Higher Order Support Vector Random Fields for Hyperspectral Image Classification


Abstract
:1. Introduction
2. Higher Order Support Vector Random Fields for HSI Classification
2.1. Problem Formulation
2.2. Higher Order Support Vector Random Fields
- Step 1. Start with some initial and .
2.3. Parameter Learning and Inference
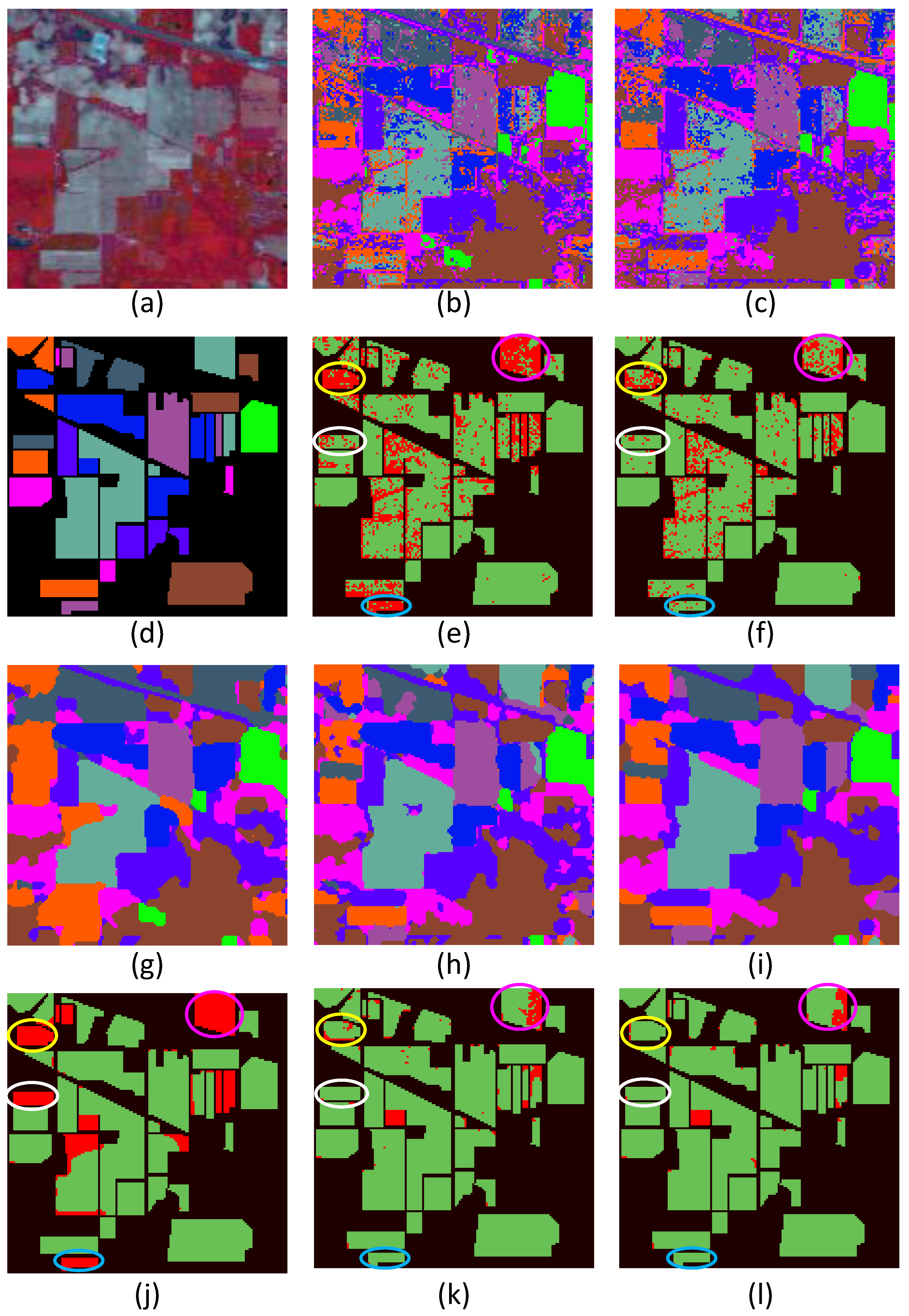
3. Experimental Results
3.1. Experimental Setting
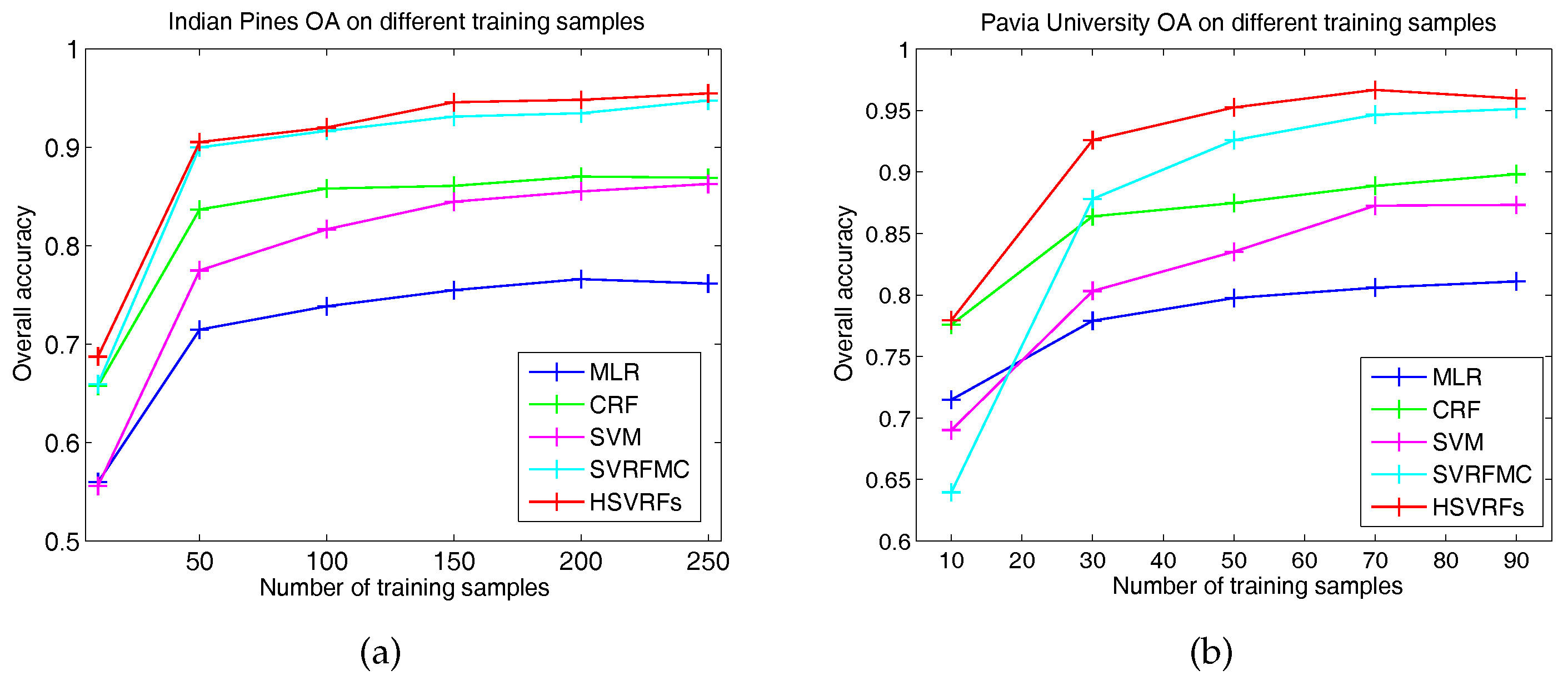
3.2. Classification Performance
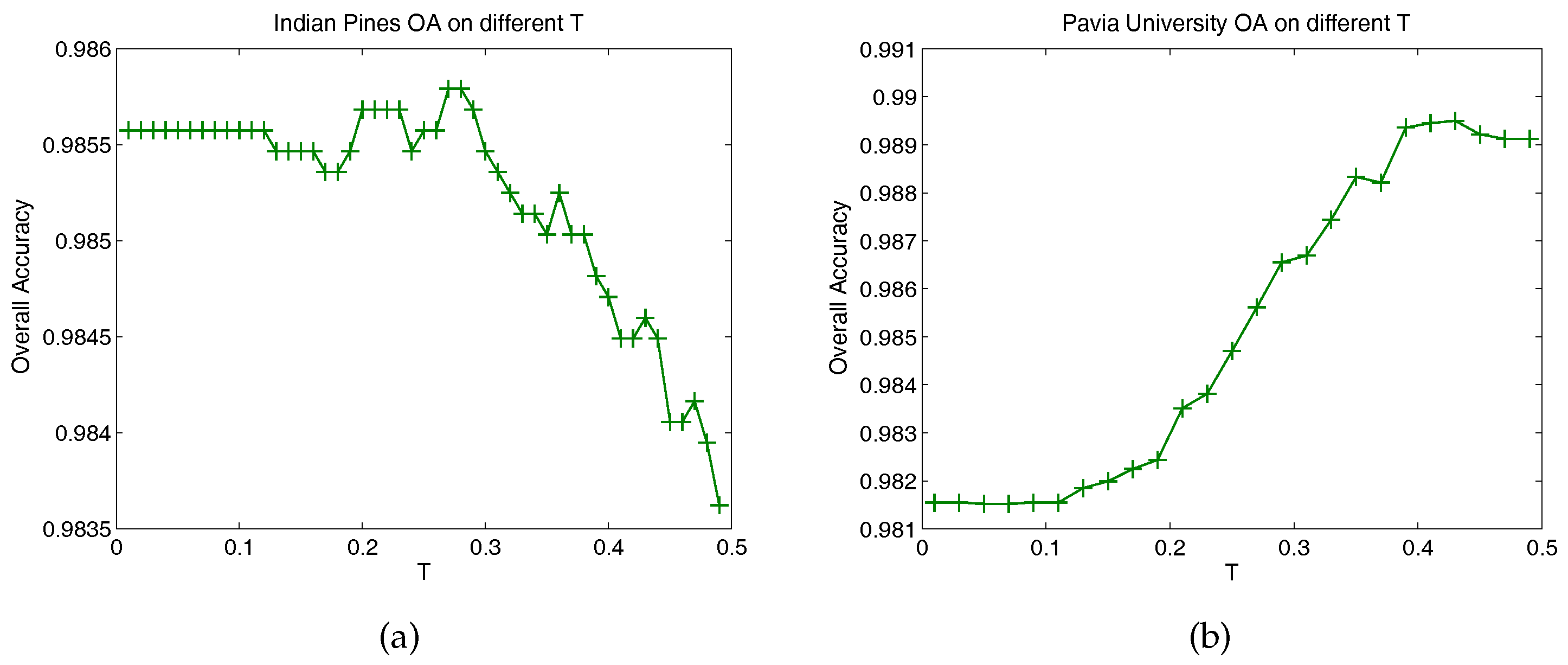
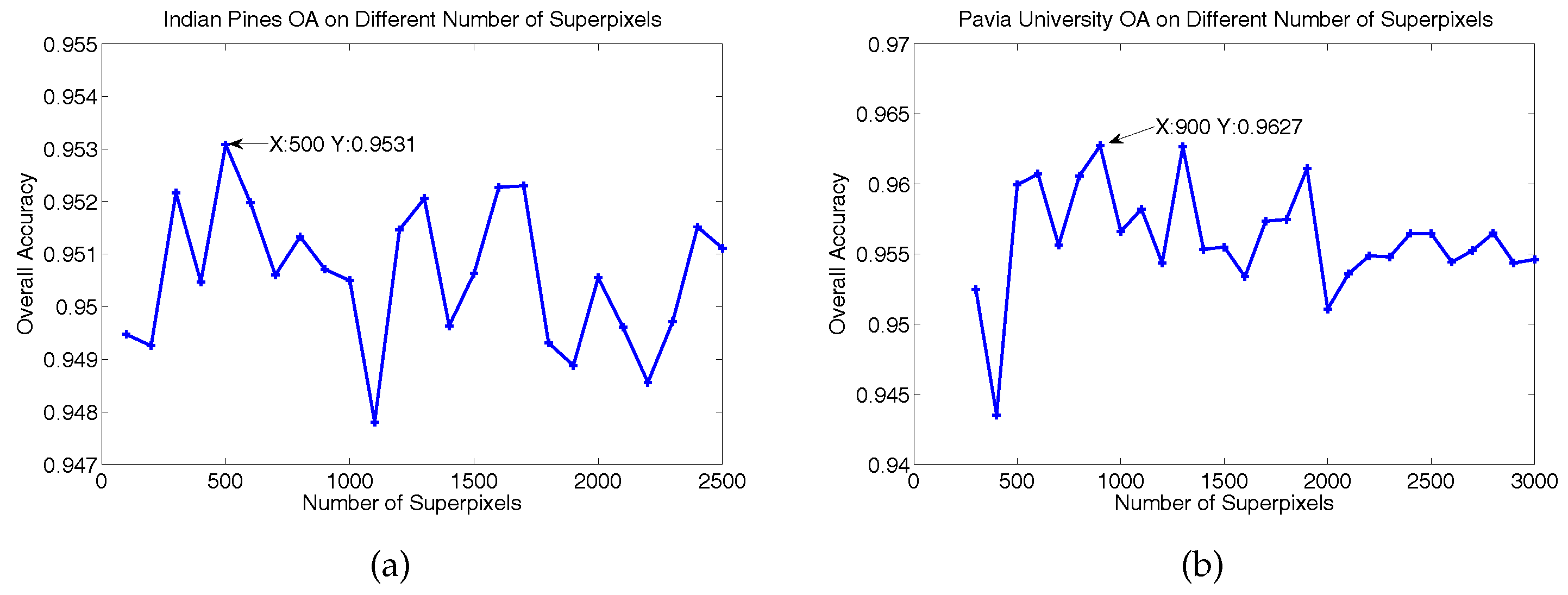
3.3. Parameter Analysis
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Gualtieri, J.; Chettri, S. Support vector machines for classification of hyperspectral data. In Proceedings of the IEEE 2000 International Geoscience and Remote Sensing Symposium (IGARSS 2000), Honolulu, HI, USA, 24–28 July 2000; Volume 2, pp. 813–815. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Munoz-Mari, J.; Vila-Frances, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J. Spectral-spatial Classification of Hyperspectral Imagery Based on Partitional Clustering Techniques. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2973–2987. [Google Scholar] [CrossRef]
- Khodadadzadeh, M.; Li, J.; Plaza, A.; Ghassemian, H.; Bioucas-Dias, J.M. Spectral-spatial classification for hyperspectral data using SVM and subspace MLR. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, VIC, Australia, 21–26 July 2013; pp. 2180–2183. [Google Scholar]
- Campsvalls, G.; Tuia, D.; Bruzzone, L.; Atli Benediktsson, J. Advances in Hyperspectral Image Classification: Earth Monitoring with Statistical Learning Methods. IEEE Signal Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Learning conditional random fields for classification of hyperspectral images. IEEE Trans. Image Process. 