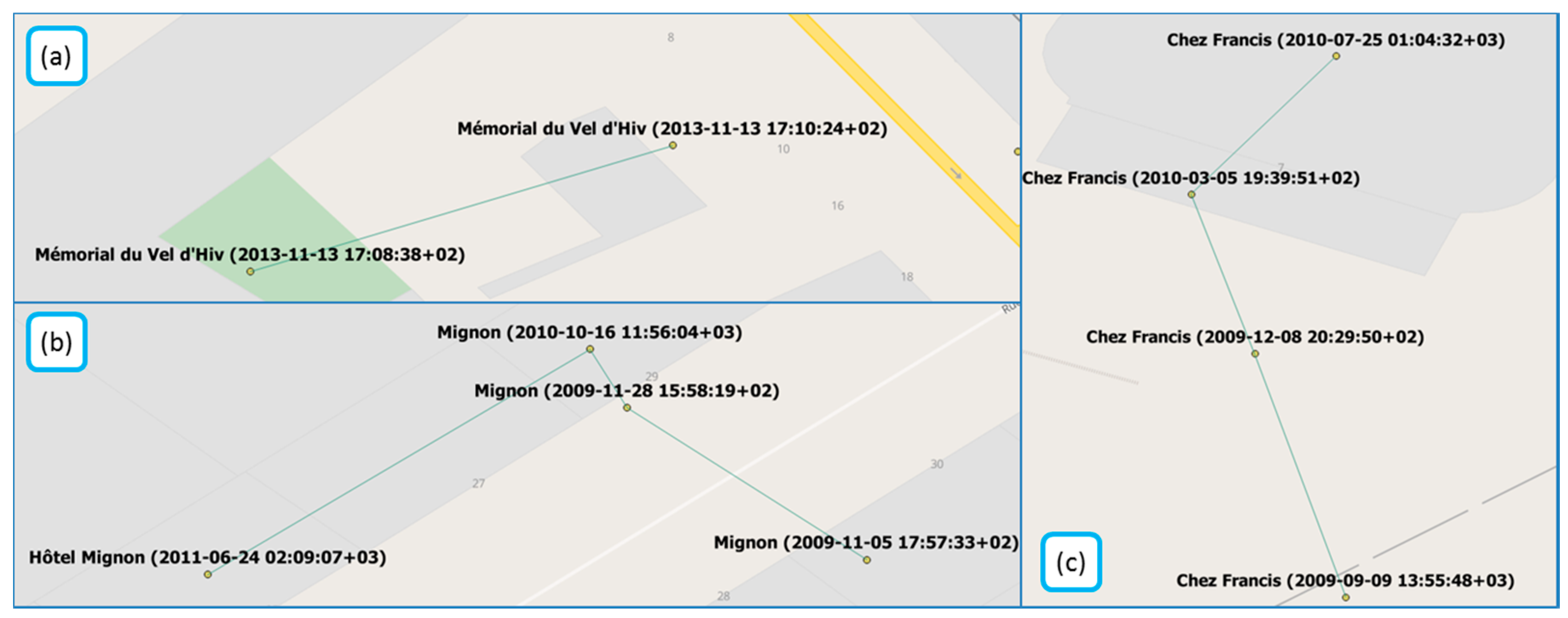
Figure 1.
Examples of displacement in OSM POIs (©OpenStreetMap contributors).
Figure 1.
Examples of displacement in OSM POIs (©OpenStreetMap contributors).
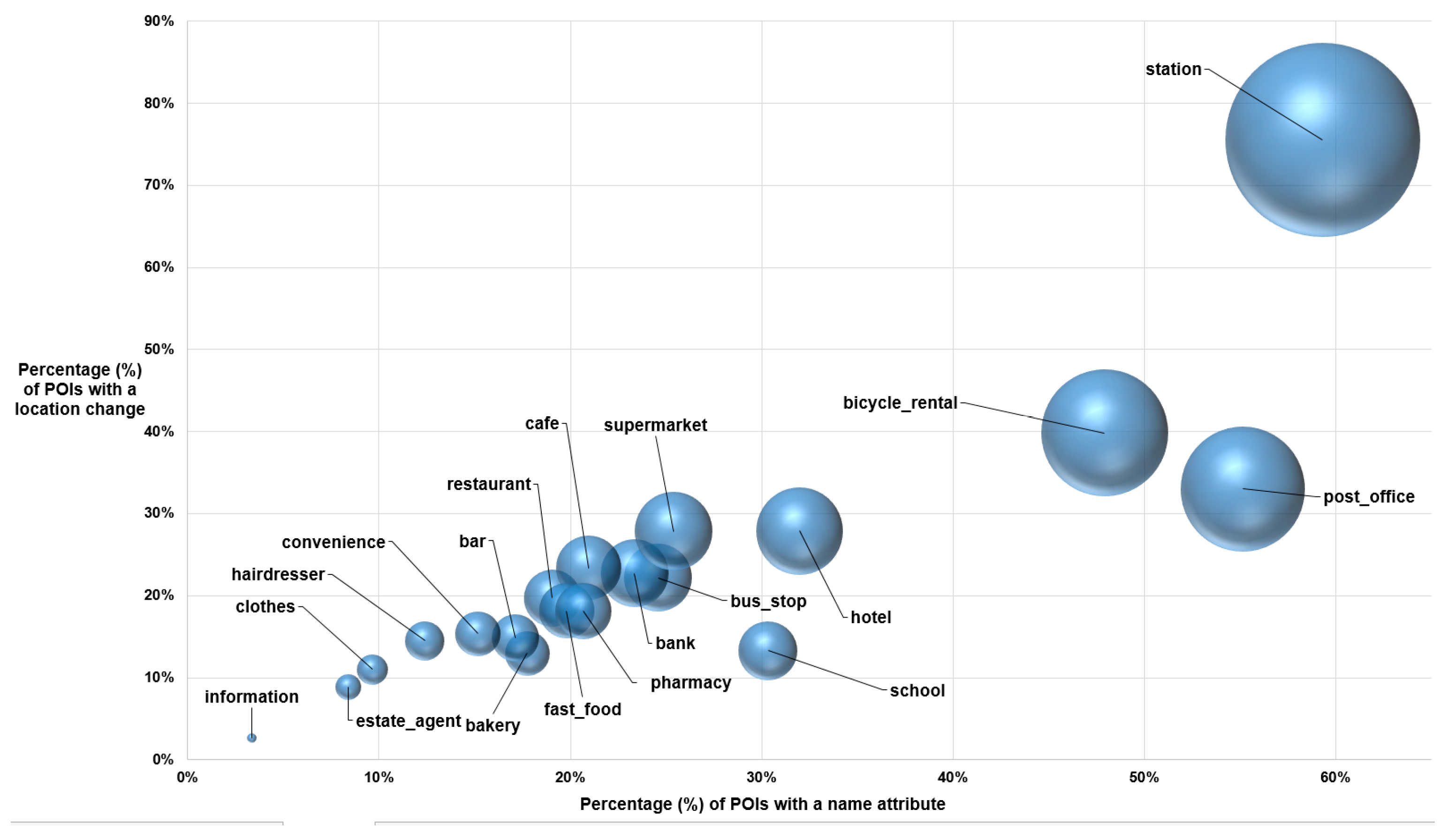
Figure 2.
Percentage of POIs that had a name (x-axis) and a location (y-axis) change. The size of the bubble corresponds to the intersection of the two changes.
Figure 2.
Percentage of POIs that had a name (x-axis) and a location (y-axis) change. The size of the bubble corresponds to the intersection of the two changes.
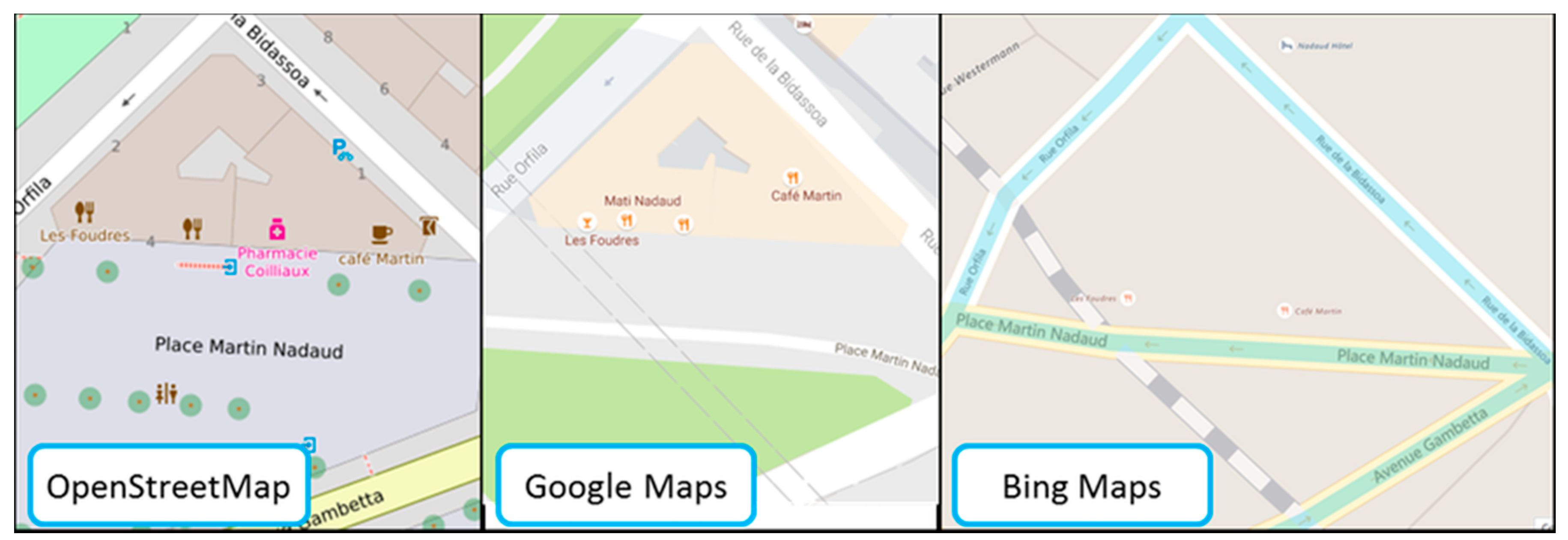
Figure 3.
