Combined Forecasting Method of Landslide Deformation Based on MEEMD, Approximate Entropy, and WLS-SVM


Abstract
:1. Introduction
2. Landslide Prediction Model Based on MEEMD, Approximation Entropy, and WLS-SVM
2.1. Modified Ensemble Empirical Mode Decomposition
2.2. Approximate Entropy Principle
2.3. Phase Space Reconstruction Theory
2.4. Weighted Least Squares Support Vector Machine
2.4.1. Least Squares Support Vector Machine
2.4.2. Weighted Least Squares Support Vector Machine
2.4.3. Parameters Optimization of WLS-SVM
- (1)
- Setting the value range, the step size, and grid spacing of parameters , the optimization process in this paper is divided into two steps of coarse selection and accurate selection. The parameters are set as follows; the optimization interval of and is , the number of grid points is , the search step size of coarse selection is 1, and the search step size of accurate selection is 0.1.
- (2)
- Since the optimization process is a traversal process, the selection of parameter initial value has no effect on the result. The initial values of this search process are and . Selecting the position of the first cross-validation grid point, obtaining the training RMSE using the cross-validation method as the objective function of the grid point calculation, and calculating all of the grid point values.
- (3)
- Selecting the with the smallest RMSE as the optimal parameters. If the selected parameters cannot satisfy the accuracy requirement, then take the selecting parameters as the center grid point, build a new 2-dimensional grid plane in a smaller range to recalculate the objective function, and select the parameter with the smallest RMSE again as the optimal parameter. If the accuracy requirement is satisfied, stop or repeat the above steps, acquire the accurate parameters , and take them as the optimal values.
2.4.4. Computational Procedure of WLS-SVM
- (1)
- According to the given sample of landside deformation data , determining the optimal parameter , obtaining from formula (12), and then calculating ;