2010, 19, 1890–1907. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Zhao, J.; Zhang, L. A hybrid object-oriented conditional random field classification framework for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7023–7037. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models For Segmenting And Labeling Sequence Data. Proceeding of the Eighteenth International Conference on Machine Learning (ICML ’01), San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Kumar, S.; Hebert. Discriminative Random Fields: A Discriminative Framework for Contextual Interaction in Classification. Proceeding of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; IEEE Computer Society: Washington, DC, USA, 2003; pp. 1150–1157. [Google Scholar]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. TextonBoost: Joint Appearance, Shape and Context Modeling for Multi-class Object Recognition and Segmentation. Proceeding of the Computer Vision ECCV 2006, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–15. [Google Scholar]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef]
- He, X.; Zemel, R.S.; Carreira-Perpiñán, M.Á. Multiscale conditional random fields for image labeling. Proceeding of the IEEE Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 695–702. [Google Scholar]
- He, X. Learning Structured Prediction Models for Image Labeling; University of Toronto: Toronto, ON, Canada, 2008. [Google Scholar]
- Torralba, A.; Murphy, K.P.; FFreeman, W.T. Contextual models for object detection using boosted random fields. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Gould, S.; Rodgers, J.; Gould, S.; Rodgers, J.; Cohen, D.; Elidan, G.; Koller, D. Multi-class segmentation with relative location prior. Int. J. Comput. Vis. 2008, 80, 300–316. [Google Scholar] [CrossRef]