Three maps where the POIs are located differently inside the buildings that host them.
Figure 3.
Three maps where the POIs are located differently inside the buildings that host them.
Figure 4.
Three spatial relations are checked: inside a building, the distance to the building center, and the distance to the nearest boundary as a proxy for an amenity entrance (©OpenStreetMap contributors).
Figure 4.
Three spatial relations are checked: inside a building, the distance to the building center, and the distance to the nearest boundary as a proxy for an amenity entrance (©OpenStreetMap contributors).
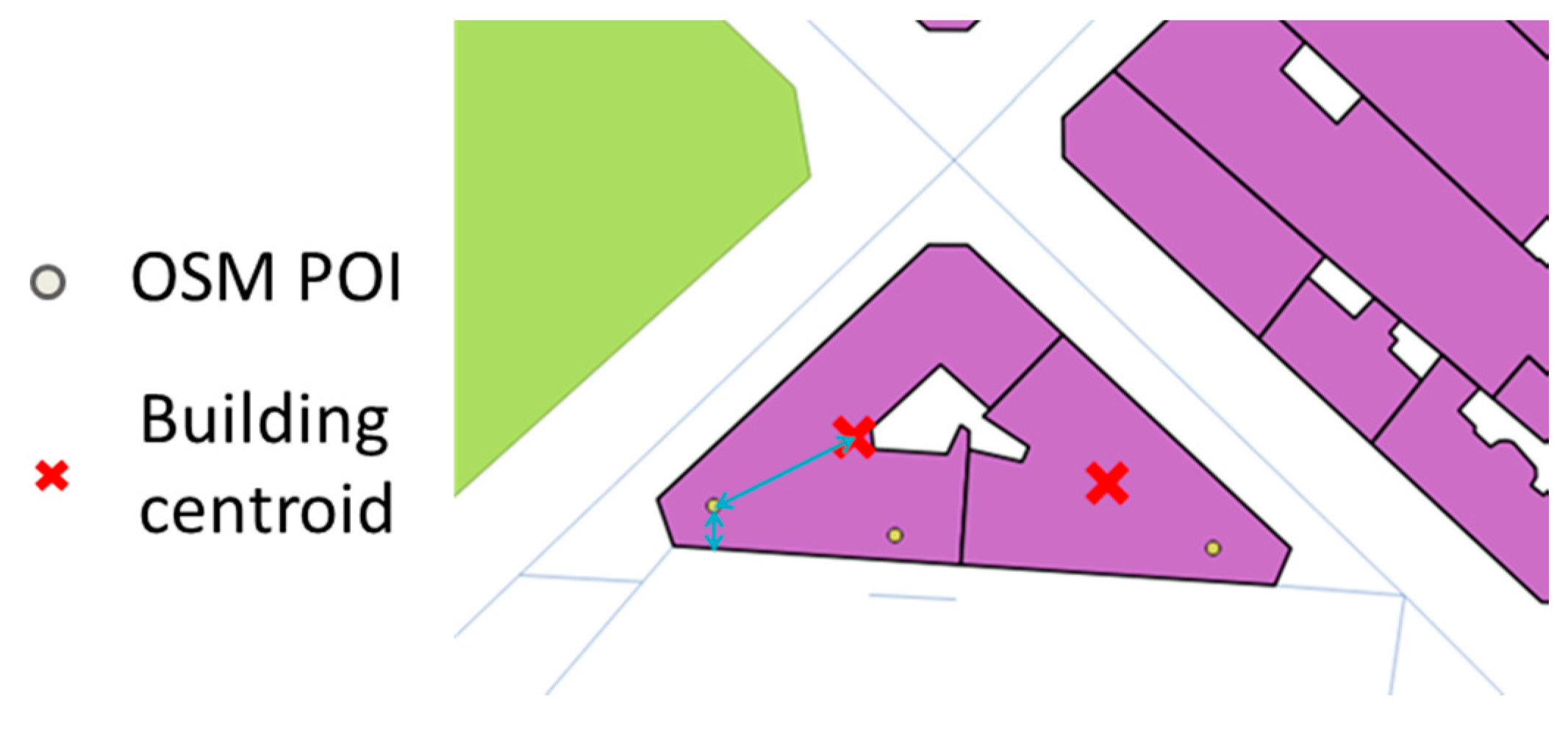
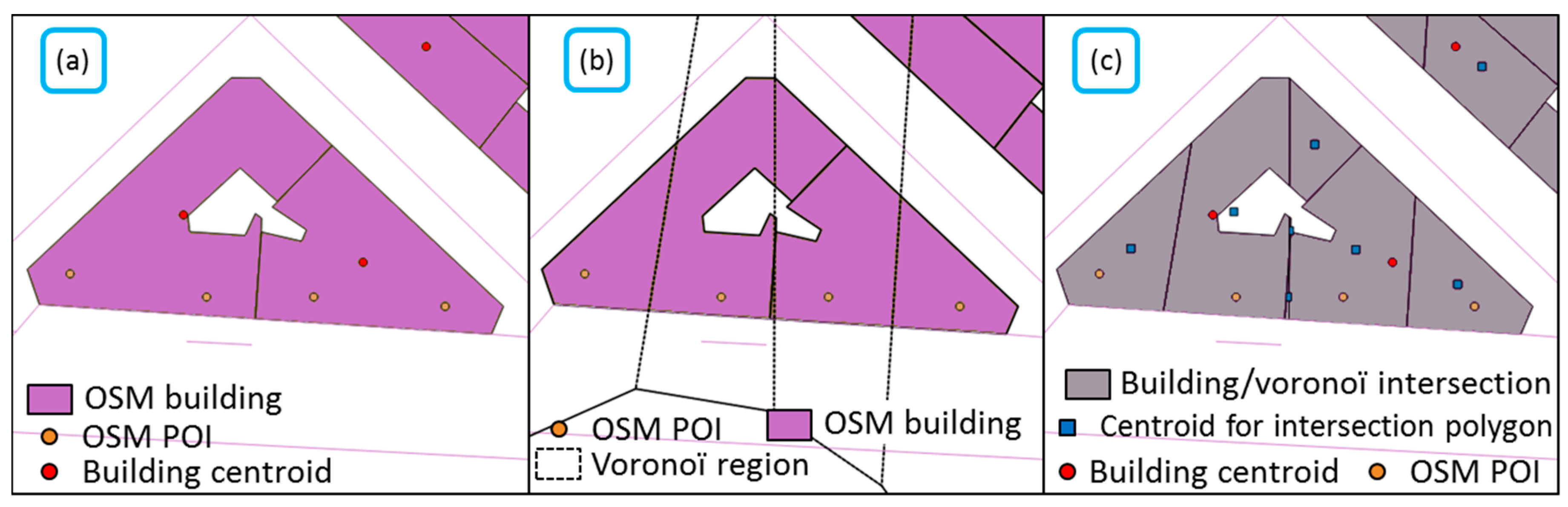
Figure 5.
(a) One building may cover several amenities so the centroid may be far from the amenity center, (b) using the Voronoï region intersected with the building gives (c) a better approximation of the amenity center (©OpenStreetMap contributors).
Figure 5.
(a) One building may cover several amenities so the centroid may be far from the amenity center, (b) using the Voronoï region intersected with the building gives (c) a better approximation of the amenity center (©OpenStreetMap contributors).