- (2)
- Calculating the robust estimation according to the distribution of error ;
- (3)
- Determining the corresponding weight values according to and through formulation (17);
- (4)
- Finally and can be got by formulation (16). Accordingly the final nonlinear prediction model can be obtained as follows:
3. Analysis of Examples
3.1. Basic Characteristics of Landside
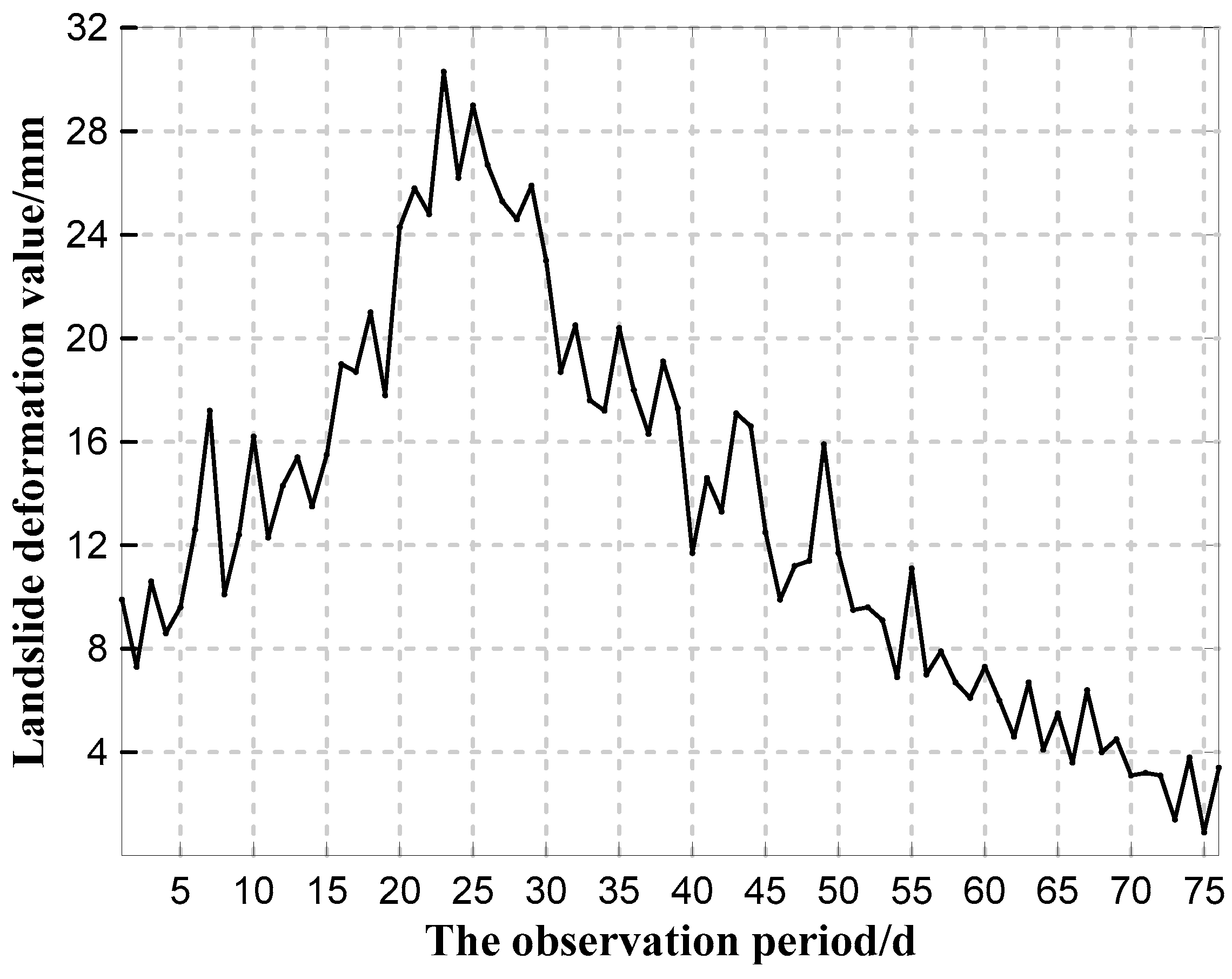
3.2. Experimental Data
3.3. Modeling Process
- (1)
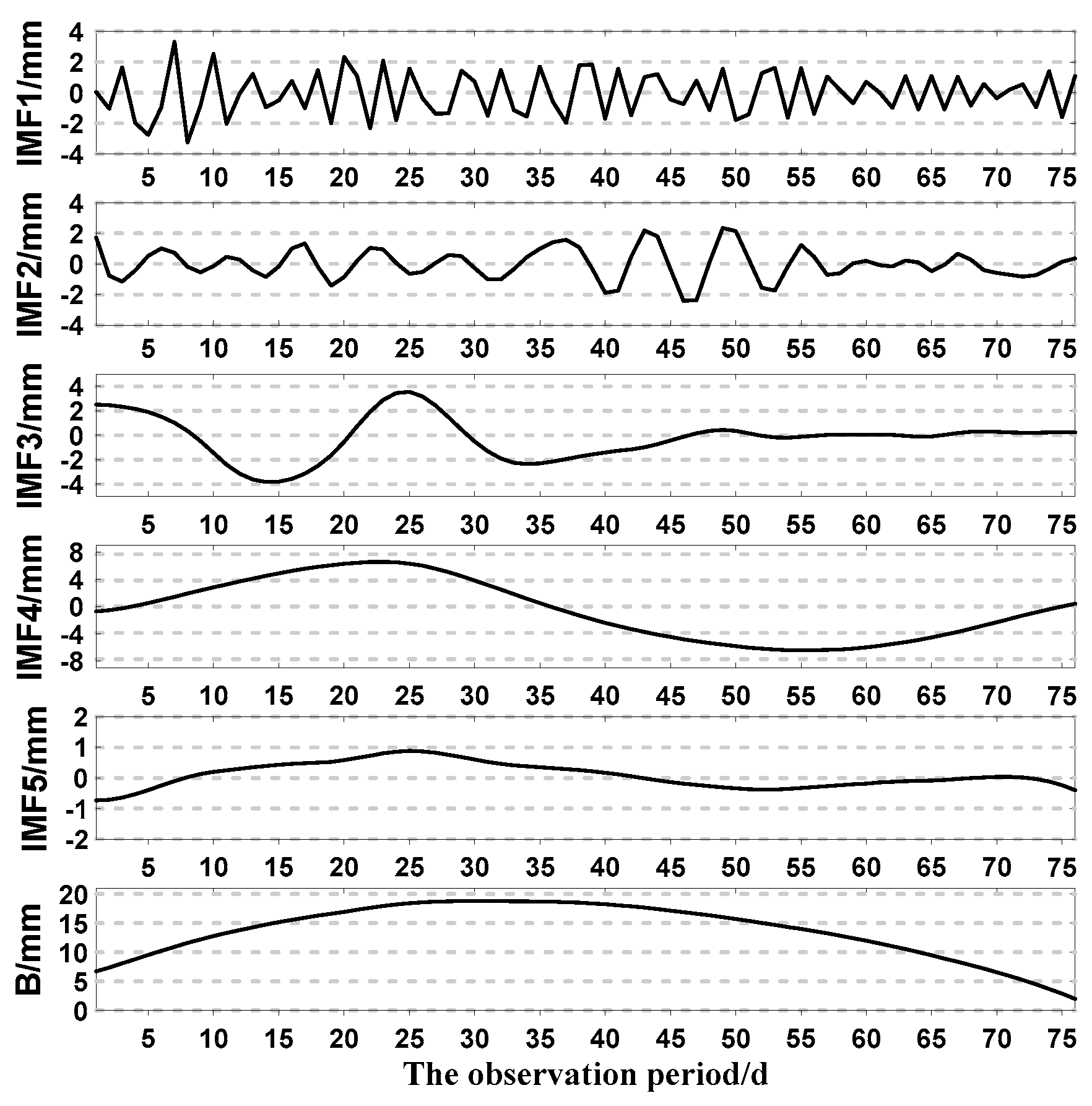
- To make the complex sequence smooth, the landslide sequence was decomposed to obtain a finite number of IMF components and a margin using MEEMD.
- (2)
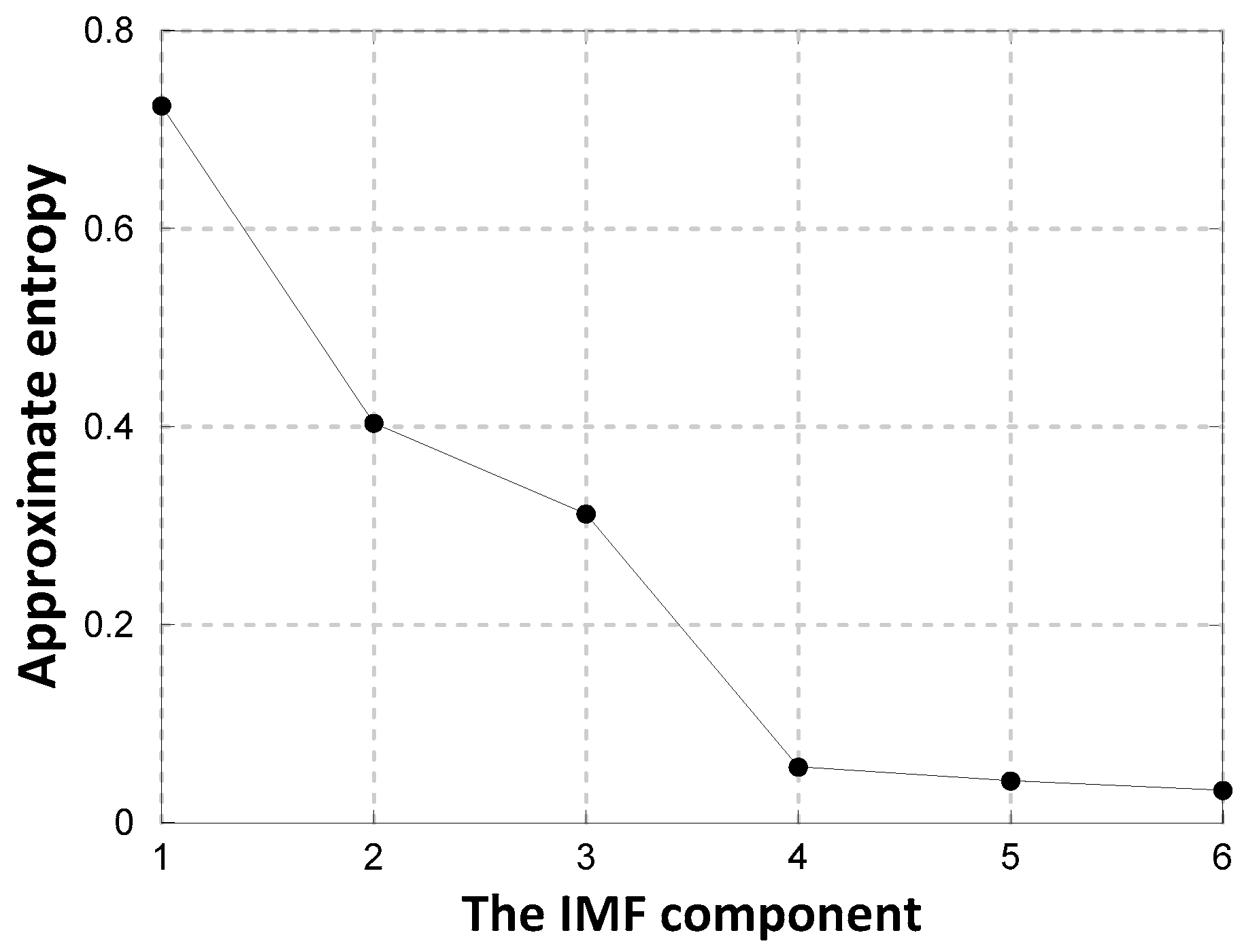
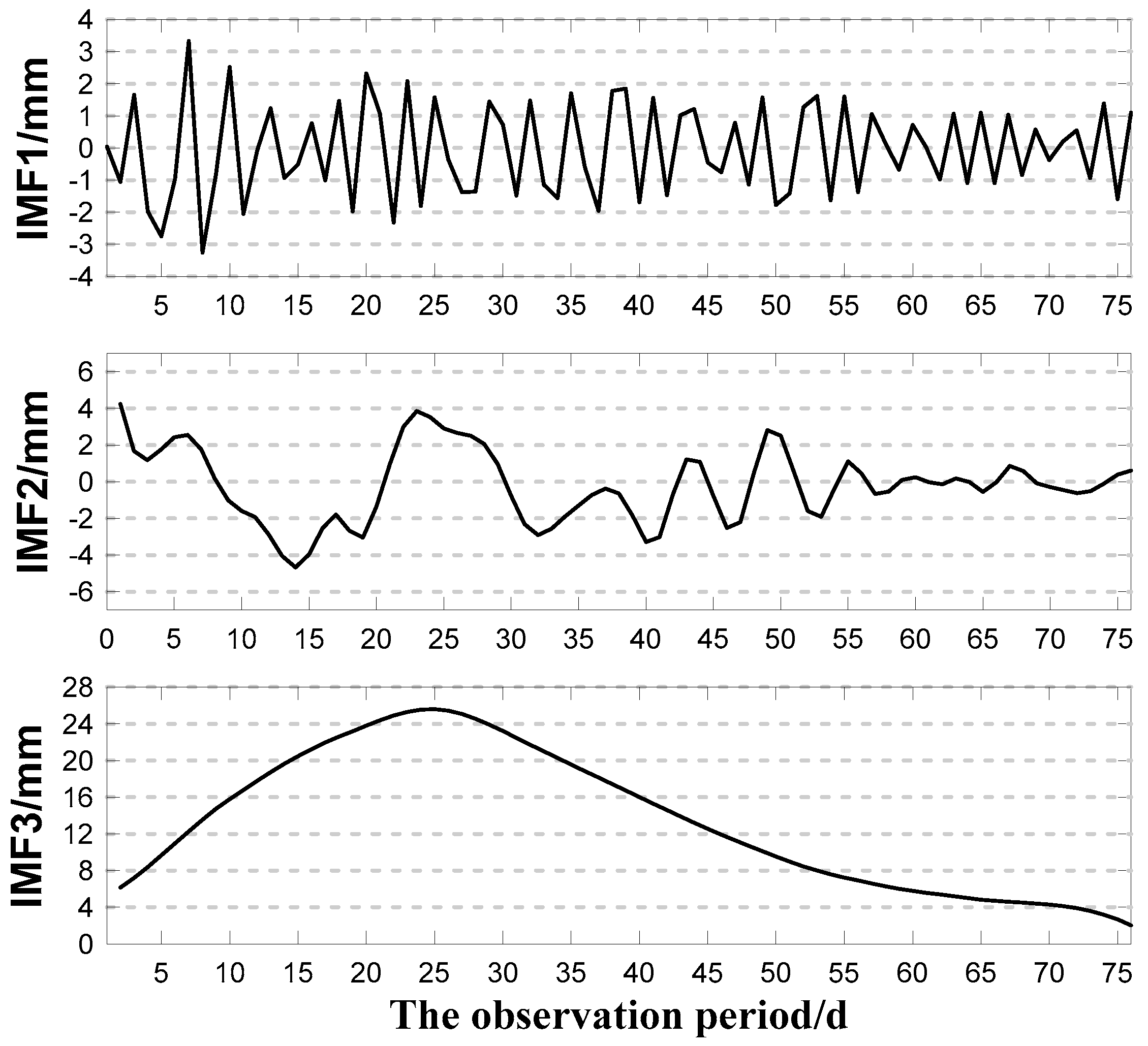
- Analyzing the complexity of each component using approximate entropy, combining the adjacent components with a small difference in entropy, and obtaining a new subsequence to reduce the size of the calculation.