- Gould, S.; Fulton, R.; Koller, D. Decomposing a scene into geometric and semantically consistent regions. Proceeding of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1–8. [Google Scholar]
- Ladicky, L.; Sturgess, P.; Russell, C.; Sengupta, S.; Bastanlar, Y.; Clocksin, W.; Torr, P.H. Joint optimization for object class segmentation and dense stereo reconstruction. Int. J. Comput. Vis. 2012, 100, 122–133. [Google Scholar] [CrossRef]
- Ladicky, L.; Russell, C.; Kohli, P.; Torr, P.H. Associative hierarchical CRF for object class image segmentation. Proceeding of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 739–746. [Google Scholar]
- Huang, Q.; Han, M.; Wu, B.; Ioffe, S. A hierarchical conditional random field model for labeling and segmenting images of street scenes. Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1953–1960. [Google Scholar]
- Li, X.; Sahbi, H. Superpixel-Based Object Class Segmentation Using Conditional Random Fields. Proceeding of the 36th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2011), Prague, Czech Republic, 22–27 May 2011; pp. 1101–1104. [Google Scholar]
- Kohli, P.; Ladicky, L.; Torr, P.H.S. Robust higher order potentials for enforcing label consistency. Int. J. Comput. Vis. 2009, 82, 302–324. [Google Scholar] [CrossRef]
- Kohli, P.; Kumar, M.P.; Torr, P.H.S. P3 and beyond: Solving energies with higher order cliques. Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Zhong, Y.; Lin, X.; Zhang, L. A support vector conditional random fields classifier with a mahalanobis distance boundary constraint for high spatial resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1314–1330. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Modeling and classifying hyperspectral imagery by CRFs with sparse higher order potentials. IEEE Trans. Geosci. Remote Sens. 2011, 49, 688–705. [Google Scholar] [CrossRef]