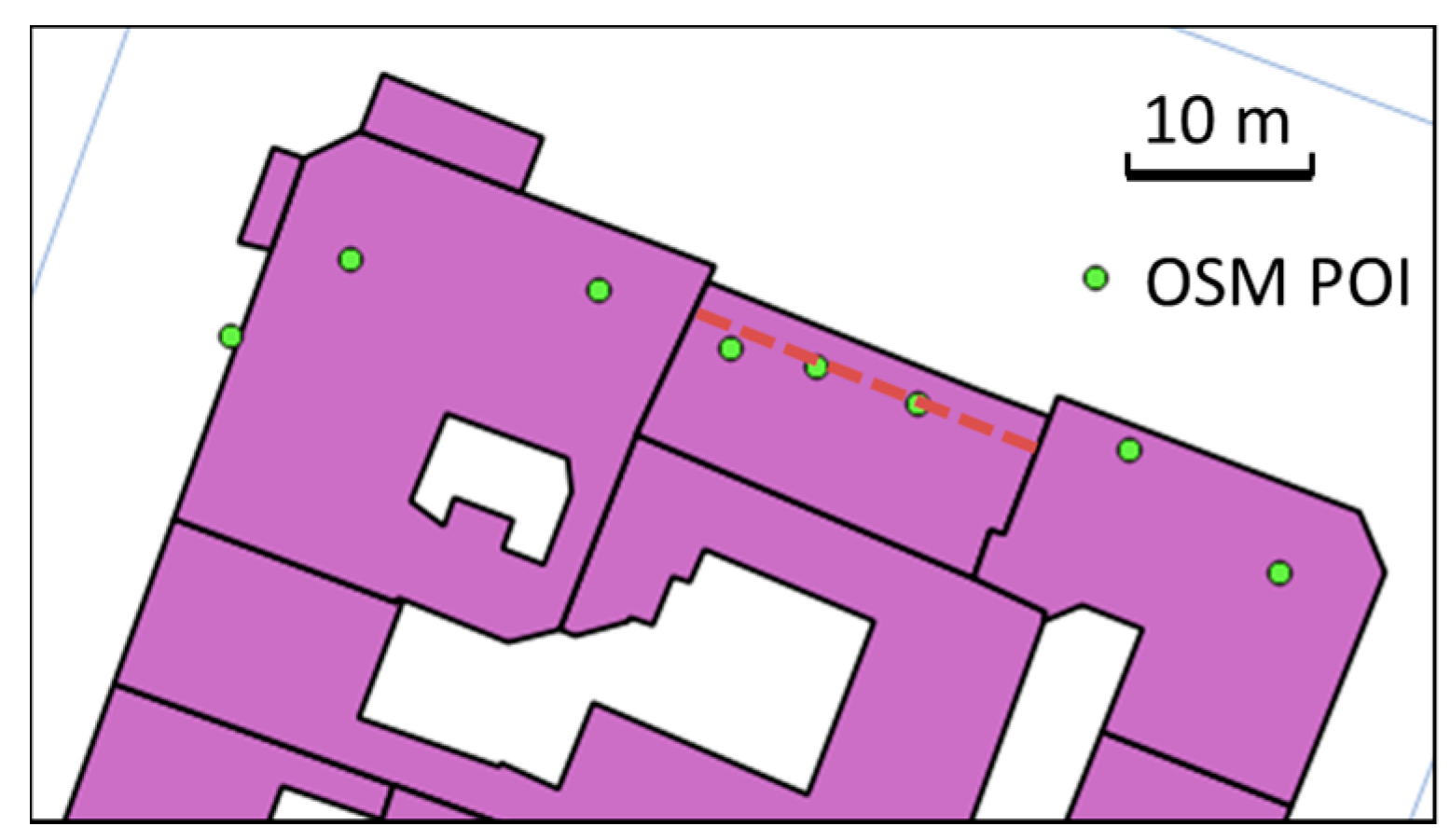
Figure 6.
Even if there is no unique location for an amenity POI inside a building, consistency in POI location (here points should all be aligned) is better than inconsistency (©OpenStreetMap contributors).
Figure 6.
Even if there is no unique location for an amenity POI inside a building, consistency in POI location (here points should all be aligned) is better than inconsistency (©OpenStreetMap contributors).
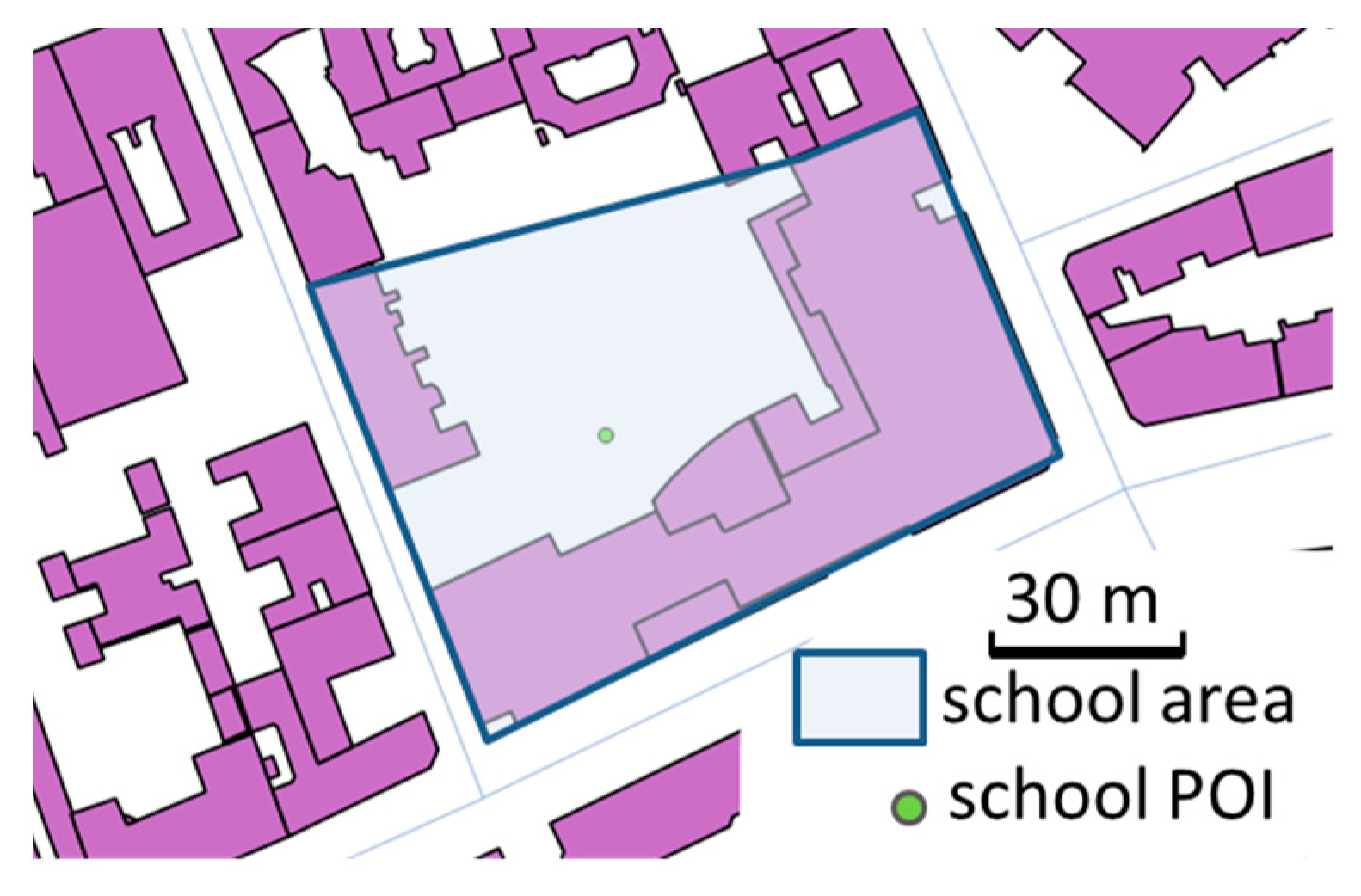
Figure 7.
A school area, buildings, and a school POI: schools can be composed of several buildings and school yards, so the POI might be located outside a building (©OpenStreetMap contributors).
Figure 7.
A school area, buildings, and a school POI: schools can be composed of several buildings and school yards, so the POI might be located outside a building (©OpenStreetMap contributors).
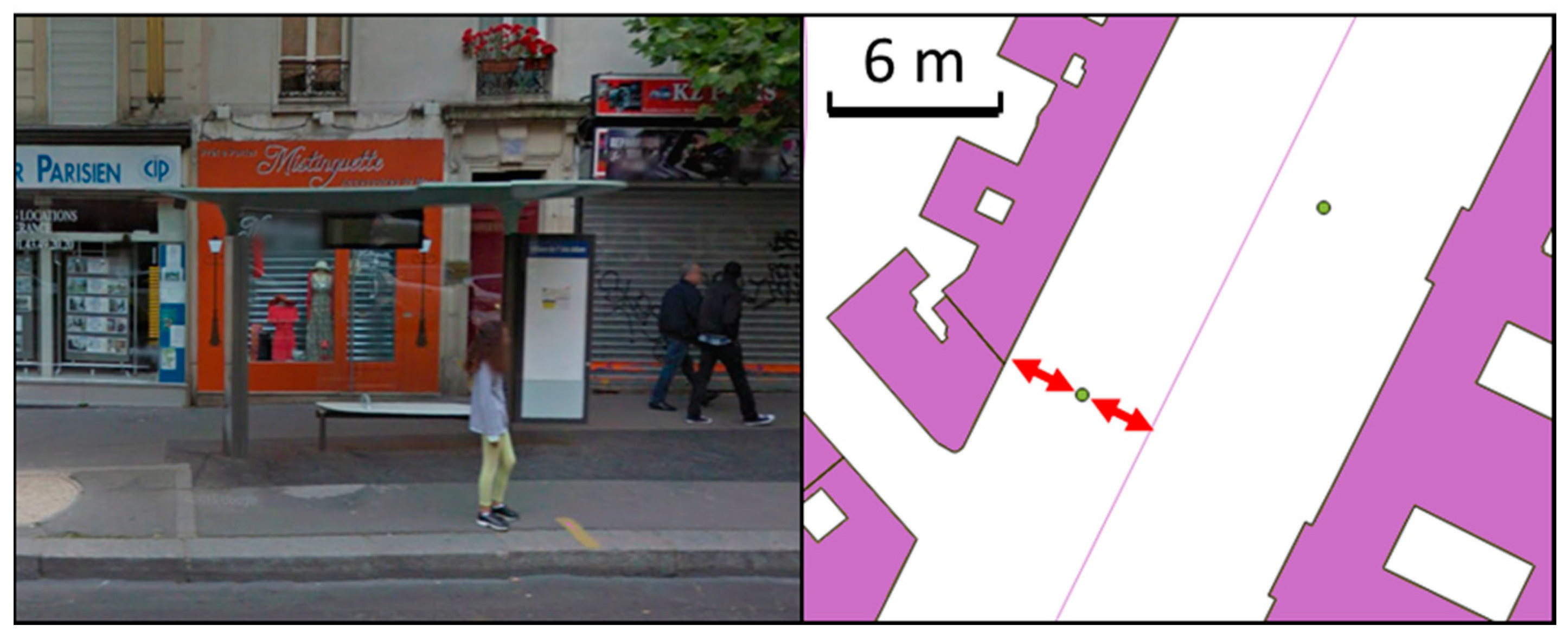
Figure 8.