- (3)
- Reconstructing the phase space of each new subsequence using the C-C method, which could avoid the random selection of the input dimensions of the prediction model.
- (4)
- Establishing the WLS-SVM prediction model based on the reconstructed phase space of the new subsequences by Step 3 to make a forecast.
- (5)
- Superposing the prediction result of each new subsequence to obtain the final forecast value of landslide deformation, and then evaluating the accuracy of each model.
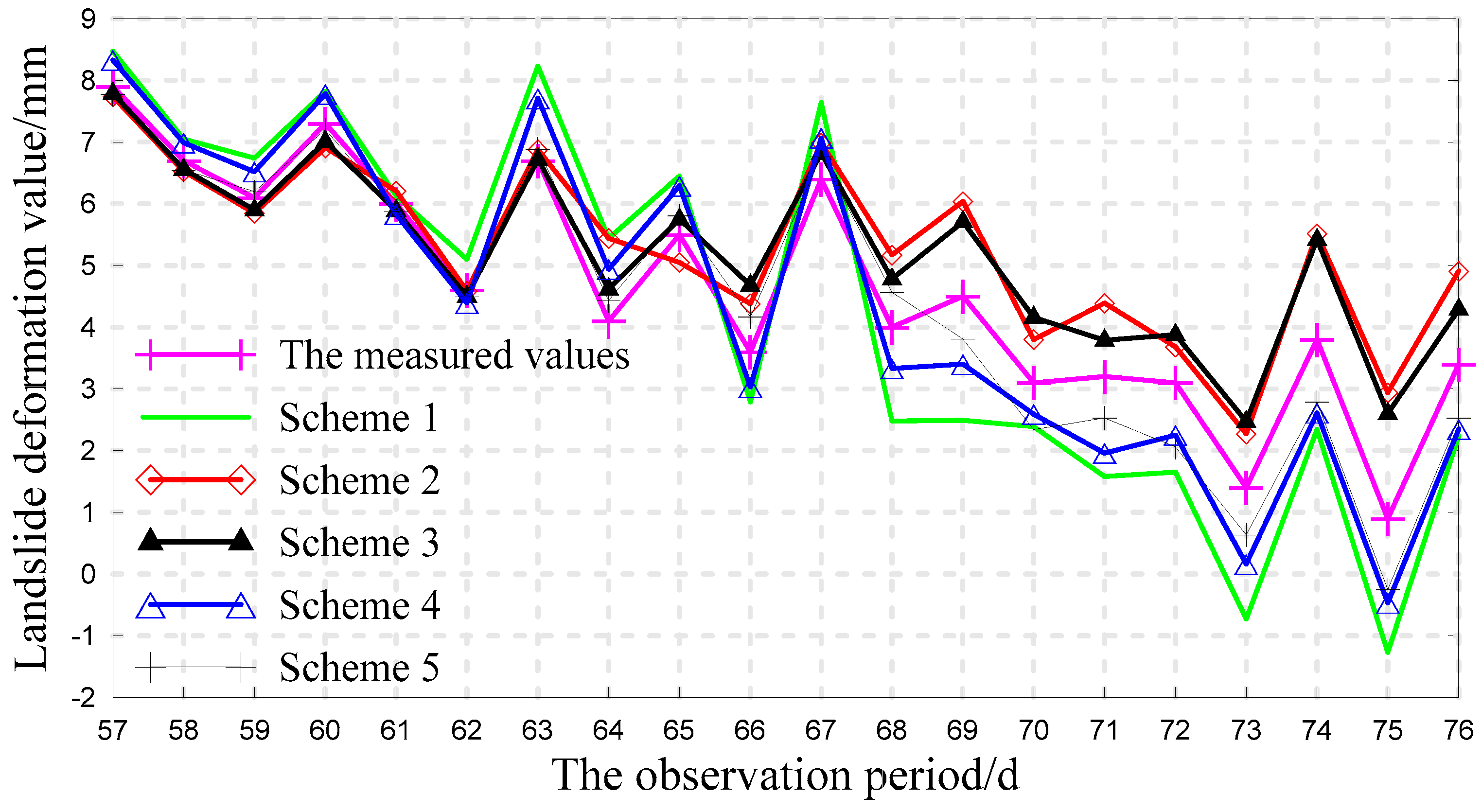
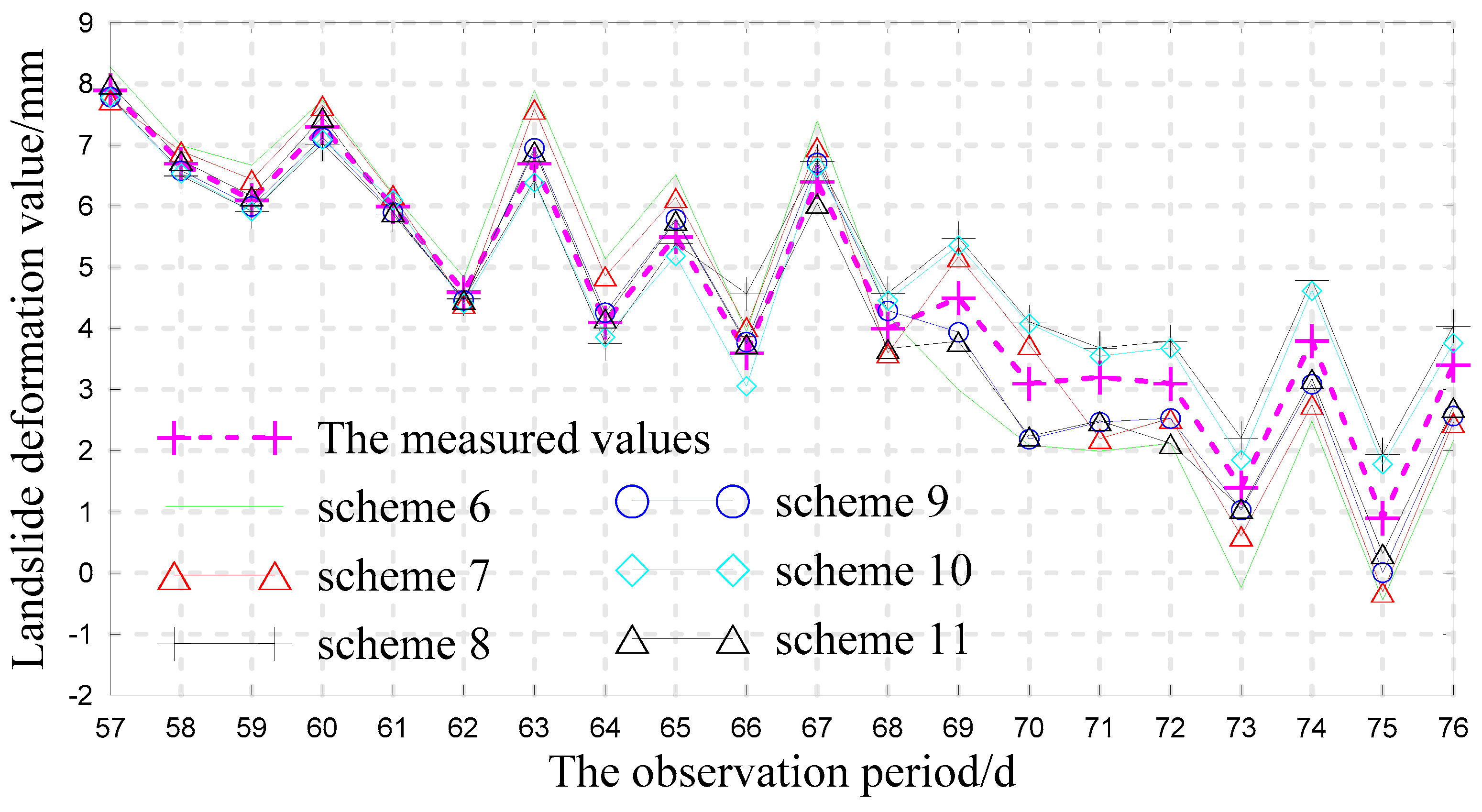
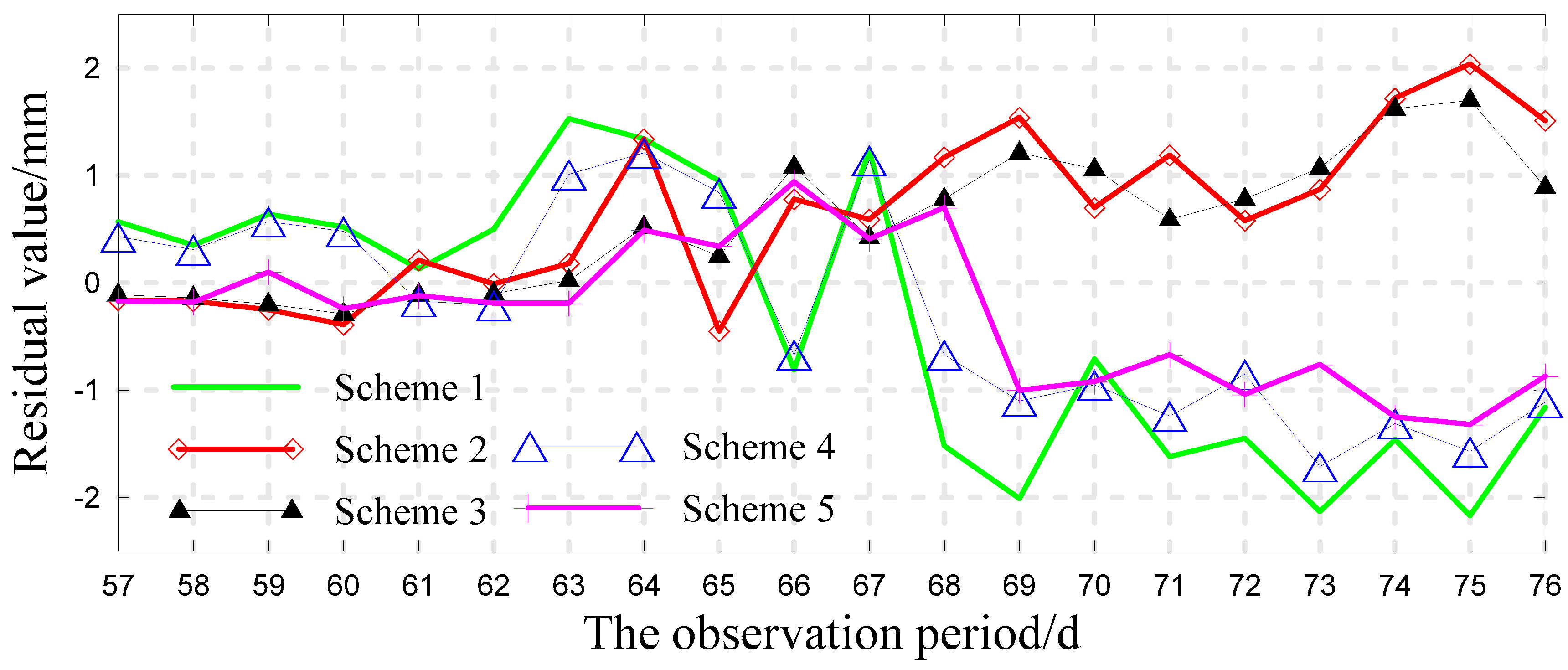
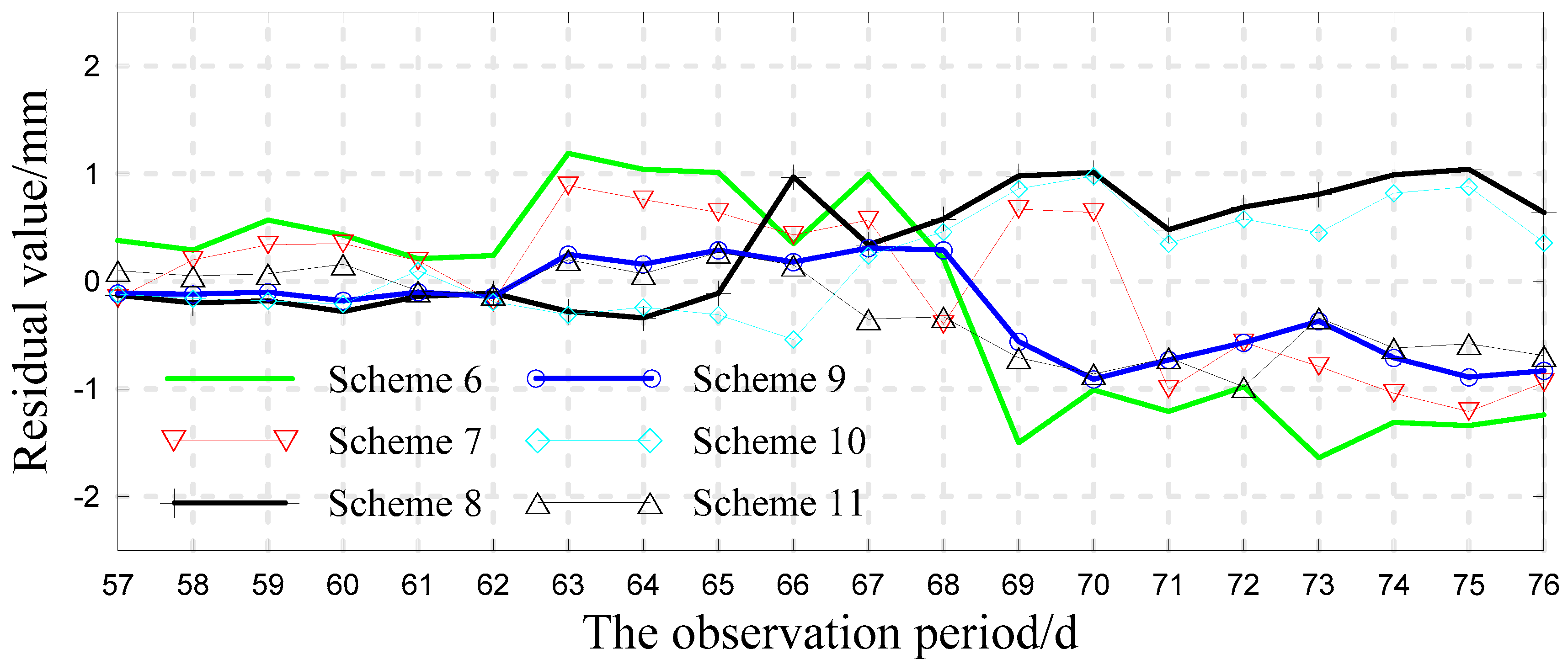
3.4. Analysis of the Forecast Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Behling, R.; Roessner, S.; Kaufmann, H.; Kleinschmit, B. Automated spatiotemporal landslide mapping over large areas using rapideye time series data. Remote Sens. 2014, 6, 8026–8055. [Google Scholar] [CrossRef]
- Dou, J.; Yamagishi, H.; Pourghasemi, H.R.; Yunus, A.P.; Song, X.; Xu, Y.; Zhu, Z. An integrated artificial neural network model for the landslide susceptibility assessment of Osado Island, Japan. Nat. Hazards 2015, 78, 1749–1776. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, G.; Fang, L. Distribution pattern of landslides triggered by the 2014 Ludian earthquake of China: Implications for regional threshold topography and the seismogenic fault identification. ISPRS Int. J. Geo-Inf. 2016, 5, 46. [Google Scholar] [CrossRef]
- Manfré, L.A.; de Albuquerque Nóbrega, R.A.; Quintanilha, J.A. Evaluation of multiple classifier systems for landslide identification in Landsat Thematic Mapper (TM) images. ISPRS Int. J. Geo-Inf. 2016, 5, 164. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; Wang, Y.; Chen, G.; Liu, S. Forested landslide detection using LiDAR data and the random forest algorithm: A case study of the Three Gorges. Remote Sens. Environ. 2014, 152, 291–301. [Google Scholar] [CrossRef]
- Li, Z.; Jiao, Q.; Liu, L.; Tang, H.; Liu, T. Monitoring geologic hazards and vegetation recovery in the Wenchuan earthquake region using aerial photography. ISPRS Int. J. Geo-Inf. 2014, 3, 368–390. [Google Scholar] [CrossRef]
