Understanding the Functionality of Human Activity Hotspots from Their Scaling Pattern Using Trajectory Data


Abstract
:1. Introduction
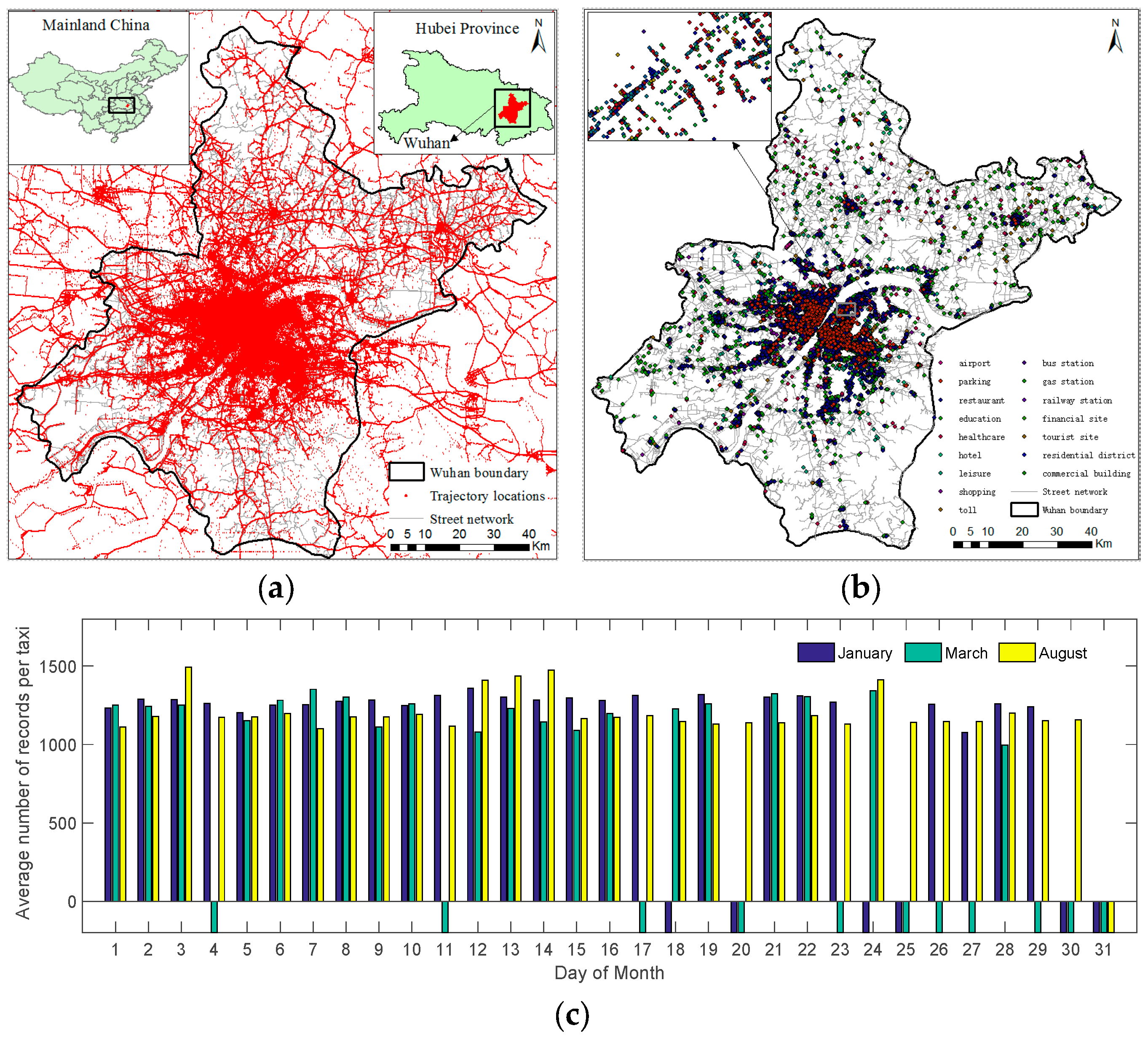
2. Datasets and Preprocessing
2.1. GPS Trajectory Dataset
2.2. POI Dataset
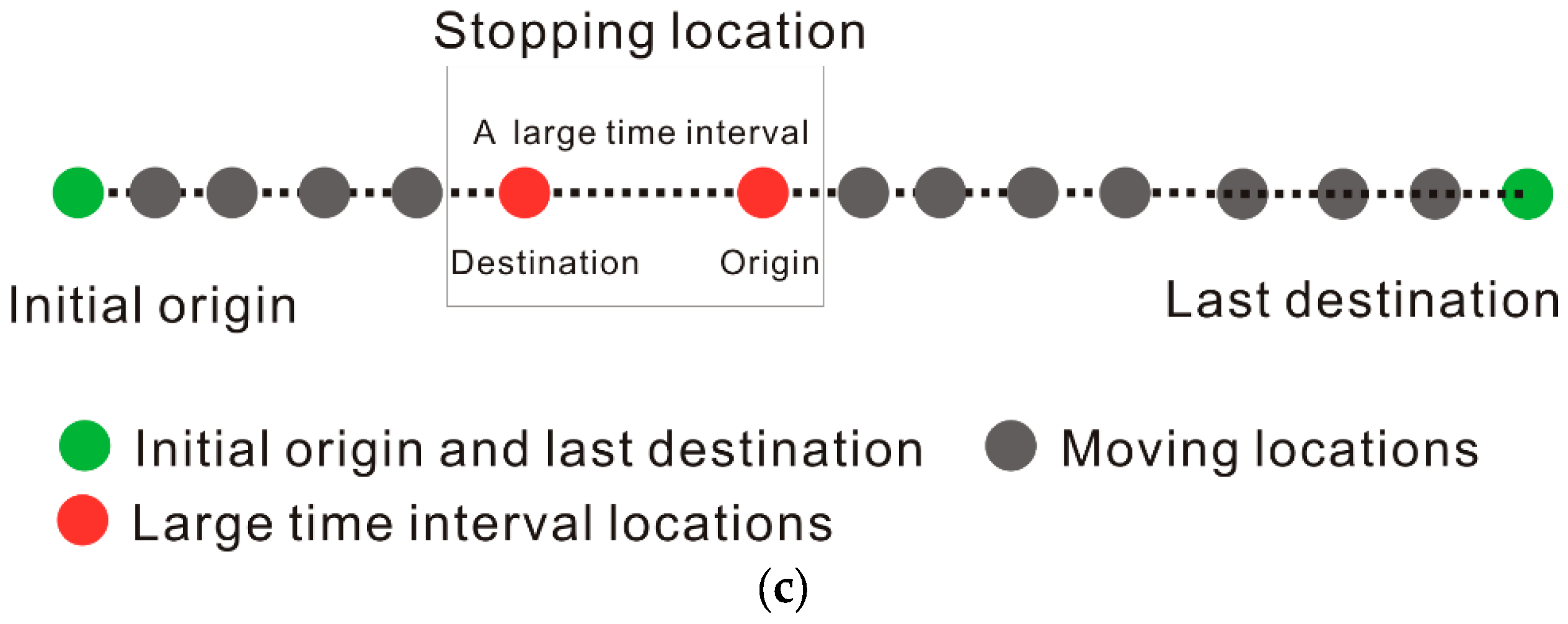
2.3. Stopping Locations
2.4. Human Activity Hotspots
3. Identify the Reliable Human Activity Hotspots from Their Scaling Pattern
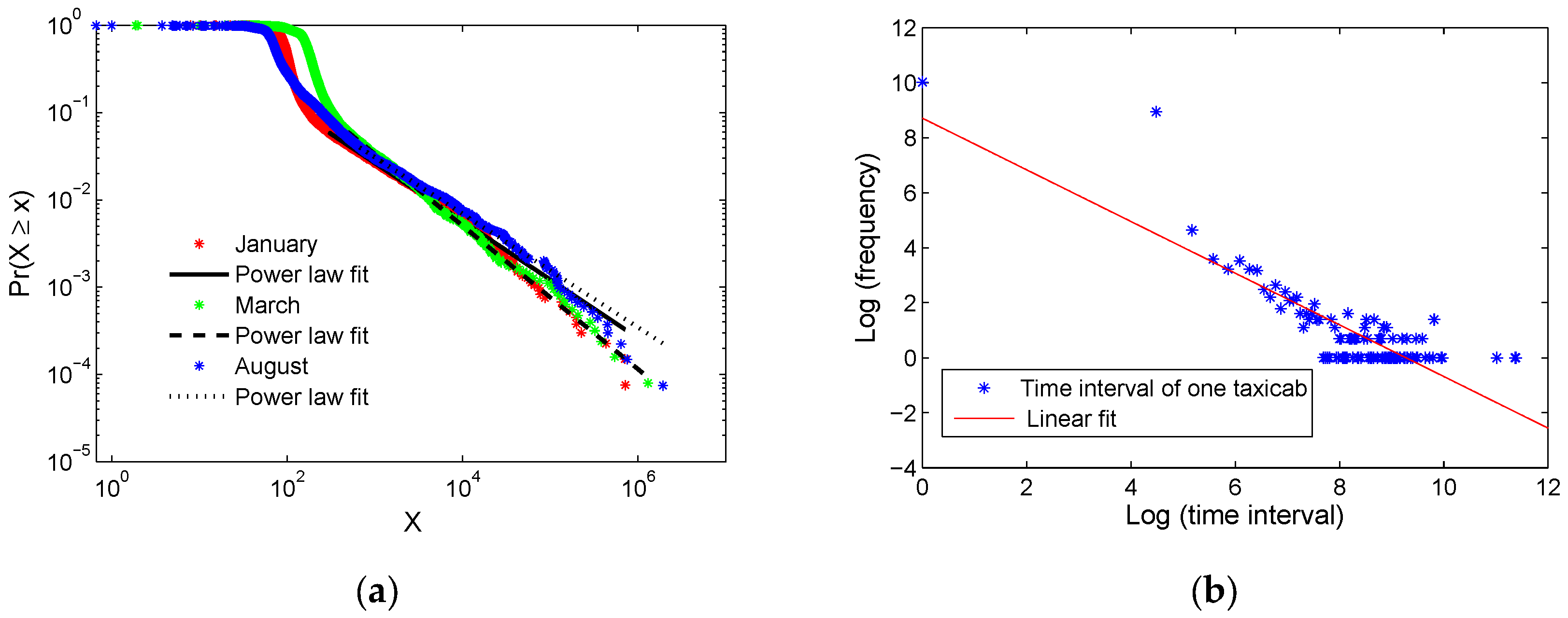