Bus stops in Paris are located on the pavement, so should be located far enough from a road centerline and the buildings (©OpenStreetMap contributors).
Figure 8.
Bus stops in Paris are located on the pavement, so should be located far enough from a road centerline and the buildings (©OpenStreetMap contributors).
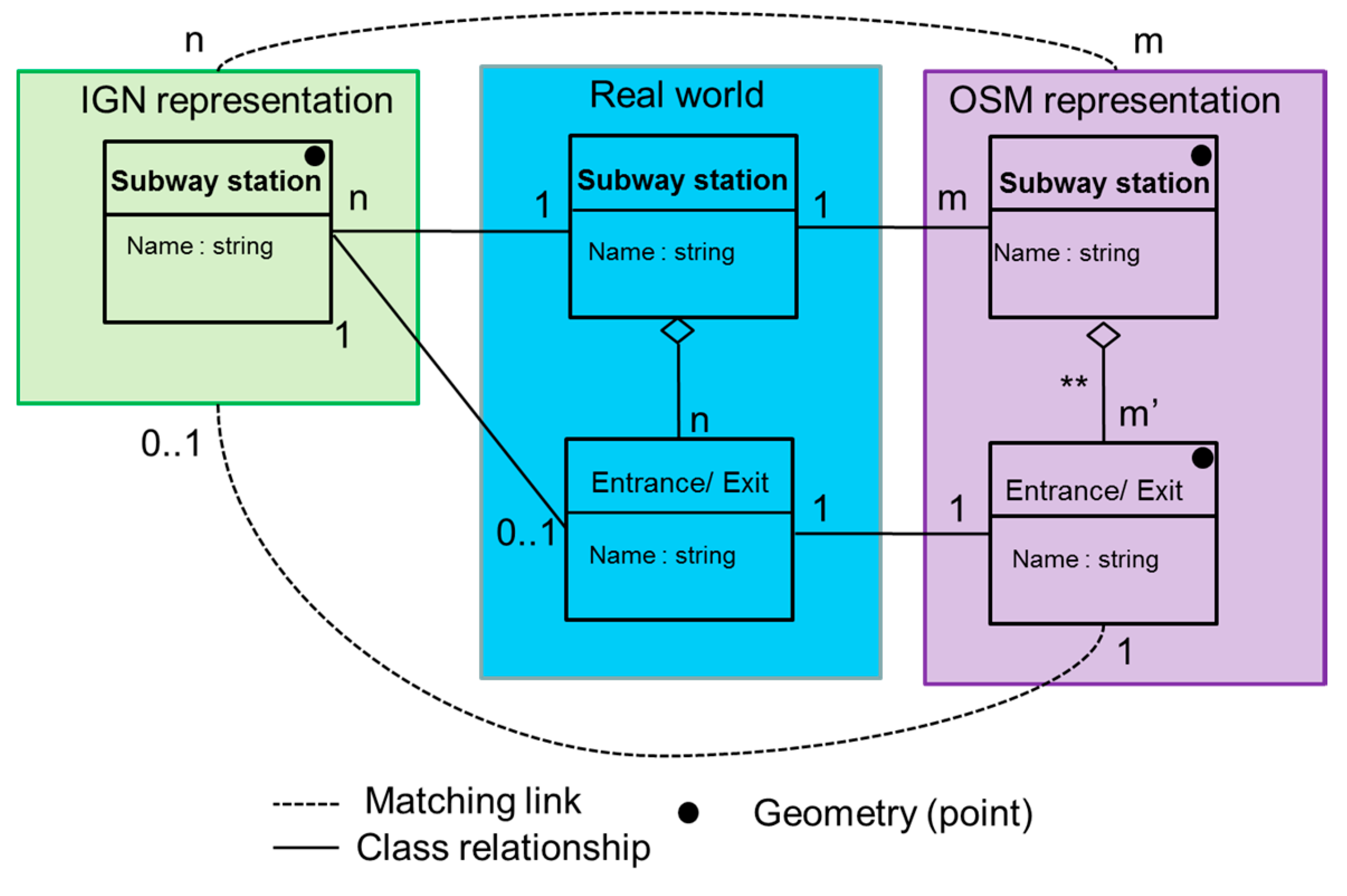
Figure 9.
Representation of subway stations in OSM and IGN datasets.
Figure 9.
Representation of subway stations in OSM and IGN datasets.
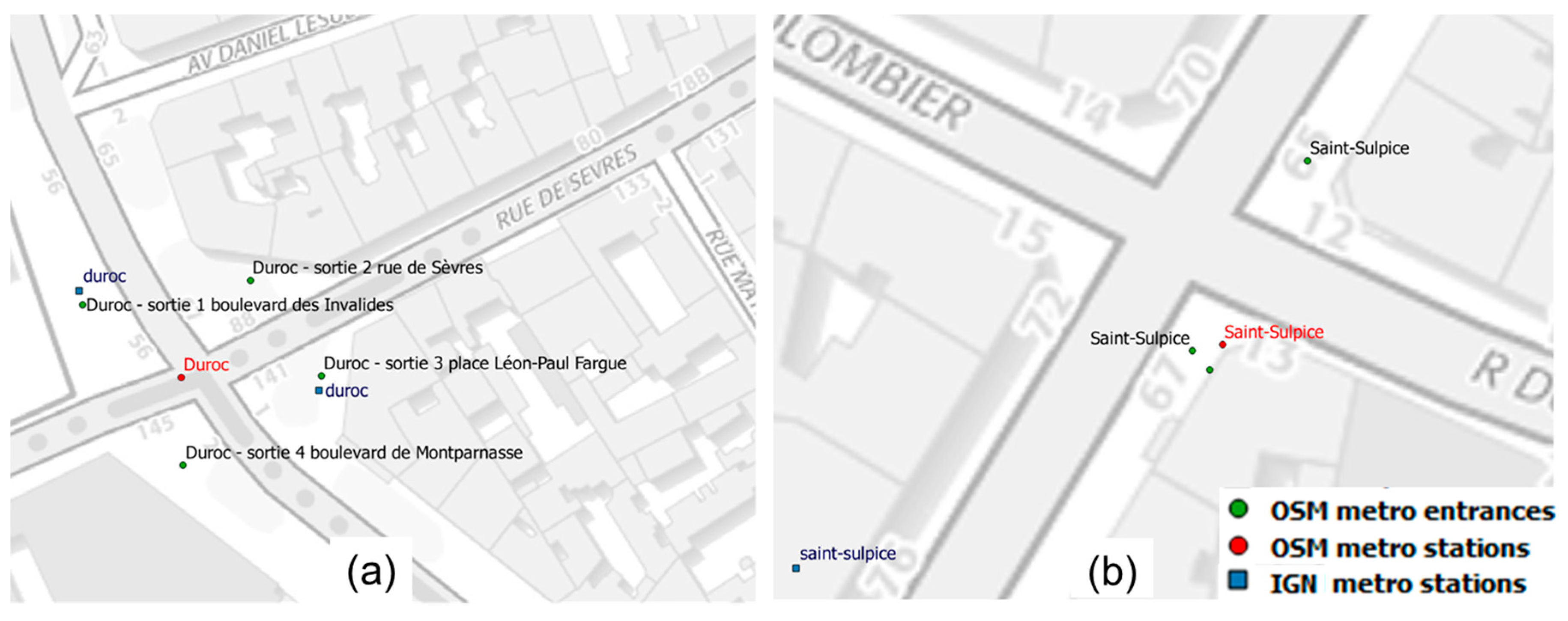
Figure 10.
Different representations of a subway station: (a) the two station POI in IGN are closer to OSM entrance POIs than to OSM station POI; (b) only one station POI in both datasets but not located at the same place (©OpenStreetMap contributors, ©BDTOPO).
Figure 10.
Different representations of a subway station: (a) the two station POI in IGN are closer to OSM entrance POIs than to OSM station POI; (b) only one station POI in both datasets but not located at the same place (©OpenStreetMap contributors, ©BDTOPO).