- Akcay, O. Landslide fissure inference assessment by ANFIS and logistic regression using UAS-based photogrammetry. ISPRS Int. J. Geo-Inf. 2015, 4, 2131–2158. [Google Scholar] [CrossRef]
- Stumpf, A.; Malet, J.P.; Allemand, P.; Pierrot-Deseilligny, M.; Skupinski, G. Ground-based multi-view photogrammetry for the monitoring of landslide deformation and erosion. Geomorphology 2015, 231, 130–145. [Google Scholar] [CrossRef]
- Ballabio, C.; Sterlacchini, S. Support vector machines for landslide susceptibility mapping: The Staffora River Basin case study, Italy. Math. Geosci. 2012, 44, 47–70. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhao, H. The application of support vector machine in the deformation prediction of tunnel surrounding rock. Chin. J. Rock Mech. Eng. 2005, 24, 649–652. (In Chinese) [Google Scholar]
- Suykens, J.A.K.; Brabanter, J.D.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar] [CrossRef]
- Shi, J.; Liu, X. Melt index prediction by weighted least squares support vector machines. J. Appl. Polym. Sci. 2006, 101, 285–289. [Google Scholar] [CrossRef]
- Qin, S.; Jiao, J.J.; Wang, S. A nonlinear dynamical model of landslide evolution. Geomorphology 2002, 43, 77–85. [Google Scholar] [CrossRef]
- Qin, S.Q.; Jiao, J.J.; Wang, S.J. The predictable time scale of landslides. Bull. Eng. Geol. Environ. 2001, 59, 307–312. [Google Scholar] [CrossRef]
- Huang, Z.; Law, K.T.; Liu, H.; Jiang, T. The chaotic characteristics of landslide evolution: A case study of Xintan landslide. Environ. Geol. 2009, 56, 1585–1591. [Google Scholar] [CrossRef]
- Hovius, N.; Stark, C.P.; Tutton, M.A.; Abbott, L.D. Landslide-driven drainage network evolution in a presteady state mountain belt: Finisterre Mountains, Papua New Guinea. Geology 1998, 26, 1071–1074. [Google Scholar] [CrossRef]
- Wang, X.; Fan, Q.; Xu, C.; Li, Z. Dam deformation predictions based on wavelet transforms and support vector machine. Geomat. Inf. Sci. Wuhan Univ. 2008, 33, 469–471. (In Chinese) [Google Scholar]
- Li, X.; Xu, J. Landslide deformation prediction based on the wavelet analysis and LSSVM. J. Geod. Geodyn. 2009, 29, 127–130. (In Chinese) [Google Scholar]