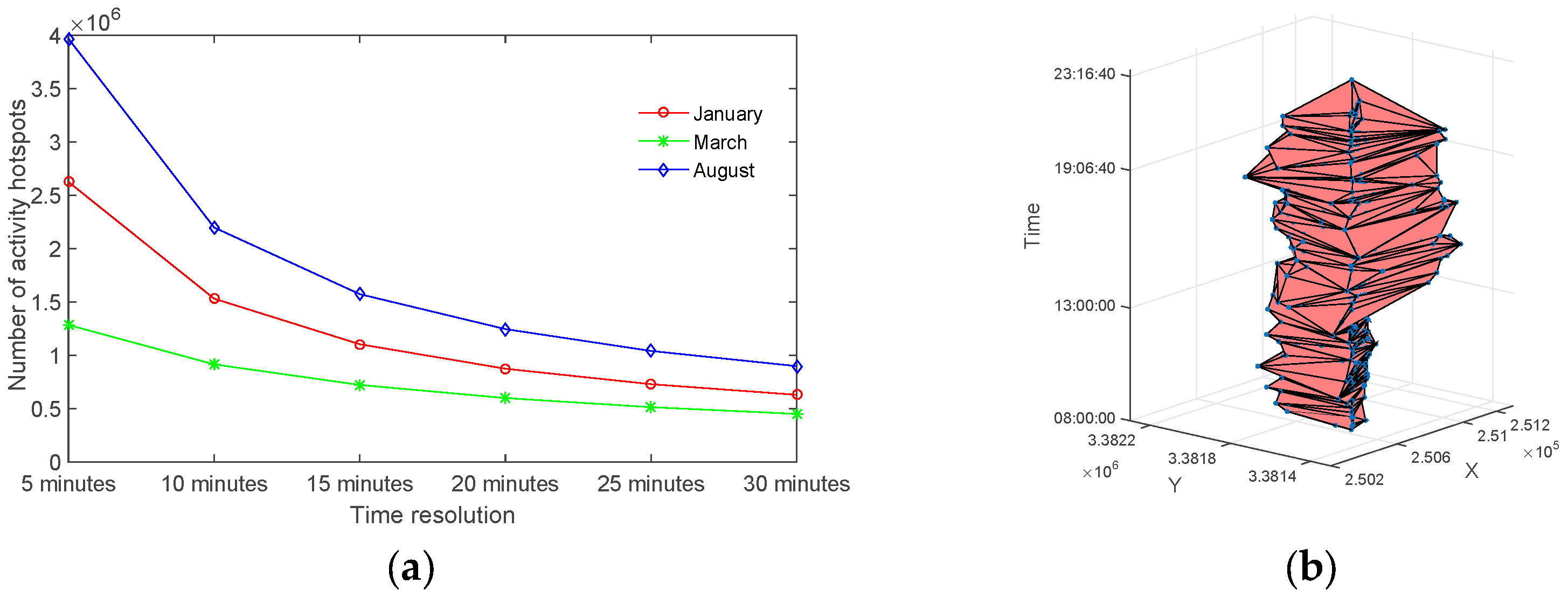
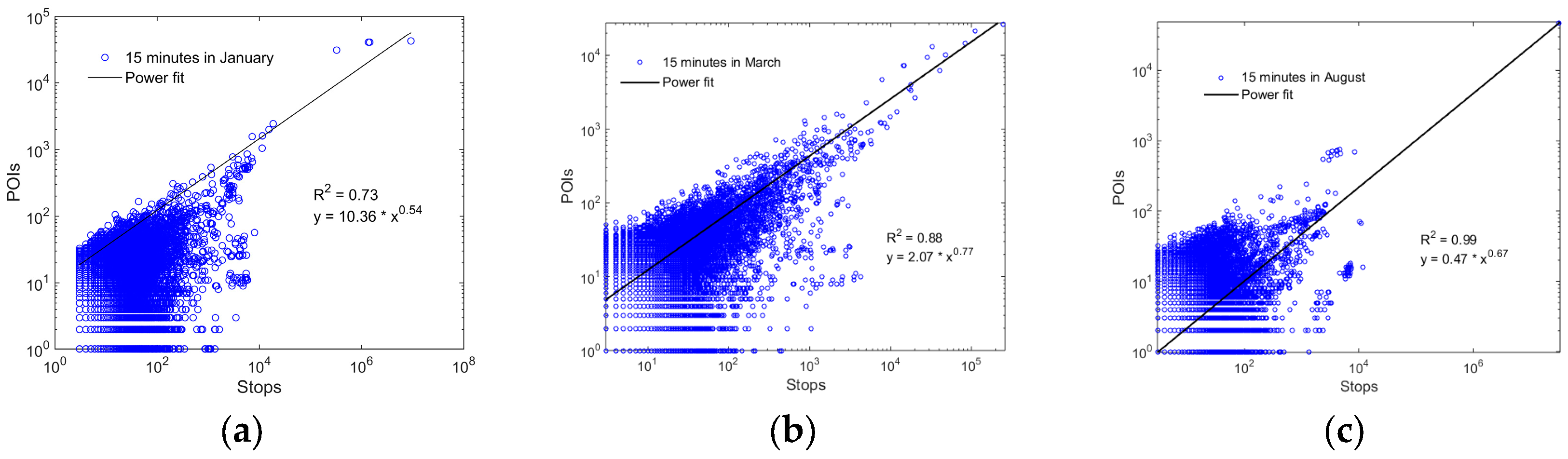
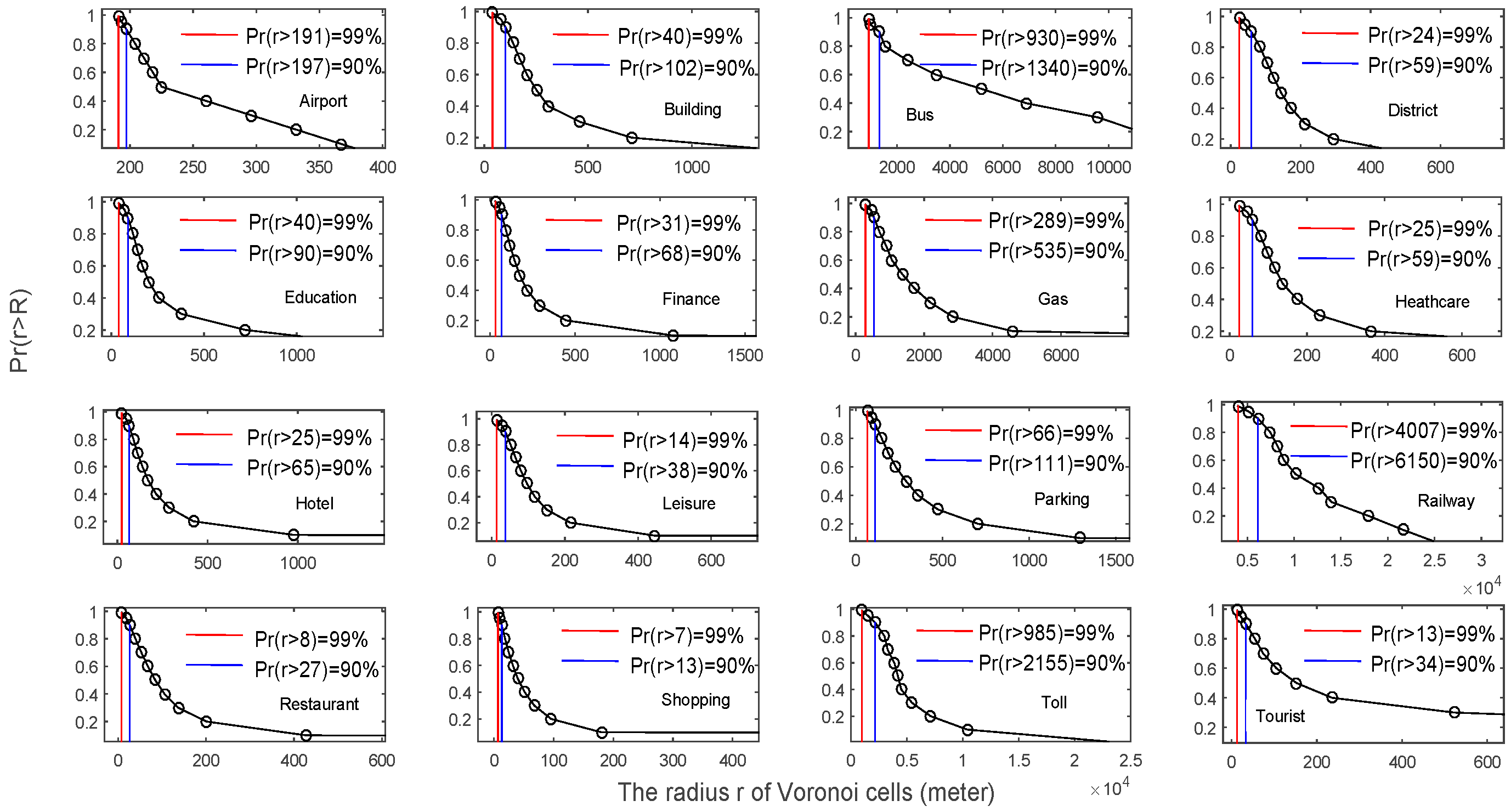
3.1. Scaling Pattern of Human Activity Hotspots
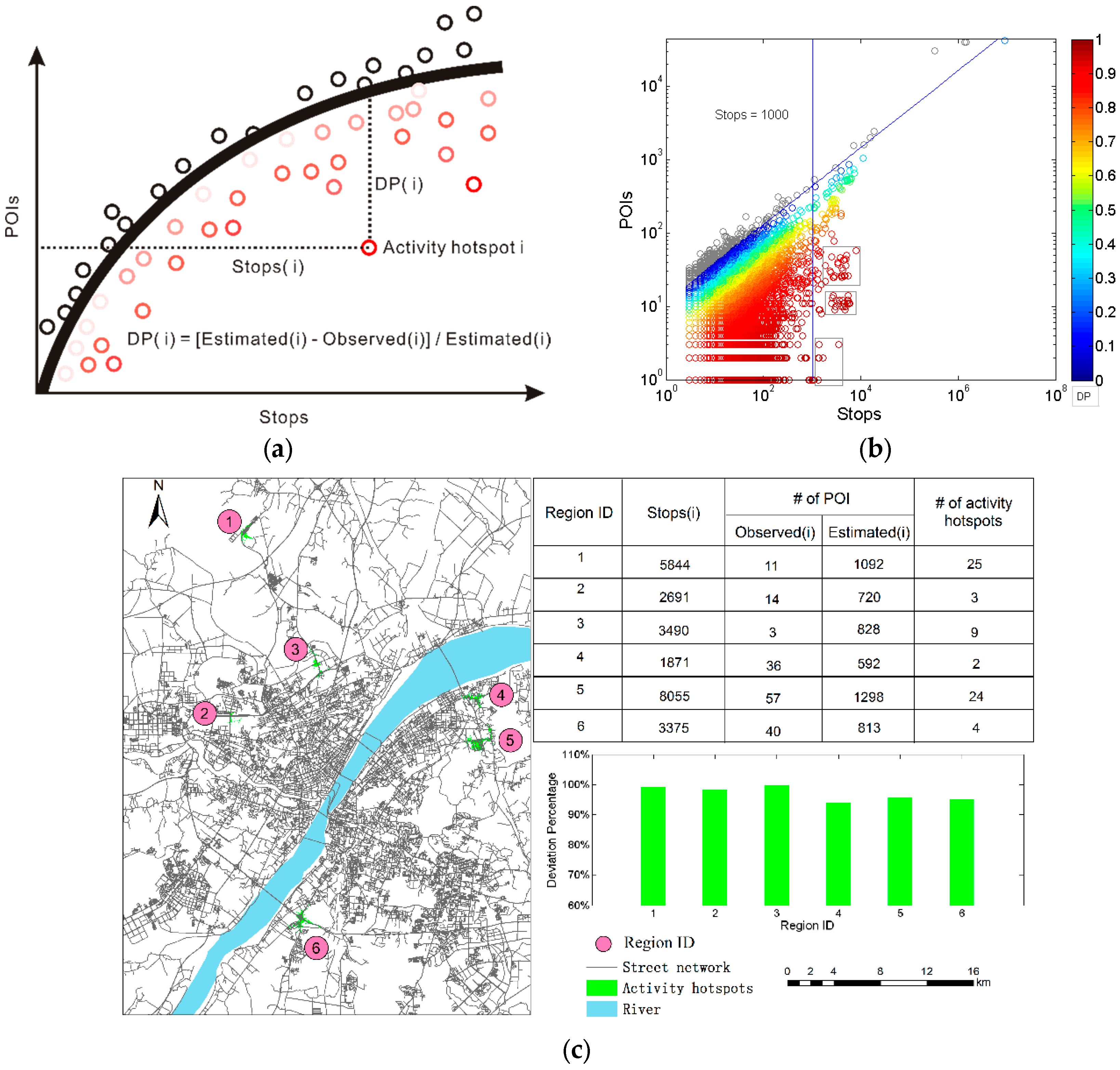
3.2. Identification of the Reliable Human Activity Hotspots
4. Inferring the Functionality of Reliable Activity Hotspots Using a Bayesian Model
4.1. Construct the Bayesian Inference Model
4.2. Train the Model and Infer the Urban Functionality