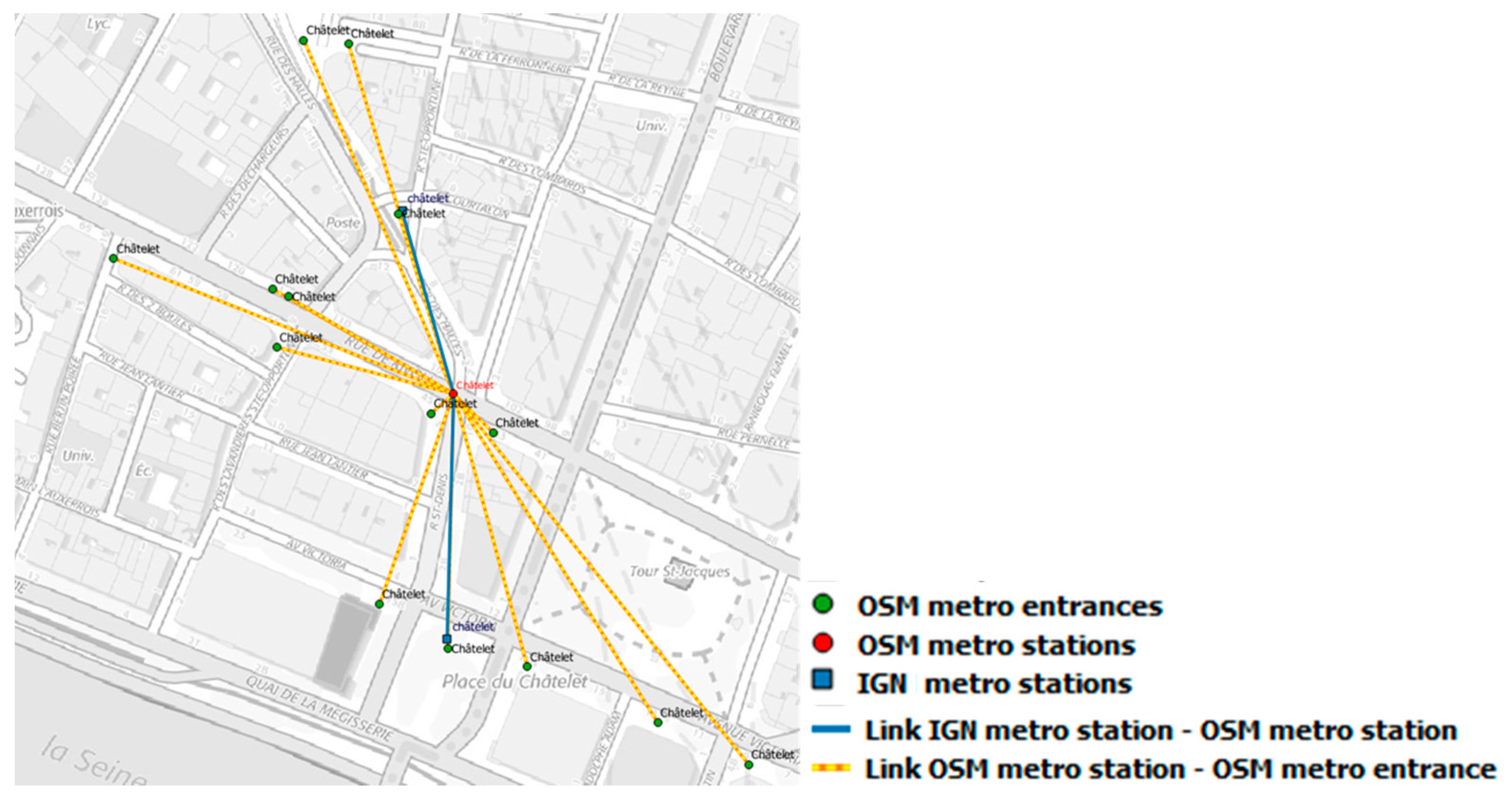
Figure 11.
Data matching results for Châtelet subway station (©OpenStreetMap contributors, ©BDTOPO).
Figure 11.
Data matching results for Châtelet subway station (©OpenStreetMap contributors, ©BDTOPO).
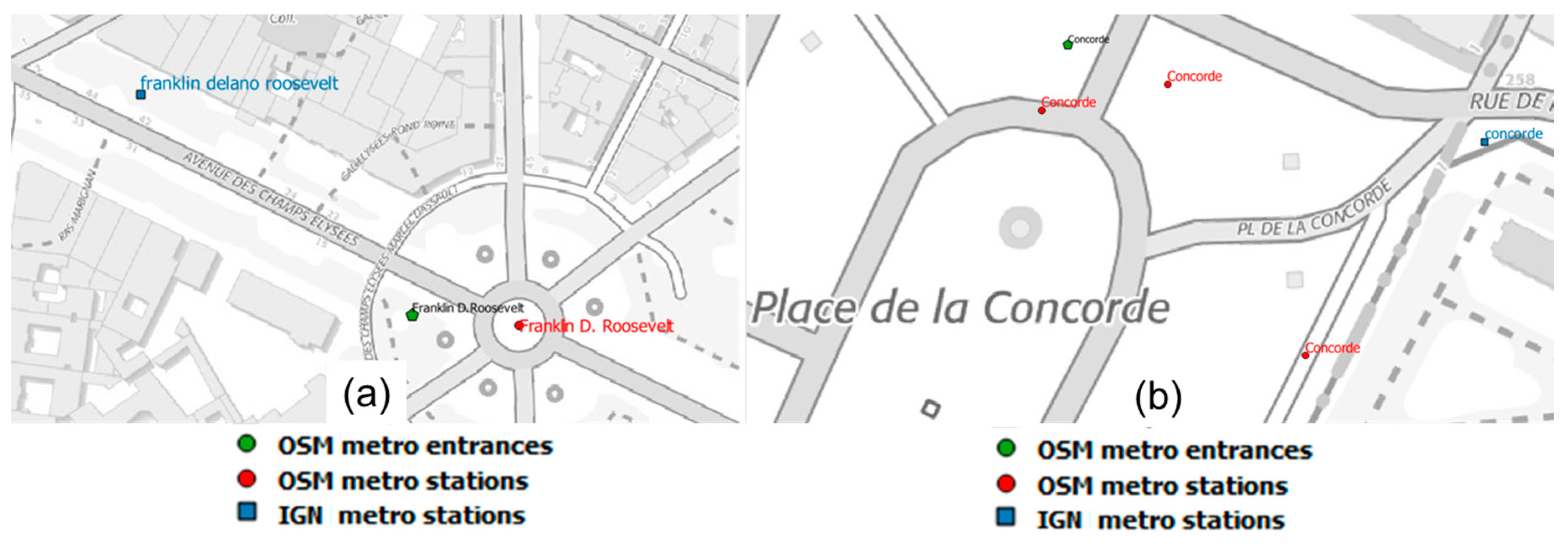
Figure 12.
Data matching results: (a) wrongly non-matched; (b) correctly non-matched (©OpenStreetMap contributors, ©BDTOPO).
Figure 12.
Data matching results: (a) wrongly non-matched; (b) correctly non-matched (©OpenStreetMap contributors, ©BDTOPO).
Figure 13.
Comparison between homologous features: (a) Euclidian distance between IGN and OSM subway stations and (b) Euclidian distance between IGN and OSM subway stations in red and the distance between IGN subway stations and the nearest corresponding OSM subway entrances in green.
Figure 13.
Comparison between homologous features: (a) Euclidian distance between IGN and OSM subway stations and (b) Euclidian distance between IGN and OSM subway stations in red and the distance between IGN subway stations and the nearest corresponding OSM subway entrances in green.
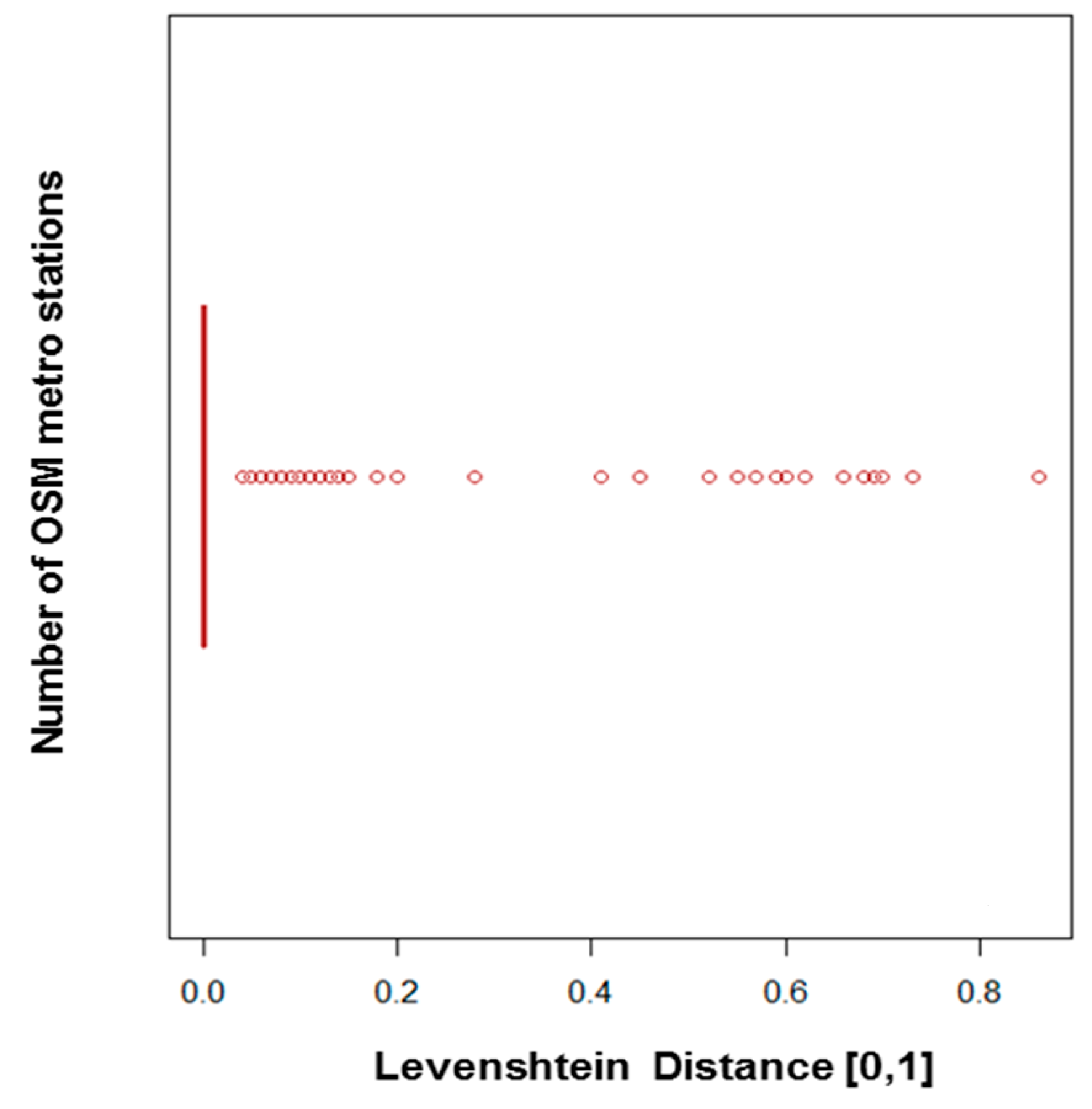
Figure 14.
Comparison of names of homologous subway stations using the Levenshtein distance.