- Zhong, P.; Liu, F.; Wang, R. Learning sparse conditional random fields to select features for land development classification. Int. J. Remote Sens. 2011, 32, 4203–4219. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Jointly learning the hybrid CRF and MLR model for simultaneous denoising and classification of hyperspectral imagery. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1319–1334. [Google Scholar] [CrossRef]
- Zhao, J.; Zhong, Y.; Zhang, L. Detail-Preserving Smoothing Classifier Based on Conditional Random Fields for High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2440–2452. [Google Scholar] [CrossRef]
- Besbes, O.; Benazza-Benyahia, A. Road network extraction by a higher-order CRF model built on centerline cliques. Proceeding of the IEEE 23rd European Signal Processing Conference, Nice, France, 31 August–4 September 2015; pp. 1631–1635. [Google Scholar]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust Rooftop Extraction From Visible Band Images Using Higher Order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Aghighi, H.; Trinder, J.; Tarabalka, Y.; Lim, S. Dynamic Block-Based Parameter Estimation for MRF Classification of High-Resolution Images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1687–1691. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Rana, A. Graph-Cut-Based Model for Spectral-Spatial Classification of Hyperspectral Images. Proceeding of the 2014 IEEE International Conference on Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 3418–3421. [Google Scholar]
- Lee, C.H.; Greiner, R.; Schmidt, M. Support vector random fields for spatial classification. In Knowledge Discovery in Databases: PKDD 2005; Springer: New York, NY, USA, 2005; pp. 121–132. [Google Scholar]