- Lian, C.; Zeng, Z.; Yao, W.; Tang, H. Displacement prediction model of landslide based on a modified ensemble empirical mode decomposition and extreme learning machine. Nat. Hazards 2013, 66, 759–771. [Google Scholar] [CrossRef]
- Shen, Z.; Wang, Q.; Shen, Y.; Jin, J.; Lin, Y. Accent extraction of emotional speech based on modified ensemble empirical mode decomposition. In Proceedings of the 2010 IEEE Instrumentation & Measurement Technology Conference (I2MTC), Austin, TX, USA, 3–6 May 2010.
- Wu, Z.; Huang, N.E.; Chen, X. The multi-dimensional ensemble empirical mode decomposition method. Adv. Adapt. Data Anal. Theory Appl. 2009, 1, 339–372. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, 2039–2049. [Google Scholar]
- Kennel, M.B.; Brown, R.; Abarbanel, H.D.I. Determining embedding dimension for phase space reconstruction using a geometrical construction. Phys. Rev. A 1992, 45, 3403–3411. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Jia, D.; Li, H.; Jiang, J. Research on kernel parameter optimization of support vector machine in speaker recognition. Sci. Technol. Energy 2010, 10, 1669–1673. (In Chinese) [Google Scholar]
- Monfared, M.; Rastegar, H.; Kojabadi, H.M. A new strategy for wind speed forecasting using artificial intelligent methods. Renew. Energy 2009, 34, 845–848. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, R.; Gao, R.X.; Feng, Z. Performance enhancement of ensemble empirical mode decomposition. Mech. Syst. Signal Process. 2010, 24, 2104–2123. [Google Scholar] [CrossRef]
- Takens, F. Detecting Strange Attractors in Turbulence; Dynamical Systems and Turbulence, Lecture Notes in Mathematics; Springer: Berlin, Germany, 1981. [Google Scholar]
- Li, L. Landslide Prediction Research Based on the Theory of Phase Space Reconstruction; Chengdu University of Technology: Chengdu, China, 2008. (In Chinese) [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intrinsic Mode Function | Component Serial Number | ||
|---|---|---|---|
| New IMF | IMF1 | IMF2 | IMF3 |
| Original IMF | IMF1 | IMF2,IMF3 | IMF4,IMF5,IMF6 |
| Sample | Prediction Model | Step Size: 1 to 5 | Step Size: 6 to 10 | Step Size: 11 to 15 | Step Size: 16 to 20 | Running Time/s | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| IAA | EAA | IAA | EAA | IAA | EAA | IAA | EAA | |||