Figure 14.
Comparison of names of homologous subway stations using the Levenshtein distance.
Figure 15.
The use of Flickr photographs to verify OSM POIs. (a) OSM map for an area in Paris with POIs that are under trees; (b) the same area with the IGN polygons of the wooded areas and the position of geo-tagged Flickr photographs. A Flickr photograph is shown in a pop-up as well as additional attributes provided by the photographer (©OpenStreetMap contributors, ©IGN).
Figure 15.
The use of Flickr photographs to verify OSM POIs. (a) OSM map for an area in Paris with POIs that are under trees; (b) the same area with the IGN polygons of the wooded areas and the position of geo-tagged Flickr photographs. A Flickr photograph is shown in a pop-up as well as additional attributes provided by the photographer (©OpenStreetMap contributors, ©IGN).
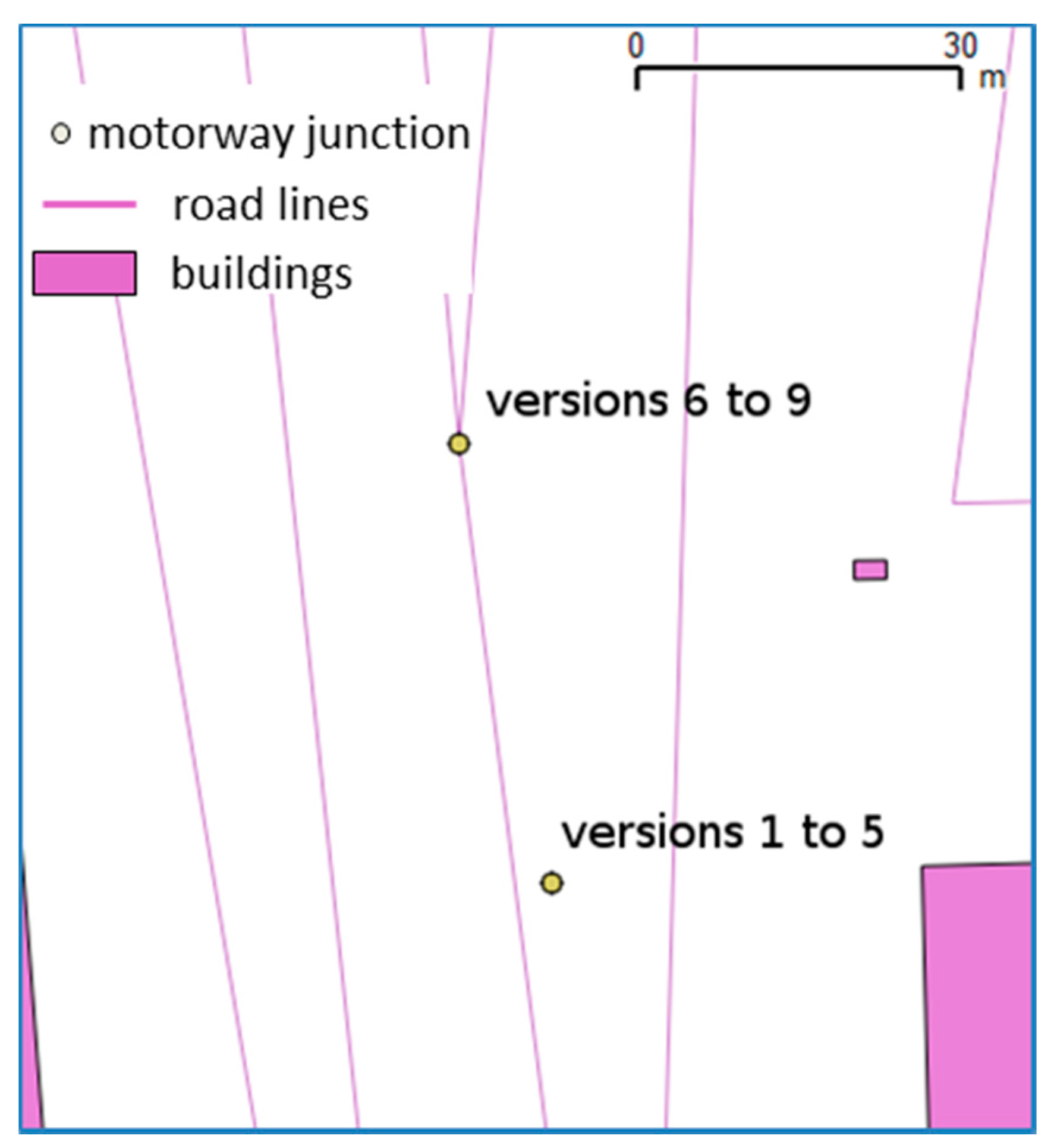
Figure 16.
The motorway junction is displaced at the intersection of the motorway and the ramp at version 6, where the displacement is large, i.e., greater than 30 m (©OpenStreetMap contributors).
Figure 16.
The motorway junction is displaced at the intersection of the motorway and the ramp at version 6, where the displacement is large, i.e., greater than 30 m (©OpenStreetMap contributors).
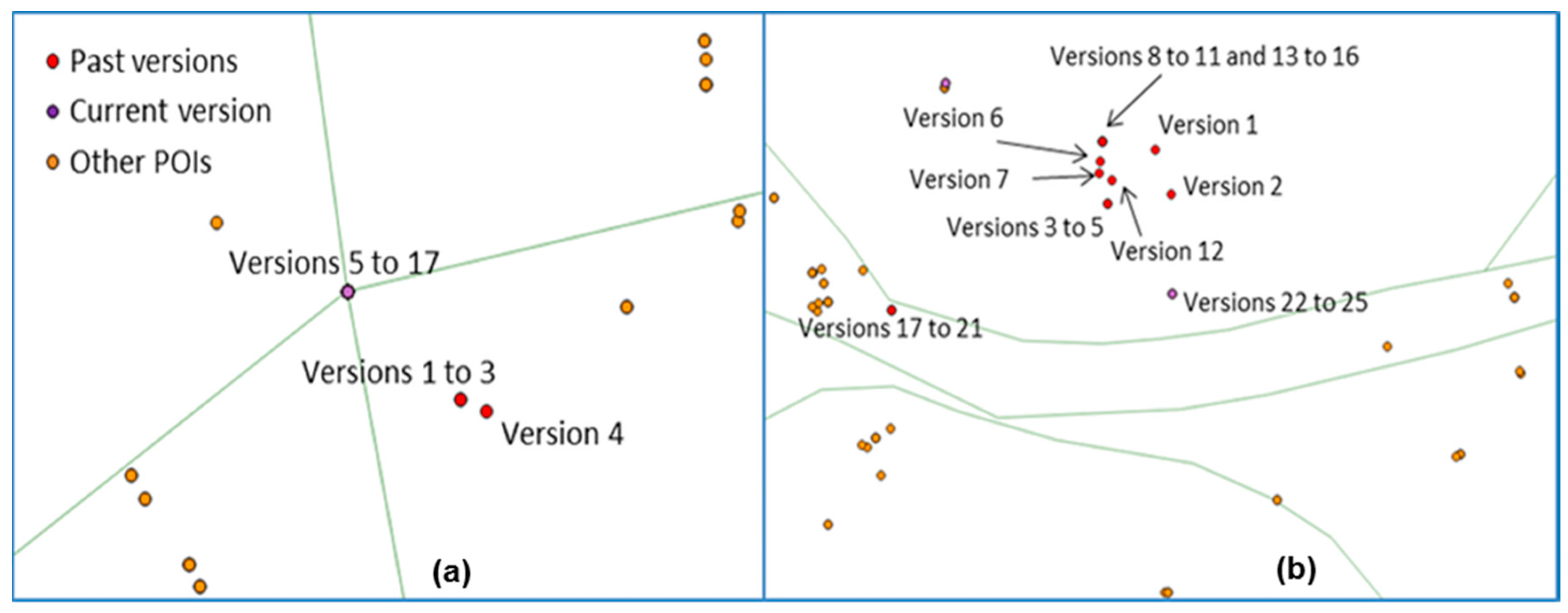
Figure 17.
Two examples of the evolution of subway station location: (a) the station is put at the intersection of the subway lines in version 5 and then never moves (only tags are then modified); (b) the current version is still wrongly located, and we can see many displacements due to contributor disagreements, as 17 contributors edited this feature (©OpenStreetMap contributors).
Figure 17.
Two examples of the evolution of subway station location: (a) the station is put at the intersection of the subway lines in version 5 and then never moves (only tags are then modified); (b) the current version is still wrongly located, and we can see many displacements due to contributor disagreements, as 17 contributors edited this feature (©OpenStreetMap contributors).
