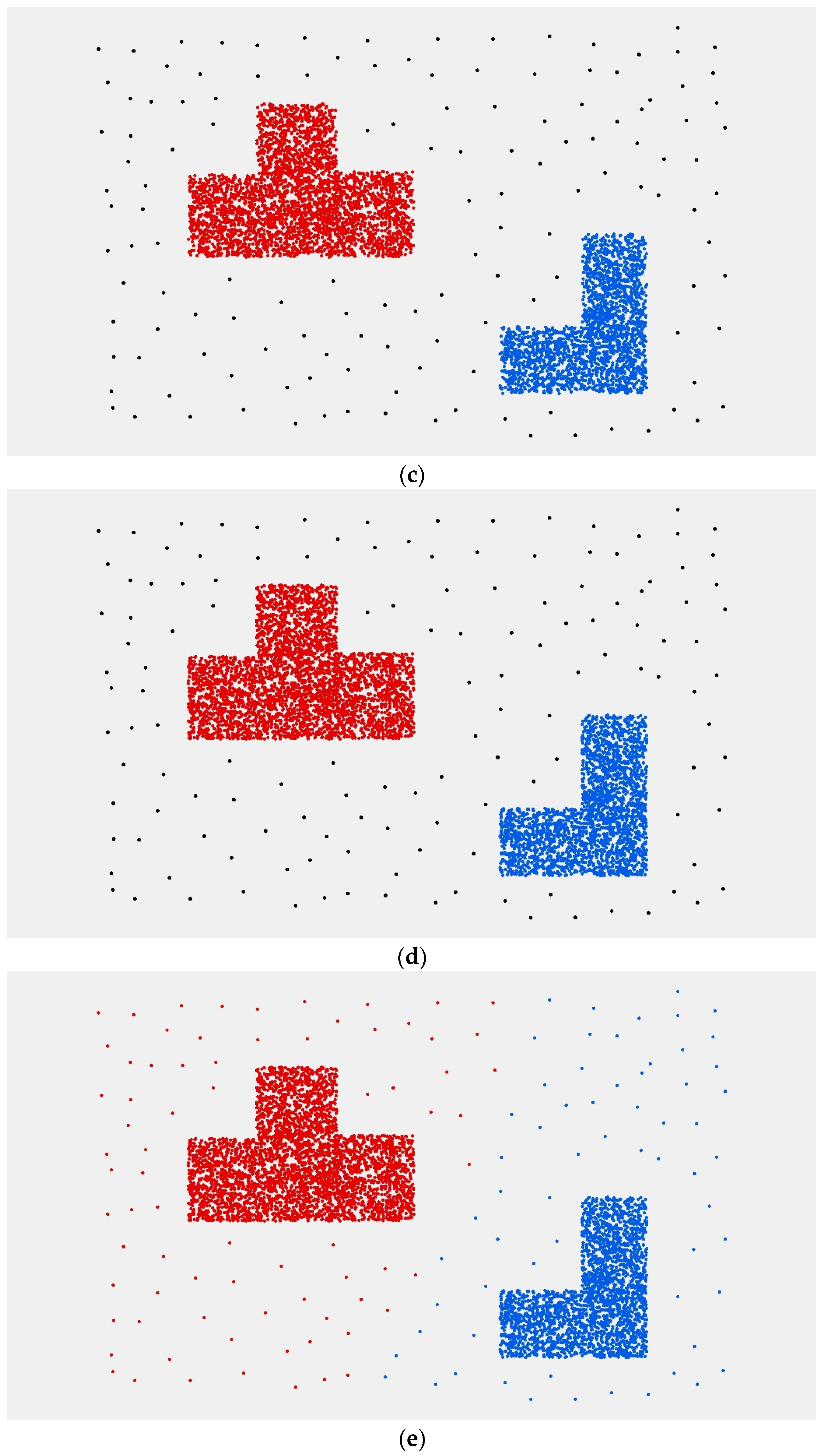
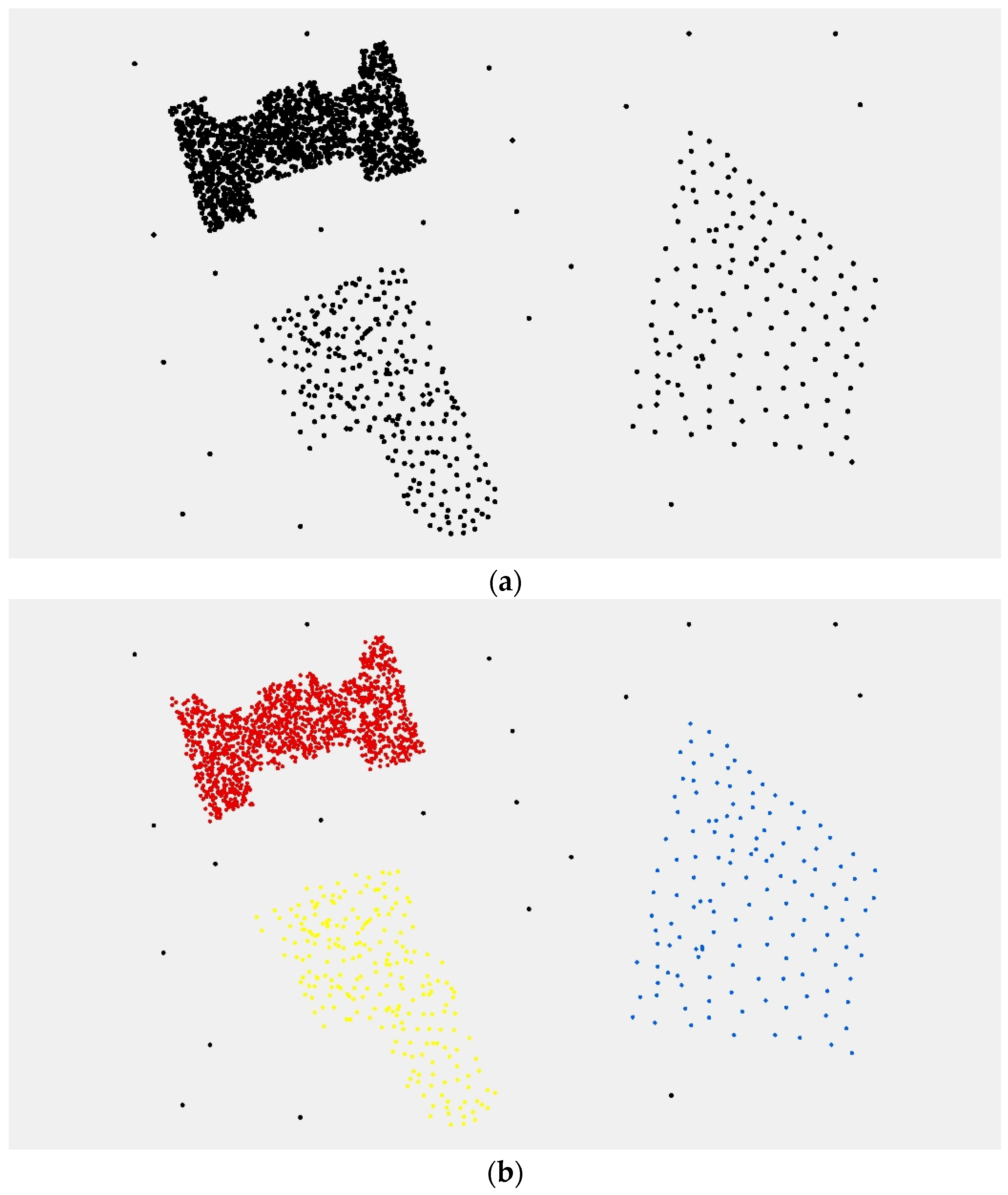
The sub-cluster obtained by the points division can be regarded as an independent cluster. Then, we repeat Steps 2 to 4 until all the borderlines of the sub-clusters are marked as “0”. If there are no more than three points in a sub-cluster and it is not able to build a convex hull, the points are regarded as noise.
The clustering process above is similar to the process of cell division in biology. Therefore, we name the clustering algorithm Cell-dividing Hierarchical Clustering (CDHC for short).