| Original data | Scheme 1 | ±0.44 | ±0.53 | ±0.95 | ±1.22 | ±1.34 | ±1.66 | ±1.52 | ±1.93 | 13.92 |
| Scheme 2 | ±0.20 | ±0.28 | ±0.61 | ±0.81 | ±1.11 | ±1.22 | ±1.32 | ±1.62 | 10.27 | |
| Scheme 3 | ±0.13 | ±0.20 | ±0.50 | ±0.61 | ±0.84 | ±0.96 | ±1.24 | ±1.42 | 8.13 | |
| Scheme 4 | ±0.39 | ±0.47 | ±0.84 | ±0.96 | ±0.99 | ±1.16 | ±1.37 | ±1.50 | 17.35 | |
| Scheme 5 | ±0.13 | ±0.19 | ±0.48 | ±0.57 | ±0.75 | ±0.86 | ±1.09 | ±1.20 | 11.97 | |
| IMF1 | Scheme 6 | ±0.09 | ±0.13 | ±0.11 | ±0.15 | ±0.15 | ±0.19 | ±0.20 | ±0.23 | 11.42 |
| Scheme 7 | ±0.06 | ±0.10 | ±0.10 | ±0.14 | ±0.13 | ±0.17 | ±0.16 | ±0.20 | 14.84 | |
| Scheme 8 | ±0.03 | ±0.08 | ±0.06 | ±0.10 | ±0.10 | ±0.16 | ±0.13 | ±0.18 | 7.51 | |
| Scheme 9 | ±0.03 | ±0.07 | ±0.03 | ±0.08 | ±0.09 | ±0.13 | ±0.10 | ±0.15 | 9.14 | |
| Scheme 10 | ±0.03 | ±0.07 | ±0.04 | ±0.09 | ±0.08 | ±0.13 | ±0.10 | ±0.15 | 5.84 | |
| Scheme 11 | ±0.00 | ±0.05 | ±0.03 | ±0.08 | ±0.05 | ±0.11 | ±0.08 | ±0.14 | 7.92 | |
| IMF2 | Scheme 6 | ±0.19 | ±0.24 | ±0.47 | ±0.54 | ±0.89 | ±1.06 | ±1.10 | ±1.21 | 12.67 |
| Scheme 7 | ±0.16 | ±0.20 | ±0.36 | ±0.41 | ±0.60 | ±0.68 | ±0.67 | ±0.76 | 16.79 | |
| Scheme 8 | ±0.10 | ±0.15 | ±0.21 | ±0.27 | ±0.35 | ±0.41 | ±0.39 | ±0.48 | 7.94 | |
| Scheme 9 | ±0.09 | ±0.13 | ±0.13 | ±0.18 | ±0.27 | ±0.33 | ±0.36 | ±0.41 | 10.97 | |
| Scheme 10 | ±0.10 | ±0.14 | ±0.18 | ±0.24 | ±0.29 | ±0.37 | ±0.38 | ±0.45 | 6.96 | |
| Scheme 11 | ±0.07 | ±0.11 | ±0.06 | ±0.10 | ±0.19 | ±0.28 | ±0.29 | ±0.37 | 8.27 | |
| IMF3 | Scheme 6 | ±0.31 | ±0.38 | ±0.56 | ±0.64 | ±1.01 | ±1.19 | ±1.15 | ±1.30 | 13.57 |
| Scheme 7 | ±0.21 | ±0.26 | ±0.37 | ±0.43 | ±0.79 | ±0.85 | ±0.90 | ±0.97 | 16.91 | |
| Scheme 8 | ±0.17 | ±0.22 | ±0.28 | ±0.34 | ±0.59 | ±0.67 | ±0.61 | ±0.69 | 8.10 | |
| Scheme 9 | ±0.13 | ±0.18 | ±0.15 | ±0.21 | ±0.45 | ±0.51 | ±0.47 | ±0.56 | 11.37 | |
| Scheme 10 | ±0.16 | ±0.20 | ±0.23 | ±0.29 | ±0.55 | ±0.61 | ±0.57 | ±0.64 | 7.24 | |
| Scheme 11 | ±0.11 | ±0.18 | ±0.11 | ±0.19 | ±0.44 | ±0.51 | ±0.46 | ±0.53 | 9.14 | |
| Model | Prediction Step: 5 | Prediction Step: 10 | Prediction Step: 20 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Max | Min | RMSE | MAE | Max | Min | RMSE | MAE | Max | Min | RMSE | MAE | |