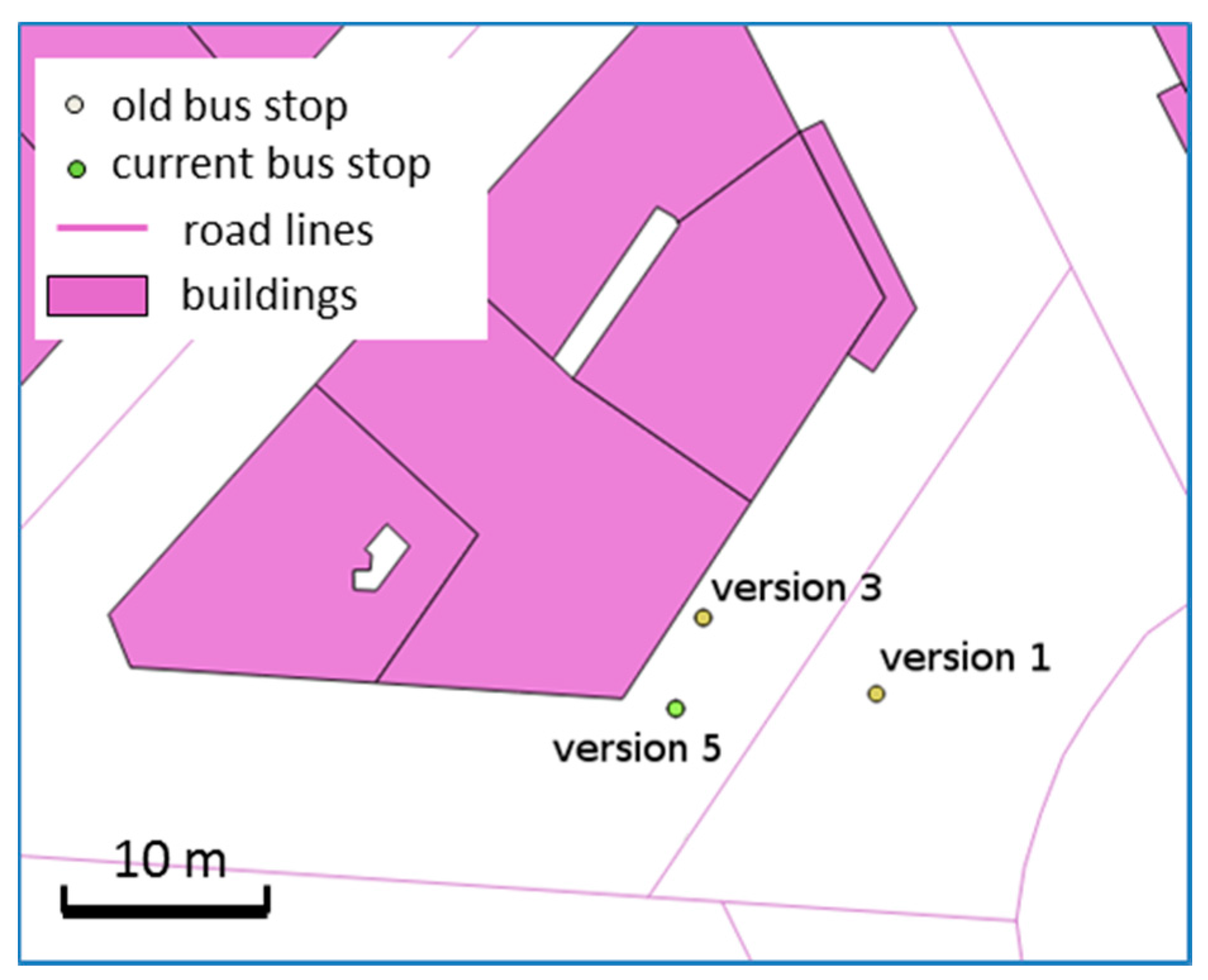
Figure 18.
Evolution of bus stop location: the bus stop did move between version 1 and 3, but version 5 is just a better placement as version 3 was too close to the building boundary (©OpenStreetMap contributors).
Figure 18.
Evolution of bus stop location: the bus stop did move between version 1 and 3, but version 5 is just a better placement as version 3 was too close to the building boundary (©OpenStreetMap contributors).
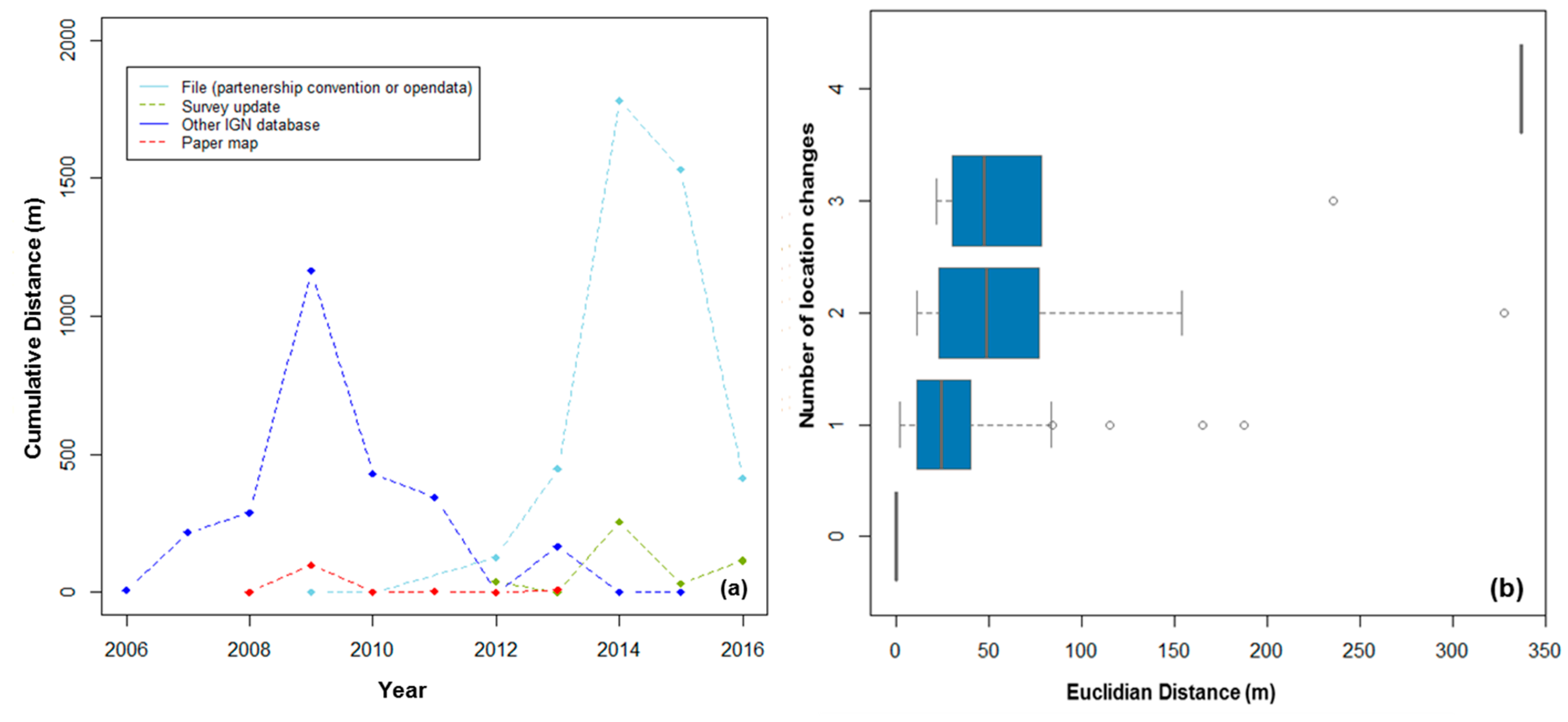
Figure 19.
Evolution of subway stations in the IGN dataset: (a) sources of change and (b) location changes over time for the Paris region.
Figure 19.
Evolution of subway stations in the IGN dataset: (a) sources of change and (b) location changes over time for the Paris region.
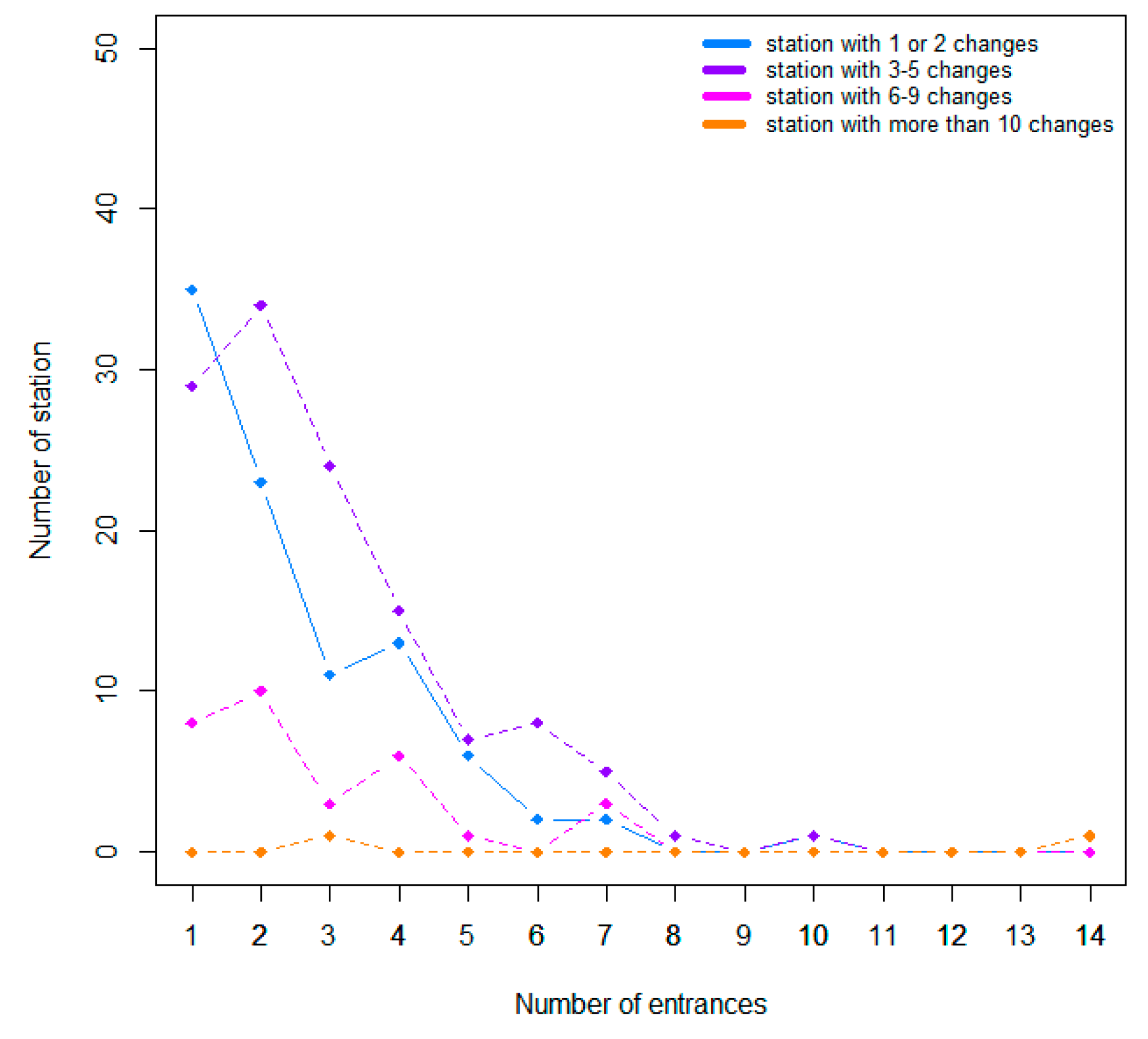
Figure 20.