4. Discussion and Conclusions
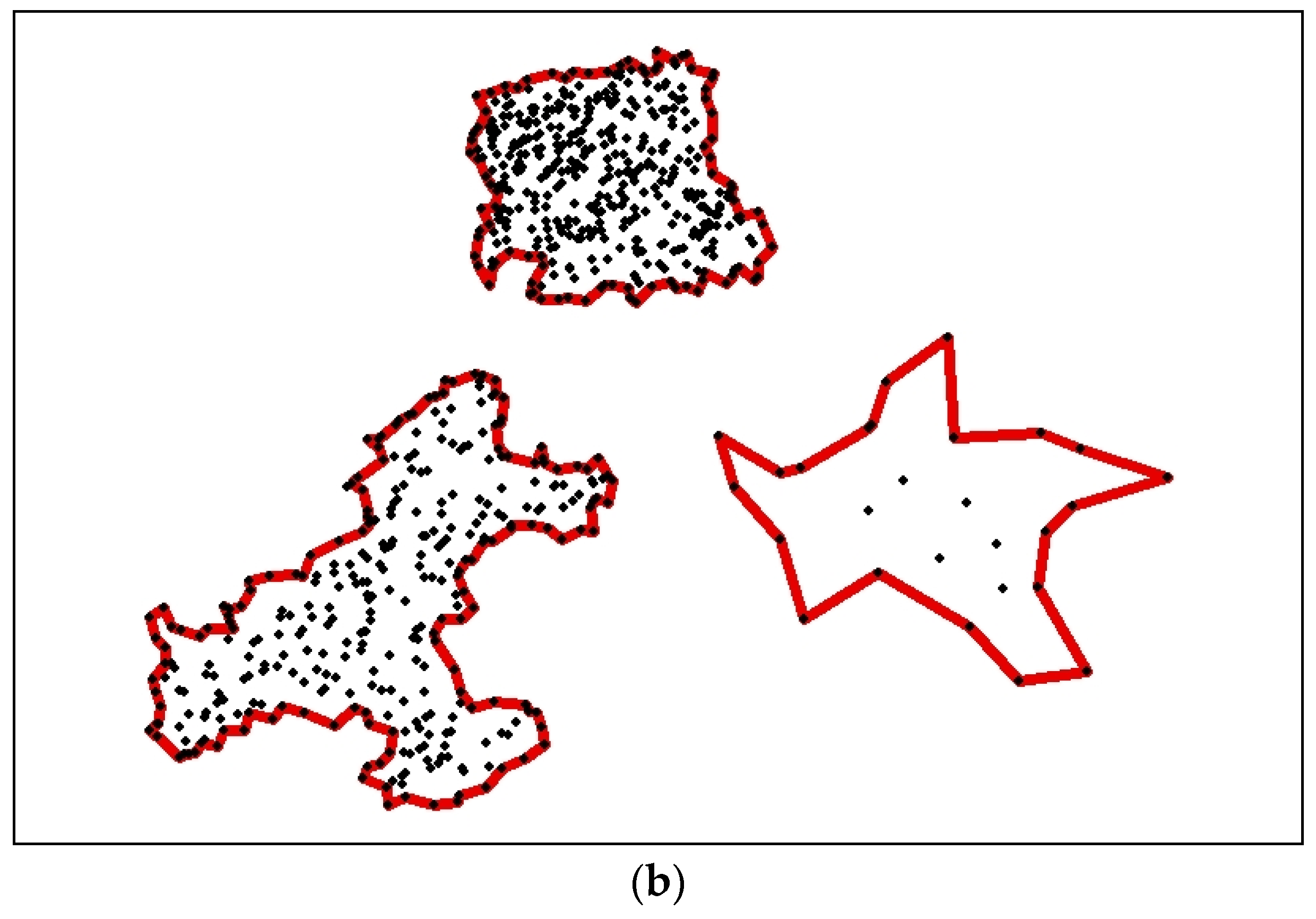
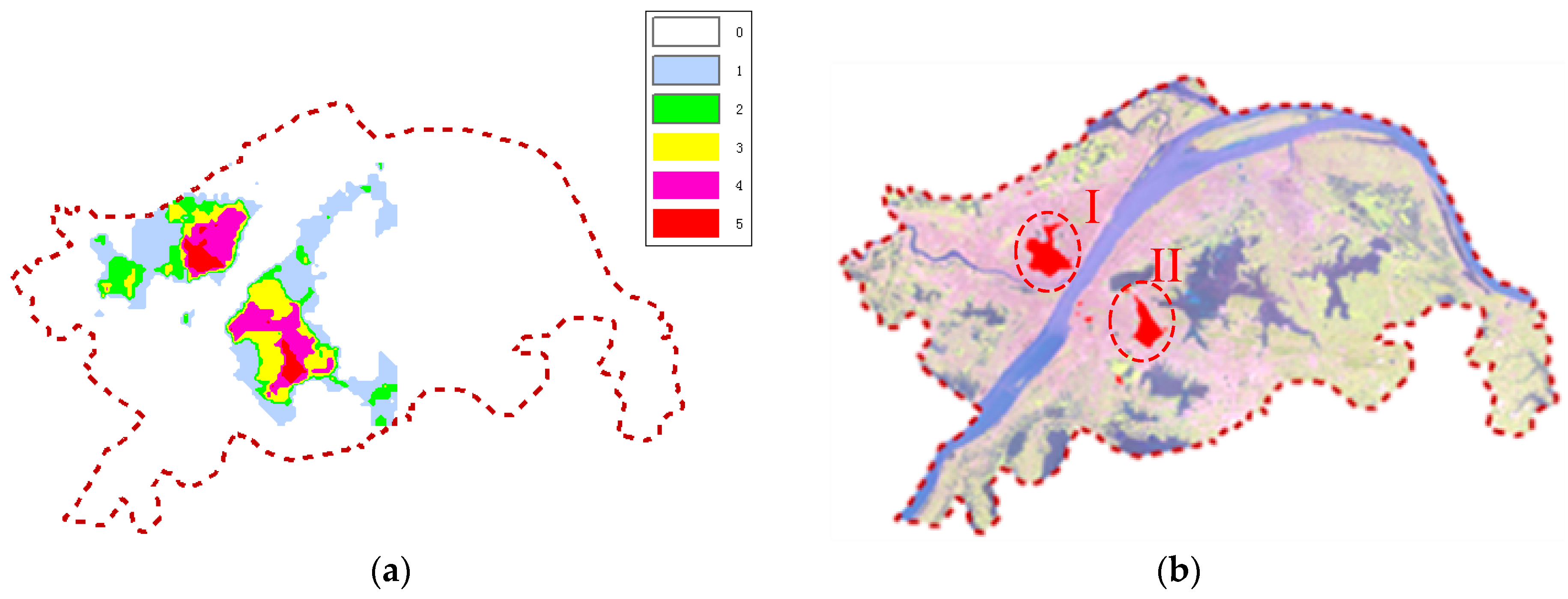
Spatial clustering algorithms are developed to group a set of objects in such a way that discrete objects in the same group, which are close to each other, are separate from those in other groups. However, there is a similarity of spatial structure between multi-density objects and noise data. Thus, it becomes more difficult to distinguish between the two in the local spatial context. It is necessary to address multi-density discrete objects based on a global spatial structure. In this paper, a modified convex hull structure is presented to describe the global spatial context of discrete objects. A boundary retraction is used to mine spatially stratified heterogeneity between clusters in our clustering method. Then, the boundary structure of each sub-cluster describes the global spatial context of the new subset. The density of spatial objects is used as the termination condition of the algorithm, so the CDHC algorithm can easily distinguish noise from multi-density objects.
Algorithmic efficiency has long been one of the issues in clustering analysis when dealing with large amounts of data. Many clustering algorithms work well in processing a small amount of data, but algorithm performance becomes worse as the data volumes grow. After comparison with two hierarchical clustering algorithms in experiment 1, we find that the CDHC algorithm has advantages in dealing with a large amount of spatial objects. The CDHC algorithm is a divisive hierarchical clustering, applying a “top–down” approach: all spatial objects start in one cluster and are split into two sub-clusters by the hierarchy. This avoids computing the position of each object at each iteration, so the CDHC algorithm can significantly improve efficiency of clustering analysis.
This paper proposes a new spatial clustering algorithm: cell-dividing hierarchical clustering (CDHC), which manages multi-density geospatial points. The CDHC algorithm can describe the global spatial context of geospatial points by establishing a minimum convex hull structure. After a cluster is split into two sub-clusters due to boundary retraction, each sub-cluster will be split again in the same way. Thus, it can be seen that geospatial points can be classified based on global structure at all times. Then, the algorithm uses a parabolic-limited retracted method to split the points, and achieve the requirements of split hierarchical clustering.
The experimental results show that the noise points and multi-density point sets are well identified using the CDHC algorithm. In addition, the CDHC algorithm can extract the internal differentiation regularity of a geospatial objects cluster using a variable parameter strategy according to the characteristics of spatial clusters. The CDHC algorithm avoids the uncertainty resulting from deterministic parameters, as well as the high computational complexity required by traditional hierarchical clustering algorithms. Although the CDHC algorithm has the ability to identify the points at boundaries, it is unable to address the clusters contained within another cluster. The improved DBSCAN methods are able to handle this challenge, although there are still some problems and limitations. Future work will continue research in this area, combining the two clustering methods to solve the multi-density clustering problem.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}