- Zhang, G.; Jia, X. Simplified Conditional Random Fields With Class Boundary Constraint for Spectral-Spatial Based Remote Sensing Image Classification. IEEE Geosci. Remote Sens. Lett. 2012, 9, 856–860. [Google Scholar] [CrossRef]
- Cheng, Q.; Varshney, P.K.; Arora, M.K. Logistic regression for feature selection and soft classification of remote sensing data. IEEE Geosci. Remote Sens. Lett. 2006, 3, 491–494. [Google Scholar] [CrossRef]
- Platt, J. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. Proceeding of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Waske, B.; Benediktsson, J.A. Fusion of support vector machines for classification of multisensor data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3858–3866. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Wu, T.F.; Lin, C.J.; Weng, R.C. Probability estimates for multi-class classification by pairwise coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. Piecewise pseudolikelihood for efficient training of conditional random fields. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; ACM: New York, NY, USA, 2007; pp. 863–870. [Google Scholar]
- Besag, J. Statistical analysis of non-lattice data. Statistician 1975, 24, 179–195. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Aviris, N. Indiana’s Indian Pines 1992 Data Set. 2012. Available online: http://www.ehu.eus/ccwintco/index.php?title=HyperspectralRemoteSensingScenes (accessed on 24 October 2017).
- Zhong, P.; Wang, R. Learning sparse CRFs for feature selection and classification of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4186–4197. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cognit. Model. 1988, 5, 3. [Google Scholar] [CrossRef]
- Bryson, A.E. Applied Optimal Control: Optimization, Estimation and Control; Halsted Press: Sydney, Australia, 1975. [Google Scholar]