Relationship between the number of subway entrances for each subway stations and the number of changes.
Figure 20.
Relationship between the number of subway entrances for each subway stations and the number of changes.
Table 1.
The statistics of the positional movement of the top 10 OSM feature types according to the number of features.
Table 1.
The statistics of the positional movement of the top 10 OSM feature types according to the number of features.
| # | POI Category | Count | Mean Distance (m) | SDev. (m) | Max Distance (m) |
|---|
| 1 | bus_stop | 3418 | 9.2 | 23.6 | 567.0 |
| 2 | restaurant | 1248 | 8.6 | 28.7 | 467.4 |
| 3 | station | 535 | 39.9 | 138.5 | 2794.3 |
| 4 | bicycle_rental | 499 | 13.8 | 35.8 | 340.3 |
| 5 | bank | 464 | 6.4 | 19.8 | 349.7 |
| 6 | cafe | 452 | 6.0 | 24.8 | 412.2 |
| 7 | supermarket | 393 | 11.7 | 45.5 | 842.7 |
| 8 | pharmacy | 364 | 5.7 | 14.1 | 198.2 |
| 9 | hotel | 274 | 14.7 | 38.0 | 338.9 |
| 10 | bakery | 265 | 4.7 | 10.9 | 113.1 |
Table 2.
The statistics of the positional movement of the top 10 OSM feature types according to the mean distance (in m) of positional movement.
Table 2.
The statistics of the positional movement of the top 10 OSM feature types according to the mean distance (in m) of positional movement.
| # | POI Category | Count | Mean Distance (m) | SDev. (m) | Max Distance (m) |
|---|
| 1 | station | 535 | 39.9 | 138.5 | 2794.3 |
| 2 | motorway_junction | 223 | 34.3 | 42.7 | 321.5 |
| 3 | fuel | 186 | 33.7 | 75.5 | 659.7 |
| 4 | drinking_water | 63 | 21.0 | 66.0 | 372.6 |
| 5 | hotel | 274 | 14.7 | 38.0 | 338.9 |
| 6 | bicycle_rental | 499 | 13.8 | 35.8 | 340.3 |
| 7 | kindergarten | 45 | 13.3 | 21.3 | 108.3 |
| 8 | school | 239 | 12.8 | 17.2 | 122.7 |
| 9 | supermarket | 393 | 11.7 | 45.5 | 842.7 |
| 10 | post_office | 231 | 11.1 | 23.2 | 250.4 |
Table 3.
Summary of the amenities’ locations consistency in buildings that contain at least three POIs.
Table 3.
Summary of the amenities’ locations consistency in buildings that contain at least three POIs.
| % of POIs Outside Buildings (m) | Mean Distance to Centroid (DC) (m) | SDev. of DC (m) | DC with Voronoï (m) | Mean Distance to Boundary (DB) (m) | SDev. of DB (m) | DB with Voronoï (m) |
|---|
| Gift shops | 0 | 12.9 | 11.5 | 7.72 | 2.3 | 3 | 3.15 |
| Bars, cafes, Restaurants | 3 | 10.8 | 10.5 | 7.21 | 2.3 | 2.1 | 2.27 |
| Cinemas | 5.5 | 16.9 | 18.4 | 9.39 | 4.9 | 4.9 | 4.57 |
| Hairdressers | 1.4 | 11.3 | 9.5 | 7.07 | 2.1 | 1.2 | 2.19 |
Table 4.
Summary of the locations’ consistency of amenities in buildings that contain at least three POIs.
Table 4.
Summary of the locations’ consistency of amenities in buildings that contain at least three POIs.
| Mean of SDev | Median of SDev | Minimum of SDev | Maximum of SDev |
|---|
| Distance to center | 2.99 | 1.56 | 0 | 76.5 |
| Distance to boundary | 2.46 | 2.15 | 0 | 38.5 |
Table 5.
Summary of the ATM locations in relation to building center and boundary.
Table 5.
Summary of the ATM locations in relation to building center and boundary.
| Mean (m) | Median (m) | SDev (m) |
|---|
| Distance to center | 17.6 | 13 | 12.9 |
| Distance to boundary | 1.1 | 0 | 4.6 |
Table 6.
Summary of the school locations in relation to building/extent center and boundary.
Table 6.
Summary of the school locations in relation to building/extent center and boundary.
| % Outside Buildings | Mean Distance to Center (m) | Mean Distance to Boundary (m) |
|---|
| Schools with a polygon | 40 | 31.6 | 13.3 |
| Schools without a polygon | 30 | 19.1 | 4.7 |
Table 7.
Summary of the bus stop locations in relation to buildings and road centerlines.
Table 7.
Summary of the bus stop locations in relation to buildings and road centerlines.
| Mean (m) | SDev (m) | Maximum (m) | % Too Close | % Too Far |
|---|
| Distance to roads | 6.2 | 2.9 | 18.5 | 6.8 | 0.4 |
| Distance to buildings | 7.4 | 5.8 | - | 6.7 | - |
Table 8.
Data matching results and evaluation.
Table 8.
Data matching results and evaluation.
| Data Matching | | Number of Features | Precision | Recall |
|---|
| IGN subway stations/OSM stations (348 IGN subway stations/704 OSM stations) | Matched IGN subway station | 329 (1 error) | 99.7% | 98% |
| Non-matched IGN subway station | 9 (2 errors) | 78% | 78% |
| Without decision IGN subway station | 10 | - | - |
| OSM subway entrances/OSM stations (794 OSM subway entrances/704 OSM stations) | Matched OSM subway entrances | 701 | 100% | - |
| Non-matched OSM subway entrances | 19 | 0% | 0% |
| Without decision OSM subway entrances | 74 | - | - |
Table 9.
Data quality analysis with respect to the observed naming standard for OSM subway entrances.
Table 9.
Data quality analysis with respect to the observed naming standard for OSM subway entrances.
| Name of OSM Subway Entrances Versus Name of Subway Stations |
|---|
| case 1 | 340 OSM subway entrances have a name starting with the corresponding name of the OSM subway station |
| 156 OSM subway entrances have a name partially starting with its corresponding OSM subway station |
| 6 OSM subway stations have a name more detailed than the name of the OSM subway entrances ‘Chaussée d’Antin—La Fayette’ (OSM subway station) versus ‘Chaussée d’Antin’ (OSM subway entrances) |
| 5 OSM subway stations have names strictly integrated into the OSM subway entrances: ‘Denfert-Rochereau’ versus ‘Métropolitain, station Denfert-Rochereau’, ‘Saint-Michel’ versus ‘Quai Saint-Michel (Notre-Dame)’ |
| case 2 | For an OSM subway station that has at least two corresponding OSM subway entrances, 463 OSM subway entrances have a name contained in the name of the OSM subway station |
| Among the 463 OSM subway entrances, 306 (66%) have exactly the same name as the corresponding OSM subway station |
| case 3 | 168 OSM subway entrances contain the word exit. Among those, 22 do not contain the name of the OSM subway station (e.g., ‘Pernéty’ versus ‘Pernety—sortie 2—rue Niepce’. Adding the sign ‘—‘ between the name of the subway station and the word exit has been noticed |
| 142 OSM subway entrances that contain the name of the subway stations follow the standard: Name of the subway station—Exit nn—street xxx (e.g., ‘Bastille—sortie 1—rue de la Roquette’) |
| 4 OSM subway entrances start with the word Exit (e.g., ‘Sortie 3—Rue Goscinny’) |
| 148 OSM subway entrances have a number after the word Exit |
Table 10.
Change location patterns for subway stations and subway entrances with respect to a reference.
Table 10.
Change location patterns for subway stations and subway entrances with respect to a reference.
| Patterns | OSM Subway Station vs. IGN Subway Station (a) | IGN Subway Station vs. OSM Subway Station (b) | OSM Subway Entrance vs. IGN Subway Station (c) |
|---|
| Without location history | 0 | 0 | 449 |
| Get closer to the reference | 109 | 61 | 76 |
| Diverging from the reference | 52 | 92 | 60 |
| Disagreement but finally get closer to the reference | 35 | 9 | 7 |
| Disagreement but finally diverge from the reference | 69 | 6 | 47 |
| Disagreement: Get closer and return to the previous location | 17 | 0 | 0 |
| Disagreement: Diverge and return to the previous location | 14 | 0 | 0 |
Table 11.
Evolution of names of OSM subway entrances.
Table 11.
Evolution of names of OSM subway entrances.
| Current Version (T)/523 | Previous Version Ti+j/258 | Previous Version Ti+j/64 |
|---|
| Case 1 | 458 | 117 | 11 |
| Case 2 | 383 | 101 | 11 |
| Case 3 | 144 | 17 | 3 |


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}