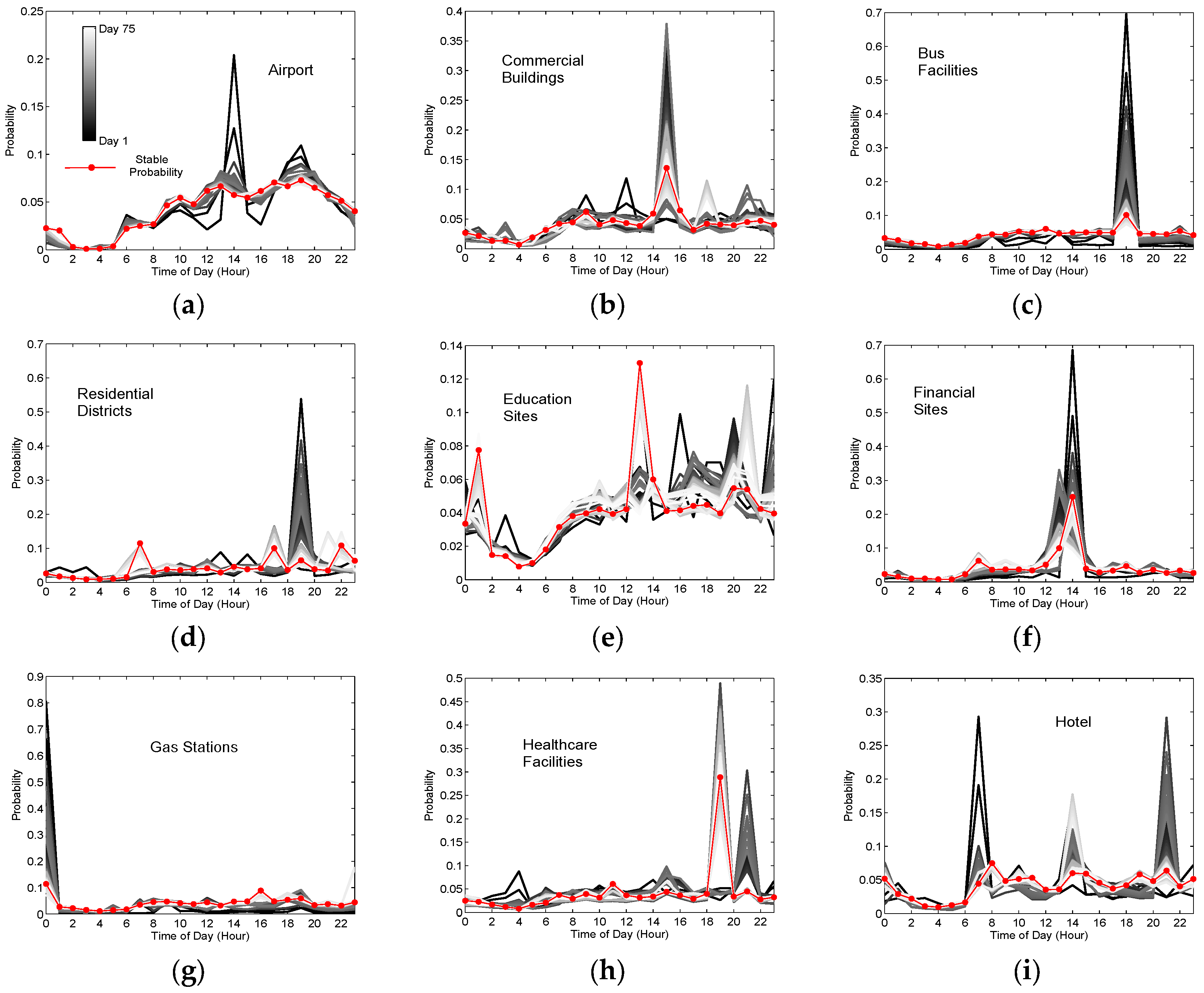
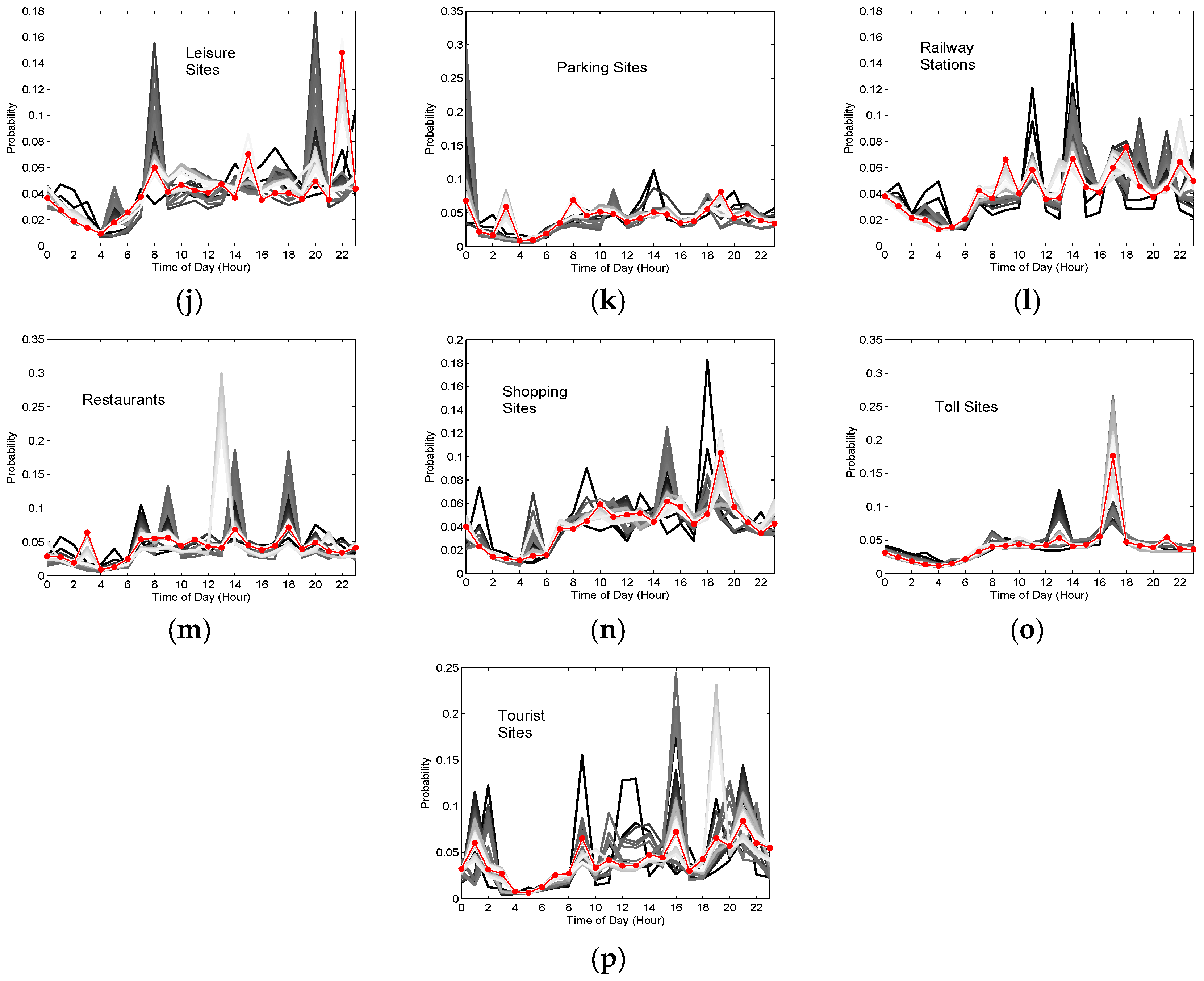
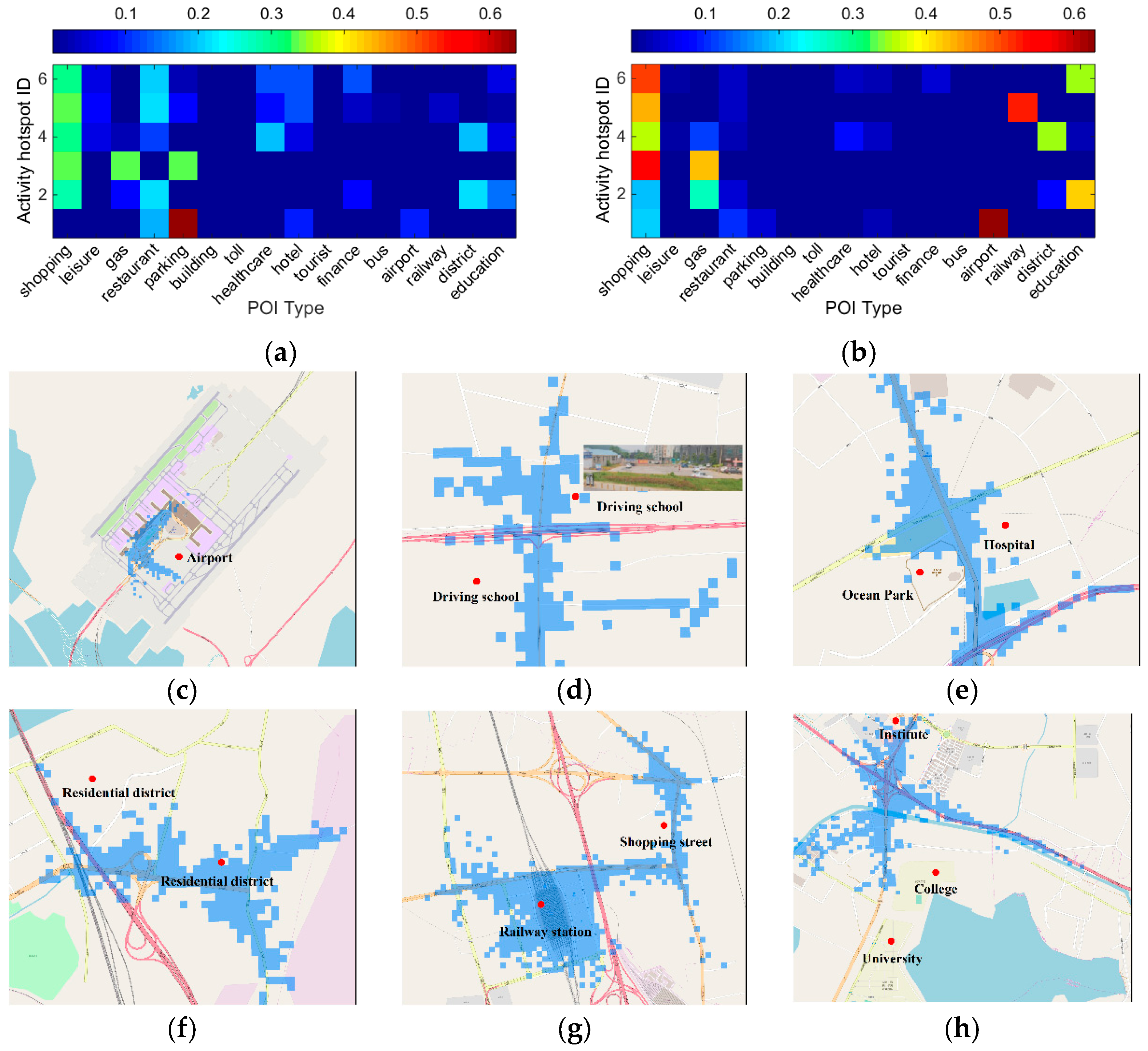
- Activity hotspot 1: It is enhanced by improving the importance of airport, namely many stopping locations are matched with the POI of airport. Hence, it is considered to provide aviation service, which coincides with the real situation by visual check in Figure 7c.
- Activity hotspot 2: It is enhanced by improving the importance of education and gas station. The two major functionalities indicate that it mainly provides the service of driver training, which can be visually checked in Figure 7d with two driving schools.
- Activity hotspot 3: It is not enhanced by our model, which is considered as a shopping region. But, as shown in Figure 7e, it mainly provides healthcare and recreation services. The reason can be probably attributed to the long walking distance from the stopping locations to the two POIs due to the current city planning.
- Activity hotspot 4: It is slightly enhanced by improving the importance of residential district and shopping. Hence, it is considered as a residential area with abundant shopping sites, few gas stations and healthcare sites by visual check in Figure 7f.
- Activity hotspot 5: It is obviously enhanced by improving the importance of railway stations, namely many stopping locations are matched with the POI of railway station. Hence, it is considered as a railway service area, which agrees well the real land use pattern (Figure 7g).
- Activity hotspot 6: It is clearly enhanced by emphasizing the importance of education. Hence, it is regarded as the place mainly providing education services, which is compatible with the three institutions or universities there by visual check in Figure 7h.