- Arora, H.; Loeff, N.; Forsyth, D.; Ahuja, N. Unsupervised segmentation of objects using efficient learning. Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’07), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training Samples | Testing Samples | MLR | CRFs | SVM | SVRFMC | HSVRFs |
|---|---|---|---|---|---|---|---|
| Corn-notill | 200 | 1228 | 72.08 | 77.98 | 81.68 | 85.03 | 90.78 |
| Corn-mintill | 200 | 630 | 65.62 | 95.78 | 83.97 | 96.54 | 98.13 |
| Grass-pasture | 200 | 283 | 94.06 | 96.82 | 95.97 | 98.80 | 97.95 |
| Grass-trees | 200 | 530 | 97.96 | 99.66 | 98.94 | 99.89 | 99.92 |
| Hay-windrowed | 200 | 278 | 99.86 | 100 | 100 | 100 | 100 |
| Soybean-notill | 200 | 772 | 76.01 | 82.23 | 85.65 | 94.90 | 94.97 |
| Soybean-mintill | 200 | 2255 | 62.07 | 78.05 | 74.59 | 90.10 | 91.03 |
| Soybean-clean | 200 | 393 | 78.88 | 95.73 | 91.60 | 97.81 | 97.96 |
| Woods | 200 | 1065 | 97.45 | 99.32 | 98.46 | 99.57 | 99.61 |
| OA | 76.62 | 87.03 | 85.52 | 93.47 | 94.83 | ||
| Kappa | 72.46 | 84.64 | 82.84 | 92.20 | 93.81 |
| Class | Training Samples | Testing Samples | MLR | CRF-H [27] | CRFs | SVM | SVRFMC | HSVRFs |
|---|---|---|---|---|---|---|---|---|
| Corn-notill | 742 | 692 | 82.75 | 91.04 | 82.51 | 83.70 | 81.07 | 88.62 |
| Corn-mintill | 442 | 392 | 68.55 | 85.97 | 67.27 | 88.28 | 98.28 | 99.14 |
| Grass-pasture | 260 | 237 | 93.46 | 87.34 | 96.41 | 96.14 | 99.57 | 97.85 |
| Grass-trees | 390 | 357 | 98.46 | 98.32 | 99.71 | 98.96 | 99.58 | 100.00 |
| Hay-windrowed | 236 | 253 | 98.55 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Soybean-notill | 488 | 480 | 70.08 | 84.58 | 80.99 | 84.35 | 95.29 | 98.75 |
| Soybean-mintill | 1246 | 1222 | 84.27 | 96.07 | 93.63 | 74.51 | 89.98 | 92.06 |
| Soybean-clean | 306 | 308 | 75.82 | 96.10 | 80.49 | 92.42 | 97.38 | 98.54 |
| Woods | 652 | 642 | 99.23 | 99.84 | 99.18 | 98.72 | 99.61 | 99.80 |