| Scheme 1 | −2.17 | 0.13 | 1.283 | 1.141 | −2.31 | 0.34 | 1.312 | 1.273 | −3.11 | 0.27 | 1.482 | 1.395 |
| Scheme 2 | 2.04 | −0.16 | 0.986 | 0.793 | 1.98 | 0.15 | 1.141 | 0.904 | 2.14 | 0.57 | 1.207 | 1.016 |
| Scheme 3 | 1.70 | −0.10 | 0.820 | 0.647 | 1.67 | −0.24 | 0.956 | 0.741 | 1.99 | 0.34 | 1.189 | 0.861 |
| Scheme 4 | −1.71 | −0.17 | 0.974 | 0.878 | −1.83 | −0.34 | 1.085 | 0.957 | −2.01 | 0.47 | 1.261 | 1.204 |
| Scheme 5 | −1.32 | 0.10 | 0.711 | 0.595 | −1.18 | 0.21 | 0.854 | 0.611 | −1.57 | 0.29 | 1.097 | 0.773 |
| Scheme 6 | −1.34 | 0.21 | 0.973 | 0.857 | −1.57 | 0.18 | 1.037 | 0.911 | −1.61 | −0.17 | 1.197 | 0.999 |
| Scheme 7 | −1.21 | −0.16 | 0.673 | 0.599 | −1.39 | 0.09 | 0.794 | 0.715 | −1.45 | −0.27 | 0.897 | 0.809 |
| Scheme 8 | 1.04 | −0.11 | 0.617 | 0.515 | 1.21 | −0.10 | 0.698 | 0.601 | 1.28 | −0.09 | 0.788 | 0.689 |
| Scheme 9 | −0.91 | −0.10 | 0.480 | 0.390 | −0.95 | −0.10 | 0.492 | 0.397 | −1.00 | 0.07 | 0.504 | 0.407 |
| Scheme 10 | 0.98 | 0.10 | 0.496 | 0.417 | 0.89 | −0.13 | 0.579 | 0.497 | 0.95 | −0.09 | 0.657 | 0.479 |
| Scheme 11 | −0.86 | 0.05 | 0.472 | 0.373 | −0.88 | 0.01 | 0.484 | 0.380 | 0.91 | −0.04 | 0.495 | 0.397 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Liang, Y.; Zheng, Z.; Liu, H. Combined Forecasting Method of Landslide Deformation Based on MEEMD, Approximate Entropy, and WLS-SVM. ISPRS Int. J. Geo-Inf. 2017, 6, 5. https://doi.org/10.3390/ijgi6010005
Xie S, Liang Y, Zheng Z, Liu H. Combined Forecasting Method of Landslide Deformation Based on MEEMD, Approximate Entropy, and WLS-SVM. ISPRS International Journal of Geo-Information. 2017; 6(1):5. https://doi.org/10.3390/ijgi6010005
Chicago/Turabian StyleXie, Shaofeng, Yueji Liang, Zhongtian Zheng, and Haifeng Liu. 2017. "Combined Forecasting Method of Landslide Deformation Based on MEEMD, Approximate Entropy, and WLS-SVM" ISPRS International Journal of Geo-Information 6, no. 1: 5. https://doi.org/10.3390/ijgi6010005
APA StyleXie, S., Liang, Y., Zheng, Z., & Liu, H. (2017). Combined Forecasting Method of Landslide Deformation Based on MEEMD, Approximate Entropy, and WLS-SVM. ISPRS International Journal of Geo-Information, 6(1), 5. https://doi.org/10.3390/ijgi6010005