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cleveland, W.S. Data science: An action plan for expanding the technical areas of the field of statistics. Stat. Anal. Data Min. 2014, 7, 414–417. [Google Scholar] [CrossRef]
- Widener, M.J.; Li, W. Using geolocated Twitter data to monitor the prevalence of healthy and unhealthy food references across the US. Appl. Geogr. 2014, 54, 189–197. [Google Scholar] [CrossRef]
- Yang, W.; Mu, L. GIS analysis of depression among Twitter users. Appl. Geogr. 2015, 60, 217–223. [Google Scholar] [CrossRef]
- Yan, Z.X. Towards semantic trajectory data analysis: A conceptual and computational approach. In Proceedings of the 2009 Very Large Data Bases (VLDB) Conference, Lyon, France, 28 August 2009. [Google Scholar]
- Bohte, W.; Maat, K. Deriving and validating trip purposes and travel modes for multi-day GPS-based travel surveys: A large-scale application in the Netherlands. Transp. Res. Part C Emerg. Technol. 2009, 17, 285–297. [Google Scholar] [CrossRef]
- Jia, T.; Carling, K.; Håkansson, J. Trips and their CO2 emissions to and from a shopping center. J. Transp. Geogr. 2013, 33, 135–145. [Google Scholar] [CrossRef]
- Carling, K.; Håkansson, J.; Jia, T. Out-of-town shopping and its induced CO2 emissions. J. Retail. Consum. Serv. 2013, 20, 382–388. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Wang, X.; Qin, Q.; Wei, Z.; Li, J. Application of GPS Trajectory Data for Investigating the Interaction between Human Activity and Landscape Pattern: A Case Study of the Lijiang River Basin, China. ISPRS Int. J. Geo-Inf. 2016, 5, 104. [Google Scholar] [CrossRef]
- Reades, J.; Calabrese, F.; Ratti, C. Eigenplaces: Analysing cities using the space-time structure of the mobile phone network. Environ. Plan. B Plan. Des. 2009, 36, 824–836. [Google Scholar] [CrossRef]
- Neuhaus, F. Urban Diary-A tracking project: Capturing the beat and rhythm of the city: Using GPS devices to visualize individual and collective routines within Central London. J. Space Syntax 2010, 1, 315–336. [Google Scholar]
- Jia, T.; Jiang, B. Exploring human activity patterns using taxicab static points. ISPRS Int. J. Geo-Inf. 2012, 1, 89–107. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, J.; Wilkie, D.; Zheng, Y.; Xie, X. Sensing the pulse of urban refueling behavior: A perspective from taxi mobility. ACM Trans. Intell. Syst. Technol. 2013, 9, 1–24. [Google Scholar] [CrossRef]
- Scholz, R.W.; Lu, Y. Detection of dynamic activity patterns at a collective level from large-volume trajectory data. Int. J. Geogr. Inf. Sci. 2014, 28, 946–963. [Google Scholar] [CrossRef]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; de Macedo, J.A.F.; Moelans, B.; Vaisman, A. A model for enriching trajectories with semantic geographical information. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems, Seattle, WA, USA, 7–9 November 2007. [Google Scholar]
- Rozenfeld, H.D.; Rybski, D.; Andrade, J.S., Jr.; Batty, M.; Stanley, H.E.; Makse, H.A. Laws of population growth. Proc. Natl. Acad. Sci. USA 2008, 105, 18702–18707. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Xu, W. A clustering-based approach for discovering interesting places in a single trajectory. In Proceedings of the 2009 Second International Conference on Intelligent Computation Technology and Automation, Zhangjiajie, China, 10–11 October 2009. [Google Scholar]
- Louail, T.; Lenormand, M.; Cantu-Ros, O.G.; Picornell, M.; Herranz, R.; Frias-Martinez, E.; Ramasco, J.J.; Barthelemy, M. From mobile phone data to the spatial structure of cities. Sci. Rep. 2014, 4, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Y.; Fan, H.; Li, M.; Zipf, A. Identifying the city center using human travel flows generated from location-based social networking data. Environ. Plan. B Plan. Des. 2016, 43, 480–498. [Google Scholar] [CrossRef]
- Santos, M.; Moreira, A. Automatic classification of location contexts with decision trees. In Proceedings of the CSMU-2006: Conference on Mobile and Ubiquitous Systems, Guimares, Portugal, 29–30 June 2006. [Google Scholar]
- Jiang, S.; Alves, A.; Rodrigues, F.; Ferreira, J.; Pereira, F.C. Mining point-of-interest data from social networks for urban land use classification and disaggregation. Comput. Environ. Urban Syst. 2015, 53, 36–46. [Google Scholar] [CrossRef]
- Zeng, L.R.; Lin, H.F. Analysis of land use along urban rail transit based on POI Data. In Proceedings of the 16th COTA International Conference of Transportation Professionals, Shanghai, China, 6–9 July 2016. [Google Scholar]
- Yue, Y.; Zhuang, Y.; Yeh, A.G.O.; Xie, J.Y.; Ma, C.L.; Li, Q.Q. Measurements of POI-based mixed use and their relationships with neighbourhood vibrancy. Int. J. Geogr. Inf. Sci. 2017, 31, 658–675. [Google Scholar] [CrossRef]
- Wolf, J.; Schönfelder, S.; Samaga, U.; Oliveira, M.; Axhausen, K.W. 80 weeks of GPS-traces: Approaches to enriching the trip information. Transp. Res. Rec. 2004, 1870, 46–54. [Google Scholar] [CrossRef]
- Xie, K.; Deng, K.; Zhou, X. From trajectories to activities: A spatio-temporal join approach. In Proceedings of the 2009 International Workshop on Location Based Social Networks, New York, NY, USA, 4–6 November 2009. [Google Scholar]
- Griffin, T.; Huang, Y. A decision tree classification model to automate trip purpose derivation. In Proceedings of the ISCA 18th International Conference on Computer Applications in Industry and Engineering, Honolulu, HI, USA, 9–11 November 2005; pp. 44–49. [Google Scholar]
- Montini, L.; Rieser-Schüssler, N.; Horni, A.; Axhausen, K. Trip purpose identification from gps tracks. Transp. Res. Rec. J. Transp. Res. Board 2014, 2405, 16–23. [Google Scholar] [CrossRef]
- Furletti, B.; Cintia, P.; Renso, C.; Spinsanti, L. Inferring human activities from gps tracks. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11 August 2013. [Google Scholar]