| OA | 85.07 | 93.69 | 89.13 | 91.66 | 97.43 | 98.50 | ||
| Kappa | 87.12 | 90.18 | 96.97 | 98.23 |
| Class | Training Samples | Testing Samples | MLR | CRFs | SVM | SVRFMC | HSVRFs |
|---|---|---|---|---|---|---|---|
| Asphalt | 70 | 6561 | 71.75 | 79.13 | 80.98 | 97.95 | 95.11 |
| Meadows | 70 | 18579 | 80.51 | 90.07 | 87.27 | 96.32 | 96.73 |
| Gravel | 70 | 2029 | 82.12 | 89.48 | 83.53 | 98.99 | 92.78 |
| Trees | 70 | 2994 | 93.04 | 94.78 | 94.60 | 75.87 | 92.19 |
| Metal sheets | 70 | 1275 | 99.60 | 99.57 | 99.44 | 99.64 | 99.50 |
| Bare Soil | 70 | 4959 | 84.46 | 96.17 | 89.08 | 100.00 | 99.60 |
| Bitumen | 70 | 1260 | 85.89 | 88.65 | 93.76 | 99.62 | 99.87 |
| Bricks | 70 | 3612 | 73.96 | 90.05 | 82.57 | 84.62 | 98.10 |
| Shadows | 70 | 877 | 98.13 | 99.56 | 99.95 | 85.09 | 100.00 |
| OA | 80.59 | 88.88 | 87.27 | 94.65 | 96.67 | ||
| Kappa | 84.88 | 91.39 | 90.13 | 93.12 | 97.10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Jiang, Z.; Hao, S.; Zhang, H. Higher Order Support Vector Random Fields for Hyperspectral Image Classification. ISPRS Int. J. Geo-Inf. 2018, 7, 19. https://doi.org/10.3390/ijgi7010019
Yang J, Jiang Z, Hao S, Zhang H. Higher Order Support Vector Random Fields for Hyperspectral Image Classification. ISPRS International Journal of Geo-Information. 2018; 7(1):19. https://doi.org/10.3390/ijgi7010019
Chicago/Turabian StyleYang, Junli, Zhiguo Jiang, Shuang Hao, and Haopeng Zhang. 2018. "Higher Order Support Vector Random Fields for Hyperspectral Image Classification" ISPRS International Journal of Geo-Information 7, no. 1: 19. https://doi.org/10.3390/ijgi7010019
APA StyleYang, J., Jiang, Z., Hao, S., & Zhang, H. (2018). Higher Order Support Vector Random Fields for Hyperspectral Image Classification. ISPRS International Journal of Geo-Information, 7(1), 19. https://doi.org/10.3390/ijgi7010019