- Moiseeva, A.; Jessurun, J.; Timmermans, H. Semiautomatic imputation of activity-travel diaries using GPS traces, prompted recall, and context-sensitive learning algorithms. Transp. Res. Rec. J. Transp. Res. Board 2010, 2183, 60–68. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, G.; Pan, G.; Lu, H.; Li, S.; Wu, Z. City-Scale social event detection and evaluation with taxi traces. ACM Trans. Intell. Syst. Technol. 2015, 6, 40. [Google Scholar] [CrossRef]
- Fuchs, G.; Stange, H.; Hecker, D.; Andrienko, N.; Andrienko, G. Constructing semantic interpretation of routine and anomalous mobility behaviors from big data. ACM SIGSPAT. Spec. 2015, 7, 27–34. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Pan, G.; Qi, G.; Wu, Z.; Zhang, D.; Li, S. Land-Use classification using taxi GPS traces. IEEE Trans. Intell. Transp. Syst. 2013, 14, 113–123. [Google Scholar] [CrossRef]
- Gong, L.; Liu, X.; Wu, L.; Liu, Y. Inferring trip purposes and uncovering travel patterns from taxi trajectory data. Cartogr. Geogr. Inf. Sci. 2015, 43, 103–114. [Google Scholar] [CrossRef]
- Brockmann, D.; Hufnagel, L.; Geisel, T. The scaling laws of human travel. Nature 2006, 439, 462–465. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Jia, T. Zipf’s law for all the natural cities in the United States: A geospatial perspective. Int. J. Geogr. Inf. Sci. 2011, 25, 1269–1281. [Google Scholar] [CrossRef]
- Jia, T.; Jiang, B.; Carling, K.; Bolin, M.; Ban, Y.F. An empirical study on human mobility and its agent-based modeling. J. Stat. Mech. Theory Exp. 2012. [Google Scholar] [CrossRef]
- Bettencourt, L.M.A.; Lobo, J.; Helbing, D.; Kühnert, C.; West, G.B. Growth, innovation, scaling, and the pace of life in cities. Proc. Natl. Acad. Sci. USA 2007, 104, 7301–7306. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, N.K. Scaling: Why Is Animal Size So Important; Cambridge University Press: Cambridge, UK, 1984. [Google Scholar]
- Lobo, J.; Bettencourt, L.M.A.; Strumsky, D.; West, G.B. Urban scaling and the production function for cities. PLoS ONE 2013, 8, e58407. [Google Scholar] [CrossRef] [PubMed]
- Schlapfer, M.; Bettencourt, L.M.A.; Grauwin, S.; Raschke, M.; Claxton, R.; Smoreda, Z.; West, G.B.; Ratti, C. The scaling of human interactions with city size. J. R. Soc. Interface 2014, 11, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Sutton, P.C. A scale-adjusted measure of “Urban sprawl” using nighttime satellite imagery. Remote Sens. Environ. 2003, 86, 353–369. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, X.; Jia, T. Scaling of geographic space as a universal rule for map generalization. Ann. Am. Assoc. Geogr. 2013, 103, 844–855. [Google Scholar] [CrossRef]
- Jiang, B. Head/Tail breaks: A new classification scheme for data with a heavy-tailed distribution. Prof. Geogr. 2013, 65, 482–494. [Google Scholar] [CrossRef]
- Dunham-Snary, K.J.; Sandel, M.W.; Westbrook, D.G.; Ballinger, S.W. A method for assessing mitochondrial bioenergetics in whole white adipose tissues. Redox Biol. 2014, 2, 656–660. [Google Scholar] [CrossRef] [PubMed]
- Long, Y.; Thill, J.C. Combining smart card data and household travel survey to analyze jobs–housing relationships in Beijing. Comput. Environ. Urban Syst. 2015, 53, 19–35. [Google Scholar] [CrossRef]
- Long, Y. Redefining Chinese city system with emerging new data. Appl. Geogr. 2016, 75, 36–48. [Google Scholar] [CrossRef]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Christaller, W. Central Places in Southern Germany, 1st ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1966. [Google Scholar]
- Page, L.; Brin, S. The anatomy of a large-scale hypertextual web search engine. In Proceedings of the Seventh International World-Wide Web Conference, Brisbane, Australia, 14–18 April 1998. [Google Scholar]
- Mtibaa, A.; May, M.; Ammar, M. Social Forwarding in Mobile Opportunistic Networks: A Case of PeopleRank. In Handbook of Optimization in Complex Networks; Thai, M., Pardalos, P., Eds.; Springer: New York, NY, USA, 2012; Volume 58. [Google Scholar]
- Ganji: The Monthly Income Distribution of Taxi Drivers in Wuhan. Available online: http://wh.ganji.com/gz_zpczcsiji/ (accessed on 3 November 2017).
- Haklay, M.; Weber, P. OpenStreetMap—User generated street map. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Resolution | a | b | R2 | Time Resolution | a | b | R2 | |
|---|---|---|---|---|---|---|---|---|
| January | 5 min | 4.02 | 0.64 | 0.82 | 20 min | 12.00 | 0.53 | 0.73 |
| 10 min | 7.45 | 0. 58 | 0.85 | 25 min | 13.68 | 0.52 | 0.73 | |
| 15 min | 10.36 | 0.54 | 0.73 | 30 min | 15.20 | 0.52 | 0.74 | |
| March | 5 min | 1.54 | 0.74 | 0.60 | 20 min | 3.18 | 0.74 | 0.89 |
| 10 min | 1.10 | 0.83 | 0.84 | 25 min | 3.43 | 0.72 | 0.92 | |
| 15 min | 2.07 | 0.77 | 0.88 | 30 min | 4.48 | 0.70 | 0.92 | |
| August | 5 min | 1.58 | 0.60 | 0.97 | 20 min | 0.29 | 0.69 | 0.99 |
| 10 min | 0.65 | 0.65 | 0.99 | 25 min | 0.25 | 0.70 | 0.99 | |
| 15 min | 0.47 | 0.67 | 0.99 | 30 min | 0.24 | 0.71 | 0.99 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, T.; Ji, Z. Understanding the Functionality of Human Activity Hotspots from Their Scaling Pattern Using Trajectory Data. ISPRS Int. J. Geo-Inf. 2017, 6, 341. https://doi.org/10.3390/ijgi6110341
Jia T, Ji Z. Understanding the Functionality of Human Activity Hotspots from Their Scaling Pattern Using Trajectory Data. ISPRS International Journal of Geo-Information. 2017; 6(11):341. https://doi.org/10.3390/ijgi6110341
Chicago/Turabian StyleJia, Tao, and Zheng Ji. 2017. "Understanding the Functionality of Human Activity Hotspots from Their Scaling Pattern Using Trajectory Data" ISPRS International Journal of Geo-Information 6, no. 11: 341. https://doi.org/10.3390/ijgi6110341
APA StyleJia, T., & Ji, Z. (2017). Understanding the Functionality of Human Activity Hotspots from Their Scaling Pattern Using Trajectory Data. ISPRS International Journal of Geo-Information, 6(11), 341. https://doi.org/10.3390/ijgi6110341